SpringCloud项目阶段六:feign服务降级处理以及基于DFA算法的自管理敏感词审核和tess4j图片文字识别集成
feign远程接口调用
- 流程:
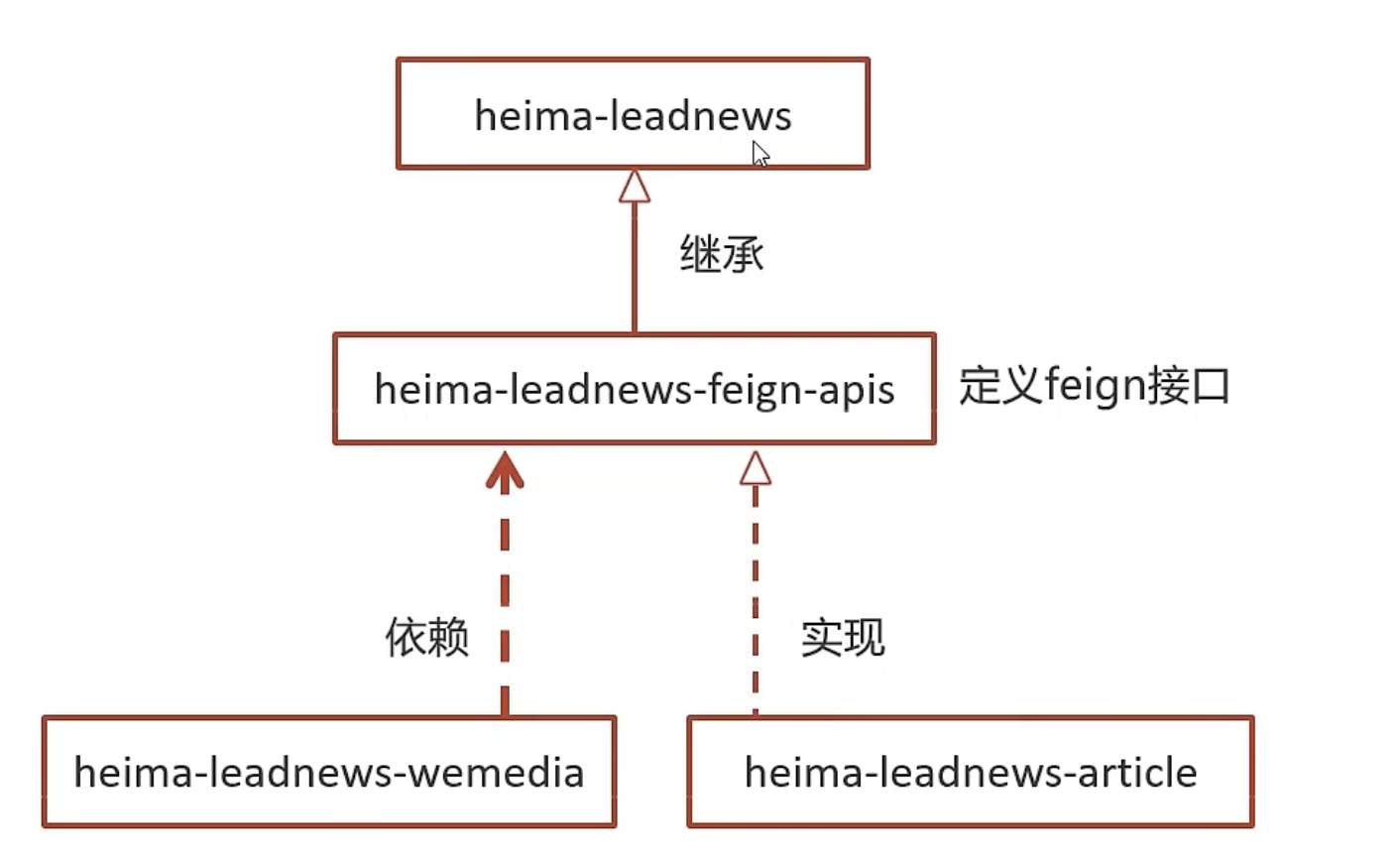
- 添加依赖
- 在service父模块中添加common模块
<dependency><groupId>com.heima</groupId><artifactId>heima-leadnews-common</artifactId>
</dependency>
- 使用说明:
-
- 直接注入
-
@Autowired
private IArticleClient articleClient;
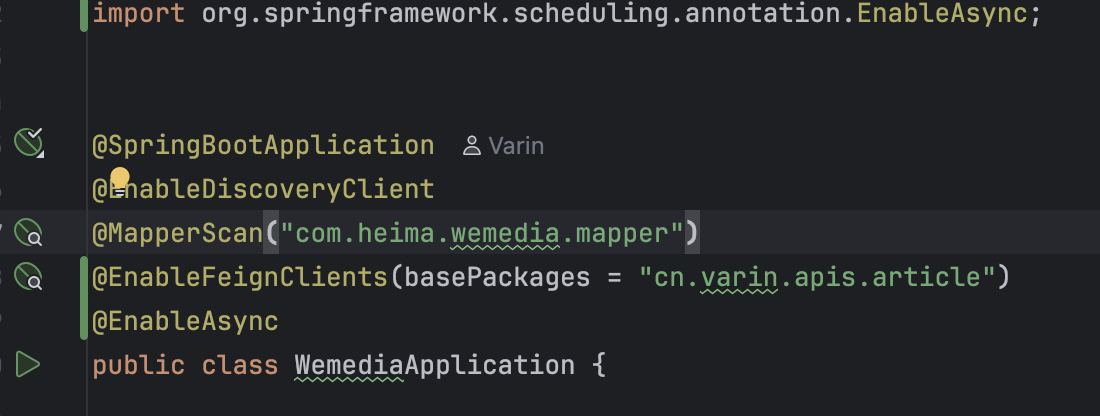
2. 在启动类中开启feign并添加扫描geign路径
package com.heima.wemedia;import com.baomidou.mybatisplus.annotation.DbType;
import com.baomidou.mybatisplus.extension.plugins.MybatisPlusInterceptor;
import com.baomidou.mybatisplus.extension.plugins.inner.PaginationInnerInterceptor;
import org.mybatis.spring.annotation.MapperScan;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.cloud.client.discovery.EnableDiscoveryClient;
import org.springframework.cloud.openfeign.EnableFeignClients;
import org.springframework.context.annotation.Bean;@SpringBootApplication
@EnableDiscoveryClient
@MapperScan("com.heima.wemedia.mapper")
@EnableFeignClients(basePackages = "cn.varin.apis.article")
public class WemediaApplication {public static void main(String[] args) {SpringApplication.run(WemediaApplication.class,args);}@Beanpublic MybatisPlusInterceptor mybatisPlusInterceptor() {MybatisPlusInterceptor interceptor = new MybatisPlusInterceptor();interceptor.addInnerInterceptor(new PaginationInnerInterceptor(DbType.MYSQL));return interceptor;}
}
审核成功后将自媒体文章添加到app端中
文件:heima-leadnews-service/heima-leadnews-wemedia/src/main/java/com/heima/wemedia/service/impl/WmNewAutoScanServiceImpl.java
方法名:saveArticle
@Autowiredprivate IArticleClient articleClient;@Autowiredprivate WmChannelMapper wmChannelMapper;@Autowiredprivate WmUserMapper wmUserMapper;// 保存app端文章private ResponseResult saveArticle(WmNews wmNews) {ArticleDto dto = new ArticleDto();// 复制属性BeanUtils.copyProperties(wmNews, dto);// 布局dto.setLayout(wmNews.getType());// 频道WmChannel wmChannel = wmChannelMapper.selectById(wmNews.getChannelId());if(wmChannel != null){dto.setChannelName(wmChannel.getName());dto.setChannelId(wmNews.getChannelId());}//作者dto.setAuthorId(wmNews.getUserId().longValue());WmUser wmUser = wmUserMapper.selectById(wmNews.getUserId());if(wmUser != null){dto.setAuthorName(wmUser.getName());}// 判断是否是已经审核过的app文章if (wmNews.getArticleId()!=null) {dto.setId(wmNews.getArticleId());}dto.setCreatedTime(new Date());ResponseResult save = articleClient.save(dto);return save;}
综合测试
- 测试类
package cn.varin;import com.heima.wemedia.WemediaApplication;
import com.heima.wemedia.service.WmNewAutoScanService;
import com.tencentcloudapi.common.exception.TencentCloudSDKException;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.junit.runner.Runner;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.test.context.junit4.SpringRunner;@SpringBootTest(classes = WemediaApplication.class)
@RunWith(SpringRunner.class)
public class handleScanTest {@Autowiredprivate WmNewAutoScanService wmNewAutoScanService;@Testpublic void wmNewAutoScanTest() {wmNewAutoScanService.AutoScanWmNews(6232);}
}
- 效果
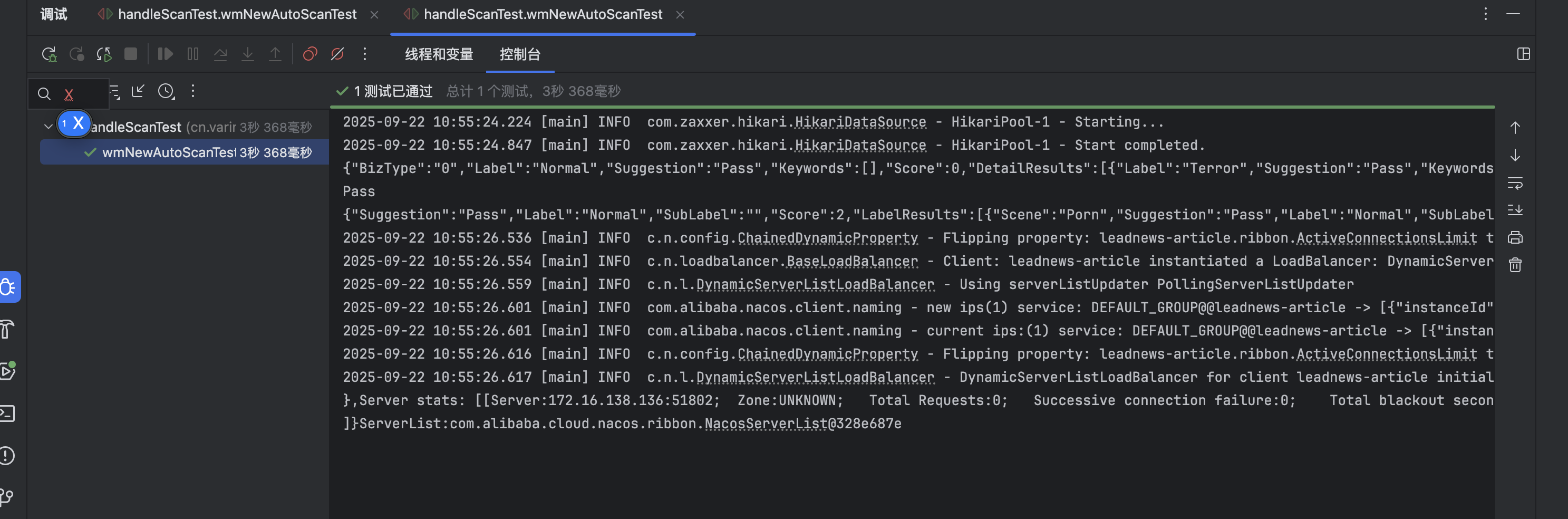
ap_article表:

wm_news表:

feign远程调用服务降级处理

具体实现
- 编写一个fallback类并实现IArticleClient接口
package cn.varin.apis.article.fallback;import cn.varin.apis.article.IArticleClient;
import com.heima.model.article.dtos.ArticleDto;
import com.heima.model.common.dtos.ResponseResult;
import com.heima.model.common.enums.AppHttpCodeEnum;
import org.springframework.stereotype.Component;import javax.xml.ws.Response;
import java.util.ResourceBundle;@Component
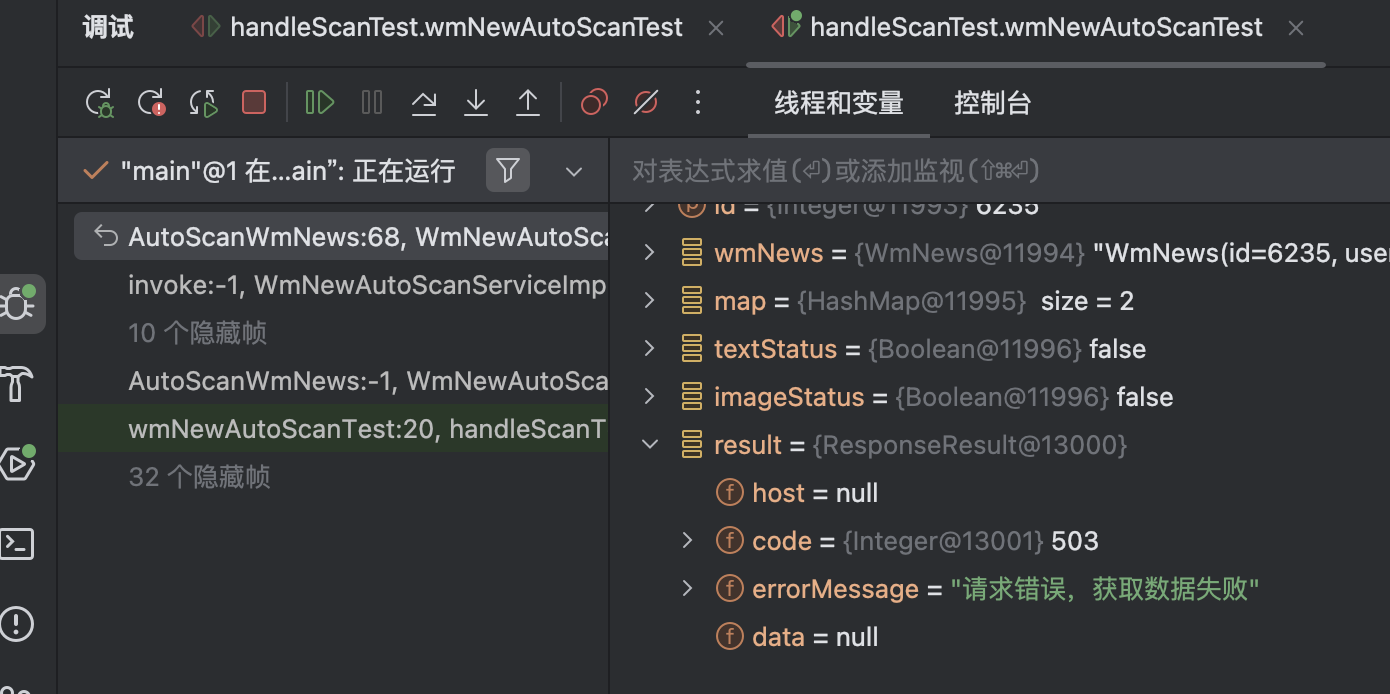
public class IArticleClientFallback implements IArticleClient {@Overridepublic ResponseResult save(ArticleDto dto) {return ResponseResult.errorResult(AppHttpCodeEnum.SERVER_ERROR,"请求错误,获取数据失败");}
}
- 载IArticleClient接口中添加fallback配置
package cn.varin.apis.article;import cn.varin.apis.article.fallback.IArticleClientFallback;
import com.heima.model.article.dtos.ArticleDto;
import com.heima.model.article.pojos.ApArticleConfig;
import com.heima.model.common.dtos.ResponseResult;
import org.springframework.cloud.openfeign.FeignClient;
import org.springframework.web.bind.annotation.PostMapping;
import org.springframework.web.bind.annotation.RequestBody;@FeignClient(value = "leadnews-article",fallback = IArticleClientFallback.class)
public interface IArticleClient {@PostMapping("/api/v1/article/save")ResponseResult save(@RequestBody ArticleDto dto);
}
- 配置applicaiton.yml
feign:# 开启feign对hystrix熔断降级的支持hystrix:enabled: true# 修改调用超时时间client:config:default:connectTimeout: 5000readTimeout: 5000
模拟
- 在调用IArticleClient中的save方法后,使用线程睡眠5秒。
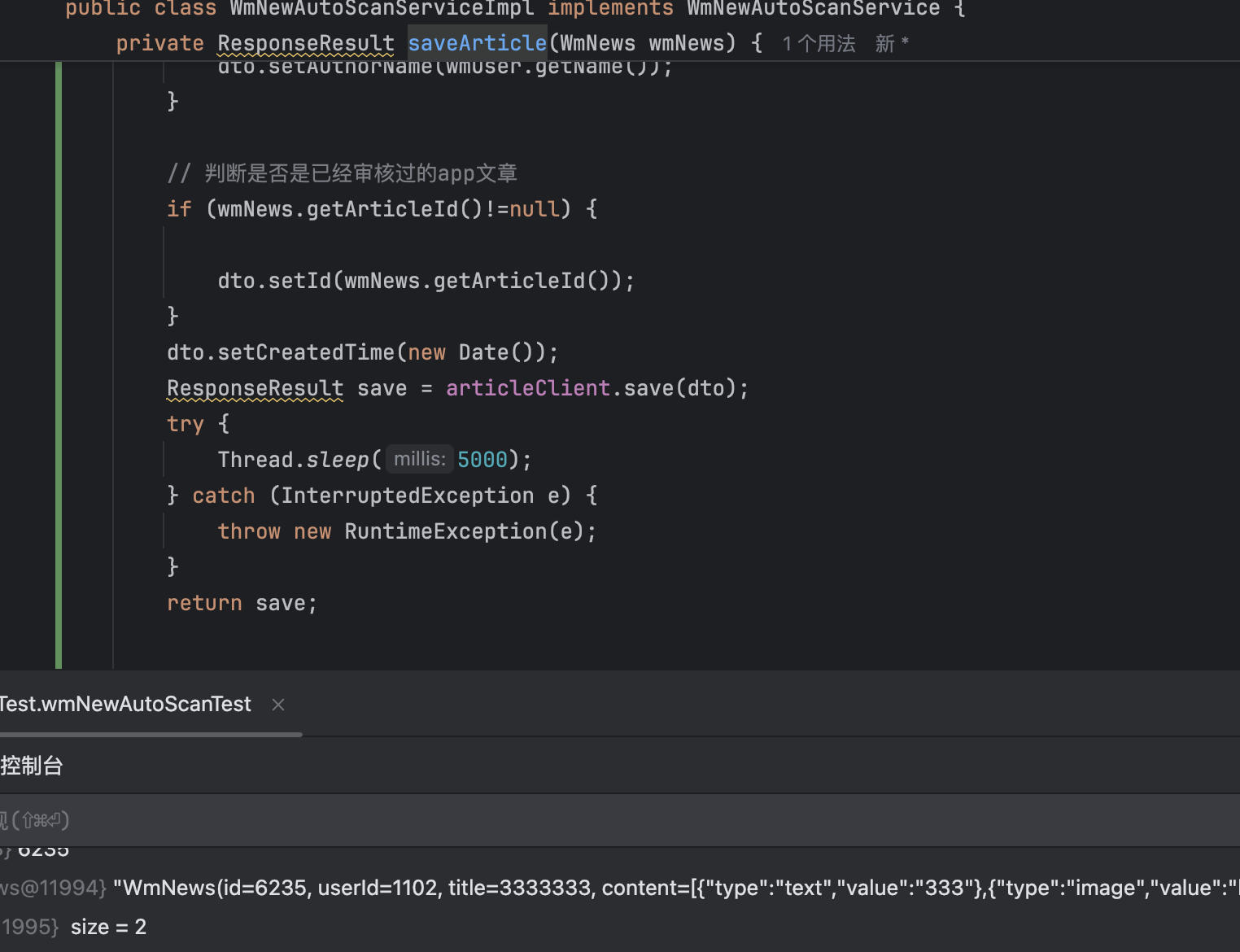
- 测试结果
异步任务审核文章
同步和异步概念
同步:就是在发出一个调用时,在没有得到结果之前,该调用就不返回(实时处理)
异步:调用在发出之后,这个调用就直接返回了,没有返回结果(分时处理)
需求
当我们在自媒体端上发布文章后,并不是一定需要直接返回文章的审核结果,而是可以等待文章发布后,一段时间后再得到结果也是可以的。
所有,根据以上需求,我们可以在文章发布后,将审核的操作该成异步的操作。
实现
- 在审核方法上田间 @ Async注解

- 在多媒体类上启动异步注解@EnableAsync
自管理敏感词集成
新需求:
- 文章审核不能过滤一些敏感词: 私人侦探、针孔摄象、信用卡提现、广告代理、代开发票、刻章办、出售答案、小额贷款…
使用技术:DFA算法
介绍:Deterministic Finite Automaton,即确定有穷自动机。
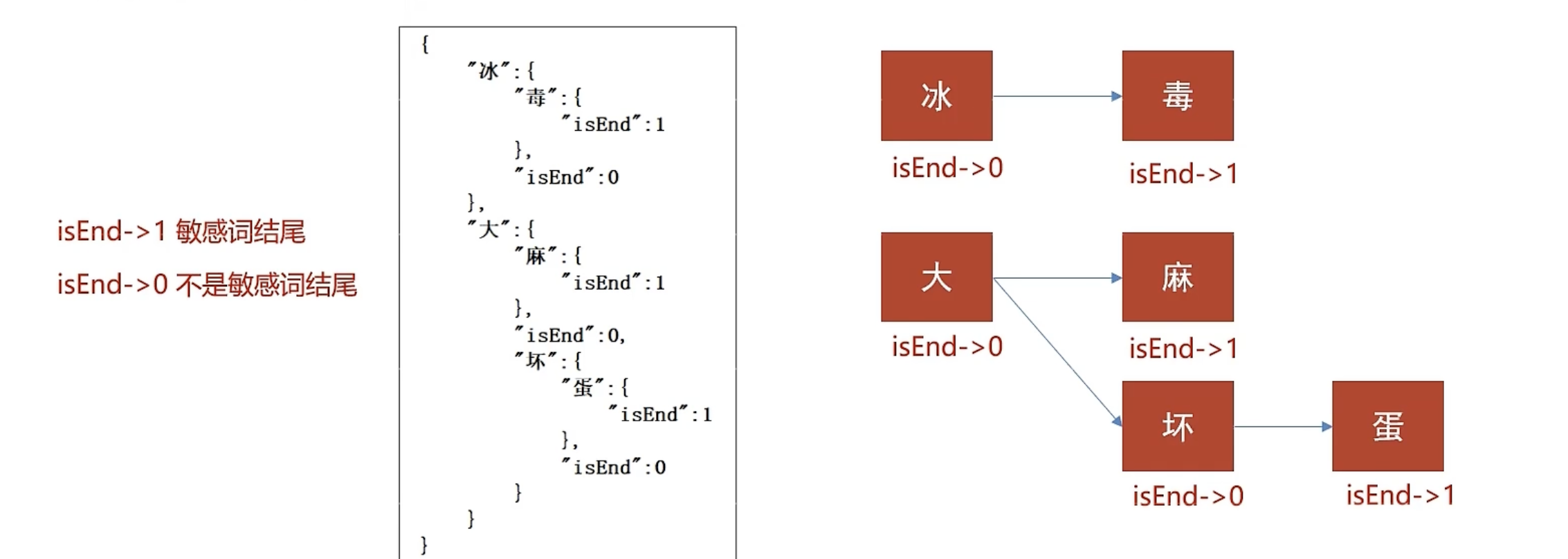
存储:一次性的把所有的敏感词存储到了多个map中,就是下图表示这种结构
敏感词:冰毒、大麻、大坏蛋
工具类和测试
package com.heima.utils.common;import java.util.*;public class SensitiveWordUtil {public static Map<String, Object> dictionaryMap = new HashMap<>();/*** 生成关键词字典库* @param words* @return*/public static void initMap(Collection<String> words) {if (words == null) {System.out.println("敏感词列表不能为空");return ;}// map初始长度words.size(),整个字典库的入口字数(小于words.size(),因为不同的词可能会有相同的首字)Map<String, Object> map = new HashMap<>(words.size());// 遍历过程中当前层次的数据Map<String, Object> curMap = null;Iterator<String> iterator = words.iterator();while (iterator.hasNext()) {String word = iterator.next();curMap = map;int len = word.length();for (int i =0; i < len; i++) {// 遍历每个词的字String key = String.valueOf(word.charAt(i));// 当前字在当前层是否存在, 不存在则新建, 当前层数据指向下一个节点, 继续判断是否存在数据Map<String, Object> wordMap = (Map<String, Object>) curMap.get(key);if (wordMap == null) {// 每个节点存在两个数据: 下一个节点和isEnd(是否结束标志)wordMap = new HashMap<>(2);wordMap.put("isEnd", "0");curMap.put(key, wordMap);}curMap = wordMap;// 如果当前字是词的最后一个字,则将isEnd标志置1if (i == len -1) {curMap.put("isEnd", "1");}}}dictionaryMap = map;}/*** 搜索文本中某个文字是否匹配关键词* @param text* @param beginIndex* @return*/private static int checkWord(String text, int beginIndex) {if (dictionaryMap == null) {throw new RuntimeException("字典不能为空");}boolean isEnd = false;int wordLength = 0;Map<String, Object> curMap = dictionaryMap;int len = text.length();// 从文本的第beginIndex开始匹配for (int i = beginIndex; i < len; i++) {String key = String.valueOf(text.charAt(i));// 获取当前key的下一个节点curMap = (Map<String, Object>) curMap.get(key);if (curMap == null) {break;} else {wordLength ++;if ("1".equals(curMap.get("isEnd"))) {isEnd = true;}}}if (!isEnd) {wordLength = 0;}return wordLength;}/*** 获取匹配的关键词和命中次数* @param text* @return*/public static Map<String, Integer> matchWords(String text) {Map<String, Integer> wordMap = new HashMap<>();int len = text.length();for (int i = 0; i < len; i++) {int wordLength = checkWord(text, i);if (wordLength > 0) {String word = text.substring(i, i + wordLength);// 添加关键词匹配次数if (wordMap.containsKey(word)) {wordMap.put(word, wordMap.get(word) + 1);} else {wordMap.put(word, 1);}i += wordLength - 1;}}return wordMap;}}
// 测试
public static void main(String[] args) {List<String> list = new ArrayList<>();list.add("法轮");list.add("法轮功");list.add("冰毒");initMap(list);String content="我是一个好人,并不会卖冰毒,也不操练法轮功,我真的不卖冰毒";Map<String, Integer> map = matchWords(content);System.out.println(map);}�
集成到文章审核中
- 倒入数据库表
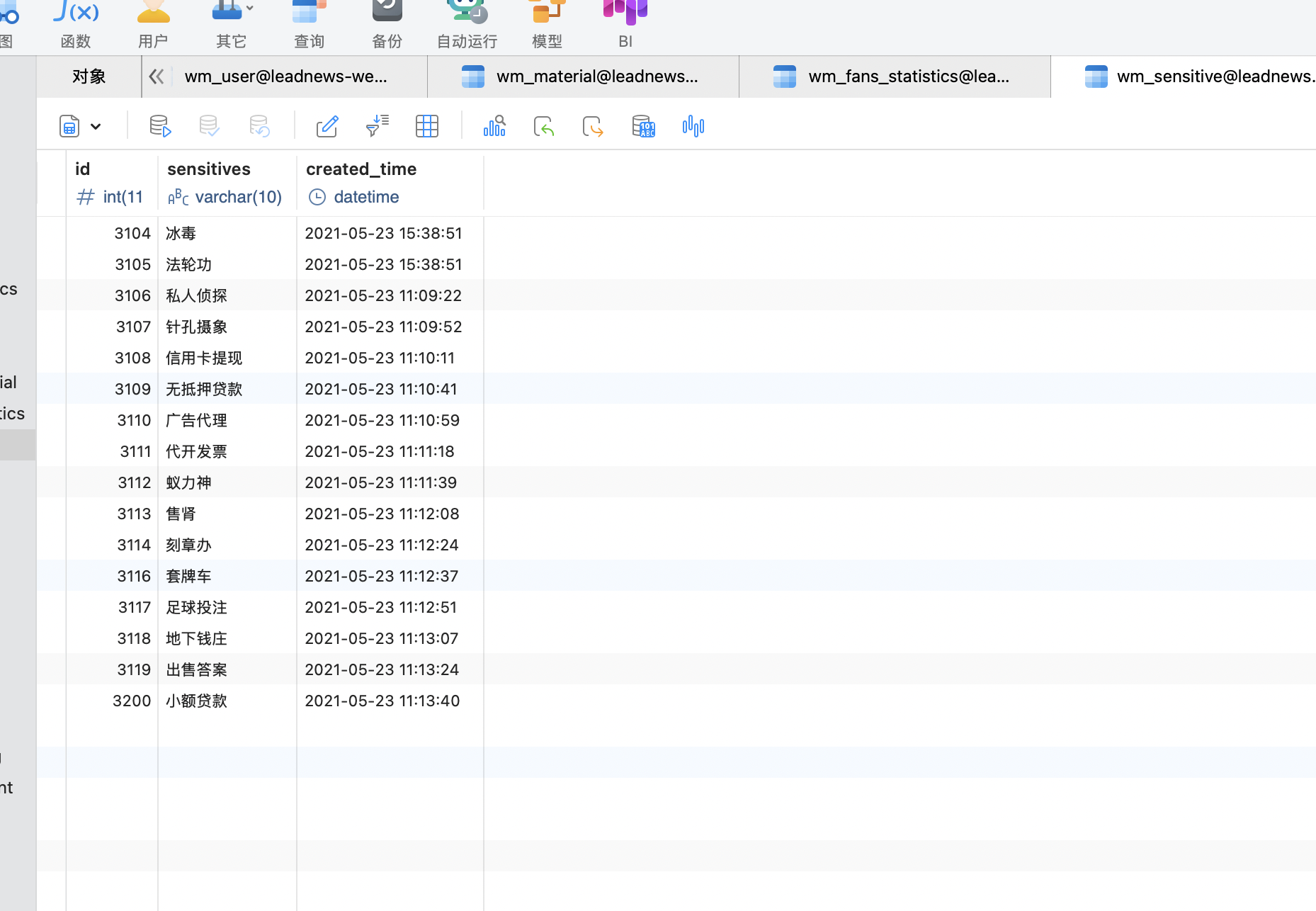
- 编写mapper
package com.heima.wemedia.mapper;import com.baomidou.mybatisplus.core.mapper.BaseMapper;
import com.heima.model.wemedia.pojos.WmSensitive;
import org.apache.ibatis.annotations.Mapper;
// 自管理敏感词
@Mapper
public interface WmSensitiveMapper extends BaseMapper<WmSensitive> {
}
- 在使用腾讯云文本内容安全服务前调用自管理的敏感词库
@Autowiredprivate WmSensitiveMapper wmSensitiveMapper;private Boolean handleSensitiveScan(Map<String, Object> map, WmNews wmNews) {Boolean flag = false;String content =map.get("text").toString();List<WmSensitive> wmSensitives = wmSensitiveMapper.selectList(Wrappers.<WmSensitive>lambdaQuery().select(WmSensitive::getSensitives));List<String> collect = wmSensitives.stream().map(WmSensitive::getSensitives).collect(Collectors.toList());SensitiveWordUtil.initMap(collect);Map<String, Integer> stringIntegerMap = SensitiveWordUtil.matchWords(content);if (stringIntegerMap.size() > 0) {flag=true;updataWmnews(wmNews,WmNews.Status.FAIL.getCode(),"文章出现违规信息,审核失败:"+stringIntegerMap.toString());}
- 结果:

图片识别文字审核敏感词
需求:
- 文章中包含的图片要识别文字,过滤掉图片文字的敏感词
- 导入依赖
<dependency><groupId>net.sourceforge.tess4j</groupId><artifactId>tess4j</artifactId><version>4.1.1</version></dependency>- 测试文件
package cn.varin.test4j.test;import cn.varin.test.Test4jApplication;
import net.sourceforge.tess4j.Tesseract;
import net.sourceforge.tess4j.TesseractException;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.test.context.junit4.SpringRunner;import java.io.*;@SpringBootTest(classes = Test4jApplication.class)
@RunWith(SpringRunner.class)public class Test4jTest {@Testpublic void test(){// 1.获取图片File file = new File("src/main/resources/images/ImageScanText.jpg");// 2.创建test4j对象Tesseract tesseract = new Tesseract();//设置字库路径tesseract.setDatapath("src/main/resources/tessdata");// 设置为识别中文tesseract.setLanguage("chi_sim");//执行ocrString s = null;try {s = tesseract.doOCR(file);System.out.println(s);} catch (TesseractException e) {throw new RuntimeException(e);}}
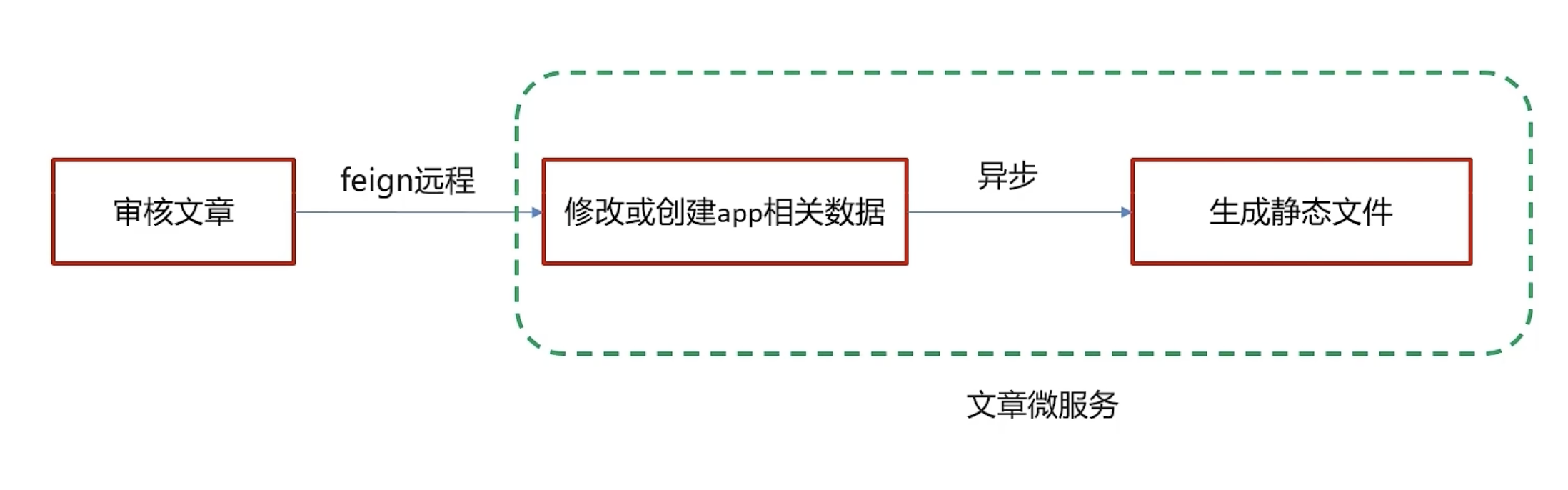
}异步调用freemarker生成html并存储Minio
-
涉及模块 heima-leadnews-article
-
流程
- service
package com.heima.article.service;import com.heima.model.article.pojos.ApArticle;public interface ArticleFreemarkerService {void buildArticletoMinIO(ApArticle article, String content);
}
- serivceImpl
package com.heima.article.service.impl;import com.alibaba.fastjson.JSONArray;
import com.baomidou.mybatisplus.core.toolkit.StringUtils;
import com.baomidou.mybatisplus.core.toolkit.Wrappers;
import com.heima.article.mapper.ApArticleContentMapper;
import com.heima.article.mapper.ApArticleMapper;
import com.heima.file.service.FileStorageService;
import com.heima.model.article.pojos.ApArticle;
import com.heima.model.article.pojos.ApArticleContent;
import freemarker.template.Configuration;
import freemarker.template.Template;
import lombok.Synchronized;
import lombok.extern.slf4j.Slf4j;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.scheduling.annotation.Async;
import org.springframework.stereotype.Service;
import org.springframework.transaction.annotation.Transactional;import java.io.ByteArrayInputStream;
import java.io.IOException;
import java.io.InputStream;
import java.io.StringWriter;
import java.util.HashMap;
import java.util.Map;@Service
@Transactional
@Slf4j
public class ArticleFreemarkerServiceImpl implements com.heima.article.service.ArticleFreemarkerService {@AutowiredConfiguration configurable;@AutowiredFileStorageService fileStorageService;@Autowiredprivate ApArticleMapper apArticleMapper;@Override@Asyncpublic void buildArticletoMinIO(ApArticle article, String content) {// 第一步:获取到文章内容//判断是否有内容if ( StringUtils.isNotBlank(content)) {// 生成html文件Template template = null;StringWriter stringWriter = new StringWriter();try {template = configurable.getTemplate("article.ftl");Map<String, Object> map = new HashMap<>();map.put("content", JSONArray.parseArray(content));template.process(map,stringWriter);} catch (Exception e) {throw new RuntimeException(e);}// 上传InputStream byteArrayInputStream = new ByteArrayInputStream(stringWriter.toString().getBytes());String static_url = fileStorageService.uploadHtmlFile("", article.getId()+ ".html", byteArrayInputStream);System.out.println(static_url);// 修改 article表ApArticle apArticle = new ApArticle();apArticle.setId(article.getId());apArticle.setStaticUrl(static_url);apArticleMapper.updateById(apArticle);}}
}
- 开启异步
package com.heima.article;import com.baomidou.mybatisplus.annotation.DbType;
import com.baomidou.mybatisplus.extension.plugins.MybatisPlusInterceptor;
import com.baomidou.mybatisplus.extension.plugins.inner.PaginationInnerInterceptor;
import org.mybatis.spring.annotation.MapperScan;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.cloud.client.discovery.EnableDiscoveryClient;
import org.springframework.context.annotation.Bean;
import org.springframework.scheduling.annotation.EnableAsync;@SpringBootApplication
@EnableDiscoveryClient
@MapperScan("com.heima.article.mapper")
@EnableAsync
public class ArticleApplication {public static void main(String[] args) {SpringApplication.run(ArticleApplication.class,args);}@Beanpublic MybatisPlusInterceptor mybatisPlusInterceptor() {MybatisPlusInterceptor interceptor = new MybatisPlusInterceptor();interceptor.addInnerInterceptor(new PaginationInnerInterceptor(DbType.MYSQL));return interceptor;}
}
- 效果:

今天也是加油的一天呀。⛽️