分布式专题——14 RabbitMQ之集群实战
1 RabbitMQ的性能监控
-
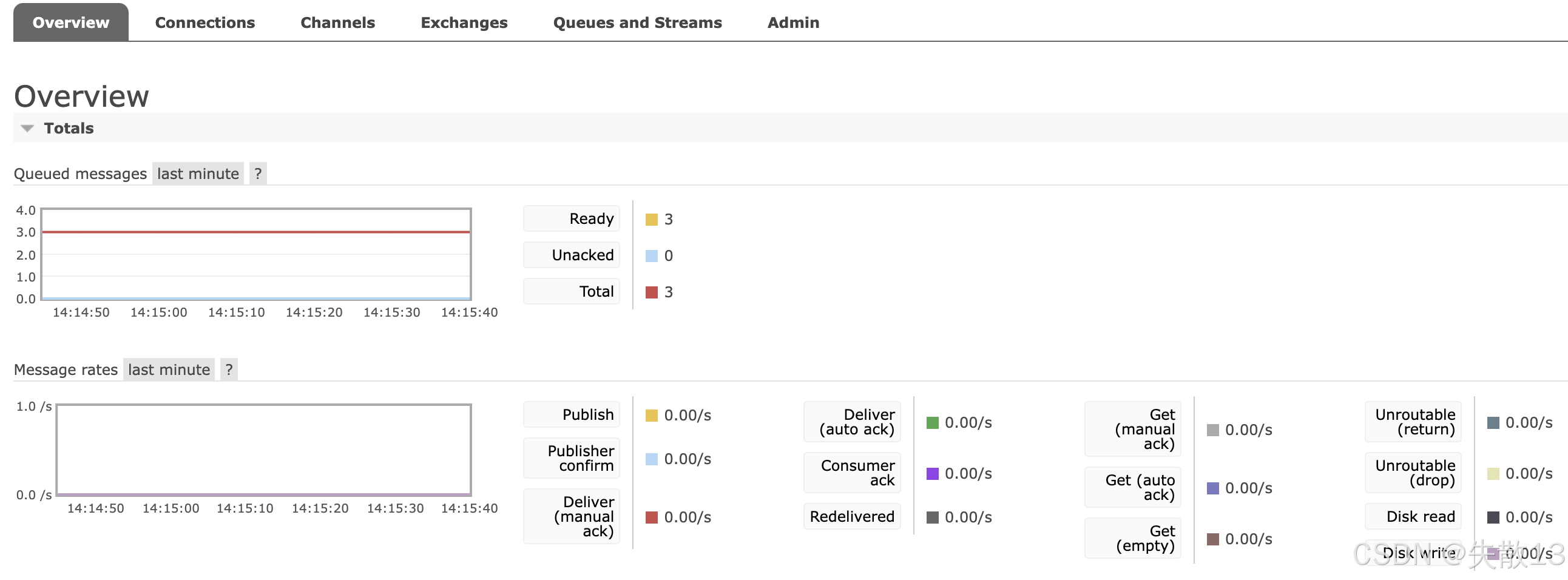
RabbitMQ 的管理控制台为性能监控提供了直观的界面。在控制台的**Overview(概览)**页面,能看到诸多关键信息:
-
Queued messages(队列消息):可查看最近一分钟内队列中的消息数量变化,包括
Ready(就绪可消费的消息数)、Unacked(已投递但未确认的消息数)以及Total(消息总数); -
Message rates(消息速率):展示各类消息操作的速率,像
Publish(消息发布速率)、Deliver(消息投递速率)、Consumer ack(消费者确认速率)等; -
此外,还能了解消息的生产消费频率、关键组件(如连接、通道等)的使用情况。不过,管理控制台更适合人工查看和临时监控,若要构建自动化的性能监控系统,就需要借助 RabbitMQ 提供的 HTTP API;
-
-
RabbitMQ 提供了丰富的 HTTP API,用于更灵活、自动化地管理和监控 RabbitMQ,这些 API 文档可在部署的管理控制台页面下方找到;
-
认证与虚拟主机:
- API 使用 HTTP 基本认证,默认用户是
guest/guest,访问时需提供 RabbitMQ 的用户名和密码; - 很多 API 需要指定虚拟主机(virtual host),默认虚拟主机是
/,在路径中需编码为%2F;
- API 使用 HTTP 基本认证,默认用户是
-
请求与响应:
- 支持多种 HTTP 请求方法,如 GET 用于获取信息,POST 用于创建资源(如绑定、队列等),PUT 用于修改资源,DELETE 用于删除资源等;
- 请求体通常为 JSON 格式,创建资源时,JSON 对象需包含必填字段,缺少必填字段会报错;多余字段会被忽略;
-
查询参数:
sort和sort_reverse:sort指定排序的字段,sort_reverse设为true时可反转排序顺序,还可对字段子项进行排序(如sort=name按名称排序);limit:用于限制返回结果的数量,便于分页或获取部分数据;columns:可指定返回结果中包含的字段,减少返回数据量,提升性能,尤其在监控场景下能降低系统资源消耗;
-
典型 API 示例:
http://[server]:[port]/api/overview,这是常用的 API 接口,能获取系统的资源使用情况等大量信息,可很好地对接 Prometheus、Grafana 等监控工具,构建灵活的监控告警体系; -
安全性考虑:由于这些 API 能通过不同类型的 HTTP 请求管理 RabbitMQ 的各种资源,所以在实际使用时,要考虑接口的安全性,比如限制 API 的访问权限、使用安全的认证方式等,防止未授权的访问和操作。
-
2 RabbitMQ的备份与恢复
-
RabbitMQ 有一个
data目录用于保存分配到该节点上的所有消息,在实验环境中,默认是在/var/lib/rabbitmq/mnesia目录下。这个目录里的备份分为元数据(定义结构的数据)和消息存储目录两部分; -
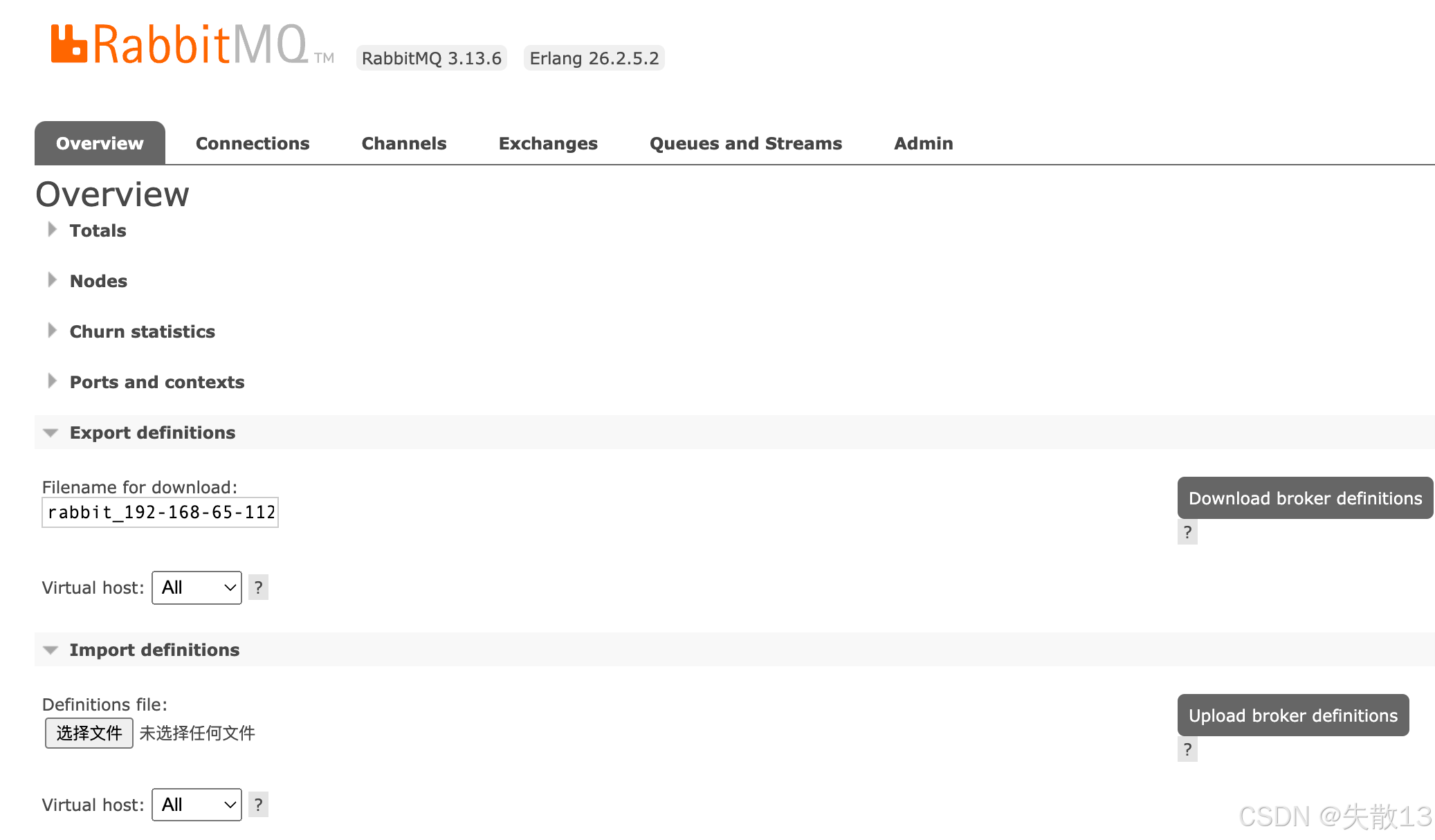
对于元数据,可以在 Web 管理页面通过 JSON 文件直接导出或导入:
-
导出:在管理页面的 Export definitions 部分,可设置文件名,选择虚拟主机(如选择 “All” 表示所有虚拟主机),然后点击 Download broker definitions 按钮,即可下载包含元数据的 JSON 文件;
-
导入:在 Import definitions 部分,选择要导入的定义文件(JSON 格式),选择虚拟主机,点击 Upload broker definitions 按钮,就能将元数据导入到 RabbitMQ 中;
-
-
对于消息,可手动进行备份恢复,但由于 MQ(消息队列)的特性,不建议频繁进行备份恢复操作,不过 RabbitMQ 进行数据备份恢复的流程比较简单:
-
首先,要保证要恢复的 RabbitMQ 中已经有了全部的元数据,这可以通过上述导出的 JSON 文件来恢复元数据实现;
-
然后,备份过程必须要先停止应用,如果是针对镜像集群,还需要把整个集群全部停止;
-
最后,在 RabbitMQ 的数据目录中,有按虚拟主机(virtual hosts)组织的文件夹。只需要按照虚拟主机,将整个文件夹复制到新的服务中即可,持久化消息和非持久化消息都会一起备份。
-
3 使用联邦插件(Federation 插件)进行远程消息同步
3.1 插件的作用
-
在企业的大型分布式业务场景中,希望服务能进行分布式部署。这样做有两方面好处:
-
提升数据安全性:分布式部署后,数据分散在不同节点或机房,降低了因单点故障等问题导致数据丢失或不可用的风险;
-
优化消息读取性能:消费者服务可连接本地的 RabbitMQ 服务,无需跨地域连接远程服务,减少了网络传输等带来的延迟,从而提升消息读取的效率;
-
-
搭建跨地域的内部子网来实现数据同步成本过高且不划算,而 RabbitMQ 的 Federation 插件能解决这个问题。通过 Federation 可以搭建一个单向的数据同步通道,实现不同机房 RabbitMQ 服务之间的消息同步,满足分布式场景下的消息同步需求。
3.2 使用步骤
3.2.1 启用插件
-
RabbitMQ 官方运行包已包含 Federation 插件,无需额外安装,只需启动即可使用;
# 确认联邦插件 rabbitmq-plugins list|grep federation [ ] rabbitmq_federation 3.13.6 [ ] rabbitmq_federation_management 3.13.6# 启用联邦插件 rabbitmq-plugins enable rabbitmq_federation # 启用联邦插件的管理平台支持,方便在管理控制台对联邦相关功能进行管理操作 rabbitmq-plugins enable rabbitmq_federation_management -
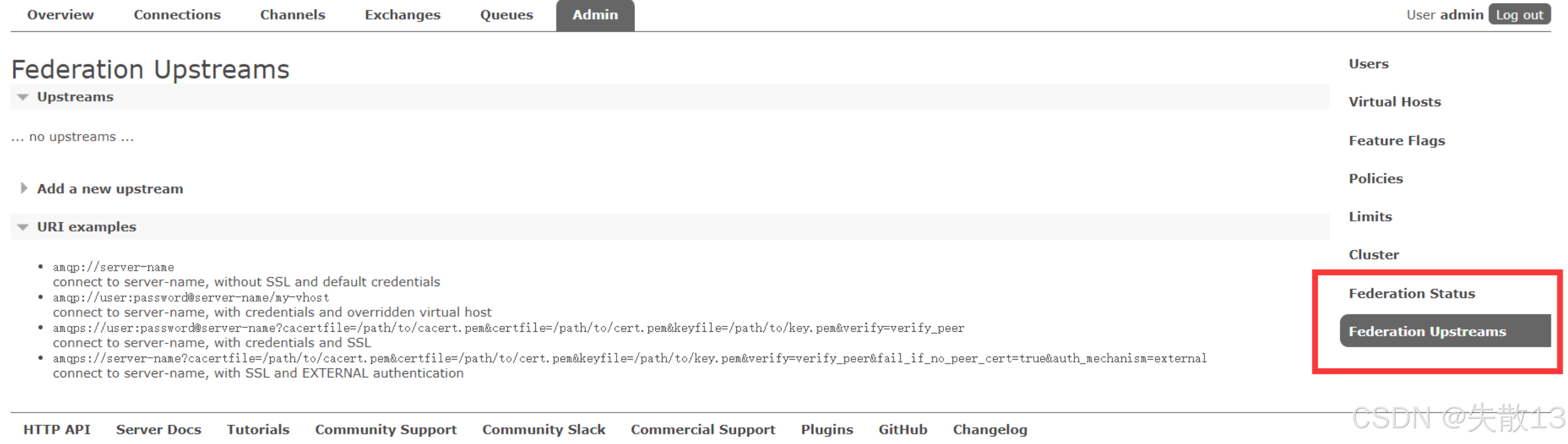
插件启用完成后,在管理控制台的
Admin(管理)菜单下,会新增两个选项:-
Federation Status:可查看联邦相关的状态信息,比如联邦连接、同步等的状态情况;
-
Federation Upstreams:用于配置联邦的上游(Upstreams)信息,上游可以理解为消息同步的源端等相关配置对象,同时还提供了添加新上游(Add a new upstream)的入口以及 URI 示例,方便进行联邦同步的源端配置等操作;
-
3.2.2 配置 Upstream(上游)
-
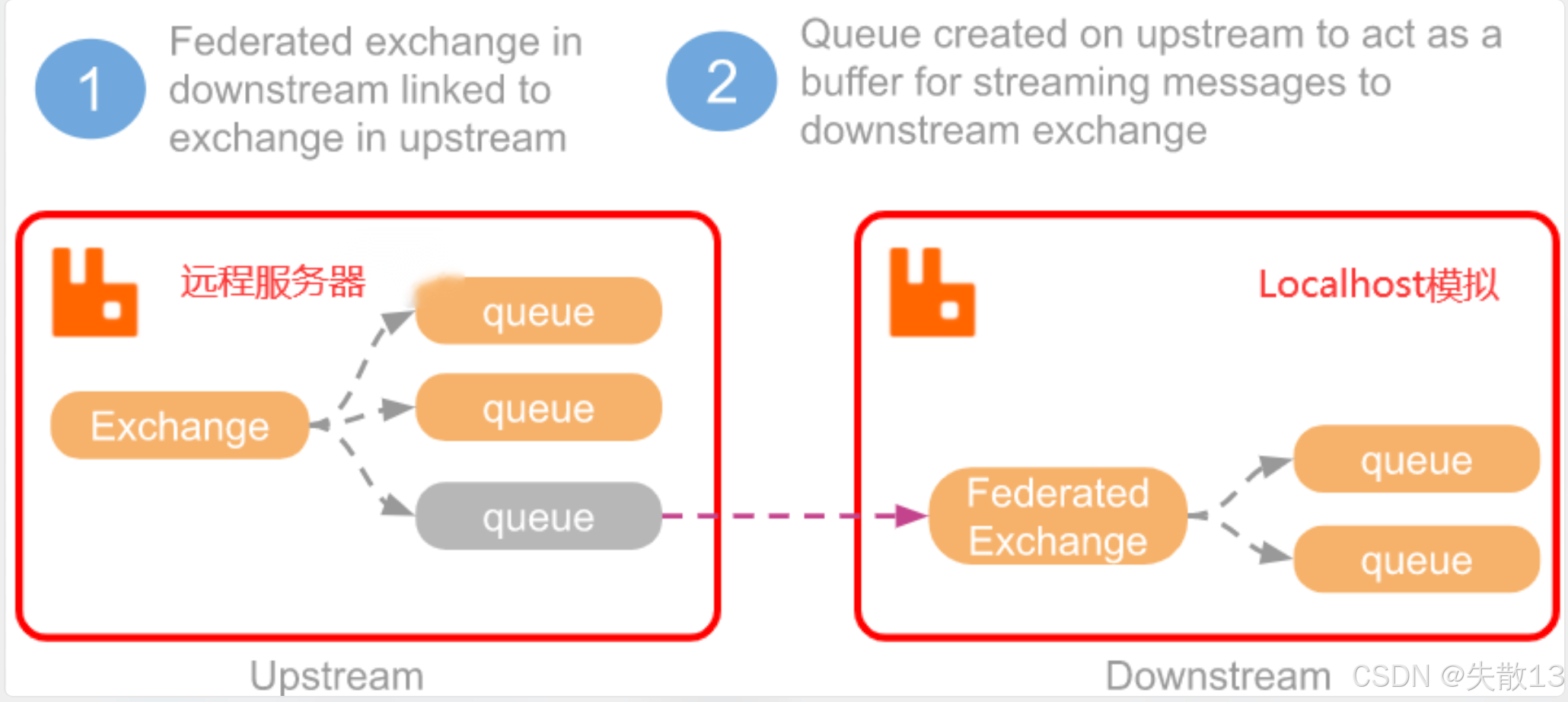
Upstream 表示上游的服务节点,在 RabbitMQ 里,它可以是一个交换机(Exchange),也可以是一个队列(Queue)。配置方式是由下游服务主动配置一个与上游服务的链接,之后数据就会从上游服务主动同步到下游服务中;
-
接下来用
192.168.65.112上的的 RabbitMQ 服务来模拟 DownStream 下游服务,去指向192.168.65.193服务器上搭建的 RabbitMQ 服务,搭建一个联邦交换机 Federation Exchange;-
联邦交换器(Federated exchange):下游(Downstream)的联邦交换器链接到上游(Upstream)的交换器,同时上游会创建队列作为缓冲,用于将消息流式传输到下游交换器;
-
首先在下游 RabbitMQ 中声明一个交换机和交换队列,用来接收远端(上游)的数据。这里直接用客户端 API 来快速进行声明:
- 通过客户端 API 声明交换器(
fed_exchange)和队列(fed_queue),并进行绑定; - 同时创建消费者来处理接收到的消息,以此来接收从上游同步过来的数据;
public class DownStreamConsumer {public static void main(String[] args) throws IOException, TimeoutException {ConnectionFactory factory = new ConnectionFactory();factory.setHost("192.168.65.112");factory.setPort(5672);factory.setUsername("admin");factory.setPassword("admin");factory.setVirtualHost("/mirror");Connection connection = factory.newConnection();Channel channel = connection.createChannel();channel.exchangeDeclare("fed_exchange","direct");channel.queueDeclare("fed_queue",true,false,false,null);channel.queueBind("fed_queue","fed_exchange","routKey");Consumer myconsumer = new DefaultConsumer(channel) {@Overridepublic void handleDelivery(String consumerTag, Envelope envelope,AMQP.BasicProperties properties, byte[] body)throws IOException {System.out.println("========================");String routingKey = envelope.getRoutingKey();System.out.println("routingKey >" + routingKey);String contentType = properties.getContentType();System.out.println("contentType >" + contentType);long deliveryTag = envelope.getDeliveryTag();System.out.println("deliveryTag >" + deliveryTag);System.out.println("content:" + new String(body, "UTF-8"));}};channel.basicConsume("fed_queue", true, myconsumer);} } - 通过客户端 API 声明交换器(
-
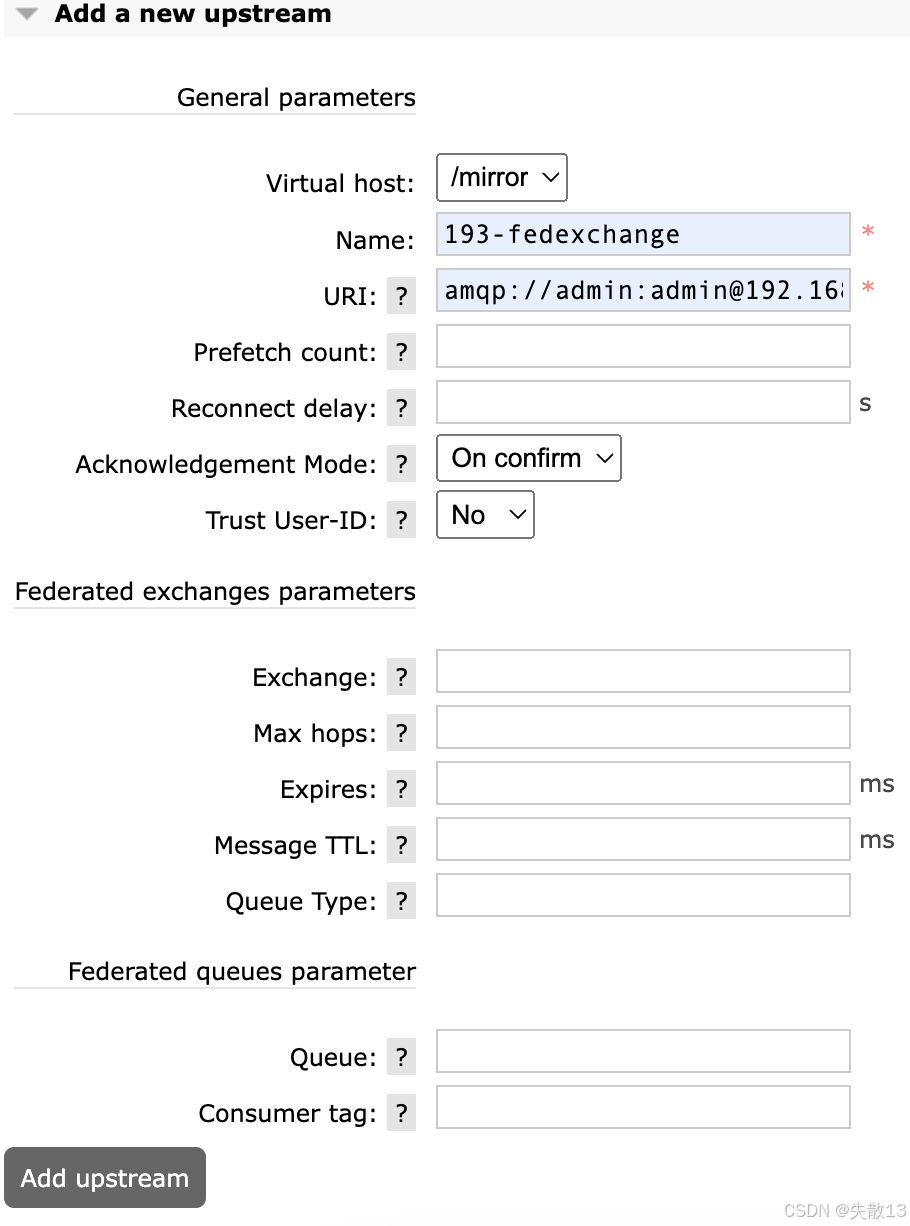
然后在下游 RabbitMQ 服务中配置一个上游服务:
General parameters(通用参数):
Virtual host:指定虚拟主机,如下图示例中的/mirrorName:上游服务的名称,下图示例中为193 - fedexchangeURI:上游服务的连接地址,包含认证信息等,如下图amqp://admin:admin@192.16...Prefetch count:预取消息的数量Reconnect delay:重连延迟时间(单位:秒)Acknowledgement Mode:确认模式,下图示例中为On confirmTrust User-ID:是否信任用户 ID,下图示例中为No
Federated exchanges parameters(联邦交换器参数):
Exchange:指定要联邦的交换器Max hops:最大跳数,即消息能经过的联邦交换器的最大次数Expires:联邦交换器的过期时间(单位:毫秒)Message TTL:消息的生存时间(单位:毫秒)Queue Type:队列类型
Federated queues parameter(联邦队列参数):
Queue:指定要联邦的队列Consumer tag:消费者标签

-
-
注意:
-
Federated exchanges parameters(联邦交换器参数,用于指定上游的交换器)和 Federated queues parameters(联邦队列参数,用于指定上游的队列)如果不指定上游的 Exchange 或 Queue:
- 就会使用上游中和下游(DownStream)中相同名称的 Exchange 和 Queue;
- 如果上游里没有与下游相同名称的 Exchange 或 Queue,就会在上游中新建对应的 Exchange 和 Queue;
-
关于虚拟主机的配置,如果在配置 Upstream 时指定了
Virtual Host属性,那么在 URI 中就不能再添加 Virtual Host 配置了,要避免重复配置导致问题。
-
3.2.3 配置 Federation 策略
-
需要配置一个指向上游服务的 Federation 策略,配置时可以选择针对 Exchange(交换机) 或者 Queue(队列) 来生效;
-
下表展示了一个简化的 Federation 策略配置:

-
Virtual Host:
/mirror,指定该策略作用的虚拟主机; -
Name:
193-fed-policy,策略的名称,用于标识该策略; -
Pattern:
^fed_*,匹配模式,这里表示匹配名称以fed_开头的 Exchange 或 Queue(具体由Apply to决定); -
Apply to:
exchanges,表示该策略应用于交换机(也可选择应用于队列); -
Definition:
federation-upstream-set: all,策略的定义部分federation-upstream-set参数表示以集合的方式针对多个 Upstream(上游服务节点)生效,all表示对全部 Upstream 生效;- 若使用
federation-upstream参数,则表示只对某一个 Upstream 生效;
-
Priority:
0,策略的优先级,数值越大优先级越高,当存在多个策略时,优先级高的策略会被优先应用;
-
-
注意:每个策略的
Definition部分,至少需要指定一个 Federation 目标,以此来确定策略作用的上游服务范围等关键信息。
3.2.4 测试
-
在配置完 Upstream(上游服务节点)和对应的 Federation 策略后,进入
Federation Status菜单,可查看 Federation 插件的执行情况。若状态为running,表示启动成功;若配置出错,会提示失败原因。下图中显示状态为running,说明配置成功;
-
在上游远程服务(IP 为 193 的 RabbitMQ 服务)中,能看到对应生成的 Federation 交换机。通过过滤(如过滤
fed相关),可找到名为fed_exchange的交换机,以及由 Federation 生成的关联交换机(如federation: fed_exchange -> rabbit@192-168-65-112);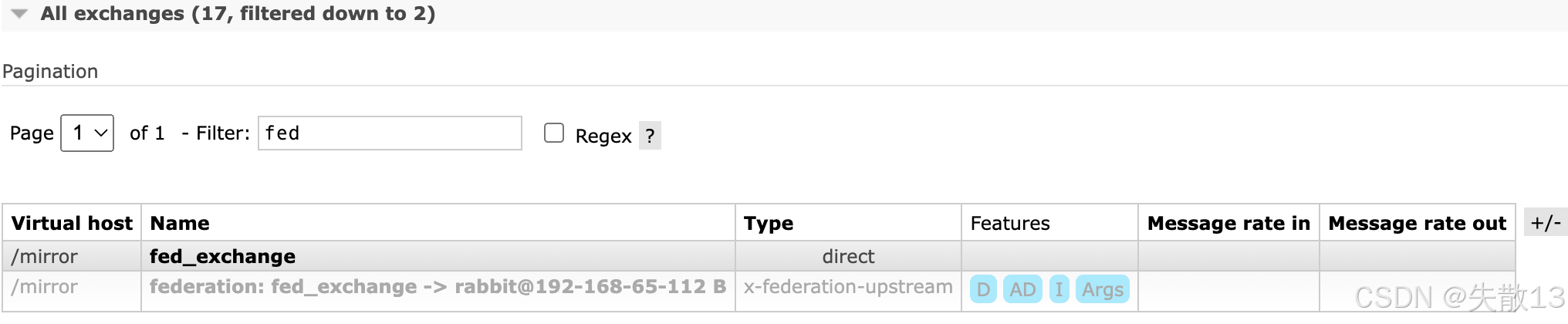
-
在
fed_exchange的详情页中,能看到绑定关系,且会给出一个默认的Routing key(示例中为routKey),同时还有相关参数(如x-bound-from等)说明绑定的来源等信息;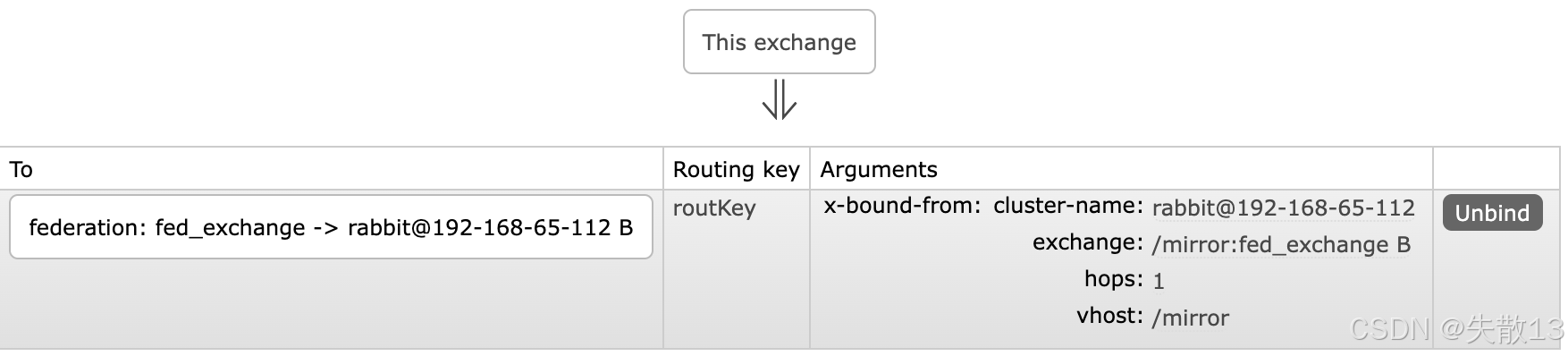
-
接下来可在上游服务(193)的
fed_exchange中发送消息,消息会同步到本地(Local)的联邦交换机,进而被对应的消费者消费。比如下图通过 RabbitMQ 管理控制台发送消息(消息内容为Federation Message),并成功被消费者接收到,验证了 Federation 功能实现了消息的同步与消费;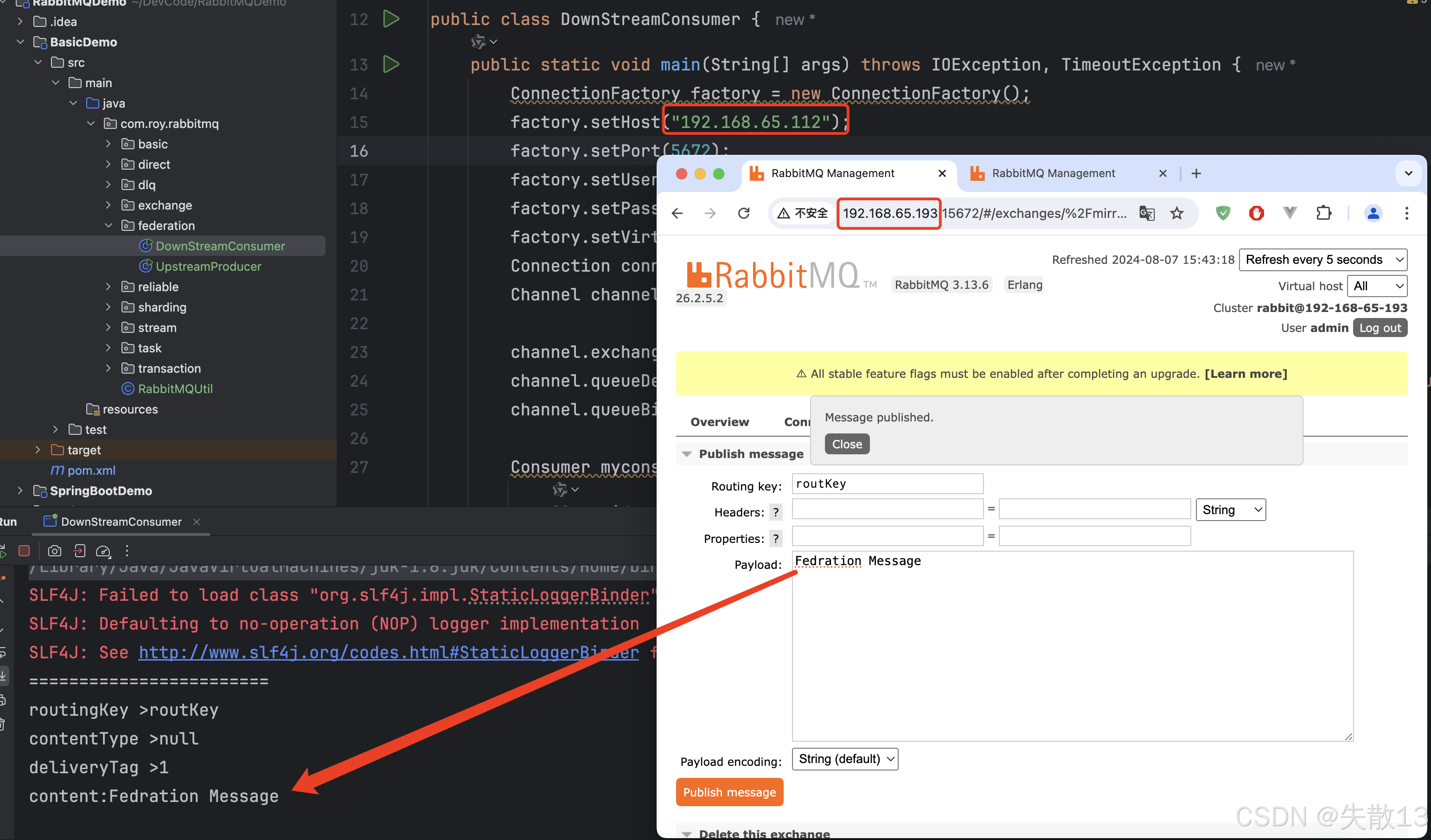
4 RabbitMQ服务的高可用机制
4.1 RabbitMQ的集群机制
-
在企业实际使用中,单机版 RabbitMQ 存在弊端。若单机服务崩溃,重启服务即可;但要是服务器磁盘出问题,存储在队列(Queue)里的消息会丢失,这在生产环境是无法接受的。所以 RabbitMQ 采用集群模式来保障消息安全,核心思路是:
-
为每个队列提供多个备份,一个服务的队列坏了,还能从其他队列获取数据;
-
而且,在 RabbitMQ 中,一个节点的服务也作为集群来处理,可在 Web 控制台的
admin -> cluster中查看和修改集群名称;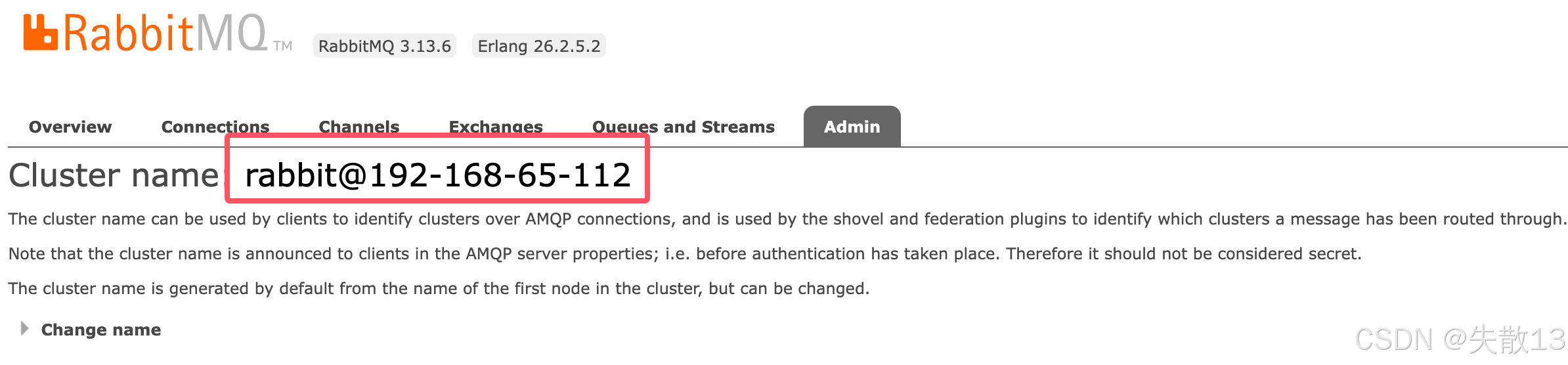
-
-
RabbitMQ 实现了两种集群模式:
-
默认的普通集群模式
-
利用 Erlang 语言天生具备的集群方式搭建;
-
这种集群模式下,集群各节点只有相同的元数据(队列结构),消息只存在于一个节点。消费时,若消费的不是存有数据的节点,RabbitMQ 会临时在节点间传输数据,将消息从存有数据的节点传输到消费的节点;
问题1:“若消费的不是存有数据的节点”,节点不存数据还能存什么?
答:一个不存储某条消息(或某个队列的全部消息体)的节点,存储的是以下内容:
- 元数据(Metadata):这是最关键的一点。所有节点都拥有完全相同的元数据,包括:
- 队列(Queue)的结构信息:例如队列的名字、属性(是否持久化、是否自动删除等);
- 交换机(Exchange)的结构信息:交换机名字、类型(direct, topic, fanout)、绑定关系(Bindings)等;
- 虚拟主机(vHost) 和用户权限等信息;
- 连接和信道(Connections & Channels):客户端可以连接到集群中的任何一个节点。这个节点负责维护与客户端的 TCP 连接和 AMQP 信道;
例:假设有一个三节点集群:
node1,node2,node3- 创建了一个队列
my_queue,并且该队列的主节点(所有者)是node1; - 此时,
node1,node2,node3的元数据中都知道存在一个叫my_queue的队列,并且知道它的主节点是node1; - 生产者发送一条消息到
my_queue,这条消息的实体只会被存储在node1上; node2和node3上没有这条消息的实体数据,但它们通过元数据知道这条消息存在于node1上;
问题2:“RabbitMQ 会临时在节点间传输数据,将消息从存有数据的节点传输到消费的节点。”是什么意思?
答:消费节点本身没有消息数据,但它会根据元数据信息,临时从拥有数据的节点那里把消息“取过来”,再交给消费者。这个过程对消费者是透明的,消费者感觉不到消息是在另一个节点上;
例:一个消费者(Consumer)连接到了
node3,并开始消费my_queue里的消息,过程如下- 消费请求:消费者向它连接的
node3发出一个Basic.Get或通过Basic.Consume订阅消息; - 查询元数据:
node3检查自己的元数据,发现队列my_queue的实际主人(Master)是node1,所有消息都物理存储在node1上; - 拉取消息:
node3会扮演一个“代理”或“中间人”的角色。它内部会建立一个到node1的临时通道,从node1上拉取(Fetch)一条(或一批)消息; - 传输与投递:消息从
node1通过网络传输到node3,然后node3再将这条消息投递给它所连接的消费者; - 确认与转发:当消费者处理完消息并发送确认(Ack)回执时,这个回执也是先发给
node3,然后由node3转发给node1。node1在收到确认后,才会将消息从磁盘或内存中移除;
- 元数据(Metadata):这是最关键的一点。所有节点都拥有完全相同的元数据,包括:
-
缺点:
- 消息可靠性低。若有节点服务宕机,该节点上的数据无法消费,需等节点恢复,期间消费者可能因已消费过消息却无法给服务端正确应答,导致节点重启后消息重复消费;若消息未持久化,重启后消息会丢失;
- 不支持高可用。节点服务挂了,需手动重启才能保证消息正常消费;
-
适用场景:仅适合对消息安全性要求不高的场景,且使用时消费者应尽量连接每一个节点,减少消息在集群中的传输;
-
-
镜像模式
-
是在普通集群模式基础上的增强方案,是 RabbitMQ 官方的高可用(HA)方案,需在普通集群搭建好后补充搭建;
-
核心原理:
- 会在镜像节点中主动进行消息同步,而非在客户端拉取消息时临时同步;
- 集群内部有算法选举产生 master 和 slave,master 挂了会自动选出新的,提升集群可用能力;
-
优点:消息可靠性更高,每个节点都存着全量的消息;
-
缺点:集群内部网络带宽会因同步通讯大量消耗,降低整个集群的性能,所以队列数量最好不要过多。
-
-
4.2 搭建普通集群
-
准备工作
-
服务器准备:准备三台服务器,分别命名为 worker1、worker2、worker3,在每台服务器上搭建 RabbitMQ 服务;
-
域名映射调整:在三台服务器上修改
/etc/hosts文件,添加 IP 与域名的映射,如下面指令。同时将每个节点的集群名调整为类似rabbit@[worker1]的形式;vi /etc/hosts 192.168.65.193 192-168-65-193 192.168.65.112 192-168-65-112 192.168.65.170 192-168-65-170
-
-
同步集群节点的 cookie。RabbitMQ 集群依赖
.erlang.cookie文件(默认在/var/lib/rabbitmq/目录下),该文件中的字符串需在集群所有节点上一致。接下来将 worker1 加入到 worker2 的 RabbitMQ 集群中,所以将 worker2 的.erlang.cookie文件分发到 worker1,同步时要注意文件权限:-
将文件所属用户调整为
rabbitmq,执行命令chown rabbitmq:rabbitmq .erlang.cookie; -
确保文件只有当前用户可读,执行
chmod 400 .erlang.cookie;
-
-
将节点加入集群。以将 worker2 加入 worker1 的集群为例:
-
先确保 worker1 上的 RabbitMQ 服务正常启动;
-
在 worker2 上执行
rabbitmqctl stop_app停止应用; -
执行
rabbitmqctl join_cluster --ram rabbit@worker2,以 ram 节点(后续会讲解 ram 节点特性)的方式将 worker2 加入 worker1 的集群; -
再执行
rabbitmqctl start_app启动应用;
RabbitMQ 集群节点分为 disk 节点 和 ram 节点:
- disk 节点:会将元数据(交换机、队列等的定义)保存到硬盘,数据安全性高,但与硬盘交互多,元数据操作性能相对低;
- ram 节点:仅在内存中保存元数据,减少了与硬盘的交互,元数据操作性能较好,但数据安全性依赖于其他节点(若集群中只有 ram 节点,元数据可能丢失,导致集群停止后无法启动);
- 补充说明:
- 本集群中 worker1 和 worker3 以 ram 节点身份加入 worker2 集群,存在单点故障风险(若 worker2 崩溃,元数据可能丢失),企业部署时需在性能和安全性间平衡;
- ram 节点的性能优势仅体现在元数据管理(如修改队列、交换机、虚拟主机等),与消息的生产和消费速度无关;
- 官方不建议全部使用 ram 节点,推荐集群中至少有一个 disk 节点,保证元数据安全;
-
-
集群状态查看:
-
可在 worker2 的 Web 管理界面查看集群节点情况;
-
也可通过命令行
rabbitmqctl cluster_status查看集群状态; -
实际项目中,通常建议搭建奇数台服务器的集群,因为这样的集群对官方推荐的 Quorum 队列更友好。
-
4.3 搭建镜像集群
-
注意:需先完成普通集群的搭建,在此基础上再搭建镜像集群;
-
在生产环境中,为减少 RabbitMQ 集群间的数据传输,配置镜像策略时会针对固定的虚拟主机(virtual host)进行配置;
-
虚拟主机的作用:RabbitMQ 中的虚拟主机类似 MySQL 中的库,可针对每个虚拟主机配置不同权限、策略等,且不同虚拟主机的数据相互隔离;
-
具体操作步骤:
-
先创建一个名为
/mirror的虚拟主机,执行命令rabbitmqctl add_vhost /mirror; -
再添加对应的镜像策略,执行
rabbitmqctl set_policy ha-all --vhost "/mirror" "^" '{"ha-mode":"all"}'。这些配置也可在 Web 控制台或通过 HTTP API 操作;参数:
pattern是队列的匹配规则,^表示全部匹配;ha-mode是关键参数,生产通常选all,表示队列镜像到集群中的所有节点,新节点加入集群时,队列也会镜像到该节点;另外还有:
exactly:需指定镜像节点数量,若集群节点数少于该数量,队列镜像到集群内所有节点;nodes:将队列镜像到指定节点,若指定队列不在集群中不会报错,声明队列时指定的镜像节点都不在则会创建在声明客户端节点上
-
-
-
镜像集群的特性与生产场景
-
消息同步特性:搭建好的镜像集群具备集群特性,在任何一个节点上发送消息,消息都会同时同步到各个节点中;
-
生产适用性:镜像模式的集群能满足大部分生产场景,虽然对系统资源消耗较高,但生产环境会预留资源,正常使用无问题。不过在做业务集成时,要注意队列数量不宜过多,且尽量避免 RabbitMQ 产生大量消息堆积;
-
-
基于镜像集群的扩展运维。在实际企业部署时,常以 RabbitMQ 镜像队列为基础,增加运维手段进一步提高集群安全性和实用性:(了解)
-
服务保活:用
keepalived保证每个 RabbitMQ 的稳定性,某个节点的 RabbitMQ 服务崩溃时可及时重启; -
节点扩展与简化使用:增加
HA-proxy做节点负载均衡,应用可像使用单点服务一样使用整个 RabbitMQ 集群。
-
4.4 Haproxy+Keepalived 高可用集群部署方案(了解)
-
Haproxy 反向代理的作用
- 有了 RabbitMQ 镜像集群后,客户端应用可访问集群中任意节点,但若访问的节点崩溃,虽集群消息不丢失、其他服务仍可用,可客户端需主动切换访问地址;
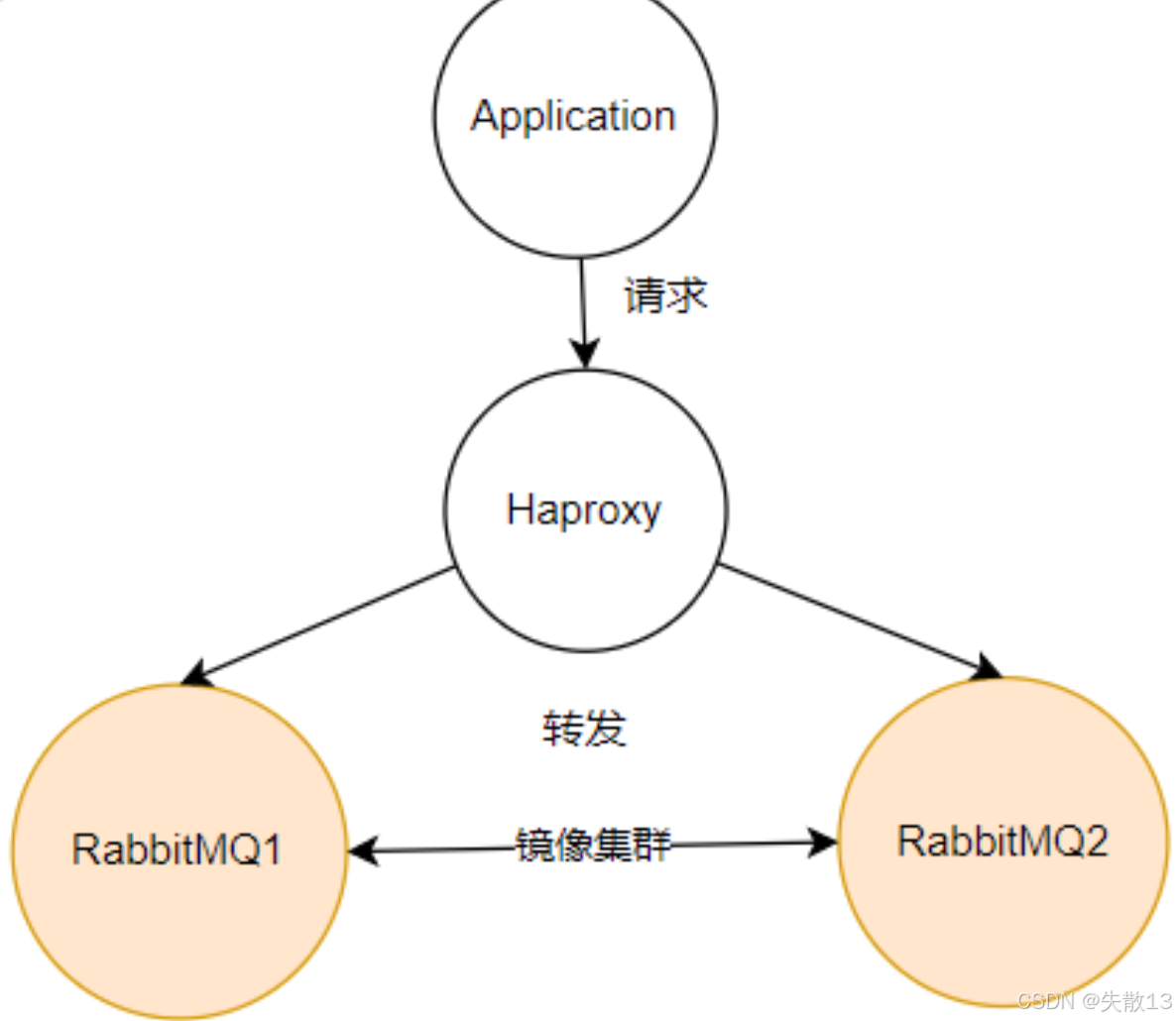
- 为避免这种情况,在 RabbitMQ 服务之前部署
Haproxy(一款免费开源的 TCP 负载均衡工具,类似工具还有 LVS、Nginx 等)。应用程序只需访问Haproxy的服务端口,Haproxy会以负载均衡的方式将请求转发到后端的 RabbitMQ 服务上。若某一 RabbitMQ 服务崩溃,Haproxy会将请求往另外一个 RabbitMQ 服务转发,应用程序无需做 IP 切换,保障了 RabbitMQ 服务的稳定性;
-
Keepalived 防止 Haproxy 单点崩溃
-
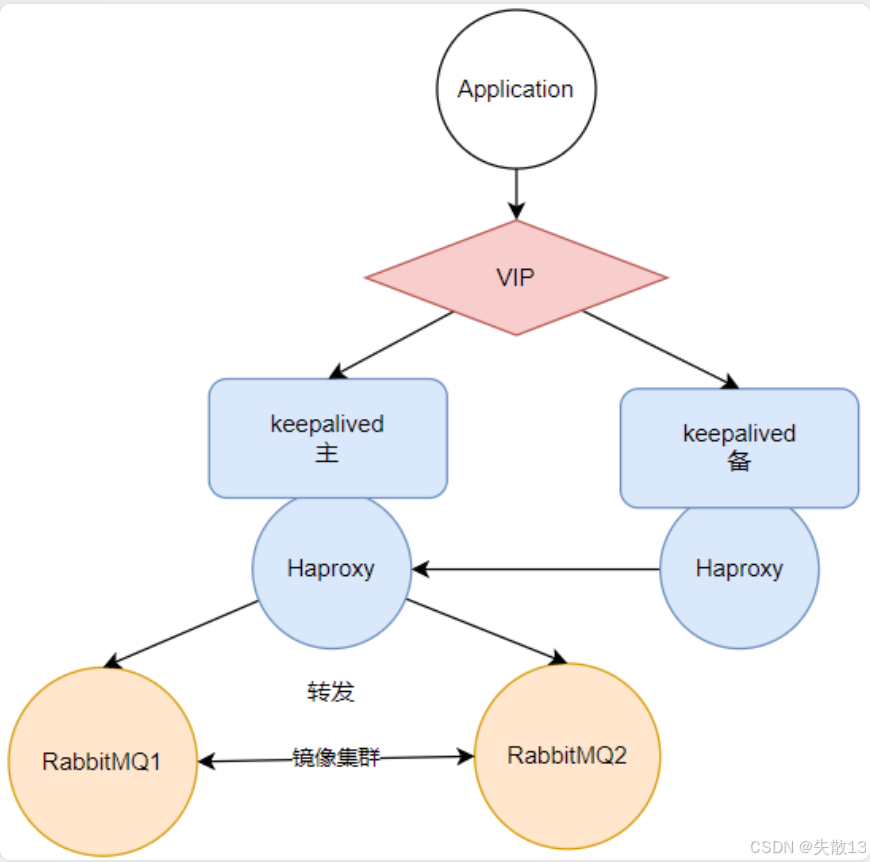
Haproxy虽保证了 RabbitMQ 服务的高可用,却带来了自身的单点崩溃问题(若Haproxy服务崩溃,整个应用程序就无法访问 RabbitMQ)。为解决此问题,引入Keepalived组件来保证Haproxy的高可用; -
Keepalived是搭建高可用服务的常见工具,会暴露一个虚拟 IP(VIP),并将 VIP 绑定到不同网卡上。引入后,先将 VIP 绑定到已有的Haproxy服务上,再引入一个从Haproxy作为备份。当主Haproxy服务出现异常后,Keepalived可将虚拟 IP 转为绑定到从Haproxy服务的网卡上(此过程为 VIP 漂移)。对于应用程序,自始至终只需访问Keepalived暴露出来的 VIP,感知不到 VIP 漂移的过程,从而保证了Haproxy服务的高可用性;
-
-
Haproxy + Keepalived的组合是分布式场景中经常用到的一种高可用方案,部署流程大致为下载 + 配置 + 运行即可,若有搭建兴趣,可参考RabbitMQ+HAProxy+Keepalived 搭建高可用RabbitMQ镜像模式集群。