ETL详解:从核心流程到典型应用场景
目录
一、ETL的核心流程
1. Extract(抽取)
2. Transform(转换)
3. Load(加载)
二、ETL的典型应用场景
三、ETL的价值:为什么企业愿意投入资源?
1.提高数据质量
2.提升效率
3.支持复杂分析
4.降低长期成本
5.增强数据一致性
总结
你是否曾遇到过这样的情况:财务同事抱怨报表上的数字和销售团队提供的对不上;分析师为了出一份月报,花费了大把时间手动整合十几个Excel文件;公司上了新的CRM系统,却发现历史数据一团乱麻,根本无法迁移。
听着是不是很熟?这些让人头疼的问题,背后往往指向同一个根源:数据分散、标准不一、质量堪忧。
而解决这些问题的关键核心,就是一个你可能听过但未必深入了解的流程——ETL。
用过来人的经验告诉你,理解ETL,就是你从被动处理数据问题,转向主动掌控数据价值的开始。
下面我将从ETL的流程、应用场景入手,告诉你为什么企业愿意为它投入资源。
一、ETL的核心流程
在进入具体应用前,我们先拆解 ETL 的核心运作逻辑。ETL是三个英文单词的缩写:Extract(抽取)、Transform(转换)、Load(加载)。这三步构成了一个完整的流程,目的是把数据从来源系统移动到目标系统(比如数据仓库或数据库),并让数据变得规范、干净、易于使用。
1. Extract(抽取)
第一步是从各个地方把数据提取出来。这些数据可能来自不同的源头,比如业务数据库、第三方API、Excel表格,甚至是云存储服务。
在这一步如果只是靠Excel表格收集这些庞大的数据,那必然会出现数据口径不统一、数据接入不全等情况,因此我们需要一个能完美解决这些问题的工具,这里我推荐用一款数据集成工具,比如FineDataLink,它除了能解决前面提到的问题,还能对接收到的数据进行清洗、过滤等行动;此外还可以对数据进行权限管理,能够保障数据的安全性。
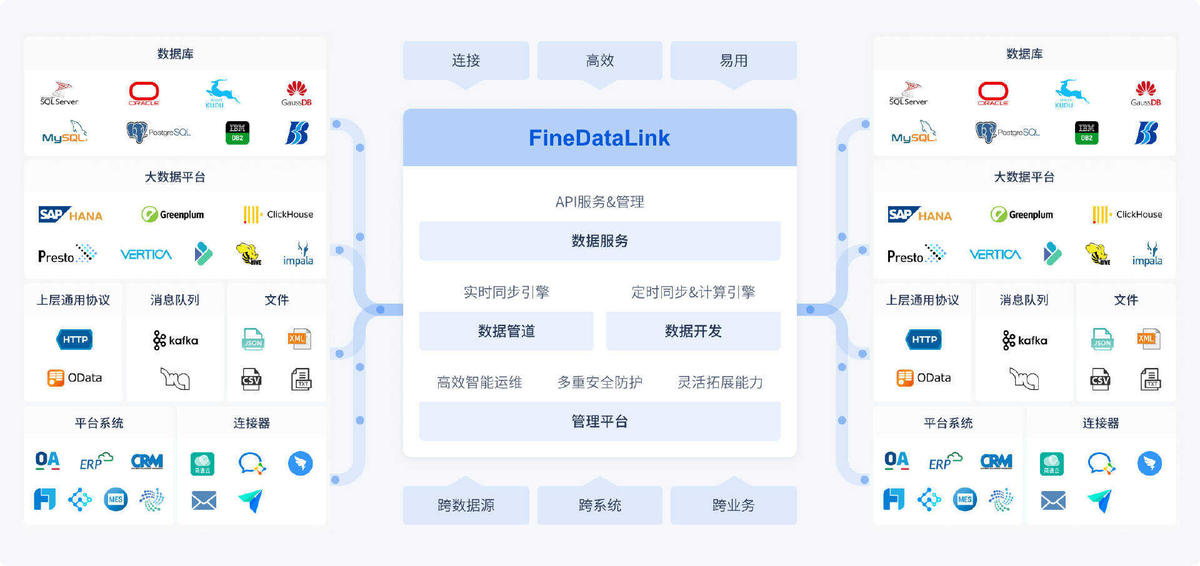
听着是不是很熟?现实中,数据往往分散在不同系统中,格式也不一样。抽取阶段的关键是尽可能完整地拿到原始数据,不要丢失任何可能有用的信息。但注意,此时的数据还是原始状态,可能存在重复、错误或格式不一致的问题。
2. Transform(转换)
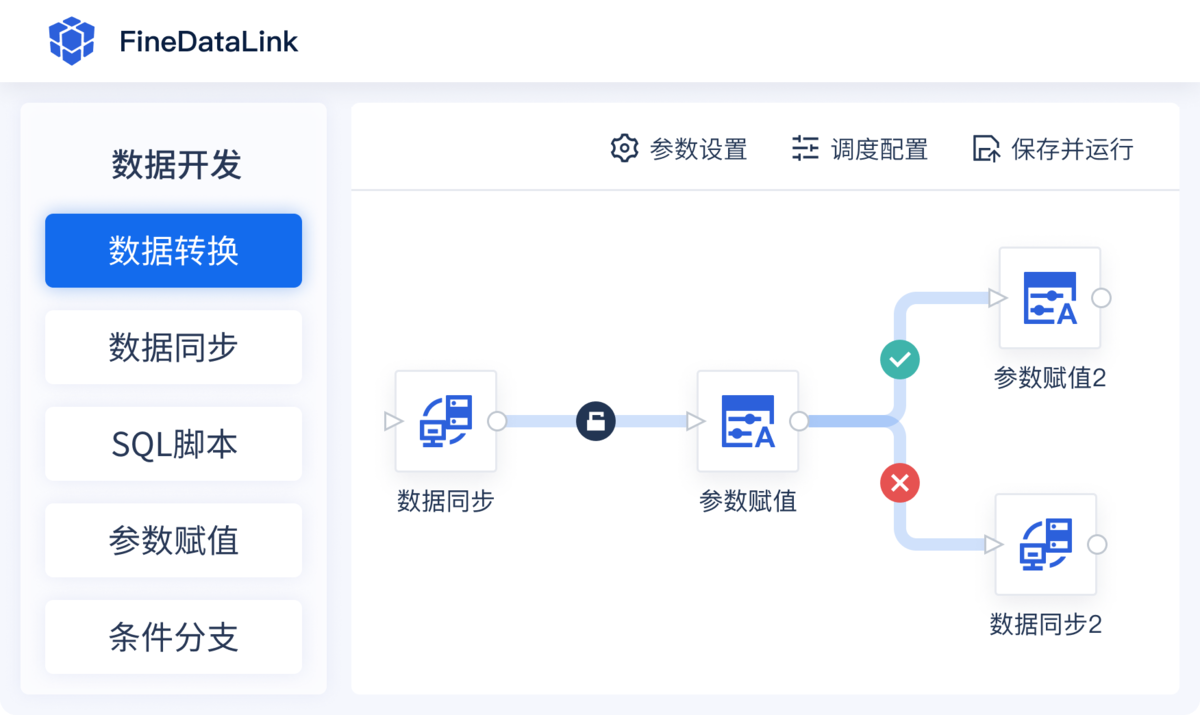
这是ETL中最核心的一步。转换的目的是对原始数据进行清洗、加工和整理,使其符合目标系统的要求。简单来说,就是让数据变得规范、统一、有用。
转换阶段常见操作包括:
- 数据清洗:处理缺失值、删除重复记录、纠正错误数据。
- 格式标准化:比如将日期统一为“YYYY-MM-DD”格式,或者将货币单位转换为统一标准。
- 数据计算:生成新字段,例如通过单价和数量计算总金额。
- 数据聚合:对数据进行分组汇总,比如按月份统计销售额。
我一直强调,转换阶段是体现数据质量的关键。
如果转换没做好,后续的数据分析结果可能毫无意义,你懂我意思吗?这是数据领域的经典原则。
3. Load(加载)
最后一步是将处理好的数据加载到目标系统中,通常是数据仓库、数据湖或业务数据库。
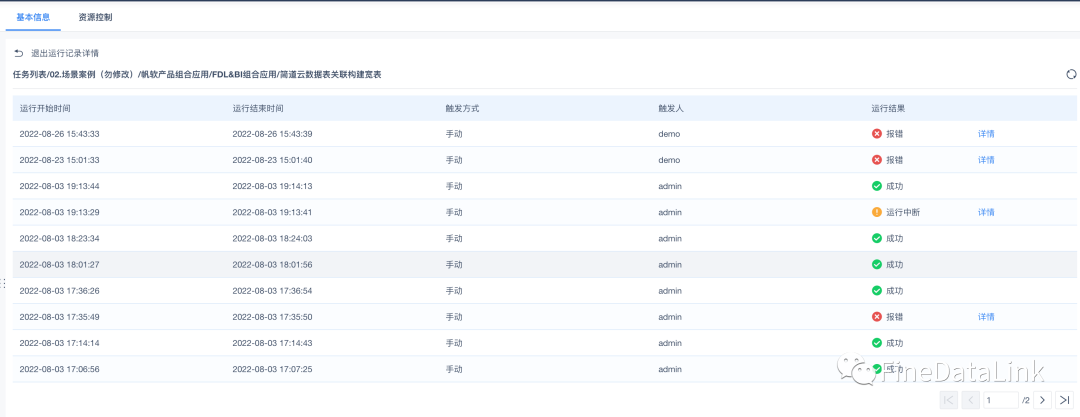
加载方式有两种:全量加载(全部数据一次性导入)和增量加载(只导入新增或变化的数据)。
增量加载是比较常见的,因为它效率更高,尤其适用于数据量大的场景,说白了,每次只处理变化的部分,节省时间和计算资源。
这三步形成了一个闭环流程,每隔一定周期(比如每天或每小时),ETL流程就会自动运行一次,确保目标系统中的数据持续更新。
二、ETL的典型应用场景
了解了 ETL 的核心运作逻辑后,我们再看它的实际价值落地。
ETL在现实中应用极广,以下是一些常见场景,或许你正在间接接触它们:
1.业务报表与数据分析
企业需要定期生成销售报表、财务报表或运营仪表盘。ETL负责将分散在多个业务系统(如CRM、ERP)的数据整合到一起,经过清洗后加载到数据仓库,供分析师或管理层使用。
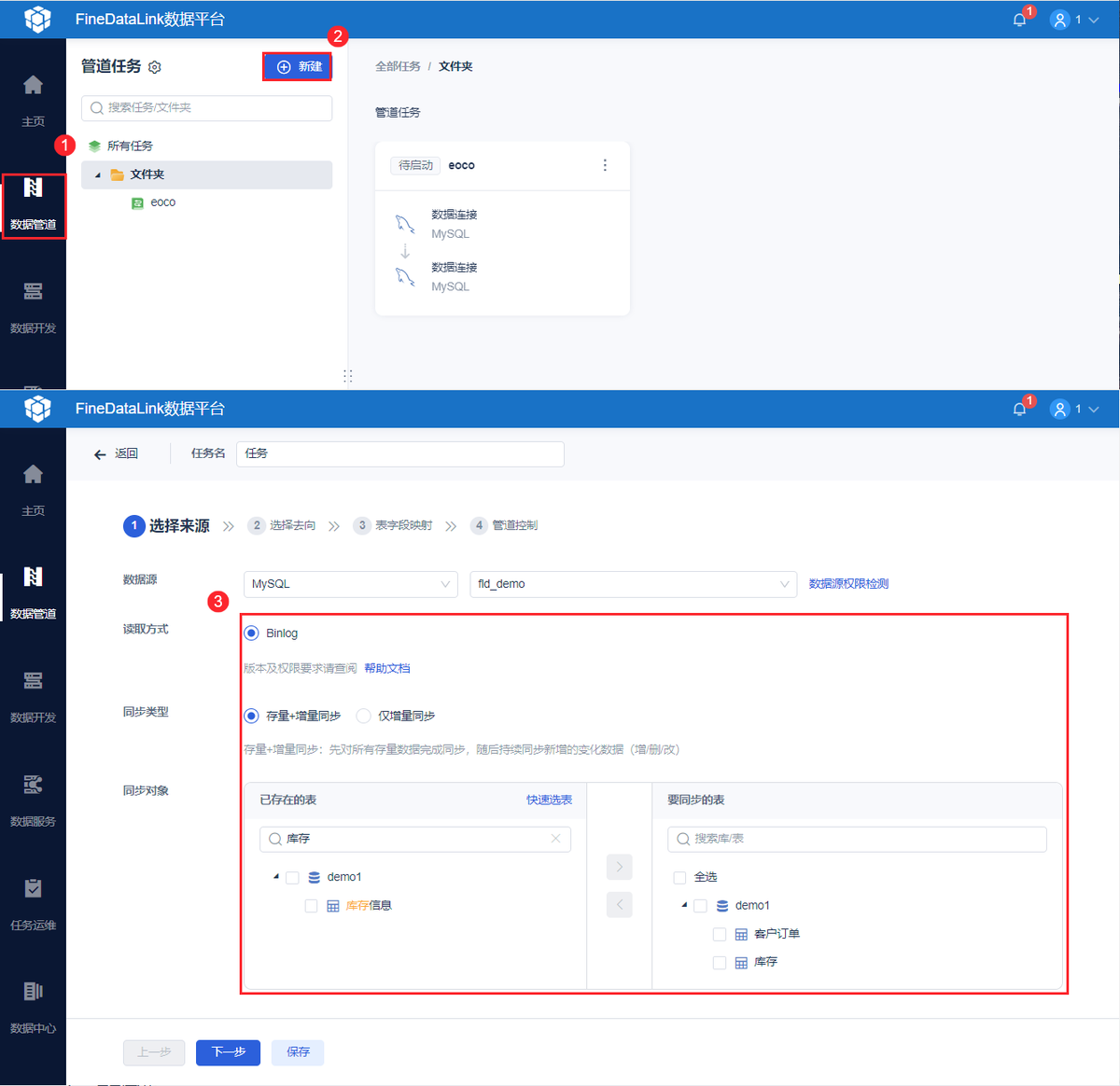
举个例子:
一家零售公司每周需要生成销售报表,那么ETL流程会每日夜间自动运行:首先从线上商城数据库(MySQL)和线下门店系统(SQL Server)抽取原始销售记录;随后进行转换,比如统一商品编码、将销售额转换为标准货币单位、并按门店和日期进行聚合;最后将处理好的数据加载到云端数据仓库(如Snowflake)中。第二天,分析师就可以直接使用这些整洁的数据在Tableau上制作可视化报表,就不需要再手动整理数据了。
2.数据迁移与系统集成
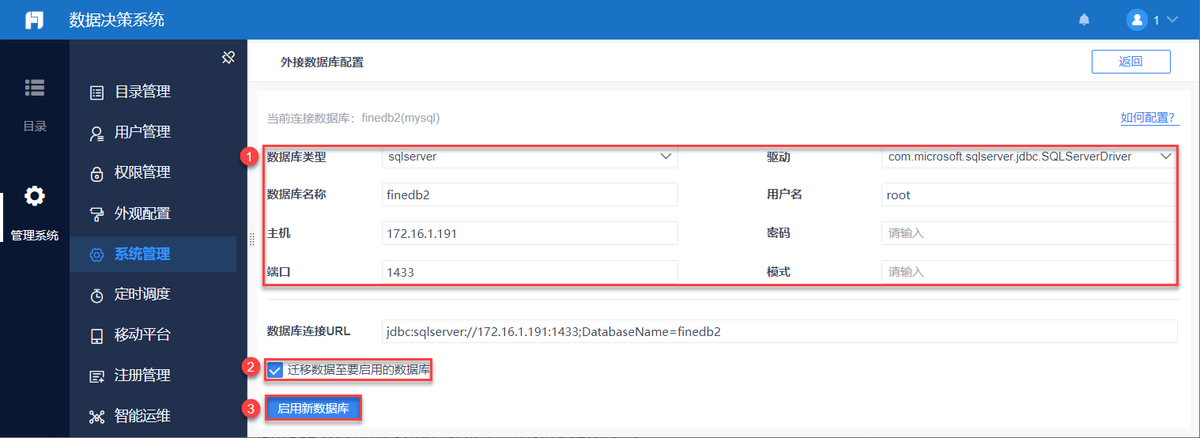
当公司更换系统(例如从旧数据库迁移到云平台)时,ETL可以帮助安全、准确地将历史数据转移至新环境。
3.数据仓库与商业智能(BI)
数据仓库是专门为分析而设计的存储系统。ETL是构建数据仓库的基础,它定期从业务数据库抽数、转换并加载到仓库中,最终支持BI工具进行可视化分析。
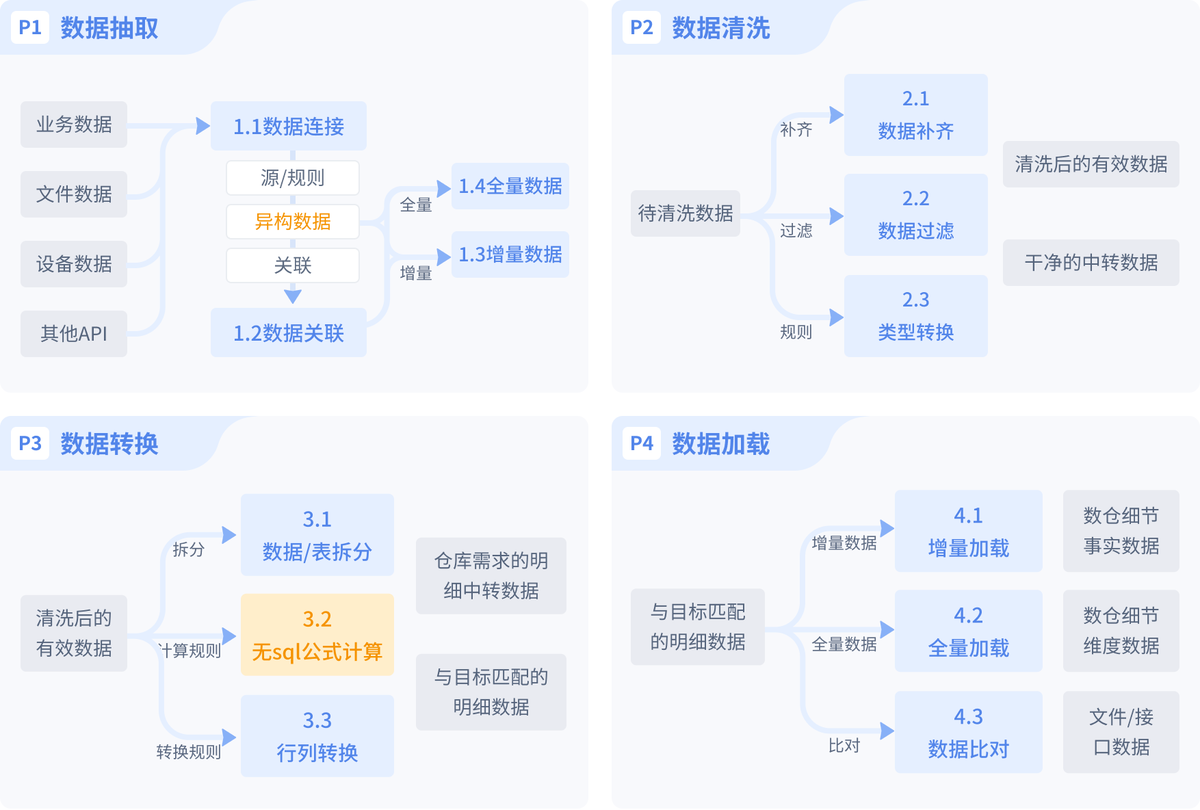
比如,一家电商公司为分析用户行为构建了数据仓库。ETL任务定时启动:从业务订单库、用户日志文件及APP埋点中抽取数据;经过复杂的转换,如清洗无效点击、匹配用户ID与订单ID、计算用户购买转化率等;之后加载至公司专用的Amazon Redshift数据仓库。此后,业务人员便可通过BI工具对这些模型化的数据进行自助式的多维分析和探索。
4.合规与数据审计
在一些高度监管的行业(如金融、医疗),ETL可用于整合数据以满足合规要求,例如生成标准化审计日志。
5.实时数据处理
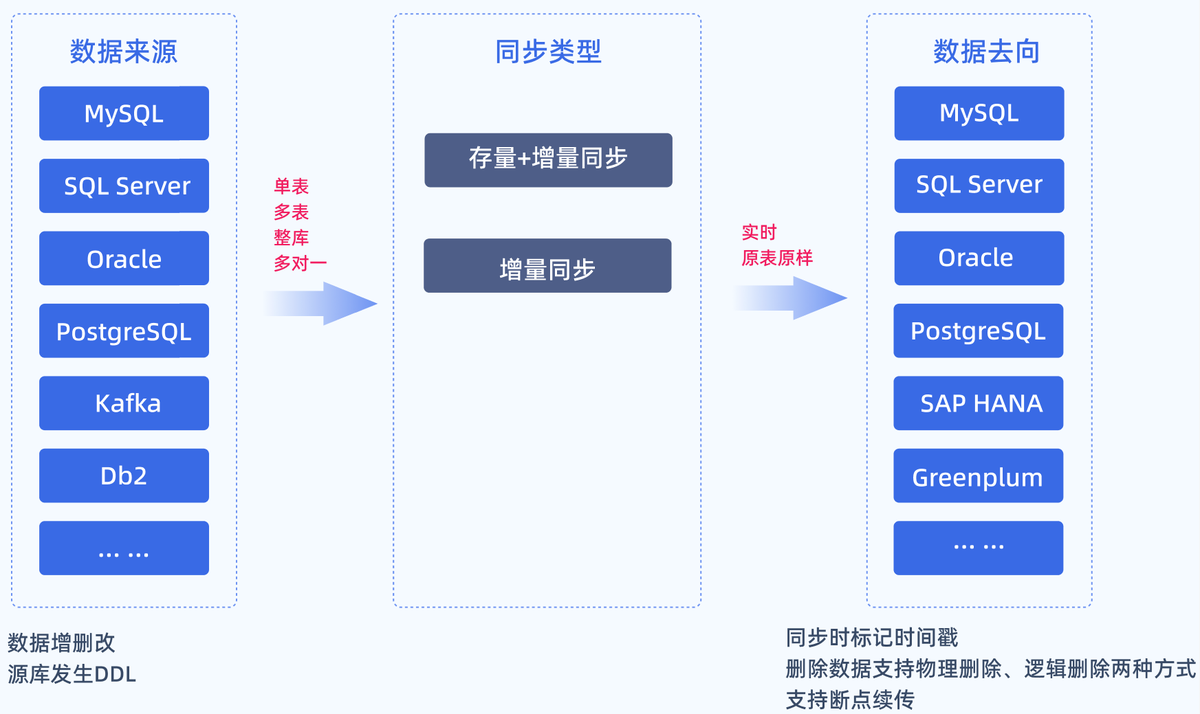
传统ETL是定时批处理,但现在也有更实时的模式(俗称ELT或流式ETL),用于监控用户行为、实时推荐等场景。
三、ETL的价值:为什么企业愿意投入资源?
从上述多样的应用场景中不难看出,ETL看似是一个技术流程,但实际上它带来了实实在在的业务价值。主要体现在以下几点:
1.提高数据质量
通过清洗和转换,ETL消除了原始数据中的错误和不一致,使数据分析结果更可靠。
决策依赖高质量数据,否则就是只是靠感觉瞎猜。
2.提升效率
自动化ETL流程减少了手动处理数据的时间成本。以前可能需要人工导出Excel、合并表格,现在全部交给系统调度完成。
比如:
财务部门以前每月初需要3名分析师花费整整4天手动操作:从7个不同的业务系统导出Excel报表,通过Vlookup函数匹配关键信息,复制粘贴整合成一张总表。
而现在,部署好的ETL任务会在每月1号零点自动启动,无需人工干预,3小时内就能完成所有数据的抽取、关联和整合,并直接生成标准报表;分析师就能从重复劳动中解脱,将精力投入到更具价值的财务分析工作中。
3.支持复杂分析
数据仓库中的结构化数据更适合做多维度分析。ETL把数据变成“分析友好型”,让分析师能更专注于业务问题而不是数据准备。比如,市场团队想分析“不同渠道的广告投放如何影响不同地区客户的终身价值”,而这个分析涉及用户、订单、渠道投放和客服多个维度的数据。
ETL流程会提前将这些数据按主题建模,并整合到数据仓库的维度表中,这样分析师只需要通过点击关键词就能查看数据,不用在原始日志中对数据一个个查询了。
4.降低长期成本
虽然搭建ETL需要初始投入,但它减少了因数据错误导致的业务损失,也避免了重复手动工作的浪费。
5.增强数据一致性
不同来源的数据经过ETL后,按照统一标准整合在一起,避免了部门间数据口径不一致的问题。

说白了,ETL是企业数据治理的基石。没有它,数据很可能是一团乱麻,分析起来困难重重。
总结
用过来人的经验告诉你,ETL看似是技术流程,本质就是用标准化方式解决数据混乱问题的思维模式。
我一直强调,数据处理的核心不是工具多高级,而是对业务的理解和对细节的把握。
在你看完这篇内容,或许你能真正理解ETL为什么是数据工作的基石,学会使用ETL,就能让数据真正为你所用。