CV论文速递:覆盖视频理解与生成、跨模态与定位、医学与生物视觉、图像数据集等方向(11.03-11.07)
本周精选12篇CV领域前沿论文,覆盖视频理解与生成、跨模态与定位、医学与生物视觉、图像数据集与模型优化等方向。全部200多篇论文感兴趣的自取!

原文 资料 这里!
一、视频理解与生成方向
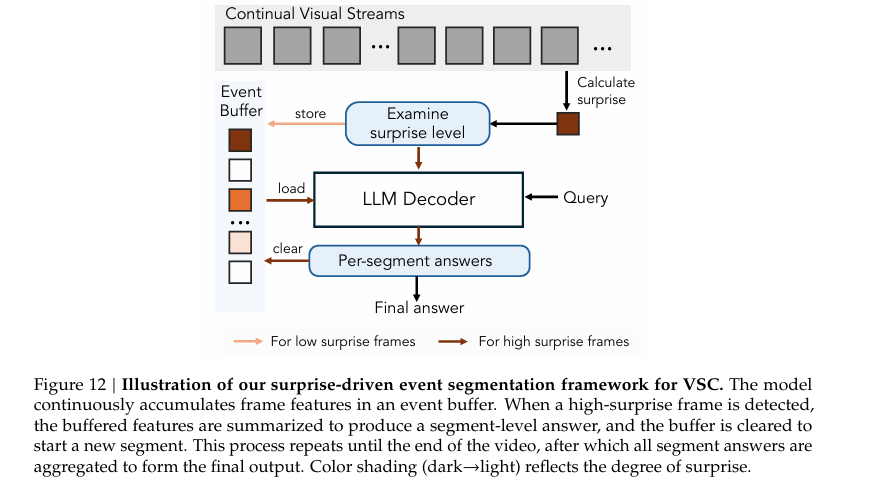
1、Cambrian-S: Towards Spatial Supersensing in Video
作者:Shusheng Yang, Jihan Yang, Pinzhi Huang, Ellis Brown, Zihao Yang, Yue Yu, Shengbang Tong, Zihan Zheng, Yifan Xu, Muhan Wang, Daohan Lu, Rob Fergus, Yann LeCun, Li Fei-Fei, Saining Xie
亮点:提出空间超感知范式,划分语义感知、流式事件认知等四个阶段突破纯语言理解局限。构建VSI-SUPER双部分基准与VSI-590K数据集,训练的Cambrian-S在VSI-Bench上实现30%绝对性能提升。创新性提出预测性感知方案,通过自监督下一潜在帧预测器利用预测误差实现记忆与事件分割,大幅优于主流专有基线模型。
论文:https://arxiv.org/abs/2511.04670
开源代码:https://github.com/cambrian-mllm/cambrian-s
Comments:Website: https://cambrian-mllm.github.io/
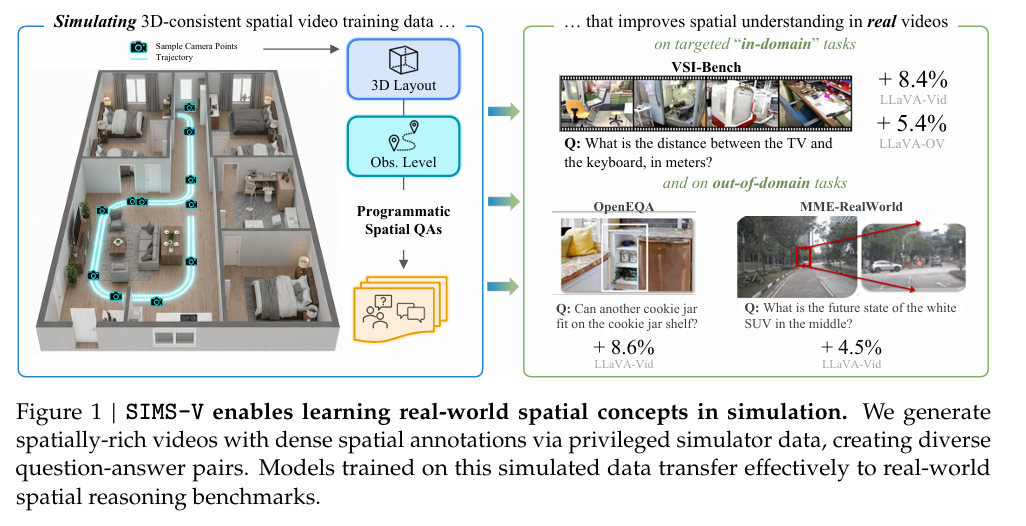
2、SIMS-V: Simulated Instruction-Tuning for Spatial Video Understanding
作者:Ellis Brown, Arijit Ray, Ranjay Krishna, Ross Girshick, Rob Fergus, Saining Xie
亮点:提出SIMS-V模拟数据生成框架,借助3D模拟器生成富含空间信息的视频训练数据,解决真实数据标注瓶颈。通过系统性消融实验锁定三类关键问题类别,仅用25K模拟样本微调的7B参数视频LLM,性能超越更大参数量的72B基线模型,在真实世界空间推理基准中与专有模型竞争力相当,同时兼顾通用视频理解能力。
论文:https://arxiv.org/abs/2511.04668
开源代码:https://ellisbrown.github.io/sims-v
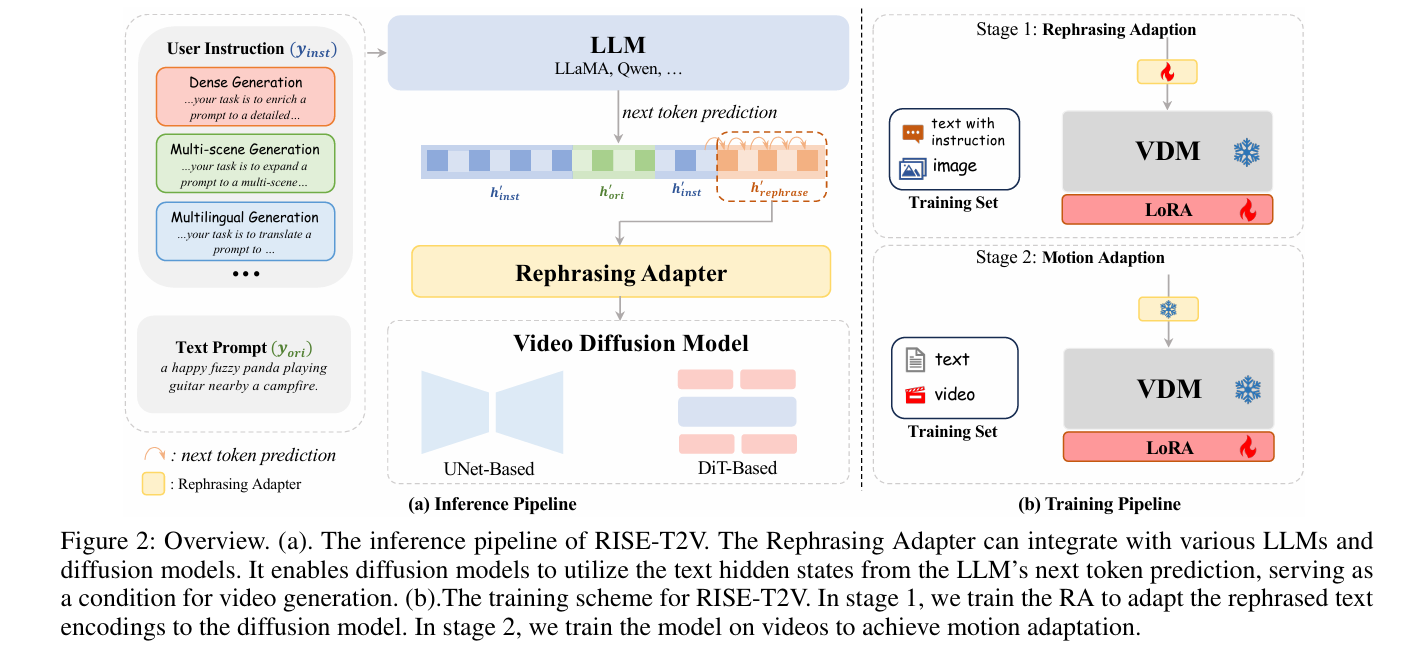
3、RISE-T2V: Rephrasing and Injecting Semantics with LLM for Expansive Text-to-Video Generation
作者:Xiangjun Zhang, Litong Gong, Yinglin Zheng, Yansong Liu, Wentao Jiang, Mingyi Xu, Biao Wang, Tiezheng Ge, Ming Zeng
亮点:解决T2V模型对简洁提示语义理解不足的问题,创新整合提示改写与语义特征提取流程。设计改写适配器模块,使扩散模型能利用LLM下一词预测的文本隐藏状态生成视频,实现基础提示向贴合用户意图的全面表达转化。该框架通用性强,可适配多种LLM与视频扩散模型,显著提升生成视频质量与语义对齐度。
论文:https://arxiv.org/abs/2511.04317
开源代码:https://rise-t2v.github.io/
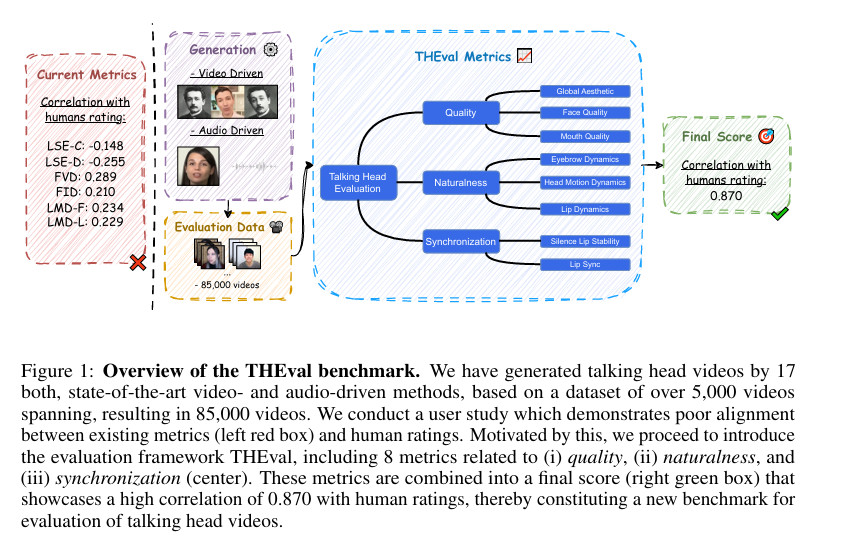
4、THEval. Evaluation Framework for Talking Head Video Generation
作者:Nabyl Quignon, Baptiste Chopin, Yaohui Wang, Antitza Dantcheva
亮点:针对说话人头部视频生成评估指标不足的问题,提出涵盖质量、自然度、同步性三大维度的8项评估指标,聚焦头部、嘴部等细节动态与面部质量分析。基于新构建的真实数据集,对17种SOTA模型生成的85000个视频开展实验,发现多数模型唇同步表现优异,但在表情生成和无伪影细节呈现上存在短板,相关代码、数据集与排行榜将公开发布并定期更新。
论文:https://arxiv.org/abs/2511.04520
二、跨模态与定位方向
1、DINOv2 Driven Gait Representation Learning for Video-Based Visible-Infrared Person Re-identification
作者:Yujie Yang, Shuang Li, Jun Ye, Neng Dong, Fan Li, Huafeng Li
亮点:针对VVI-ReID任务忽略步态特征的缺陷,提出DinoGRL框架,借助DINOv2的视觉先验学习与外观特征互补的步态特征。设计SASGL模型,利用DINOv2语义先验生成并增强剪影表示;研发PBMGE模块,通过步态与外观流的多粒度双向交互,强化全局特征的局部细节,在HITSZ-VCM和BUPT数据集上显著超越现有SOTA方法。
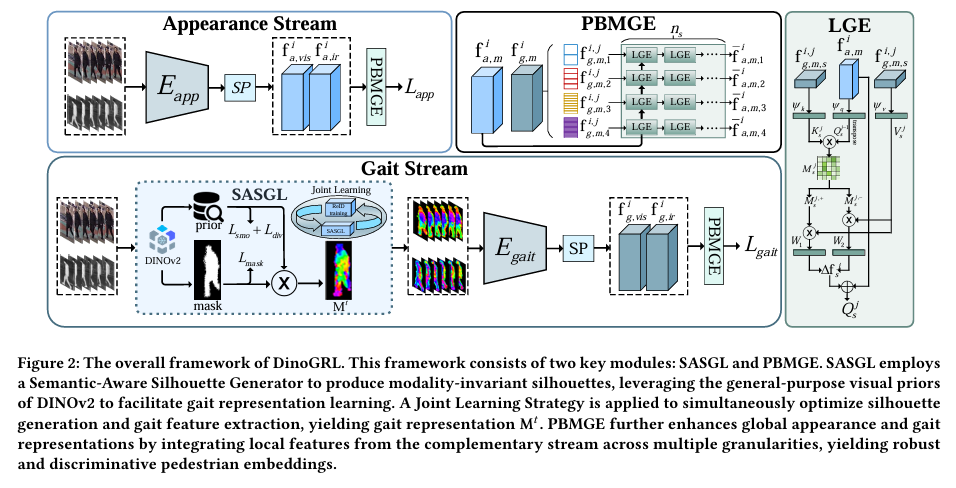
论文:https://arxiv.org/abs/2511.04281
Comments:ACMMM2025
2、Object Detection as an Optional Basis: A Graph Matching Network for Cross-View UAV Localization
作者:Tao Liu, Kan Ren, Qian Chen
亮点:解决GNSS拒止区域无人机定位难题,提出以目标检测为基础的跨视角匹配框架。摒弃传统图像检索思路,通过目标检测提取无人机与卫星图像中的显著目标,结合图神经网络推理图像间与图像内节点关系。基于细粒度图节点相似度指标,该方法能有效应对异质外观差异,在红外-可见光等大模态差距场景中泛化性强,数据集将公开。
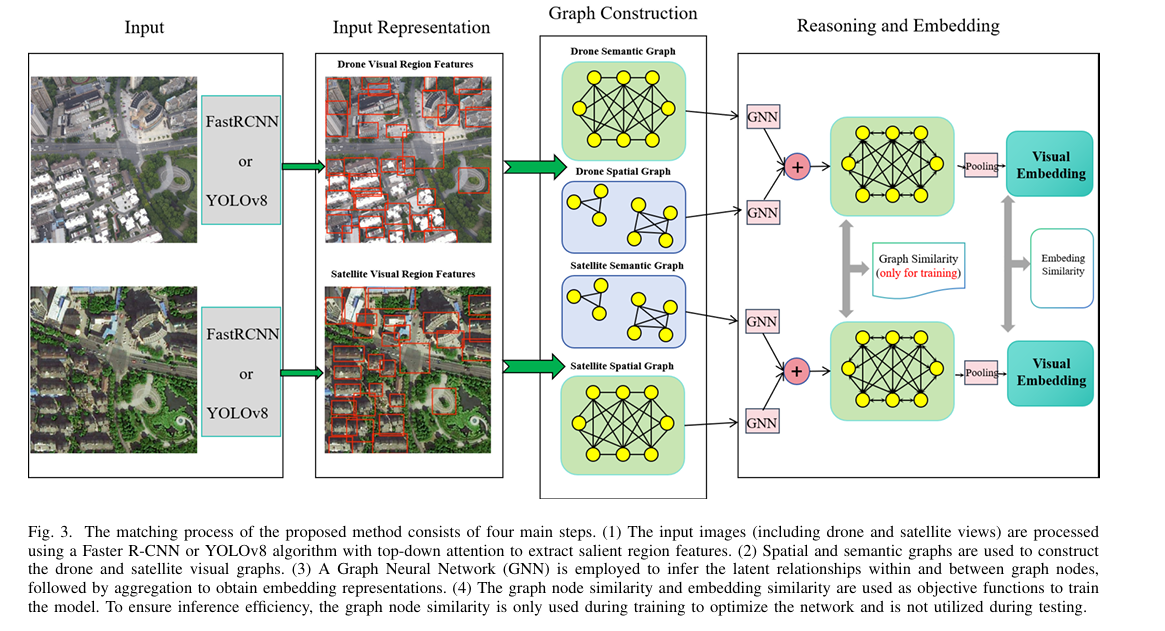
论文:https://arxiv.org/abs/2511.02489
开源代码:https://github.com/liutao23/ODGNNLoc.git
Comments:20 pages, Submitted to IEEE TIM
3、RIS-Assisted 3D Spherical Splatting for Object Composition Visualization using Detection Transformers
作者:Anastasios T. Sotiropoulos, Stavros Tsimpoukis, Dimitrios Tyrovolas, Sotiris Ioannidis, Panagiotis D. Diamantoulakis, George K. Karagiannidis, Christos K. Liaskos
亮点:结合可重构智能表面与射频传感技术,解决传统光学重建在遮挡和低光照下的性能退化问题。提出可编程无线环境驱动的射频框架,通过RIS实现场合成,搭配检测Transformer从射频特征中直接推断空间和材料参数。该框架基于材料感知球形基元完成3D重建,模拟实验中物体几何逼近与材料分类总体准确率达79.35%。
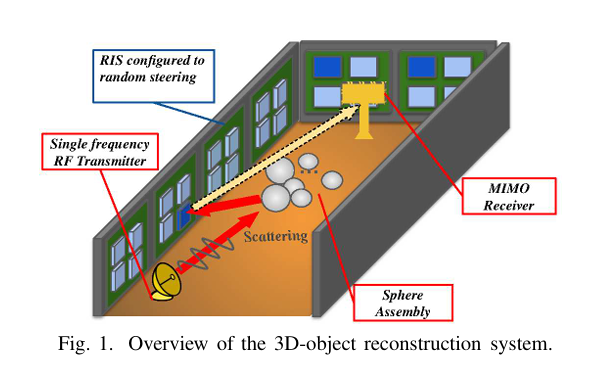
论文:https://arxiv.org/abs/2511.02573
Comments:Submitted to IEEE ICC 2026
原文 资料 这里!
三、医学与生物视觉方向
1、Building Trust in Virtual Immunohistochemistry: Automated Assessment of Image Quality
作者:Tushar Kataria, Shikha Dubey, Mary Bronner, Jolanta Jedrzkiewicz, Ben J. Brintz, Shireen Y. Elhabian, Beatrice S. Knudsen
亮点:提出以准确性为核心的虚拟免疫组化图像质量评估框架,通过颜色反卷积生成IHC阳性像素掩码,计算Dice、IoU等指标量化像素级标记准确性,无需专家手动标注。实验证实FID、PSNR等传统保真度指标与染色准确性和病理学家评估相关性低,同时发现配对模型染色准确性最优,且全切片图像评估能暴露切片级评估无法发现的性能下降问题。

论文:https://arxiv.org/abs/2511.04615
2、Polarization-resolved imaging improves eye tracking
作者:Mantas Žurauskas, Tom Bu, Sanaz Alali, Beyza Kalkanli, Derek Shi, Fernando Alamos, Gauresh Pandit, Christopher Mei, Ali Behrooz, Ramin Mirjalili, Dave Stronks, Alexander Fix, Dmitri Model
亮点:提出偏振增强眼动追踪系统,结合偏振滤光阵列相机与线偏振近红外光源,能捕捉巩膜上的可追踪特征和角膜上的视线相关图案,这些特征在纯强度图像中难以显现。在346名参与者的测试中,基于该系统训练的模型,在正常条件及眼睑遮挡、眼距变化等场景下,中位95百分位绝对视线误差降低10%-16%,为可穿戴设备提供更可靠的传感方案。
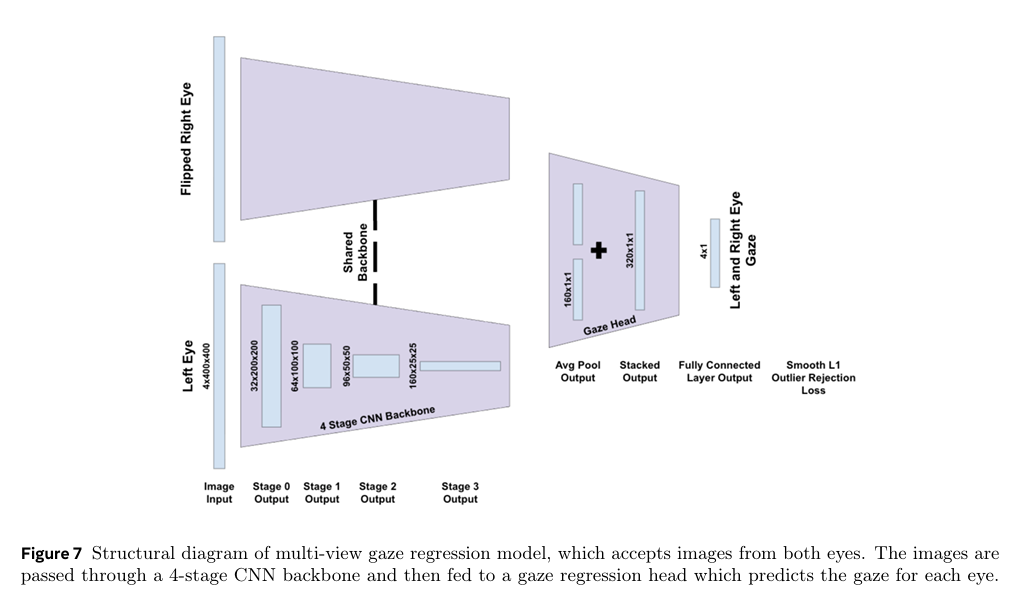
论文:https://arxiv.org/abs/2511.04652
四、图像数据集与模型优化方向
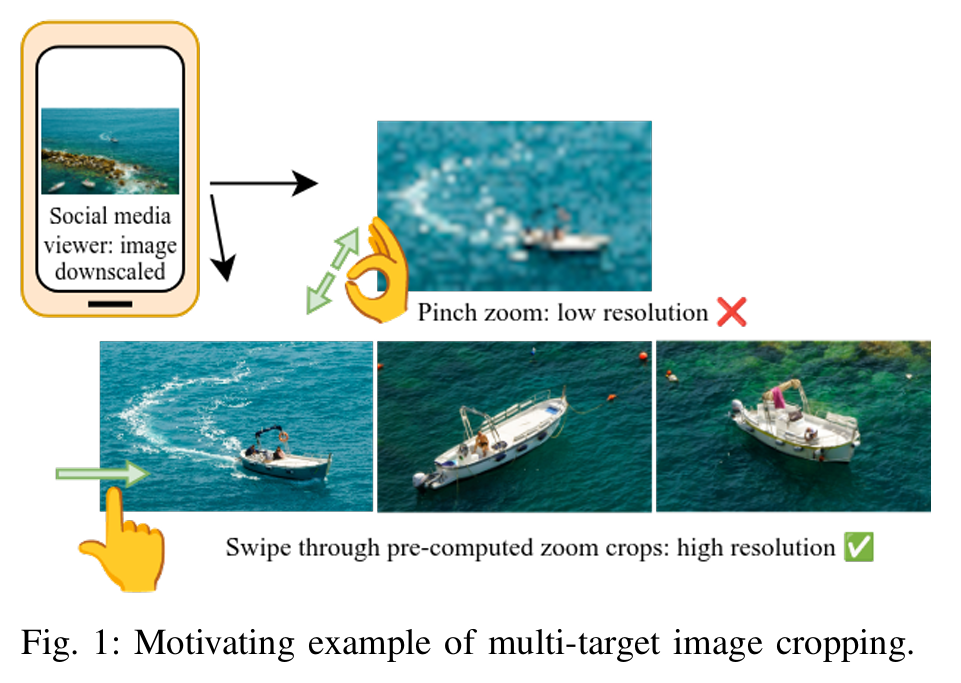
1、Carousel: A High-Resolution Dataset for Multi-Target Automatic Image Cropping
作者:Rafe Loya, Andrew Hamara, Benjamin Estell, Benjamin Kilpatrick, Andrew C. Freeman
亮点:聚焦社交媒体等场景下多目标美观裁剪的研究缺口,创新性构建包含277张相关图像及人工标注的高分辨率数据集。通过图像分割算法预处理,评估多种单裁剪模型在多目标裁剪任务中的效能,为后续多目标自动图像裁剪技术的研发提供了关键的数据支撑和基准参照。
论文:https://arxiv.org/abs/2511.04680
开源代码:https://github.com/RafeLoya/carousel
Comments:Accepted to the Datasets track of VCIP 2025
2、Linear Mode Connectivity under Data Shifts for Deep Ensembles of Image Classifiers
作者:C. Hepburn, T. Zielke, A. P. Raulf
亮点:深入研究数据偏移下图像分类器深度集成的线性模式连接(LMC)现象,将数据偏移视为随机梯度噪声的额外来源,并发现小学习率和大批次大小可降低该噪声影响。揭示LMC相关模型虽误差趋同,但能平衡训练效率与集成模型的多样性增益,为优化图像分类集成模型的训练策略、提升泛化能力提供了重要理论参考。

论文:https://arxiv.org/abs/2511.04514
开源代码:https://github.com/DLR-KI/LMC
原文 资料 这里!