python基础知识2
1. 函数
定义:是一个封装了特定逻辑的可重复使用的代码块,它的核心作用是接收输入、执行预定操作,然后返回结果(或执行特定动作)
def func():passpass :是 Python 中的一个 “空语句”,它的作用是占位(表示 “这里暂时没有具体代码”),避免因函数体为空而导致语法错误。
1.1 带参数的函数
(name) 表示这个函数需要接收一个参数(输入),name 是 “形式参数”(简称 “形参”),相当于一个变量,用于接收调用时传入的值。
“AMY"是实际参数。实参
def func(name):print(f"名字是{name}")func("AMY")1.2 return
在 Python 函数中,return 是一个关键字,用于指定函数执行完毕后返回的结果,同时会终止函数的执行(return 后的代码不会被运行)
#基本用法
def add(a,b):return a+b#res = add(1,1)
#print(res)
print(add(1,1))#没有return的函数
def say_hello():print("hello")res = say_hello() #hello
print(res) #None
#如果函数中没有 return,或者 return 后没有值,函数默认返回 None(表示 “无结果”)#return终止函数
def score(num):if num < 10 :return "垃圾"if num == 10 :return "大垃圾"else :return "一般般"s = score(10)
print(s) #大垃圾#返回多个值
# return 可以同时返回多个值(本质是返回一个元组),调用时可以用多个变量接收(解包)
def func():name = "lily"age = 10return name, agename,age = func()
print(name,age)
# lily 10注意:位置参数必须关键字参数之前
1.3 关键字参数
关键字参数是指通过 “参数名=值” 的形式传递的实际参数(实参)。它的核心作用是明确指定每个值对应的形式参数(形参)
def func(name,age,city):print(f"{name}已经{age}岁,来自{city}")func("小红",age = 11, city = "上海")
# 小红已经11岁,来自上海在 Python 中,函数参数列表里的 ** 斜杠(/)** 是一个语法标记(Python 3.8 及以上版本支持),用于明确:斜杠左侧的参数,只能通过「位置参数」的形式传递,不能用「关键字参数」(即不能写成 参数名=值 的形式)。

函数参数列表中的 * 是一个特殊分隔符,它的作用是:* 之后的参数(此处为 b 和 c)必须以「关键字参数」的形式传递(即调用时必须写成 参数名=值 的形式,不能用位置参数)。
这个星号其实就是一个匿名的收集参数,后面不加参数名的话会被一起收进去
def abc(a,*,b,c):print(a,b,c)1.4 *args
*args 是一种用于灵活接收任意数量位置参数的语法
1.4.1 基本作用:收集任意位置参数为元组
函数定义时,*args 会把调用时传入的所有额外位置参数打包成一个元组
def func(*args):total = 0for i in args :total += iprint(total)func(1,2,3,4,5)1.4.2 与普通参数结合使用(位置参数在前)
*args 必须放在普通位置参数之后,这样普通参数会优先匹配,剩余的位置参数才会被 *args 收集
def func(size,*food):print(f"制作{size}寸pizza,配料是什么")for i in food:print("{}".format(i))func(12, "蘑菇", "芝士", "火腿")1.4.3 顺序
函数参数的顺序必须遵循:普通位置参数 → *args → 关键字参数 → **kwargs
1.4.4 调用时解包序列(列表 / 元组)给 *args
如果已有一个序列(如列表、元组),调用函数时可以用 * 把序列解包成多个位置参数,传给 *args
可以把 * 理解为 “拆分 / 解包” 的操作符,它的作用是把一个序列(列表、元组等)拆成多个独立的元素,然后作为位置参数传给函数。结合 *args 来看,其实是 “解包” 和 “打包” 的配合
def func(*fruit):print("今天吃的水果有:",fruit)func(["草莓", "葡萄", "西瓜"])
# 今天吃的水果有: (['草莓', '葡萄', '西瓜'],)
# 调用是 func(["草莓", "葡萄", "西瓜"]) —— 这里是 ** 把整个列表当作「一个参数」** 传给 func。
# 因为函数定义是 def func(*fruit):(*fruit 会把传入的多个位置参数打包成元组),
# 所以此时 fruit 会被打包成:(['草莓', '葡萄', '西瓜'],)(元组里只有一个元素,就是这个列表)func(*["草莓", "葡萄", "西瓜"])
# 今天吃的水果有: ('草莓', '葡萄', '西瓜')
# 在调用函数时,给序列前面加 *,让列表被拆成多个独立参数注意:
传入实际参数的列表前面加不加*的区别
1.5 **kwargs
它允许函数接受任意数量的关键字参数,并将这些参数收集到一个字典中
在函数定义时,** 后面跟一个参数名(习惯上用 kwargs,全称是 keyword arguments,但也可以是其他合法变量名,比如 **options、**extra_args 等 )。当函数被调用时,所有以 键=值 形式传入的关键字参数,都会被打包到这个字典中,键就是参数名,值就是对应传入的参数值
def func(**kwargs):print(kwargs)print(type(kwargs))func(name = 'amy' , age = 20)
# {'name': 'amy', 'age': 20}
# <class 'dict'>普通参数、*args、**kwargs
def func(a,*b,**c):print(a)print(b)print(c)func(1,2,3,name = "lily")
# 1
# (2, 3)
# {'name': 'lily'}1.5.1 在函数内部操作 kwargs
def func(**k):for key in k :print(key)print(k[key])print(k.get(key))for value in k.values():print(value)print(k.items()) #dict_items([('name', 'amy'), ('age', 11), ('city', 'sz')])func(name = "amy" , age = 11 , city = "sz")def connet_datebase(**config):host = config.get('host','localhost')port = config.get('port','3306')user = config.get('user')password = config.get('password')connet_datebase(host="192.168.1.100", user="admin", password="secret") 字典的 get 方法有两个关键参数:
第一个参数 'host':要从 config 中查找的键(key)
第二个参数 'localhost':默认值(default) —— 当 config 中不存在 'host' 这个键时,就会返回这个默认值
如果 config 中不存在 'host' 键(比如配置文件没写 host,或字典里没有这个键),则 host 会被赋值为默认值 'localhost'
1.5.2 解包字典作为 kwargs 传入
user_info = {"name": "David","age": 28,"email": "david@example.com"
}def func(**user_info):print(user_info)func(**user_info)
1.6 作用域
Local → Enclosing → Global → Builtins
规定了解释器在查找一个变量时,按照「局部 → 嵌套 → 全局 → 内置」的顺序依次搜索,直到找到目标变量为止。优先使用 “最内层” 作用域的变量
| 作用域类型 | 定义与特点 | 示例场景 |
|---|---|---|
| Local(局部) | 变量定义在函数 / 方法内部,仅在函数执行期间可见,执行完毕后销毁。 | 函数内的临时计算变量 |
| Enclosing(嵌套 / 闭包) | 出现在嵌套函数中,内层函数可访问外层函数的变量(需 nonlocal 才能修改)。 | 闭包(保留外层函数的状态) |
| Global(全局) | 变量定义在模块(.py 文件)顶层,对整个模块可见。 | 模块级的配置、共享变量 |
| Builtins(内置) | Python 解释器内置的函数 / 对象(如 print、len、int、内置异常等),全局可直接访问。 | 直接使用 Python 内置功能 |
1.6.1 局部作用域(Local)
函数 / 方法内部定义的变量,属于 “临时作用域”
函数调用时创建,执行完毕后销毁
函数内赋值的变量默认视为局部变量,外部无法访问
def local_demo():local_var = "我是局部变量"print(local_var) # 函数内可访问 → 输出:我是局部变量local_demo()
# print(local_var) # 报错:NameError(外部不可见)1.6.2 嵌套作用域(Enclosing)
当函数嵌套时,外层函数的作用域对 “直接内层函数” 可见(但内层默认不能修改外层变量,需 nonlocal)
如果第二层函数使用第一层函数的变量没有加nonlocal就会报错
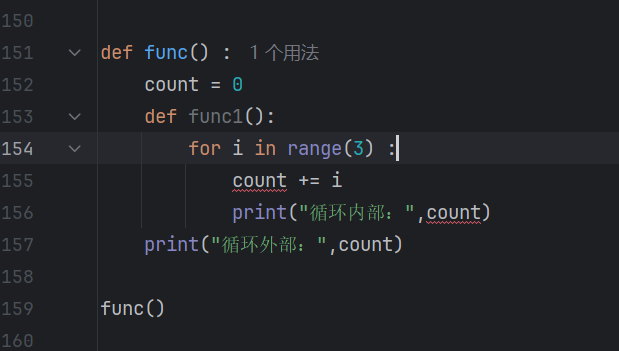
def func() :count = 0def func1():for i in range(3) :nonlocal countcount += iprint("循环内部:",count)print("循环外部:",count)return func1a = func()
a()#第二种写法
def func() :count = 0def func1():for i in range(3) :nonlocal countcount += iprint("循环内部:",count)print("循环外部:",count)return func1func()()
注意:
当我们进行双重函数嵌套时,我们需要将内部方法暴露出来,这样他才会被执行。意思是
我们需要返回第二个函数,并且用一个变量来接收第二个函数。所以变量a是func1,是一个函数。所以才会有a().
a不是一个值,是函数
返回func1时不加小括号,是因为小括号只有在定义函数和方法才会使用,这里返回的是名字
第二种写法:
def func() :count = 0def func1():for i in range(3) :nonlocal countcount += iprint("循环内部:",count)print("循环外部:",count)func1()func()
1.6.3 全局作用域(Global)
模块(.py 文件)顶层定义的变量,对整个模块的所有函数、类可见
函数内直接赋值全局变量时,Python 会默认创建 “同名局部变量”(遮蔽全局变量);若要修改全局变量,需用 global 声明
global_var = "我是全局变量"def access_global():print(global_var) # 函数内可直接访问全局变量access_global() # 输出:我是全局变量
print(global_var) # 模块外部也可访问 → 我是全局变量global_var = 10def modify_global():global global_var # 声明:此变量是全局变量global_var = 20 # 修改全局变量modify_global()
print(global_var) # 输出:20(全局变量被修改)1.6.4 内置作用域(Builtins)
Python 解释器自带的函数、对象(如 print、len、range、ValueError 等),属于 “最高级作用域”
无需导入,全局可直接使用;应避免覆盖内置名称(如不要把变量命名为 print)
print(len("hello")) # 直接使用内置函数 len → 输出:5
print(range(3)) # 直接使用内置类 range → 输出:range(0, 3)1.7 闭包
闭包的核心:“函数 + 它需要的外部变量 = 带记忆的工具”
想象你要去旅行:
外层函数 → “打包行李” 的过程(准备你需要的 “变量”,比如相机、护照)
内层函数 → “旅行时用这些物品的动作”(用相机拍照、用护照通关)
闭包 → “打包好的行李 + 使用行李的动作”(行李里的物品不会因为 “打包完了” 就消失,旅行时还能继续用)
def func(exp):def sum(base):return base ** expreturn suma = func(2)
b = func(3)
print(a(1))
print( b(2))1.8 装饰器
把函数当参数传递,增强其他函数的行为” 的思路,是 Python 装饰器(Decorator) 的核心基础
def myfunc():print('正在调用程序')def report(a):print("开始的调用函数")a()print("结束")report(myfunc)# 开始的调用函数
# 正在调用程序
# 结束
装饰器是不修改原函数代码,却能给函数添加额外逻辑(比如日志、计时、权限校验等)
假设你有个「做早餐」的流程,现在想给它加「洗碗(前置准备)」和「擦桌子(后置收拾)」的动作,但不想改动「做早餐」本身的步骤
装饰器就像一个“流程包装器”:把「做早餐」包进去,自动在前后插入新动作
def report(a):print("开始的调用函数")a()print("结束")@report
def myfunc():print('正在调用程序') Python 解释器执行到 @report 这一行时,会自动做两件事:
定义 myfunc 函数(先把函数体 “存起来”)
立即调用 report(myfunc)(把刚定义的 myfunc 传给 report 函数)
正常装饰器会返回一个新函数,而这里的 report 没有返回值(默认返回 None)
执行完 myfunc = report(myfunc) 后,myfunc 其实变成了 None(不再是函数)。如果你之后尝试 myfunc(),会报错(因为 None 不能被调用)。
#计时器
def func(x):def func1(*a,**b):start = time.time()res = x(*a,**b)end = time.time()print(end - start,'攻击多少秒')return res #保留被装饰函数的返回值,确保调用装饰后的函数时,能拿到和原函数一样的结果return func1@func
def func3(n):time.sleep(2)return n ** n# 没有 return res 会丢结果,没有 return func1 装饰器根本用不了1.8.1 最基础的装饰器(无参数,无返回值)
#最基础的装饰器,无参数、无返回值
def simple(func):def wrapper():print("开始")func()print("结束")return wrapper@simple
def heelo():print("hello")#最基础的装饰器,无参数、无返回值
def simple(func):def wrapper():print("开始")func()print("结束")return wrapper#@simple
def heelo():print("hello")heelo = simple(heelo)
print(heelo)
# 代码中通过 heelo = simple(heelo) 手动完成了装饰器的绑定(等价于 @simple 语法),
# 此时变量 heelo 已不再指向原 heelo 函数,而是指向装饰器 simple 内部定义的 wrapper 函数
# 最后一行 print(heelo) 打印的是 heelo 变量指向的函数对象本身(而非调用函数)
# ,因此会输出该函数的类型、所在作用域(simple.<locals>)和内存地址#最基础的装饰器,无参数、无返回值
def simple(func):def wrapper():print("开始")func()print("结束")return wrapper# 将包装后的函数(wrapper)返回,让原函数名指向这个新的包装函数,# 从而实现对原函数的 “增强@simple
def heelo():print("hello")
#
# 如果不写 return wrapper 会怎样
# @simple 等价于 heelo = simple(heelo)。
# 但 simple 函数没有返回值(默认返回 None),所以 heelo 会被赋值为 None。
# 当你调用 heelo() 时,会直接报错(NoneType is not callable),因为 heelo 已经不是一个函数了wrapper 函数内部的逻辑(打印 “开始”、调用原函数、打印 “结束”),只有在调用被装饰后的 heelo 函数时才会执行
装饰器只是 “包装” 了函数,并没有自动执行它。必须显式调用 heelo(),才会触发 wrapper 的执行
#把函数比作 “工具”,装饰器比作 “改造工具的工厂”
def func(x):def factory():print("开始改造锤子")x()print("锤子改造完成")return factory@func
def hammer():print("锤子的作用是敲钉子")#hammer 这个名字不再指向原函数,而是指向这个新返回的 factory 函数
hammer()
#所以hammer= func(hammer)
#把当前 hammer 标签所指的 “原函数”,传给 func 函数处理。
#然后,把 func 函数的返回值,重新赋值给 hammer 标签(即标签换地方1.8.2 装饰带参数的函数(适配任意参数)
def param(func):def wrapper(*args,**kwargs):print("接受的参数是",f'{args},{kwargs}')res = func(*args,**kwargs)print('end')return resreturn wrapper@param
def sum(a,b):return (a+b)a = sum(1,2)
print(a)
# 执行 a = sum(1,2) 时:
# sum(1,2) 实际调用的是装饰器中的 wrapper(1,2)(因为 @param 装饰后,sum 指向 wrapper)。
# wrapper 函数内部会按顺序执行:
# 先打印 接受的参数是 (1, 2),{}(第一步输出);
# 调用原 sum 函数计算 1+2=3,存到 res;
# 再打印 end(第二步输出);
# 最后返回 res(即 3)。
# 因此,a 被赋值为 3,但此时控制台已经输出了前两行内容\#第二种写法
def param(func):def wrapper(*args,**kwargs):print("接受的参数是",f'{args},{kwargs}')res = func(*args,**kwargs)print('end')return wrapper@param
def sum(a,b):print(a+b)sum(1,2)1.8.3 带参数的装饰器(装饰器本身有参数)
装饰器可以自定义 “前缀文本”,比如打印日志时指定前缀是 "INFO" 还是 "DEBUG"
def first(prefix):def second(func):def third(*a,**kw):print(f"{prefix},开始")print(f"{prefix},结束")return func(*a, **kw)return thirdreturn second#最外层函数必须返回中层函数(即 return decorator)@first(prefix = 'INFO')
def func1(x,y):return x ** yres = func1(1,2)
print(res)
# INFO,开始
# INFO,结束
# 1# 带参数的装饰器需要三层结构:
# 最外层函数:接收参数(如 prefix)。
# 中间层函数:接收被装饰的函数(如 func)。
# 最内层函数:实现装饰逻辑(如打印日志)。
# 且最外层函数必须返回中间层函数,否则会返回 None,导致装饰器调用失败def first(prefix):def second(func):def third(*a,**kw):print(f"{prefix},开始")res = func(*a, **kw)print(f"{prefix},结束")return resreturn thirdreturn second#最外层函数必须返回中层函数(即 return decorator)@first(prefix = 'INFO')
def func1(x,y):print( x ** y)func1(1,2)
# INFO,开始
# 1
# INFO,结束def choose_color(color): # 第一步:选颜色(接收参数)def add_case(func): # 第二步:生成“套该颜色壳”的工具(第二层函数)def wrapper(): # 套好壳的手机print(f"套上{color}的手机壳")func() # 保留原功能return wrapper # 返回“套好壳的手机”return add_case # 关键:返回“套该颜色壳的工具”@choose_color(color = 'red')
def phone():print("手机可以打电话")phone()# 第一步:choose_color("red") 必须返回 add_case(套红色壳的工具),否则拿不到工具
# @choose_color(color='red') 等价于手动执行两步操作:
# 先调用 choose_color(color='red'),得到返回值 add_case(即 “套红色壳的工具”);
# 再用这个 add_case 装饰 phone 函数,即 phone = add_case(phone)。
# 等价于 @choose_color(color='red') 的手动操作
# decorator = choose_color(color='red') # 第一步:获取装饰器(add_case)
# phone = decorator(phone) # 第二步:用装饰器装饰原函数1.9 lambda 匿名函数
格式: lambda 参数1, 参数2, ... : 表达式
参数1, 参数2, ...:接收的参数(数量任意,也可无参数)
表达式:函数的核心逻辑,必须是单个表达式,计算结果会自动作为返回值(无需写 return)
res = lambda a : a * a
print(res(3))res = lambda a,b : a * b
print(res(2,3))直接调用(无需赋值给变量)
如果函数仅用一次,可直接定义并调用:
res = (lambda a,b : a ** b)(3,3)
print(res)无参数或带默认参数
无参数的匿名函数:
res = lambda :"hello"
print(res())lambda: "hello" 定义的是一个 “函数”,而不是直接返回 “hello” 这个值。res 是一个函数对象,须通过加括号() 才能 “被调用”
map():对可迭代对象的每个元素做相同操作
例如,将列表中每个数加 1:
map 函数的作用是:将第一个参数(函数)依次应用到第二个参数(可迭代对象,如列表 nums)的每个元素上,但它返回的是一个 “迭代器”(惰性计算的对象),而非立即生成结果列表
map 返回的是 “迭代器”,它不直接存储结果。直接打印迭代器,只能看到它的 “身份信息”(如内存地址),看不到具体内容,所以这里会有print(list(res)),一个list
res = map(lambda x : x +1,nums )
print(list(res))迭代器只能用一次:迭代器是 “一次性的”,遍历完就空了
nums = [1, 2, 3]
res = map(lambda x: x+1, nums)# 第一次遍历迭代器(能得到结果)
for num in res:print(num) # 输出 2、3、4# 第二次遍历(已经空了,什么都没有)
for num in res:print(num) # 无输出sorted():自定义排序规则
sorted(iterable, key=None, reverse=False) 的核心功能是对 iterable(可迭代对象,如列表)中的元素排序
students = [{"name": "Alice", "age": 20}, {"name": "Bob", "age": 18}]
res = sorted(students,key = lambda s: s['age'])
print(res)def get_age(s):return s["age"]sorted_students = sorted(students, key=get_age) # 和用lambda效果完全一样闭包场景:捕获外部变量
def func(n):return lambda x : x * nres = func(2)(3)
print(res)1.10 生成器
一种特殊的 “迭代器”,它能逐步生成值(而非一次性生成所有值),从而极大节省内存,尤其适合处理大数据量或无限序列
- 按需生成:用的时候才生成下一个值,不提前占用内存
- 迭代性:生成器本身是 “迭代器”,支持 for 循环、next() 调用
- 状态保留:执行过程中可以 “暂停” 和 “恢复”,记住当前的执行位置和变量状态
普通函数用 return 返回值后会结束执行,而生成器函数用 yield 关键字 “暂停并返回” 值,下次调用时从暂停处继续执行
def fib(n):a,b = 0,1 # ① 这一行还没执行!for i in range(n): # ② 这一行也没执行!yield a #③ 关键:每次执行到这里会暂停a,b = b,a+bres = fib(5) #调用生成器函数,返回生成器对象(此时函数内部一行代码都没执行)
print(res)
# <generator object fib at 0x0000017EC8F6F3D0>
# fib(n) 是生成器函数,res = fib(5) 返回的是生成器对象,直接打印只能看到对象信息
# 调用生成器函数时,它不会立即执行,
# 而是返回一个 “生成器对象”(比如你的 res = fib(5) 得到的就是生成器对象)。
# 只有通过 迭代(比如用 next() 函数或 for 循环),生成器函数才会逐步执行def fib(n):a,b = 0,1for i in range(n):yield aa,b = b,a+bres = fib(5)
# for i in list(res):
# print(i)
print(next(res))
print(next(res))
print(next(res))
print(next(res))
print(next(res))# 生成器开始执行 fib(5) 内部代码:
# 先执行 a, b = 0, 1(初始化 a=0,b=1);
# 进入 for i in range(5) 循环,第一次循环 i=0;
# 执行到 yield a,返回 a=0,然后暂停(记住当前状态:a=0,b=1,i=0,下次从 yield 的下一行开始)。
# 结果:返回 0。
#
# 第二次调用 next(res)
# 生成器从上次暂停的位置(yield a 的下一行)恢复:
# 执行 a, b = b, a + b → 计算后 a=1(原 b 的值),b=0+1=1;
# 循环进入下一次,i=1;
# 执行到 yield a,返回 a=1,再次暂停(状态:a=1,b=1,i=1)。
# 结果:返回 1。yield 会 “暂停” 函数执行,并保存当前的变量状态。下次迭代时,函数会从 yield 的下一行继续运行,而不是从头开始
什么时候需要用 yield?
- 数据量大:当需要生成百万 / 千万级数据时,用 yield 避免内存爆炸
- 无限序列:比如实时数据流、无限计数器,只能用 yield 实现
- 按需处理:数据需要逐个处理(而非一次性处理)时,用 yield 更高效(比如读取大文件时一行一行处理)
yield 的核心是让函数从 “一次性返回所有结果” 变成 “边生成边返回”
1.11 递归
函数自身调用自身
- 终止条件(Base Case):存在一个或多个 “最小子问题”,可以直接返回结果(防止无限递归)
- 递归关系(Recursive Relation):原问题可以分解为 “与原问题结构相同但规模更小的子问题”,且子问题的解可以组合成原问题的解
- 递”(分解):函数不断调用自身,将原问题分解为更小的子问题,直到达到 “终止条件”
- “归”(合并):从 “终止条件” 的结果开始,逐步回溯,合并子问题的解,最终得到原问题的解
def func(n):if n == 1 :return 1else:return n*func(n-1)print(func(5))# 回溯合并结果(从最底层向上计算)
# factRecur(2) = 2 × factRecur(1) = 2 × 1 = 2
# factRecur(3) = 3 × factRecur(2) = 3 × 2 = 6
# factRecur(4) = 4 × factRecur(3) = 4 × 6 = 24
# factRecur(5) = 5 × factRecur(4) = 5 × 24 = 120
# 假设你要计算 5!(5 的阶乘),但你只知道 “自己的数 × 下一个数的阶乘”,于是开始传话接力:
# 你(计算 factRecur(5)):“我不知道 5! 是多少,但我知道 5! = 5 × 4!。所以我需要问下一个人:4! 是多少?”(此时,你暂停等待 4! 的结果,然后才能算出 5!。)
# 第二个人(计算 factRecur(4)):“我不知道 4! 是多少,但我知道 4! = 4 × 3!。所以我需要问下一个人:3! 是多少?”(同样暂停,等 3! 的结果。)
# 第三个人(计算 factRecur(3)):“我不知道 3! 是多少,但我知道 3! = 3 × 2!。所以我需要问下一个人:2! 是多少?”(继续暂停,等 2! 的结果。)
# 第四个人(计算 factRecur(2)):“我不知道 2! 是多少,但我知道 2! = 2 × 1!。所以我需要问下一个人:1! 是多少?”(还是暂停,等 1! 的结果。)
# 第五个人(计算 factRecur(1)):“哦,我知道!1! 就是 1,所以我直接回复:1。”
# 回溯:把结果 “传回来”
# 现在,每个人拿到了下一个人的结果,开始反向计算自己的结果:
# 第四个人(factRecur(2)):“我之前说 2! = 2 × 1!,现在知道 1! = 1,所以 2! = 2 × 1 = 2。我回复:2。”
# 第三个人(factRecur(3)):“我之前说 3! = 3 × 2!,现在知道 2! = 2,所以 3! = 3 × 2 = 6。我回复:6。”
# 第二个人(factRecur(4)):“我之前说 4! = 4 × 3!,现在知道 3! = 6,所以 4! = 4 × 6 = 24。我回复:24。”
# 你(factRecur(5)):“我之前说 5! = 5 × 4!,现在知道 4! = 24,所以 5! = 5 × 24 = 120。最终结果是 120。”优点:
代码简洁:直接映射数学定义或问题的递归结构(如阶乘、树的遍历),可读性高。
解决复杂问题:适合处理 “天然具有递归结构” 的问题(如二叉树、分治算法、回溯算法)。
缺点:
性能开销:每次递归调用会在内存栈中保存函数状态(参数、局部变量等),可能导致栈溢出(递归深度过深时)。
重复计算:部分递归(如未优化的斐波那契)会重复计算相同的子问题,效率低(可通过 “备忘录” 优化)
def fib(n):# 终止条件if n == 0:return 0if n == 1:return 1# 递归关系:分解为两个更小的子问题return fib(n - 1) + fib(n - 2)print(fib(5)) # 输出:5(序列:0,1,1,2,3,5)1.12 内省
程序在运行过程中,能够 “检查自身结构、属性、类型等信息” 的能力 —— 简单说,就是让程序具备 “自我观察” 的本领,知道自己 “是什么、有什么、能做什么”
1. 查看 “对象类型”
用 type() 或 isinstance() 检查对象的类型
print(type(3.14)) # 输出:<class 'float'>
print(isinstance([1,2,3], list)) # 输出:True2. 列出 “所有属性 / 方法”
用 dir() 列出对象的全部属性和方法(返回字符串列表):
print(dir("python")) # 列出字符串的所有方法,如 'upper', 'split' 等3. 检查 “属性是否存在”
用 hasattr()、getattr()、setattr() 操作对象的属性:
obj = "hello"
print(hasattr(obj, "replace")) # 检查是否有replace方法 → True
print(getattr(obj, "replace")("l", "X")) # 调用replace → "heXXo"4. 探索 “模块 / 类的内部”
查看模块内容、类的继承关系等:
import random
print(dir(random)) # 列出random模块的所有函数(如 'randint', 'choice')class Fruit: pass
class Apple(Fruit): pass
print(Apple.__bases__) # 查看Apple的父类 → (<class '__main__.Fruit'>,)5. 获取对象的名称 __name__
times.__name__
1.13 高价函数
既能接收函数作为参数,又能返回函数作为结果的函数
核心特点是:将 “函数” 视为一种 “数据”,可以像整数、列表等普通数据一样被传递、操作和返回
高阶函数必须满足以下至少一个条件:
- 接收函数作为参数(用函数来控制逻辑)
- 返回函数作为结果(动态生成新的函数
1.13.1 reduce
是 Python 中用于累积计算的高阶函数,属于 functools 模块,核心功能是:将一个接收两个参数的函数反复应用于可迭代对象的元素,从左到右依次累积,最终得到一个单一结果
#以前reduce也是,现在不是了
def add(x,y):return x+y
import functools
res = functools.reduce(add,[1,2,3,4,5])
#相当于
#add(add(add(add(1,2),3),4),5)
print(res)res = functools.reduce(lambda x,y :x*y,[1,2,3,4,5])
print(res)
res = functools.reduce(lambda x,y :x*y,range(1,11))
print(res)1.13.2. 内置高阶函数 map()
map(func, iterable) 接收一个函数 func 和一个可迭代对象(如列表),对可迭代对象的每个元素应用 func,返回结果的迭代器
res = map(lambda x,y : x * y ,(1,),(2,))
print(list(res))res = map(lambda x,y : x * y ,[1],[2])
print(list(res))res = map(lambda x,y : x * y , [1, 3], [2, 4])
print(list(res))
# [2, 12]1.13.3. 内置高阶函数 filter()
filter(func, iterable) 接收一个 “返回布尔值的函数 func” 和可迭代对象,保留 func 返回 True 的元素,返回结果的迭代器
def ou(x):return x % 2 == 0nums = [1,2,3,4,5,6]
res = filter(ou,nums)
print(list(res))
# [2, 4, 6]nums = [1, 2, 3, 4, 5, 6]
res = filter(lambda x : x if (x % 2 == 0) else False,nums)
print(list(res))1.13.4 内置高阶函数 sorted()
sorted(iterable, key=func) 接收一个 “用于计算排序依据的函数 func”,根据 func 的返回值对元素排序。
words = ["apple", "banana", "cherry", "date"]
res = sorted(words , key = lambda s :len(s))
# 这里的 lambda 不是 “条件判断”,
# 而是一个映射函数:它接收列表 words 中的每个元素(假设 words 是字符串列表,
# 比如 ["apple", "cat", "banana"]),然后返回该元素的长度(len(s))
print(res)
sorted(words, key=lambda s: len(s))
# 在 sorted(words, key=lambda s: len(s)) 中,
# lambda 函数能取到列表 words 中每一个值,核心是因为 sorted 函数内部会自动遍历列表,
# 并把每个元素逐个传给 key 函数1.13.5 装饰器(典型的返回函数的高阶函数)
装饰器本质是 “接收一个函数,返回一个包装后的新函数” 的高阶函数(详见之前的装饰器解析)
1.13.6 wraps
保留被装饰函数元信息的装饰器工具
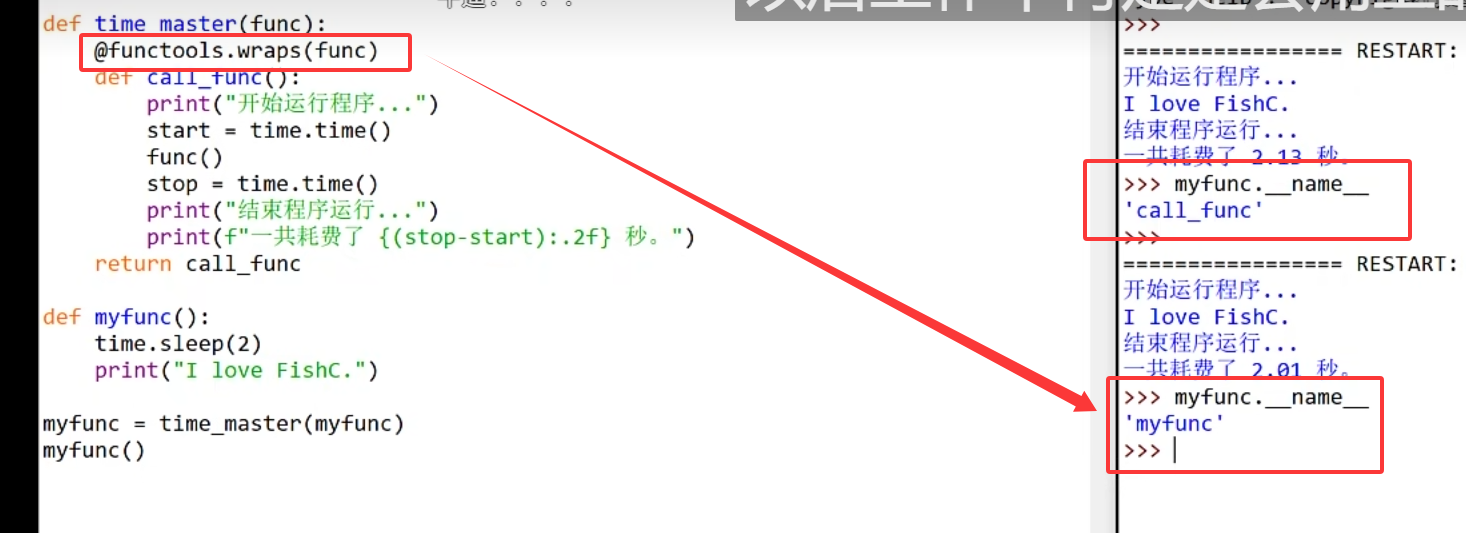
from functools import wraps # 导入wrapsdef decorator(func):@wraps(func) # 用wraps保留原函数func的元信息def wrapper(*args, **kwargs):"""这是wrapper函数的文档字符串"""print("装饰器逻辑执行")return func(*args, **kwargs)return wrapper@decorator
def add(a, b):"""返回两个数的和"""return a + b# 再次查看元信息
print(add.__name__) # 输出:add(正确保留原函数名)
print(add.__doc__) # 输出:返回两个数的和(正确保留原文档字符串)wraps 本质是一个装饰器,它会将 wrapper 函数的以下元信息 “替换” 为原函数 func 的对应信息:
__name__:函数名__doc__:文档字符串(docstring)__module__:函数所在模块__annotations__:函数注解__dict__:函数的属性字典
1.13.7 偏函数
固定一个函数的部分参数(位置参数或关键字参数),生成一个新的函数。这个新函数调用时,只需要传入剩下的参数,从而简化重复调用的代码
from functools import partial
s = functools.partial(pow,exp = 2)
print(s(3))
# pow(x, y) 是 Python 内置函数
# 2 指的是 “指数(exponent) partial() 的第一个参数必须是一个函数、方法或其他可调用对象(比如类、lambda 等),这是要被 “包装” 的原函数。例如:pow(内置函数)、int(内置函数)、自定义函数 def add(a, b): return a+b 等,都可以作为第一个参数
后续参数:要固定的 “位置参数” 或 “关键字参数”,从第二个参数开始,是要 “预填充” 到原函数中的参数,分为两种:
(1)固定 “位置参数”(按顺序传递)
按原函数的参数顺序,提前传入部分参数,后续调用新函数时,这些参数会被 “固定” 在对应位置
示例:原函数 pow(x, y) 计算 x^y,固定第二个位置参数为 2(即指数为 2)
(2)固定 “关键字参数”(按名称传递)
通过 “参数名 = 值” 的形式,固定原函数中指定名称的参数,无论顺序如何,都会绑定到对应参数上
原函数 int(s, base=10) 转换字符串为整数,固定 base=2(即二进制转换)
# 固定 int 的关键字参数 base=2(按名称传递,无需关心顺序)
int_bin = partial(int, base=2)# 调用新函数时,只需传入字符串(s 参数)
print(int_bin("1010")) # 等价于 int("1010", base=2) → 10
print(int_bin("111")) # 等价于 int("111", base=2) → 72 文件处理
2.1 文件的打开:open() 函数参数解析
用 open() 函数打开文件
open(file, mode='r', buffering=-1, encoding=None, errors=None)1. file
指定要打开的文件路径,可以是相对路径(如 'data.txt',相对于当前工作目录)或绝对路径(如 'C:/Users/xxx/data.txt')
2. mode:文件打开模式(核心)
控制文件的 “打开方式、权限、类型”,常见模式及含义:
| 模式 | 含义 |
|---|---|
'r' | 只读模式(默认),文件必须已存在,否则报错。 |
'w' | 写入模式,若文件存在则截断清空原有内容;若不存在则创建新文件。 |
'x' | 排他性创建,若文件已存在则打开失败(确保 “新建文件不覆盖已有文件”)。 |
'a' | 追加模式,若文件存在则在末尾追加内容;若不存在则创建新文件。 |
'b' | 二进制模式(与其他模式组合用,如 'rb'“二进制只读”、'wb'“二进制写入”),用于处理图片、音频等非文本文件。 |
't' | 文本模式(默认,与其他模式组合如 'rt',通常可省略),用于处理字符串形式的文本文件。 |
'+' | 更新模式(与其他模式组合,如 'r+'“读写”、'w+'“写读”),允许同时读写文件。 |
3. buffering:缓冲策略
控制文件的 “缓冲行为”(内存与磁盘间的临时数据存储)
- 0:关闭缓冲(仅二进制模式 'b' 下可用)
- 1:行缓冲(仅文本模式 't' 下可用,遇到换行符时刷新缓冲)
- >1 的整数:指定 “块缓冲” 的字节大小(如 4096 表示每次缓冲 4096 字节)
- 不指定时:二进制文件默认用 “固定大小块缓冲”(通常 4096/8192 字节);交互式文本文件(isatty() 返回 True)用行缓冲,其他文本文件用块缓冲
4. encoding:编码 / 解码格式
仅文本模式('t' 或默认)下有效,指定文件的编码(如 'utf-8'、'gbk' 等),控制文本的编码和解码规则
5. errors:编码错误处理
| 选项 | 含义 |
|---|---|
'strict' | 若有编码错误,抛出 ValueError 异常(默认行为)。 |
'ignore' | 忽略编码错误(可能导致数据丢失)。 |
'replace' | 将错误字符替换为特殊字符(如 ?)。 |
'surrogateescape' | 将错误字节暂存为 “代理字符”,适用于处理未知编码的文件。 |
'xmlcharrefreplace' | 将不支持的字符替换为 XML 字符引用(如 &#nnn;),仅写入文件时支持。 |
#1. 'r':只读模式(默认)
#文件必须已存在,否则报错;只能读,不能写
# 假设存在文件 test.txt,内容为 "Hello World"
f = open("test.txt", "r")
content = f.read()
print(content) # 输出:Hello World# 如果尝试写入,会报错
# f.write("abc") # 取消注释会触发:io.UnsupportedOperation: not writablef.close()#2. 'w':写入模式
#文件存在则清空原有内容;文件不存在则新建;打开后只能写,不能读(若要读需结合 +)# 情况1:文件不存在 → 新建并写入
f = open("new.txt", "w")
f.write("I love Python")
f.close() # 生成 new.txt,内容为 "I love Python"# 情况2:文件已存在(假设 new.txt 已有内容 "Old")
f = open("new.txt", "w")
f.write("New")
f.close() # new.txt 被清空,新内容为 "New"#3. 'x':排他性创建
#强制新建文件,若文件已存在则打开失败(避免误覆盖已有文件
# 情况1:文件不存在 → 新建并写入
f = open("exclusive.txt", "x")
f.write("This is new")
f.close() # 成功创建# 情况2:文件已存在(如上面的 exclusive.txt)
try:f = open("exclusive.txt", "x")
except FileExistsError:print("文件已存在,打开失败") # 输出:文件已存在,打开失败#4. 'a':追加模式
#文件存在则在末尾追加内容;文件不存在则新建;打开后只能在末尾写,不能读(若要读需结合 +)
# 假设存在 append.txt,内容为 "Start "
f = open("append.txt", "a")
f.write("End")
f.close()# 读取验证:
f = open("append.txt", "r")
print(f.read()) # 输出:Start End
f.close()#5. 'b':二进制模式(与其他模式组合)
#用于处理图片、音频、视频等非文本文件(按 “二进制数据” 而非 “字符串” 处理
# 示例:复制一张图片(二进制读 + 二进制写)
with open("cat.jpg", "rb") as f_read:img_data = f_read.read() # 读取图片的二进制数据with open("cat_copy.jpg", "wb") as f_write:f_write.write(img_data) # 将二进制数据写入新文件,生成副本#6. 't':文本模式(默认,可省略)
#用于处理文本文件(按 “字符串” 处理,会自动处理编码),通常与 r/w 等组合(如 'rt' 等价于 'r')
f = open("poem.txt", "rt") # 同 open("poem.txt", "r")
content = f.read()
print(content) # 按字符串读取文本内容(如诗句、代码等)
f.close()#7. '+':更新模式(与其他模式组合)
#允许同时读写文件,需结合基础模式(如 'r+'“读写”、'w+'“写读”)
# 假设 r_plus.txt 原有内容为 "Hello"
f = open("r_plus.txt", "r+")
content = f.read() # 先读:"Hello"
f.write(" World") # 从文件末尾写入,内容变为 "Hello World"f.seek(0) # 把“读取指针”移回文件开头
new_content = f.read() # 再读:"Hello World"
print(new_content)f.close()#② 'w+':写读模式(先清空文件,再读写)
f = open("w_plus.txt", "w+")
f.write("First line\n") # 写入后,文件内容:"First line\n"f.seek(0) # 移到开头
print(f.read()) # 输出:First linef.write("Second line") # 继续写入,内容变为:"First line\nSecond line"
f.seek(0)
print(f.read()) # 输出:First line\nSecond linef.close()2.2 文件对象的方法
打开文件后得到 “文件对象”(如 f = open(...)),可通过以下方法操作文件
1. f.close()
关闭文件对象,释放系统资源。建议:用 with open(...) as f: 语法(上下文管理),可自动关闭文件,避免资源泄漏。
2. f.flush()
将文件对象的缓冲数据强制写入磁盘(但系统级缓冲可能仍存在,不一定完全实时生效)。
3. f.read(size=-1)
从文件中读取内容:
size 为正整数:读取指定数量的字符(文本模式)或字节(二进制模式)。
size=-1(默认):读取剩余所有内容,直到文件末尾(EOF)。
4. f.readable()
判断文件是否支持读取。若返回 False,调用 f.read() 会触发 OSError 异常。
5. f.readline(size=-1)
读取文件中的一行内容(包含换行符 \n);若指定 size,则读取该行的前 size 个字符。
6. f.seek(offset, whence=0)
修改文件指针的位置(控制 “从哪里开始读写”):
offset:偏移的字节数。
whence:基准位置(0= 文件起始位置;1= 当前指针位置;2= 文件末尾位置)。
返回新的指针位置(字节索引)。
7. f.seekable()
判断文件是否支持修改指针位置。若返回 False,调用 f.seek()、f.tell()、f.truncate() 会触发 OSError 异常。
8. f.tell()
返回当前文件指针在文件中的位置(字节索引)。
9. f.truncate(pos=None)
将文件截断到指定位置:
pos=None(默认):截断到 “当前文件指针的位置”。
pos 为整数:截断到 pos 字节处,后续内容被删除。
10. f.write(text)
将字符串 text 写入文件,返回 “写入的字符数量”(即字符串长度)。需确保文件以 “可写入模式”(如 'w'、'a'、'r+' 等)打开,否则报错。
11. f.writable()
判断文件是否支持写入。若返回 False,调用 f.write() 会触发 OSError 异常。
12. f.writelines(lines)
将一系列字符串(如列表 ['a\n', 'b\n'])写入文件,但不会自动添加换行符,需手动在每个字符串末尾加 \n。
2.3 路径处理
2.4 with
3 异常
Python 的异常是类(继承自 BaseException),常见类型及场景:
- SyntaxError:语法错误(写代码时就会提示,不是运行时异常)
- NameError:使用未定义的变量 / 名称
- TypeError:类型错误(如对字符串做数字运算)
- ValueError:值错误(如 int("abc"),类型对但值不合法)
- FileNotFoundError:文件不存在(打开不存在的文件时触发)
- ZeroDivisionError:除数为 0(如 10 / 0
异常处理
try:# 可能触发异常的代码risky_code()
except 异常类型1 as 变量名:# 捕获到“异常类型1”时执行的逻辑handle_error()
except 异常类型2:# 捕获到“异常类型2”时执行的逻辑
else:# try 内代码“无异常”时执行的逻辑
finally:# 无论是否有异常,都会执行的逻辑(常用于资源清理,如关闭文件)在 Python 中,把多个异常用元组包裹起来放在 except 后,是为了让一个 except 块能处理多种不同类型的异常
try:# 可能触发异常的代码
except (ZeroDivisionError, TypeError, ValueError):pass # 统一处理这三种异常可以用 raise 手动触发异常,常用于自定义校验逻辑(如参数合法性检查)
def check_age(age):if age < 0:# 主动抛出 ValueError,并附带错误信息raise ValueError("年龄不能为负数!")return agetry:user_age = check_age(-5)
except ValueError as e:print(e) # 输出:年龄不能为负数!可通过继承 Exception 定义自己的异常类,用于业务专属的错误场景
class InsufficientBalanceError(Exception):def __init__(self, balance, amount):self.message = f"余额不足!当前余额:{balance},需支付:{amount}"def pay(balance, amount):if balance < amount:raise InsufficientBalanceError(balance, amount)print("支付成功")try:pay(100, 200)
except InsufficientBalanceError as e:print(e.message) # 输出:余额不足!当前余额:100,需支付:200raise链????