ACP(六)自动化评测机器人的表现
评估RAG应用表现
答疑机器人存在的问题
在前面的章节中,完成了一个答疑机器的开发,但你发现它目前在员工查询类的问题上表现不佳。
比如,张伟是员工信息表里的第一个员工,但是你的答疑机器人中却无法回答[张伟是哪个部门的]

from chatbot import rag
query_engine = rag.create_query_engine(rag.load_index())
print('提问:张伟是哪个部门的')
response = query_engine.query('张伟是哪个部门的')
print('回答:', end='')
response.print_response_stream()
提问:张伟是哪个部门的
回答:根据提供的信息,没有提到张伟所在的部门。如果您能提供更多关于张伟的信息,我可能能够帮助您找到答案。
查看RAG检索结果排查问题
为了解决这个问题,你需要确认在你的答疑机器人回答问题前,召回的参考资料里是带有张伟的相关资料。
通过下面的代码,可以获取到答疑机器回答这次问题检索至的参考信息。
contexts = [node.get_content() for node in response.source_nodes]
contexts
#输出示例
['核,提供⾏政管理与协调⽀持,优化⾏政⼯作流程。 \n⾏政部 秦⻜ 蔡静 G705 034 ⾏政 ⾏政专员 13800000034 qinf@educompany.com 维护公司档案与信息系统,负责公司通知及公告的发布,','⽀持。 \n绩效管理部 韩杉 李⻜ I902 041 ⼈⼒资源 绩效专员 13800000041 hanshan@educompany.com 建⽴并维护员⼯绩效档案,定期组织绩效评价会议,协调各部⻔反馈,制定考核流程与标准,确保绩效']
尝试建立自动化测试机制
尽管你总是能想办法定位到问题,但是如果每次都要这样去确认是检索出错、还是检索正确但模型生成答案出错,会非常耗时。你应该建立一个测试机制,能够自动地对你准备的一批问题进行测试。
在前面的学习中,你已经tduy大模型可以用来回答问题、检查错误。同样的,大模型也可以用于检测答疑机器人的回复是否准确回答了问题,只要在提示词中提供参考信息并限制回答样式即可。
下边的test_answer函数可以用来检测答疑机器人的回答是否有效回答了问题,你需要在提示词传入问题与答疑机器人的回答,并限制回答样式为:“只能是:有效回答 或者 无效回答”。
from chatbot import llmdef test_answer(question, answer):prompt = ("你是一个测试人员。\n""你需要检测下面的这段回答是否有效回答了用户的问题。\n""回复只能是:有效回答 或者 无效回答。请勿给出其他信息。\n""------"f"回答是 {answer}""------"f"问题是: {question}")return llm.invoke(prompt,model_name="qwen-max")test_answer("张伟是哪个部门的", "根据提供的信息,没有提到张伟所在的部门。如果您能提供更多关于张伟的信息,我可能能够帮助您找到答案。")
#输出:无效回答
传入的回答没有有效地回复“张伟是哪个部门的”这个问题,大模型回复的“无效回答”符合预期。
在RAG应用中,除了回答的有效性,你还需要确保检索到参考信息是否有用。下边的test_contexts函数可以用来检测检索到的参考信息是否有效,你需要在提示词中传入问题与检索到的参考信息,并限制回答样式为:“只能是:参考信息有用 或者 参考信息无用”。
def test_contexts(question, contexts):prompt = ("你是一个测试人员。\n""你需要检测下面的这些参考资料是否能对回答问题有帮助。\n""回复只能是:参考信息有用 或者 参考信息无用。请勿给出其他信息。\n""------"f"参考资料是 {contexts}""------"f"问题是: {question}")return llm.invoke(prompt,model_name="qwen-max")
test_contexts("张伟是哪个部门的", "核,提供⾏政管理与协调⽀持,优化⾏政⼯作流程。 \n⾏政部 秦⻜ 蔡静 G705 034 ⾏政 ⾏政专员 13800000034 qinf@educompany.com 维护公司档案与信息系统,负责公司通知及公告的发布,\n\n⽀持。 \n绩效管理部 韩杉 李⻜ I902 041 ⼈⼒资源 绩效专员 13800000041 hanshan@educompany.com 建⽴并维护员⼯绩效档案,定期组织绩效评价会议,协调各部⻔反馈,制定考核流程与标准,确保绩效")
#输出 '参考信息无用'
有了上面的两个方法,你已经初步搭建好了一个大模型测试工程雏形,但截至目前的实现还并完善,比如:
- 因为大模型有时候会捏造事实(幻觉),其给出的答案看起来就像是真的一样,对于这种情况
test_answer方法并不能很好的检测出来。 - 检索召回的参考信息中相关的信息占比越多越好(信噪比),但目前我们的测试方法还比较简单,没有考虑这些。
你可以考虑使用一些成熟的测试框架来进一步完善你的测试工程,比如Ragas,它是一个专门设计用于评估RAG应用表现的测试框架。
RAG自动化评测体系
为了系统化地评测RAG系统,业界出现了一些非常实用的开源自动经评测框架,这些框架通常会从以下几个维度进行评估:
- 召回质量(Retrieval Quality):RAG系统是否检索到了正确且相关的文档片段?
- 答案忠实度(Faithfulness):生成的答案是否完全基于检索到的上下文,没有“胡编乱造”(幻觉)?
- 答案相关性(Answer Relevance):生成的答案是否准确地回答了用户的问题?
- 上下文利用率/效率(Context Utilixation/Efficiency):大模型是否有效地利用了所有提供给它的上下文信息?
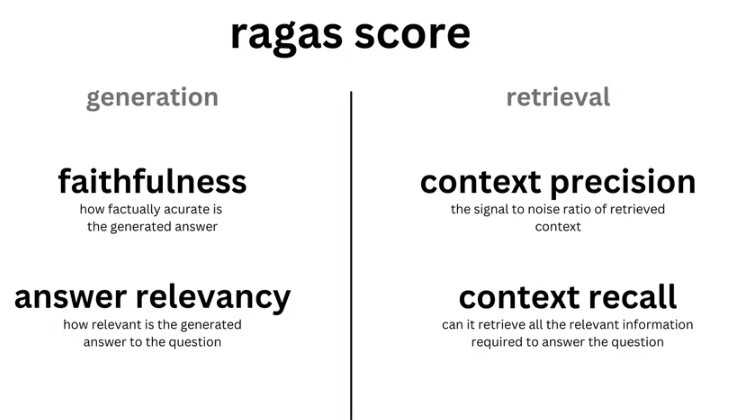
Ragas
这是领域里非常出名的一个框架,它的核心思想是“让大模型来帮助你评估RAG系统”。在评测时,Ragas要会调用一个大模型作为评测专家来阅读你的问题、RAG检索到的上下文和生成的答案,然后根据预设的指标给出分数。Ragas要的评估指标高度契合RAG系统的痛点,主要包括:
- 整体回答质量的评估:
- Answer Correctness,用于评估RAG应用生成答案的准确度。
- 生成环节的评估:
- Answer Relevancy,用于评估RAG应用生成的答案是否与问题相关。
- Faithfulness ,用于评估RAG应用生成的答案和检索到的参考资料的事实一致性
- 召回阶段的评估:
- Context Precision,用于评估contexts中与准确答案相关的条目是否排名靠前、占比高(信噪比)。
- Context Recall,用于评估有多少相关参考资料被检索到,越高的得分意味更少的相关参考资料被遗漏
该框架提供了Python库,只需几千代码就能集成到你的RAG工作流中。
Trulens
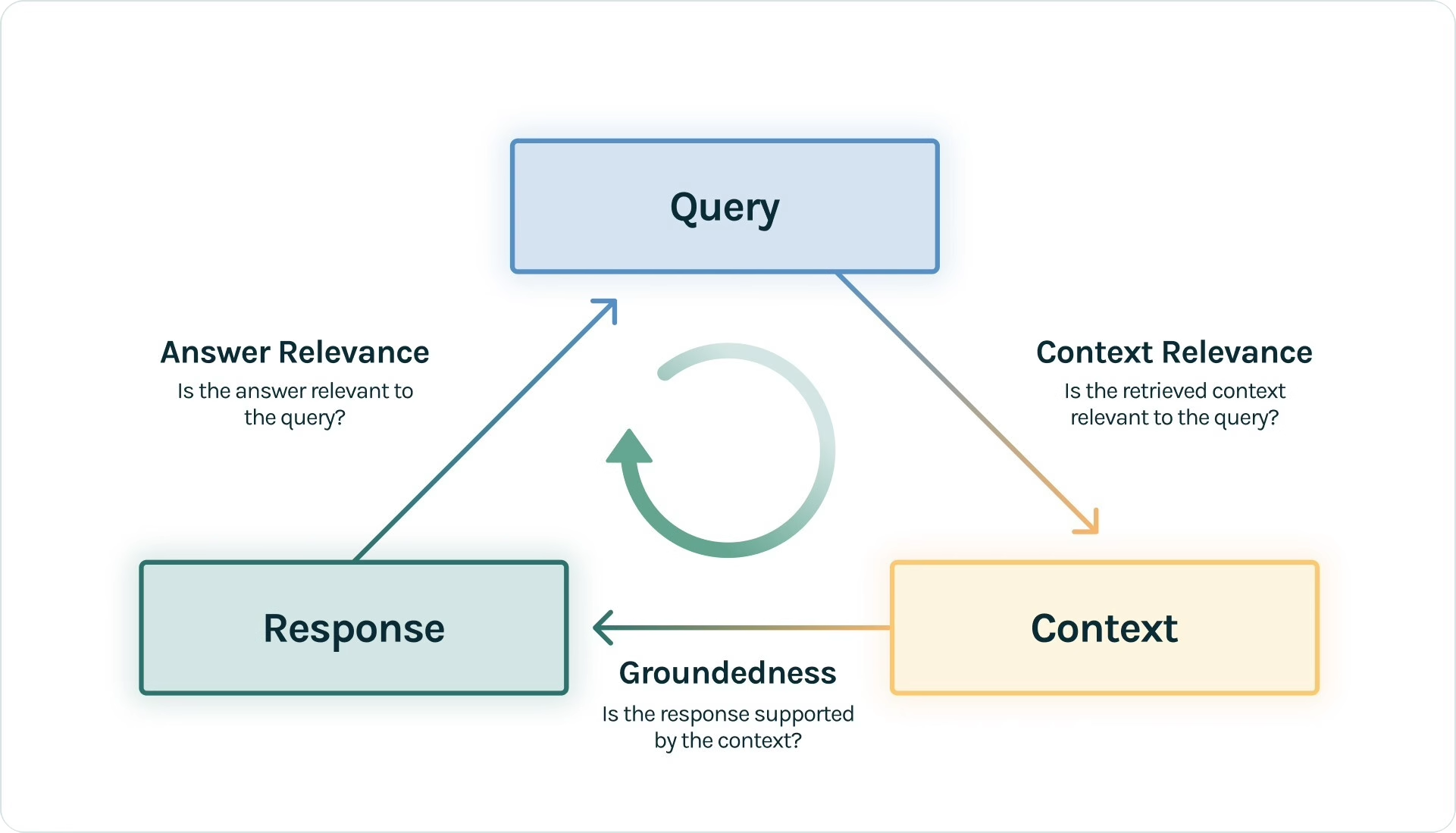
这个框架专注于评估的可观测性,它不仅仅告诉你RAG哪里可能有问题,它还能帮你追溯RAG的整个运行过程。包括每次运行的输入、输出、中间步骤、调用的大模型、检索召回的上下文等等,并提供一系列“反馈函数”自动化评估这些运行。TruLens框架可以与LangChain、LlamaIndex等框架无缝集成,并提供了一套可视化工具,展示每次RAG调用的详细过程。同时,TruLens提供了细粒度的反馈函数,从多个角度评估RAG性能,帮助你快速定位问题。其主要评估指标包括:
- Groundedness:生成的答案是否来自于检索召回的知识
- Answer Relevansce:生成的答案是否与问题相关
- Context Relevance: 评估召回的知识是否跟问题相关
你也可以访问 TruLens官网了解其他评估指标如(User sentiment、Fairness and bias)等等。
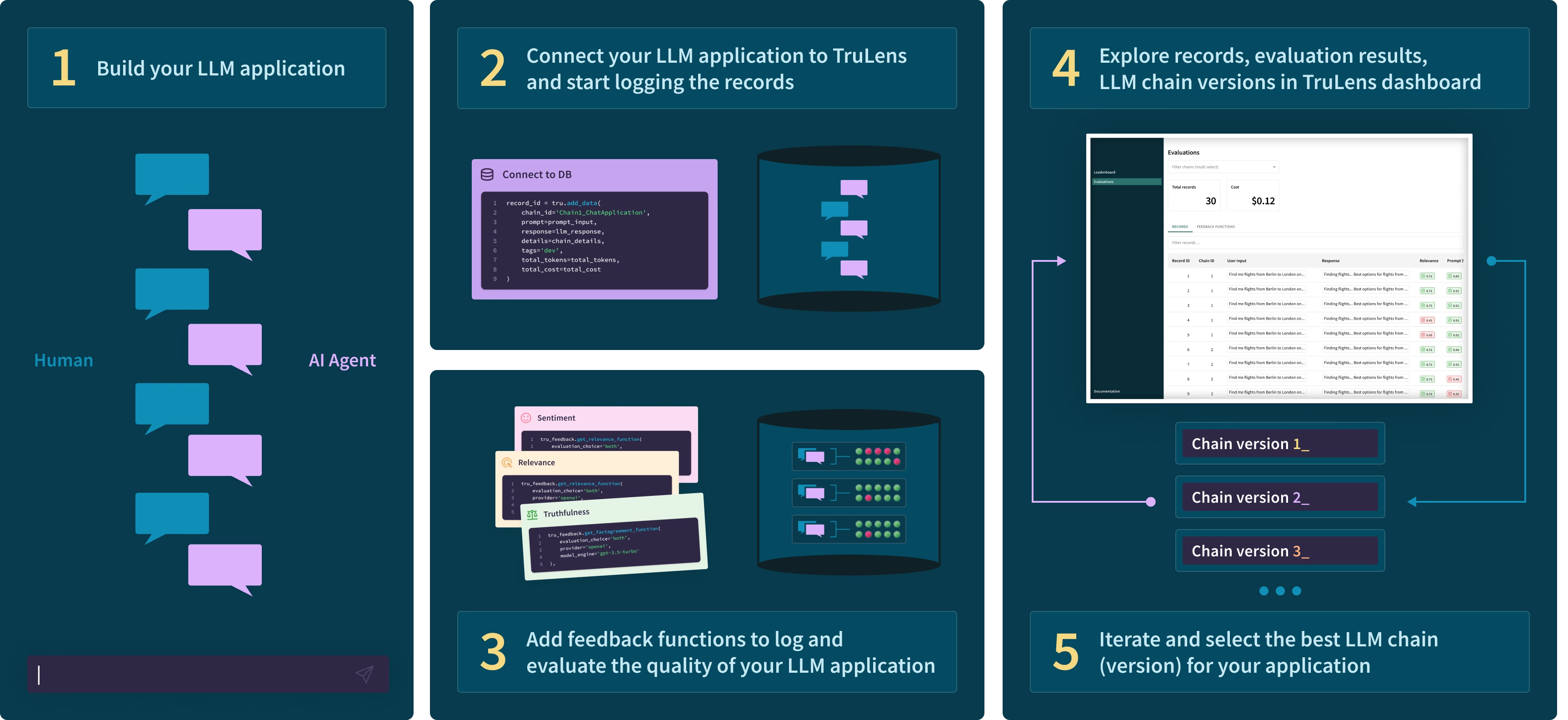
DeepEval
DeepEval则将传统软件开发的测试理念引入到RAG应用中,它鼓励你采用单元测试和驱动开发(TDD)的思想,在RAG功能开发前就编写评估测试,确保应用性能从一开始就符合预期。为此,DeepEval提供了一个专门的测试框架,让你能够像编写传统软件的单元测试一样,为RAG系统创建LLM评估测试。它支持为每个测试用例设置明确的通过/失败(Pass/Fail)阈值,这使得DeepEval能轻松集成到你的持续集成/持续部署(CI/CD)流程中,从而实现自动化回归测试。DeepEval的主要评测指标类似Ragas,也支持Faithfulness,Answer Relevance,Context Relevance,Context Recall等。
自定义评测框架
除了前面介绍的Ragas、TruLens、DeepEval等专业评测框架,你可能也接触过其他的开源评测工具,比如LlamaIndex和LangChain这些主流RAG开发框架本身也有内置评估工具。这些评估工具能让你在构建RAG流程的同时,方便地进行性能评估,实现无缝衔接。但是,在某些特定场景下,你可能需要更灵活、更贴合业务的评估方式,这时你也可以选择自定义评测框架。
对于评测一个智能客服系统而言,你不仅仅想知道RAG有没有“瞎说”(Faithfulness)或者答案是否“想关”(Relevance),你更想知道它是事符合你业务的特定规则,或者提供的答案是否真正解决了用户的痛点。
- 案例一:当用户询问“报销的流程是什么?”,你们的业务专家可能会要求“好的报销答案,必须明确包含报销单链接和二级主管审批信息。”或者“好的答案,必须引导用户到费用系统提交报销申请。”,这样才能满足**“流程合规”**的要求。
- 案例二:当用户询问“订单延迟了怎么办?”,更好的回答可能是先要“安抚用户的情绪,再给出物流状态,预期送达时间、延误原因(如果已知)、以及后续处理(如退款/投诉)的指引。”,而不是仅仅是回答“您的订单正在派送中,请耐心等待”。
因此,你可能把“流程可操作性”、“政策合规性”、“情绪安抚度”、“问题解决完备性”等指标,加入你的自定义评测框架。
请注意,领域专家的尝试参与是评测系统乃至AI应用成功的关键。使用自动化评测框架并非要让机器彻底取代人工判断,而是旨在为评测提效。前而介绍的许多自动化框架(如Ragas)会利用大模型来充当“评委”,对RAG表现进行初步判断。然而,只有领域专家才能提供那些最宝贵的、真正反映业务需要的高价值“正确答案”(Ground Truth),并对用户提问和RAG回答的正确性进行权威性的审定。
因此,我们必须让领域专家尝试参与到评测集的构建和系统性评估中。自动化评测的真正价值,在于它能将专家提价的这些宝贵Ground Truth或评估标准,转化为大规模、可重复的日常评测任务,从而解放专家的时间,让他们聚集于更具挑战性的问题分析和优化策略制定,而非陷入重复性的判断劳动中。
使用Ragas 来评估应用表现
你可以使用Ragas来做全链路评测,这只需要在你的Python项目中加入几行代码。
评估RAG应用回答质量
快速上手
在评估RAG应用整体回答质量时,使用Ragas的Answer Correctness是一个很好的指标。为了计算这个指标,你需要准备以下两种数据来评测RAG应用产生的answer质量:
- question(输入给RAG应用的问题)
- ground_truth(你预知道的正确的答案)
为了便于展示不同回答的评测指标差异,我们针对问题「张伟是哪个部门的」准备了三组RAG应用回答:
| question | ground_truth | answer |
|---|---|---|
| 张伟是哪个部门的 | 张伟是教研部的。 | 根据提供的信息,没有提到张伟所在的部门。如果您能提供更多关于张伟的信息,我可能能够帮助您找到答案。(无效答案) |
| 张伟是哪个部门的 | 张伟是教研部的。 | 张伟是人事部门的。(幻觉) |
| 张伟是哪个部门的 | 张伟是教研部的。 | 张伟是教研部的。(正确) |
然后我们就可以运行下面的代码,来计算回答准确度(即Answer Correctness)的得分。
from langchain_community.llms.tongyi import Tongyi
from langchain_community.embeddings import DashScopeEmbeddings
from datasets import Dataset
from ragas import evaluate
from ragas.metrics import answer_correctnessdata_samples = {'question': ['张伟是哪个部门的?','张伟是哪个部门的?','张伟是哪个部门的?'],'answer': ['根据提供的信息,没有提到张伟所在的部门。如果您能提供更多关于张伟的信息,我可能能够帮助您找到答案。','张伟是人事部门的','张伟是教研部的'],'ground_truth':['张伟是教研部的成员','张伟是教研部的成员','张伟是教研部的成员']
}dataset = Dataset.from_dict(data_samples)
score = evaluate(dataset = dataset,metrics=[answer_correctness],llm=Tongyi(model_name="qwen-plus"),embeddings=DashScopeEmbeddings(model="text-embedding-v3")
)
score.to_pandas()

可以看到,Ragas的Answer Correctness 指标准确的反映出了三种回答的表现,越符合事实的answer得分越高。
了解answer correctness的计算过程
从直观感受上Answer correctness 的打分确实与你的预期相符。它在打分过程使用到了大模型(代码中的llm=Tongyi(model_name="qwen-plus"))与embedding模型(代码中的embeddings=DashscopeEmbeddings(model="text-emdedding-v3")),由answer和ground_truth的语言相似度和事实准确度计算得出。
语义相似度
语义相似度是通过embedding模型得到answer 和ground_truth的文本向量,然后计算两个文本向量的相似度。向量相似度的计算有许多种方法,如余弦相似度、欧氏距离、曼哈顿距离等,Ragas使用了最常用的余弦相似度。
事实准确度
事实准确度是衡量answer与ground_truth在事实描述上差异的指标。比如以下两个描述:
- answer:张伟是教研部负责大模型课程的同事。
- ground_truth:张伟是教研部负责大数据方向的同事。
answer 和ground_truth 在事实描述上存在差异(工作方向),但也存在一致的地方(工作部门)。这样的差异很难通过大模型或embedding模型的简单调用来量化。Ragas通过大模型将answer与ground_truth分别生成各自的观点列表,并对观点列表中的元素进行比较与计算。
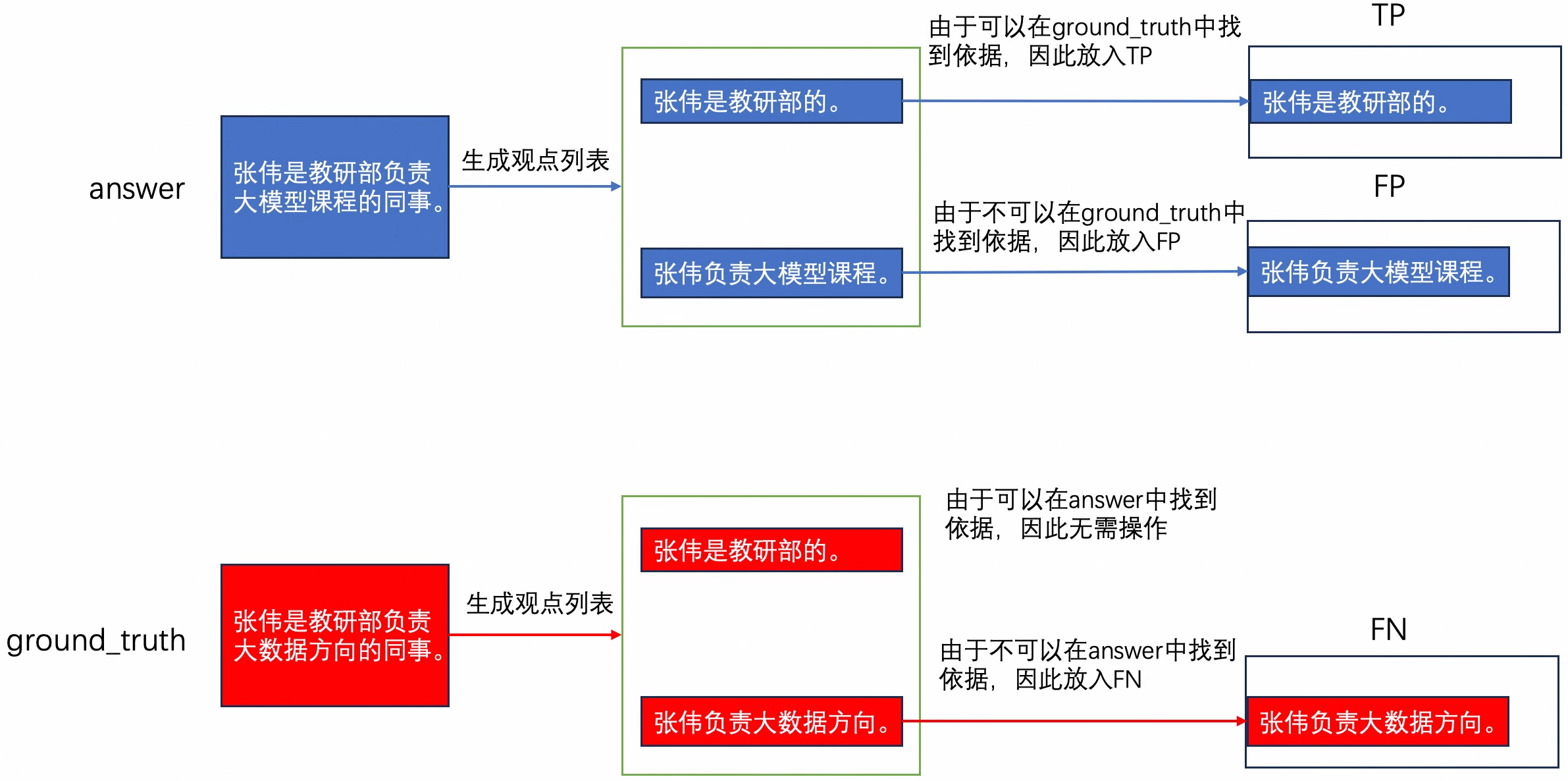
下图可能帮助你理解Ragas衡量事实准确的方法:
-
通过大模型将answer、ground_truth分别生成各自的观点列表。比如:
- 生成 answer 的观点列表: 张伟是教研部负责大模型课程的同事。 —> [“张伟是教研部的”, “张伟负责大模型课程”]
- 生成 ground_truth 的观点列表:张伟是教研部负责大数据方向的同事。—> [“张伟是教研部的”, “张伟负责大数据方向”]
-
遍历answer与ground_truth列表,并初始化三个列表,TP、FP与FN
- 对于由answer生成的观点
- 如果该观点与ground_truth的观点相匹配,则将该观点添加到TP列表中。比如:「张伟是教研部的」。
- 如果该观点在 ground_truth 的观点列表中找不到依据,则将该观点添加到FP列表中。比如:「张伟负责大模型课程」。
- 对于ground_truth生成的观点
- 如果该观点在 answer 的观点列表中找不到依据,则将该陈述添加到FN列表中。比如:「张伟负责大数据方向」。
- 对于由answer生成的观点
该步骤的判断过程均由大模型提供。
- 统计TP、FP与FN列表的元素个数,并按照以下方式计算f1 score分数:
f1 score = tp / (tp + 0.5 * (fp + fn)) if tp > 0 else 0
以上文为例:f1 score = 1/(1+0.5*(1+1)) = 0.5
分数汇总
得到语义相似度和事实准确的分数后,对两者加权求和,即可得到最终的Answer Correctness的分数。
Answer Correctness 的得分 = 0.25 * 语义相似度得分 + 0.75 * 事实准确度得分
评估检索召回效果
快速上手
Ragas中的context precision 和 context recall 指标可以用于评估RAG应用中的检索的召回效果。
- Context precision 会评估检索召回的参考信息(contexts) 中与准确答案相关的条目是否排名靠前、占比高(信噪比),侧重相关性。
- Context recall则会评估contexts与ground_truth的事实一致性程度,侧重事实准确度。
实际应用时,可以将两者结合使用。
为了计算这些指标,你需要准备的数据集应该包括以下信息:
- question,输入给RAG的问题。
- contexts,检索召回的参考信息。
- ground_truth,你预先知道的正确的答案
你可以继续使用「张伟是哪个部门的」这个问题,准备三级数据,运行下面的代码,来同时计算context precision 和 context recall的得分
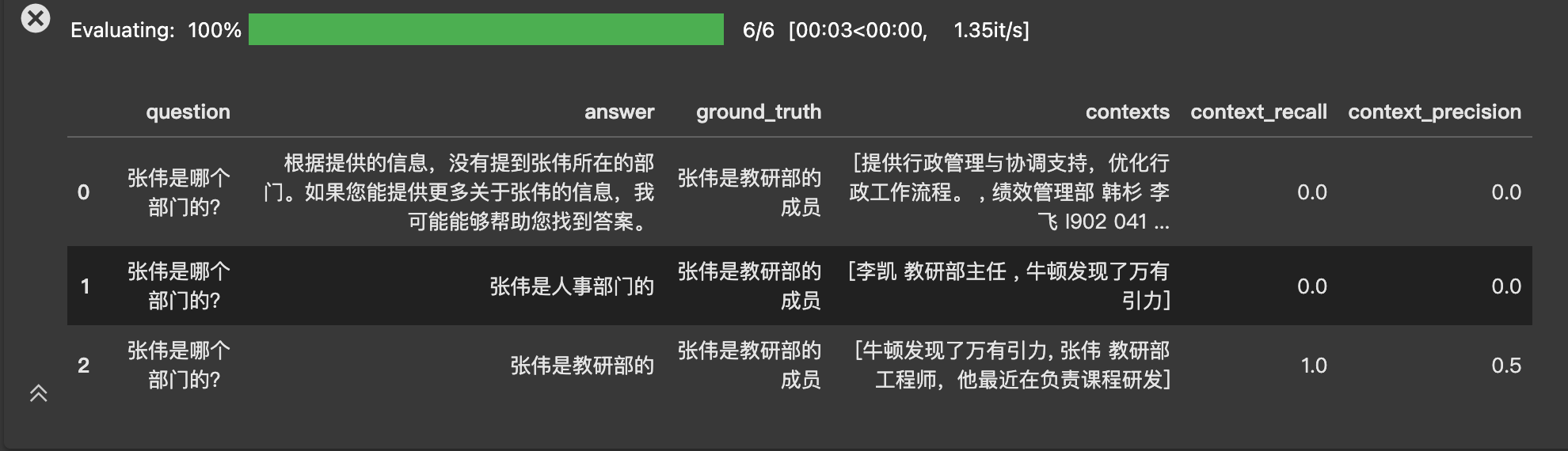
由上面的数据可以看到:
- 最后一行数据的回答是准确的
- 过程中检索到的参考资料(contexts)中包含了正确答案的观点,即「张伟是教研部的」。这一情况体现在了context recall得分为1
- 但是context中并不是每一条都是和和问题及答案相关的,比如「牛顿发现了万有引力」。这一情况体现在了context precision 得分为0.5
了解context recall和context precision的计算过程
Context recall
你已经从上文了解到context recall 是衡量contexts与ground_truth是否一致的指标。
在Raga要中,context recall 用来描述ground_truth中有多少比例的观点可以得到contexts的支持,计算过程如下:
- 由大模型将ground_truth分解成n个观点(statements)。
比如,可以由ground_truth【张伟是教研部的成员】生成观点列表【张伟是教研部的】。 - 由大模型判断每个观点能在检索到的参考资料(contexts)中找到依据,或者说context是否能支撑ground_truth的观点
比如,这个观点在第三数据 的contexts中能找到依据【张伟教研部工程师,他最近在负责课程开发】。 - 然后ground _truth观点列表中,能在contexts中找到依据的观点占比,作为context_recall分数。这里的得分为1=1/1。
Context precision
在Ragas中,context precision不仅衡量了contexts中有多少比例的context与ground_truth相关,还衡量了contexts中的排名情况。计算过程比较复杂:
- 按顺序读取contexts中的contexti是否相关,相关为1分,否则为0分。
比如上面第三行数据中,context1(牛顿发布了万有引力)是不相关的,context2相关。 - 对于每一个context,以该context及之前context的分数之和作为分子,context所处排位作为分母,计算precision分。
对于上面第三行数据,context1 precision分为0/1=0,context2分为1/2=0.5。 - 对每一个context的precision分求和,除以相关的context个数,得到context_precision。
对于上面第三行数据,context_precision = (0 + 0.5) / 1 = 0.5。
如何根据Ragas指标进行优化
做评测的最终目的不是为了拿到分数,而是根据这些分数确定优化的方向。你已经学习到了answer corrextnness、context recall 、context precision三个指标的概念与计算方法,当你观察到某几个指标 的分数较低时,应该制定相应的优化措施。
4.1 上下文是RAG的生命线
当用户提出一个问题时,大模型通过阅读理解你提价的**上下文 (context)**来给出回答。上下文决定了大模型能否给出准确、完整的答案。如果上下文缺失重要知识点,或存在错误、无关的内容,大模型就无法给出正确的结论。正如你在前面看到的问题一样:如果上下文(Context)里缺少了“张伟部门”的内容,大模型自然无法给出正确答案。
于是,为了不丢失有效知识,有人提出把全部可用资料**“一股脑全部灌给大模型”,让大模型来做甄别,结果产生了一个更复杂的问题:即使某个关键线索确实存在于你提供的大量资料中,但如果它被埋藏在海量的无关信息里,大模型也很可能**“视而不见”,这便是RAG系统中常说的“Lost in the Middle”现象。试想,关于“张伟部门”的有效信息,可能只是一句简单的“张伟,技术 部,工号XXXX”,如果这句话被夹杂在几百页的员工考勤记录、会议纪要甚至公司食堂菜单里,大模型很可能就会在这些冗余信息中迷失,导致最终无法给出正确的答案。它的**“注意力”被分散了,关键信息被“淹没”**了。
所以,RAG精度的瓶颈,往往不在于大模型本身是否足够“聪明”,而在于你提价给它的上下文(Context)的 “知识浓度” 。一个高质量的上下文,理应具有较高的知识浓度,意味着其中的相关信息密度高,噪音少、与问题直接关联。能让大模型准确地专注总是核心,得出正确结论。因此,你提供的上下文质量,直接决定了RAG系统的上限。
context recall
context recall 指标评测的是RAG应用在检索阶段的表现。如果该指标得分较低,你可以尝试从以下方面进行优化:
- 检查知识库

知识库是RAG应用的源头,如果知识库的内容**不够完备,**则会导致召回的参考信息不充分,从而影响context recall 。你可以对比知识库的内容与测试样本,观察知识库的内容是否可以支持每一条测试样本(这个过程你也可以借助大模型来完成)。如果你发现某些测试样本缺少相关知识,则需要对知识进行补充。 - 更换embedding模型
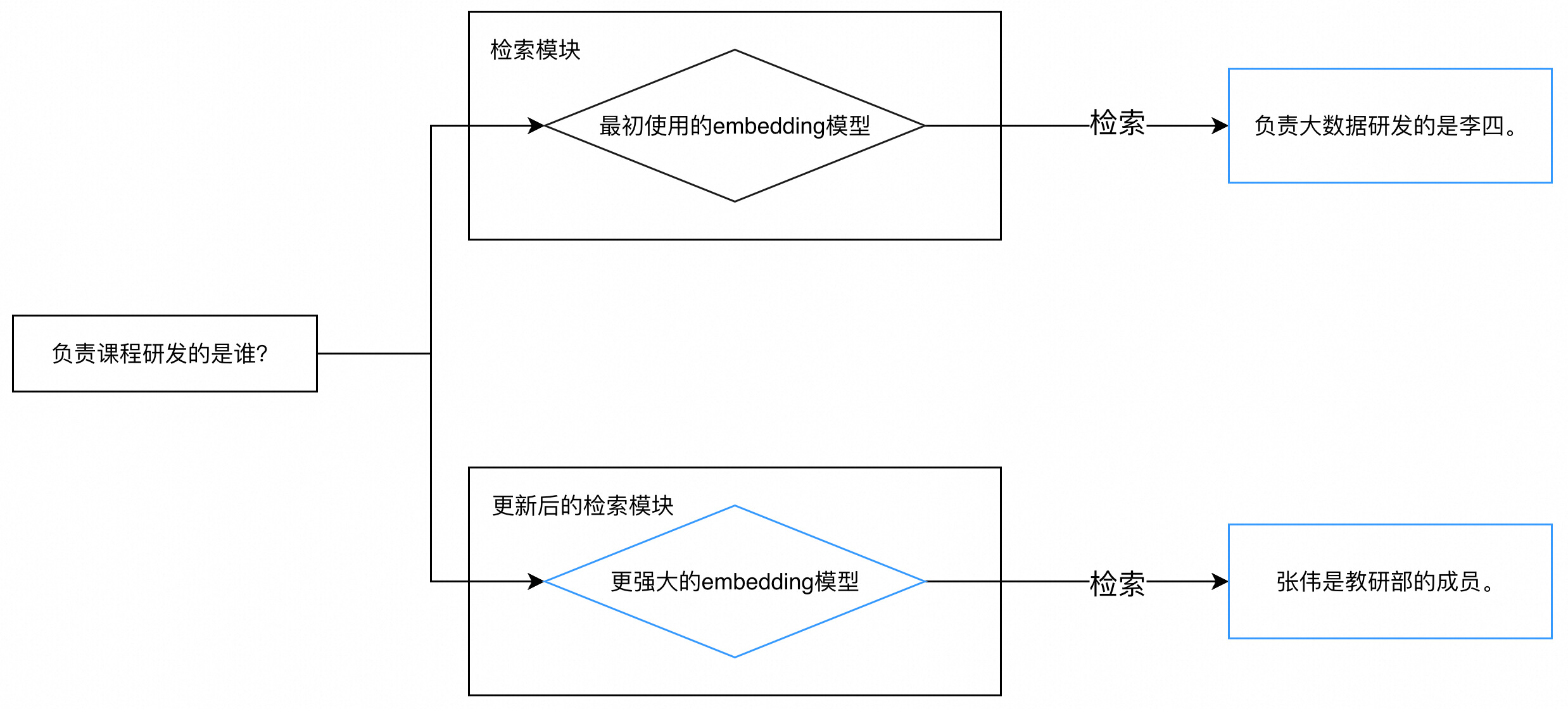
如果你的知识库内容已经很完备,则可以考虑更换embedding模型。好的embedding模型可以理解文本的深层次语义,如果两句深层次相关,那么即使“看上去”不相关,也可以获得较高的相似度分数。比如提问是“负责课程研发的是谁?”,知识库对应文本段是“张伟是教研部的成员”,尽管是重合的词汇较少,但优秀的embedding模型仍然可以为这两句话打出较高的相似度分数,从而将“张伟是教研部的成员”这一文本段召回。 - query 改写
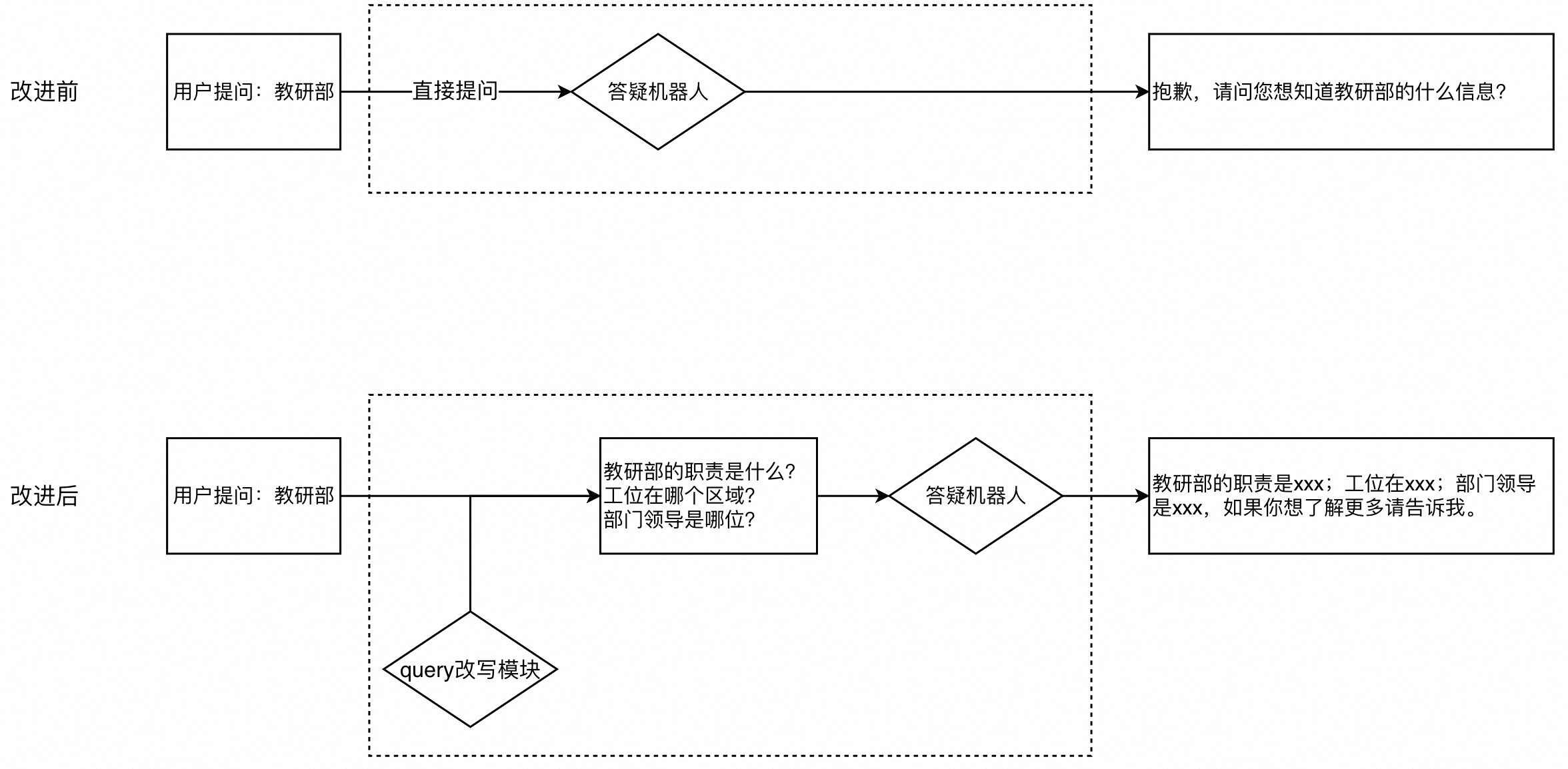
作为开发者,对用户的提问方式做过多要求是不现实的,因此你可能会得到这样缺少信息的问题:“教研部”、“请假”、“项目管理”。如果直接将这样的问题输入RAG应用中,大概率无法召回有效的文本段,你可以通过对员工常见总是的梳理来设计一个promp模板,使用大模型来改写query,提升召回的准确率。
context precision
与context recall 一样,context precision 指标评测的也是
RAG应用在检索阶段的表现,但是更注重相关文本段是否具有靠前的排名。如果该指标得分较低,你可以尝试context recall中的优化措施,并且可以尝试在检索阶段加入rerank(重排序),来提升相关文本段的排名。
answer correctness
answer correctness指标评测的是RAG系统整体的综合指标。如果該指标得分较低,而前两项分数较高,说明RAG系统在检索阶段表现良好,但是生成阶段出了问题。你可以尝试前边教程学到的方法,如优化prompt、调整大模型生成的超参数(如temperature)等,你也可以更换性能更加强劲的大模型,甚至对大模型进行微调(后边的教程会介绍)等方法来提升生成答案的准确度。
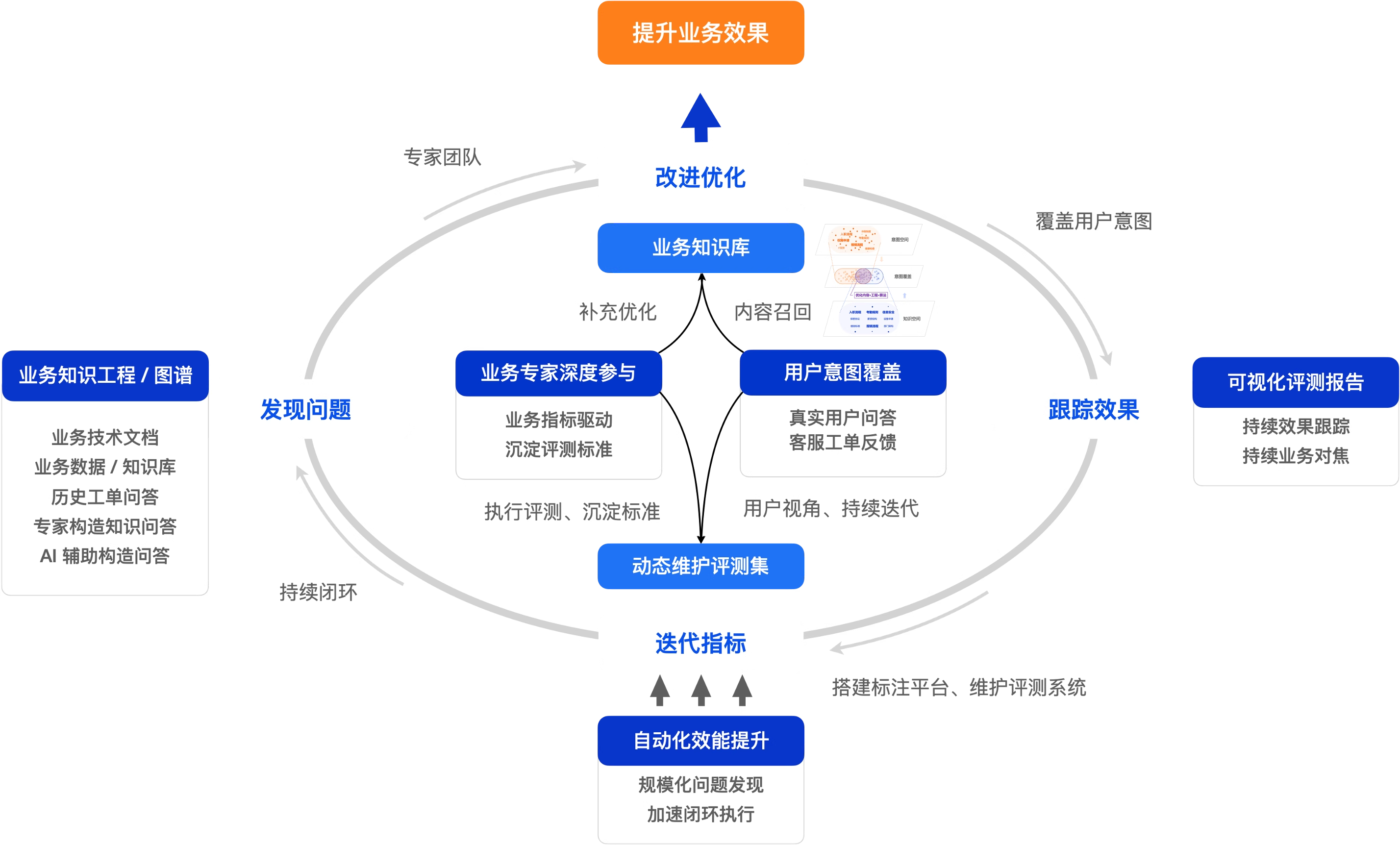
##打造卓越的评测运营体系
自动化评测虽然能有效提升评测效率,但是更大的挑战来自于构建高质量的评测样本以及如何凝练、积累深厚的领域知识。因此,你还需要结合自身业务特点,建立一套完善的评测运营体系。你可以从“找到最懂业务的人,用科学的方法,深度参与评测”入手:
- 让业务专家参与AI评测:评测的最终目的是提升业务效果,因此需要设定合理的业务目标,驱动业务专家来参与评测并沉淀评测方法。例如:让电商客服主管评测促销规则回复准确性,让物流专员评测运费时效回复 准确性,让售后专家验证退换货流程回复准确性,等等。
- 从最终用户视角出发构建评测体系:首先,基于真实用户对话样本评估答疑机器人是否有效解答了用户问题,从用户视角评判答案的正确性、简洁性与可操作性。其次,综合线上用户满意度统计与抽样答准率确立核心评测指标。最后,将评测体系细化为具体的算法指标,如意图识别准确率、问题改写准确率、知识召回准确率、知识库覆盖率及模型生成准确率等。
- 持续运营评测体系:你需要将评测答疑机器人的工作融入业务体系。你可以同时利用标注平台构建专家评测机制,并开发自动化评测工具,实现两者的协同运作。更重要的是,你需要在工作流程中建立“发现问题 -> 改进优化 -> 跟踪效果 -> 迭代指标”的闭环机制,让评测持续驱动业务系统改进,最终形成良性循环。
- 维护覆盖用户意图的高质量评测集:除了采集真实用户对话作为评测样本,你也可以收集用户反馈的错误案例(bad case),统计客服记录中的高频问题。你还可以通过知识图谱、对知识做语义化结构化处理,来建立知识库,让领域专家们根据知识库来构建标准评测集,或者通过 AI 辅助生成一些样本。你的目标是构建一个能覆盖用户意图的标准评测集。
当你引入业务领域专家帮助你解决了认知问题,同时持续运营评测标准体系确保评测指标的稳定性之后,你就可以考虑如何将这些知识沉淀到你的自动化评测中。通过自动化提升工作效率,你就可以更好地贯彻执行评测标准。例如,根据用户问答及时发现问题,修订和补充用户需要的内容,或者根据业务目标的变化来调整评测指标的计算口径等等。
拓展
更换Ragas的提示词模板
Ragas的许多评测指标是基于大模型来实现的。与LlamaIndex一样,Ragas的默认提示词模板是英文的,同时允许自定义修改。你可以将Ragas各指标的默认提示词翻译成英文,使得评测的结果更符合中文问答场景。
我们在ragas_prompt文件夹中提供了中文的提示词模板,你可以参考以下代码将中文提示词适配到Ragas的不同指标中。
Ragas会在提示词中向大模型提供一些示例,来帮助大模型理解应该如何进行判断、生成观点列表等操作,因此你也可以更改示例来适配到你的业务场景。
Ragas自带prompt模板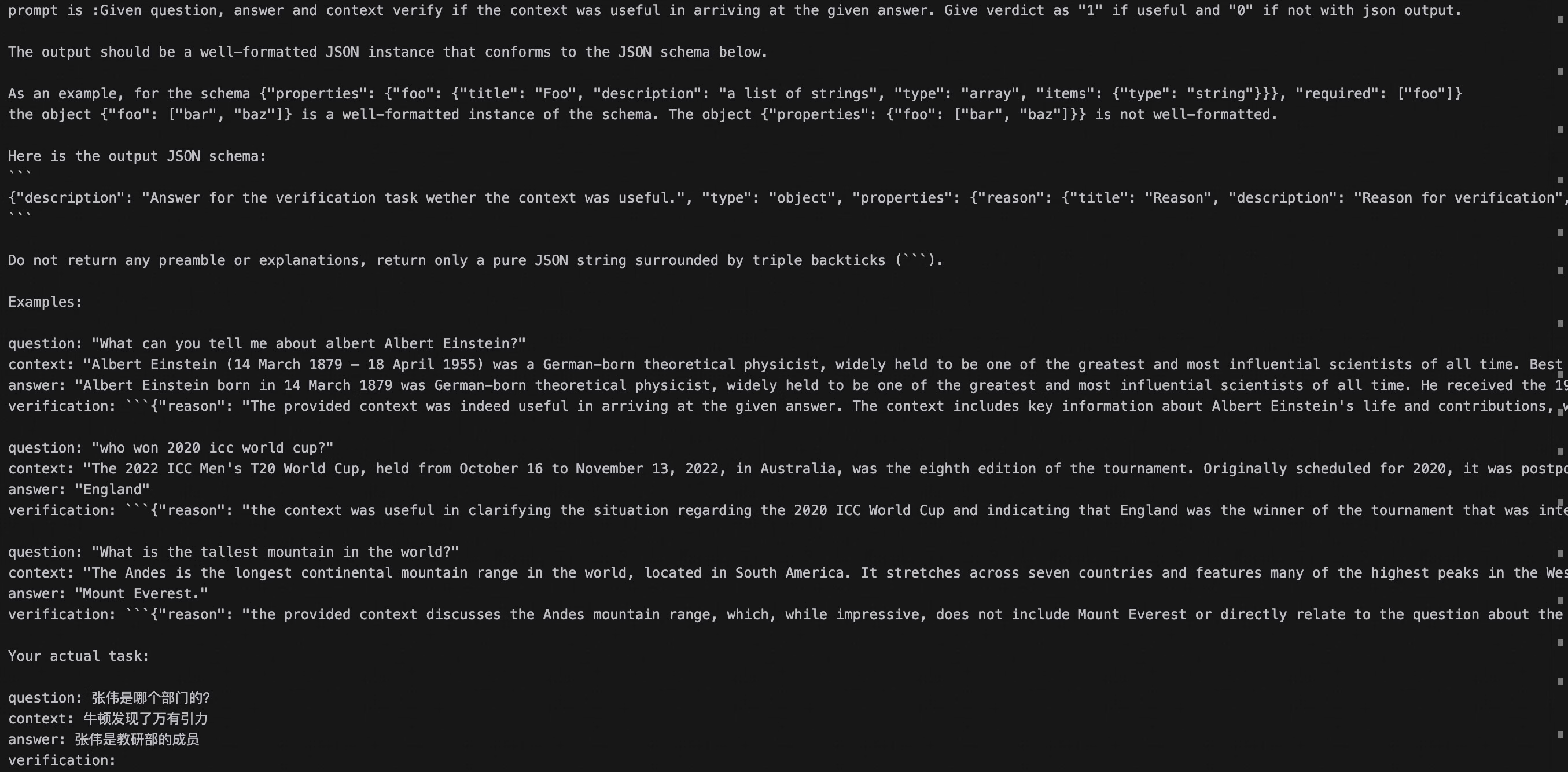
更改 prompt 模板之后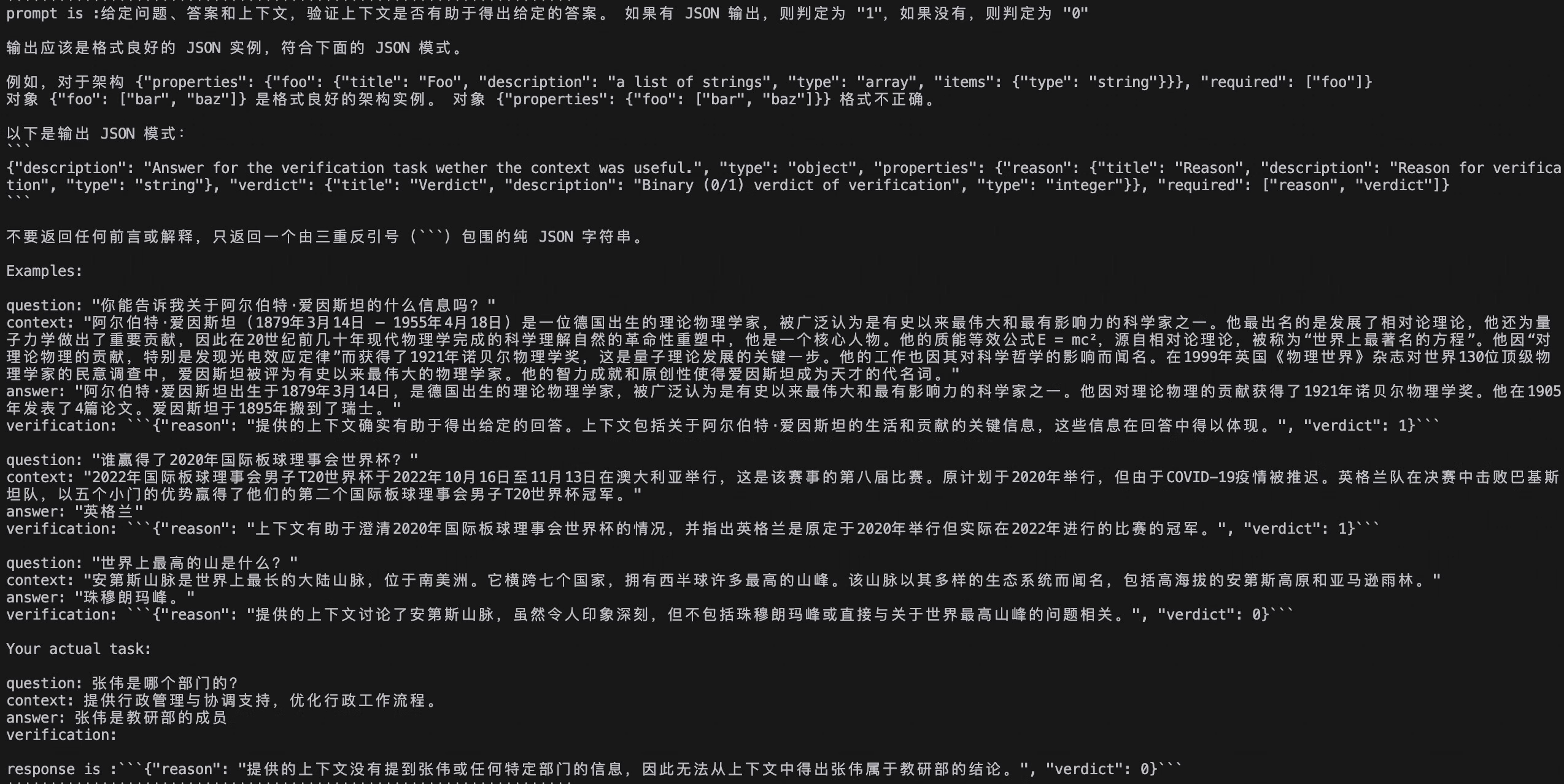
# 导入中文提示词模板
from ragas_prompt.chinese_prompt import ContextRecall,ContextPrecision,AnswerCorrectness# 进行各指标的自定义 prompt 设置
context_recall.context_recall_prompt.instruction = ContextRecall.context_recall_prompt["instruction"]
context_recall.context_recall_prompt.output_format_instruction = ContextRecall.context_recall_prompt["output_format_instruction"]
context_recall.context_recall_prompt.examples = ContextRecall.context_recall_prompt["examples"]context_precision.context_precision_prompt.instruction = ContextPrecision.context_precision_prompt["instruction"]
context_precision.context_precision_prompt.output_format_instruction = ContextPrecision.context_precision_prompt["output_format_instruction"]
context_precision.context_precision_prompt.examples = ContextPrecision.context_precision_prompt["examples"]answer_correctness.correctness_prompt.instruction = AnswerCorrectness.correctness_prompt["instruction"]
answer_correctness.correctness_prompt.output_format_instruction = AnswerCorrectness.correctness_prompt["output_format_instruction"]
answer_correctness.correctness_prompt.examples = AnswerCorrectness.correctness_prompt["examples"]data_samples = {'question': ['张伟是哪个部门的?','张伟是哪个部门的?','张伟是哪个部门的?'],'answer': ['根据提供的信息,没有提到张伟所在的部门。如果您能提供更多关于张伟的信息,我可能能够帮助您找到答案。','张伟是人事部门的','张伟是教研部的'],'ground_truth':['张伟是教研部的成员','张伟是教研部的成员','张伟是教研部的成员'],'contexts' : [['提供⾏政管理与协调⽀持,优化⾏政⼯作流程。 ', '绩效管理部 韩杉 李⻜ I902 041 ⼈⼒资源'],['李凯 教研部主任 ', '牛顿发现了万有引力'],['牛顿发现了万有引力', '张伟 教研部工程师,他最近在负责课程研发'],],
}dataset = Dataset.from_dict(data_samples)score = evaluate(dataset = dataset,metrics=[answer_correctness,context_recall,context_precision],llm=Tongyi(model_name="qwen-plus"),embeddings=DashScopeEmbeddings(model="text-embedding-v3"))score.to_pandas()

更多评价指标
除了RAG外,还有许多种大模型或者自然语言处理(NLP)的应用或任务,如Agent、NL2SQL、机器翻译、文本摘要等。Ragas提供了许多可以评测这些任务的指标。
| 评价指标 | 使用场景 | 指标含义 |
|---|---|---|
| ToolCallAccuracy | Agent | 评估 LLM 在识别和调用完成特定任务所需工具方面的表现,该参数由参考工具调用与大模型做出的工具调用比较得到,取值范围是0-1。 |
| DataCompyScore | NL2SQL | 评估大模型生成的SQL语句在数据库检索后得到的结果与正确结果的差异性,取值为0-1。 |
| LLMSQLEquivalence | NL2SQL | 相比于上者,无需真正在数据库中进行检索,只评估大模型生成的SQL语句与正确的SQL语句的区别,取值为0-1。 |
| BleuScore | 通用 | 基于 n-gram 评估响应与正确答案之间的相似性。最初被设计用于评估机器翻译系统,评测时无需使用大模型,取值为0-1。在2.7教程中,你会学习到如何对大模型进行微调,BleuScore就可以用来评测微调带来的收益。 |