基于 ComfyUI + Wan2.2 animate实现 AI 视频人物换衣:完整工作流解析与资源整合(附一键包)
✅ 本文目标:手把手教你用 ComfyUI 搭建一个支持“视频换衣”的 AI 工作流,基于 WanVideo Animate Embeds 模型,实现从输入视频 + 衣服图片 → 输出换装视频的全流程自动化。文末提供 一键整合包下载地址 和 仙宫云端预装环境链接,支持快速部署。
一、前言:我们为什么需要“AI视频换衣”?
在电商、虚拟偶像、短视频内容创作等领域,传统“试穿”或“变装”视频制作成本高、周期长。而随着 AIGC 技术的发展,尤其是 时序可控视频生成模型 的突破,我们终于可以尝试让 AI 自动完成“给人物换衣服”这件事。
不同于简单的图像 inpainting 或静态换装,真正的视频换衣需要解决三大挑战:
- 精准区域控制:只替换指定衣物(如上衣/裤子),不干扰其他区域;
- 时序一致性:保证帧间纹理、光影、运动连贯,不闪烁、不跳变;
- 姿态适应性:衣服能贴合动态人体,即使原始服装图是平铺的。
本文将介绍我近期成功实现的一套 基于 Wan2.2 的 ComfyUI 工作流,已验证可在本地 GPU 环境下稳定运行,效果自然,支持多种服装类型替换。
效果演示:
这下全了!5个工作流,Wan2.2 animate 实现换头+换上衣+换裤子+动作迁移+静态图片跳舞,附整合包+云端直达链接!
二、整体工作流架构
以下是该工作流的核心节点流程图(可在 B站 视频中查看可视化连线):
[目标视频] ↓
[Frame Extract] → [LayerMask: Segformer B2 Clothes Ultra] → [Dynamic Mask]↓ ↗
[ clothes image ] → [Load Image + Clip Encode ]↓[WanVideo Animate Embeds]↓[WanVideo Sampler (dpmpp_2m_sde)]↓[Video Combine & Output]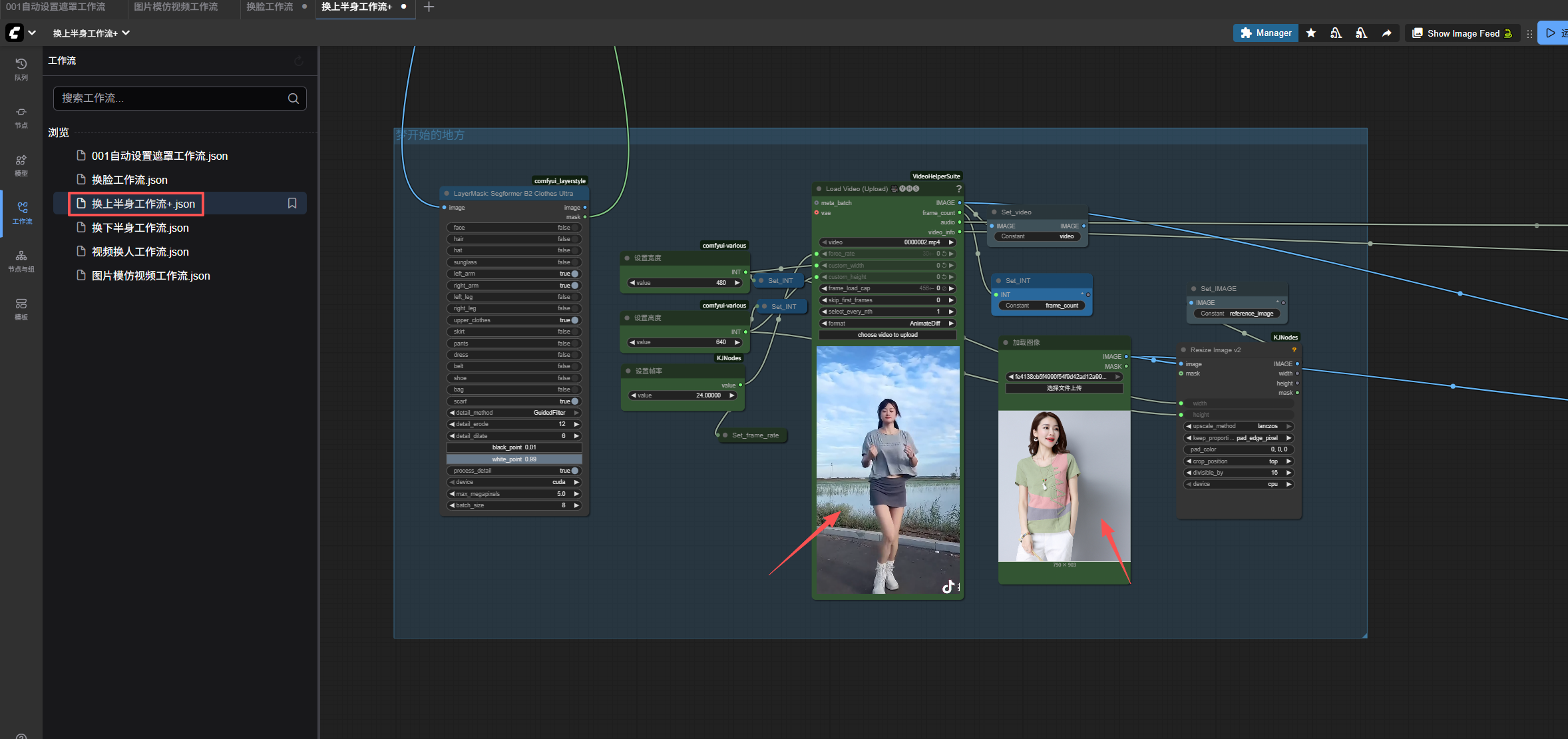
输入参数:
- 目标视频(mp4, mov 等常见格式)
- 替换衣物图片(JPG/PNG,建议正面清晰图)
- 输出分辨率(如 1080x1920)
- 帧率(默认 24fps)
- 替换类别:Top / Pants / Skirt / Dress(通过 LayerMask 节点选择)
三、关键技术模块详解
1. 动态遮罩生成:LayerMask + Segformer B2 Clothes Ultra
这是本工作流的核心前置模块。传统方法依赖手动蒙版或简单人体解析,容易出现边缘锯齿、误分割等问题。
我采用的是 LayerMask 插件中的 Segformer B2 Clothes Ultra 模型,它支持 12 类服装部件识别,精度高、边界柔滑。
📌 使用技巧:
- 在节点中选择
Clothing Type为目标替换项(如 Skirt) - 可调节
Mask Expand参数(建议 3-5px)防止边缘遗漏 - 添加
Gaussian Blur节点柔化边缘,避免生硬过渡
⚠️ 注意:该模型对背光、遮挡严重的情况效果下降,建议输入视频光照均匀、人物清晰。
2. 内容驱动:WanVideo Animate Embeds 节点
这是实现“换衣”的关键。该节点基于 Wan2.2 的 Animate Embeds 架构,支持将外部图像的纹理特征注入到指定区域。
工作原理:
- 将衣服图片通过 CLIP 编码为文本+图像嵌入向量
- 结合动态遮罩,在每帧的目标区域进行条件注入
- 利用时序注意力机制保持帧间一致性
📌 参数建议:
motion_scale: 1.2 ~ 1.5(控制动作保留程度)texture_weight: 0.8 ~ 1.0(增强衣服纹理表现)cfg: 6 ~ 7steps: 20 ~ 25(推荐 dpmpp_2m_sde)
3. 采样器优化:WanVideo Sampler
使用官方推荐的 WanVideo Sampler,内置帧间光流补偿与噪声调度优化,显著减少闪烁和抖动。
对比测试:
| 采样器 | 效果 | 推荐指数 |
|---|---|---|
| Euler a | 快但闪烁明显 | ⭐⭐ |
| DDPMSampler | 稳定但细节模糊 | ⭐⭐⭐ |
| WanVideo Sampler (dpmpp_2m_sde) | 流畅自然,细节保留好 | ⭐⭐⭐⭐⭐ |
四、实测效果与局限性
✅ 成功案例:
- 连衣裙 → 渐变亮片裙(动作自然,褶皱跟随身体)
- 白T恤 → 印花卫衣(图案完整还原,无扭曲)
- 黑色长裤 → 牛仔短裤(边缘处理干净,无穿模)
❌ 当前局限:
- 对多人视频支持较差(遮罩易混淆)
- 极端动作(如翻滚、跳跃)可能导致纹理错位
- 输入衣服图若为模特图(非平铺),可能引入姿态干扰
五、如何快速部署?(懒人福音)
我知道很多人不想折腾环境配置。因此我准备了:
📦 【ComfyUI 一键整合包】
包含:
- 预装 Wan2.2 所需模型(animate_embeds, wan_video_models)
- LayerMask 插件及 Segformer 模型
- 自定义节点(WanVideo Sampler, Animate Embeds Loader)
- 已配置好的
.json工作流文件 - 详细 README 安装指南
📥 下载地址:https://pan.quark.cn/s/57b7575295ae
☁️ 【仙宫云端预装环境】
无需下载,直接在线使用:
- 支持 RTX 4090 24G 48G 实例,生成效率高
🚀 入口地址(邀请码注册送8元现金):https://www.xiangongyun.com/image/detail/af97c7bd-a933-4f84-919b-3b3008a5b400?r=KSGHSD
仙宫云邀请码: KSGHSD
六、B站教程视频已发布
为了方便大家理解节点连接逻辑和参数设置,我录制了全程操作演示视频,包括:
- 环境配置过程
- 工作流节点详解
- 实际生成演示
- 常见报错解决方案(如 OOM、mask 错误等)
🎥 视频地址:https://www.bilibili.com/video/BV1JdsPzZEDR/?vd_source=8977926e52346834c9c6a6b1eaf76778#reply278240893585
👉 建议配合本文食用,效果更佳。
七、总结与展望
本文分享了一套基于 ComfyUI + Wan2.2 的 AI 视频换衣工作流,实现了从“想法”到“可运行系统”的落地。虽然目前仍有优化空间,但已具备实用价值。
未来计划:
- 支持多衣物同时替换(上衣+裤子)
- 引入 ControlNet 辅助姿态控制
- 开发 WebUI 简化操作流程
如果你也在研究 AI 视频生成、数字人、虚拟穿搭等方向,欢迎留言交流,一起推动 AIGC 落地!