人工智能数学基础(八)—— 最优化理论
最优化理论在人工智能领域占据着举足轻重的地位,无论是训练机器学习模型,还是让机器人规划最优路径,亦或是解决复杂的工程设计问题,都离不开最优化方法的有力支持。今天,我将带大家深入浅出地探索最优化理论的奇妙世界。资源绑定附上完整资源供读者参考学习!
8.1 最优化理论的基础知识
8.1.1 最优化示例
你有没有想过,怎么让一个函数的输出值尽可能的小(或者尽可能的大)?或者说,在有限的资源下,怎样分配才能让收益最大化?这些都可以归结为最优化问题。比如,企业生产中,要在成本有限的情况下让利润最大化,这就是一个典型的最优化问题。
8.1.2 最优化的基本概念
最优化问题一般可以描述为:在给定的约束条件下,找到一个变量的值,使得某个目标函数达到最小值(或者最大值)。这里的变量可以是一个数值、一个向量,甚至是一个函数。
8.1.3 求最优化问题的一般步骤
-
明确目标函数:也就是你要优化的那个东西,比如成本、利润、误差等。
-
确定变量和约束条件:变量是你可以调整的那些因素,约束条件则是变量需要满足的一些限制。
-
选择合适的方法求解:根据问题的特点,选择合适的最优化算法,比如梯度下降法、牛顿法等。
-
验证结果:检查得到的结果是否满足约束条件,是否真的让目标函数达到了最优。
8.1.4 最优化问题的几何解释
可以想象一下三维空间中的一个曲面,这个曲面代表了目标函数的值。最优化问题就像是在这个曲面上寻找最低点或者最高点。约束条件则像是在这个空间中围起的一个区域,解必须在这个区域内找到。
8.1.5 最优化问题的基本解法
穷举法
如果变量的取值范围是有限的,我们可以尝试所有可能的值,然后找到使目标函数最优的那个。但是,这种方法在变量很多或者取值范围很大的时候就不实用了。
解析法
通过对目标函数求导,找到导数为零的点,这些点可能是极值点。然后进一步判断这些点是否是最优解。但是,很多复杂函数的导数很难求,甚至求不出来。
迭代法
从一个初始猜测值开始,不断调整变量的值,逐步逼近最优解。梯度下降法和牛顿法都是迭代法。
示例(解析法求解简单最优化问题)
import numpy as np
# 定义目标函数
def f(x):return x**2 + 2*x + 1
# 求导函数
def df(x):return 2*x + 2
# 解方程 df(x)=0
x_optimal = -2 / 2 # 解为 x = -1
print("最优解为 x =", x_optimal)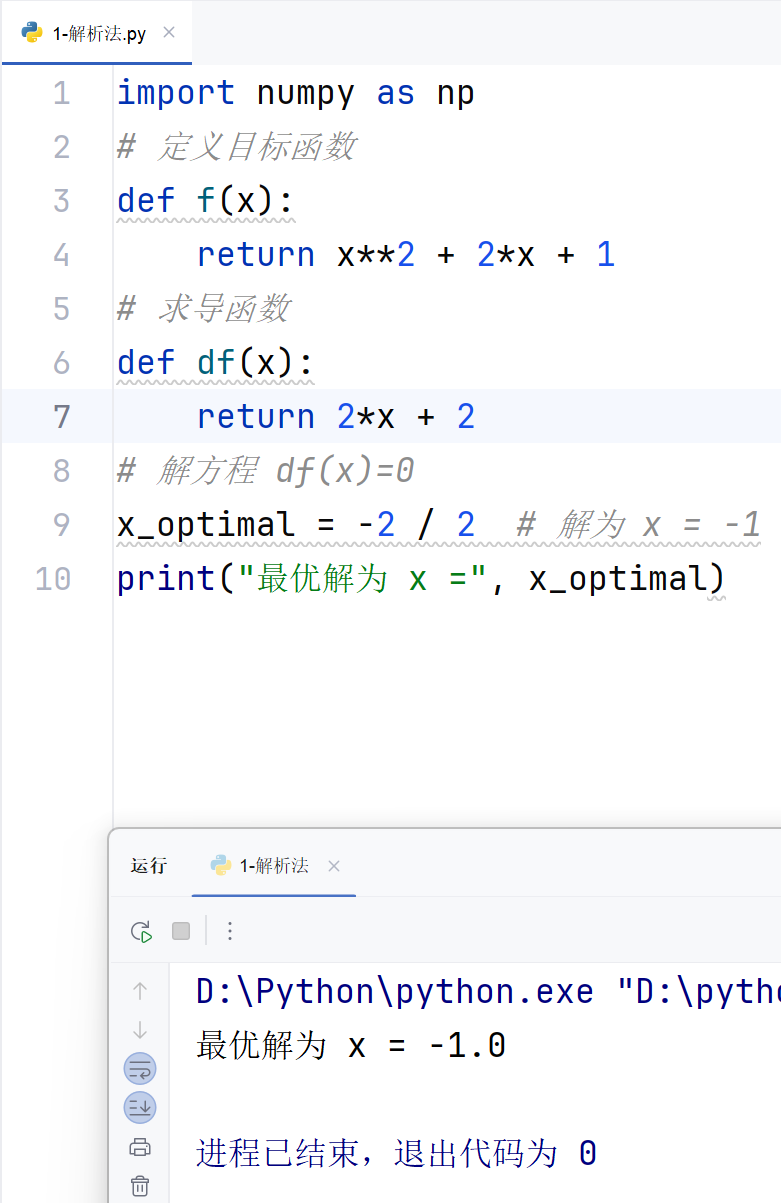
8.2 线性规划
8.2.1 线性规划问题及其数学模型
线性规划问题的目标函数和约束条件都是线性的。一个标准的线性规划问题可以表示为:
minimize(cTx)
subject toA x≤b,x≥0
其中,x 是决策变量,c 是目标函数的系数向量,A 是约束条件的系数矩阵,b 是约束条件的右侧向量。
8.2.2 线性规划问题的几何意义
在线性规划中,每一个不等式约束条件都定义了一个半空间,而所有约束条件的交集形成了一个凸多面体,称为可行域。目标函数则可以看作是一个超平面,随着目标函数值的变化,这个超平面会平移。最优解一定在这个可行域的顶点上。
8.2.3 单纯形法
单纯形法是一种求解线性规划问题的经典算法。它的基本思想是:从可行域的一个顶点出发,沿着使目标函数值改进的方向移动到相邻的顶点,直到找到最优解。
示例(用单纯形法求解线性规划问题)
from scipy.optimize import linprog
# 目标函数系数(注意这里是求最小值,所以直接用)
c = [-1, 4]
# 不等式约束条件的系数矩阵和右侧向量
A = [[-3, 1], [1, 2]]
b = [6, 4]
# 变量的下界
x0_bounds = (0, None)
x1_bounds = (0, None)
# 求解线性规划问题
res = linprog(c, A_ub=A, b_ub=b, bounds=[x0_bounds, x1_bounds], method='highs')
print('结果:', res)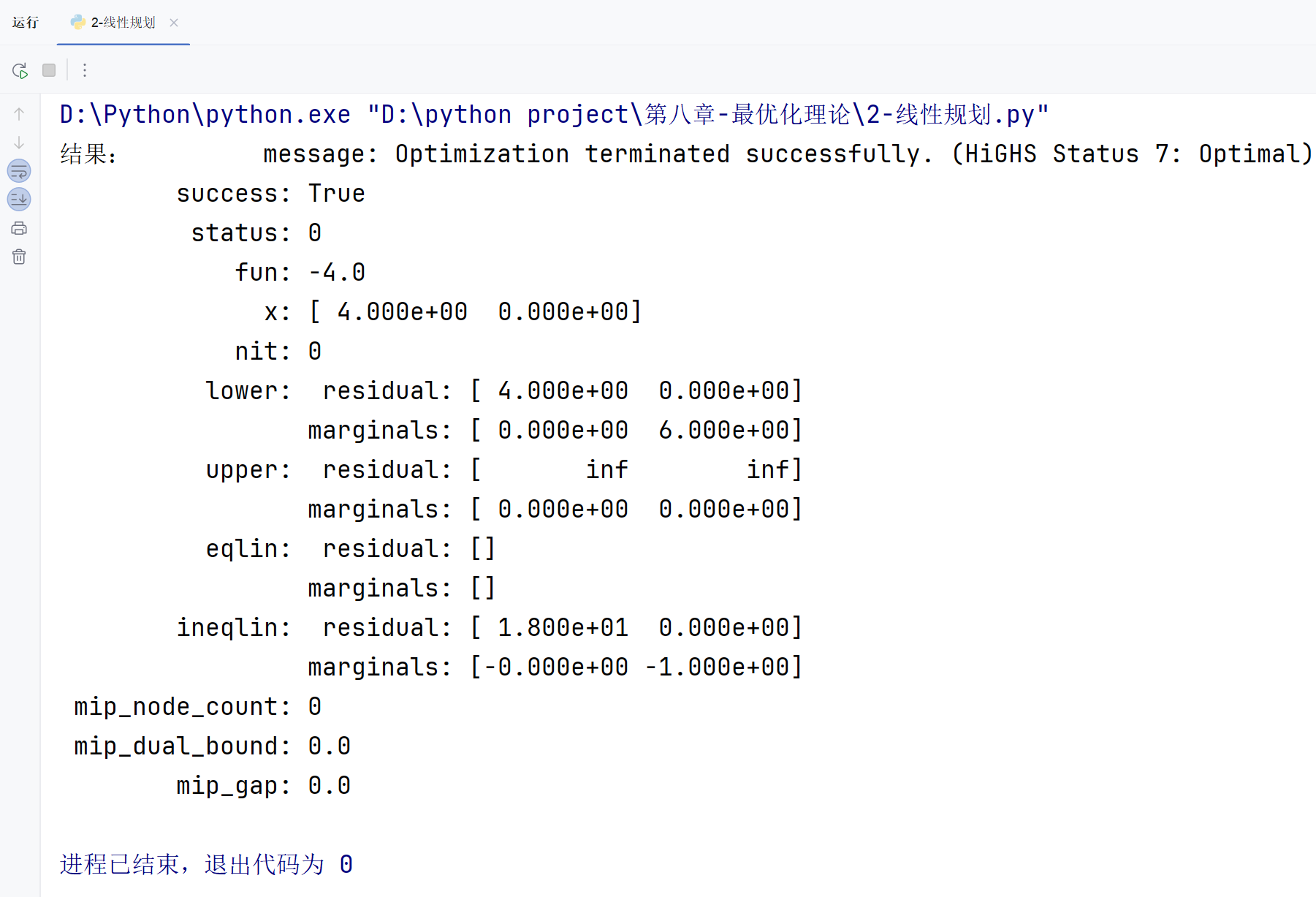
8.3 非线性规划
8.3.1 非线性规划的基本概念
如果目标函数或者约束条件中包含非线性函数,那么这个问题就是一个非线性规划问题。非线性规划问题比线性规划问题要复杂得多,也更难以求解。
8.3.2 无约束条件下的单变量函数最优化方法
对于单变量无约束的最优化问题,常用的方法有:
-
黄金分割法:通过不断缩小包含极小点的区间来寻找最优解。这种方法不需要计算导数,适用于不可导的函数。
示例(黄金分割法求解单变量无约束最优化问题)
import numpy as np
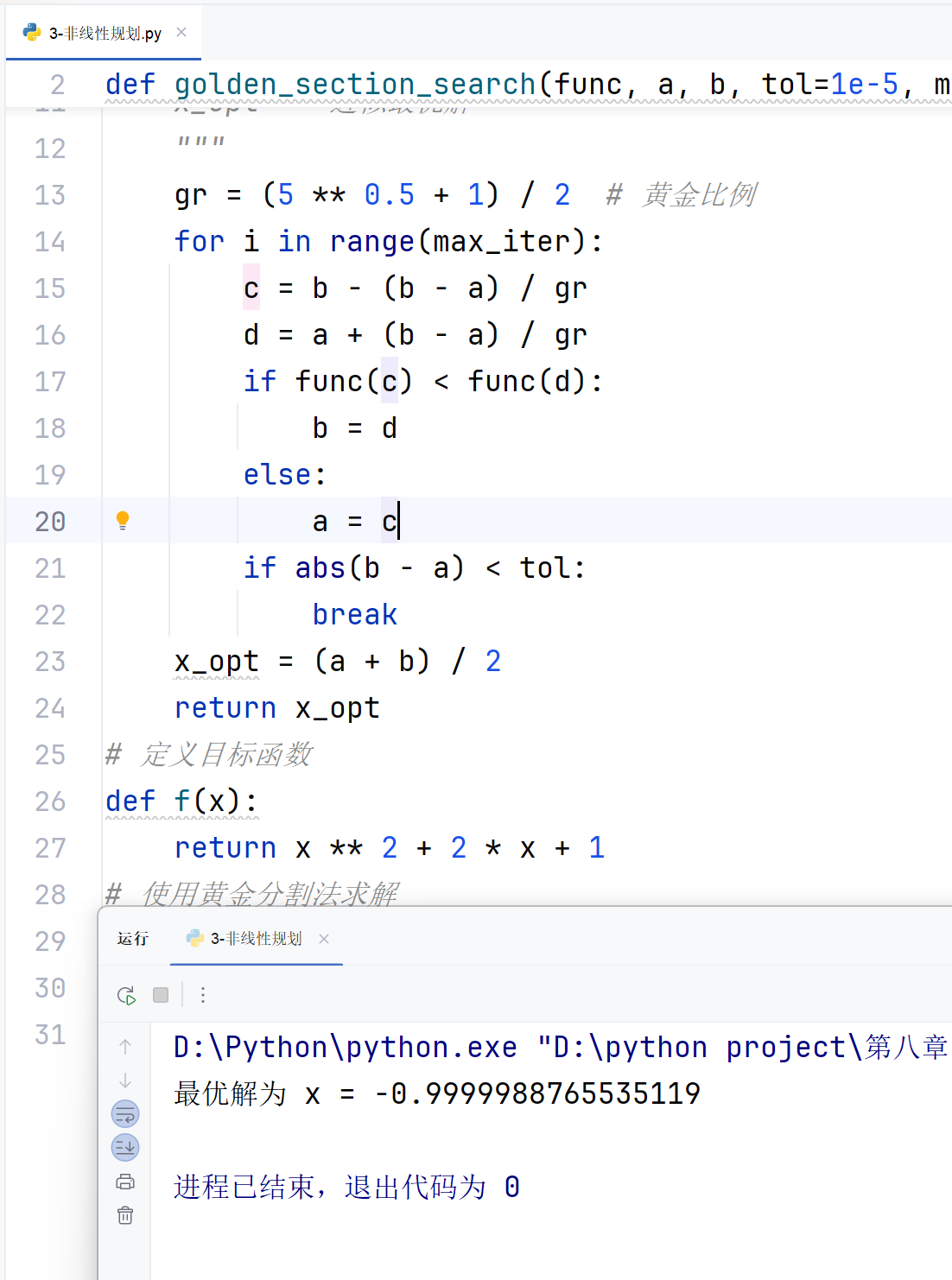
def golden_section_search(func, a, b, tol=1e-5, max_iter=100):"""使用黄金分割法求解单变量无约束最优化问题参数:func -- 目标函数a, b -- 初始区间端点tol -- 容忍误差max_iter -- 最大迭代次数返回:x_opt -- 近似最优解"""gr = (5 ** 0.5 + 1) / 2 # 黄金比例for i in range(max_iter):c = b - (b - a) / grd = a + (b - a) / grif func(c) < func(d):b = delse:a = cif abs(b - a) < tol:breakx_opt = (a + b) / 2return x_opt
# 定义目标函数
def f(x):return x ** 2 + 2 * x + 1
# 使用黄金分割法求解
x_opt = golden_section_search(f, -5, 5)
print("最优解为 x =", x_opt)
8.3.3 无约束条件下的多变量函数最优化方法
对于多变量无约束的最优化问题,常用的方法有:
-
梯度下降法:利用目标函数的梯度信息,沿着梯度的反方向更新变量的值,逐步逼近最优解。
示例(梯度下降法求解多变量无约束最优化问题)
import numpy as np
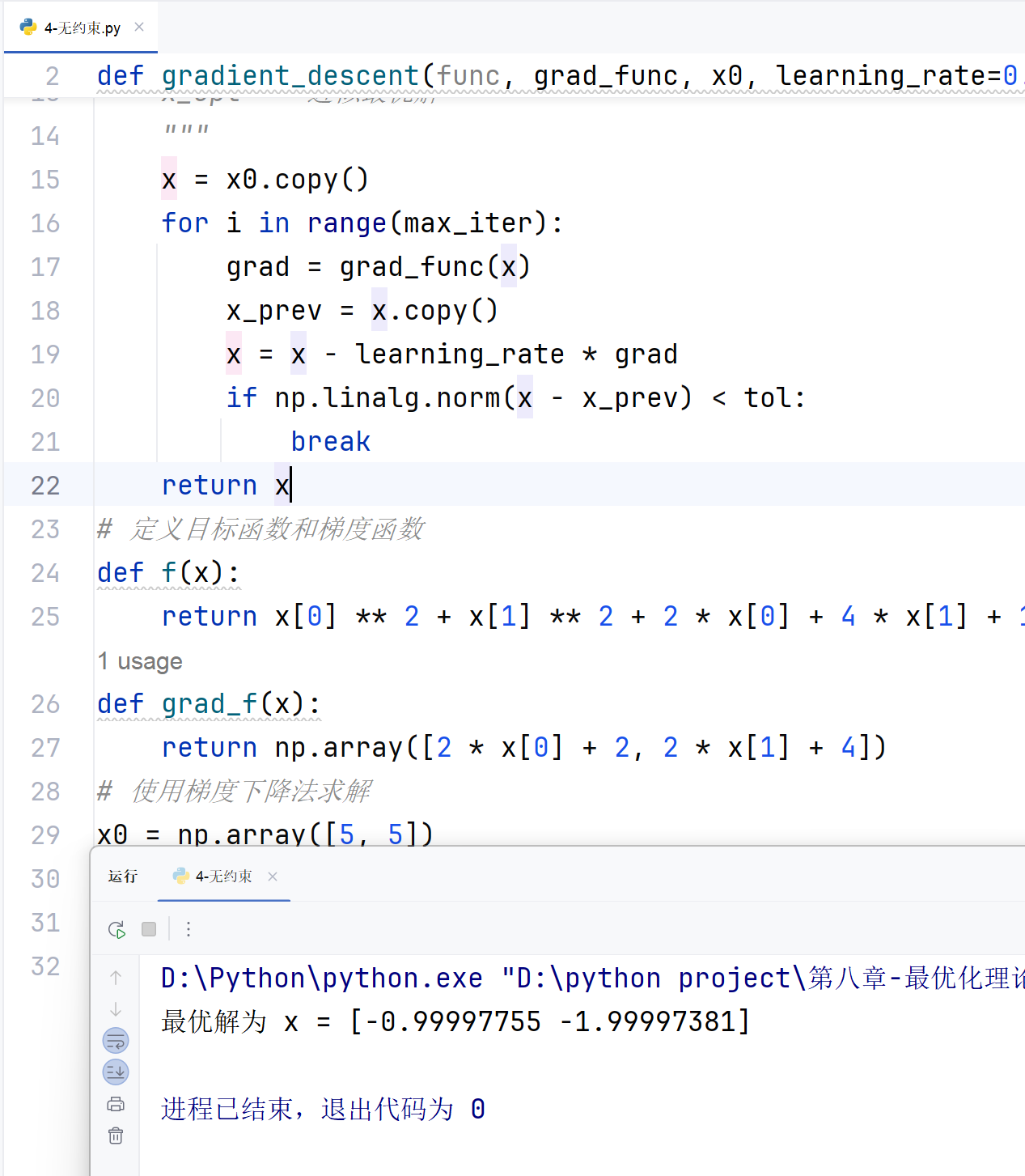
def gradient_descent(func, grad_func, x0, learning_rate=0.1, tol=1e-5, max_iter=1000):"""使用梯度下降法求解多变量无约束最优化问题参数:func -- 目标函数grad_func -- 目标函数的梯度函数x0 -- 初始点learning_rate -- 学习率tol -- 容忍误差max_iter -- 最大迭代次数返回:x_opt -- 近似最优解"""x = x0.copy()for i in range(max_iter):grad = grad_func(x)x_prev = x.copy()x = x - learning_rate * gradif np.linalg.norm(x - x_prev) < tol:breakreturn x
# 定义目标函数和梯度函数
def f(x):return x[0] ** 2 + x[1] ** 2 + 2 * x[0] + 4 * x[1] + 1
def grad_f(x):return np.array([2 * x[0] + 2, 2 * x[1] + 4])
# 使用梯度下降法求解
x0 = np.array([5, 5])
x_opt = gradient_descent(f, grad_f, x0, learning_rate=0.1)
print("最优解为 x =", x_opt)
8.4 实验:用梯度下降法求 Rosenbrock 函数的最小值
8.4.1 实验目的
掌握梯度下降法的基本原理和实现方法,学会使用梯度下降法求解非线性规划问题。
8.4.2 实验要求
用梯度下降法求 Rosenbrock 函数的最小值,并绘制迭代过程。
8.4.3 实验原理
Rosenbrock 函数是一个经典的测试函数,用于验证优化算法的性能。其定义为:
f(x,y)=(a−x)2+b(y−x2)2
其中,a 和 b 是常数,通常取 a=1,b=100。这个函数的最小值在 (x,y)=(1,1) 处,最小值为 0。Rosenbrock 函数的形状像一个香蕉谷,使得许多优化算法在寻找最小值时容易陷入困境。
梯度下降法是一种迭代的优化算法,它利用目标函数的梯度信息来更新变量的值,逐步逼近最优解。在每次迭代中,变量的更新方向是梯度的反方向,因为梯度的方向是函数值增长最快的方向。
8.4.4 实验步骤
-
定义 Rosenbrock 函数及其梯度函数:根据 Rosenbrock 函数的定义,编写相应的 Python 函数,并计算其梯度。
-
初始化参数:设置初始点、学习率、最大迭代次数和容忍误差等参数。
-
梯度下降迭代:从初始点出发,沿着梯度的反方向更新变量的值,直到满足停止条件。
-
记录迭代过程:在每次迭代中,记录变量的值和目标函数值,用于后续分析和绘图。
-
绘制迭代过程:将迭代过程中变量的值和目标函数值绘制出来,观察梯度下降法的收敛过程。
8.4.5 实验结果
import numpy as np
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
def rosenbrock(x):"""Rosenbrock 函数参数:x -- 输入变量,形状为 (2,) 的 NumPy 数组返回:函数值"""a = 1b = 100return (a - x[0]) ** 2 + b * (x[1] - x[0] ** 2) ** 2
def grad_rosenbrock(x):"""Rosenbrock 函数的梯度参数:x -- 输入变量,形状为 (2,) 的 NumPy 数组返回:梯度向量"""a = 1b = 100grad_x0 = 2 * (x[0] - a) + 4 * b * x[0] * (x[0] ** 2 - x[1])grad_x1 = 2 * b * (x[1] - x[0] ** 2)return np.array([grad_x0, grad_x1])
def gradient_descent(rosenbrock, grad_rosenbrock, x0, learning_rate=0.001, tol=1e-5, max_iter=1000):"""使用梯度下降法求解 Rosenbrock 函数的最小值参数:rosenbrock -- Rosenbrock 函数grad_rosenbrock -- Rosenbrock 函数的梯度函数x0 -- 初始点,形状为 (2,) 的 NumPy 数组learning_rate -- 学习率,默认为 0.001tol -- 容忍误差,默认为 1e-5max_iter -- 最大迭代次数,默认为 1000返回:x_opt -- 近似最优解,形状为 (2,) 的 NumPy 数组f_values -- 每次迭代的目标函数值,形状为 (num_iter,) 的 NumPy 数组x_values -- 每次迭代的变量值,形状为 (num_iter, 2) 的 NumPy 数组"""x = x0.copy()f_values = []x_values = []for i in range(max_iter):# 记录当前函数值和变量值f_values.append(rosenbrock(x))x_values.append(x.copy())# 计算梯度grad = grad_rosenbrock(x)# 更新变量x_prev = x.copy()x = x - learning_rate * grad# 检查是否收敛if np.linalg.norm(x - x_prev) < tol:break# 将列表转换为 NumPy 数组f_values = np.array(f_values)x_values = np.array(x_values)return x, f_values, x_values# 初始化参数
x0 = np.array([-2, 2])
learning_rate = 0.001
tol = 1e-5
max_iter = 10000# 梯度下降
x_opt, f_values, x_values = gradient_descent(rosenbrock, grad_rosenbrock, x0, learning_rate, tol, max_iter)# 绘制迭代过程
plt.figure(figsize=(12, 5))# 绘制函数值变化
plt.subplot(1, 2, 1)
plt.plot(f_values,color='r')
plt.xlabel('迭代次数')
plt.ylabel('目标函数值')
plt.title('目标函数值变化')# 绘制变量值变化
plt.subplot(1, 2, 2)
plt.plot(x_values[:, 0], x_values[:, 1])
plt.xlabel('x')
plt.ylabel('y')
plt.title('变量值变化')plt.tight_layout()
plt.show()print("最优解为 x =", x_opt)
print("最小值为 f(x) =", rosenbrock(x_opt)) 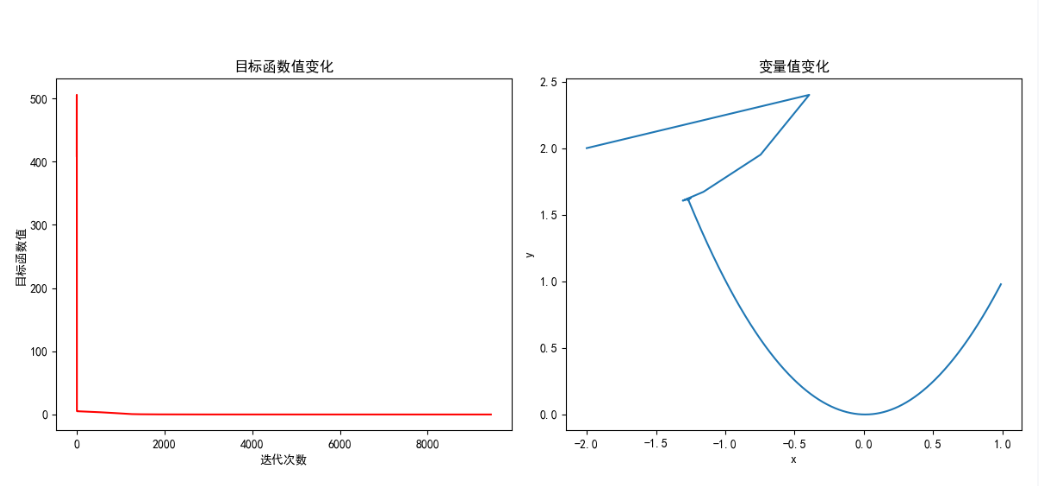
上图左图展示了梯度下降法在优化 Rosenbrock 函数过程中的目标函数值变化情况,随着迭代次数的增加,目标函数值逐渐减小并趋于稳定。右图展示了变量值在迭代过程中的变化轨迹,可以看到变量值逐步逼近最优解 (1, 1)。最终,算法成功找到了近似最优解,验证了梯度下降法在求解非线性规划问题中的有效性。
这一实验不仅加深了我对梯度下降法的理解,也让我对 Rosenbrock 函数的特性有了更直观的认识。通过实践操作,我更加熟练地掌握了如何运用优化算法解决实际问题,为今后在人工智能领域深入探索奠定了坚实基础。资源绑定附上完整资源供读者参考学习!
牛顿法示例:
import numpy as np
import matplotlib.pyplot as pltplt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# 定义目标函数
def f(x):x1, x2 = x[0], x[1]return x1 ** 2 + x1 * x2 + x2 ** 2 + 3 * x1# 定义梯度函数(手动计算偏导数)
def gradient(x):x1, x2 = x[0], x[1]# 对 x1 的偏导数df_dx1 = 2 * x1 + x2 + 3# 对 x2 的偏导数df_dx2 = x1 + 2 * x2return np.array([df_dx1, df_dx2])# 定义Hessian矩阵(手动计算二阶偏导数)
def hessian(x):# Hessian矩阵的元素d2f_dx1x1 = 2 # 对x1的二阶偏导数d2f_dx1x2 = 1 # 对x1和x2的混合偏导数d2f_dx2x2 = 2 # 对x2的二阶偏导数return np.array([[d2f_dx1x1, d2f_dx1x2], [d2f_dx1x2, d2f_dx2x2]])# 牛顿法(仅迭代一次)
def newton_method(initial_point):x = initial_point.copy()# 计算梯度grad = gradient(x)# 计算Hessian矩阵hess = hessian(x)# 计算牛顿步长(梯度的负方向乘以Hessian矩阵的逆)# 牛顿步长:-H^{-1} * gnewton_step = -np.linalg.solve(hess, grad)# 更新 xx_new = x + newton_stepreturn x_new# 参数设置
initial_point = np.array([1.0, 1.0]) # 初始点# 执行牛顿法(仅迭代一次)
new_point = newton_method(initial_point)# 绘制收敛轨迹
def plot_convergence_path(initial_point, new_point):# 创建网格x1 = np.linspace(-5, 5, 100)x2 = np.linspace(-5, 5, 100)X1, X2 = np.meshgrid(x1, x2)Z = X1 ** 2 + X1 * X2 + X2 ** 2 + 3 * X1# 绘制等高线图plt.figure(figsize=(10, 8))plt.contourf(X1, X2, Z, levels=30, alpha=0.5, cmap='viridis')plt.colorbar(label='f(x1, x2)')plt.contour(X1, X2, Z, levels=30, colors='k', alpha=0.3)# 绘制初始点和新点plt.scatter(initial_point[0], initial_point[1], color='r', s=100, label='初始点')plt.scatter(new_point[0], new_point[1], color='g', s=100, label='新点')# 绘制箭头表示移动方向plt.arrow(initial_point[0], initial_point[1],new_point[0] - initial_point[0], new_point[1] - initial_point[1],head_width=0.2, head_length=0.3, fc='b', ec='b', label='牛顿步长')plt.xlabel('x1')plt.ylabel('x2')plt.title('牛顿法收敛路径',font='SimHei',fontsize=20)plt.legend()plt.grid(True)plt.show()# 绘制收敛轨迹
plot_convergence_path(initial_point, new_point)# 输出结果
print(f"初始点: x = {initial_point}")
print(f"经过一次牛顿法迭代后的点: x = {new_point}")
print(f"初始点的目标函数值: f(x) = {f(initial_point)}")
print(f"新点的目标函数值: f(x) = {f(new_point)}")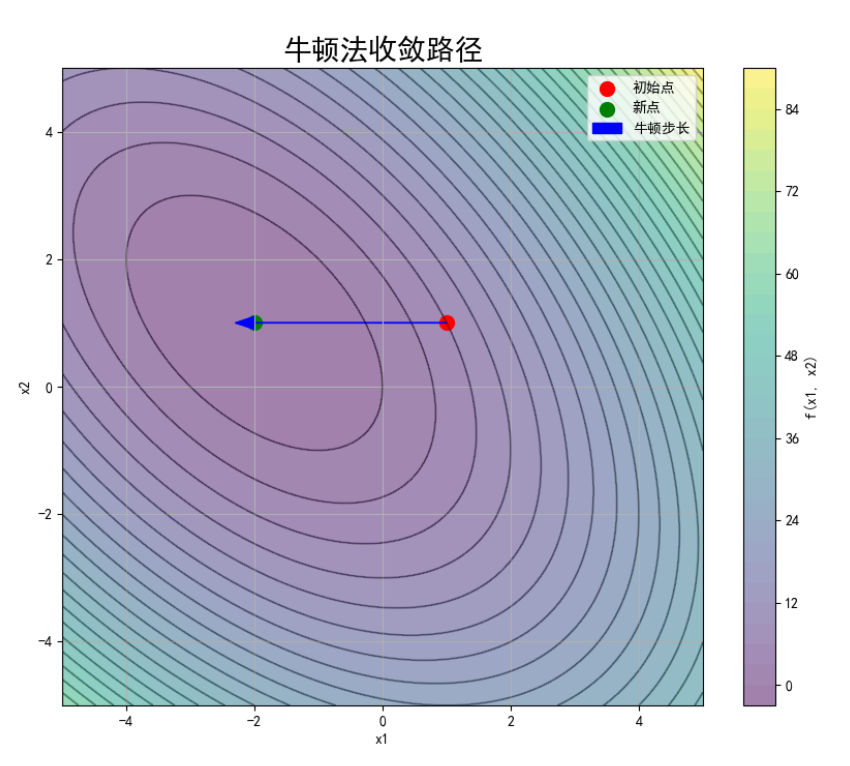
梯度下降法:
import numpy as np
# 可视化迭代过程(可选)
import matplotlib.pyplot as pltplt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# 定义目标函数
def f(x):x1, x2 = x[0], x[1]return x1 ** 2 - 2 * x1 * x2 + 4 * x2 ** 2 + x1 - 3 * x2# 定义梯度函数(手动计算偏导数)
def gradient(x):x1, x2 = x[0], x[1]# 对 x1 的偏导数df_dx1 = 2 * x1 - 2 * x2 + 1# 对 x2 的偏导数df_dx2 = -2 * x1 + 8 * x2 - 3return np.array([df_dx1, df_dx2])# 梯度下降法
def gradient_descent(initial_point, learning_rate, max_iterations, tolerance=1e-6):x = initial_point.copy()history = [x.copy()] # 记录每次迭代的点for iteration in range(max_iterations):grad = gradient(x) # 计算梯度x_prev = x.copy()x = x - learning_rate * grad # 更新 xhistory.append(x.copy())# 检查收敛条件(梯度的模长是否小于容忍度)if np.linalg.norm(grad) < tolerance:print(f"Converged after {iteration + 1} iterations.")breakreturn x, history# 参数设置
initial_point = np.array([1.0, 1.0]) # 初始点
learning_rate = 0.01 # 学习率
max_iterations = 1000 # 最大迭代次数# 执行梯度下降
optimal_point, history = gradient_descent(initial_point, learning_rate, max_iterations)# 输出结果
print(f"最优解: x = {optimal_point}")
print(f"函数f(x)最小值: {f(optimal_point)}")# 绘制函数等高线
x1 = np.linspace(-2, 2, 100)
x2 = np.linspace(-2, 2, 100)
X1, X2 = np.meshgrid(x1, x2)
Z = X1 ** 2 - 2 * X1 * X2 + 4 * X2 ** 2 + X1 - 3 * X2plt.contourf(X1, X2, Z, levels=30, alpha=0.5)
plt.colorbar(label='f(x1, x2)')# 绘制迭代路径
history = np.array(history)
plt.plot(history[:, 0], history[:, 1], 'ro-', markersize=5)
plt.scatter(history[0, 0], history[0, 1], color='b', s=100, label='起始点')
plt.scatter(history[-1, 0], history[-1, 1], color='g', s=100, label='最优解')
plt.xlabel('x1')
plt.ylabel('x2')
plt.title('梯度下降路径')
plt.legend()
plt.show() 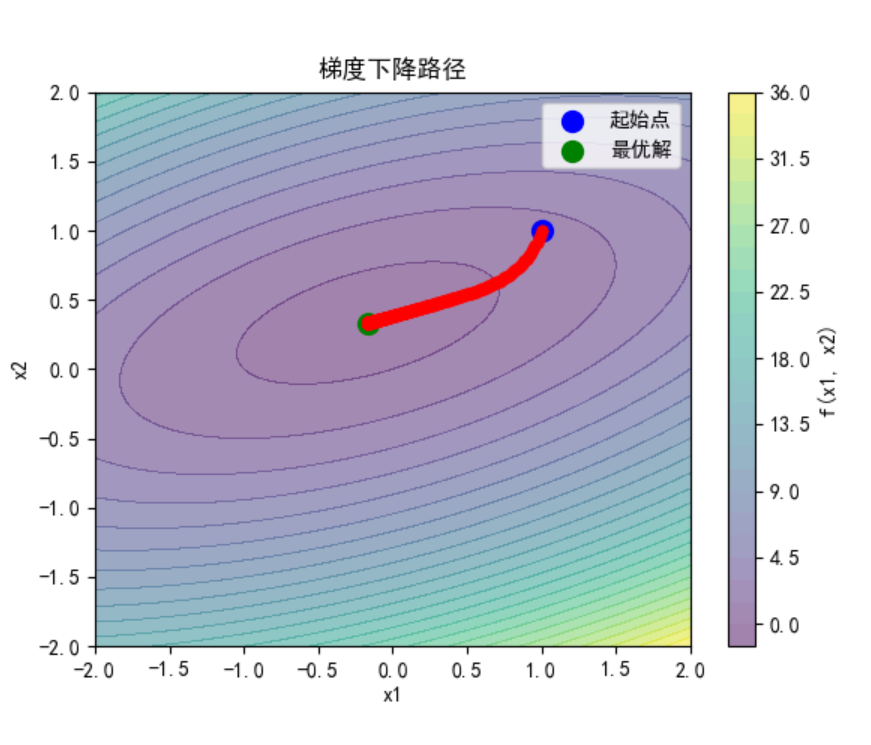
以上就是本期关于最优化理论的全部内容啦!如果你在学习过程中有任何疑问或者想法,欢迎在评论区留言,大家一起交流探讨呀!