微服务-分布式追踪 / 监控工具大全
分布式追踪 / 监控工具
Sleuth-日志追踪(埋点+标记)
:::color5
Spring Cloud Sleuth 是微服务分布式链路追踪的“基石”,
它通过给请求打“唯一标记”,让我们能在复杂的微服务调用中,串联起完整的请求链路,快速定位问题和分析性能。
:::

一、理论:为什么需要 Sleuth?
在单体应用中,我们可以直接登录服务器查看日志排查问题;但在微服务架构中,一个请求可能经过多个服务(如下单→库存→支付),每个服务的日志分散在不同服务器,手动逐个排查几乎不可能。
此时就需要“全链路调用跟踪":通过给**每个请求生成唯一的「Trace ID」,并在服务调用间传递「Span ID」**,把分散的日志串联成一条完整的链路,从而快速定位错误根源、分析性能瓶颈。
Spring Cloud Sleuth 就是这套链路追踪的“实现方案”,它的核心是两个 ID:
- Trace ID:全局唯一,标记一次完整的请求链路(比如用户“下单”操作的全流程)。
- Span ID:标记链路中的一个**“工作单元”**(比如“下单服务调用库存服务”就是一个 Span)。
二、实战:Sleuth 链路追踪落地
我们通过两个微服务(simple-demo-1 和 simple-demo-2)的调用场景,演示 Sleuth 的实战流程。
步骤 1:创建两个微服务项目
项目 1:simple-demo-1(端口 9000)
- 作用:作为请求入口,调用
simple-demo-2。
<!-- pom.xml -->
<dependencies><!-- Spring Boot Web 依赖 --><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency><!-- Sleuth 依赖:核心链路追踪能力 --><dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-sleuth</artifactId></dependency>
</dependencies>// SimpleDemo1Application.java
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RestController;
import org.springframework.web.client.RestTemplate;@SpringBootApplication
public class SimpleDemo1Application {public static void main(String[] args) {SpringApplication.run(SimpleDemo1Application.class, args);}// 注册 RestTemplate,用于服务间调用@Beanpublic RestTemplate restTemplate() {return new RestTemplate();}@RestControllerclass DemoController {private final RestTemplate restTemplate;public DemoController(RestTemplate restTemplate) {this.restTemplate = restTemplate;}@GetMapping("/order")public String order() {// 调用 simple-demo-2 的 /payment 接口return restTemplate.getForObject("http://localhost:9001/payment", String.class);}}
}
# application.properties
server.port=9000
spring.application.name=simple-demo-1 # 应用名,Sleuth 会把它加入日志标记
项目 2:simple-demo-2(端口 9001)
- 作用:被
simple-demo-1调用,返回模拟支付结果。
<!-- pom.xml -->
<dependencies><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency><dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-sleuth</artifactId></dependency>
</dependencies>// SimpleDemo2Application.java
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RestController;@SpringBootApplication
public class SimpleDemo2Application {public static void main(String[] args) {SpringApplication.run(SimpleDemo2Application.class, args);}@RestControllerclass DemoController {@GetMapping("/payment")public String payment() {return "payment success";}}
}
# application.properties
server.port=9001
spring.application.name=simple-demo-2 # 应用名,Sleuth 会把它加入日志标记
步骤 2:启动服务并观察日志
- 分别启动
simple-demo-1和simple-demo-2。 - 访问接口:
http://localhost:9000/order。 - 查看两个服务的控制台日志:
日志中的方括号内容是 Sleuth 的核心标记,解释如下:
- **simple-demo-1 日志**:
INFO [simple-demo-1,4d2e63ad9bc890b,ddfe378c0a8ec7cc,true] ... order() 执行
- **simple-demo-2 日志**:
INFO [simple-demo-2,4d2e63ad9bc890b,5a7b8c9d0e1f2a3b,true] ... payment() 执行
- `simple-demo-1`/`simple-demo-2`:**应用名称**(对应 `spring.application.name`)。
- `4d2e63ad9bc890b`:**Trace ID**(全局唯一,两个服务的 Trace ID 相同,说明是同一条请求链路)。
- `ddfe378c0a8ec7cc`/`5a7b8c9d0e1f2a3b`:**Span ID**(每个服务的“工作单元”ID,不同服务的 Span ID 不同)。
- `true`:**是否采样**(`true` 表示该请求的追踪信息会被收集,用于后续对接 Zipkin/Elastic Stack)。
步骤 3:采样配置(控制追踪信息的收集比例)
在高并发场景下,全量收集追踪信息会增加系统开销,因此 Sleuth 支持“采样收集”:通过配置只收集部分请求的追踪信息。
在 simple-demo-1 的 application.properties 中添加配置:
# 采样比例:0.1 表示收集 10% 的请求追踪信息(范围 0~1)
spring.sleuth.sampler.probability=0.1
重启 simple-demo-1 后,多次访问 http://localhost:9000/order,观察日志中的第四个布尔值:大部分请求会显示 false(不收集),只有约 10% 的请求显示 true(收集)。

三、Sleuth 核心原理:B3 协议与链路传递
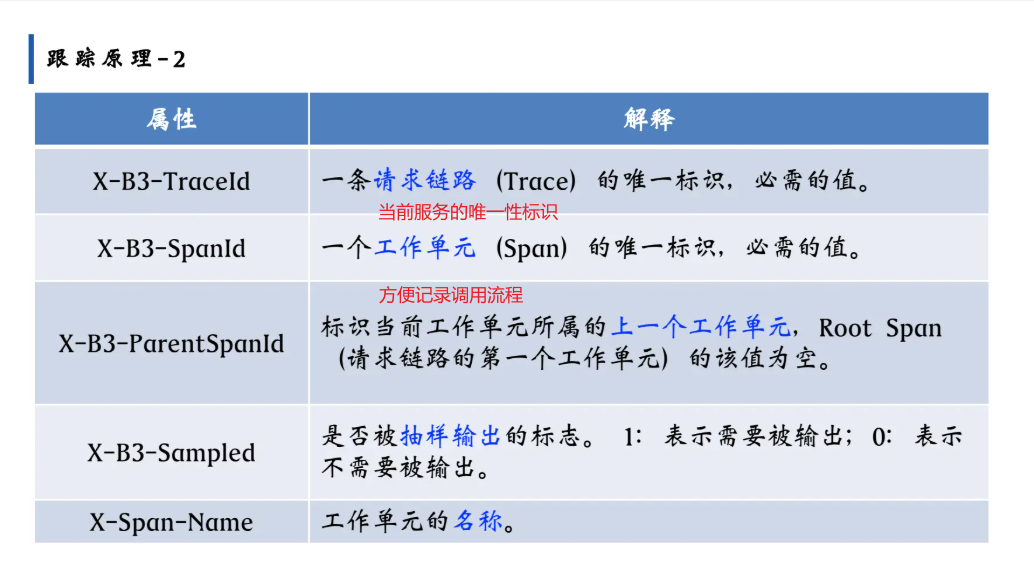
Sleuth 基于 B3 协议 实现链路追踪,核心是通过 HTTP 头传递追踪信息:
X-B3-TraceId:全局 Trace ID(与 Sleuth 日志中的 Trace ID 对应)。X-B3-SpanId:当前 Span ID。X-B3-ParentSpanId:父 Span ID(表示调用关系,如 simple-demo-1 是父,simple-demo-2 是子)。X-B3-Sampled:是否采样(与日志中的true/false对应)。
当 simple-demo-1 调用 simple-demo-2 时,会自动在 HTTP 请求头中携带这些信息,从而让 simple-demo-2 能识别“这是同一条请求链路的一部分”,保证 Trace ID 全局唯一、Span ID 正确关联。

四、总结
Sleuth 是微服务链路追踪的“基础设施”——它不存储、不展示数据,只负责**“给请求打标记”**,让分散的微服务日志能被串联成完整链路。
后续可结合 Zipkin(可视化链路)或 Elastic Stack(全维度监控),将 Sleuth 生成的追踪信息进行存储和展示,从而实现“快速定位微服务调用问题、分析链路性能瓶颈”的目标。
Zipkin-链路追踪可视化(存储 + 展示)
:::color5
Zipkin 是微服务链路追踪的可视化工具,专注于“请求链路的时间延迟分析、服务依赖展示”,
弥补了 ELK 在“链路耗时定位”上的不足。
:::
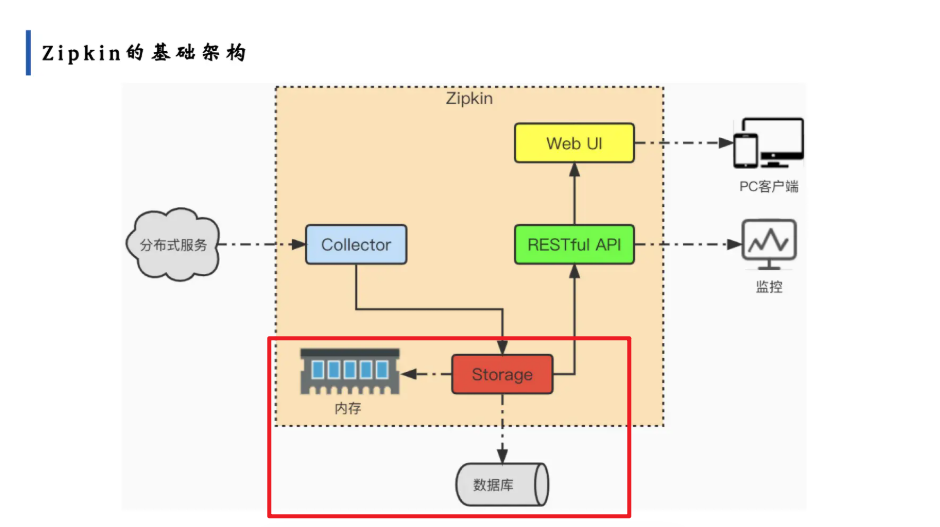

一、理论:Zipkin 核心架构与组件
Zipkin 的核心架构分为四个组件,各司其职:
| 组件 | 作用 |
|---|---|
| Collector(收集器) | 接收微服务(如 Sleuth)发送的链路追踪数据,转换为 Zipkin 内部的 <font style="color:rgb(0, 0, 0);">Span</font> 格式。 |
| Storage(存储) | 存储链路数据,默认存内存,支持 MySQL、Elasticsearch 等持久化存储。 |
| RESTful API | 对外提供接口,支持查询、分析链路数据。 |
| Web UI | 可视化界面,展示链路耗时、服务依赖等信息,支持按 Trace ID、服务名筛选。 |
二、实战:Zipkin 链路追踪全流程
我们基于“微服务 + Sleuth + Zipkin”的架构,实现链路的可视化追踪。
步骤 1:启动 Zipkin 服务端
方式 1:内存存储(快速测试)
直接下载 Zipkin 可执行包并启动(数据重启后丢失):
# 下载并启动(以 2.23.16 版本为例)
curl -sSL https://zipkin.io/quickstart.sh | bash -s
java -jar zipkin.jar
启动后访问 <font style="color:rgb(0, 0, 0);">http://localhost:9411</font>,进入 Zipkin 界面。
方式 2:MySQL 持久化存储(生产可用)
创建 MySQL 数据库:
CREATE DATABASE zipkin DEFAULT CHARACTER SET utf8 COLLATE utf8_general_ci;
- 执行初始化脚本:
从 Zipkin GitHub 下载<font style="color:rgb(0, 0, 0);">mysql.sql</font>,在<font style="color:rgb(0, 0, 0);">zipkin</font>库中执行。
启动 Zipkin 并指定 MySQL 存储:
java -jar zipkin-server-2.23.16-exec.jar \--STORAGE_TYPE=mysql \--MYSQL_HOST=localhost \--MYSQL_TCP_PORT=3306 \--MYSQL_DB=zipkin \--MYSQL_USER=root \--MYSQL_PASS=root
步骤 2:微服务集成 Sleuth + Zipkin
以之前的 <font style="color:rgb(0, 0, 0);">simple-demo-1</font> 和 <font style="color:rgb(0, 0, 0);">simple-demo-2</font> 为例,改造微服务以对接 Zipkin。
微服务依赖配置(pom.xml)
<dependencies><!-- Sleuth 核心依赖 --><dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-sleuth</artifactId></dependency><!-- Zipkin 集成依赖:将 Sleuth 数据发送到 Zipkin --><dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-sleuth-zipkin</artifactId></dependency><!-- Spring Boot Web 依赖 --><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency>
</dependencies>微服务配置文件(application.properties)
# 应用名称
spring.application.name=simple-demo-1 # simple-demo-2 同理,只需改名称# 配置 Zipkin 服务端地址
spring.zipkin.base-url=http://localhost:9411# 配置采样率(1.0 表示全量采样)
spring.sleuth.sampler.probability=1.0
微服务代码(与之前一致,无需修改)
保持 <font style="color:rgb(0, 0, 0);">simple-demo-1</font> 和 <font style="color:rgb(0, 0, 0);">simple-demo-2</font> 的 Controller 代码不变,Sleuth 会自动生成链路信息并发送到 Zipkin。
步骤 3:启动微服务并触发链路
- 启动
<font style="color:rgb(0, 0, 0);">simple-demo-1</font>(端口 9000)和<font style="color:rgb(0, 0, 0);">simple-demo-2</font>(端口 9001)。 - 发送请求:
<font style="color:rgb(0, 0, 0);">http://localhost:9000/order</font>。 - 重复发送多次请求,让链路数据更丰富。
步骤 4:在 Zipkin 中分析链路
1. 查看链路列表
访问 <font style="color:rgb(0, 0, 0);">http://localhost:9411</font>,在 Zipkin 界面中:
- 选择“服务”为
<font style="color:rgb(0, 0, 0);">simple-demo-1</font>或<font style="color:rgb(0, 0, 0);">simple-demo-2</font>。 - 点击“RUN QUERY”,会看到所有请求的链路列表,每条链路包含
<font style="color:rgb(0, 0, 0);">Trace ID</font>、服务名、总耗时等信息。
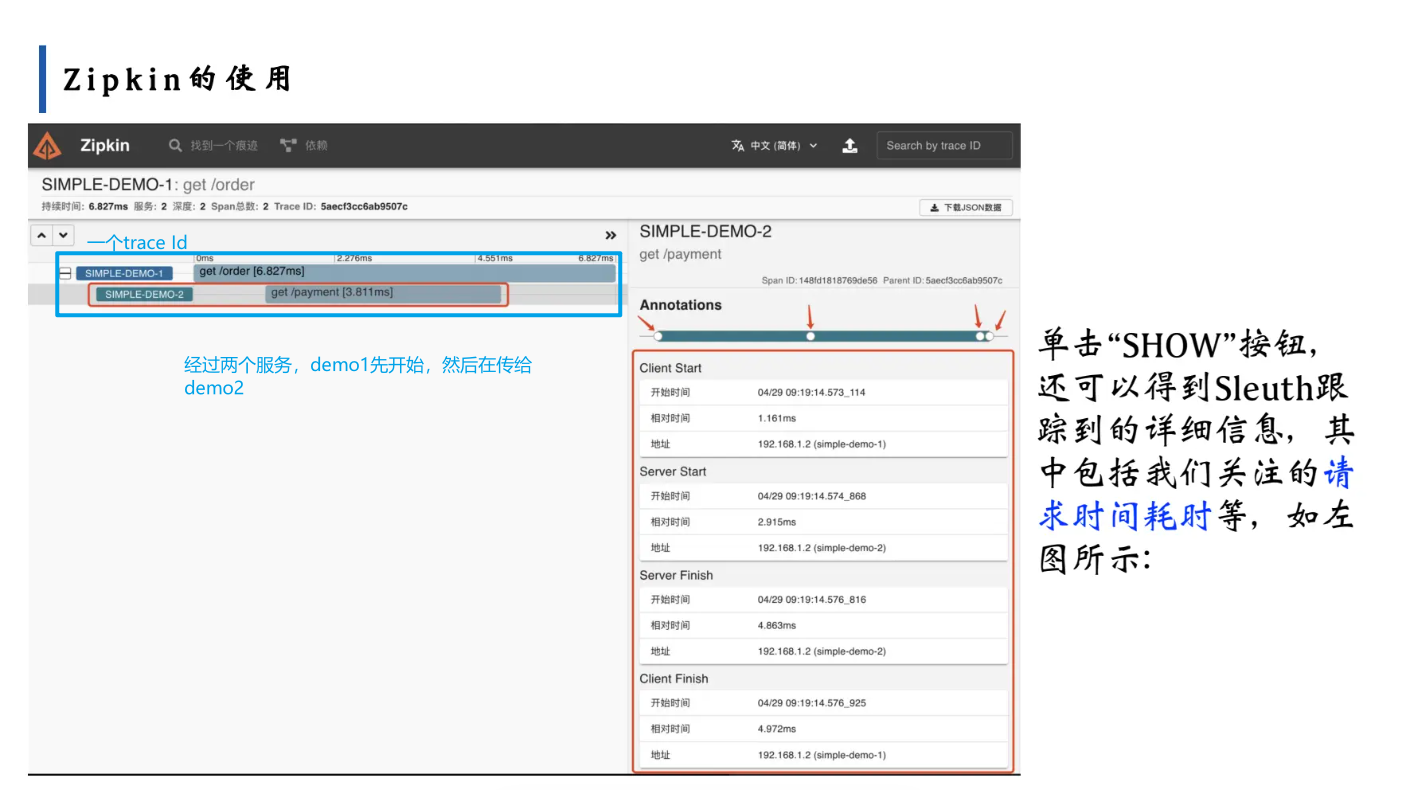
2. 分析单条链路的耗时细节
点击某条链路的“SHOW”按钮,可展开查看:
- 链路的时间轴:每个服务的调用阶段(Client Start、Server Start、Server Finish、Client Finish)及对应的耗时。
- 服务的依赖关系:直观展示
<font style="color:rgb(0, 0, 0);">simple-demo-1</font>调用<font style="color:rgb(0, 0, 0);">simple-demo-2</font>的依赖链路。
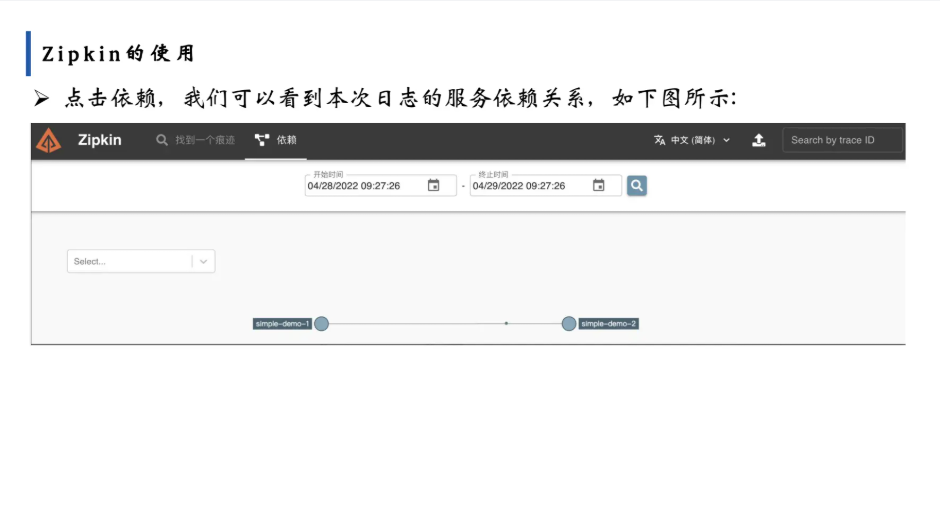
3. 查看服务依赖图
点击界面上的“依赖”标签,可看到服务间的依赖关系图(如 <font style="color:rgb(0, 0, 0);">simple-demo-1</font> → <font style="color:rgb(0, 0, 0);">simple-demo-2</font> 的调用关系)。
三、Zipkin 的核心价值与原理
1. 链路耗时定位
Zipkin 通过记录每个 <font style="color:rgb(0, 0, 0);">Span</font> 的“开始时间”和“结束时间”,计算出各阶段的耗时(如“服务调用的网络耗时”“业务逻辑耗时”),帮助你快速定位“链路中哪个环节最耗时”。
2. 服务依赖分析
通过聚合所有链路数据,Zipkin 能生成服务依赖图,清晰展示“哪些服务被哪些服务调用”“调用频次如何”,为微服务架构优化提供依据。
3. 与 Sleuth 的协同
Sleuth 负责生成链路标记(Trace ID、Span ID)并埋点,Zipkin 负责收集这些标记并做可视化展示,两者结合实现“链路生成→收集→分析”的完整闭环。
四、总结
Zipkin 是微服务链路追踪的“可视化大脑”,它与 Sleuth 配合,让你能直观看到:
- 一条请求在各服务间的流转耗时;
- 服务之间的依赖关系;
- 链路中的异常点(如某服务响应超时)。
相比 ELK,Zipkin 更聚焦“链路耗时与依赖”的分析,是微服务性能优化和问题定位的关键工具。
Elastic Stack(追踪 + 日志 + 指标一体化)
:::color5
Elastic Stack(原 ELK Stack)是微服务**日志集中化、可视化、分析**的核心工具链,
解决了“微服务日志分散、排查难”的痛点。
:::
一、日志采集流程与原理
在微服务场景中,Elastic Stack 的日志流转流程为:
微服务日志文件 → Filebeat(采集) → Kafka(消息队列,可选) → Logstash(处理) → Elasticsearch(存储+检索) → Kibana(可视化)
各组件作用:
:::color5
- Filebeat:轻量级日志采集器,部署在微服务服务器上,实时监控日志文件变化,将日志发送到 Kafka 或直接到 Logstash。
- Kafka:消息队列,用于解耦采集和处理流程,缓冲日志流量(高并发场景可选)。
- Logstash:日志处理管道,可对日志进行过滤、格式化、 enrichment(如添加额外字段),再转发到 Elasticsearch。
- Elasticsearch:分布式搜索引擎,存储日志并提供高效检索能力。
- Kibana:可视化平台,通过图表、仪表盘展示 Elasticsearch 中的日志和链路数据。
:::
二、实战:搭建 Elastic Stack 日志系统
我们基于“微服务 + Filebeat + Logstash + Elasticsearch + Kibana”的架构,实现日志集中化管理。
前期准备:安装中间件
- 安装并启动 ZooKeeper(Kafka 依赖):
zkServer.sh start
- 安装并启动 Kafka:
kafka-server-start.sh config/server.properties
步骤 1:搭建 Elasticsearch
Elasticsearch 是日志的“存储与检索中心”。
1. 下载并启动 Elasticsearch
- 官网下载对应版本:https://www.elastic.co/downloads/elasticsearch
- 启动(以 Mac/Linux 为例):
cd elasticsearch-<version>/bin
./elasticsearch
- 验证:访问
http://localhost:9200,返回 JSON 表示启动成功。
2. 核心配置(config/elasticsearch.yml)
# 集群名称(默认即可)
cluster.name: elasticsearch
# 节点名称(默认即可)
node.name: node-1
# 数据存储路径
path.data: data
# 日志存储路径
path.logs: logs
# 允许外部访问(开发环境临时配置)
network.host: 0.0.0.0
http.port: 9200
步骤 2:搭建 Kibana
Kibana 是日志的“可视化界面”。
1. 下载并启动 Kibana
- 官网下载对应版本:https://www.elastic.co/downloads/kibana
- 启动(以 Mac/Linux 为例):
cd kibana-<version>/bin
./kibana
- 验证:访问
http://localhost:5601,进入 Kibana 界面表示启动成功。
2. 核心配置(config/kibana.yml)
# 连接 Elasticsearch
elasticsearch.hosts: ["http://localhost:9200"]
# 允许外部访问(开发环境临时配置)
server.host: "0.0.0.0"
步骤 3:搭建 Logstash
Logstash 是日志的“处理管道”。
1. 下载并配置 Logstash
- 官网下载对应版本:https://www.elastic.co/downloads/logstash
- 创建配置文件
logstash.conf,定义“从 Kafka 读取日志 → 处理 → 写入 Elasticsearch”:
input {kafka {bootstrap_servers => "localhost:9092" # Kafka 地址topics => "spring-log" # 订阅的 Kafka 主题codec => "json" # 日志格式为 JSON}
}filter {# 可选:日志过滤、格式化逻辑(如解析 Sleuth 链路字段)
}output {elasticsearch {hosts => ["http://localhost:9200"] # Elasticsearch 地址index => "spring-log-%{+YYYY.MM.dd}" # 按天生成索引}
}
2. 启动 Logstash
cd logstash-<version>/bin
./logstash -f /path/to/logstash.conf
步骤 4:搭建 Filebeat
Filebeat 是日志的“采集器”,部署在微服务所在服务器。
1. 下载并配置 Filebeat
- 官网下载对应版本:https://www.elastic.co/downloads/beats/filebeat
- 修改配置文件
filebeat.yml,定义“采集微服务日志 → 发送到 Kafka”:
filebeat.inputs:- type: logenabled: truepaths:- /path/to/your-microservice/logs/*.log # 微服务日志文件路径fields:service: your-microservice-name # 标记服务名称(便于后续区分)output.kafka:enabled: truehosts: ["localhost:9092"] # Kafka 地址topic: "spring-log" # 发送到的 Kafka 主题codec.format:string: "%{[@timestamp]} %{[message]}" # 日志格式
2. 启动 Filebeat
cd filebeat-<version>/
./filebeat -e -c filebeat.yml
步骤 5:微服务配置日志格式
为了让日志能被 Elastic Stack 解析,微服务需输出JSON 格式的日志(包含 Sleuth 链路字段)。
以 Spring Boot 微服务为例,修改 application.properties:
# 配置日志为 JSON 格式
logging.pattern.console=%json%
# 配置日志级别
logging.level.org.springframework.web=INFO
并添加日志依赖(若未添加):
<dependency><groupId>net.logstash.logback</groupId><artifactId>logstash-logback-encoder</artifactId><version>7.4</version>
</dependency>创建 src/main/resources/logback-spring.xml,定义 JSON 日志格式:
<?xml version="1.0" encoding="UTF-8"?>
<!-- 日志配置核心文件,基于 logback 框架,整合 Sleuth 链路信息并输出 JSON 格式 -->
<configuration scan="true" scanPeriod="30 seconds"><!-- 1. 引入默认配置(可选,Spring Boot 已集成部分默认配置) --><include resource="org/springframework/boot/logging/logback/defaults.xml"/><!-- 2. 定义日志格式变量(复用配置,避免重复编写) --><property name="LOG_PATTERN" value="%d{yyyy-MM-dd HH:mm:ss.SSS} [%thread] %-5level %logger{36} - %msg%n"/><!-- 3. 控制台输出配置(开发环境常用) --><appender name="CONSOLE" class="ch.qos.logback.core.ConsoleAppender"><!-- 控制台输出流配置 --><target>System.out</target><!-- 编码器:使用 Logstash 编码器输出 JSON 格式日志 --><encoder class="net.logstash.logback.encoder.LogstashEncoder"><!-- 包含 Sleuth 上下文数据(Trace ID、Span ID 等链路信息) --><includeContextData>true</includeContextData><!-- 过滤不需要的上下文字段(可选,精简日志) --><includeMdcKeyName>traceId</includeMdcKeyName> <!-- 必须保留:Sleuth 全局链路 ID --><includeMdcKeyName>spanId</includeMdcKeyName> <!-- 必须保留:Sleuth 步骤 ID --><includeMdcKeyName>spanExportable</includeMdcKeyName> <!-- 链路是否可导出 --><includeMdcKeyName>X-B3-TraceId</includeMdcKeyName> <!-- B3 协议 Trace ID --><includeMdcKeyName>X-B3-SpanId</includeMdcKeyName> <!-- B3 协议 Span ID --><!-- 自定义字段:添加服务名称(便于在 Kibana 中按服务筛选) --><customFields>{"service":"${spring.application.name:-unknown-service}"}</customFields><!-- 时间戳格式(统一为 ISO 格式,便于 Elasticsearch 解析) --><timestampPattern>yyyy-MM-dd'T'HH:mm:ss.SSSXXX</timestampPattern><!-- 日志字段映射(可选,重命名字段使其更符合业务习惯) --><fieldNames><timestamp>logTimestamp</timestamp> <!-- 重命名时间戳字段 --><message>logMessage</message> <!-- 重命名日志内容字段 --><logger>loggerName</logger> <!-- 重命名日志器名称字段 --><thread>threadName</thread> <!-- 重命名线程名字段 --><level>logLevel</level> <!-- 重命名日志级别字段 --></fieldNames></encoder></appender><!-- 4. 文件输出配置(生产环境常用,按天滚动切割) --><appender name="FILE" class="ch.qos.logback.core.rolling.RollingFileAppender"><!-- 日志文件路径及名称(建议使用绝对路径) --><file>/var/log/microservice/${spring.application.name}/app.log</file><!-- 滚动策略:按时间+大小切割 --><rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy"><!-- 滚动文件命名格式(按天归档,保留 30 天日志) --><fileNamePattern>/var/log/microservice/${spring.application.name}/app-%d{yyyy-MM-dd}.%i.log</fileNamePattern><maxHistory>30</maxHistory> <!-- 日志保留天数 --><!-- 按大小切割(单个文件超过 100MB 时触发切割) --><timeBasedFileNamingAndTriggeringPolicy class="ch.qos.logback.core.rolling.SizeAndTimeBasedFNATP"><maxFileSize>100MB</maxFileSize></timeBasedFileNamingAndTriggeringPolicy></rollingPolicy><!-- 编码器:与控制台一致,确保文件日志也是 JSON 格式 --><encoder class="net.logstash.logback.encoder.LogstashEncoder"><includeContextData>true</includeContextData><includeMdcKeyName>traceId</includeMdcKeyName><includeMdcKeyName>spanId</includeMdcKeyName><customFields>{"service":"${spring.application.name:-unknown-service}"}</customFields><timestampPattern>yyyy-MM-dd'T'HH:mm:ss.SSSXXX</timestampPattern></encoder></appender><!-- 5. 日志级别配置(可针对不同包设置不同级别) --><root level="INFO"><!-- 开发环境:输出到控制台 --><appender-ref ref="CONSOLE" /><!-- 生产环境:输出到文件(取消注释即可) --><!-- <appender-ref ref="FILE" /> --></root><!-- 6. 自定义包日志级别(示例) --><!-- 降低 Spring 框架日志级别,避免冗余 --><logger name="org.springframework" level="WARN" additivity="false"><appender-ref ref="CONSOLE" /><appender-ref ref="FILE" /></logger><!-- 提高业务包日志级别,便于调试 --><logger name="com.yourcompany.business" level="DEBUG" additivity="false"><appender-ref ref="CONSOLE" /><appender-ref ref="FILE" /></logger>
</configuration>1. 核心功能
- JSON 格式输出:日志以 JSON 结构展示,包含时间戳、级别、消息、服务名等字段,便于 Elastic Stack 解析
- 链路信息整合:自动包含 Sleuth 生成的
traceId(全局链路 ID)和spanId(步骤 ID),支持全链路追踪 - 多环境适配:同时配置了控制台输出(开发环境)和文件输出(生产环境),可按需切换
- 日志切割:文件日志按天 + 大小滚动,避免单文件过大,默认保留 30 天
2. 配置生效流程
- 微服务启动时,Spring Boot 会自动加载
logback-spring.xml配置 - 日志输出时,
LogstashEncoder会将日志转换为 JSON 格式,并注入 Sleuth 链路信息 - Filebeat 监控日志文件(或控制台输出),将 JSON 日志发送到 Elastic Stack
- Elasticsearch 存储日志后,可在 Kibana 中通过
traceId搜索完整链路日志
3. 自定义调整
- 服务名称:修改
application.properties中的spring.application.name,日志会自动带上该服务名 - 日志路径:调整
logback-spring.xml中FILEappender 的file和fileNamePattern路径 - 保留天数:修改
maxHistory调整日志保留时间(默认 30 天) - 日志级别:通过
<logger>标签为不同包配置级别(如DEBUG用于开发,INFO用于生产)
步骤 6:验证日志流转
- 启动微服务,触发业务请求(如访问接口),生成日志。
- Filebeat 采集日志并发送到 Kafka 主题
spring-log。 - Logstash 从 Kafka 消费日志,处理后写入 Elasticsearch。
- 打开 Kibana(
http://localhost:5601),创建索引模式spring-log-*,即可在“Discover”中看到集中化的日志,且能通过traceId等 Sleuth 字段筛选链路。
4. 验证配置
启动服务后,控制台会输出类似以下的 JSON 日志(格式化后):
json
{"logTimestamp": "2024-09-21T15:30:00.123+08:00","logLevel": "INFO","loggerName": "com.yourcompany.controller.OrderController","threadName": "http-nio-8080-exec-1","logMessage": "订单创建成功","service": "order-service","traceId": "4d2e63ad9bc890b","spanId": "ddfe378c0a8ec7cc","spanExportable": "true"
}若能看到包含 traceId 和 spanId 的 JSON 日志,说明配置生效。
三、各组件作用总结
| 组件 | 作用 | 核心价值 |
|---|---|---|
| Filebeat | 轻量级日志采集,实时监控文件变化 | 无侵入、性能开销小 |
| Kafka | 消息队列,解耦采集与处理,缓冲高并发日志流量 | 削峰填谷、流量控制 |
| Logstash | 日志过滤、格式化、 enrichment | 灵活处理复杂日志需求 |
| Elasticsearch | 分布式存储与检索,支持秒级全文检索、聚合分析 | 存储+检索的核心引擎 |
| Kibana | 可视化仪表盘,支持图表、链路追踪展示 | 让日志“可视化、可分析” |
四、整流程示例
整体流程概览
用户请求 → 微服务调用(生成带链路信息的日志) → Filebeat采集 → Kafka缓冲 → Logstash处理 → Elasticsearch存储 → Kibana可视化
分步详解(含代码与验证)
步骤1:微服务调用与日志生成
作用:接收用户请求,触发服务间调用,生成包含Sleuth链路信息的JSON日志。
1.1 微服务A(订单服务,端口8080)代码
// OrderController.java
package com.example.order.controller;import lombok.extern.slf4j.Slf4j;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.PathVariable;
import org.springframework.web.bind.annotation.RestController;
import org.springframework.web.client.RestTemplate;@RestController
@Slf4j // 日志注解
public class OrderController {@Autowiredprivate RestTemplate restTemplate;// 用户下单接口@GetMapping("/order/create/{userId}")public String createOrder(@PathVariable String userId) {log.info("用户[{}]开始创建订单", userId); // 生成业务日志// 调用微服务B(库存服务)String stockResult = restTemplate.getForObject("http://localhost:8081/stock/deduct/" + userId, String.class);log.info("用户[{}]订单创建完成,库存处理结果:{}", userId, stockResult);return "订单创建成功:" + stockResult;}
}
1.2 微服务B(库存服务,端口8081)代码
// StockController.java
package com.example.stock.controller;import lombok.extern.slf4j.Slf4j;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.PathVariable;
import org.springframework.web.bind.annotation.RestController;@RestController
@Slf4j
public class StockController {// 扣减库存接口@GetMapping("/stock/deduct/{userId}")public String deductStock(@PathVariable String userId) {log.info("开始为用户[{}]扣减库存", userId); // 生成业务日志// 模拟库存扣减逻辑log.info("用户[{}]库存扣减完成", userId);return "库存扣减成功";}
}
1.3 日志配置(复用之前的完整配置)
- 确保两个服务都已配置
logback-spring.xml和application.properties(含Sleuth和JSON日志格式)。
1.4 启动服务并触发调用
- 启动微服务A和B。
- 发送请求:
http://localhost:8080/order/create/1001。 - 验证日志生成:
查看两个服务的控制台,会输出包含traceId、spanId、service等字段的JSON日志,例如:
{"logTimestamp": "2024-09-21T16:30:00.456+08:00","logLevel": "INFO","loggerName": "com.example.order.controller.OrderController","message": "用户[1001]开始创建订单","service": "order-service","traceId": "a1b2c3d4e5f6g7h8","spanId": "1a2b3c4d5e6f7g8h"
}
步骤2:Filebeat采集日志
作用:监控微服务日志文件,将JSON日志发送到Kafka。
2.1 Filebeat配置(filebeat.yml)
# 采集源配置
filebeat.inputs:- type: logenabled: truepaths:- /var/log/microservice/order-service/*.log # 微服务A的日志路径- /var/log/microservice/stock-service/*.log # 微服务B的日志路径fields:log_source: "microservice" # 自定义字段,标记日志来源# 输出到Kafka
output.kafka:hosts: ["localhost:9092"]topic: "micro-log-topic" # 发送到的Kafka主题codec:json:pretty: false # 不格式化JSON,节省空间# 关闭无关模块(可选)
filebeat.modules:- module: systemenabled: false
2.2 启动Filebeat并验证
- 启动命令:
./filebeat -e -c filebeat.yml。 - 验证采集:
查看Filebeat控制台,若出现类似Successfully published events的日志,说明采集成功。
步骤3:Kafka缓冲日志
作用:接收Filebeat的日志,作为中间件缓冲流量,解耦采集与处理。
3.1 查看Kafka消息(验证)
- 启动Kafka消费者,监听主题
micro-log-topic:
kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic micro-log-topic
- 再次发送请求
http://localhost:8080/order/create/1001,消费者会打印出接收到的JSON日志,说明Kafka已接收。
步骤4:Logstash处理日志
作用:从Kafka读取日志,过滤/格式化后发送到Elasticsearch。
4.1 Logstash配置(logstash.conf)
# 输入:从Kafka读取
input {kafka {bootstrap_servers => "localhost:9092"topics => ["micro-log-topic"]codec => "json" # 解析JSON格式日志}
}# 过滤:添加/提取字段(示例:提取userId到单独字段)
filter {# 从日志message中提取userId(正则匹配“用户[1001]”中的1001)grok {match => { "message" => "用户\[(?<userId>[0-9]+)\]" }add_field => { "extracted_userId" => "%{userId}" } # 添加自定义字段}# 移除无效字段,精简日志mutate {remove_field => ["@version", "host"]}
}# 输出:到Elasticsearch
output {elasticsearch {hosts => ["http://localhost:9200"]index => "micro-log-%{+YYYY.MM.dd}" # 按天创建索引}# 同时输出到控制台(调试用)stdout { codec => rubydebug }
}
4.2 启动Logstash并验证
- 启动命令:
./logstash -f logstash.conf。 - 验证处理:
查看Logstash控制台,会输出处理后的日志(包含extracted_userId字段),说明处理成功。
步骤5:Elasticsearch存储日志
作用:存储结构化日志,提供全文检索能力。
5.1 验证日志存储
- 访问Elasticsearch索引列表:
http://localhost:9200/_cat/indices?v。 - 会看到名为
micro-log-2024.09.21的索引(日期为当天),说明日志已存储。 - 查看具体日志:
http://localhost:9200/micro-log-2024.09.21/_search,返回结果中包含完整日志信息。
步骤6:Kibana可视化日志
作用:通过界面查询、分析、展示Elasticsearch中的日志。
6.1 配置Kibana索引模式
- 打开Kibana:
http://localhost:5601。 - 进入 Management → Stack Management → Index Patterns → Create index pattern。
- 输入索引模式
micro-log-*,点击 Next step,选择时间字段logTimestamp,完成创建。
6.2 查询与分析日志
- 进入 Discover 页面,选择
micro-log-*索引模式。 - 可通过以下方式查询:
- 按
traceId搜索:输入traceId:a1b2c3d4e5f6g7h8,查看完整调用链路日志。 - 按服务名筛选:输入
service:order-service,查看订单服务的所有日志。 - 按
extracted_userId搜索:输入extracted_userId:1001,查看用户1001的所有操作日志。
- 按
流程总结与各组件作用
| 环节 | 组件/操作 | 核心作用 | 数据形态变化 |
|---|---|---|---|
| 1. 调用与日志生成 | 微服务A/B + Sleuth | 生成带链路信息(traceId/spanId)的JSON日志 | 业务日志 → 带链路标记的JSON日志 |
| 2. 日志采集 | Filebeat | 监控日志文件,发送到Kafka | JSON日志 → 原样转发至Kafka |
| 3. 流量缓冲 | Kafka | 接收并暂存日志,解耦上下游 | 日志暂存,等待Logstash消费 |
| 4. 日志处理 | Logstash | 过滤、提取字段(如userId),格式化日志 | 原始JSON → 带业务字段的结构化日志 |
| 5. 日志存储 | Elasticsearch | 存储日志,提供检索能力 | 结构化日志 → 分布式索引存储 |
| 6. 可视化分析 | Kibana | 界面化查询、展示日志 | 索引数据 → 可交互的日志仪表盘 |
通过这个流程,原本分散在两个微服务的日志被集中管理,结合Sleuth的链路标记,可快速定位“哪个用户的哪个请求在哪个服务出了问题”,彻底解决微服务日志排查难题。