DeepSeek-OCR:用图像压缩文本?一种面向长上下文的新思路
DeepSeek-OCR:用图像压缩文本?一种面向长上下文的新思路
引言:为什么我们需要“压缩文本”?
大语言模型(LLM)在处理长文档、长对话时面临一个根本性瓶颈:计算开销随文本长度呈平方级增长。例如,一段 4000 字的对话可能需要 4000 个 token,而 LLM 的注意力机制要对这 4000 个 token 两两计算关联,导致显存爆炸、推理变慢。
传统思路是“剪掉旧内容”或“外接数据库”,但会丢失信息。有没有可能既保留全部内容,又大幅减少 token 数量?
DeepSeek 最新(2025)提出的 DeepSeek-OCR 给出了一个反直觉但有效的答案:把文本“打印成图”,用视觉模态来压缩它。
听起来奇怪?其实这背后是一套严谨的工程设计,核心在于一个名为 DeepEncoder 的新型视觉编码器。本文将用通俗语言解释:它如何工作?为什么有效?以及这种“视觉压缩”到底压缩了什么。
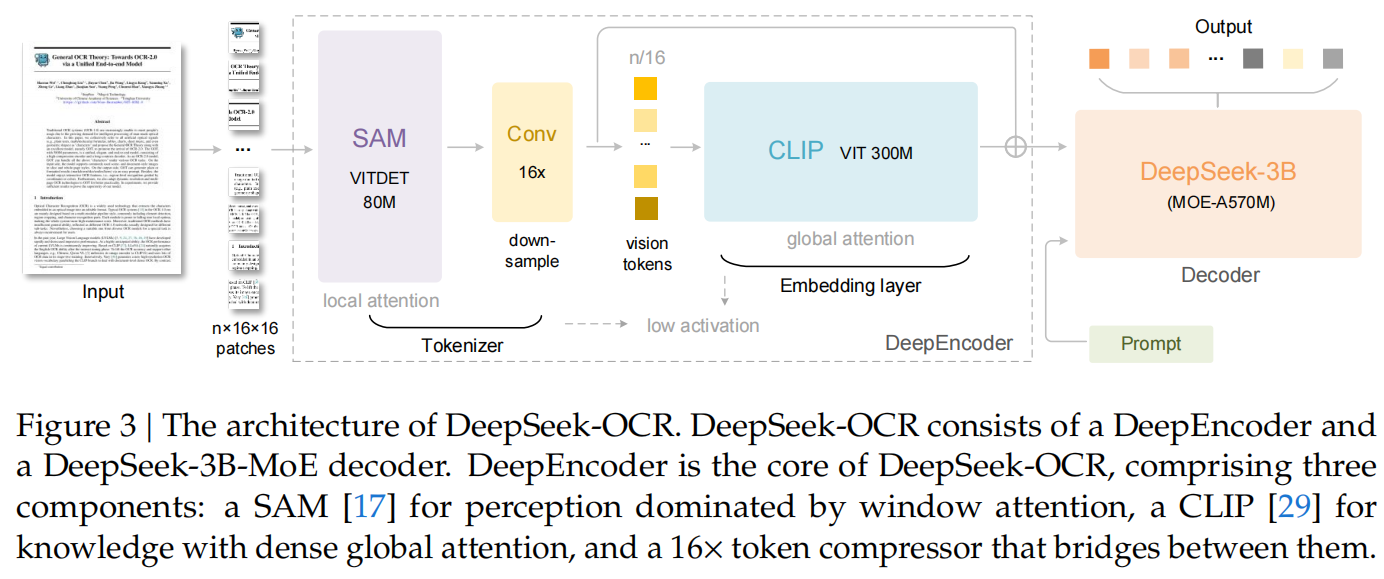
一、DeepEncoder:专为“高分辨率 + 低开销”设计的视觉引擎
DeepSeek-OCR 的核心不是 OCR 本身,而是其视觉编码器 DeepEncoder。它的目标很明确:
在输入高分辨率图像(如 1024×1024)的同时,输出极少的视觉 token(如 256 个),且不爆显存。
现有主流视觉编码器(如 Qwen-VL、InternVL)难以兼顾这三点。DeepEncoder 的解决方案是“分阶段处理”:
阶段 1:看清细节(局部感知)
- 使用 SAM-base(Segment Anything Model 的基础版)作为前端;
- 将 1024×1024 图像切成 64×64 = 4096 个小块(patch);
- 每块变成一个 token,共 4096 个;
- 但不计算全局注意力,而是用 窗口注意力(Windowed Attention)——只在每个 8×8 小窗口内计算关联;
- 好处:能看清小字号、密集排版,同时显存可控。
💡 窗口注意力就像“用放大镜一块一块看”,而不是“一眼扫全图”。
阶段 2:压缩 token(卷积下采样)
- 通过一个两层卷积网络(每层 stride=2),将空间尺寸从 64×64 压缩到 16×16;
- token 数从 4096 → 256,压缩 16 倍;
- 关键:这不是模糊图像,而是保留结构信息的语义压缩(如行、列、表格线)。
阶段 3:理解语义(全局建模)
- 将 256 个压缩后的 token 输入 CLIP-Large(一个强大的预训练视觉模型);
- CLIP 使用全局注意力,理解整个文档的结构(如“这是表格”“这是公式”);
- 输出最终的 256 个高语义视觉 token,供语言模型解码。
整个流程:局部看清 → 高效压缩 → 全局理解。
总参数约 380M,但训练时可冻结前端,仅微调 CLIP 部分,兼顾效率与性能。
二、视觉 token 真的能“代替”多个文本 token 吗?
是的,但仅限于结构化文档(如 PDF、论文、财报、表格)。原因如下:
1. 文本表示 vs 视觉表示:谁更“啰嗦”?
- 文本表示:要描述一个表格,需写
<table><tr><td>A</td><td>B</td></tr>...,大量格式 token; - 视觉表示:表格就是一张图,行列对齐、字体大小等信息天然存在于像素中,无需额外说明。
✅ 视觉表示把“内容 + 结构”一体化编码,文本表示则需分开描述。
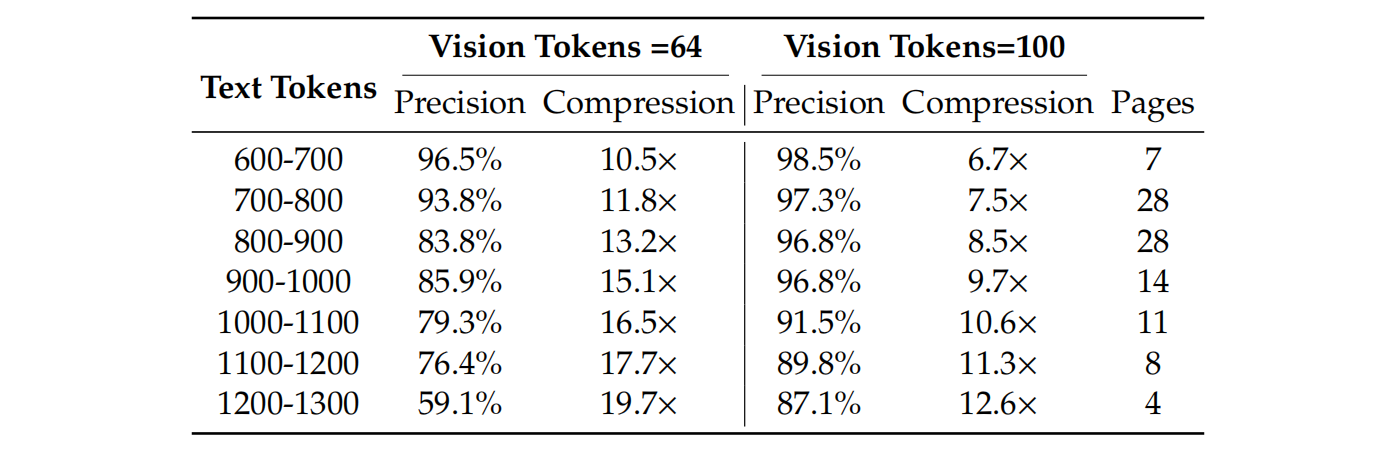
2. 实验证明:10 倍压缩仍高精度
论文在 Fox benchmark 上测试:
- 用 100 个视觉 token(640×640 图像)还原 ~700–1000 个文本 token;
- OCR 精度达 97%+;
- 即使压缩到 20 倍(256 视觉 token → 5000 文本 token),精度仍有 ~60%。
这意味着:一个视觉 token 平均可代表 7–10 个文本 token(在结构化文档中)。
3. 但对纯文本无效
如果是无格式小说、聊天记录等纯自然语言,渲染成图后只是“一整块文字”,没有结构优势,反而可能因字号小而模糊。此时,直接用文本 token 更高效。
📌 结论:视觉压缩的优势来自“排版结构”,不是图像本身。
三、这项技术意味着什么?
1. 为 LLM 长上下文提供新路径
- 可将历史对话渲染为图像,实现“光学记忆”;
- 近期对话用高分辨率(高保真),远期对话用低分辨率(模糊化);
- 自然模拟人类“记忆遗忘”机制(见论文图 13)。
2. 极大提升 OCR 实用性
- 在 OmniDocBench 上:
- 仅用 100 视觉 token,超越 GOT-OCR2.0(256 tokens);
- 用 <800 tokens,超越 MinerU2.0(~7000 tokens);
- 支持表格、公式、图表、多语言等“OCR 2.0”任务;
- 生产级效率:单 A100-40G 日处理 20 万+ 页面。
3. 推动 VLM 架构演进
- 视觉模态不再只是“看图说话”,而是成为 LLM 的“压缩记忆模块”;
- 未来智能体可能同时拥有“文本思维”和“视觉记忆”。
四、实际应用场景(来自论文)
DeepSeek-OCR 不仅是研究原型,更是高度实用的工程系统,已在多个场景落地:
1. 大规模训练数据生产
- 日处理 3300 万页(20 节点,每节点 8×A100-40G);
- 为 LLM/VLM 预训练提供高质量结构化文本数据。
2. OCR 2.0:结构化解析(Deep Parsing)
- 图表 → HTML 表格;
- 化学式 → SMILES 字符串;
- 几何图 → 坐标字典;
- 自然图像 → 密集描述 + grounding。

3. 多语言文档处理
- 支持 近 100 种语言,包括阿拉伯语、僧伽罗语等低资源语言;
- 通过“模型飞轮”策略构建小语种标注数据。
4. 长上下文压缩与记忆模拟
- 通过调整渲染分辨率,实现多级压缩;
- 近期内容高保真,远期内容自动“遗忘”,无需额外设计。


五、局限与边界
- 依赖高质量渲染:低分辨率扫描件、手写体效果差;
- 非端到端可微:文本→图像为离散过程,无法联合优化;
- 不适用于纯文本场景;
- 仍需 GPU 支持高分辨率图像处理。
结语
DeepSeek-OCR 并非宣称“图像比文本更高效”,而是揭示了一个重要事实:
在结构化信息场景下,视觉表示格式能以更少的 token 承载更丰富的语义。
DeepEncoder 的设计,正是为了最大化这一优势。它不仅是一个高性能 OCR 系统,更是一次对“如何高效表示信息”的重新思考。在 LLM 面临长上下文瓶颈的今天,这种“用空间换序列”的思路,或许正是通往下一代智能体记忆架构的关键一步。
代码与模型已开源:http://github.com/deepseek-ai/DeepSeek-OCR