《MedChat智能医疗问答系统》项目介绍
【LIC·2025语言与智能技术竞赛——人民日报健康客户端赛道一 --二等奖方案】
🎯 项目概述
-
🚀 技术特色:Agentic RAG架构 + 多智能体协作 + 血象智能分析
-
💡 技术探索:算力约束下的"小模型大能力"技术方案
-
🏥 应用场景:面向医疗问答的智能化解决方案
参考编排模板来源: AI Studio 项目模板
🏆 比赛背景
本项目参与了LIC·2025语言与智能技术竞赛——人民日报健康客户端赛道一,在学习和实践中不断改进技术方案。
🎯 赛事介绍
语言与智能技术竞赛(LIC)是中国计算机学会(CCF)和中国中文信息学会(CIPS)联合主办的中文NLP顶级赛事,为NLP领域的研究者和开发者提供了宝贵的交流平台。
本届赛事与人民日报健康客户端、智源研究院、TVB合作,围绕文心大模型技术栈,开放高价值数据集,为探索大模型在医疗健康领域的应用提供了良好机会。
⚙️ 技术要求
本赛事使用文心大模型4.5系列(全系列已开源):
-
🔥 MoE模型:47B和3B的混合专家模型(最大424B总参数)
-
⚡ 稠密模型:0.3B稠密参数模型
一、🎖️ 项目简介
MedChat 是一套面向医疗问答场景的多智能体系统,采用 Agentic RAG 架构,集成微调医学小模型、通用大模型、VL 视觉语言模型、三层知识图谱。
🎯 设计理念
面向"低成本·高质量·可落地"的医疗 AI 方案探索
📋 项目特点
| 项目维度 | 我们的实践 |
|---|---|
| 参赛赛道 | 赛道一 - 健康医疗智能问答 |
| 技术方向 | Agentic RAG架构 + 多智能体协作 + 血象智能分析 |
| 技术探索 | 算力约束下的"小模型大能力"技术方案 |
| 应用价值 | 为资源受限环境提供医疗AI解决方案思路 |
二、📊 训练数据集构建流程
2.1 🎬 多模态数据采集与处理
我们构建了一套完整的医疗数据处理流水线,从多官方提供的数据集进行抓取转换:
📹 视频数据处理流程
-
视频文件下载:爬取官方excel中提供的网页链接中的视频
- 语音转文字:使用 FunASR 进行高精度的语音识别转换
-
支持中文医疗术语识别
-
保持专业词汇的准确性
-
处理医学专业发音
-
🌐 网页内容抓取
-
网页文字提取:系统化抓取医疗网站的文字内容
2.2 🔄 数据预处理与质量控制
📝 文本汇总与过滤
-
数据汇总:将所有来源的文字内容进行统一整理
-
格式标准化处理
-
重复内容识别
-
数据质量评估
-
-
智能过滤:多层次的内容过滤机制
-
医疗相关性筛选
-
内容质量评估
-
噪音数据清理
-
敏感信息过滤
-
2.3 🤖 AI驱动的知识生成
🧠 GPT-4.1-Nano智能处理
-
QA对生成:使用 GPT-4.1-Nano 进行问答对生成
-
基于医疗文本生成高质量问答对
-
确保医学专业性和准确性
-
覆盖不同难度层次的问题
-
-
知识图谱构建:同步生成结构化知识图谱
-
实体识别与抽取
-
关系建模与验证
-
三层图谱架构构建
-
2.4 📋 数据整合与分发
🔧 最终数据处理
-
QA数据整合:问答对数据的最终处理
-
内容去重与质量筛选
-
格式统一与标准化
-
训练集/验证集/测试集划分
-
-
知识图谱整合:知识图谱数据的优化处理
-
实体关系去重
-
图谱完整性验证
-
向量化预处理
-
🎯 数据分发策略
-
模型训练数据:为0.3B医疗微调模型提供高质量训练数据
-
约70万医疗问答对
-
覆盖多个医疗专业领域
-
难度梯度合理分布
-
-
知识图谱数据库:为RAG系统构建知识检索库
-
三层知识图谱结构
-
支持语义检索的向量化数据
-
实时查询优化的索引结构
-
2.5 🔄 数据处理流程图
graph TDA[📹 视频文件下载] --> B[🎤 FunASR语音转文字]C[🌐 网页文字抓取] --> D[📝 文本汇总]B --> DD --> E[🔍 智能过滤]E --> F[🤖 GPT-4.1-Nano处理]F --> G[❓ QA对生成]F --> H[🕸️ 知识图谱生成]G --> I[🔧 QA数据整合去重]H --> J[📊 KG数据整合去重]I --> K[🎯 模型训练数据]J --> L[📚 向量知识图谱库]
2.6 📈 数据规模统计
| 数据类型 | 数量规模 | 用途 |
|---|---|---|
| 原始视频 | 约500小时医疗教学视频 | FunASR转文字处理 |
| 网页文本 | 约200万条医疗相关文档 | 知识内容提取 |
| 过滤后文本 | 约70万条高质量医疗文档 | GPT-4.1-Nano处理 |
| 生成QA对 | 约70万医疗问答对 | 0.3B模型微调训练 |
| 知识图谱 | 约15万实体,50万关系 | RAG系统知识检索 |
三、🚀 核心技术特性
3.1 🎯 技术背景与挑战
在比赛环境下,我们面临着一些技术挑战,这也推动了我们的技术创新:
| 挑战类型 | 具体问题 | 我们的思考 |
|---|---|---|
| 🔧 算力约束 | 比赛提供的A800算力只能支持ERNIE4-0.3B模型训练 | 如何在有限资源下实现良好效果 |
| 🤖 小模型局限 | 0.3B参数规模在复杂医疗推理中的表现有限 | 探索小模型协作的可能性 |
| 📊 传统RAG挑战 | 医药领域强因果推理特性,传统向量检索可能引入噪音 | 寻找更适合医疗场景的RAG方案 |
3.2 💡 技术方案:Agentic RAG架构
基于上述挑战,我们尝试了Agentic RAG架构的技术路线:
🔄 核心设计思路
graph TDA[复杂用户问题] --> B[20B模型问题分解]B --> C[多个精确子问题]C --> D[0.3B微调模型分布式推理]D --> E[三层知识图谱增强]E --> F[大模型质量把控]F --> G[综合答案输出]
-
🎯 微调:将ERNIE4.5-0.3B模型的PPL训练到5-6区间
-
🔀 问题分解:利用ERNIE4.5-21B大模型拆分复杂问题
-
⚡ 分布式推理:让子问题分别查询ERNIE4.5-0.3B微调模型
-
🕸️ 知识图谱:三层知识图谱提供结构化支持,加深知识点的关联跟踪
-
🛡️ 质量保障:大模型(ERNIE-4.5-300B-A47B-Paddle)进行最终质量把控
-
🛡️ Agentic设计:ERNIE4.5-21B会收集用户更多的信息,然后再利用以上的核心处理提高回答的质量具体设计见(完整系统工作流程)
技术栈
AI模型架构:
-
智能询问模型:ernie-4.5-21b-a3b (降低成本,可本地部署)
-
通用总结模型:ernie-4.5-turbo-128k-preview (大模型兜底保证质量)
-
医疗专用模型:ernie-4.5-0.3b-medical (微调,速度快成本低)
-
视觉语言模型:ernie-4.5-turbo-vl-preview (医学图像识别)
-
嵌入模型:BAAI/bge-large-zh-v1.5
后端技术栈:
-
框架:FastAPI (Python 3.8+)
-
数据库:SQLite + SQLite-vec (向量搜索)
-
日志系统:Loguru
-
数据验证:Pydantic
前端技术栈:
-
框架:Vue 3 + TypeScript
-
UI组件:Element Plus
-
状态管理:Pinia
-
构建工具:Vite
-
样式框架:Tailwind CSS
四、🩸 血象智能分析
4.1 💡 功能背景
🌟 在医疗AI应用中,我们尝试实现血常规报告的智能化分析,希望能为血液检验的自动化处理提供一些技术思路。
4.2 ⭐ 功能设计
| 功能模块 | 技术方案 | 设计目标 |
|---|---|---|
| 🔍 报告识别 | ernie-4.5-turbo-vl-preview | 尝试自动识别血象报告 |
| 📊 数据提取 | VL模型结构化识别 | 提取WBC、RBC、HGB、PLT等指标 |
| ⚠️ 异常检测 | 参考范围比对 | 标注可能的异常项目 |
| 🧠 智能问诊 | 基于异常项的问题生成 | 收集相关症状和病史信息 |
| 📝 综合分析 | 多模态信息整合 | 结合症状和检验数据进行分析 |
4.3 🔄 处理流程设计
graph LRA[📤 上传图片] --> B[🔍 VL模型识别]B --> C[⚠️ 异常项检测]C --> D[❓ 生成问诊问题]D --> E[👥 收集症状信息]E --> F[🧠 综合分析]F --> G[📋 输出分析结果]
五、📊 系统架构展示
5.1 🤖 智能体协作架构设计
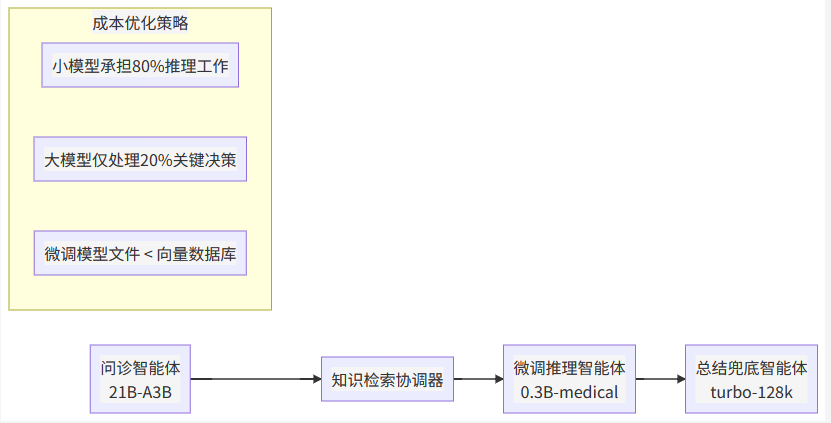
5.2 📈 数据生成流程

微调效果指标
-
**困惑度(PPL)**:5.7
-
训练轮次:500
-
学习率:1e-06
5.3 🕸️ 三层知识图谱架构
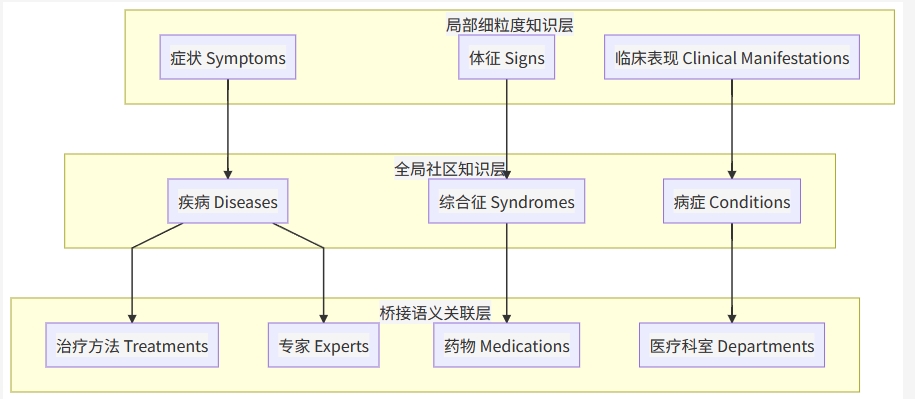
关系驱动的桥接发现
系统通过分析医学知识图谱中的关系网络,动态发现桥接知识:
关系类型:
-
症状→疾病关系
-
疾病→治疗关系
-
疾病→科室关系
桥接发现算法: 通过关系图谱发现桥接实体,采用双向关系查找、置信度过滤和类型匹配的方式,实现智能的知识关联。
5.4 🧠 智能问诊流程
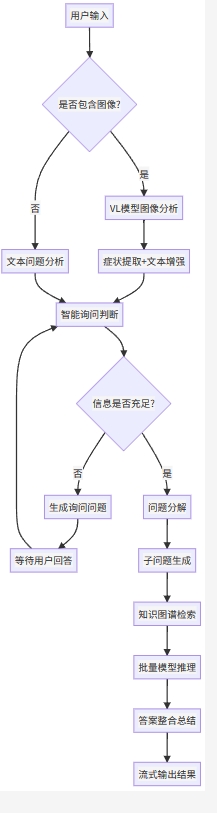
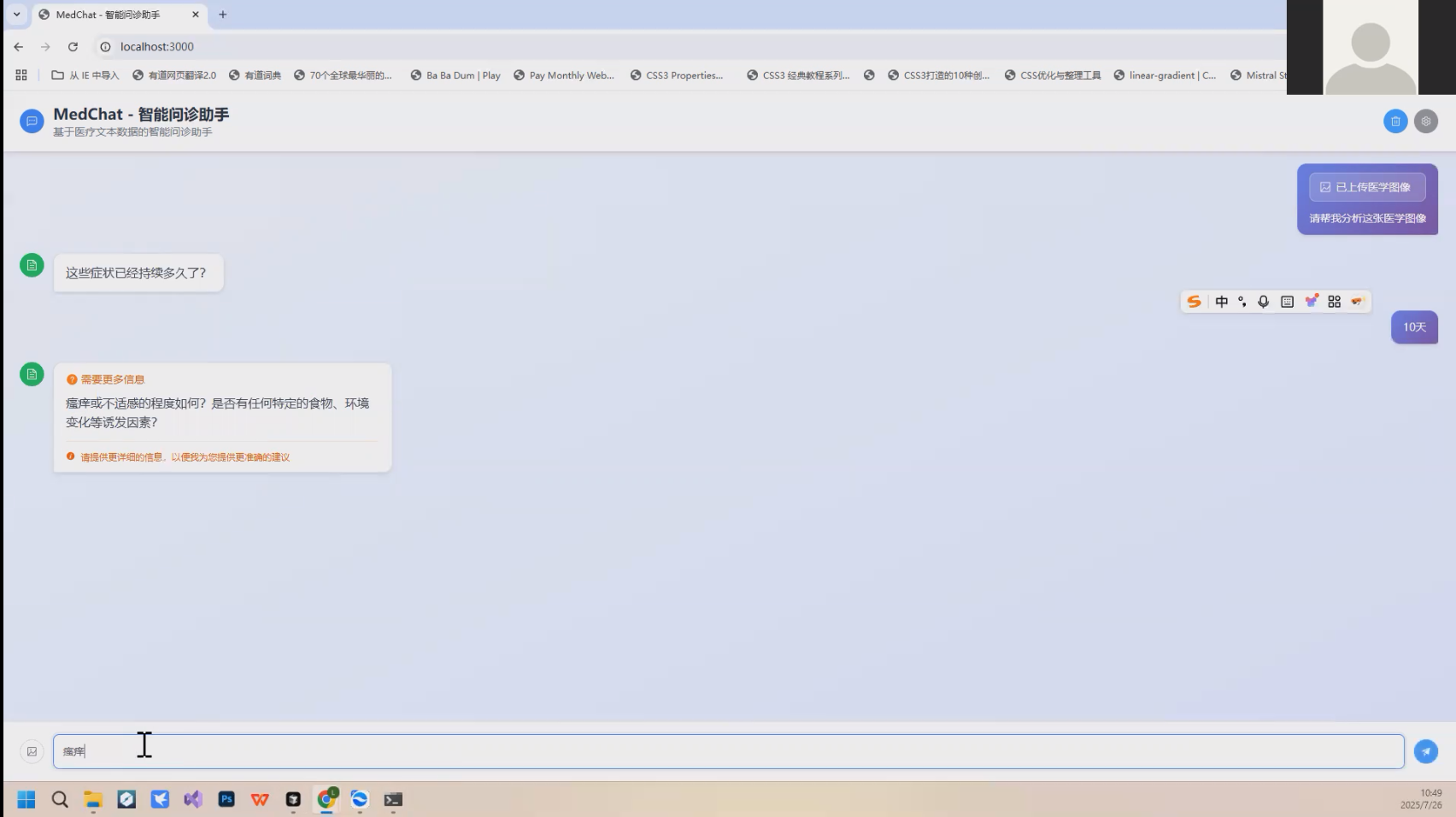
询问策略
询问限制:最多2(可设置)轮询问,避免过度询问
询问优先级:
-
症状具体部位
-
持续时间
-
严重程度
-
伴随症状
-
诱发因素
重复问题避免:
-
记录询问历史
-
语义相似性检测
-
渐进式信息收集
5.5 🔄 完整系统工作流程
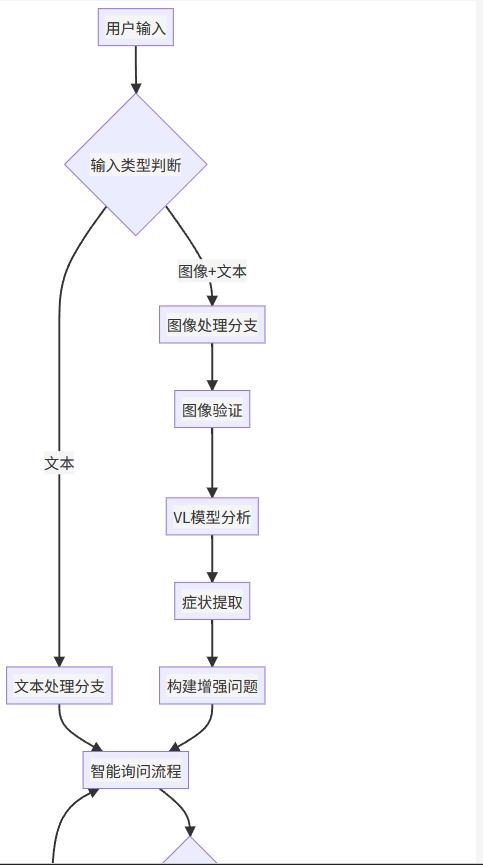
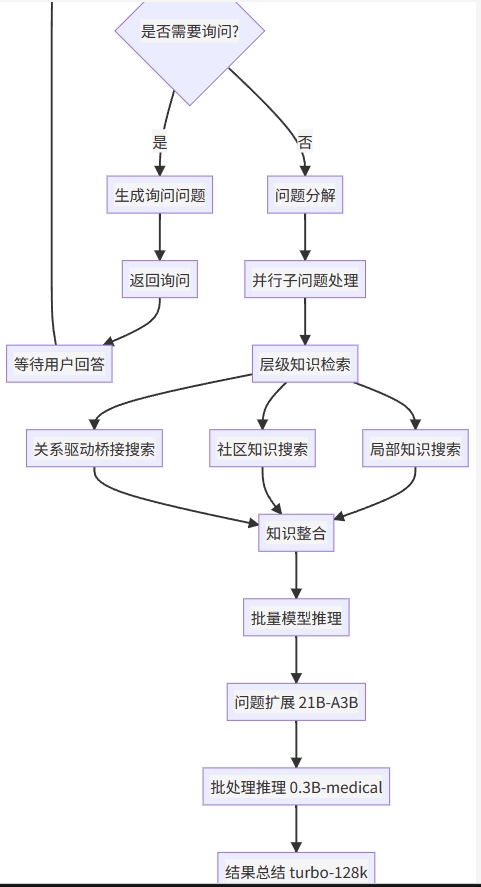
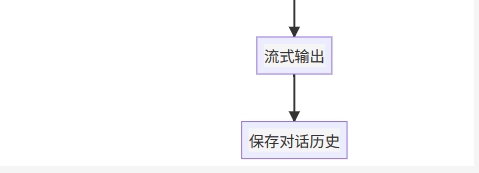
图像分析提示词设计
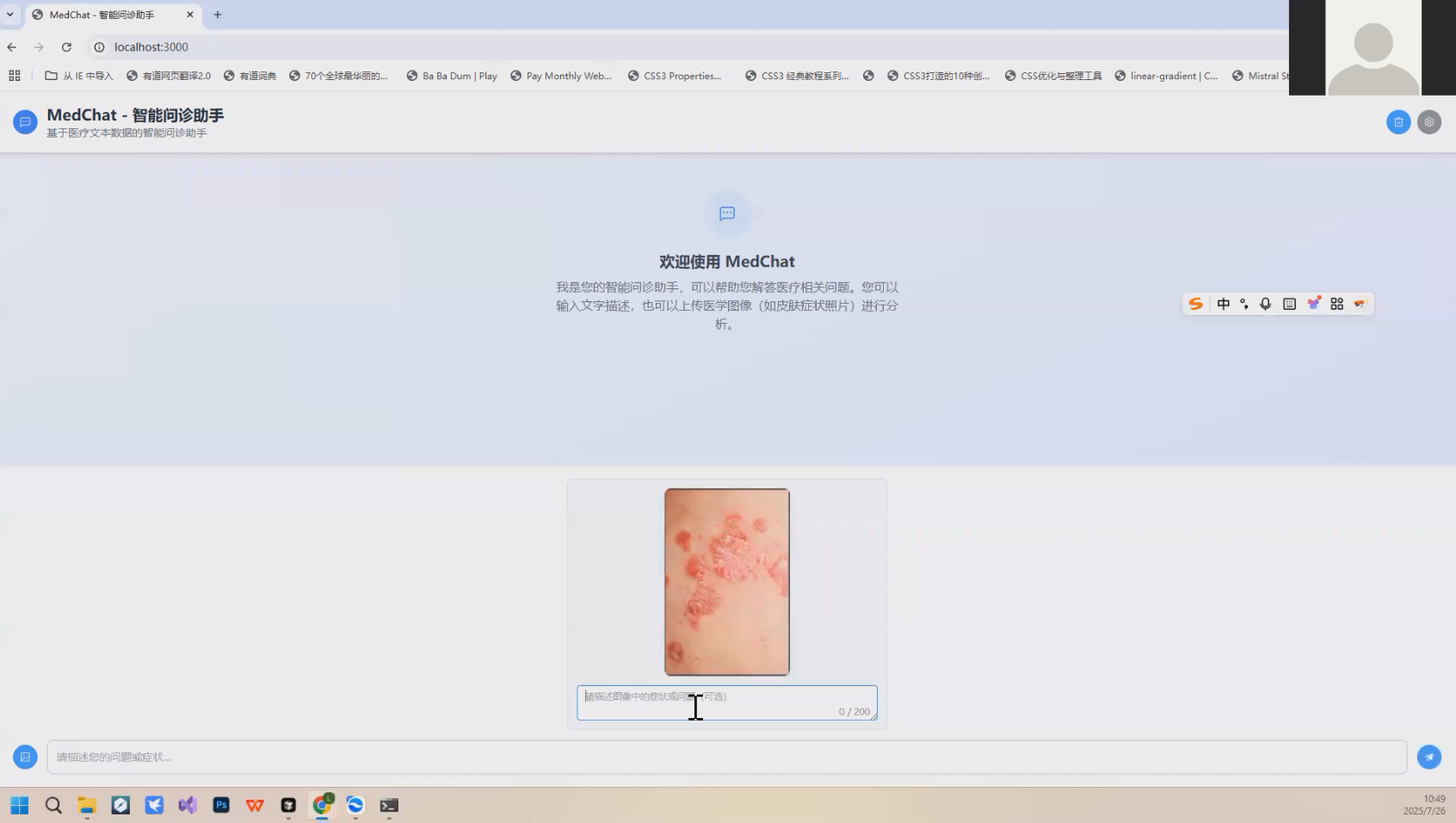
系统采用专业的医学图像分析提示词,包括:
-
图像观察:描述观察到的症状、病变特征、颜色、形状、大小、分布等
-
可能的诊断:基于观察列出可能的疾病(按可能性排序)
-
症状描述:用专业但易懂的语言描述主要症状
-
建议:提供初步建议和注意事项
-
重要提醒:强调这只是初步分析,不能替代专业医生诊断
def _build_blood_detection_prompt(self, user_description: str) -> str: """构建血象检测的提示词""" return """你是一位专业的血液检验医师。请仔细分析这张图像,判断是否为血常规检查报告(血象)。
第一步:图像类型判断
判断这张图像是否为血常规检查报告。血常规检查报告的特征包括:
-
包含白细胞(WBC)、红细胞(RBC)、血红蛋白(HGB)、血小板(PLT)等指标
-
有具体的数值和参考范围
-
通常有医院或检验科的标识
-
格式规范,像检验报告单
第二步:如果是血象报告,提取关键数据
如果确认是血象报告,请提取以下关键指标(如果图像中存在):
-
白细胞计数(WBC)、红细胞计数(RBC)、血红蛋白(HGB/HB)
-
血细胞比容(HCT)、平均红细胞体积(MCV)
-
平均红细胞血红蛋白含量(MCH)、平均红细胞血红蛋白浓度(MCHC)
-
血小板计数(PLT)、淋巴细胞百分比(LY%)、中性粒细胞百分比(NE%)
第三步:分析异常项目
标记出超出正常参考范围的项目,并简要说明其临床意义。
用户描述:{user_description}"""
def _get_inquiry_system_prompt(self) -> str: return """你是一位经验丰富的医生,负责智能问诊。你的任务是判断患者的描述是否需要进一步澄清。
核心原则
-
精准问诊:只在关键信息缺失时询问
-
避免过度询问:最多询问2轮,避免患者厌烦
-
医学专业性:基于临床经验判断重要信息
需要进一步询问的情况
-
症状描述模糊,缺少关键细节(部位、程度、持续时间)
-
可能存在多种疾病,需要鉴别诊断的关键信息
-
症状严重但描述不完整,需要评估紧急程度
直接回答的情况
-
问题描述清楚完整
-
常见症状,信息足够诊断
-
已经询问过相关信息
输出格式
请严格按照JSON格式输出: { "need_more_info": true/false, "reason": "判断理由", "question": "询问问题(仅在need_more_info为true时)", "complete_question": "完整问题描述(仅在need_more_info为false时)" }"""
七、🏆 技术实践总结
7.1 🎯 参赛体会与收获
通过参与LIC·2025语言与智能技术竞赛,我们在技术实践中有一些收获和体会:
🔧 算力约束下的技术探索
| 实践方向 | 我们的尝试 | 体会与收获 |
|---|---|---|
| 资源优化 | A800算力下的ERNIE-4.5-0.3B模型微调 | 学会了在有限资源下寻找技术突破点 |
| 协作架构 | 多智能体分工合作的尝试 | 体会到了小模型协作的潜在价值 |
| 成本控制 | 小模型+大模型(ERNIE-4.5-300B-A47B-Paddle)的混合方案 | 在成本与效果之间找到了一些平衡点 |
7.2 🌟 技术方案特点
| 技术维度 | 我们的实践 |
|---|---|
| 💡 创新探索 | 在医疗领域尝试Agentic RAG架构 |
| 🛠️ 系统完整性 | 包含前后端的完整系统实现 |
| 👨⚕️ 专业性 | 在血象分析等专业功能上的探索 |
| 💰 实用性 | 关注资源约束下的实际应用价值 |
| 📊 数据处理 | 完整的多模态数据处理流水线 |
💡 实践感悟:通过这次竞赛,我们体会到了在资源约束条件下进行技术创新的挑战与乐趣。从数据处理流水线到Agentic RAG架构,从血象智能分析到多智能体协作,每个环节都让我们对医疗AI应用有了更深入的理解。虽然还有很多需要改进的地方,但这次实践为我们今后的技术发展提供了宝贵的经验。
🚀作品演示
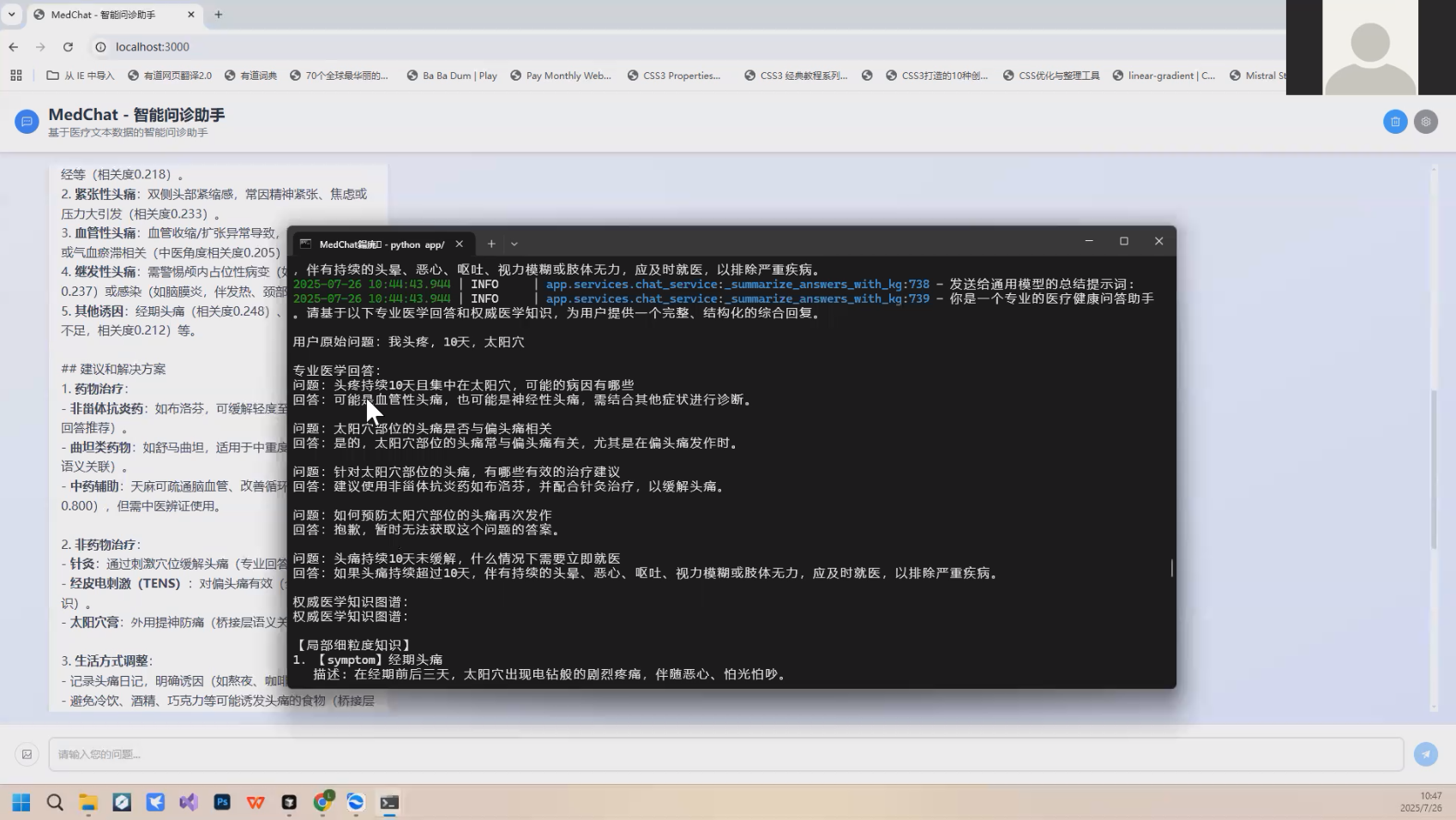
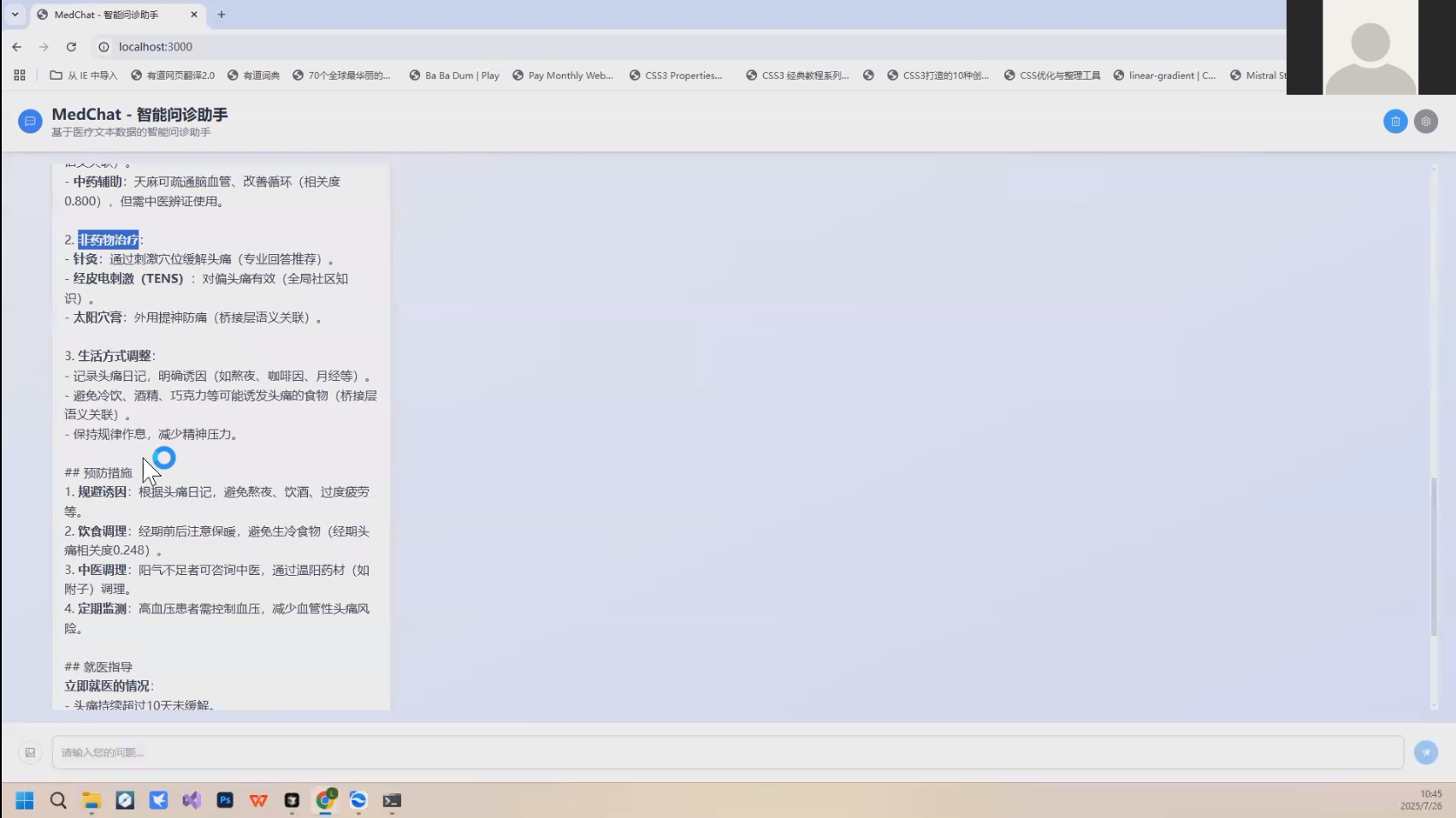
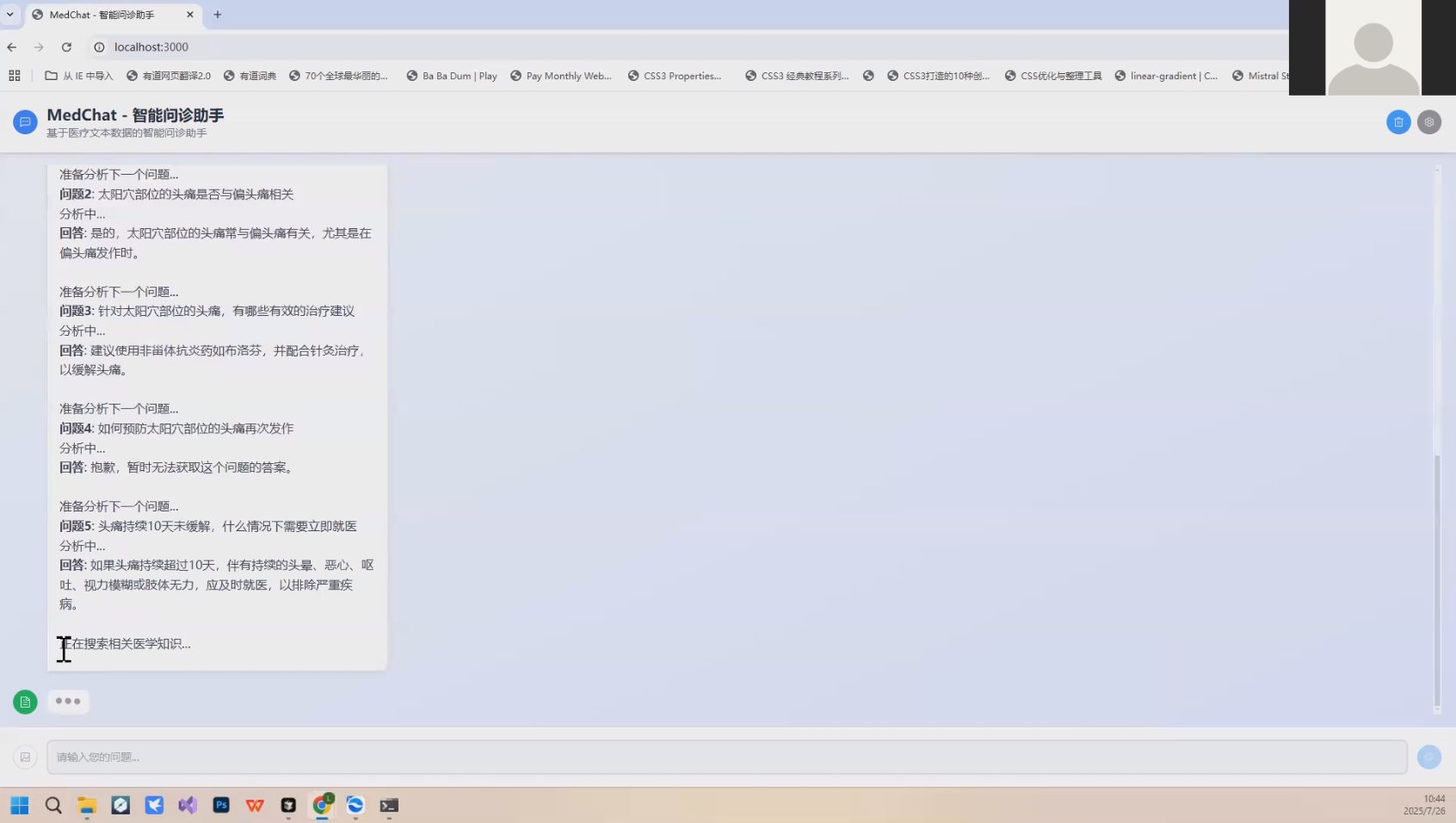
八、🚀 项目总结与展望
8.1 🏆 竞赛参与总结
本次参与LIC·2025语言与智能技术竞赛——人民日报健康客户端赛道一,我们的MedChat智能医疗问答系统在学习和实践中不断改进。
🎖️ 主要实践内容
-
📊 数据处理创新:构建了完整的多模态数据处理流水线,从视频转文字到知识图谱生成
-
🔧 技术探索:在A800算力限制下,尝试了Agentic RAG架构的"小模型大能力"方案
-
🏥 应用创新:探索了血象智能分析功能,为血液检验自动化提供技术思路
-
🤖 架构实践:通过多智能体协作,验证了小参数模型协作的可能性
8.2 🙏 感谢与致谢
🏆 竞赛平台支持
-
感谢LIC·2025竞赛组委会
-
感谢百度AI Studio社区:提供的算力支持和技术环境
-
感谢ERNIE模型生态:ERNIE-4.5系列模型为项目提供的AI能力支持
🌐 技术社区贡献
-
🐼 PaddlePaddle生态应用:充分利用飞桨生态的预训练模型和工具链
-
💻 开源实践分享:希望将竞赛中的技术探索与开源社区分享交流
-
🏥 医疗AI发展:为医疗AI领域的技术发展贡献一些实践经验