《RAG是什么?为什么它比微调更适合让AI拥有“专业知识”?》
本文禁止
AI学习委员和调参侠之外的任何生物阅读!开个玩笑,欢迎所有人!本文将用“开卷考”和“闭卷背书”的比喻,带你轻松理解两大技术,保你笑着进门,明白着出去。
一、引言:AI的“知识焦虑症”与我的“加班焦虑症”
大家好,我是那个试图让ChatGPT帮我写周报,结果它却把2021年的项目写得天花乱坠的倒霉蛋。
这不能全怪它。ChatGPT、文心一言这些通用大模型就像一位博学的“老学究”,但他有个致命缺点:他的知识库停在了某个截点。你问他“今天的天气怎么样?”他可能会根据去年的天气数据给你编一个,堪称AI界的“刻舟求剑”。
https://img-blog.csdnimg.cn/direct/bc9426f36d1e4f0c9f6b8e67c86cb5f5.png
(AI的内心独白:不是我不想帮你,是我的知识它过期了啊!)
那么,怎么让这位“老学究”瞬间变成你公司里的“百事通”、你代码库里的“活文档”呢?
目前有两个主流门派:
-
微调 (Fine-Tuning) - “闭关修炼,重塑筋骨”
-
检索增强生成 (RAG) - “随身携带图书馆”
今天,咱们就来扒一扒,为啥RAG这位“带书考生”,正把“闭门背书”的微调按在地上摩擦。
二、灵魂比喻:一场开卷考 vs 一场闭卷考
想象一下,你要让一个聪明的大学生(大模型)去参加一场“你公司内部知识”的考试。
-
微调 (Fine-Tuning) = 闭卷考试
-
操作:考试前,你把公司所有的规章制度、项目文档、代码规范全都塞给他,让他
闭关背诵。他需要把这些知识消化吸收,变成自己脑细胞的一部分。 -
优点:考试时(回答问题时),他
反应飞快,对答如流,因为知识都在脑子里了。 -
缺点:文档一更新,完了,他脑子里的知识
过期了!你得把他抓回来,再把新书重新塞一遍(重新训练),费时费力费钱(训练成本极高!)。而且,他偶尔还会自信地胡说八道(幻觉问题),因为他觉得自己“背过”。
-
-
RAG (Retrieval-Augmented Generation) = 开卷考试
-
操作:这个学生
不用背书。考试时,你允许他带一个万能图书馆(你的知识库)进场。遇到问题,他先飞速地去图书馆查资料(检索),找到最相关的几本书(文档片段),然后快速阅读、理解、组织语言,最后写出答案(生成)。 -
优点:知识库随时更新,他每次查到的都是
最新资料!答案准确度高,因为“言之有据”。成本极低,几乎就是电费(API调用费)。 -
缺点:答题速度
稍慢一点(多了检索步骤),而且万一图书馆里没这本书(知识库没相关内容),他也巧妇难为无米之炊。
-
看到这,你是不是已经感觉RAG真香了?别急,咱们用流程图看得更清楚!

三、RAG的“开卷”流程:一看就懂
下图完美诠释了RAG同学是如何“作弊”的:
A[用户提问<br>咱们公司年会有预算吗?] --> B[检索<br>冲向知识库“翻书”]B --> C[知识库<br>《2024年会指南》<br>《财务制度》...]C --> D[增强<br>把“翻到的答案”和问题放一起]D --> E[生成<br>大模型组织语言]E --> F[最终答案<br>根据《2024年会指南》第一章第五条...] 这就是RAG的核心魅力:答案来源于你的知识库,大模型只是一个“超级理解员”和“金牌播音员”,负责把查到的资料用人类语言组织起来。这意味着答案可追溯、可验证、可更新。
四、代码实战:5行代码感受RAG的魅力
理论说得再多,不如代码来得实在。下面我们用Python和LangChain框架,快速体验一下RAG的流程。
环境准备:
pip install langchain-openai chromadb langchain# 1. 导入工具包
from langchain_community.document_loaders import TextLoader # 文档加载器
from langchain_text_splitters import CharacterTextSplitter # 文本分割器
from langchain_openai import OpenAIEmbeddings # 嵌入模型,用于创建向量
from langchain_chroma import Chroma # 向量数据库
from langchain.prompts import ChatPromptTemplate # 提示词模板
from langchain_openai import ChatOpenAI # Chat模型# 2. 把我们自己的知识库(比如一个TXT文件)加载进来
loader = TextLoader("company_knowledge.txt", encoding="utf-8")
documents = loader.load()# 3. 把长文档切分成小块,方便检索
text_splitter = CharacterTextSplitter(chunk_size=500, chunk_overlap=50)
docs = text_splitter.split_documents(documents)# 4. 初始化嵌入模型和向量数据库(这就是我们的“图书馆”)
embeddings = OpenAIEmbeddings()
vectorstore = Chroma.from_documents(documents=docs, embedding=embeddings)# 5. 模拟用户提问
query = "咱们公司年会在什么时候?预算有多少钱?"# 6. 最关键的RAG步骤!
# 6.1 检索:从“图书馆”里找到最相关的文档片段
retriever = vectorstore.as_retriever()
relevant_docs = retriever.invoke(query)
print("检索到的相关文档片段:", relevant_docs[0].page_content[:100] + "...")# 6.2 增强:把问题和检索到的片段组合成一个更牛的提示词
template = """
请根据以下上下文信息回答问题。如果信息不相关,就说你不知道。
上下文:{context}
问题:{question}
"""
prompt = ChatPromptTemplate.from_template(template)
enhanced_prompt = prompt.invoke({"context": relevant_docs, "question": query})# 6.3 生成:把增强后的提示词扔给大模型,让它生成最终答案
model = ChatOpenAI()
response = model.invoke(enhanced_prompt)
print("n最终答案:", response.content)代码解读:
-
准备图书馆:我们把
company_knowledge.txt(公司知识)加载进来,切块,然后转换成向量存入Chroma数据库(建图书馆并给图书编索引)。 -
用户提问:用户问“年会时间和预算”。
-
检索:程序将问题也转换成向量,去数据库里
找到最相似的文本片段(比如《2024年会安排通知》)。 -
增强:把
原始问题和找到的片段打包成一个新的、信息更全面的提示词:“请根据《2024年会安排通知》这篇文章,回答‘年会时间和预算’的问题。” -
生成:把这个
超级提示词发给ChatGPT。ChatGPT一看,哦豁,答案都给我准备好了,我只需要做个总结、转述一下就行。
看,这就是RAG!我们没有动大模型一根手指头(没有微调),只是巧妙地给它递了小纸条,它就给出了精准且最新的答案。
五、总结:一张图帮你做选择
最后,送上一张决策图,当你需要给AI注入知识时,再也不纠结了:
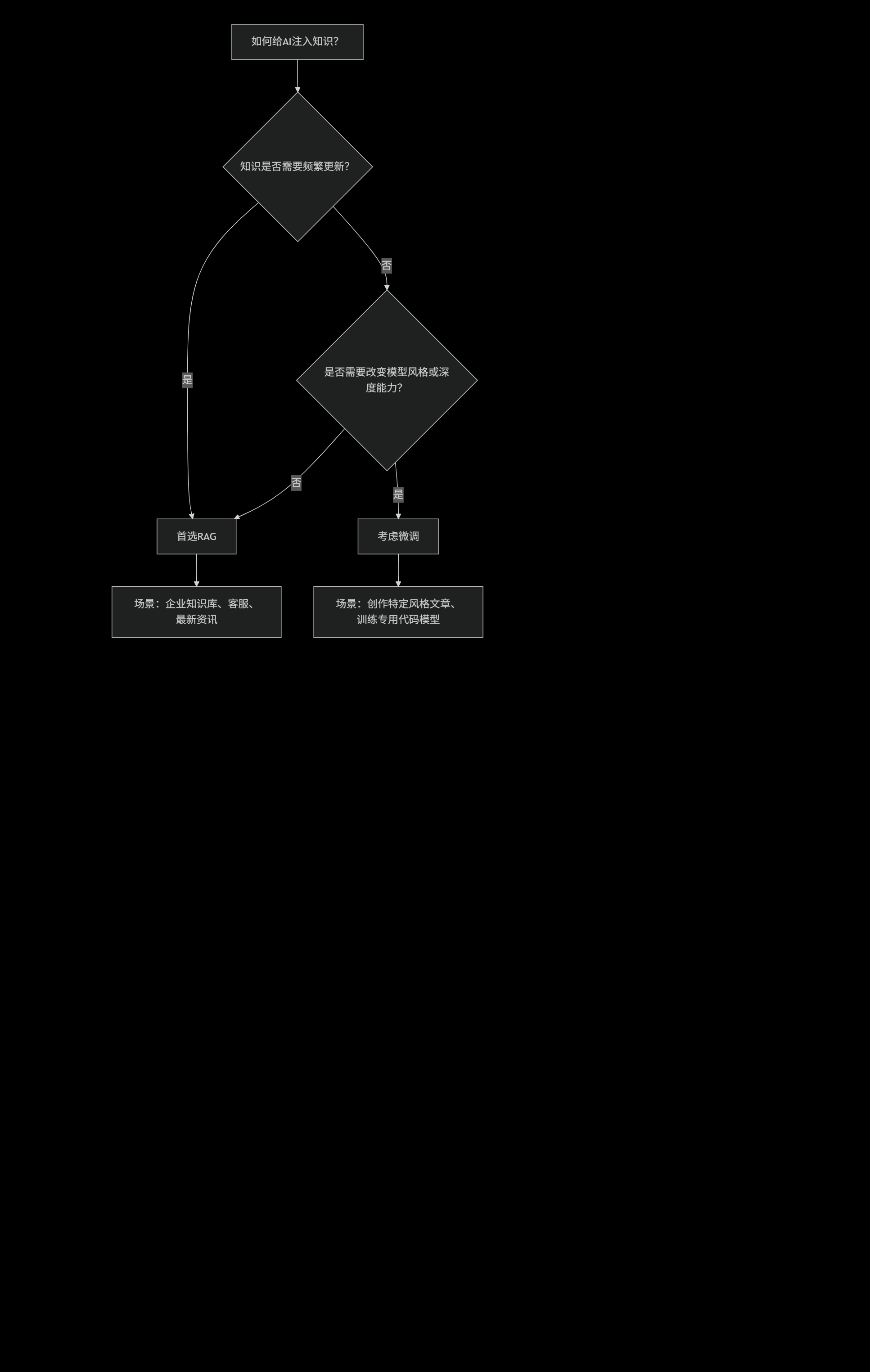
所以,如果你想让AI成为你公司的“活手册”、“百事通”,RAG无疑是更高效、更经济、更可靠的选择。它就像给一位博学的老先生配了一个无所不知的万能秘书,强强联合,天下无敌!
而微调,则更像是培养一个领域专家,需要投入大量资源“回炉重造”,适合那些风格固化、需求稳定的深度场景。