Kimi K2 Thinking 量化之后再量化,模型文件缩水60%,准确率85%,部署教程来了
Kimi K2 Thinking
大家好,我是Ai学习的老章
Kimi K2 Thinking 实测,碾压Qwen3-Max
迄今为止最强大的开源模型:Kimi K2 Thinking ,比肩闭源模型
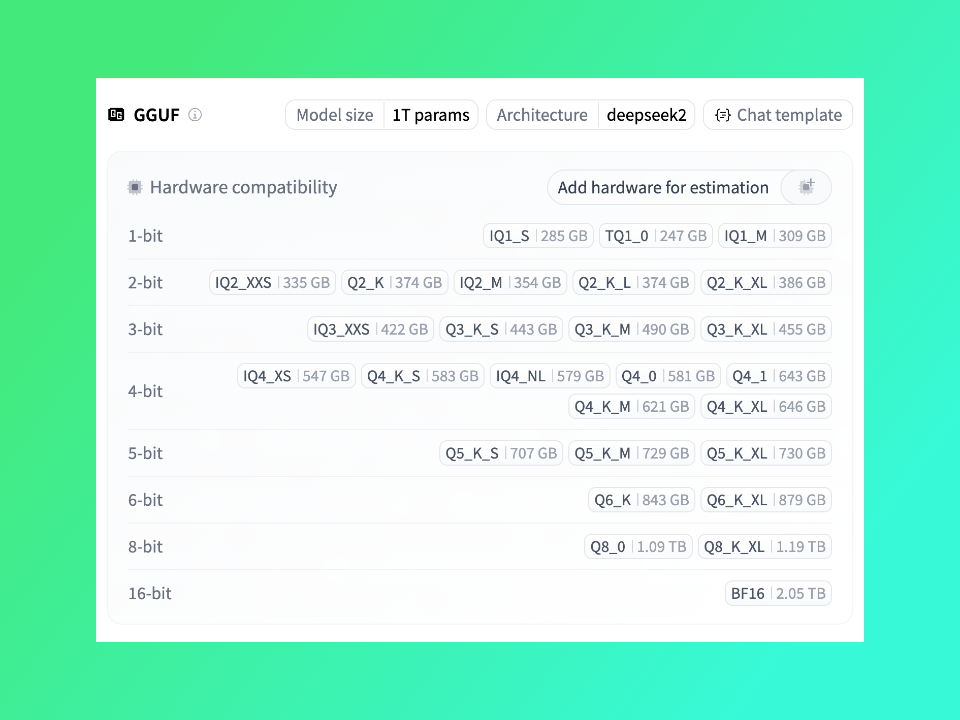
Kimi K2 Thinking 原生 INT4 量化实现了2 倍快速推理,1TB参数的大模型模型文件只有594GB,但即便如此要启动 Kimi-K2-Thinking 需要 8 个 141GB 的 H200/H20,成本还是蛮高的。前文我就提到:即便再量化,估计向下空间也不大了。已经 int4 了,还能怎样?
这不大模型量化界翘楚:unsloth又来整活儿了,重现Kimi K2极致量化时刻,直接迎来了1-bit版,最低仅需247GB 内存!!!
运行模型需:
磁盘空间 + 内存(RAM) + 显存(VRAM) ≥ 量化模型大小
以 1.8-bit 的 UD-TQ1_0 量化版本(约247GB)为例:
- 最低要求:你的磁盘、内存和显存总和需要大于 247GB。
llama.cpp支持磁盘卸载(mmap),所以即使内存+显存不足,模型也能运行,只是速度会很慢(可能低于 1 token/s)。 - 推荐配置:为了获得流畅体验(例如 5+ tokens/s),建议 内存+显存总和 约等于模型大小。
- GPU 玩家示例:拥有一张 24GB 显存的 GPU(如 RTX 3090/4090),配合足够大的内存(如 256GB RAM),通过 MoE 卸载技术,可以实现约 1-2 tokens/s 的推理速度。
Unsloth 官方建议使用 UD-Q2_K_XL(约360GB)版本,以在模型大小和准确性之间取得最佳平衡。
有条件还是更多地上GPU吧,上面方案也仅仅是提供了可能性,几乎不可用啊。越多显存,才能实现越快的生成速度,从594到360,也大幅降低成本了。
部署教程:一共三步
第一步:编译最新的 llama.cpp
首先,需要一个支持 Kimi-K2 的最新版 llama.cpp。
# 更新并安装依赖
apt-get update
apt-get install pciutils build-essential cmake curl libcurl4-openssl-dev -y# 克隆 llama.cpp 仓库
git clone https://github.com/ggml-org/llama.cpp# 编译(根据你的硬件选择)
# 如果有 NVIDIA GPU
cmake llama.cpp -B llama.cpp/build -DBUILD_SHARED_LIBS=OFF -DGGML_CUDA=ON -DLLAMA_CURL=ON
# 如果没有 GPU,纯 CPU 运行
# cmake llama.cpp -B llama.cpp/build -DBUILD_SHARED_LIBS=OFF -DGGML_CUDA=OFF -DLLAMA_CURL=ONcmake --build llama.cpp/build --config Release -j --clean-first
cp llama.cpp/build/bin/llama-* llama.cpp
第二步:下载 Unsloth 量化模型
使用 huggingface_hub 脚本(推荐) 这种方式更灵活,可以选择下载特定版本。
# 安装依赖
# pip install huggingface_hub hf_transferimport os
# 如果下载速度慢或卡住,可以禁用 hf_transfer
os.environ["HF_HUB_ENABLE_HF_TRANSFER"] = "0"
from huggingface_hub import snapshot_download# 下载模型文件
snapshot_download(repo_id = "unsloth/Kimi-K2-Thinking-GGUF",local_dir = "unsloth/Kimi-K2-Thinking-GGUF",# UD-TQ1_0 是 1.8-bit (247GB) 版本# UD-Q2_K_XL 是 2.7-bit (381GB) 版本,官方推荐allow_patterns = ["*UD-Q2_K_XL*"],
)
第三步:运行模型与高级技巧:MoE 卸载
这是在有限硬件上成功运行 Kimi 的关键!Kimi 是一个混合专家模型(MoE),我们可以将部分的“专家层”卸载到 CPU 和内存中,只在 GPU 中保留核心部分,从而大幅降低显存占用。
这是通过 -ot 或 --offload-tensor 参数实现的。
./llama.cpp/llama-cli \--model unsloth/Kimi-K2-Thinking-GGUF/UD-Q2_K_XL/Kimi-K2-Thinking-UD-Q2_K_XL-00001-of-00008.gguf \--n-gpu-layers 99 \--temp 1.0 \--min-p 0.01 \--ctx-size 16384 \--seed 3407 \-ot ".ffn_.*_exps.=CPU"
MoE 卸载技巧详解:
-ot ".ffn_.*_exps.=CPU":卸载所有 MoE 层。这是最节省显存的模式,大约只占用 8GB VRAM。-ot ".ffn_(up|down)_exps.=CPU":卸载 MoE 的 up 和 down projection 层,需要稍多一些显存。-ot ".ffn_(up)_exps.=CPU":只卸载 up projection 层,需要更多显存。- 不使用
-ot:如果你有足够的显存(例如 360GB+),去掉此参数,将所有层加载到 GPU 以获得最快速度。
可以用正则表达式进行更精细的控制,例如只卸载第6层之后的 MoE 层。
还可以使用 llama-server 将本地模型封装成一个与 OpenAI API 兼容的服务。
-
启动服务:
./llama.cpp/llama-server \--model unsloth/Kimi-K2-Thinking-GGUF/UD-Q2_K_XL/Kimi-K2-Thinking-UD-Q2_K_XL-00001-of-00008.gguf \--alias "unsloth/Kimi-K2-Thinking" \--threads -1 \-fa on \--n-gpu-layers 999 \-ot ".ffn_.*_exps.=CPU" \--min_p 0.01 \--ctx-size 16384 \--port 8001 \--jinja -
使用 Python 调用:
# pip install openai from openai import OpenAIclient = OpenAI(base_url = "http://127.0.0.1:8001/v1",api_key = "sk-no-key-required", )completion = client.chat.completions.create(model = "unsloth/Kimi-K2-Thinking",messages = [{"role": "user", "content": "What is 2+2?"},], ) print(completion.choices[0].message.content)
其他细节
- Thinking 模型参数:官方建议
temperature设置为1.0,min_p设置为0.01,以减少重复并抑制低概率 token 的出现。 - 看见模型的“思考”:Kimi-Thinking 模型有一项特殊能力,会生成
<think>标签来展示其“思考过程”。在llama.cpp中,你需要在命令末尾添加--special标志才能看到这些标签。 <|im_end|>结束符:你可能会在输出末尾看到这个特殊 token,这是正常的。可以在你的应用中将其设置为 stop string 来隐藏它。