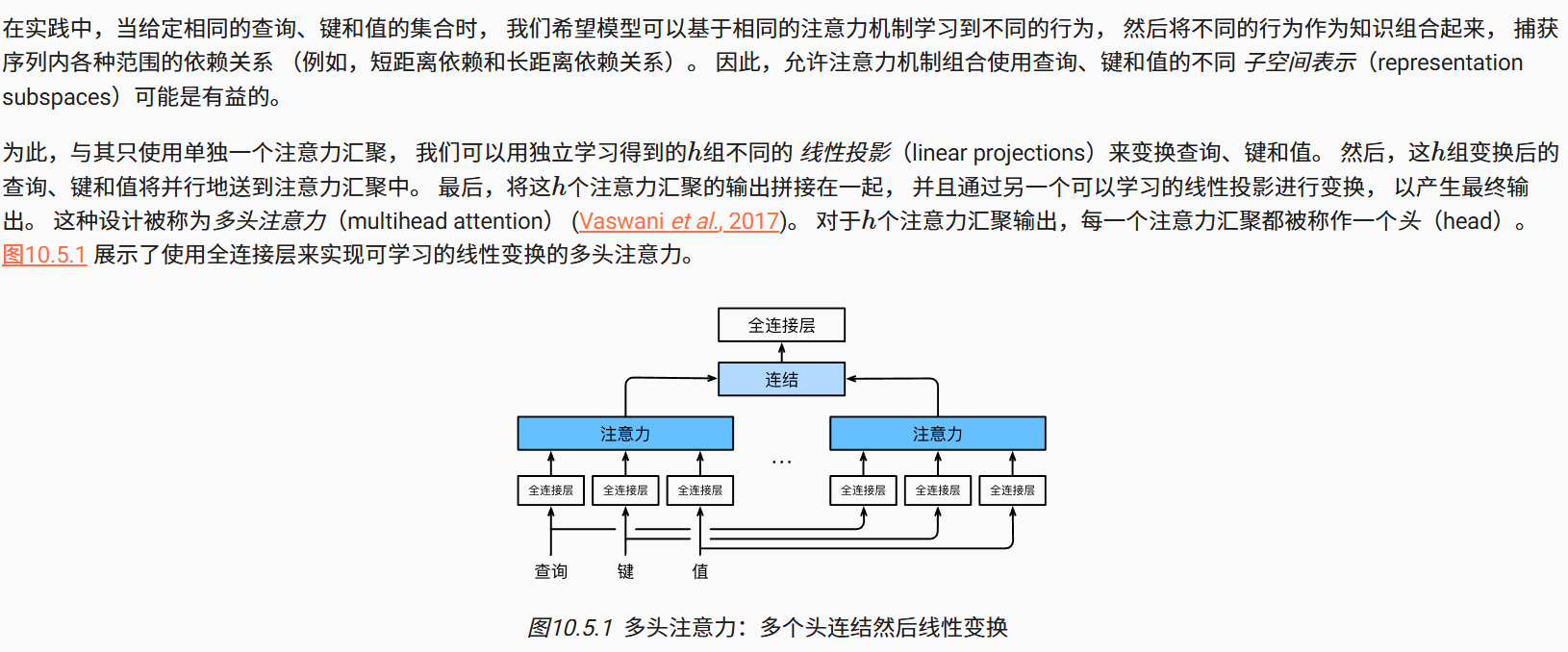
1.多头注意力机制
import math
import torch
from torch import nn
from d2l import torch as d2l
def transpose_qkv(X, num_heads):#[B,T,H]->[B,T,N,H/N]X=X.reshape(X.shape[0],X.shape[1],num_heads,-1)#[B,T,N,H/N]->[B,N,T,H/N]X=X.permute(0,2,1,3)#[B*N,T,H/N]return X.reshape(-1,X.shape[2],X.shape[3])
#逆转回去:
def transpose_output(X, num_heads):"""逆转transpose_qkv函数的操作"""X = X.reshape(-1, num_heads, X.shape[1], X.shape[2])X = X.permute(0, 2, 1, 3)return X.reshape(X.shape[0], X.shape[1], -1)class MultiHeadAttention(nn.Module):def __init__(self,key_size,query_size,value_size,num_hiddens,num_heads,dropout,bias=False,**kwargs):super(MultiHeadAttention,self).__init__(**kwargs)self.num_heads=num_headsself.attention=d2l.DotProductAttention(dropout)self.w_q=nn.Linear(query_size,num_hiddens,bias=False)self.w_k=nn.Linear(key_size,num_hiddens,bias=False)self.w_v=nn.Linear(value_size,num_hiddens,bias=False)self.w_o=nn.Linear(num_hiddens,num_hiddens,bias=False)def forward(self,queries,keys,values,valid_lens):queries=transpose_qkv(self.w_q(queries),self.num_heads)keys = transpose_qkv(self.w_k(keys), self.num_heads)values = transpose_qkv(self.w_v(values), self.num_heads)if valid_lens is not None:valid_lens = torch.repeat_interleave(valid_lens, repeats=self.num_heads, dim=0)output = self.attention(queries, keys, values, valid_lens)# output_concat的形状:(batch_size,查询的个数,num_hiddens)output_concat=transpose_output(output,self.num_heads)return self.w_o(output_concat)
num_hiddens, num_heads = 100, 5
attention = MultiHeadAttention(num_hiddens, num_hiddens, num_hiddens,num_hiddens, num_heads, 0.5)
attention.eval()
batch_size, num_queries = 2, 4
num_kvpairs, valid_lens = 6, torch.tensor([3, 2])
X = torch.ones((batch_size, num_queries, num_hiddens))
Y = torch.ones((batch_size, num_kvpairs, num_hiddens))
attention(X, Y, Y, valid_lens).shape
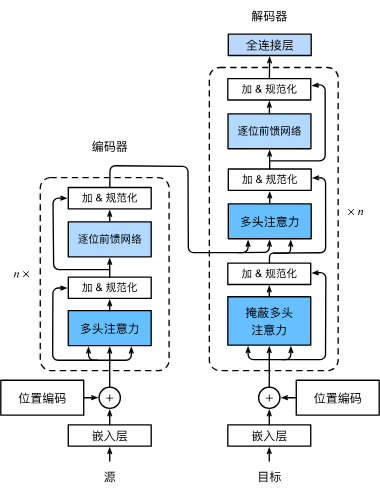
2.Transformer架构
import math
import pandas as pd
import torch
from torch import nn
from d2l import torch as d2l
########################################################################################
#FFN
class PositionWiseFFN(nn.Module):"""基于位置的前馈网络"""def __init__(self, ffn_num_input, ffn_num_hiddens, ffn_num_outputs,**kwargs):super(PositionWiseFFN, self).__init__(**kwargs)self.dense1 = nn.Linear(ffn_num_input, ffn_num_hiddens)self.relu = nn.ReLU()self.dense2 = nn.Linear(ffn_num_hiddens, ffn_num_outputs)#mlp->relu->mlpdef forward(self, X):return self.dense2(self.relu(self.dense1(X)))
#add&norm(ln)
class AddNorm(nn.Module):"""残差连接后进行层规范化"""def __init__(self, normalized_shape, dropout, **kwargs):super(AddNorm, self).__init__(**kwargs)self.dropout = nn.Dropout(dropout)self.ln = nn.LayerNorm(normalized_shape)def forward(self, X, Y):return self.ln(self.dropout(Y) + X)
#编码器
class EncoderBlock(nn.Module):def __init__(self,key_size,query_size,value_size,num_hiddens,norm_shape,ffn_num_input,ffn_num_hiddens,num_heads,dropout,use_bias=False,**kwargs):super(EncoderBlock,self).__init__(**kwargs)self.attention=d2l.MultiHeadAttention(key_size,query_size,value_size,num_hiddens,num_heads,dropout,use_bias)self.addnorm1=AddNorm(norm_shape,dropout)self.ffn=PositionWiseFFN(ffn_num_input,ffn_num_hiddens,num_hiddens)self.addnorm2=AddNorm(norm_shape,dropout)def forward(self,X,valid_lens):Y=self.addnorm1(X,self.attention(X,X,X,valid_lens))return self.addnorm2(Y,self.ffn(Y))
#transformer堆叠实现:
class TransformerEncoder(nn.Module):def __init__(self, vocab_size, key_size, query_size, value_size,num_hiddens, norm_shape, ffn_num_input, ffn_num_hiddens,num_heads, num_layers, dropout, use_bias=False, **kwargs):super(TransformerEncoder,self).__init__(**kwargs)self.num_hiddens=num_hiddensself.embedding=nn.Embedding(vocab_size,num_hiddens)self.pos_encoding=d2l.PositionalEncoding(num_hiddens,dropout)self.blks=nn.Sequential()for i in range(num_layers):self.blks.add_module("block"+str(i),EncoderBlock(key_size, query_size, value_size, num_hiddens,norm_shape, ffn_num_input, ffn_num_hiddens,num_heads, dropout, use_bias)) def forward(self,X,valid_lens,*args):X=self.pos_encoding(self.embedding(X)*math.sqrt(self.num_hiddens))self.attention_weights=[None]*len(self.blks)for i,blk in enumerate(self.blks):X=blk(X,valid_lens)self.attention_weights[i]=blk.attention.attention.attention_weightsreturn X
class DecoderBlock(nn.Module):def __init__(self, key_size, query_size, value_size, num_hiddens,norm_shape, ffn_num_input, ffn_num_hiddens, num_heads,dropout, i, **kwargs):super(DecoderBlock, self).__init__(**kwargs)self.i=iself.attention1 = d2l.MultiHeadAttention(key_size, query_size, value_size, num_hiddens, num_heads, dropout)self.addnorm1=AddNorm(norm_shape, dropout)self.attention2 = d2l.MultiHeadAttention(key_size, query_size, value_size, num_hiddens, num_heads, dropout)self.addnorm2=AddNorm(norm_shape,dropout)self.ffn=PositionWiseFFN(ffn_num_input,ffn_num_hiddens,num_hiddens)self.addnorm3=AddNorm(norm_shape,dropout)def forward(self,X,state):enc_output,enc_valid_lens=state[0],state[1]if state[2][self.i] is None:key_values=Xelse:key_values=torch.cat((state[2][self.i],X),axis=1)state[2][self.i]=key_valuesif self.training:batch_size,num_steps,_=X.shapedec_valid_lens=torch.arange(1,num_steps+1,device=X.device).repeat(batch_size,1)else:dec_valid_lens=NoneX2=self.attention1(X,key_values,key_values,dec_valid_lens)Y=self.addnorm1(X,X2)Y2=self.attention2(Y,enc_output,enc_output,enc_valid_lens)Z=self.addnorm2(Y,Y2)return self.addnorm3(Z,self.ffn(Z)),state
class TransformerDecoder(d2l.AttentionDecoder):def __init__(self, vocab_size, key_size, query_size, value_size,num_hiddens, norm_shape, ffn_num_input, ffn_num_hiddens,num_heads, num_layers, dropout, **kwargs):super(TransformerDecoder, self).__init__(**kwargs)self.num_hiddens=num_hiddensself.num_layers=num_layersself.embedding=nn.Embedding(vocab_size,num_hiddens)self.pos_encoding=d2l.PositionalEncoding(num_hiddens,dropout)self.blks=nn.Sequential()for i in range(num_layers):self.blks.add_module("block"+str(i),DecoderBlock(key_size, query_size, value_size, num_hiddens,norm_shape, ffn_num_input, ffn_num_hiddens,num_heads, dropout, i))self.dense=nn.Linear(num_hiddens,vocab_size)def init_state(self,enc_outputs,enc_valid_lens,*args):return [enc_outputs,enc_valid_lens,[None]*self.num_layers]def forward(self,X,state):X=self.pos_encoding(self.embedding(X)*math.sqrt(self.num_hiddens))self._attention_weights=[[None]*len(self.blks) for _ in range(2)]for i,blk in enumerate(self.blks):X,state=blk(X,state)self._attention_weights[0][i]=blk.attention1.attention.attention_weightsself._attention_weights[1][i]=blk.attention2.attention.attention_weightsreturn self.dense(X),state@propertydef attention_weights(self):return self._attention_weights
########################################################################################
num_hiddens, num_layers, dropout, batch_size, num_steps = 32, 2, 0.1, 64, 10
lr, num_epochs, device = 0.005, 200, d2l.try_gpu()
ffn_num_input, ffn_num_hiddens, num_heads = 32, 64, 4
key_size, query_size, value_size = 32, 32, 32
norm_shape = [32]train_iter, src_vocab, tgt_vocab = d2l.load_data_nmt(batch_size, num_steps)encoder = TransformerEncoder(len(src_vocab), key_size, query_size, value_size, num_hiddens,norm_shape, ffn_num_input, ffn_num_hiddens, num_heads,num_layers, dropout)
decoder = TransformerDecoder(len(tgt_vocab), key_size, query_size, value_size, num_hiddens,norm_shape, ffn_num_input, ffn_num_hiddens, num_heads,num_layers, dropout)
net = d2l.EncoderDecoder(encoder, decoder)
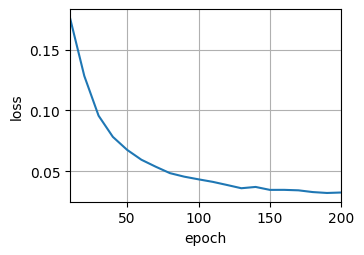
d2l.train_seq2seq(net, train_iter, lr, num_epochs, tgt_vocab, device)
engs = ['go .', "i lost .", 'he\'s calm .', 'i\'m home .']
fras = ['va !', 'j\'ai perdu .', 'il est calme .', 'je suis chez moi .']
for eng, fra in zip(engs, fras):translation, dec_attention_weight_seq = d2l.predict_seq2seq(net, eng, src_vocab, tgt_vocab, num_steps, device, True)print(f'{eng} => {translation}, ',f'bleu {d2l.bleu(translation, fra, k=2):.3f}')

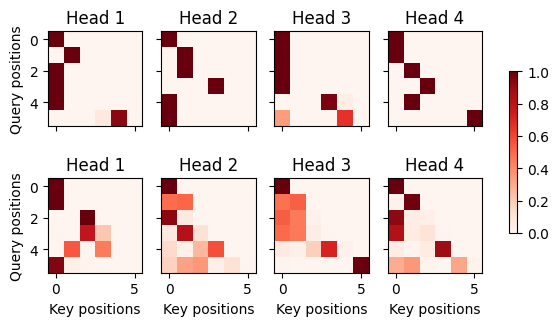
dec_attention_weights_2d = [head[0].tolist()for step in dec_attention_weight_seqfor attn in step for blk in attn for head in blk]
dec_attention_weights_filled = torch.tensor(pd.DataFrame(dec_attention_weights_2d).fillna(0.0).values)
dec_attention_weights = dec_attention_weights_filled.reshape((-1, 2, num_layers, num_heads, num_steps))
dec_self_attention_weights, dec_inter_attention_weights = \dec_attention_weights.permute(1, 2, 3, 0, 4)
dec_self_attention_weights.shape, dec_inter_attention_weights.shape
d2l.show_heatmaps(dec_self_attention_weights[:, :, :, :len(translation.split()) + 1],xlabel='Key positions', ylabel='Query positions',titles=['Head %d' % i for i in range(1, 5)], figsize=(7, 3.5))