伪装图像生成之——GAN与Diffusion
伪装图像生成之——GAN与Diffusion
一、引言
图像生成是人工智能领域的核心研究方向之一,其目标是让模型学会“创造”逼真的图像,而不仅仅是识别或分类。 近年来,生成模型广泛应用于艺术创作、虚拟场景、医学影像合成、图像修复、图像风格迁移,以及特殊任务如 伪装图像生成(Camouflage Image Generation)。
在众多生成方法中,生成对抗网络(Generative Adversarial Network, GAN) 和 扩散模型(Diffusion Model) 是最具代表性的两大技术路线。前者以对抗博弈为核心,强调“真假难辨”;后者以概率建模为核心,通过“逐步去噪”实现高质量图像合成。
本文将系统梳理 GAN 与 Diffusion 的基本原理、训练机制、优缺点及其在伪装图像生成中的潜在应用。
二、生成对抗网络(GAN)
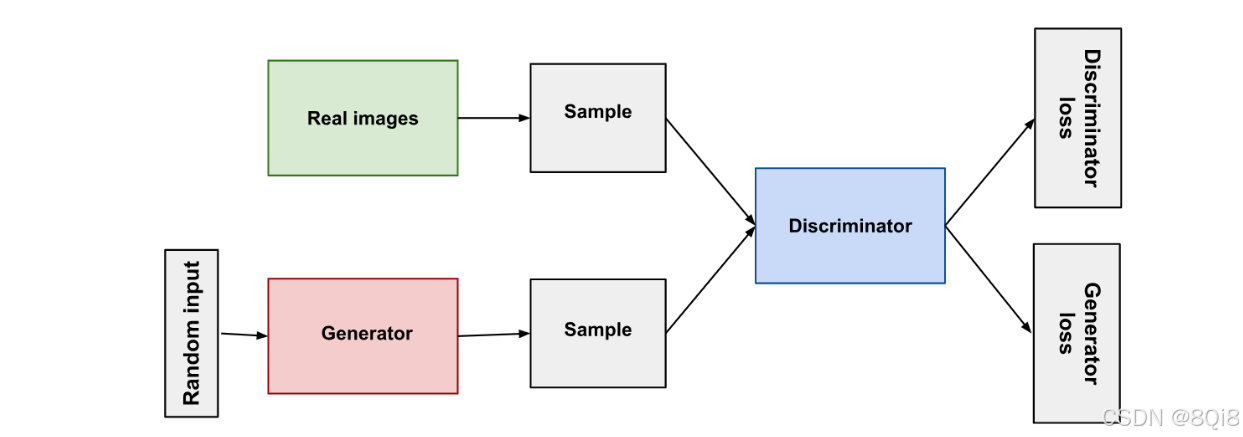
1. 基本思想
GAN 由 Ian Goodfellow 于 2014 年提出,灵感来源于“造假者与警察的博弈”:
- 生成器(Generator, G):试图根据随机噪声 z 生成尽可能逼真的图像 G(z);
- 判别器(Discriminator, D):试图区分输入样本是真实的 x∼pdata(x),还是生成的 G(z)。
二者在训练中进行零和博弈,生成器不断提升造假能力,判别器不断增强识别能力,最终达到“真假难分”的平衡状态。
2. 数学原理
GAN 的核心优化目标为:
minGmaxDV(D,G)=Ex∼pdata(x)[logD(x)]+Ez∼pz(z)[log(1−D(G(z)))]
\min_G \max_D V(D, G) = \mathbb{E}_{x\sim p_{data}(x)}[\log D(x)] + \mathbb{E}_{z\sim p_z(z)}[\log(1 - D(G(z)))]
GminDmaxV(D,G)=Ex∼pdata(x)[logD(x)]+Ez∼pz(z)[log(1−D(G(z)))]
- 判别器希望最大化上式,即正确识别真实样本;
- 生成器希望最小化上式,使判别器误判其生成样本为真。
当训练达到纳什均衡(Nash Equilibrium)时,生成器生成的数据分布 pg 将逼近真实数据分布 pdata。
3. 网络结构与训练流程
典型的 GAN 结构包括两个神经网络:
- 生成器 G:通常采用反卷积或上采样结构,将低维噪声映射为高维图像;
- 判别器 D:采用卷积神经网络(CNN)结构,将输入图像映射为真假概率。
训练步骤:
- 使用真实样本训练判别器,使其输出“真”;
- 使用生成样本训练判别器,使其输出“假”;
- 更新生成器,使判别器更难分辨;
- 重复迭代,直至两者达到平衡。
4. 典型变体
- DCGAN(Deep Convolutional GAN):引入卷积结构,提高图像质量;
- CGAN(Conditional GAN):加入条件信息(如类别或文本),实现可控生成;
- CycleGAN:可实现无配对样本的图像风格迁移;
- StyleGAN:通过多尺度特征调控,生成极为逼真的人脸与艺术图像。
5. 优缺点分析
| 优点 | 缺点 |
|---|---|
| 生成样本逼真、细节丰富 | 训练不稳定,需平衡 G 与 D |
| 模型直观,易于扩展 | 存在“模式崩塌”(Mode Collapse)问题 |
| 适合无监督学习与迁移任务 | 难以量化生成质量 |
6. 在伪装图像生成中的应用
在伪装图像生成任务中,GAN 可用于:
- 生成不同环境下的伪装物体(如森林、沙地、海洋伪装);
- 模拟伪装物体与背景的融合;
- 利用条件 GAN,根据输入背景自动生成适配的伪装图像。
例如:
使用背景图像作为条件输入 c,GAN 学习生成 G(z∣c) 形式的伪装目标,实现背景一致性与伪装效果的联合优化。
三、扩散模型(Diffusion Model)
1. 基本思想
扩散模型最早来源于物理中的扩散过程(Diffusion Process),由 DDPM(Denoising Diffusion Probabilistic Model)在 2020 年重新定义。
其核心思想是:
先逐步将图像“加噪声”,再训练模型“去噪”,反向生成图像。
具体过程包括两个阶段:
- 前向扩散(Forward Diffusion):逐步向真实图像中添加噪声,使其最终变为纯随机噪声;
- 反向生成(Reverse Diffusion):学习一个神经网络,逐步去除噪声,还原出清晰图像。

2. 数学原理
前向过程定义为:
q(xt∣xt−1)=N(1−βt xt−1,βtI)
q(x_t | x_{t-1}) = \mathcal{N}(\sqrt{1-\beta_t}\,x_{t-1}, \beta_t I)
q(xt∣xt−1)=N(1−βtxt−1,βtI)
经过 T 步后得到噪声图像
xT≈N(0,I)
x_T \approx \mathcal{N}(0, I)
xT≈N(0,I)
反向过程由神经网络 pθ(xt−1∣xt) 近似:
pθ(xt−1∣xt)=N(μθ(xt,t),Σθ(xt,t))
p_\theta(x_{t-1}|x_t) = \mathcal{N}(\mu_\theta(x_t, t), \Sigma_\theta(x_t, t))
pθ(xt−1∣xt)=N(μθ(xt,t),Σθ(xt,t))
训练目标通常是最小化噪声预测误差:
Lsimple=Ex0,ϵ,t∥ϵ−ϵθ(xt,t)∥2
L_{simple} = \mathbb{E}_{x_0, \epsilon, t}\|\epsilon - \epsilon_\theta(x_t, t)\|^2
Lsimple=Ex0,ϵ,t∥ϵ−ϵθ(xt,t)∥2
其中 ϵθ(xt,t) 是网络预测的噪声。
3. 采样与生成
生成时,从纯噪声 xT∼N(0,I) 开始,逐步执行反向去噪,最终得到 x0即生成图像。现代模型(如 Stable Diffusion)通过在 潜在空间(Latent Space) 进行扩散,大幅提升效率。
4. 常见模型
- DDPM:基础去噪扩散概率模型;
- DDIM:改进采样速度,可在少量步骤下生成高质量图像;
- Latent Diffusion Model (LDM):如 Stable Diffusion,使用 VAE 将图像编码为潜在表示后再进行扩散;
- ControlNet / InstructPix2Pix:通过加入结构或文字引导,实现可控生成。
5. 优缺点分析
| 优点 | 缺点 |
|---|---|
| 生成质量高,细节真实 | 采样速度慢,需要多步推理 |
| 训练相对稳定 | 计算量大,资源需求高 |
| 可实现条件控制与多模态融合 | 参数多,设计复杂 |
6. 在伪装图像生成中的应用
Diffusion 模型可以自然地适应“背景融合”的伪装生成任务:
- 在训练阶段,通过“加噪—去噪”过程学习背景纹理与目标边界的细微变化;
- 在生成阶段,可以以“背景+文本条件”控制伪装目标的生成;
- 使用 Latent Diffusion,可高效地生成不同场景的伪装物体;
- 若结合 CLIP 等语义模型,还可实现“语义伪装生成”(如:“生成在沙漠中与背景颜色融合的动物”)。
四、GAN 与 Diffusion 对比总结
| 项目 | GAN | Diffusion |
|---|---|---|
| 核心思想 | 对抗博弈(造假与辨别) | 概率建模(加噪与去噪) |
| 训练稳定性 | 易崩塌、不稳定 | 稳定但耗时 |
| 生成速度 | 快(单步前向) | 慢(多步采样) |
| 生成质量 | 高,但细节略差 | 极高、自然逼真 |
| 可控性 | 依赖条件结构 | 支持多模态控制(文本、图像等) |
| 应用于伪装图像 | 快速生成伪装样本 | 高保真伪装融合与细节控制 |
在伪装图像生成研究中,可以根据任务需求选择不同方法:
- 若需要快速生成大量训练样本,可选 条件 GAN;
- 若注重细节真实性、背景融合性,可选 扩散模型(如 LDM 或 Stable Diffusion);
- 若想兼顾两者,可探索 Diffusion-GAN 混合架构。
五、未来研究方向
- 多模态伪装生成:结合文本、图像、深度图信息;
- 可控伪装生成:通过条件引导(环境、纹理、光照)控制生成结果;
- Diffusion + GAN 混合模型:用 GAN 加速 Diffusion 采样过程;
- 评估体系构建:研究伪装质量评价指标(可检测性、背景融合度、视觉一致性等);
多模态伪装生成:结合文本、图像、深度图信息; - 可控伪装生成:通过条件引导(环境、纹理、光照)控制生成结果;
- Diffusion + GAN 混合模型:用 GAN 加速 Diffusion 采样过程;
- 评估体系构建:研究伪装质量评价指标(可检测性、背景融合度、视觉一致性等);
- 轻量化模型:减少扩散模型生成步骤,实现实时伪装图像生成。