AI数据库研究:RAG 架构运行算力需求?
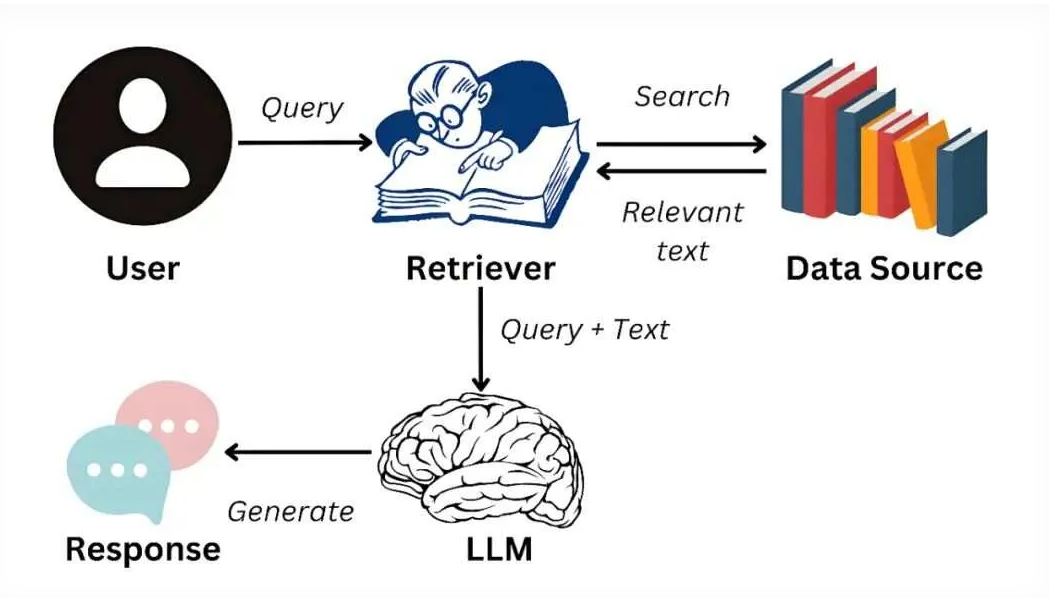
RAG 架构运行算力需求与架构复杂度、知识库规模、检索 / 生成并行量正相关,从 “低成本 CPU 可用” 到 “高成本 GPU 集群” 不等,优先按架构模式匹配算力,再根据业务量弹性扩容。

一、各架构模式算力需求明细(从低到高)
1. 基础流水线模式(最低算力)
- 核心消耗组件:检索器(向量 / 关键词)+ 生成器(轻量大模型)
- 算力要求:
- 中小知识库(<10 万文档):单机 CPU(16 核 32G)即可,向量检索用 FAISS CPU 版,生成器调用 GPT-3.5-turbo / 通义千问 1.8B 等轻量模型 API(无需本地 GPU)。
- 略大规模(10-50 万文档):单机 GPU(1 张 T4/3090,16G 显存),向量检索用 GPU 加速,生成器可部署开源 7B 模型(如 Llama-2-7B 量化版)。
- 适用场景:内部办公问答、小体量 FAQ,并行请求 < 100 QPS。
2. 增强检索模式(中等算力)
- 核心消耗组件:混合检索(向量 + 关键词)+ 重排器(Cross-BERT 等)+ 生成器
- 算力要求:
- 大规模知识库(50-100 万文档):单机多 GPU(2 张 T4/3090)或单张 A10(24G 显存),重排器(如 CoSENT、Cross-BERT)需 GPU 推理,混合检索需 Elasticsearch 集群(3 节点,8 核 16G / 节点)。
- 超大规模(>100 万文档):GPU 集群(4 张 A10/A30),向量检索用 Milvus/Zilliz Cloud(GPU 版),重排器批量推理提速。
- 适用场景:ToC 客服、电商商品问答,并行请求 100-500 QPS。
3. 多阶段迭代模式(中高算力)
- 核心消耗组件:查询拆解器(大模型)+ 多轮检索器 + 结果整合生成器
- 算力要求:
- 复杂推理场景(多跳 / 长文本):单张 A100(40G 显存)或 2 张 A30(24G 显存),查询拆解需部署 13B/34B 开源模型(如 Qwen-13B-Chat 量化版),多轮检索需缓存中间结果降低重复计算。
- 高并发场景:GPU 集群(4-8 张 A100),搭配 Redis 缓存检索结果,生成器做负载均衡。
- 适用场景:专业咨询(法律 / 医疗)、科研文献问答,并行请求 50-300 QPS(因多轮计算,并发低于增强检索)。
4. 闭环反馈模式(高算力)
- 核心消耗组件:基础架构(增强 / 多阶段)+ 反馈分析器 + 模型调优模块
- 算力要求:
- 反馈处理:单机 GPU(1 张 A10),用于分析用户反馈(如语义相似度计算、评分建模)。
- 模型调优:至少 1 张 A100(80G 显存),用于微调嵌入模型 / 重排器(如用 LoRA 微调 BERT/MPNet),数据量越大,显存需求越高。
- 适用场景:长期运营的 ToC 产品、付费咨询系统,需持续迭代效果。
二、算力优化实用技巧(降本不降效)
- 检索层优化:文档 Chunk 按语义合并(减少检索次数),用量化向量(如 FP16→INT8)降低显存占用,热门查询结果缓存(Redis)。
- 生成层优化:用模型量化(GPTQ/AWQ)部署开源模型,短上下文优先(截断非关键文本),批量处理低并发请求。
- 云资源选型:低并发用 “CPU + 云向量数据库(如阿里云向量检索服务)”,高并发用 “GPU 云服务器 + 弹性伸缩”,避免闲置算力。
三、快速算力匹配表
初步实施可使用线上云服务器:如“智算云扉https://waas.aigate.cc/user/charge?channel=W6P9Y2F8H&coupon=3ROAWRGJRH等租赁平台,已经按照应用需求优化好使用环境,支持各类镜像服务,按量计费。
| 架构模式 | 最小算力配置 | 推荐算力配置(高并发) | 月度成本参考(云资源) |
|---|---|---|---|
| 基础流水线 | 16 核 32G CPU | 1 张 T4 GPU + 32G 内存 | 1000-3000 元 |
| 增强检索 | 1 张 T4 GPU + ES 集群 | 2 张 A10 GPU + ES 集群 | 5000-15000 元 |
| 多阶段迭代 | 1 张 A10 GPU | 4 张 A100 GPU | 20000-50000 元 |
| 闭环反馈 | 1 张 A10 GPU + 1 张 A100 | 4 张 A10 + 2 张 A100 | 30000-80000 元 |