【c++】深入理解string类(4)
目录
一 常见接口补充
1 c_str
二 string类问题的模拟实现
1 打印函数
2 构造函数 析构函数
3 扩容函数
4 尾插函数
5 测试
6 迭代器实现
7 insert
8 erase
一 常见接口补充
1 c_str

这个接口就是为了兼容C语言,C++有时候会去调用C的接口,因为C++的库里面有时候提供api时会直接按照C的方式提供。就意味着就算当前我们的程序是用C++!写的,也不可避免地会调用C风格的接口。例如我们后面学习网络工程的时候,用到的send()这个接口,就会调用C_str.
2 不同类型之间的相互转换
(1)其他类型转换成浮点数
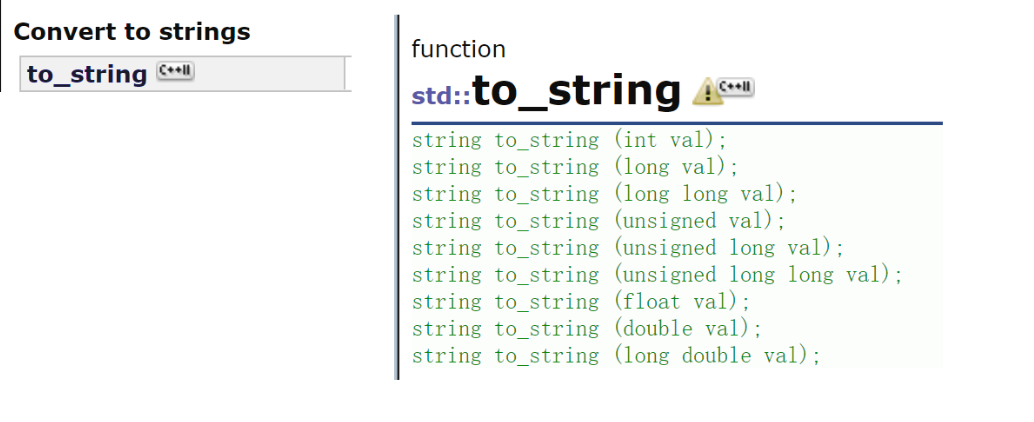
(2)浮点数转换成不同类型
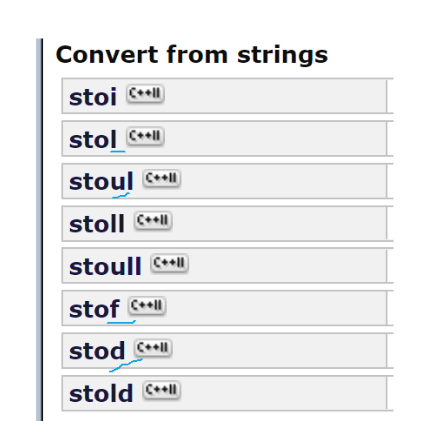
每一个看最后的字母就可以判断出是什么类型转换:例如第一个最后一个字母是i,就表示是浮点数转换成整型,第三个ul表示 unsigned long
二 string类问题的模拟实现
先包含一下头文件:
#define _CRT_SECURE_NO_WARNINGS 1#include<iostream>
#include<string>
#include<algorithm>
#include<list>
using namespace std;1 打印函数
博主直接将代码的解析附录在注释中:
// 函数功能:打印字符串的正序和逆序字符
// 参数:const string& s - 传入的字符串常量引用,保证原字符串不会被修改
void Print(const string& s)
{// 1. 正序遍历字符串// 使用const_iterator迭代器,用于遍历常量字符串,只能读取不能修改// 注意:不能用const string::iterator,因为s是const类型,其begin()返回const_iteratorstring::const_iterator it1 = s.begin();// 循环遍历直到字符串末尾(end()指向最后一个字符的下一位)while (it1 != s.end()){// *it1 = 'x'; // 编译错误:const_iterator不允许修改指向的内容cout << *it1 << " "; // 输出当前迭代器指向的字符++it1; // 迭代器向后移动一位,指向 next 字符}cout << endl; // 正序输出结束,换行// 2. 逆序遍历字符串// 使用const_reverse_iterator逆序迭代器,用于逆序遍历常量字符串,只能读取不能修改string::const_reverse_iterator it2 = s.rbegin();// 循环遍历直到逆序末尾(rend()指向第一个字符的前一位)while (it2 != s.rend()){// *it2 = 'x'; // 编译错误:const_reverse_iterator同样不允许修改内容cout << *it2 << " "; // 输出当前逆序迭代器指向的字符++it2; // 逆序迭代器"++"表示向前前移动,指向 previous 字符}cout << endl; // 逆序输出结束,换行
}我们来测试一下:
#include <iostream>
#include <string>
#include <list>
#include <algorithm> // 用于find函数
using namespace std;// 假设已有之前定义的Print函数
void Print(const string& s);// 测试字符串操作及相关C++特性的函数
void test_string2()
{// 用字符串常量初始化string对象string s1("hello world");cout << s1 << endl; // 输出: hello world// 通过下标[]修改字符串中的字符([]不做越界检查)s1[0] = 'x';cout << s1 << endl; // 输出: xello worldcout << s1[0] << endl; // 输出: x// 越界访问的两种方式及区别// s1[12]; // 用[]越界访问会触发断言(debug模式下),直接崩溃// s1.at(12); // 用at()越界访问会抛出out_of_range异常,可以捕获处理// 获取字符串长度的两种方法cout << s1.size() << endl; // 输出: 11 (推荐使用size())cout << s1.length() << endl; // 输出: 11 (与size()功能相同,历史原因保留)// 1. 使用下标+[]遍历并修改字符串for (size_t i = 0; i < s1.size(); i++){s1[i]++; // 每个字符的ASCII值加1('x'->'y','e'->'f'等)}cout << s1 << endl; // 输出: yfmmp!xpsme// 2. 使用迭代器遍历字符串(iterator支持修改)// 迭代器是一种类似指针的对象,用于访问容器元素string::iterator it1 = s1.begin(); // begin()返回指向第一个元素的迭代器while (it1 != s1.end()) // end()返回指向最后一个元素下一位的迭代器{// (*it1)--; // 取消注释可将字符改回原来的值cout << *it1 << " "; // 解引用迭代器获取字符++it1; // 迭代器向后移动}cout << endl; // 输出: y f m m p ! x p s m e // 演示list容器的迭代器使用(与string迭代器用法一致,体现容器迭代器的统一性)list<int> lt;lt.push_back(1);lt.push_back(2);lt.push_back(3);list<int>::iterator lit = lt.begin();while (lit != lt.end()){cout << *lit << " "; // 输出: 1 2 3 ++lit;}cout << endl;// 调用Print函数,打印字符串的正序和逆序(使用const迭代器)Print(s1);// 使用标准库find函数查找元素(需要包含<algorithm>)// find返回迭代器,找到则指向该元素,否则指向end()// string::iterator ret1 = find(s1.begin(), s1.end(), 'x');auto ret1 = find(s1.begin(), s1.end(), 'x'); // 使用auto简化类型声明if (ret1 != s1.end()){cout << "找到了x" << endl; // 此例中会输出该信息}// 在list中查找元素,迭代器用法与string一致// list<int>::iterator ret2 = find(lt.begin(), lt.end(), 2);auto ret2 = find(lt.begin(), lt.end(), 2); // auto自动推导为list<int>::iteratorif (ret2 != lt.end()){cout << "找到了2" << endl; // 此例中会输出该信息}// C++11特性:auto关键字(自动类型推导)int i = 0;auto j = i; // j被推导为int类型auto k = 10; // k被推导为int类型auto p1 = &i; // p1被推导为int*类型(指针)auto* p2 = &i; // p2显式指定为指针类型,同样是int*cout << p1 << endl; // 输出i的地址cout << p2 << endl; // 输出i的地址(与p1相同)// auto与引用的结合int& r1 = i; // r1是i的引用auto r2 = r1; // r2被推导为int类型(不是引用),是r1所指值的拷贝auto& r3 = r1; // r3被推导为int&类型(是r1的引用,即i的引用)// 打印地址验证cout << &r2 << endl; // 输出r2的地址(与i不同)cout << &r1 << endl; // 输出i的地址cout << &i << endl; // 输出i的地址cout << &r3 << endl; // 输出i的地址(与r1相同)// C++11特性:范围for循环(语法糖,简化迭代器遍历)// 范围for会自动遍历容器中所有元素,自动判断结束// for (auto ch : s1) // 传值方式,修改ch不影响原字符串for (auto& ch : s1) // 传引用方式,修改ch会影响原字符串{ch -= 1; // 每个字符ASCII值减1(恢复之前的++操作)}cout << endl;// 用范围for遍历并打印字符串(const引用方式,防止意外修改)for (const auto& ch : s1){cout << ch << ' '; // 输出: x e l l o w o r l d }cout << endl;// 用范围for遍历list容器for (auto e : lt){cout << e << ' '; // 输出: 1 2 3 }cout << endl;// 范围for也支持数组(编译器做了特殊处理)int a[10] = { 1,2,3 }; // 初始化前3个元素,其余为0for (auto e : a){cout << e << " "; // 输出: 1 2 3 0 0 0 0 0 0 0 }cout << endl;
}2 构造函数 析构函数
namespace bit
{string::string(const char* str):_size(strlen(str)){// Ӧ_str = new char[_size + 1];_capacity = _size;strcpy(_str, str);}string::~string(){delete[] _str;_str = nullptr;_size = 0;_capacity = 0;}
}代码解析:
strcpy(_str, str); // 将C风格字符串复制到已分配的内存中 delete[] _str; // 释放字符数组占用的内存(注意用delete[]匹配new[])3 扩容函数
void string::reserve(size_t n){if (n > _capacity){// char* tmp = new char[n + 1];strcpy(tmp, _str);delete[] _str;_str = tmp;_capacity = n;}}创建了一块新的空间来存出数据,tmp就是新的空间
// 3. 释放原有内存,避免内存泄漏delete[] _str;// 4. 将字符串指针指向新内存_str = tmp;// 5. 更新容量为n(新容量)_capacity = n;4 尾插函数
void string::push_back(char ch){if (_size == _capacity){reserve(_capacity == 0 ? 4 : _capacity * 2);}_str[_size] = ch;_size++;_str[_size] = '\0';}void string::append(const char* str){size_t len = strlen(str);if (_size + len > _capacity){reserve(std::max(_size + len, _capacity * 2));}strcpy(_str + _size, str);_size += len;}区分:
push_back 函数:
- 用于在字符串末尾添加单个字符
- 扩容策略:当容量不足时,空容量时初始化为 4,否则翻倍扩容
- 每次操作都确保保证字符串以 '\0' 结尾,维持 C 风格字符串的兼容性
append 函数:
- 用于在字符串末尾添加一个完整的 C 风格字符串
- 扩容策略:取 "所需总长度" 和 "当前容量翻倍" 的最大值,平衡内存利用率和扩容效率
- 利用
strcpy直接复制字符串,自动包含终止符,简化实现
// 检查现有容量是否足够容纳追加后的所有字符if (_size + len > _capacity){// 扩容到"当前长度+追加长度"和"当前容量*2"中的较大值// 保证既能容纳新内容,又能减少后续扩容次数reserve(std::max(_size + len, _capacity * 2));} // 更新有效长度(原有长度 + 追加的长度)_size += len;// 注意:strcpy会复制原字符串的'\0',因此无需额外手动添加终止符注意:这里的_size是string类的一个成员变量,你哦啊是当前字符串的有效数据个数。
那么我们就可以分别用push_back和append对字符和字符串进行尾插操作:
string& operator+=(const char* str){append(str);return *this;}
string& operator+=(char ch){push_back(ch);return *this;}5 测试
我们来测试一下上面自己实现的string类:
#include <iostream>
// 假设包含了自定义string类的头文件
using namespace std;// 测试自定义string类的各种功能和特性
void test_string1()
{// 1. 测试默认构造函数(创建空字符串)bit::string s1;// c_str()返回C风格字符串指针(以'\0'结尾),用于输出cout << s1.c_str() << endl; // 输出空字符串// 2. 测试带参构造函数及字符串修改string s2("hello world");cout << s2.c_str() << endl; // 输出: hello world// 通过[]运算符修改字符串第一个字符s2[0] = 'x'; // s2变为: xello world// 遍历并修改每个字符(ASCII值+1)for (size_t i = 0; i < s2.size(); i++){s2[i]++; // 每个字符递增:x->y, e->f, l->m等}cout << s2.c_str() << endl; // 输出: yfmmp!xpsme// 3. 测试字符串初始化方式// 隐式类型转换:const char* -> string(编译器优化为直接构造,避免拷贝)string s3 = "hello world"; // 直接构造(与s3等价,两种初始化方式效果相同)string s4("hello world"); // 常量字符串对象(内容不可修改)const string s5("hello world"); // 4. 测试常量字符串的访问(const对象只能读不能写)for (size_t i = 0; i < s2.size(); i++){// s5[i] = 'a'; // 编译错误:const对象不能修改cout << s5[i] << "-"; // 输出: h-e-l-l-o- -w-o-r-l-d-}cout << endl;// 5. 测试范围for循环遍历(普通对象,可读写)for (auto ch : s4){cout << ch << " "; // 输出: h e l l o w o r l d }cout << endl;// 6. 测试普通迭代器(可修改元素)string::iterator it4 = s4.begin();while (it4 != s4.end()){*it4 += 1; // 每个字符ASCII值+1(h->i, e->f等)cout << *it4 << " "; // 输出: i f m m p ! x p s m e ++it4;}cout << endl;// 7. 测试范围for遍历const字符串(只读)for (auto ch : s5){// ch = 'a'; // 编译错误:范围for遍历const对象时元素是只读的cout << ch << " "; // 输出: h e l l o w o r l d }cout << endl;// 8. 测试const迭代器(只能读不能修改)string::const_iterator it5 = s5.begin();while (it5 != s5.end()){// *it5 += 1; // 编译错误:const迭代器不能修改指向的元素cout << *it5 << " "; // 输出: h e l l o w o r l d ++it5;}cout << endl;
}6 迭代器实现
typedef char* iterator;typedef const char* const_iterator;iterator begin(){return _str;}iterator end(){return _str + _size;}const_iterator begin() const{return _str;}const_iterator end() const{return _str + _size;}7 insert
insert是在指定位置插入字符串或字符
void string::insert(size_t pos, char ch){assert(pos <= _size);if (_size == _capacity){reserve(_capacity == 0 ? 4 : _capacity * 2);}// Ųint end = _size;while (end >= (int)pos){_str[end + 1] = _str[end];--end;}_str[pos] = ch;_size++;}
字符移动:从后往前将原有字符串向后挪动一位(最后一位指向\0,这样增加完新的字符之后就不需要单独处理\0了)
为什么要将pos 强转为int类型?
因为在二目操作符中,如果先后两个类型会把小的类型自动强转为大的类型,此处就是把无符号转化成有符号,循环的终止条件是size<0(因为有可能是头插),无符号类型的-1是最大的整型,这样就会出现问题,所以需要把pos强转为int类型
有符号和无符号比较时会把无符号转换成有符号
那么除了把pos强转成int类型,还有什么其他的办法吗?
挪动数据的时候可以为end-1挪给end,判断循环条件变为end>pos
两种版本对比:

改进版本:改进版本为要插入长度为len的字符
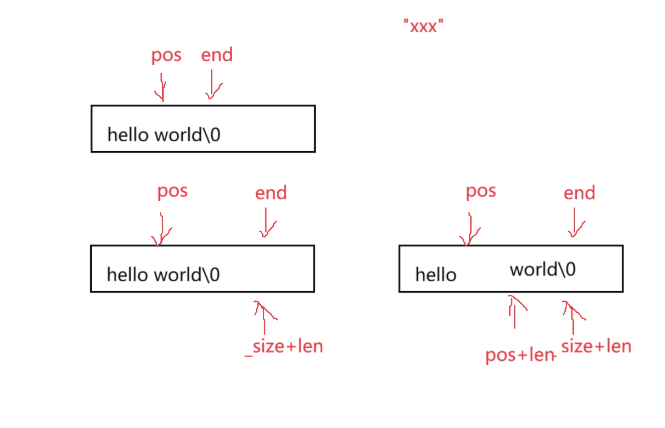
// 在当前字符串的 pos 位置插入 C 风格字符串 str
void string::insert(size_t pos, const char* str)
{// 断言:插入位置必须合法(pos 不能超过当前字符串长度)// 若 pos > _size,属于越界插入,Debug 模式下直接崩溃提示assert(pos <= _size);// 若插入的字符串为空(str 是 nullptr),直接断言失败(避免后续 strlen 崩溃)assert(str != nullptr);// 计算待插入字符串的有效长度(不含末尾的 '\0')size_t len = strlen(str);// 若插入的是空字符串(len=0),无需操作,直接返回if (len == 0){return;}// 检查是否需要扩容:插入后总长度(原长度 + 插入长度)是否超过当前容量if (_size + len > _capacity){// 扩容策略:取「插入后所需最小容量」和「原容量的2倍」中的较大值// 避免扩容后仍不足,同时兼顾减少未来扩容次数reserve(std::max(_size + len, _capacity * 2));}// 数据挪动:将原字符串中 pos 及之后的字符整体向后挪动 len 个位置// 从原字符串末尾(_size)向后偏移 len 个位置开始挪动(避免覆盖未处理的数据)size_t end = _size + len;// 终止条件:当 end 挪到「pos + len - 1」时,说明已腾出插入所需的空间// 循环中每次向前移动一个位置,直到 end 不大于目标位置while (end > pos + len - 1){// 将当前位置的字符替换为「向前偏移 len 个位置」的字符(即原位置的字符)_str[end] = _str[end - len];--end; // 向前移动一个位置,继续处理前一个字符}// 将待插入字符串 str 拷贝到腾出来的 pos 位置// 从 _str + pos 开始,拷贝 len 个字符(str 中恰好有 len 个有效字符)strncpy(_str + pos, str, len);// 更新字符串的有效长度(原长度 + 插入的字符数)_size += len;
}挪动长度为len的两种版本对比:

注意循环的条件!!end是到pos+len的位置停止循环
8 erase
用于删除字符串中指定长度和位置的字符
删除的时候要确保删除的位置是有效字符,判断是否合法
有两种情况:1删除pos后全部的字符 2 删除一部分
思路一:使用strcpy

思路二:使用memcpy
void string::erase(size_t pos, size_t len)
{assert(pos < _size);// 情况1:删除长度为 npos(通常定义为 -1,无符号下表示最大值),// 或删除长度超过「从 pos 到末尾的剩余字符数」(即删除到字符串末尾)if (len == npos || len >= _size - pos){// 直接将字符串长度截断到 pos 位置(pos 及之后的字符全部删除)_size = pos;// 在新的末尾添加 '\0',确保字符串符合 C 风格规范(避免后续输出乱码)_str[_size] = '\0';}else{// 情况2:删除部分字符(未删完,需要将后续字符前移覆盖)// 计算需要前移的字符长度:从 pos+len 到原末尾(包含 '\0')的总长度// +1 是为了将原末尾的 '\0' 也前移(确保新字符串末尾有 '\0')size_t move_len = _size - (pos + len) + 1;// 将 pos+len 位置开始的字符,拷贝到 pos 位置(覆盖被删除的部分)// 使用 memcpy 比 strcpy 更高效(直接按字节拷贝,无需检查 '\0')memcpy(_str + pos, _str + pos + len, move_len);// 更新有效长度:原长度减去删除的字符数_size -= len;}
}还有一些模拟实现的内容没有讲完,博主放到下一篇中