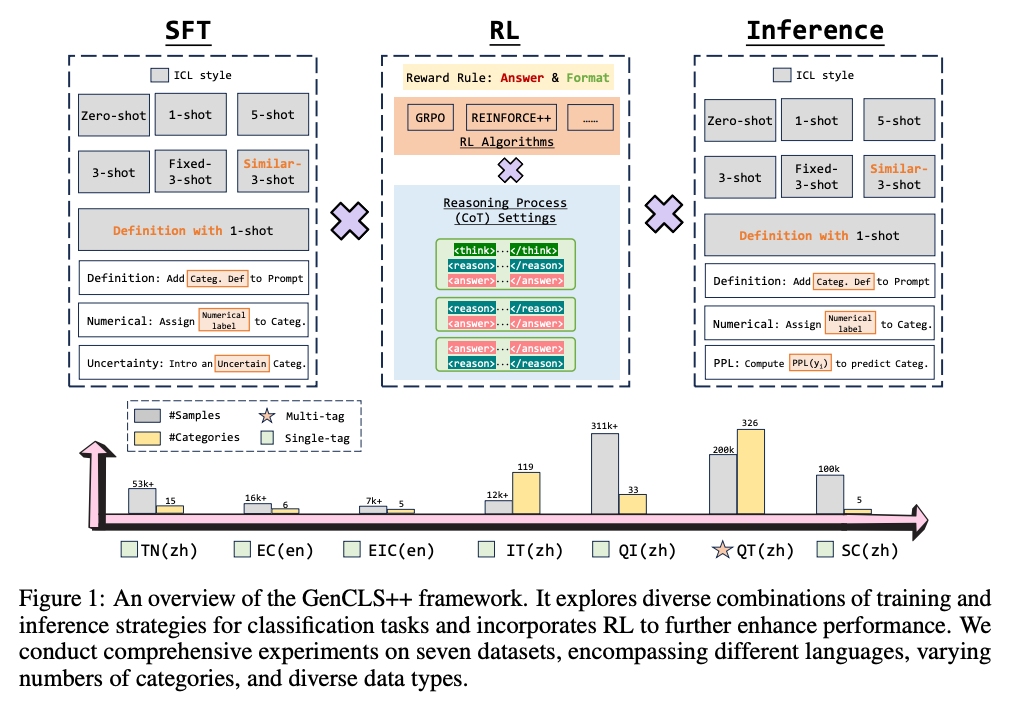
GenCLS++:通过联合优化SFT和RL,提升生成式大模型的分类效果
摘要:作为机器学习中的一个基础任务,文本分类在许多领域都发挥着至关重要的作用。随着大型语言模型(LLMs)的快速扩展,特别是通过强化学习(RL)的推动,对于更强大的分类器的需求也在不断增长。因此,分类技术的进步对于提升LLMs的整体能力正变得越来越重要。传统的判别方法将文本映射到标签,但忽视了LLMs固有的生成能力。生成式分类通过提示模型直接输出标签来解决这一问题。然而,现有的研究仍然主要依赖简单的监督微调(SFT),很少探究训练和推理提示之间的相互作用,并且没有工作系统地利用RL来构建生成式文本分类器,也没有将SFT、RL和推理时的提示统一到一个框架中。我们通过GenCLS++填补了这一空白,该框架联合优化了SFT和RL,并在训练和推理过程中系统地探索了五个高级策略维度——上下文学习变体、类别定义、显式不确定性标签、语义无关的数字标签以及基于困惑度的解码。在SFT的“策略预热”之后,我们应用了基于简单规则的奖励的RL,从而获得了显著的额外收益。在七个数据集上,GenCLS++相对于简单的SFT基线平均准确率提高了3.46%;在公开数据集上,这一提升达到了4.00%。值得注意的是,与从明确的思考过程中受益的推理密集型任务不同,我们发现分类任务在没有这些推理步骤的情况下表现更好。这些关于明确推理作用的见解为未来的LLMs应用提供了宝贵的指导。
本文目录
一、背景动机
二、核心贡献
三、实现方法
3.1 SFT策略探索
(1)上下文学习变体(In-Context Learning Variants)
(2)类别定义(Category Definitions)
(3)显式不确定性标签(Explicit Uncertainty Labels)
(4)语义无关的数值标签(Numerical Labels)
(5)基于困惑度的解码(Perplexity-based Decoding)
3.2 强化学习阶段
(1)策略预热(Policy Warm-up)
(2)推理过程的探索
四、实验结果
4.1 实验设置
4.2 基准测试表现
4.3 不同策略收益
4.4 RL 的额外收益
4.5 推理过程的影响
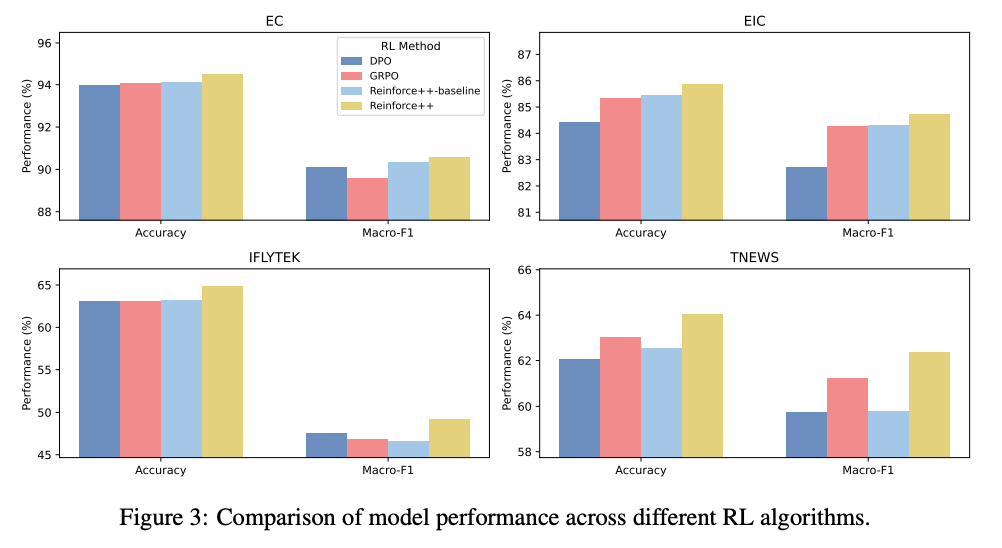
4.6 不同 RL 算法的比较
一、背景动机
论文题目:GenCLS++: Pushing the Boundaries of Generative Classification in LLMs Through Comprehensive SFT and RL Studies Across Diverse Datasets
论文地址:https://arxiv.org/pdf/2504.19898
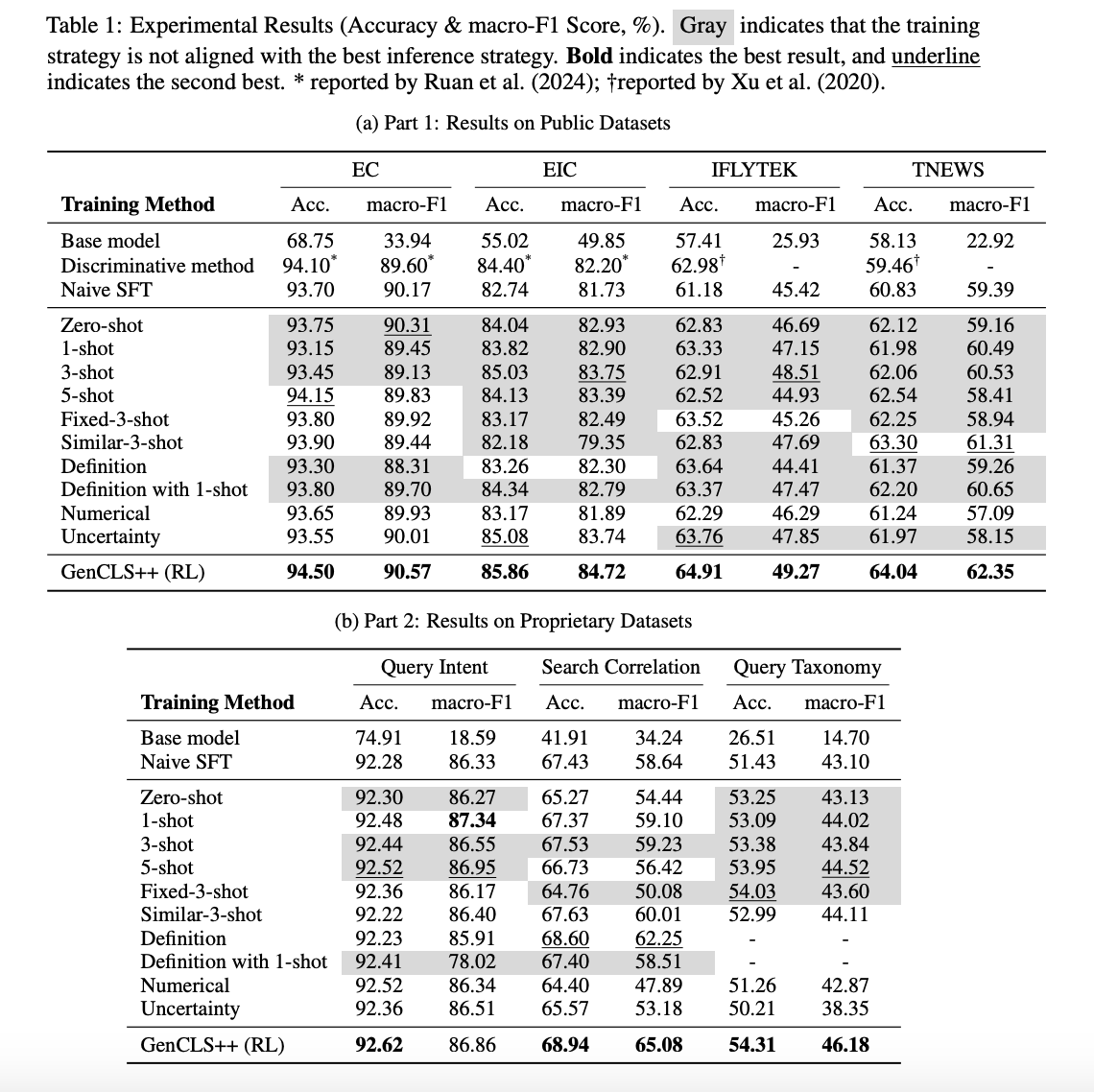
传统的判别式方法将文本映射到标签,但忽略了LLMs的内在生成能力。生成式分类通过直接输出标签来解决这一问题,但现有的研究主要依赖于简单的监督微调(SFT),很少探讨训练和推理提示之间的相互作用,也没有系统地利用RL来提升生成式文本分类器。
文章提出GenCLS++框架,通过联合优化SFT和RL,并系统地探索五个高级策略维度——上下文学习变体、类别定义、显式不确定性标签、语义无关的数值标签和基于困惑度的解码——在训练和推理过程中,以提升LLMs在分类任务中的性能。
二、核心贡献
- 提出了GenCLS++框架,该框架通过结合SFT和RL,并系统地探索多种训练和推理策略,显著提升了LLMs在文本分类任务中的性能。
- 在七个数据集上,GenCLS++相对于简单的SFT基线平均提升了3.46%的准确率,在公共数据集上这一提升达到了4.00%。
- 研究发现分类任务在没有显式推理步骤的情况下表现更好,这与推理密集型任务中显式推理过程的益处形成了对比。
三、实现方法
3.1 SFT策略探索
GenCLS++ 在训练和推理阶段系统地研究了多种策略对显著影响模型的性能
(1)上下文学习变体(In-Context Learning Variants)
-
零样本(Zero-shot):模型仅接收任务描述,不提供任何标注示例。
-
少样本(Few-shot):模型接收少量标注示例(如1-shot、3-shot、5-shot)。
-
固定示例(Fixed Examples):在每个测试案例中使用相同的三个标注示例。
-
相似示例(Similar Examples):根据输入文本的相似性检索并提供三个训练示例。
(2)类别定义(Category Definitions)
在提示中添加每个目标类别的文本定义,帮助模型更好地理解类别含义。
(3)显式不确定性标签(Explicit Uncertainty Labels)
引入一个“不确定”类别,用于标记那些模型难以高置信度分类的训练样本。
(4)语义无关的数值标签(Numerical Labels)
将每个类别分配一个数值标签,模型直接输出对应的数字,而不是类别名称。
(5)基于困惑度的解码(Perplexity-based Decoding)
在推理阶段,通过计算每个候选类别的困惑度来选择最可能的类别。
3.2 强化学习阶段
在监督微调(SFT)之后,GenCLS++ 使用基于规则的奖励函数进行强化学习(RL),以进一步提升模型性能。
(1)策略预热(Policy Warm-up)
在 RL 训练之前,使用 SFT 对模型进行预热,以赋予模型基本的分类能力。预热阶段的目的是让模型在监督数据上学习基本的分类技能,为后续的 RL 训练提供一个良好的起点。
(2)推理过程的探索
在 RL 训练中,作者探索了两种不同的推理策略:
-
包含推理步骤(Reasoning):模型在输出最终答案之前需要进行推理过程。
-
直接生成答案(Without Reasoning):模型直接输出分类结果,而不进行显式的推理步骤。
四、实验结果
4.1 实验设置
-
数据集:文章在七个数据集上进行了实验,包括四个公共基准数据集(EC、EIC、IFLYTEK、TNEWS)和三个私有数据集(Query Intent、Search Correlation、Query Taxonomy)。
-
评估指标:使用准确率(Accuracy)和宏平均 F1 分数(macro-F1)作为评估指标。
-
基线方法:与传统的判别式方法和简单的 SFT 基线进行比较。
4.2 基准测试表现
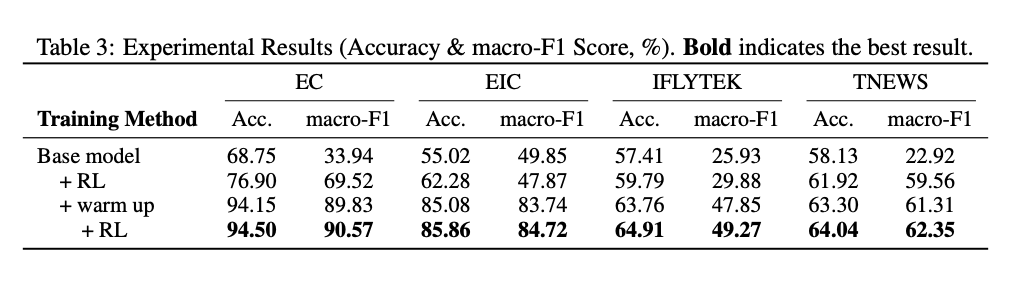
GenCLS++ 在七个数据集上的平均准确率提升了 3.46%,在公共数据集上提升了 4.00%。特别是在 IFLYTEK 数据集上,GenCLS++ 实现了 6.10% 的相对准确率提升。
4.3 不同策略收益
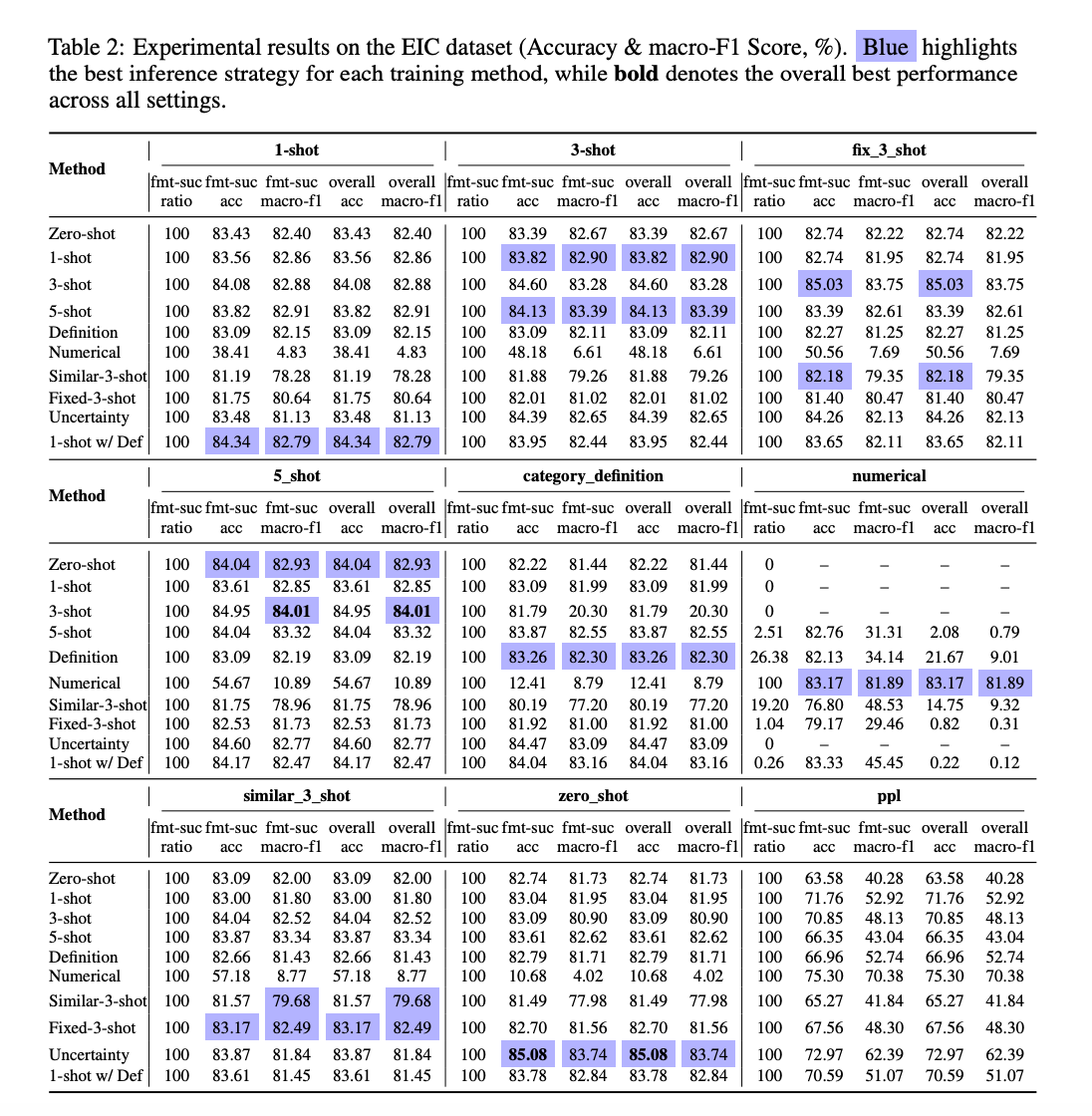
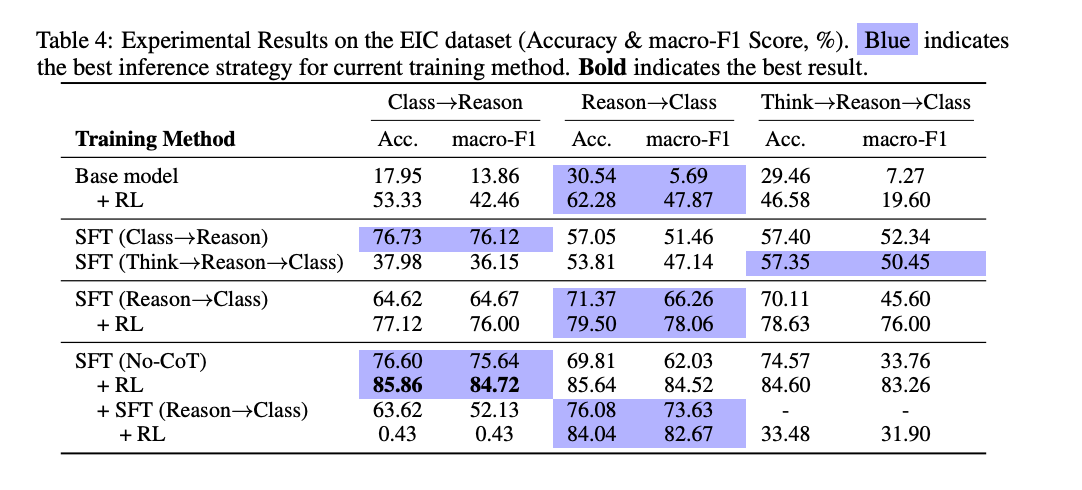
实验表明,与训练时使用的策略相比,切换到不同的推理策略通常可以带来额外的性能提升。例如,在 EIC 数据集上,使用 3-shot 训练的模型在推理时切换到 5-shot 策略,准确率从 84.04% 提升到 85.03%。
4.4 RL 的额外收益
在 SFT 之后应用 RL 可以进一步提升性能。平均相对准确率提升了 18.18%。例如,在 EIC 数据集上,SFT 预热后的模型在 RL 训练后,准确率从 82.74% 提升到 85.86%。
4.5 推理过程的影响
与推理密集型任务不同,分类任务在没有显式推理步骤的情况下表现更好。实验结果表明,直接生成答案的模型在分类任务中更为有效。例如,在 EIC 数据集上,直接生成答案的模型准确率为 85.86%,而包含推理步骤的模型准确率为 84.04%。
4.6 不同 RL 算法的比较
文章比较了不同的 RL 算法,包括 GRPO、Reinforce++-baseline 和 Reinforce++。结果表明,Reinforce++ 在所有数据集上都表现最佳,且训练效率更高。