大模型中的Token和Tokenizer:核心概念解析
引言:理解AI语言处理的基石
当我们与ChatGPT、Claude或其他大语言模型对话时,是否想过这样一个问题:计算机是如何理解我们输入的文字的?毕竟,计算机只能处理数字,而我们输入的是由汉字、英文字母、标点符号组成的自然语言文本。
这个从人类语言到机器理解的转换过程,就像是一个精密的翻译系统。而在这个系统中,Token(词元)和Tokenizer(分词)扮演着至关重要的角色——它们是连接人类语言和机器智能的桥梁。
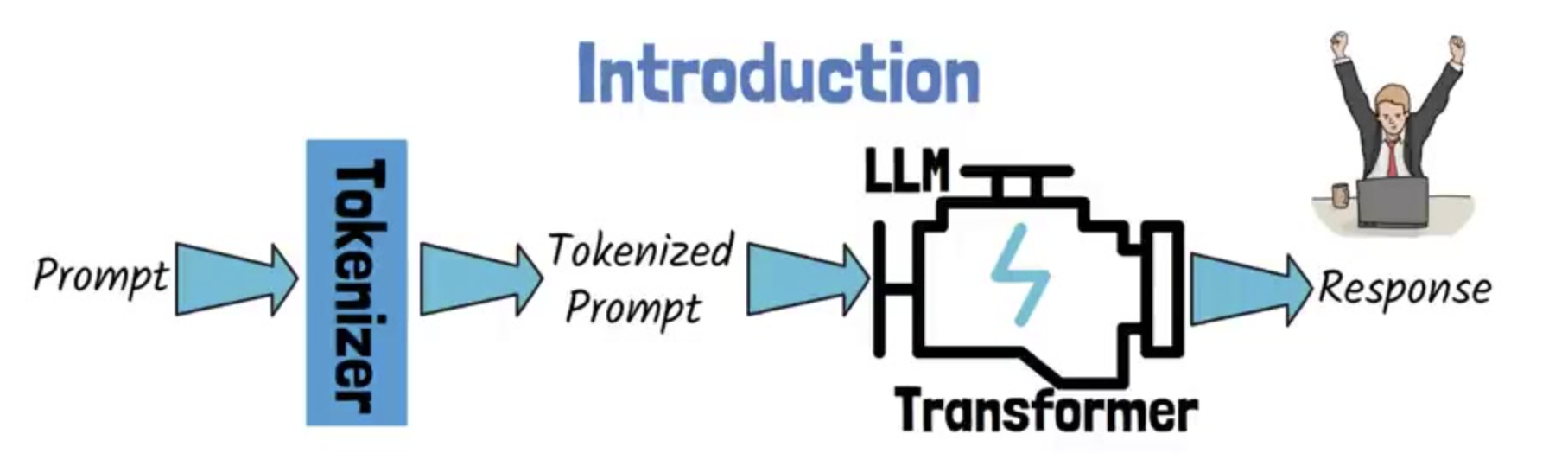
想象一下,如果把文本处理比作烹饪,那么Tokenizer就像是一把精巧的刀具,它需要将原始的食材(文本)切成合适大小的块(Token),这样才能被后续的"烹饪程序"(神经网络模型)有效处理。切得太大,模型难以消化;切得太小,又会丢失重要的营养成分(语义信息)。
Token和Tokenizer在大语言模型中的核心作用体现在三个方面:首先,它们决定了模型能够理解的语言单位的粒度;其次,它们直接影响模型的训练效率和推理速度;最后,它们关系到模型处理不同语言和领域文本的能力。
什么是Token?
Token的基本定义
在大语言模型的世界里,Token是文本处理的最小单位,它可以是一个字符、一个词、或者一个子词片段。如果把文本比作一道需要精心准备的菜肴,那么Token就是经过精心切配的食材块,每一块都有其特定的大小和用途。
Token这个概念最初来源于计算机科学中的"标记"概念,但在自然语言处理领域,它有了更加丰富的含义。简单来说,Token是模型能够"理解"和处理的基本语言单元。
Token的不同粒度
根据切分的粒度不同,Token可以分为三种主要类型:
1. 词级别Token(Word-level Token)
这是最直观的切分方式,将文本按照词汇边界进行分割。例如:
- 英文:“I love programming” → [“I”, “love”, “programming”]
- 中文:“我爱编程” → [“我”, “爱”, “编程”]
词级别Token的优点是保留了完整的语义信息,每个Token都有明确的含义。但缺点也很明显:词汇表会变得非常庞大,而且无法处理训练时未见过的新词(Out-of-Vocabulary, OOV问题)。
2. 字符级别Token(Character-level Token)
这种方法将文本切分到最小的字符单位:
- 英文:“hello” → [“h”, “e”, “l”, “l”, “o”]
- 中文:“你好” → [“你”, “好”]
字符级别Token能够处理任何文本,永远不会遇到未知词汇的问题。但是,每个字符携带的语义信息很少,模型需要学习如何将字符组合成有意义的词汇,这大大增加了学习的复杂度。
3. 子词级别Token(Subword-level Token)
这是目前主流大语言模型采用的方法,它在词和字符之间找到了平衡点:
- “unhappiness” → [“un”, “happy”, “ness”]
- “programming” → [“program”, “ming”]
子词级别的切分既能保留一定的语义信息(如词根、词缀),又能灵活处理各种词汇变化,是目前最受欢迎的Token化方法。
实际例子演示
让我们通过一个具体的例子来看看不同的Token化方法。以句子"The programmer is debugging"为例:
词级别切分:
["The", "programmer", "is", "debugging"]
字符级别切分:
["T", "h", "e", " ", "p", "r", "o", "g", "r", "a", "m", "m", "e", "r", " ", "i", "s", " ", "d", "e", "b", "u", "g", "g", "i", "n", "g"]
子词级别切分(使用BPE方法):
["The", "program", "mer", "is", "debug", "ging"]
从这个例子可以看出,子词级别的切分既避免了词级别切分可能遇到的未知词问题,又比字符级别切分保留了更多的语义信息。
Tokenizer的工作原理
Tokenizer的定义和核心作用
如果说Token是经过精心切配的食材,那么Tokenizer就是那把神奇的刀具。Tokenizer(分词器)是负责将原始文本转换为Token序列的算法工具,它的核心作用是在保持语义信息的同时,将文本转换为模型可以处理的数字形式。
现代Tokenizer的工作流程通常包含四个步骤:
- 归一化(Normalization):清理和标准化文本
- 预分词(Pre-tokenization):初步切分文本
- 模型切分(Model):应用具体的分词算法
- 后处理(Post-processing):添加特殊标记
主要Tokenization方法详解
BPE (Byte Pair Encoding):最流行的方法
BPE算法最初是一种数据压缩技术,后来被巧妙地应用到文本处理领域。它的核心思想非常简单:从字符开始,逐步合并出现频率最高的字符对,直到达到预设的词汇表大小。
BPE算法的工作步骤:
- 初始化:将所有文本切分为单个字符,建立初始词汇表
- 统计频率:统计所有相邻字符对的出现频率
- 合并操作:选择频率最高的字符对进行合并
- 迭代重复:重复步骤2-3,直到达到目标词汇表大小
让我们通过一个简化的例子来理解BPE的工作过程:
初始语料:
"low": 5, "lower": 2, "newest": 6, "widest": 3
步骤1:字符级切分
"l o w </w>": 5
"l o w e r </w>": 2
"n e w e s t </w>": 6
"w i d e s t </w>": 3
注意这里的</w>是词尾标记,用于区分词的边界。
步骤2:统计字符对频率
统计所有相邻字符对的出现次数:
- “e s”: 在"newest"和"widest"中出现,共6+3=9次
- “s t”: 在"newest"和"widest"中出现,共6+3=9次
- “l o”: 在"low"和"lower"中出现,共5+2=7次
- 其他字符对出现次数更少
最高频的字符对是"e s"(或"s t"),出现了9次。
步骤3:合并最高频字符对
选择"e s"进行合并,更新语料:
"l o w </w>": 5
"l o w e r </w>": 2
"n e w es t </w>": 6
"w i d es t </w>": 3
通过这种方式,BPE能够自动发现语言中的常见模式,如词根、词缀等。
BPE的优势:
- 算法简单,易于实现和理解
- 能够有效处理未知词汇(OOV)问题
- 在多种语言上都表现良好
- 被广泛应用于GPT系列、RoBERTa、LLaMA等主流模型
WordPiece:BERT的选择
WordPiece算法是Google为BERT模型开发的分词方法,它在BPE的基础上引入了更加智能的合并策略。
WordPiece与BPE的核心区别:
BPE选择频率最高的字符对进行合并,而WordPiece选择能够最大化语言模型概率的字符对进行合并。具体来说,WordPiece使用互信息来评估两个子词的关联性。
数学原理:
假设要合并子词x和y成为新子词z,WordPiece会计算合并前后的概率变化:
Score = log(P(z)) - log(P(x)) - log(P(y))
这个分数实际上就是x和y之间的互信息。互信息越大,说明这两个子词在语言中的关联性越强,合并后能更好地保留语义信息。
SentencePiece:语言无关的解决方案
SentencePiece是Google开发的另一个分词工具,它的最大特点是语言无关性。与传统的分词方法不同,SentencePiece直接在原始文本上工作,不需要预先的分词步骤。
SentencePiece的核心特性:
- 语言无关:不依赖于特定语言的分词规则
- 基于Unicode:直接处理Unicode字符
- 空格处理:将空格视为特殊的Token
- 多算法支持:内置BPE、Unigram等多种算法
这种设计使得SentencePiece特别适合处理多语言文本,尤其是那些没有明显词边界的语言(如中文、日文等)。
不同方法的对比和选择
| 特性 | BPE | WordPiece | SentencePiece |
|---|---|---|---|
| 核心策略 | 频率最高 | 互信息最大 | 多算法支持 |
| 语言依赖 | 中等 | 中等 | 无 |
| 实现复杂度 | 简单 | 中等 | 中等 |
| 典型应用 | GPT、RoBERTa | BERT | T5、ALBERT |
| 多语言支持 | 良好 | 良好 | 优秀 |
选择建议:
- BPE:如果你需要一个简单、高效且广泛验证的方法,BPE是很好的选择
- WordPiece:如果你的任务更注重语义理解,WordPiece可能更适合
- SentencePiece:如果你需要处理多语言文本或者希望有更大的灵活性,SentencePiece是最佳选择
分词器在线示例
我们以以下这段英文为例,演示如何使用 OpenAI 提供的在线 Tokenizer 工具,将人类可读的文本拆分为模型可处理的“子词”或“符号” —— Token,并查看其对应的数值 ID 以及处理费用估算。
Large language models such as OpenAI decode text through tokens—frequent character sequences within a text corpus. These models master the art of recognizing patterns among tokens, adeptly predicting the subsequent token in a series.

统计信息面板显示,这段文本被拆成了 42 个Tokens;包括空格和标点,一共 233 个字符(Characters);若按所选模型处理这段文本的大致费用$0.00000084。
下方以彩色方块展示了每个 Token 的 文字 片段,便于直观看出哪些字母或词组被合并成一个 Token。

当你关闭“Show text”开关,工具将每个彩色方块里的文字变为 对应的 Token ID,这些数字即模型词表(vocabulary)中每个子词的索引。例如:
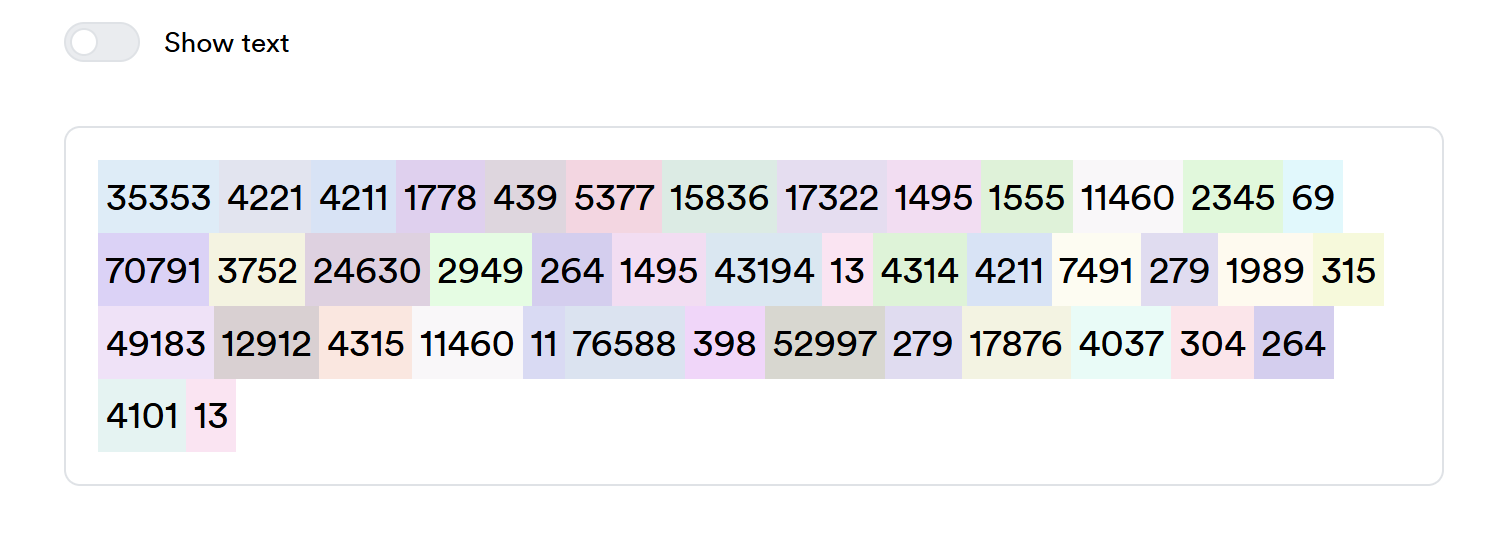
- 每个数字代表一个token在训练时使用的唯一编号。
- 模型计算时,先把文本映射成这些 ID,再在内部进行向量运算、注意力计算等。
推理代码中的应用
在掌握了 Tokenizer 的原理后,接下来只需几行代码,就能在本地快速启动一个 HuggingFace Transformers 格式的因果语言模型(如 LLaMA、ChatGLM、DeepSeek-MoE 等),完成端到端的推理流程。
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch# 指定本地或 HuggingFace 仓库路径
model_path = "path/to/your/local/model"# 一行加载分词器和模型,支持自定义实现并自动分配设备
tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(model_path, device_map="auto")# 构造输入并移动到模型所在设备
prompt = "tokenizer是什么?"
inputs = tokenizer(prompt, return_tensors="pt").to(model.device)# 生成并解码输出
outputs = model.generate(**inputs, max_new_tokens=150)
reply = tokenizer.decode(outputs[0], skip_special_tokens=True)print("模型回复:", reply)
Token在实际应用中的关键问题
词汇表外词汇(OOV)问题及解决方案
在传统的词级别分词中,最令人头疼的问题就是遇到训练时未见过的词汇。想象一下,如果你是一位只学过基础菜谱的厨师,突然遇到了一种从未见过的食材,你可能会不知所措。这就是OOV(Out-of-Vocabulary)问题的本质。
子词方法的解决策略:
现代的子词方法通过将词汇分解为更小的单元来解决这个问题。即使遇到全新的词汇,也能通过已知的子词组合来表示:
"puppy" → ["pup", "py"]
"quickly" → ["quick", "ly"]
这样,即使模型从未见过"puppy"这个完整的词,它仍然可以通过理解"pup"和"py"的含义来推断整个词的语义。
不同语言的处理挑战
不同语言的特性给Token化带来了独特的挑战。
英语等拉丁语系的特点:
- 有明确的词边界(空格分隔)
- 丰富的词形变化(如:run, runs, running, ran)
中文的特殊挑战:
- 没有明确的词边界标记
- 词汇组合灵活,新词产生频繁
- 同一个字符在不同上下文中含义差异很大
多语言模型的解决方案:
现代多语言模型(如mBERT、XLM-R)通常采用以下策略:
- 使用SentencePiece等语言无关的分词工具
- 在多语言语料上联合训练词汇表
- 通过共享子词来实现跨语言知识迁移
Token数量对模型性能和成本的影响
Token的数量直接影响模型的计算复杂度和推理成本。大多数Transformer模型的计算复杂度与序列长度的平方成正比。如果一个句子被切分为n个Token,那么自注意力机制的计算复杂度就是O(n²)。
具体数字对比:
以句子"The quick brown fox jumps"为例:
| 方法 | Token数量 | 相对计算量 |
|---|---|---|
| 词级别 | 5 | 1.0x |
| 字符级别 | 23 | 21.2x |
| 子词级别 | 6 | 1.4x |
从这个对比可以看出,字符级别的Token化会导致计算量急剧增加,而子词级别在保持合理计算量的同时提供了更好的灵活性。
上下文长度限制的考虑
现代大语言模型都有上下文长度的限制,这个限制是以Token为单位计算的。
常见模型的上下文限制:
| 模型 | 上下文长度(Token) | 大约对应的文字量 |
|---|---|---|
| GPT-3.5 | 4,096 | ~3,000词 |
| GPT-4 | 8,192 | ~6,000词 |
| GPT-4 Turbo | 128,000 | ~96,000词 |
| Claude-3 | 200,000 | ~150,000词 |
实际应用中的策略:
- 文档分块:将长文档切分为多个片段,分别处理
- 智能截断:保留最重要的部分,丢弃次要信息
- 滑动窗口:使用重叠的窗口来处理长文本
总结与实践建议
Token和Tokenizer虽然看似是技术细节,但它们是理解现代AI系统工作原理的关键。掌握这些概念不仅有助于我们更好地使用现有的AI工具,也为我们在AI技术快速发展的时代中保持竞争力奠定了基础。
正如我们在文章开头提到的烹饪比喻,好的厨师不仅要会做菜,更要理解食材的特性和切配的技巧。在AI的世界里,理解Token和Tokenizer就是掌握了处理语言这种"食材"的基本功。