38.应用层协议HTTP(一)
HTTP协议概念和理解
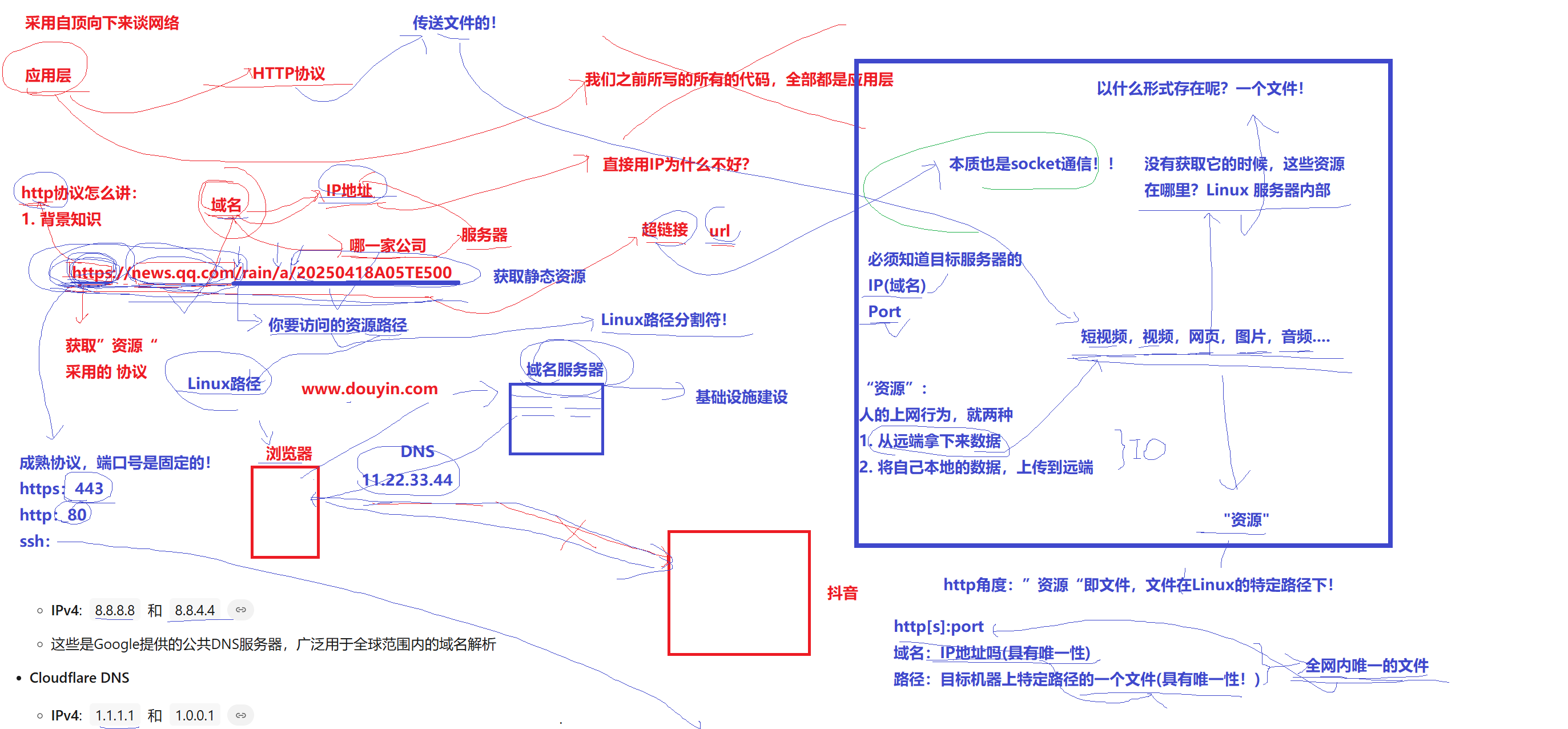
HTTP(HyperText Transfer Protocol,超文本传输协议)是一个至关重要的协议。它定义了客户端(如浏览器)与服务器之间如何通信,以交换或传输超文本(如HTML文档)(应用层协议)URL(Uniform Resource Locator,统一资源定位符)是互联网上用于标识和定位资源的标准化地址格式。URL构成实例:https://news.qq.com/rain/a/20250418A05TE500
- https(协议名称)
成熟的协议,端口号是固定的!
https:443
http:80
ssh:22
news.qq.com(域名)- 域名 -> IP地址 -> 直接用IP为什么不好?IP不利用人的阅读,人看不出含义
域名有对应的域名服务器进行解析(存放域名键值对的服务器,属于基础设施),域名转化成IP的过程称为DNS(Domain Name System,域名系统是互联网的核心服务之一,用于将人类可读的域名转换为计算机可识别的IP地址,实现网络访问的“地址翻译”)- /rain/a/20250418A05TE500(资源路径)
你访问的资源路径 -> linux路径分隔符HTTP协议,本质也是Socket通信->必须知道服务器IP(域名)+ 端口号(成熟协议端口号固定)HTTP协议本质理解:人上网的行为就两种:1)从远端拿数据(HTTP)2)把自己本地的数据上传给远端HTTP -> 传送文件的 -> 短视频,视频,网页,图片,音频 -> 在没有获取资源的时候,资源存在哪里?服务器内部 -> 以什么形式存在?一个文件HTTP角度:“资源”即文件,文件在Linux特定路径下。http[s]:port域名:IP地址,具有唯一性资源路径:目标机器上唯一一个文件http[s]:port:定位到全网唯一主机的唯一文件(超文本传输协议)
url特殊字符处理
请求的时候,url中如果有特殊字符,客户端(一般是浏览器),会自动给我们进行对特殊字符进行编码encode,浏览器urlencode,服务器urldecode。

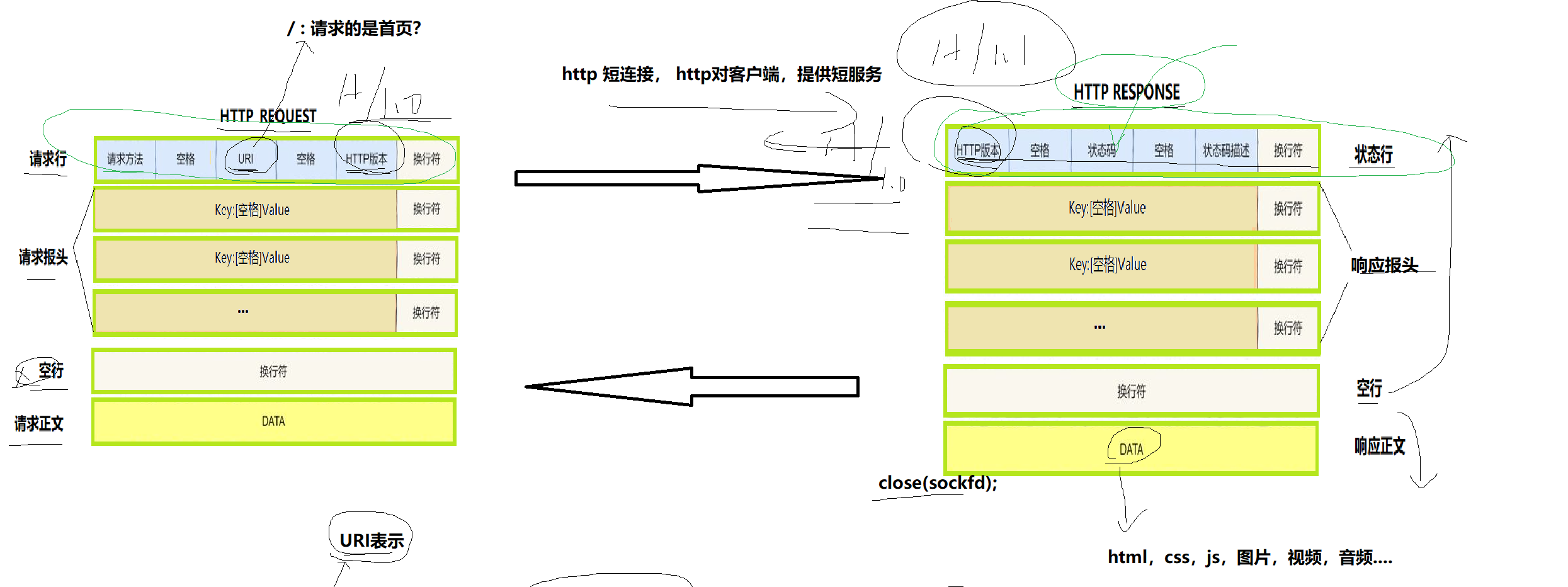
HTTP-request结构理解
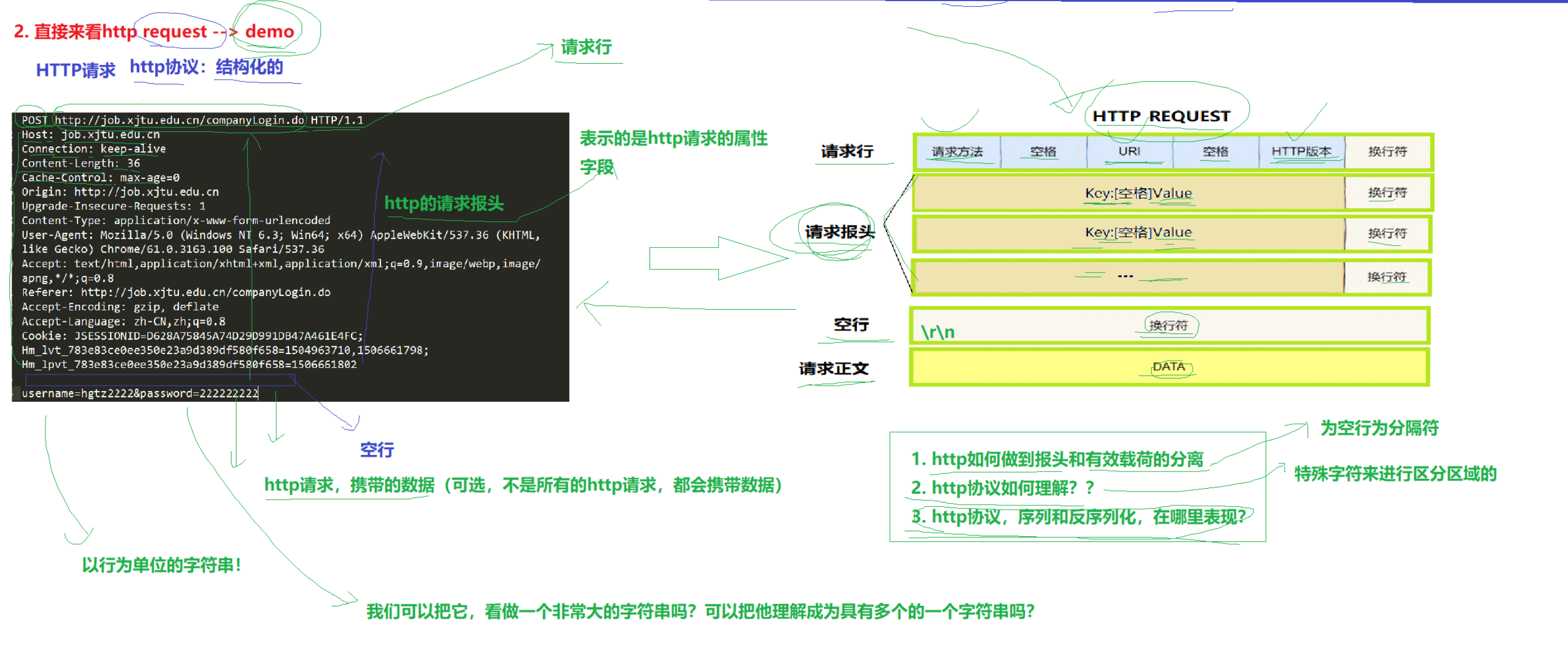
HTTP协议:结构化的,协议是通信双方约定的结构体。
不是所有的HTTP请求,都会携带数据。
三个问题:
1.http如何做到报头和有效载荷的分离?以空行为分隔符
2.http协议如何理解?特殊字符串来划分区域
3.http协议,序列化与反序列化,在哪里表现?
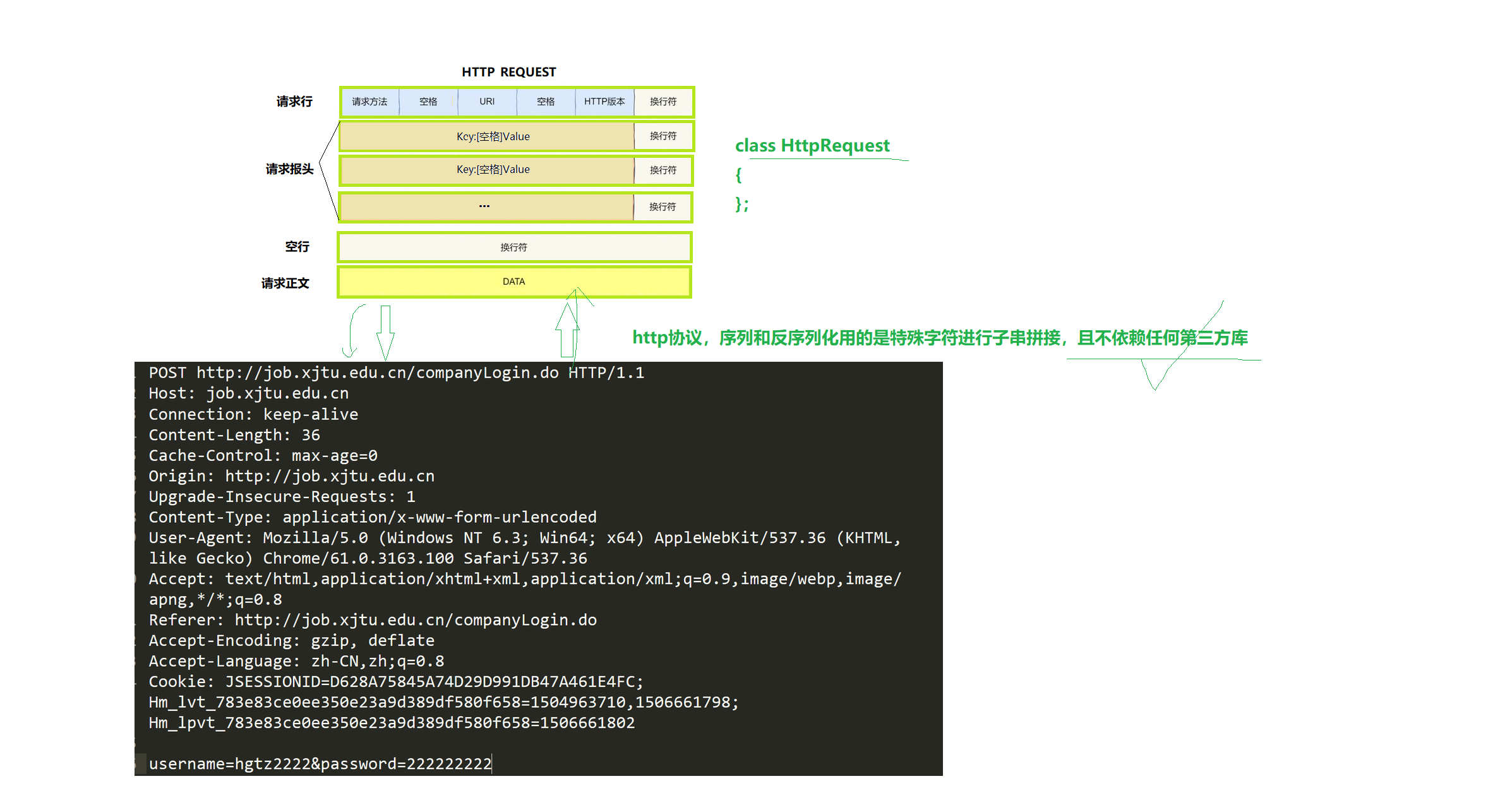
HTTP协议,序列化与反序列化用的是特殊字符进行子串拼接,且不依赖任何第三方库。
request结构分析
Request请求行:请求方法 URI HTTP版本
- 请求方法类型:最常见的GET(从远端服务器获取数据),POST(向远端服务器发送数据)
- URI:统一资源标识符(Uniform Resource Identifier),用于表示资源所在的路径。
其中 / 代表请求的是首页- HTTP版本:用于服务器进行判断版本(服务器根据客户端的HTTP版本请求可以提供相应版本的服务)
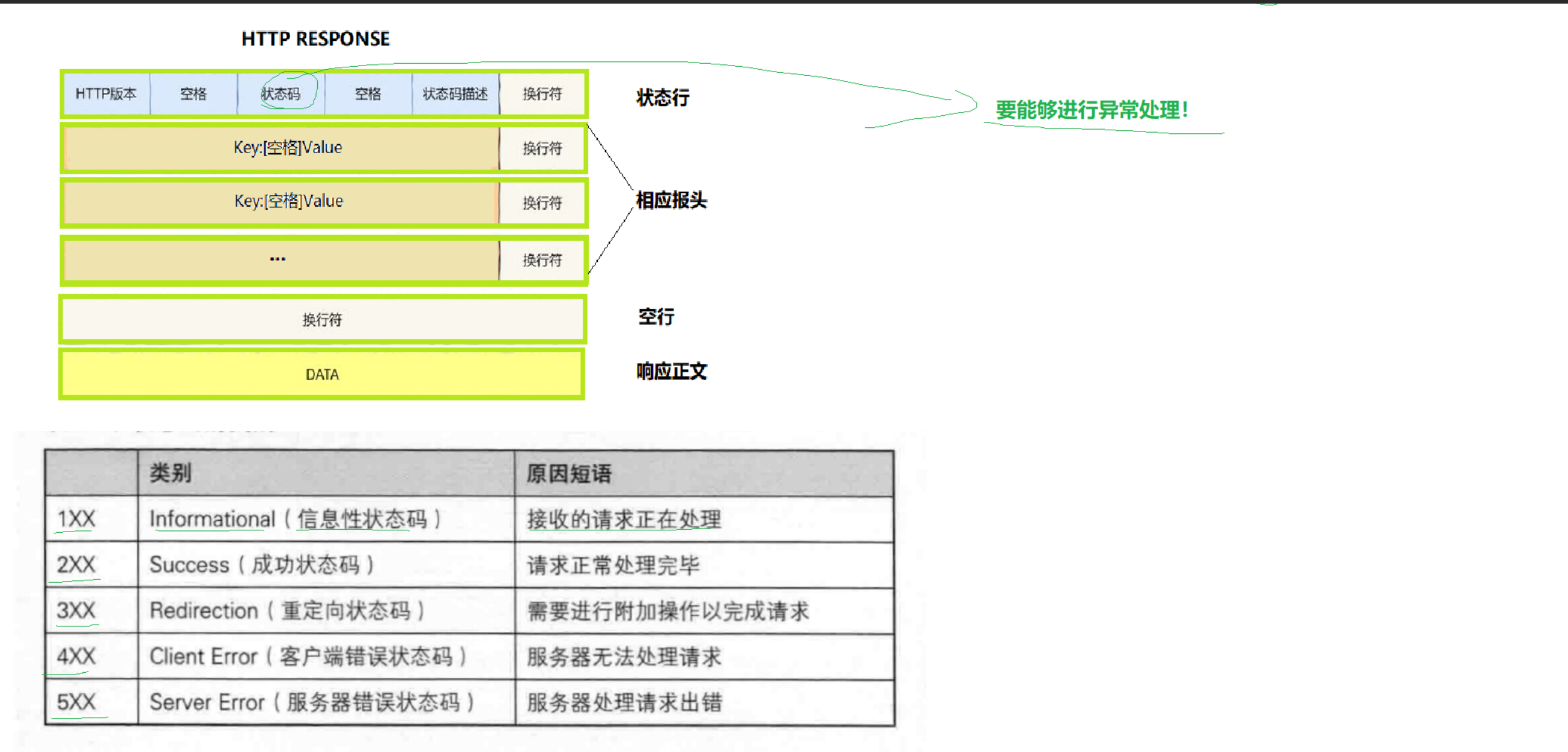
Response状态行:HTTP版本 状态码 状态码描述

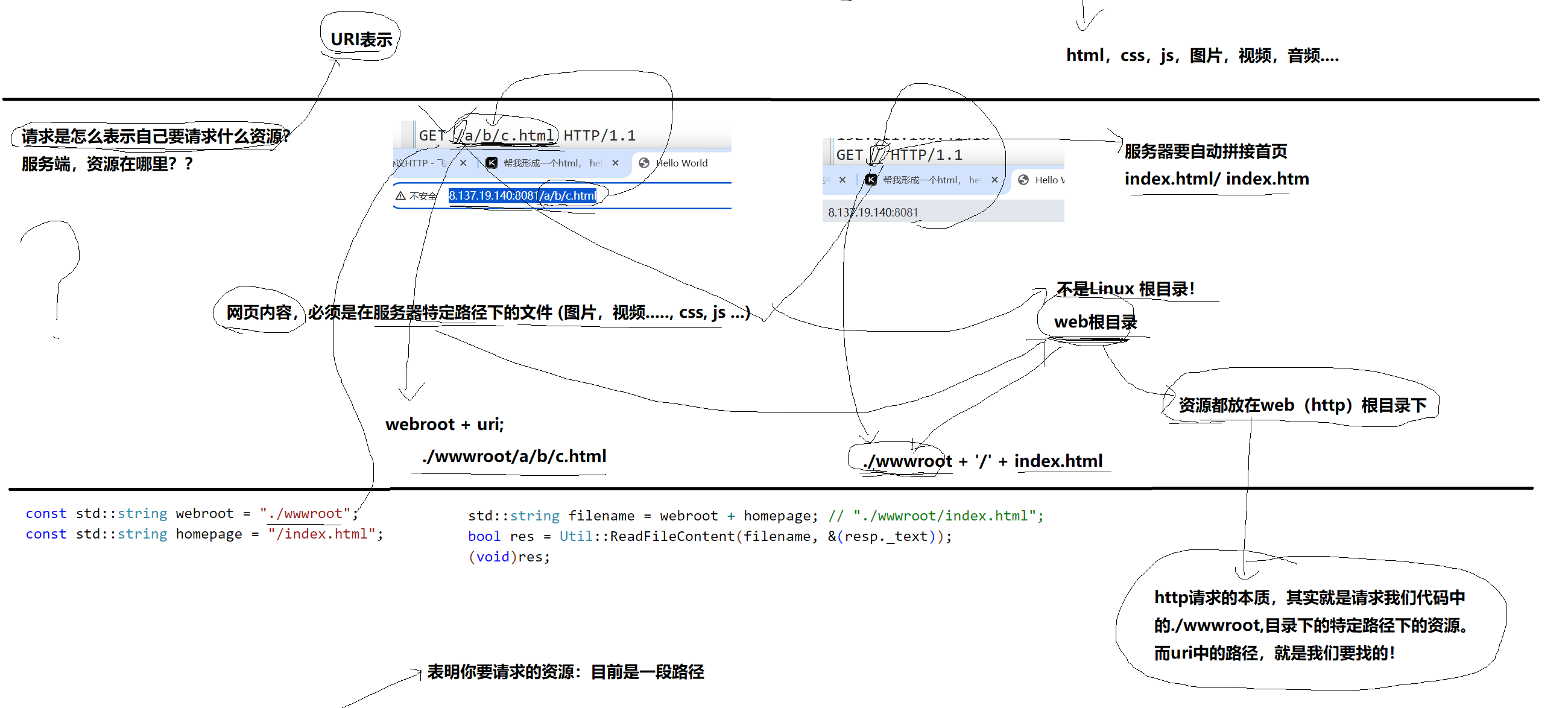
URI理解
请求是怎么表示自己要请求什么资源?URI表示
网页内容必须在服务器指定路径下的文件(图片,视频... css,js....)
URI内容 / 不是Linux根目录,而是web根目录 -> 资源都放在web(http)根目录下 -> http请求的本质,其实就是请求我们代码中的 ./wwwroot 目录下的特定路径下的资源。而URL中的路径,就是我们要请求的资源的路径。
URI路径转化成物理路径:
- / ,访问的是首页:./webroot + /index.html
- /a/b/c.html ,访问的是其他页面:./webroot + /a/b/c.html
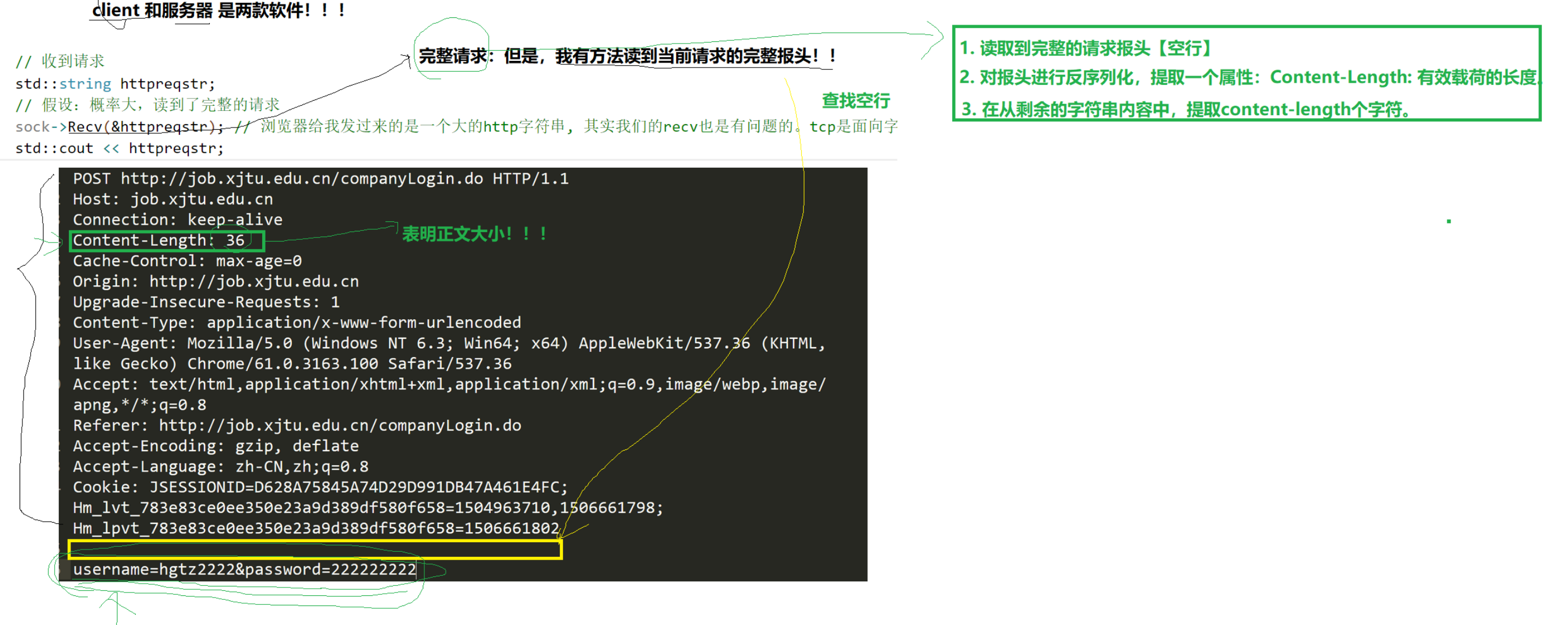
报文完整性判断方法
tcp协议是面向字节流的,读取后,需要对报文的完整性进行判断,方法:
1)读到完整的请求报头(空行分割)
2)对报头进行反序列化,提取一个属性:Content-Length(有效载荷长度)
3)从剩余字符串中,提取Content-Length个字符。
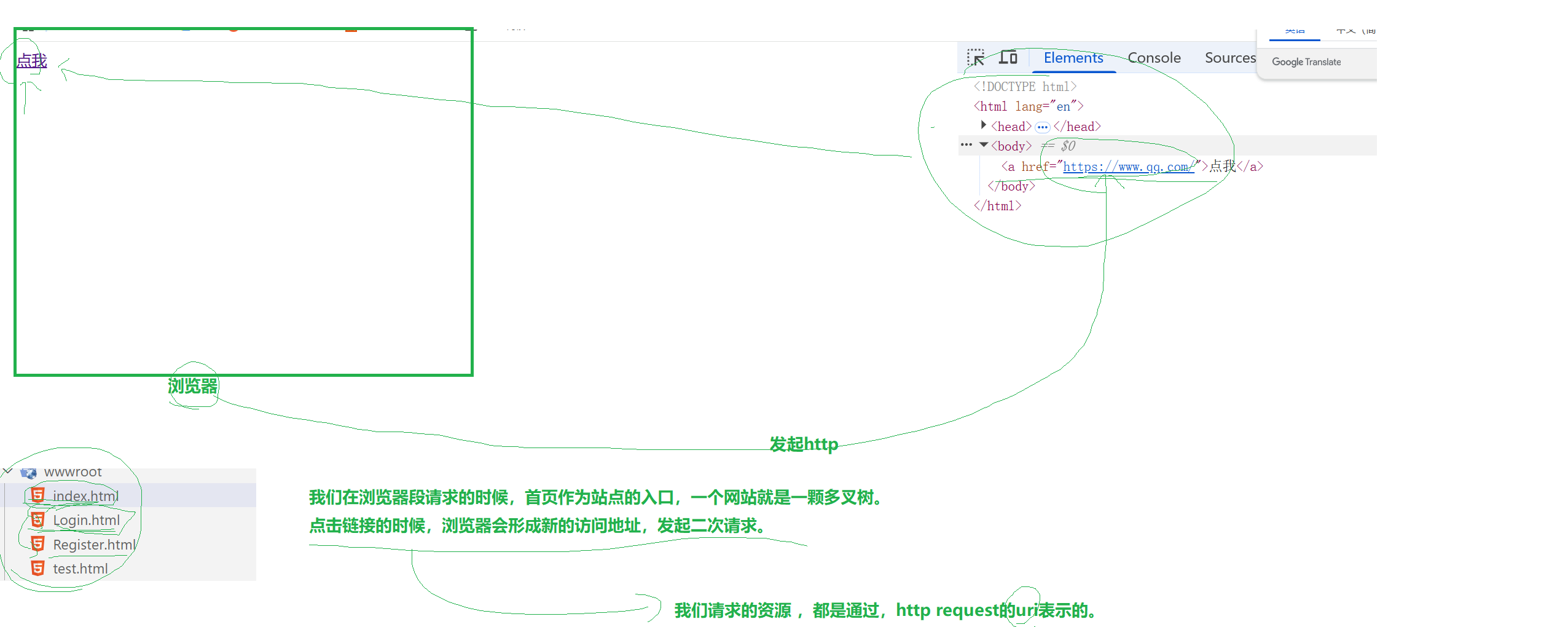
首页结构理解
a标签是存放资源路径或者url的。点击链接,浏览器会向服务器发起http请求。
我们在浏览器端请求的时候,首页作为站点的入口,一个网站就是一颗多叉树。
点击链接的时候,浏览器会形成新的访问地址,发送二次请求 -> 我们请求的资源,都是通过http request的 URI 表示的。
code理解
HTTP Response会通过特定状态码来标识对应的情况。