Apache NiFi 完全入门与实战教程:从零构建数据流水线
目录
- 什么是 Apache NiFi?
- NiFi 的核心特性
- 安装与启动 NiFi
- NiFi 核心概念详解
- 实战 1:读取文件 → 输出日志
- 实战 2:HTTP 接口接收 JSON → 写入文件
- 实战 3:定时拉取数据库 → 发送到 Kafka
- 高级功能:表达式语言、路由、转换
- 性能调优与监控
- 最佳实践与常见问题
- 处理器参考手册
1. 什么是 Apache NiFi?
Apache NiFi 是一个基于 流式数据处理 的开源数据集成工具,最初由美国国家安全局(NSA)开发,后捐赠给 Apache 基金会。
它提供了一个可视化、拖拽式界面,允许用户通过图形化方式设计、部署和监控数据流(DataFlow),实现:
- 数据采集(日志、文件、数据库、API)
- 数据转换(清洗、格式化、丰富)
- 数据路由(条件判断、分流)
- 数据分发(Kafka、HDFS、S3、Elasticsearch 等)
✅ 一句话总结:NiFi 是一个“数据管道的可视化操作系统”。
2. NiFi 的核心特性
| 特性 | 说明 |
|---|---|
| 🔧 可视化界面 | 拖拽组件,无需写代码即可构建复杂数据流 |
| ⚡ 高吞吐、低延迟 | 支持每秒数万条消息处理 |
| 🔁 数据溯源(Provenance) | 记录每条数据的来源、去向、处理过程,便于审计与调试 |
| 🔐 安全传输 | 支持 SSL/TLS、Kerberos、LDAP 认证 |
| 🔄 背压(Backpressure) | 自动控制流量,防止下游系统过载 |
| 📦 丰富的处理器(Processor) | 超过 300+ 内置组件,支持扩展 |
| 🌐 集群支持 | 可部署为集群,实现高可用与负载均衡 |
3. 安装与启动 NiFi
3.1 环境要求
- Java 21
- Linux / macOS / Windows
- 至少 4GB 内存
3.2 下载与安装
# 下载最新稳定版(以 1.26.0 为例)
wget https://mirrors.tuna.tsinghua.edu.cn/apache/nifi/2.6.0/nifi-2.6.0-bin.zip# 解压
unzip nifi-2.6.0-bin.zip
cd nifi-1.26.03.3 启动 NiFi
# 启动
bin/nifi.sh start# 查看状态
bin/nifi.sh status# 停止
bin/nifi.sh stop3.4 访问 Web UI
打开浏览器访问:
http://localhost:8080/nifi首次启动可能需要等待 1-2 分钟。
4. NiFi 核心概念详解
4.1 FlowFile(数据文件)
NiFi 中的最小数据单元,包含:
- 内容(Content):实际数据(如 JSON、日志、二进制)
- 属性(Attributes):元数据(如 filename、path、uuid、自定义属性)
📌 类比:
FlowFile = 信封(属性) + 信件内容(内容)
4.2 Processor(处理器)
执行具体操作的组件,如:
GetFile:读取文件PutKafka:写入 KafkaUpdateAttribute:修改属性LogAttribute:打印属性(调试用)
4.3 Connection(连接)
连接两个 Processor,形成数据流。
- 可设置队列(Queue),支持背压
- 可配置最大队列大小(如 10,000 条)
4.4 Process Group(处理组)
逻辑容器,用于组织多个 Processor,支持嵌套。
类比:文件夹,用于模块化管理数据流。
4.5 Controller Services(控制器服务)
共享资源,如:
DBCPConnectionPool:数据库连接池KafkaControllerService:Kafka 配置SSLContextService:SSL 配置
4.6 Data Provenance(数据溯源)
NiFi 自动记录每条 FlowFile 的:
- 何时被创建
- 经过哪些 Processor
- 属性如何变化
- 耗时、大小等
可在 UI 中点击 Provenance 标签查看。
5. 实战 1:读取文件 → 输出日志
目标
读取 /tmp/input/ 目录下的文件,打印其内容和属性。
步骤
添加
GetFile处理器- 配置
Input Directory:/tmp/input Keep Source File:false(处理后删除)Polling Interval:5 sec
- 配置
添加
LogAttribute处理器- 连接
GetFile→LogAttribute - 配置
Log Level:info Attributes to Log:留空(记录所有)
- 连接
启动处理器
- 右键点击处理器 →
Start
- 右键点击处理器 →
测试
echo "Hello NiFi!" > /tmp/input/test.txt查看 NiFi 日志(
logs/nifi-app.log),应看到属性和内容输出。
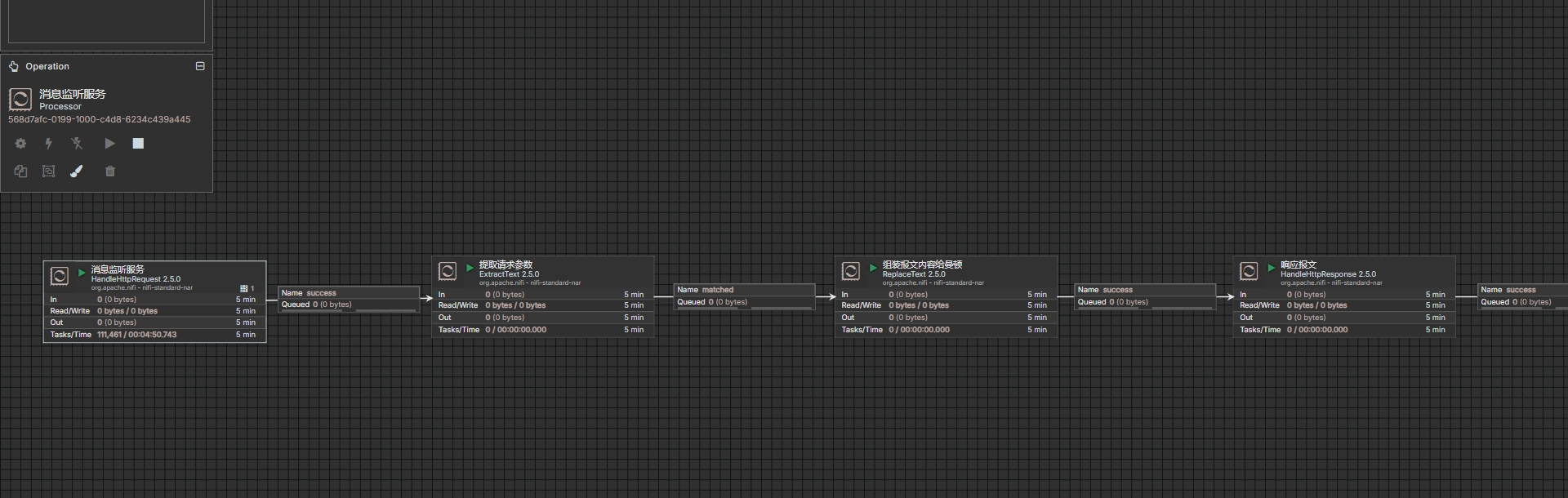
6. 实战 2:HTTP 接口接收请求 → 写入文件
目标
通过 HTTP 接收 JSON 数据,保存为本地文件。
步骤
添加
HandleHttpRequestListening Port:8081HTTP Context Path:/data
添加
HandleHttpResponse- 连接在最后,用于返回响应
添加
PutFileDirectory:/tmp/output- 文件名可设置为
${filename}-${uuid}.json
连接流程
HandleHttpRequest → PutFile → HandleHttpResponse测试
curl -X POST http://localhost:8081/data \-H "Content-Type: application/json" \-d '{"name": "张三", "age": 30}'查看
/tmp/output/目录,应生成 JSON 文件。测试图
7. 实战 3:定时拉取数据库 → 发送到 Kafka
目标
每 30 秒从 MySQL 查询数据,发送到 Kafka。
前提
- MySQL 已安装,表
users存在 - Kafka 已启动,Topic
user_events存在
步骤
配置 DBCP 连接池
- 菜单 → Controller Settings → Controller Services
- 添加
DBCPConnectionPool - 配置 JDBC URL、用户名、密码、驱动 JAR(需放入
lib/目录)
添加
QueryDatabaseTable- 选择 DBCP 服务
Table Name:usersRun Schedule:30 sec
添加
ConvertAvroToJSON(可选)- 将 Avro 格式转为 JSON
添加
PutKafka- 配置 Kafka Broker、Topic 名称
- 使用表达式
${topic}动态指定 Topic
连接并启动
QueryDatabaseTable → ConvertAvroToJSON → PutKafka
8. 高级功能:表达式语言、路由、转换
8.1 表达式语言(Expression Language)
NiFi 支持强大的 EL,语法:${attributeName}
示例
${filename:equals('data.txt')}→ 判断文件名${path:contains('logs')}→ 判断路径${now():toNumber()}→ 当前时间戳${uuid}→ 生成 UUID
8.2 路由(RouteOnAttribute)
根据属性值分流:
Condition: code == '200' → success
Condition: code != '200' → failure8.3 数据转换
JoltTransformJSON:JSON 结构转换EvaluateJsonPath:提取 JSON 字段 → 属性ReplaceText:字符串替换(支持 EL)SplitJson:将数组拆分为多个 FlowFile
9. 性能调优与监控
9.1 关键配置(nifi.properties)
| 配置项 | 建议值 | 说明 |
|---|---|---|
nifi.web.http.port | 8080 | Web 端口 |
nifi.cluster.is.node | true | 是否集群节点 |
nifi.flowfile.repository.directory | /data/nifi/flowfile | FlowFile 存储 |
nifi.database.repository.directory | /data/nifi/database | 元数据存储 |
nifi.bored.yield.duration | 10.millis | 空闲时 CPU 优化 |
9.2 监控指标
- 队列长度:避免积压
- Backpressure:触发时说明下游压力大
- Provenance Events:分析处理延迟
- JVM GC 日志:避免长时间停顿
9.3 集群模式
- 使用 ZooKeeper 管理集群
- 所有节点配置相同
nifi.cluster.node.address - 流程在集群中自动同步
10. 最佳实践与常见问题
✅ 最佳实践
- 模块化设计:使用 Process Group 划分功能模块
- 命名规范:Processor 命名为
Get-LogFile、Put-Kafka-User - 日志调试:善用
LogAttribute和LogMessage - 版本控制:导出流程为 XML,存入 Git
- 安全配置:启用 HTTPS、LDAP 认证
