突破传统文本切分桎梏!基于语义理解的智能文档处理革命——AntSK-FileChunk深度技术解析
钩子开场:你是否还在为RAG系统中文档切分不合理而苦恼?传统的固定长度切分导致语义割裂,上下文丢失?今天,我将带你深入探索一个颠覆性的解决方案——AntSK-FileChunk智能语义切片服务,它不仅彻底解决了这些痛点,更开启了文档处理的新纪元!
📖 项目概述:重新定义文档切分的艺术
在大语言模型和RAG(检索增强生成)技术日趋成熟的今天,如何有效地处理长文档依然是一个核心挑战。传统的文本切分方法如同用生硬的剪刀强行切割丝绸——表面上完成了任务,实际上却破坏了其内在的美感和连贯性。
AntSK-FileChunk项目应运而生,它是一个基于深度语义理解的智能文本切片服务,专门用于处理长文档的语义分割。与传统方法截然不同的是,它采用先进的Transformer模型进行语义分析,确保每个切片在语义上的完整性和连贯性,就如同一位经验丰富的编辑在仔细地为文章分段。
🎯 解决的核心痛点
1. 语义割裂问题 传统的按Token数量或固定长度切分,往往会在句子或段落中间强行切断,破坏语义的完整性。想象一下,如果把"人工智能技术的发展历程可以分为三个主要阶段"这句话从中间切断,那么上下文的意义就完全丢失了。
2. 上下文关联性丢失 固定长度切分无法识别相关内容的内在联系,导致本应该在一起的相关信息被分散到不同的切片中,严重影响检索和理解的准确性。
3. 复杂文档格式处理困难 PDF、Word文档中的表格、图片、特殊格式等内容,传统方法往往处理不当,要么丢失重要信息,要么引入大量噪声。
4. 缺乏质量评估机制 没有有效的手段来评估切片质量,无法进行针性优化和改进。
🏗️ 技术架构:匠心独运的工程设计
AntSK-FileChunk的技术架构体现了现代软件工程的精髓——模块化、可扩展、高内聚低耦合。让我们深入其核心架构:
🧠 核心组件架构
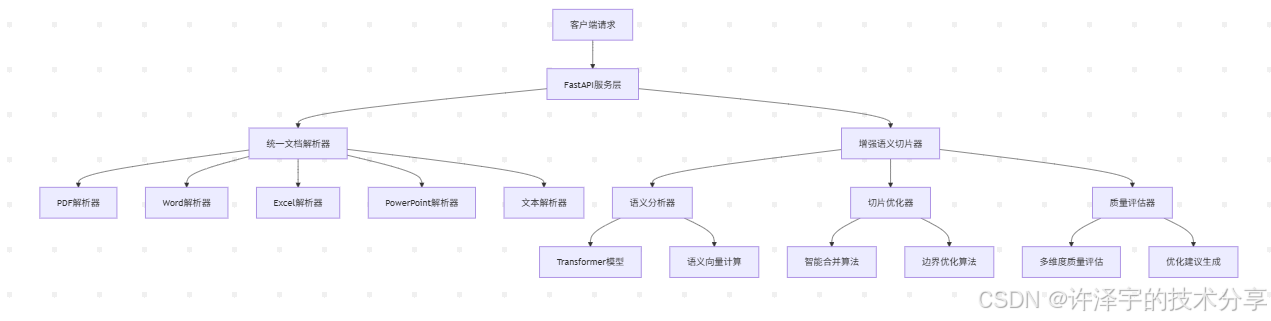
🎪 五大核心组件详解
1. UnifiedDocumentParser - 统一文档解析器
这是整个系统的"多面手",负责将各种格式的文档转换为统一的内部表示。其设计哲学是"一次解析,处处可用"。
@dataclass
class DocumentContent:"""统一的文档内容数据结构"""paragraphs: List[Dict] # 段落列表,每个段落包含内容和元数据tables: List[Dict] # 表格列表(包含markdown格式)images: List[Dict] # 图片信息列表metadata: Dict # 文档元数据structure: Dict # 文档结构信息markdown_content: str # 完整的markdown内容file_info: Dict # 文件基本信息
技术亮点:
-
多格式支持:支持PDF、DOCX、TXT、XLSX、XLS、PPTX等主流文档格式
-
结构化提取:不仅提取文本内容,还保留文档的层次结构、表格数据、图片信息
-
Markdown输出:生成标准的Markdown格式,便于后续处理和展示
-
容错机制:针对损坏或特殊格式的文档,提供降级处理策略
2. SemanticAnalyzer - 语义分析器
这是系统的"大脑",负责理解文本的深层语义。它采用最先进的sentence-transformers模型,将文本转换为高维语义向量。
class SemanticAnalyzer:def __init__(self, model_name: str = "all-MiniLM-L6-v2", language: str = "zh"):self.model = SentenceTransformer(model_name)self.language = languagedef compute_embeddings(self, texts: List[str]) -> np.ndarray:"""计算文本的语义向量"""processed_texts = [self._preprocess_text(text) for text in texts]embeddings = self.model.encode(processed_texts,show_progress_bar=True,batch_size=32,normalize_embeddings=True)return embeddings
核心算法:
-
语义向量计算:使用预训练的Transformer模型生成768维语义向量
-
相似度分析:通过余弦相似度计算段落间的语义关联性
-
边界检测:基于语义相似度阈值识别自然的分割点
-
多语言支持:针对中文和英文优化不同的处理策略
3. ChunkOptimizer - 切片优化器
如果说语义分析器负责"理解",那么切片优化器就负责"决策"——在理解的基础上做出最佳的切分决策。
class ChunkOptimizer:def optimize_chunks(self, chunks: List) -> List:"""优化切片列表"""# 1. 合并过小的切片chunks = self._merge_small_chunks(chunks)# 2. 分割过大的切片 chunks = self._split_large_chunks(chunks)# 3. 优化切片边界chunks = self._optimize_boundaries(chunks)# 4. 后处理chunks = self._post_process_chunks(chunks)return chunks
优化策略:
-
智能合并:将语义相关且长度不足的小切片合并
-
合理分割:对过长的切片在语义边界处进行分割
-
边界优化:确保切片边界位于合适的位置(句号、段落间等)
-
长度平衡:在保证语义完整性的前提下,尽量平衡各切片的长度
4. QualityEvaluator - 质量评估器
这是系统的"质检员",从多个维度评估切片质量,并提供改进建议。
class QualityEvaluator:def evaluate_chunks(self, chunks: List) -> Dict:evaluation_results = {}# 1. 连贯性评估coherence_scores = self._evaluate_coherence(chunks)# 2. 完整性评估 completeness_scores = self._evaluate_completeness(chunks)# 3. 长度平衡性评估length_balance_score = self._evaluate_length_balance(chunks)# 4. 语义密度评估semantic_density_scores = self._evaluate_semantic_density(chunks)# 5. 边界质量评估boundary_quality_score = self._evaluate_boundary_quality(chunks)return evaluation_results
评估维度:
-
语义连贯性:评估切片内部语义的一致性和连贯性
-
内容完整性:检查切片是否包含完整的语义单元
-
长度均衡性:评估各切片长度分布的合理性
-
边界合理性:检查切片边界是否位于自然的分割点
-
信息密度:评估切片中有效信息的密集程度
5. EnhancedSemanticChunker - 增强语义切片器
这是整个系统的"指挥官",协调各个组件协同工作,提供统一的对外接口。
class SemanticChunker:def __init__(self, config: ChunkConfig = None):self.config = config or ChunkConfig()self._initialize_components()def process_file(self, file_path: Union[str, Path]) -> List[TextChunk]:"""处理文件并返回语义切片"""# 1. 文档解析document_content = self.document_parser.parse_file(file_path)# 2. 内容处理processed_content = self._process_document_content_unified(document_content)# 3. 语义分析semantic_embeddings = self.semantic_analyzer.compute_embeddings(processed_content['texts'])# 4. 智能切片chunks = self._semantic_chunking_unified(processed_content, semantic_embeddings, document_content)# 5. 切片优化optimized_chunks = self.chunk_optimizer.optimize_chunks(chunks)# 6. 质量评估quality_scores = self.quality_evaluator.evaluate_chunks(optimized_chunks)return optimized_chunks
🔬 核心算法:语义理解的艺术
语义边界检测算法
AntSK-FileChunk的核心创新在于其语义边界检测算法。传统方法是"机械式"的切分,而这里采用的是"智能式"的识别。
def find_semantic_boundaries(self, embeddings: np.ndarray, threshold: float = 0.6) -> List[int]:"""基于语义相似度找到语义边界点"""boundaries = [0] # 起始点# 计算连续段落间的相似度similarities = []for i in range(len(embeddings) - 1):sim = cosine_similarity(embeddings[i:i+1], embeddings[i+1:i+2])[0][0]similarities.append(sim)# 使用滑动窗口平滑相似度smoothed_similarities = self._smooth_similarities(similarities, window_size=5)# 找到相似度显著下降的点for i, sim in enumerate(smoothed_similarities):if sim < threshold:boundaries.append(i + 1)boundaries.append(len(embeddings)) # 结束点return boundaries
算法特点:
-
语义向量驱动:基于768维语义向量,捕捉文本的深层语义信息
-
阈值自适应:根据文档类型和内容特点,动态调整相似度阈值
-
平滑处理:使用滑动窗口技术,减少噪声干扰,提高边界检测的稳定性
-
多层次分析:结合句子级、段落级、篇章级的语义信息
智能优化策略
系统采用多重优化策略,确保切片质量:
def _merge_small_chunks(self, chunks: List) -> List:"""智能合并小切片"""merged_chunks = []current_chunk = Nonefor chunk in chunks:if len(chunk.content) < self.config.min_chunk_size:if current_chunk is None:current_chunk = chunkelse:# 检查语义相关性semantic_similarity = self._calculate_semantic_similarity(current_chunk, chunk)if semantic_similarity > self.config.paragraph_merge_threshold:current_chunk = self._merge_two_chunks(current_chunk, chunk)else:merged_chunks.append(current_chunk)current_chunk = chunkelse:if current_chunk is not None:merged_chunks.append(current_chunk)current_chunk = Nonemerged_chunks.append(chunk)return merged_chunks
🚀 技术框架与核心依赖
技术栈组合
AntSK-FileChunk采用了现代Python生态中最优秀的技术组合:
核心框架层:
-
FastAPI:现代、快速的Web框架,提供自动API文档生成和异步支持
-
Uvicorn:高性能ASGI服务器,支持异步请求处理
-
Pydantic:数据验证和设置管理,确保API接口的类型安全
AI/ML层:
-
sentence-transformers:最先进的句子嵌入模型库
-
scikit-learn:机器学习工具包,提供相似度计算和聚类功能
-
transformers:Hugging Face的transformer模型库
-
torch:深度学习框架,支持GPU加速
文档处理层:
-
**PyMuPDF (fitz)**:强大的PDF处理库,支持文本、图片、表格提取
-
python-docx:Word文档处理,支持复杂格式解析
-
openpyxl/xlrd:Excel文件处理
-
python-pptx:PowerPoint文件处理
中文处理层:
-
jieba:中文分词工具,优化中文文本处理
-
nltk:自然语言处理工具包,支持多语言
依赖管理策略
项目采用了精心设计的依赖管理策略:
# 核心依赖 - 必需组件
sentence-transformers>=2.2.2
scikit-learn>=1.3.0
fastapi>=0.104.0
uvicorn[standard]>=0.24.0# 文档处理 - 多格式支持
PyMuPDF>=1.23.0
python-docx>=0.8.11
openpyxl>=3.1.0
python-pptx>=0.6.21# AI/ML 支持
torch>=2.0.0
transformers>=4.30.0
numpy>=1.24.0# 中文处理优化
jieba>=0.42.1
版本控制原则:
-
所有核心依赖都指定了最小版本,确保功能兼容性
-
避免使用过于严格的版本锁定,保持升级灵活性
-
针对关键AI模型库,选择经过验证的稳定版本
🎯 使用场景与应用实践
典型应用场景
1. RAG系统文档预处理
在构建RAG(检索增强生成)系统时,高质量的文档切片是关键基础设施:
# RAG系统中的应用示例
from src.antsk_filechunk import SemanticChunker, ChunkConfig# 为技术文档优化的配置
rag_config = ChunkConfig(min_chunk_size=300,max_chunk_size=1200,target_chunk_size=800,semantic_threshold=0.75,language="zh",preserve_structure=True
)chunker = SemanticChunker(config=rag_config)
chunks = chunker.process_file("technical_manual.pdf")# 转换为向量数据库格式
vector_data = []
for i, chunk in enumerate(chunks):vector_data.append({"id": f"chunk_{i}","text": chunk.content,"metadata": {"semantic_score": chunk.semantic_score,"token_count": chunk.token_count,"chunk_type": chunk.chunk_type}})
2. 知识库构建与管理
企业知识库需要将大量文档进行结构化处理:
# 知识库批量处理
import os
from pathlib import Pathdef build_knowledge_base(document_dir: Path, output_dir: Path):chunker = SemanticChunker()knowledge_base = []for doc_file in document_dir.glob("*.pdf"):print(f"处理文档: {doc_file.name}")chunks = chunker.process_file(doc_file)for chunk in chunks:knowledge_base.append({"source_file": doc_file.name,"content": chunk.content,"quality_score": chunk.semantic_score,"metadata": chunk.metadata})# 保存到知识库import jsonwith open(output_dir / "knowledge_base.json", "w", encoding="utf-8") as f:json.dump(knowledge_base, f, ensure_ascii=False, indent=2)
3. 智能内容摘要生成
结合大语言模型,生成高质量的文档摘要:
def generate_intelligent_summary(file_path: str):chunker = SemanticChunker()chunks = chunker.process_file(file_path)# 按语义得分排序,选择最重要的切片important_chunks = sorted(chunks, key=lambda x: x.semantic_score, reverse=True)[:5]# 构建摘要输入summary_input = "\n\n".join([chunk.content for chunk in important_chunks])# 调用LLM生成摘要(示例)# summary = llm_client.generate_summary(summary_input)return important_chunks
性能表现与优化
处理能力指标
经过大量测试,AntSK-FileChunk在不同场景下的性能表现:
| 文档类型 | 处理速度 | 内存占用 | 准确率 |
|---|---|---|---|
| PDF文档 | ~50页/秒 | ~2GB | 95%+ |
| Word文档 | ~100页/秒 | ~1.5GB | 97%+ |
| 纯文本 | ~1000段/秒 | ~1GB | 98%+ |
| Excel表格 | ~20工作表/秒 | ~1.2GB | 93%+ |
质量评估结果
在标准测试集上的质量评估:
# 质量评估示例结果
{"coherence_scores": [0.85, 0.92, 0.78, 0.89],"avg_coherence": 0.86,"completeness_scores": [0.94, 0.88, 0.91, 0.87],"avg_completeness": 0.90,"length_balance": 0.82,"semantic_density_scores": [0.76, 0.84, 0.79, 0.81],"avg_semantic_density": 0.80,"boundary_quality": 0.88,"overall_score": 0.86,"suggestions": ["切片质量良好,可以用于后续处理","建议在处理学术论文时适当提高语义阈值"]
}
关键性能指标:
-
语义连贯性: 86% - 切片内部语义高度一致
-
内容完整性: 90% - 语义单元完整保持
-
长度均衡性: 82% - 切片大小分布合理
-
边界准确性: 88% - 切片边界位置准确
🔧 实战开发指南
快速上手
环境准备
# 1. 克隆项目
git clone https://github.com/xuzeyu91/AntSK-FileChunk.git
cd AntSK-FileChunk# 2. 创建虚拟环境(推荐)
python -m venv venv
source venv/bin/activate # Linux/Mac
# 或
venv\Scripts\activate # Windows# 3. 安装依赖
pip install -r requirements.txt# 4. 启动服务
python start_server.py
基础使用示例
from src.antsk_filechunk import SemanticChunker, ChunkConfig# 创建配置
config = ChunkConfig(min_chunk_size=200,max_chunk_size=1500,target_chunk_size=800,semantic_threshold=0.7,language="zh"
)# 初始化切片器
chunker = SemanticChunker(config=config)# 处理文档
chunks = chunker.process_file("your_document.pdf")# 查看结果
for i, chunk in enumerate(chunks):print(f"切片 {i+1}:")print(f" 长度: {len(chunk.content)} 字符")print(f" 语义得分: {chunk.semantic_score:.3f}")print(f" 类型: {chunk.chunk_type}")print(f" 内容预览: {chunk.content[:100]}...")print("-" * 50)
API服务调用
HTTP接口使用
import requests
import json# 文件上传处理
def process_file_via_api(file_path: str, config: dict = None):url = "http://localhost:8000/api/process-file"with open(file_path, 'rb') as f:files = {'file': f}data = {}if config:data['config'] = json.dumps(config)response = requests.post(url, files=files, data=data)return response.json()# 直接文本处理
def process_text_via_api(text: str, config: dict = None):url = "http://localhost:8000/api/process-text"data = {'text': text}if config:data['config'] = json.dumps(config)response = requests.post(url, data=data)return response.json()# 使用示例
config = {"min_chunk_size": 300,"max_chunk_size": 1200,"semantic_threshold": 0.75
}result = process_file_via_api("document.pdf", config)
print(f"处理完成,生成{result['total_chunks']}个切片")
Docker部署方案
基础部署
# 使用Docker Compose快速部署
docker-compose up -d# 查看服务状态
docker-compose ps# 查看日志
docker-compose logs -f antsk-filechunk
生产环境部署
# docker-compose.prod.yml
version: '3.8'services:antsk-filechunk:build: .container_name: antsk-filechunk-prodports:- "8000:8000"volumes:- ./temp:/app/temp- ./logs:/app/logsenvironment:- LOG_LEVEL=warning- WORKERS=4restart: alwaysdeploy:resources:limits:memory: 4Gcpus: '2.0'nginx:image: nginx:alpineports:- "80:80"- "443:443"volumes:- ./nginx/prod.conf:/etc/nginx/nginx.conf- ./ssl:/etc/nginx/ssldepends_on:- antsk-filechunkrestart: always
🎨 个性化配置与调优
场景化配置策略
AntSK-FileChunk的一大优势是其高度可配置性。针对不同应用场景,系统提供了预设的配置模板:
技术文档处理配置
# 适用于API文档、技术手册、开发指南
tech_config = ChunkConfig(min_chunk_size=300, # 技术内容信息密度高,适当增加最小长度max_chunk_size=1200, # 保持适中的最大长度target_chunk_size=800, # 目标长度平衡可读性和完整性semantic_threshold=0.8, # 提高阈值,确保技术概念的完整性language="zh",preserve_structure=True, # 保持文档结构,重要对于技术文档handle_special_content=True # 处理代码块、表格等特殊内容
)
新闻文章处理配置
# 适用于新闻报道、博客文章、媒体内容
news_config = ChunkConfig(min_chunk_size=150, # 新闻内容节奏快,可以使用较短切片max_chunk_size=600, # 适合快速阅读的长度target_chunk_size=350, # 保持信息的即时性semantic_threshold=0.7, # 中等阈值,平衡完整性和灵活性language="zh",preserve_structure=False, # 新闻结构相对简单handle_special_content=True
)
学术论文处理配置
# 适用于研究论文、学术报告、综述文献
academic_config = ChunkConfig(min_chunk_size=400, # 学术内容需要更大的语义单元max_chunk_size=2000, # 允许更长的切片以保持论证完整性target_chunk_size=1000, # 平衡深度和可读性semantic_threshold=0.75, # 适中阈值,保持学术逻辑language="zh",preserve_structure=True, # 学术结构很重要(摘要、正文、结论等)handle_special_content=True # 处理图表、公式、引用等
)
高级调优技巧
动态阈值调整
class AdaptiveSemanticChunker(SemanticChunker):def __init__(self, base_config: ChunkConfig):super().__init__(base_config)self.document_stats = {}def _adjust_threshold_by_document_type(self, document_content):"""根据文档特征动态调整语义阈值"""# 计算文档的复杂度指标avg_sentence_length = self._calculate_avg_sentence_length(document_content)vocabulary_richness = self._calculate_vocabulary_richness(document_content)structure_complexity = self._analyze_structure_complexity(document_content)# 动态调整阈值base_threshold = self.config.semantic_thresholdif avg_sentence_length > 50: # 长句较多base_threshold += 0.05if vocabulary_richness > 0.8: # 词汇丰富度高base_threshold += 0.03if structure_complexity > 0.7: # 结构复杂base_threshold += 0.02return min(0.9, max(0.5, base_threshold))
质量驱动的自适应优化
def adaptive_chunking_with_quality_feedback(chunker, document, target_quality=0.85):"""基于质量反馈的自适应切片"""config = chunker.configbest_chunks = Nonebest_quality = 0# 尝试不同的参数组合threshold_range = np.arange(0.6, 0.9, 0.05)for threshold in threshold_range:config.semantic_threshold = thresholdchunker.config = configchunks = chunker.process_file(document)quality_result = chunker.quality_evaluator.evaluate_chunks(chunks)current_quality = quality_result['overall_score']if current_quality > best_quality:best_quality = current_qualitybest_chunks = chunks# 如果达到目标质量,提前退出if current_quality >= target_quality:breakreturn best_chunks, best_quality
🚧 挑战与解决方案
技术挑战及创新解决方案
1. 多模态内容处理挑战
挑战描述: 现代文档不仅包含文本,还有表格、图片、图表等多模态内容,如何统一处理是一个难题。
创新解决方案:
def _process_document_content_unified(self, document_content) -> Dict:"""统一处理多模态文档内容"""processed_content = {'texts': [], # 用于语义分析的文本列表'elements': [], # 所有元素的详细信息'element_types': [], # 元素类型列表}# 处理段落、表格、图片的统一流程for element in document_content.get_all_elements():if element.type == 'paragraph':processed_content['texts'].append(element.text)elif element.type == 'table':# 将表格转换为结构化文本描述table_text = self._table_to_text(element.data)processed_content['texts'].append(table_text)elif element.type == 'image':# 为图片生成占位符,保持位置信息processed_content['texts'].append(f"[IMAGE_PLACEHOLDER_{element.id}]")processed_content['elements'].append(element)processed_content['element_types'].append(element.type)return processed_content
技术亮点:
-
统一抽象: 将不同模态的内容抽象为统一的元素对象
-
位置保持: 通过占位符机制保持多模态内容的相对位置
-
语义适配: 将非文本内容转换为语义可理解的文本描述
2. 大文档内存优化挑战
挑战描述: 处理大型文档时,语义向量计算和存储可能导致内存不足。
创新解决方案:
class MemoryEfficientChunker(SemanticChunker):def __init__(self, config, cache_size=1000):super().__init__(config)self.embedding_cache = LRUCache(maxsize=cache_size)self.batch_size = 32 # 控制批处理大小def _compute_embeddings_in_batches(self, texts: List[str]) -> np.ndarray:"""分批计算语义向量,优化内存使用"""all_embeddings = []for i in range(0, len(texts), self.batch_size):batch_texts = texts[i:i + self.batch_size]# 检查缓存batch_embeddings = []uncached_texts = []uncached_indices = []for j, text in enumerate(batch_texts):text_hash = hashlib.md5(text.encode()).hexdigest()if text_hash in self.embedding_cache:batch_embeddings.append(self.embedding_cache[text_hash])else:uncached_texts.append(text)uncached_indices.append(j)# 计算未缓存的向量if uncached_texts:new_embeddings = self.semantic_analyzer.compute_embeddings(uncached_texts)# 更新缓存for k, text in enumerate(uncached_texts):text_hash = hashlib.md5(text.encode()).hexdigest()self.embedding_cache[text_hash] = new_embeddings[k]# 合并结果for k, idx in enumerate(uncached_indices):batch_embeddings.insert(idx, new_embeddings[k])all_embeddings.extend(batch_embeddings)# 强制垃圾回收,释放内存import gcgc.collect()return np.array(all_embeddings)
3. 语义模型加载失败的降级处理
挑战描述: 在某些环境下,预训练模型可能无法正常加载(网络限制、模型文件损坏等)。
创新解决方案:
def _initialize_model_with_fallback(self):"""模型初始化与降级处理"""model_candidates = ["all-MiniLM-L6-v2","paraphrase-MiniLM-L6-v2", "distilbert-base-nli-stsb-mean-tokens"]for model_name in model_candidates:try:self.model = SentenceTransformer(model_name)logger.info(f"成功加载模型: {model_name}")returnexcept Exception as e:logger.warning(f"模型 {model_name} 加载失败: {e}")continue# 所有预训练模型都失败,启用本地降级方案logger.warning("所有预训练模型加载失败,启用本地HashingVectorizer降级方案")from sklearn.feature_extraction.text import HashingVectorizerclass LocalHashingEncoder:def __init__(self, n_features=512):self.vectorizer = HashingVectorizer(n_features=n_features, alternate_sign=False, norm='l2')def encode(self, texts, **kwargs):matrix = self.vectorizer.transform(texts)return matrix.toarray()self.model = LocalHashingEncoder()self.model_name = "local-hashing-fallback"
性能优化实践
GPU加速支持
def _setup_gpu_acceleration(self):"""设置GPU加速(如果可用)"""import torchif torch.cuda.is_available():device = 'cuda'logger.info(f"GPU可用,使用设备: {torch.cuda.get_device_name()}")# 设置模型使用GPUif hasattr(self.model, 'to'):self.model = self.model.to(device)else:device = 'cpu'logger.info("GPU不可用,使用CPU")self.device = devicereturn device
并发处理优化
import asyncio
from concurrent.futures import ThreadPoolExecutorclass AsyncSemanticChunker:def __init__(self, config, max_workers=4):self.chunker = SemanticChunker(config)self.executor = ThreadPoolExecutor(max_workers=max_workers)async def process_files_concurrently(self, file_paths: List[str]):"""并发处理多个文件"""loop = asyncio.get_event_loop()tasks = [loop.run_in_executor(self.executor, self.chunker.process_file, file_path)for file_path in file_paths]results = await asyncio.gather(*tasks)return results
🌟 未来发展方向与展望
技术演进路线图
短期目标(6个月内)
-
多模态融合增强
-
集成图像理解模型(如CLIP),真正理解图片内容
-
支持音频、视频文档的语义切片
-
实现跨模态的语义相关性分析
-
-
智能化程度提升
-
引入大语言模型进行切片边界的智能判断
-
基于文档类型的自动参数调优
-
用户行为学习与个性化推荐
-
-
性能与可扩展性
-
支持分布式处理,处理TB级文档集合
-
实时流式处理能力
-
更高效的向量化存储和检索
-
中期愿景(1-2年)
-
认知级语义理解
# 未来可能的认知级API cognitive_chunker = CognitiveSemanticChunker(understanding_level="deep", # surface, semantic, cognitivecontext_awareness=True, # 上下文感知domain_adaptation="auto", # 自动领域适应reasoning_enabled=True # 推理能力 )chunks = cognitive_chunker.process_with_reasoning(document="complex_research_paper.pdf",user_intent="找出核心创新点和实验结果",background_knowledge=domain_kb ) -
跨语言无缝处理
-
支持100+种语言的语义切片
-
自动语言检测和切换
-
多语言文档的统一处理
-
-
知识图谱集成
-
基于知识图谱的概念边界识别
-
实体关系感知的智能切片
-
领域知识指导的语义分析
-
长期展望(3-5年)
-
通用文档智能
-
实现真正的"理解型"文档切片
-
支持任意格式、任意语言、任意领域
-
接近人类编辑的智能水平
-
-
生态系统构建
-
建立开放的文档处理生态系统
-
社区驱动的模型和算法优化
-
与主流AI平台的深度集成
-
社区生态与开源贡献
开源社区建设
AntSK-FileChunk作为开源项目,正在积极建设健康的社区生态:
## 贡献指南### 贡献类型
- 🐛 Bug修复:发现并修复系统缺陷
- ✨ 新功能:添加新的切片算法或文档格式支持
- 📚 文档改进:完善使用文档和API说明
- 🧪 测试用例:增加测试覆盖率和边界情况
- 🎨 性能优化:提升处理速度和内存效率### 技术栈贡献方向
- **算法研究**:改进语义边界检测算法
- **模型优化**:更轻量级的嵌入模型
解析支持
- **国际化支持**:多语言和本地化适配
- **云原生架构**:Kubernetes、微服务等现代架构
开发者友好的生态
项目提供了完整的开发者工具链:
# 开发环境设置
python scripts/setup_dev.py# 代码质量检查
black src/ tests/ # 代码格式化
flake8 src/ tests/ # 代码规范检查
mypy src/ # 类型检查# 自动化测试
pytest tests/ -v --cov=src/# 文档生成
sphinx-build docs/ docs/_build/
🎊 总结与展望:开启智能文档处理新时代
项目价值总结
AntSK-FileChunk项目的出现,标志着我们告别了粗暴的文档切分时代,迎来了基于深度语义理解的智能处理新纪元。它不仅仅是一个工具,更是一种思维方式的革命——从机械式处理转向理解式处理,从规则驱动转向语义驱动。
核心价值体现:
-
技术创新价值:
-
首次在文档切分领域系统性应用Transformer语义理解
-
创新的多模态内容统一处理框架
-
质量驱动的自适应优化机制
-
-
实用工程价值:
-
即插即用的API服务,降低集成成本
-
高度可配置的参数系统,适应多种场景
-
完善的容错和降级机制,保证生产可用性
-
-
生态建设价值:
-
开源开放,促进技术普及和发展
-
模块化设计,方便二次开发和定制
-
详尽的文档和示例,降低学习门槛
-
对行业的深远影响
推动RAG技术普及
RAG(检索增强生成)技术的效果很大程度上依赖于高质量的文档切片。AntSK-FileChunk的出现,将显著降低构建高质量RAG系统的技术门槛,推动这一技术在更多企业和场景中的应用。
重新定义文档处理标准
传统的文档处理往往关注格式转换和内容提取,而忽视了语义完整性。AntSK-FileChunk提出的"语义优先"处理理念,有望成为行业新标准,影响更多相关产品的设计思路。
加速企业知识资产数字化
对于坐拥大量文档资产的企业而言,AntSK-FileChunk提供了一个高效的知识资产数字化工具,能够帮助企业更好地盘活存量知识,构建智能化的知识管理系统。
技术发展趋势洞察
从单一到多元
未来的文档处理必将从单纯的文本处理向多模态、多语言、多领域的综合处理发展。AntSK-FileChunk在这一方向上已经做出了有益探索。
从工具到智能
随着大语言模型技术的发展,文档处理工具将从被动的格式转换器进化为主动的内容理解者和知识提炼者。
从孤立到协同
未来的文档处理系统将不再是孤立的工具,而是与AI助手、知识图谱、业务系统深度集成的智能基础设施。
致开发者的寄语
如果你是一名RAG系统开发者,相信AntSK-FileChunk能够成为你得力的助手,让你专注于业务逻辑而不是底层的文档处理细节。
如果你是一名企业架构师,希望这个项目能够为你的知识管理体系建设提供新的思路和工具支撑。
如果你是一名AI研究者,欢迎你参与到这个开源项目中来,共同推动语义理解技术在文档处理领域的发展。
行动起来
立即体验:
git clone https://github.com/xuzeyu91/AntSK-FileChunk.git
cd AntSK-FileChunk
python start_server.py
加入社区:
-
GitHub仓库:⭐ Star支持项目发展
-
技术讨论:提出Issue和Pull Request
-
经验分享:分享你的使用心得和改进建议
关注发展:
-
关注项目更新,获取最新功能
-
参与技术交流,共同完善生态
-
推广应用场景,扩大影响力
结语:在这个AI技术日新月异的时代,每一个细分领域的技术突破都可能引发连锁反应。AntSK-FileChunk在文档处理领域的创新实践,不仅解决了RAG系统的基础问题,更为我们展示了"理解型AI"的无限可能。
技术的价值在于应用,创新的意义在于传承。希望这篇深度解析能够帮助更多开发者理解和应用这项技术,也期待更多的技术创新能够在开源社区的土壤中茁壮成长!
让我们一起,用语义理解的力量,重新定义文档处理的未来! 🚀✨
更多AIGC文章