kubeadm部署K8S单master架构实战
🌟Kubernetes集群架构
什么是Kubernetes
Kubernetes简称K8S,是一款用于编排容器的工具,支持单点,集群模式。
官网地址: https://kubernetes.io/
github地址: https://github.com/kubernetes/kubernetes
K8S架构
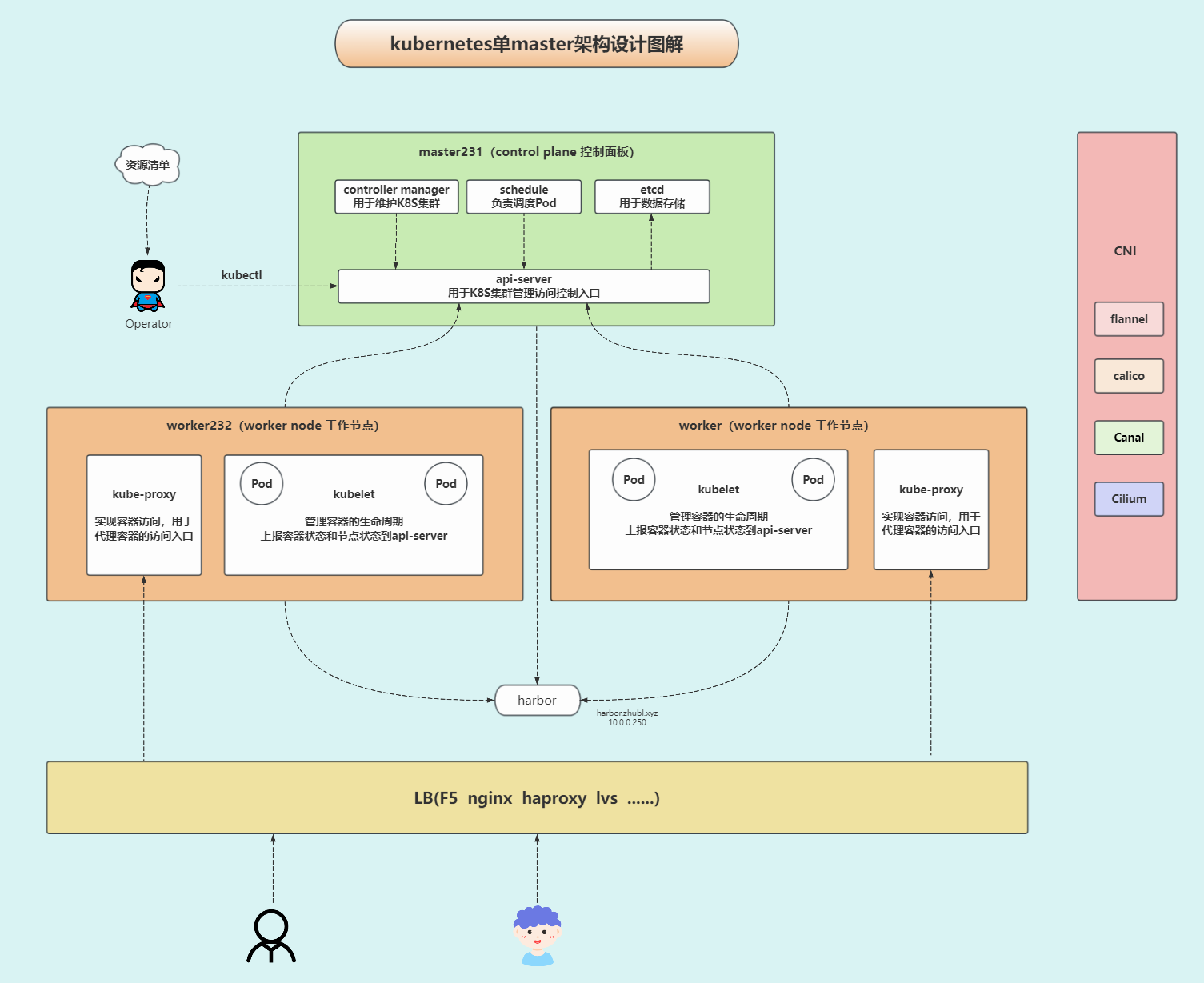
master —> control plane 控制面板
管理K8S集群。
- etcd: 默认使用https协议,用于数据存储。
- api-server: 默认使用https协议,用于K8S集群管理访问控制入口。
- controller manager: 用于维护K8S集群。
- schedule: 负责调度相关工作。
slave —> worker node 工作节点
负责干活的。
- kubelet: 管理容器的生命周期,并上报容器状态和节点状态到api-server。
- kube-proxy: 实现容器访问,用于代理容器的访问入口。
CNI:Container Network Interface
- Falnnel
- Calico
- cilium
- Canel
- …
Kubernetes的三种网络类型
- k8s组件网络:即物理机的IP地址网段。
- CNI: Pod(容器)网络:为容器提供网络。
- Service: 服务网络:为容器提供统一的访问入口,可以提供Pod的负载均衡和服务发现功能。
Kubernetes的部署方式
官方默认都有两种部署方式
- 二进制部署K8S集群
手动部署K8S各个组件,配置文件,启动脚本及证书生成,kubeconfig文件。
配置繁琐,对新手不友好,尤其是证书管理。但是可以自定义配置信息,老手部署的话2小时起步,新手20+小时
- kubeadm部署K8S集群
是官方提供的一种快速部署K8S各组件的部署方式,如果镜像准备就绪的情况下,基于容器的方式部署。
需要提前安装kubelet,docker或者containerd,kubeadm组件。
配置简单,适合新手。新手在镜像准备好的情况下,仅需要2分钟部署完毕。
第三方提供的部署方式
国内公司:
- 青云科技: kubesphere —》kubekey
底层基于kubeadm快速部署K8S,提供了丰富的图形化管理界面。
- kuboard
底层基于kubeadm快速部署K8S,提供了丰富的图形化管理界面。
- kubeasz
底层基于二进制方式部署,结合ansible的playbook实现的快速部署管理K8S集群。
国外的产品:
- rancher:
和国内的kubesphere很相似,也是K8S发行商,提供了丰富的图形化管理界面。还基于K8S研发出来了K3S,号称轻量级的K8S。
云厂商:
-
阿里云的ACK的SAAS产品
-
腾讯云的TKE的SAAS产品
-
华为云的CCE的SAAS产品
-
ucloud的UK8S的SAAS产品
-
亚马逊的Amazon EKS的SAAS产品
-
京东云,百度云的SAAS产品等。
其他部署方式:
- minikube:
适合在windows部署K8S,适合开发环境搭建的使用。不建议生产环境部署。
- kind:
可以部署多套K8S环境,轻量级的命令行管理工具。
- yum:
不推荐,版本支持较低,默认是1.5.2。
CNCF技术蓝图:https://landscape.cncf.io/
二进制部署和kubeadm部署的区别
相同点:
都可以部署K8S高可用集群。
不同点:
- 1.部署难度: kubeadm简单.
- 2.部署时间: kubeadm短时间。
- 3.证书管理: 二进制需要手动生成,而kubeadm自建三套10年的CA证书,各组件证书有效期为1年。
- 4.软件安装: kubeadm需要单独安装kubeadm,kubectl和kubelet组件,由kubelet组件启动K8S其他相关Pod,而二进制需要安装除了kubeadm的其他K8S组件。
Kubernetes的版本选择
首先,是K8S 1.23.17版本,该版本的第一个rc版本是2021年初,最后一个版本是23年年初结束。
值得注意的是,k8s 1.24版本移除了对于docker运行时的原生支持,如果需要使用docker运行时的话需要单独部署cri-docker组件。
建议生产环境如果高于1.24版本直接使用Containerd运行时,因为官方测试性能更高,为了追求更高的性能建议使用Containerd。
Containerd需要使用ctr工具来进行管理。
🌟k8s集群环境准备
环境准备
推荐阅读:
https://kubernetes.io/zh/docs/setup/production-environment/tools/kubeadm/install-kubeadm/
| ip | 主机名 | 配置 |
|---|---|---|
| 10.0.0.231 | master231 | 硬件配置: 2core 4GB 磁盘: 100GB+ [系统盘] 磁盘b: 300GB [Rook待用] 磁盘C: 500GB [Rook待用] 磁盘D: 1TB [Rook待用] |
| 10.0.0.232 | worker232 | 硬件配置: 2core 4GB 磁盘: 100GB+ [系统盘] 磁盘b: 300GB [Rook待用] 磁盘C: 500GB [Rook待用] 磁盘D: 1TB [Rook待用] |
| 10.0.0.233 | worker233 | 硬件配置: 2core 4GB 磁盘: 100GB+ [系统盘] 磁盘b: 300GB [Rook待用] 磁盘C: 500GB [Rook待用] 磁盘D: 1TB [Rook待用] |
关闭swap分区
swapoff -a && sysctl -w vm.swappiness=0
sed -ri '/^[^#]*swap/s@^@#@' /etc/fstab
确保各个节点MAC地址或product_uuid唯一
ifconfig eth0 | grep ether | awk '{print $2}'
cat /sys/class/dmi/id/product_uuid
温馨提示:
一般来讲,硬件设备会拥有唯一的地址,但是有些虚拟机的地址可能会重复。
Kubernetes使用这些值来唯一确定集群中的节点。 如果这些值在每个节点上不唯一,可能会导致安装失败。
检查网络节点是否互通
简而言之,就是检查你的k8s集群各节点是否互通,可以使用ping命令来测试。
允许iptable检查桥接流量
cat <<EOF | tee /etc/modules-load.d/k8s.conf
br_netfilter
EOFcat <<EOF | tee /etc/sysctl.d/k8s.conf
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
net.ipv4.ip_forward = 1
EOF
sysctl --system
检查端口是否被占用
参考链接: https://kubernetes.io/zh-cn/docs/reference/networking/ports-and-protocols/
检查master节点和worker节点的各组件端口是否被占用。
所有节点修改cgroup的管理进程为systemd
- 安装docker环境
- 检查cgroup驱动是否是systemd
[root@master231 ~]# docker info | grep "Cgroup Driver:"Cgroup Driver: systemd
[root@master231 ~]# [root@worker232 ~]# docker info | grep "Cgroup Driver:"Cgroup Driver: systemd
[root@worker232 ~]# [root@worker233 ~]# docker info | grep "Cgroup Driver:"Cgroup Driver: systemd
[root@worker233 ~]#
所有节点安装kubeadm,kubelet,kubectl
你需要在每台机器上安装以下的软件包:
kubeadm:用来初始化K8S集群的工具。
kubelet:在集群中的每个节点上用来启动Pod和容器等。
kubectl:用来与K8S集群通信的命令行工具。
kubeadm不能帮你安装或者管理kubelet或kubectl,所以你需要确保它们与通过kubeadm安装的控制平面(master)的版本相匹配。 如果不这样做,则存在发生版本偏差的风险,可能会导致一些预料之外的错误和问题。
然而,控制平面与kubelet间的相差一个次要版本不一致是支持的,但kubelet的版本不可以超过"API SERVER"的版本。 例如,1.7.0版本的kubelet可以完全兼容1.8.0版本的"API SERVER",反之则不可以。
apt-get -y install kubelet=1.23.17-00 kubeadm=1.23.17-00 kubectl=1.23.17-00

- 检查版本
[root@master231 opt]# kubeadm version
[root@master231 opt]# kubelet --version

参考链接: https://kubernetes.io/zh/docs/tasks/tools/install-kubectl-linux/
检查时区
ln -svf /usr/share/zoneinfo/Asia/Shanghai /etc/localtime

验证cpu核心数
lscpu | grep ^CPU\(s\)
🌟基于kubeadm组件初始化K8S的master组件
提前导入镜像(master节点)
docker load -i master-1.23.17.tar.gz

使用kubeadm初始化master节点(master节点)
[root@master231 opt]# kubeadm init --kubernetes-version=v1.23.17 --image-repository registry.aliyuncs.com/google_containers --pod-network-cidr=10.100.0.0/16 --service-cidr=10.200.0.0/16 --service-dns-domain=zhubl.xyz......
......
Your Kubernetes control-plane has initialized successfully!To start using your cluster, you need to run the following as a regular user:mkdir -p $HOME/.kubesudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/configsudo chown $(id -u):$(id -g) $HOME/.kube/configAlternatively, if you are the root user, you can run:export KUBECONFIG=/etc/kubernetes/admin.confYou should now deploy a pod network to the cluster.
Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at:https://kubernetes.io/docs/concepts/cluster-administration/addons/Then you can join any number of worker nodes by running the following on each as root:kubeadm join 10.0.0.231:6443 --token f0jgqi.luzlsi2sfxfdflgn \--discovery-token-ca-cert-hash sha256:021b73c92c38939417dc7d7e920ad2c3793ae8b39da7aa72ba4d4674f458b258
[root@master231 opt]#
相关参数说明:
–kubernetes-version: 指定K8S master组件的版本号。
–image-repository: 指定下载k8s master组件的镜像仓库地址。
–pod-network-cidr: 指定Pod的网段地址。
–service-cidr: 指定SVC的网段
–service-dns-domain: 指定service的域名。若不指定,默认为"cluster.local"。
使用kubeadm初始化集群时,可能会出现如下的输出信息:
[init]
使用初始化的K8S版本。
[preflight]
主要是做安装K8S集群的前置工作,比如下载镜像,这个时间取决于你的网速。
[certs]
生成证书文件,默认存储在"/etc/kubernetes/pki"目录哟。
[kubeconfig]
生成K8S集群的默认配置文件,默认存储在"/etc/kubernetes"目录哟。
[kubelet-start]
启动kubelet,
环境变量默认写入:“/var/lib/kubelet/kubeadm-flags.env”
配置文件默认写入:“/var/lib/kubelet/config.yaml”
[control-plane]
使用静态的目录,默认的资源清单存放在:“/etc/kubernetes/manifests”。
此过程会创建静态Pod,包括"kube-apiserver",“kube-controller-manager"和"kube-scheduler”
[etcd]
创建etcd的静态Pod,默认的资源清单存放在:“”/etc/kubernetes/manifests"
[wait-control-plane]
等待kubelet从资源清单目录"/etc/kubernetes/manifests"启动静态Pod。
[apiclient]
等待所有的master组件正常运行。
[upload-config]
创建名为"kubeadm-config"的ConfigMap在"kube-system"名称空间中。
[kubelet]
创建名为"kubelet-config-1.22"的ConfigMap在"kube-system"名称空间中,其中包含集群中kubelet的配置
[upload-certs]
跳过此节点,详情请参考”–upload-certs"
[mark-control-plane]
标记控制面板,包括打标签和污点,目的是为了标记master节点。
[bootstrap-token]
创建token口令,例如:“kbkgsa.fc97518diw8bdqid”。
如下图所示,这个口令将来在加入集群节点时很有用,而且对于RBAC控制也很有用处哟。
[kubelet-finalize]
更新kubelet的证书文件信息
[addons]
添加附加组件,例如:"CoreDNS"和"kube-proxy”
拷贝授权文件,用于管理K8S集群(master节点)
[root@master231 ~]# mkdir -p $HOME/.kube
[root@master231 ~]# sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
[root@master231 ~]# sudo chown $(id -u):$(id -g) $HOME/.kube/config
查看master组件是否正常工作(master节点)
[root@master231 ~]# kubectl get componentstatuses
[root@master231 ~]# kubectl get cs

查看工作节点(master节点)
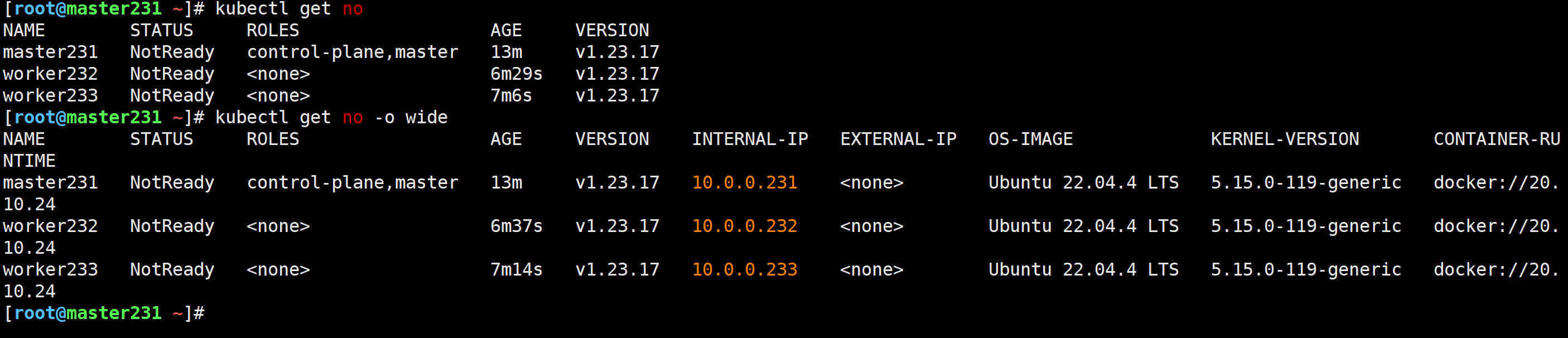
[root@master231 ~]# kubectl get nodes
[root@master231 ~]# kubectl get no
[root@master231 ~]# kubectl get no -o wide

master初始化不成功解决问题的方法
可能存在的原因:
- 由于没有禁用swap分区导致无法完成初始化;
- 每个2core以上的CPU导致无法完成初始化;
- 没有手动导入镜像;
解决方案:
- 1.检查上面的是否有上面的情况
free -h
lscpu
- 2.重置当前节点环境
[root@master231 ~]# kubeadm reset -f
- 3.再次尝试初始化master节点
🌟基于kubeadm部署worker组件
提前导入镜像
[root@worker232 opt]# docker load -i slave-1.23.17.tar.gz

[root@worker233 opt]# docker load -i slave-1.23.17.tar.gz

将worker节点加入到master集群
[root@worker232 ~]# kubeadm join 10.0.0.231:6443 --token ov7zso.0h0z24mn8y4e1t9c \--discovery-token-ca-cert-hash sha256:892e3c4ba20ef4fba726b79d12779252f94b0d2f4fc0f2c35383aee73ec3e7af[root@worker233 ~]# kubeadm join 10.0.0.231:6443 --token 4esc2h.oje3ndjv8nnass6v \--discovery-token-ca-cert-hash sha256:17410de1af03dc84422819dbe1a3d50ce587664da82d703d025f4d9093be15ac
验证worker节点是否加入成功
[root@master231 ~]# kubectl get no
[root@master231 ~]# kubectl get no -o wide
🌟部署CNI插件之Flannel
所有节点导入镜像(所有节点)
docker load -i flannel-v0.27.0.tar.gz

修改Pod网段(master节点)
[root@master231 opt]# sed -i '/16/s#244#100#' kube-flannel-v0.27.0.yml

部署服务组件
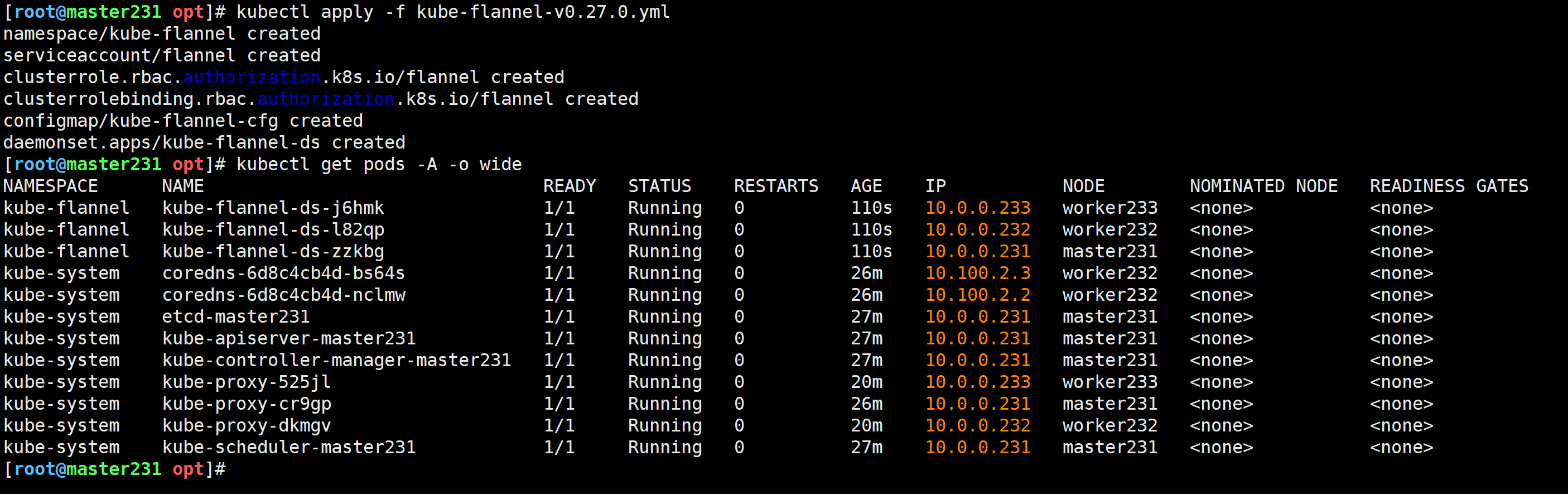
[root@master231 opt]# kubectl apply -f kube-flannel-v0.27.0.yml
[root@master231 opt]# kubectl get pods -A -o wide
检查节点是否就绪
[root@master231 opt]# kubectl get nodes
[root@master231 opt]# kubectl get nodes -o wide

🌟验证CNI网络插件是否正常
下载资源清单
network-cni-test.yaml
应用资源清单
[root@master231 opt]# cat network-cni-test.yaml
[root@master231 opt]# kubectl apply -f network-cni-test.yaml
pod/xiuxian-v1 created
pod/xiuxian-v2 created
[root@master231 opt]#
访问测试
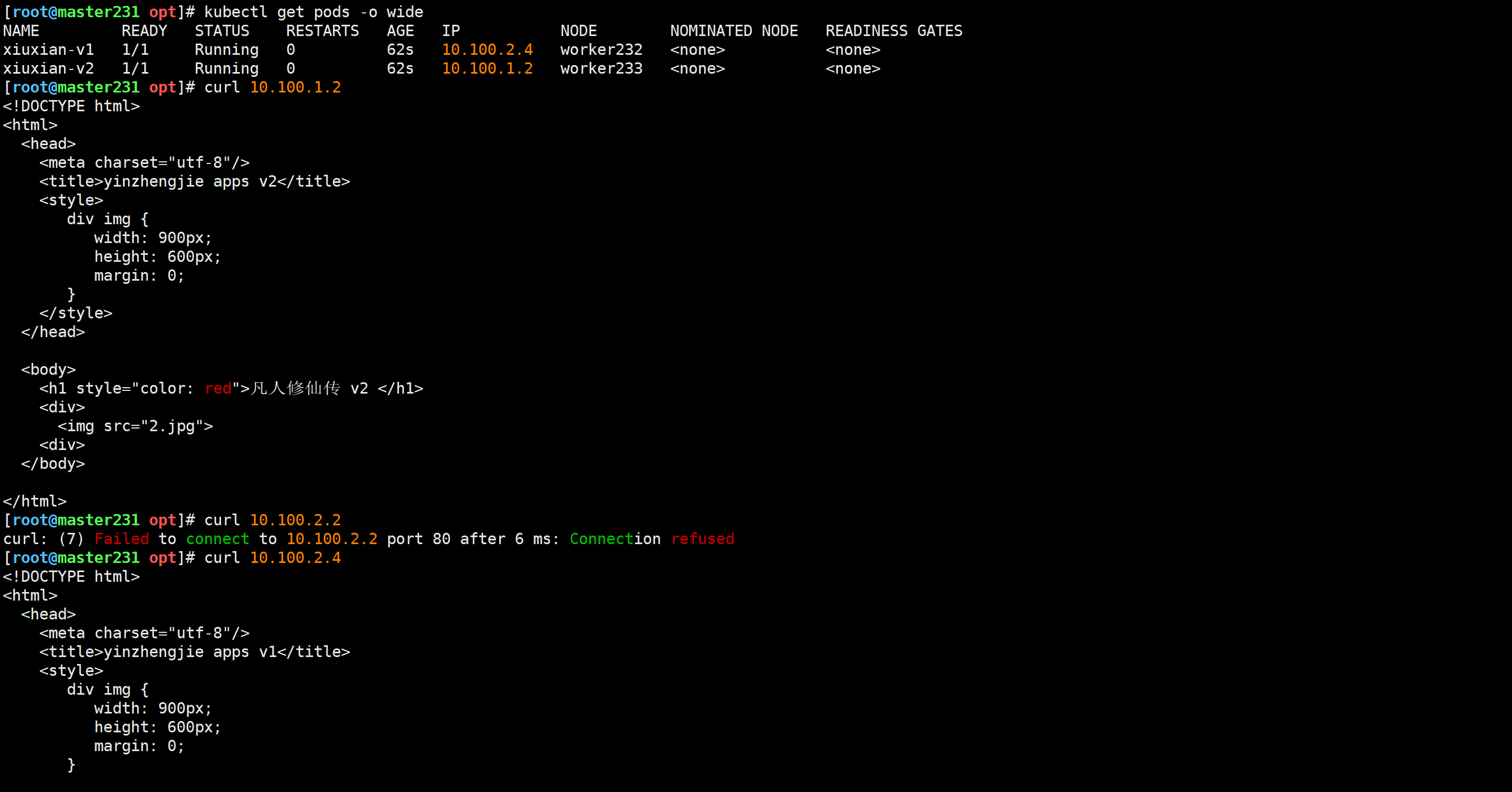
[root@master231 opt]# kubectl get pods -o wide
[root@master231 opt]# curl 10.100.1.2
[root@master231 opt]# curl 10.100.2.4
删除pod
[root@master231 opt]# kubectl delete -f network-cni-test.yaml
pod "xiuxian-v1" deleted
pod "xiuxian-v2" deleted
[root@master231 opt]# kubectl get pods -o wide
No resources found in default namespace.
[root@master231 opt]#
🌟kubectl工具实现自动补全功能
添加环境变量
[root@master231 opt]# kubectl completion bash > ~/.kube/completion.bash.inc
[root@master231 opt]# echo source '$HOME/.kube/completion.bash.inc' >> ~/.bashrc
[root@master231 opt]# source ~/.bashrc
验证自动补全功能
[root@master231 ~]# kubectl # 连续按2次tab键测试能否出现命令
