STL源码探秘(一):深入剖析List的迭代器设计与实现
目录
- 前言
- 一.什么是STL
- 二.List的使用
- 2.1 基于list迭代器的使用
- 2.2 list本身的使用
- 2.2.1 算法类别
- 2.2.1 基础行为类别
- 三.剖析List的底层设计
- 3.1 探索STL源码
- 3.1.1 如何看源码
- 3.1.2 根据源代码梳理结构
- 3.2 List的基本结构
- 3.2.1 迭代器失效问题
- 3.3 List中的迭代器设计
- 3.3.1 普通迭代器和const迭代器
- 3.3.2 操作符operator->的重载
- 3.3.3 迭代器的分类
- 3.3.4 范围for和initializer_list的底层
- 3.4 C++11的新接口
- 3.5 C++11的新语法
- 3.5.1 左值和右值
- 3.5.2 右值引用和引用折叠
- 3.5.3 移动构造和移动赋值
- 3.5.4 可变参数模板
- 3.6 C++11版本的push_back和emplace_back的实现
- 3.6.1 push_back
- 3.6.2 emplace_back
前言
本章内容默认是含有C++类和对象、模板的知识来讲述的(对于这一块不太了解的,可先自行了解),对于C++11中的语法会作为重点知识来讲解。
一.什么是STL
STL(standard template library-标准模板库):属于C++标准库的重要组成部分,包含了算法与基本数据结构的标准库,有了它的出现使得在更多的场景下可以进行不断地复用
STL六大组件:算法、迭代器、仿函数、空间配置器、容器、配接器
二.List的使用
2.1 基于list迭代器的使用
迭代器并没有一个明确的定义,《STL源码剖析》中讲到:迭代器是将算法与容器相连的一撮粘合剂。模板的使用是C++的一大特色,在实际场景中我们会定义各种各样类型的容器,如何对这些容器进行统一的遍历、设置统一的接口就是迭代器要做到的,迭代器其实就是“像指针一样的东西”。
STL提供的容器遍历的方式:
#include<list>int main()
{list<int> li = { 1,2,3,4,5,6,7,8,9 };auto it = li.begin();while (it != li.end()){cout << (*it) << " ";++it;}cout << endl;for (auto e : li){cout << e << " ";}return 0;
}

对于基本的容器都会含有两个位置的迭代器,begin返回开始的位置,end返回最后一个元素的下一个位置,也就说迭代器的范围:[begin,end),而迭代器是像指针一样的东西,++返回的当前位置的下一个位置,*返回的是访问的数据;范围for是C++11的新语法,它是从python那产生的灵感,使用起来非常的方便
<1.insert:

用途:
(1):指定迭代器之前位置插入元素
(2):指定迭代器之前位置插入n个元素
(3):指定迭代器之前位置插入一段迭代器区间
样例:
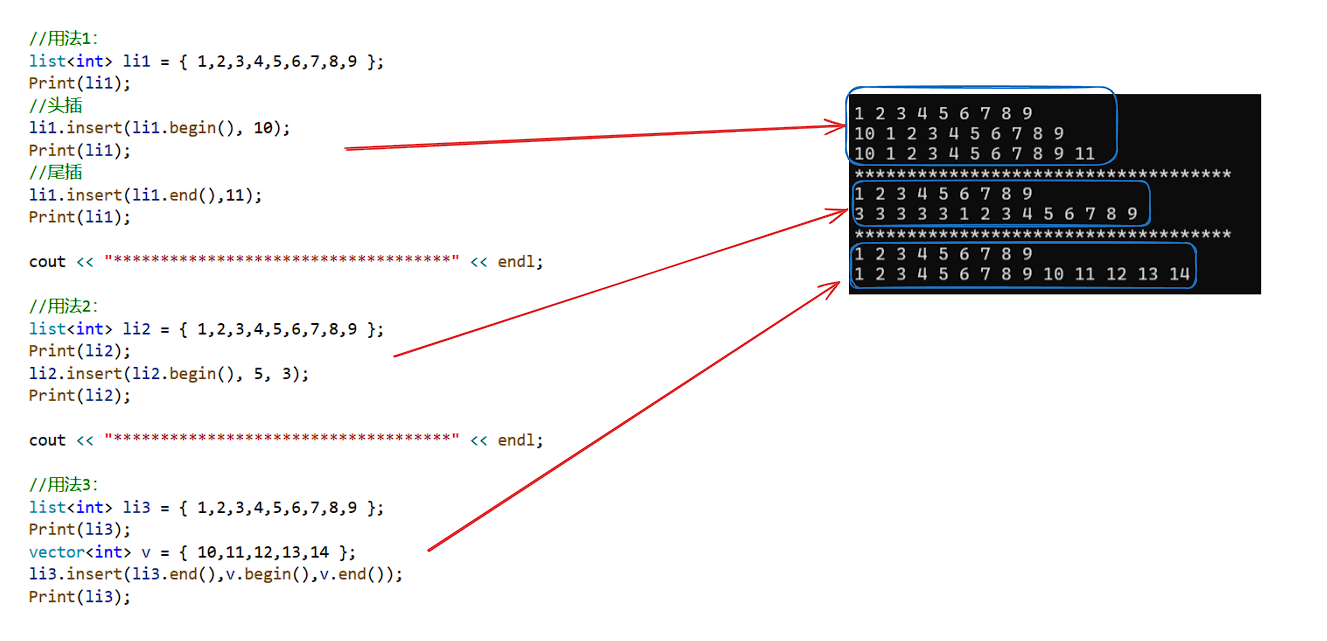
void Print(list<int>& li)
{for (auto e : li){cout << e << " ";}cout << endl;
}int main()
{//用法1:list<int> li1 = { 1,2,3,4,5,6,7,8,9 };Print(li1);//头插li1.insert(li1.begin(), 10);Print(li1);//尾插li1.insert(li1.end(),11);Print(li1);cout << "************************************" << endl;//用法2:list<int> li2 = { 1,2,3,4,5,6,7,8,9 };Print(li2);li2.insert(li2.begin(), 5, 3);Print(li2);cout << "************************************" << endl;//用法3:list<int> li3 = { 1,2,3,4,5,6,7,8,9 };Print(li3);vector<int> v = { 10,11,12,13,14 }; //类似C语言的顺序表li3.insert(li3.end(),v.begin(),v.end());Print(li3);return 0;
}
insert重载第三个版本的背后设计理念: 算法和操作不依赖于特定的容器类型,而是依赖迭代器这一抽象的概念。只要迭代器范围有效,vector、string、array都可以被使用。
<2.erase:
用途:
(1):删除指定迭代器
(2):删除指定迭代器区间
样例:
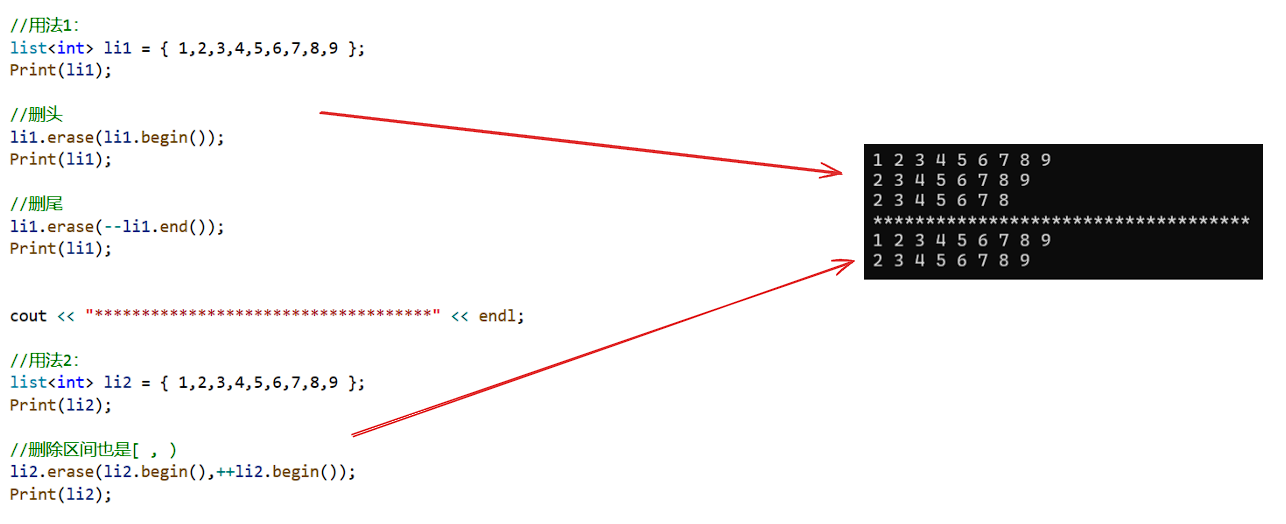
对于list的erase删除指定迭代器其实不好用,因为list的迭代器只是一个双向迭代器(只能进行++,–)
void Print(list<int>& li)
{for (auto e : li){cout << e << " ";}cout << endl;
}int main()
{//用法1:list<int> li1 = { 1,2,3,4,5,6,7,8,9 };Print(li1);//删头li1.erase(li1.begin());Print(li1);//删尾li1.erase(--li1.end());Print(li1);cout << "************************************" << endl;//用法2:list<int> li2 = { 1,2,3,4,5,6,7,8,9 };Print(li2);//删除区间也是[ , )li2.erase(li2.begin(),++li2.begin());Print(li2);return 0;
}
2.2 list本身的使用
2.2.1 算法类别
| 类方法 | 用途 |
|---|---|
| splice | 剪切 |
| remove | 删除 |
| merge | 合并两个有序链表 |
| unique | 去重 |
样例:

#include<algorithm>
#include<list>int main()
{//将其他链表的数据剪切过来list<int> li1 = { 1,2,3,4,5};Print(li1);list<int> li2 = { 6,7,8,9 };li1.splice(li1.end(), li2, li2.begin(), li2.end());Print(li1);cout << "************************************" << endl;//剪切自己的数据list<int> li3 = { 1,2,3,4,5 };Print(li3);int x;cin >> x;auto it = find(li3.begin(), li3.end(), x); //算法库提供的find,找到返回对应迭代器,未找到返回end()if (it != li3.end()){li3.splice(li3.begin(), li3, it);Print(li3);}else{cout << "未找到" << endl;}return 0;
}

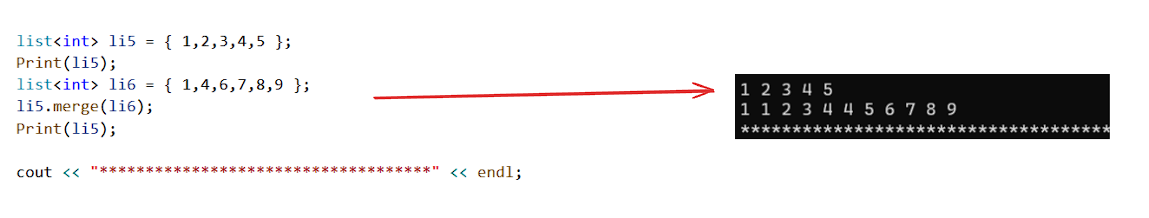

更多细节参考文档
2.2.1 基础行为类别
基于insert和erase的实现,头尾的插入删除在底层直接对其进行复用即可
| 类方法 | 时间复杂度 |
|---|---|
| 头插 | O(1) |
| 头删 | O(1) |
| 尾插 | O(n) |
| 尾删 | O(n) |
三.剖析List的底层设计
3.1 探索STL源码
3.1.1 如何看源码
- 版本的选择:本篇选择的是1997年的stl30,对于新版本的源码,会融入更多C++的新语法特性,学习成本过高
- 看源码的主要步骤: a.先抓类的结构以及核心成员 b.再看类的构造 c.熟悉完以后如果对于某个类方法不是很明白再进行深入研究
注意:看源代码切记不要一行一行地看,那样效率很低,而且过于冗余,因为有些模板、结构的设计,需要遇到实际问题才能想明白它真正的设计意图
3.1.2 根据源代码梳理结构
核心代码:
//list结点的类
template <class T>
struct __list_node {typedef void* void_pointer;void_pointer next;void_pointer prev;T data;
};//list迭代器的类
template<class T, class Ref, class Ptr>
struct __list_iterator {typedef __list_iterator<T, T&, T*> iterator;typedef __list_iterator<T, const T&, const T*> const_iterator;typedef __list_iterator<T, Ref, Ptr> self;typedef bidirectional_iterator_tag iterator_category;typedef T value_type;typedef Ptr pointer;typedef Ref reference;typedef __list_node<T>* link_type;typedef size_t size_type;typedef ptrdiff_t difference_type;link_type node;__list_iterator(link_type x) : node(x) {}__list_iterator() {}__list_iterator(const iterator& x) : node(x.node) {}bool operator==(const self& x) const { return node == x.node; }bool operator!=(const self& x) const { return node != x.node; }reference operator*() const { return (*node).data; }#ifndef __SGI_STL_NO_ARROW_OPERATORpointer operator->() const { return &(operator*()); }
#endif /* __SGI_STL_NO_ARROW_OPERATOR */self& operator++() { node = (link_type)((*node).next);return *this;}self operator++(int) { self tmp = *this;++*this;return tmp;}self& operator--() { node = (link_type)((*node).prev);return *this;}self operator--(int) { self tmp = *this;--*this;return tmp;}
};//list的类
template <class T, class Alloc = alloc>
class list {
protected:typedef void* void_pointer;typedef __list_node<T> list_node;typedef simple_alloc<list_node, Alloc> list_node_allocator;
public: typedef T value_type;typedef value_type* pointer;typedef const value_type* const_pointer;typedef value_type& reference;typedef const value_type& const_reference;typedef list_node* link_type;typedef size_t size_type;typedef ptrdiff_t difference_type;public:typedef __list_iterator<T, T&, T*> iterator;typedef __list_iterator<T, const T&, const T*> const_iterator;protected:link_type node;public:list() { empty_initialize(); }iterator begin() { return (link_type)((*node).next); }const_iterator begin() const { return (link_type)((*node).next); }iterator end() { return node; }const_iterator end() const { return node; }reverse_iterator rbegin() { return reverse_iterator(end()); }const_reverse_iterator rbegin() const { return const_reverse_iterator(end()); }iterator insert(iterator position) { return insert(position, T()); }
#ifdef __STL_MEMBER_TEMPLATEStemplate <class InputIterator>void insert(iterator position, InputIterator first, InputIterator last);
#else /* __STL_MEMBER_TEMPLATES */void insert(iterator position, const T* first, const T* last);void insert(iterator position,const_iterator first, const_iterator last);
#endif /* __STL_MEMBER_TEMPLATES */void insert(iterator pos, size_type n, const T& x);void insert(iterator pos, int n, const T& x) {insert(pos, (size_type)n, x);}void insert(iterator pos, long n, const T& x) {insert(pos, (size_type)n, x);}void push_front(const T& x) { insert(begin(), x); }void push_back(const T& x) { insert(end(), x); }iterator erase(iterator position) {link_type next_node = link_type(position.node->next);link_type prev_node = link_type(position.node->prev);prev_node->next = next_node;next_node->prev = prev_node;destroy_node(position.node);return iterator(next_node);}iterator erase(iterator first, iterator last);void resize(size_type new_size, const T& x);void resize(size_type new_size) { resize(new_size, T()); }void clear();void pop_front() { erase(begin()); }void pop_back() { iterator tmp = end();erase(--tmp);}list(size_type n, const T& value) { fill_initialize(n, value); }list(int n, const T& value) { fill_initialize(n, value); }list(long n, const T& value) { fill_initialize(n, value); }explicit list(size_type n) { fill_initialize(n, T()); }list(const list<T, Alloc>& x) {range_initialize(x.begin(), x.end());}~list() {clear();put_node(node);}
public:void splice(iterator position, list& x) {if (!x.empty()) transfer(position, x.begin(), x.end());}void splice(iterator position, list&, iterator i) {iterator j = i;++j;if (position == i || position == j) return;transfer(position, i, j);}void splice(iterator position, list&, iterator first, iterator last) {if (first != last) transfer(position, first, last);}};
<1.整体结构:底层将list封装成了三个类(链表结点,链表迭代器,链表);目前我们也可以看到一些端倪:STL中将链表结点和迭代器设置成struct,就说明这两个类中不需要私有成员的设立,对于源码很多类型喜欢typedef,不知道就去对应地方找就行
<2.当前疑点:迭代器的类设置了三个模板参数,什么原因?

❤️.拓展知识(这部分本篇不讲,只是提一下):官方文档中,设置了第二个模板参数Alloc,它是用来调用内存池的,简单来说,就是实际工程中新结点并不是直接通过堆上开辟空间,而是在达到一定空间容量之内选择在栈上获取新的结点,主要原因就是效率会更快!
为什么list的迭代器要特意封装成一个类: 首先,得先明白一个结论,迭代器它需要达到指针的行为,指针的核心行为主要有三个:operator*,operator++,operator->,设想一下,如果我们不封装为一个类,单纯用结点指针来模拟迭代器:++可以到下一个结点吗(链表的存储的结点地址可是随机的,并没有直接的数值大小关系), *可以访问到结点的数据吗(结点指针属于一个结构体指针,它访问都没有其行为),基于以上的原因,我们才需要重载这些操作符,将迭代器封装成一个类,模拟达到想要的效果
3.2 List的基本结构
实现list结构的框架:
template<class T>struct list_node{T _data;list_node* _next;list_node* _prev;list_node(const T& data = T()):_data(data), _next(nullptr), _prev(nullptr){}};template<class T>struct list_iterator{typedef list_node<T> node;typedef list_iterator<T> Self;node* _node;list_iterator(node* node):_node(node){}T& operator*(){return _node->_data;}Self& operator++(){_node = _node->_next;return *this;}Self operator++(int){node* tmp(_node);++_node;return tmp;}Self& operator--(){_node = _node->_prev;return *this;}Self operator--(int){node* tmp(_node);--_node;return tmp;}bool operator!=(const Self& s){return _node != s._node;}bool operator==(const Self& s){return _node == s._node;}};template<class T>class list{typedef list_node<T> node;public:typedef list_iterator<T> iterator;iterator begin(){//return iterator(_head->_next);//走隐式类型转换return _head->_next;}//返回有效数据的下一个位置iterator end(){return iterator(_head);return _head;}list(){_head = new node;_head->_next = _head;_head->_prev = _head;}void push_back(const T& data){/*node* newnode = new node(data);node* cur = _head;while (cur->_next != _head){cur = cur->_next;}cur->_next = newnode;newnode->_prev = cur;newnode->_next = _head;*///复用insertinsert(end(),data);}void pop_back(){erase(--end());}void insert(iterator pos,const T& data){node* newnode = new node(data);//pos._node->_prev newnode pos._node pos._node->_prev->_next = newnode;newnode->_prev = pos._node->_prev;pos._node->_prev = newnode;newnode->_next = pos._node;}void erase(iterator pos){//哨兵位的结点不能删assert(pos != end());node* prev = pos._node->_prev;node* next = pos._node->_next;//prev nextprev->_next = next;next->_prev = prev;//删除结点delete pos._node;pos._node = nullptr;}private:node* _head;};
list的结构示意图:
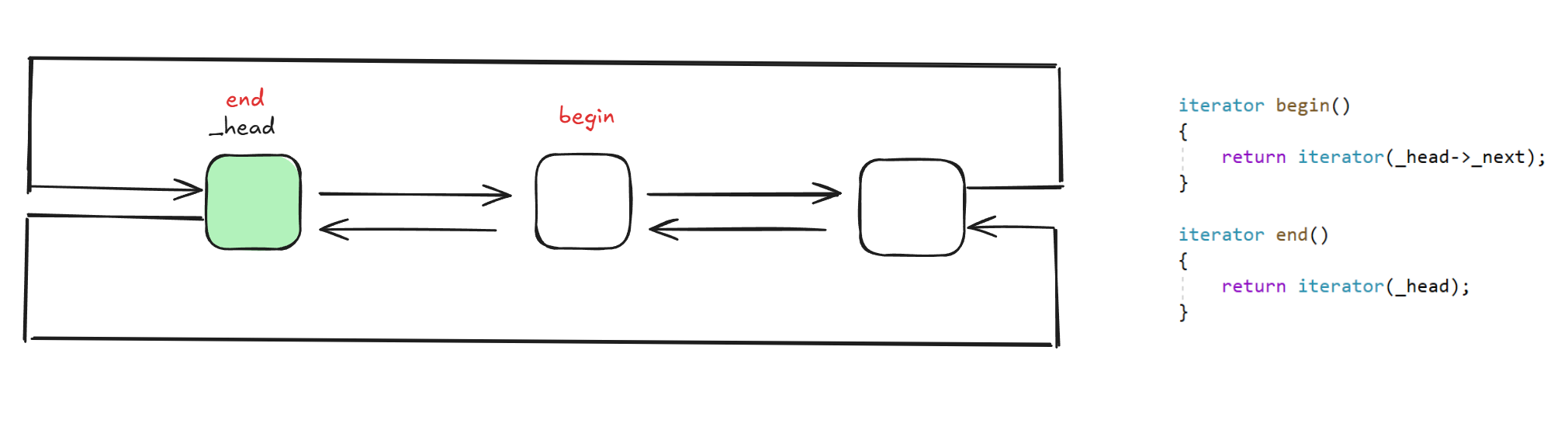
list含有一个哨兵位结点,该结点不存储有效数据,但是在很多场景会异常的好用;对于当前结构的哨兵位结合迭代器begin和end的返回位置,为我们提供了一种很好用的迭代器设置思路,换句话说:哨兵位的结点可以不单单只设置在链表结构中,其他数据结构如果要实现迭代器,也可以借鉴该种思想
insert和erase的示意图:
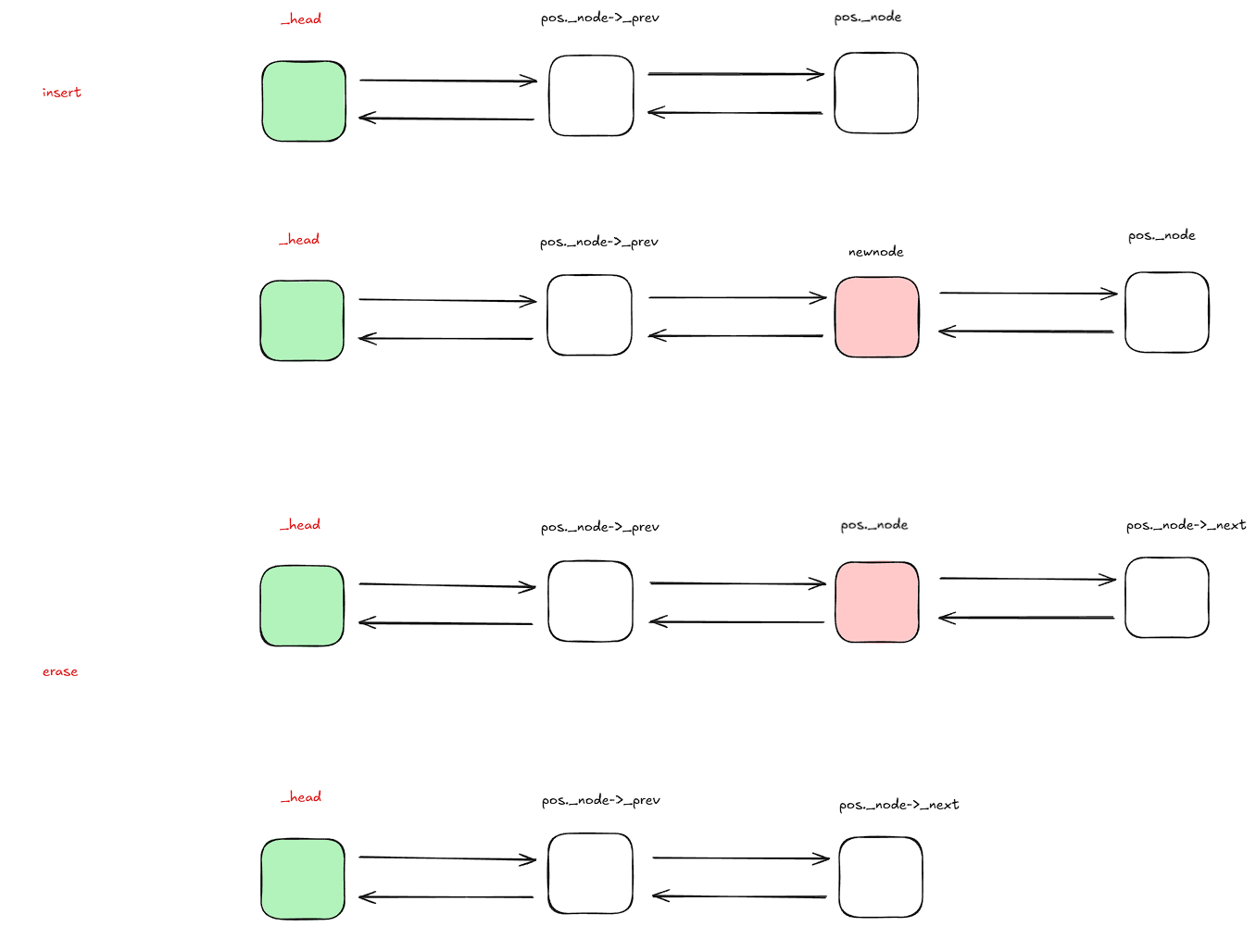
这部分快速地就实现了,因为实现思路不是特别的难,C++含有的this指针也为我们解决掉指针实质改变的一大麻烦问题
3.2.1 迭代器失效问题
目前的insert和erase接口其实是有问题的,参看官方文档:

为什么要把这两个接口的返回值设置成iterator呢?
void Test_list01()
{sy::list<int> l1;l1.push_back(1);l1.push_back(2);l1.push_back(3);l1.push_back(4);l1.push_back(5);auto it = l1.begin();while (it != l1.end()){if (*it % 2 == 0){cout << *it << "是偶数" << " ";l1.erase(it);}else{cout << *it << "是奇数" << " ";++it;}}
}
当前代码想要取出list中的偶数,执行结果:
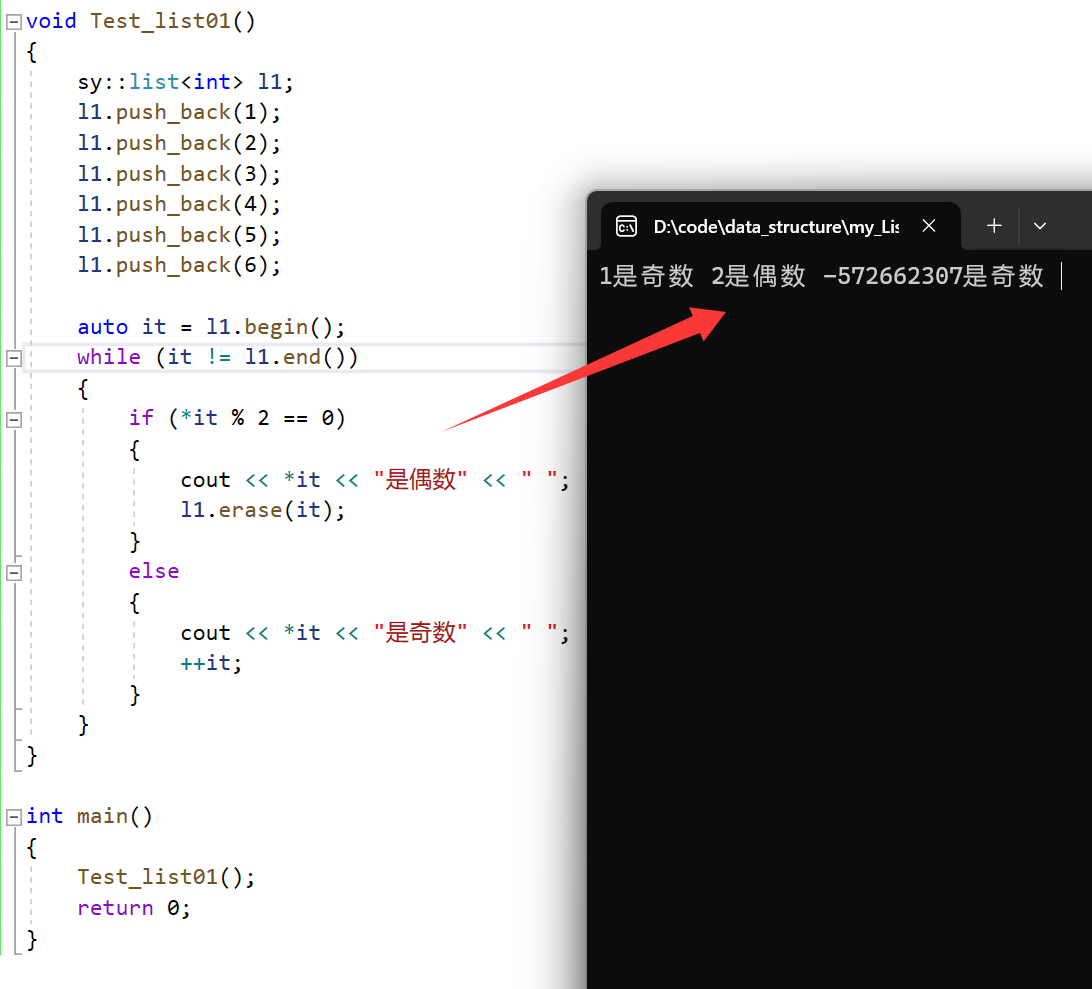
这里直接就运行崩溃了,画图进一步分析:
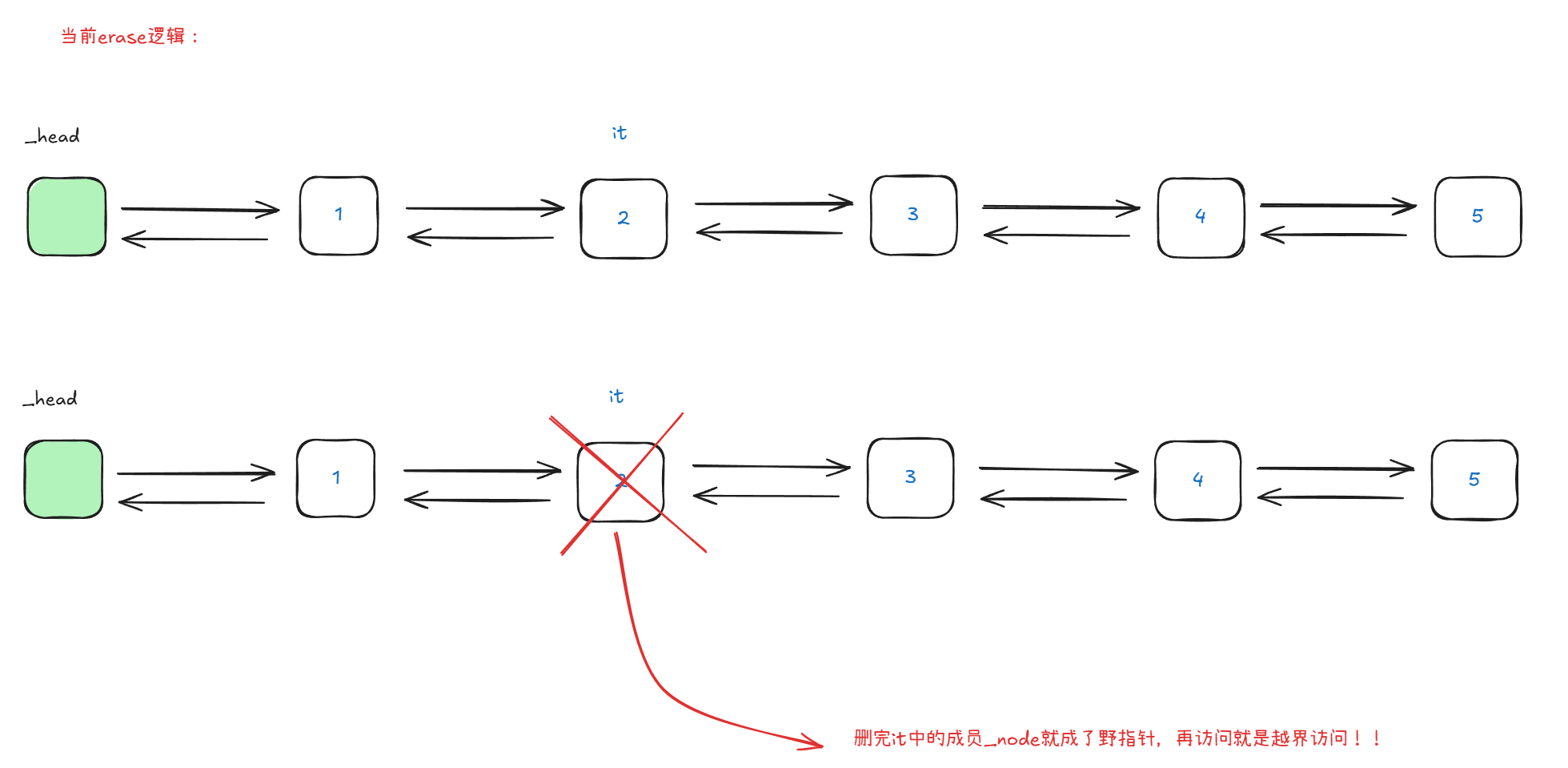
当前场景的迭代器由于以及被释放就属于是迭代器失效,所以上面输出结果输出的是越界后的指针的数据,——随机值,应该将迭代器进行重置一下,返回删除位置的下一个结点的地址
//更改为含有返回值
iterator erase(iterator pos){//哨兵位的结点不能删assert(pos != end());node* prev = pos._node->_prev;node* next = pos._node->_next;//prev nextprev->_next = next;next->_prev = prev;//删除结点delete pos._node;pos._node = nullptr;return iterator(next);}//测试用例进行重置
void Test_list01()
{list<int> l1;l1.push_back(1);l1.push_back(2);l1.push_back(3);l1.push_back(4);l1.push_back(5);l1.push_back(6);auto it = l1.begin();while (it != l1.end()){if (*it % 2 == 0){cout << *it << "是偶数" << " ";it = l1.erase(it);}else{cout << *it << "是奇数" << " ";++it;}}
}
思考一下:list的insert有没有迭代器失效的问题?
其实list的insert不存在迭代器失效,因为list不需要扩容,库里面也重载出一个返回值为迭代器的版本是为了统一接口
结论:
底层需要扩容的数据结构的insert会存在迭代器失效问题,而大部分容器的erase几乎都存在迭代器失效的问题
3.3 List中的迭代器设计
3.3.1 普通迭代器和const迭代器
STL中的迭代器分为普通迭代器和const迭代器,两者的本质区别在于是否支持修改返回值,对于const迭代器库里面将它重新命名为一个新的类型:const_iterator

当前我们将list改为需要调用const迭代器的版本:
void Print(const sy::list<int>& li)
{auto it = li.begin();while (it != li.end()){cout << *it << " ";//const迭代器不支持修改指向的内容//*it += 10;++it;}}void Test_list02()
{sy::list<int> l1;l1.push_back(1);l1.push_back(2);l1.push_back(3);l1.push_back(4);l1.push_back(5);l1.push_back(6);Print(l1);
}
执行报错(当前只有普通迭代器,const的list自动会调用const迭代器):

实现思路:
<1.再复制一份迭代器,生成两个版本的迭代器
template<class T>struct list_iterator{typedef list_node<T> node;typedef list_iterator<T> Self;node* _node;list_iterator(node* node):_node(node){}T& operator*(){return _node->_data;}Self& operator++(){_node = _node->_next;return *this;}Self operator++(int){node* tmp(_node);++_node;return tmp;}Self& operator--(){_node = _node->_prev;return *this;}Self operator--(int){node* tmp(_node);--_node;return tmp;}bool operator!=(const Self& s){return _node != s._node;}bool operator==(const Self& s){return _node == s._node;}};template<class T>struct list_constiterator{typedef list_node<T> node;typedef list_constiterator<T> Self;node* _node;list_constiterator(node* node):_node(node){}const T& operator*(){return _node->_data;}Self& operator++(){_node = _node->_next;return *this;}Self operator++(int){node* tmp(_node);++_node;return tmp;}Self& operator--(){_node = _node->_prev;return *this;}Self operator--(int){node* tmp(_node);--_node;return tmp;}bool operator!=(const Self& s){return _node != s._node;}bool operator==(const Self& s){return _node == s._node;}};//list类中(截取部分核心)typedef list_iterator<T> iterator;typedef list_constiterator<T> const_iterator;const_iterator begin() const{return const_iterator(_head->_next);}const_iterator end() const{return const_iterator(_head);}
但是当前的再复制一份,是不是有点过于冗余?只有operator*的返回值不一样,所以
就有了第二种思路
<2.增加一个模板参数
template<class T,class Ref>struct list_iterator{typedef list_node<T> node;typedef list_iterator<T, Ref> Self;node* _node;list_iterator(node* node):_node(node){}Ref operator*(){return _node->_data;}Self& operator++(){_node = _node->_next;return *this;}Self operator++(int){node* tmp(_node);++_node;return tmp;}Self& operator--(){_node = _node->_prev;return *this;}Self operator--(int){node* tmp(_node);--_node;return tmp;}bool operator!=(const Self& s){return _node != s._node;}bool operator==(const Self& s){return _node == s._node;}};//list类中的对应代码typedef list_iterator<T,T&> iterator;typedef list_iterator<T, const T&> const_iterator;iterator begin(){return iterator(_head->_next);}iterator end(){return iterator(_head);}const_iterator begin() const{return const_iterator(_head->_next);}const_iterator end() const{return const_iterator(_head);}
这里可以初步体会到模板的强大之处,虽然都是同一份类,但底层编译器生成了两份,达到了普通迭代器和const迭代器的效果
3.3.2 操作符operator->的重载
当list中的T存储的是一个自定义类型:
struct AA
{int _a1 = 10;int _a2 = 20;AA(int a1, int a2):_a1(a1),_a2(a2){}};void Test_list03()
{sy::list<AA> l1;l1.push_back({11,11});l1.push_back({ 12,12 });l1.push_back({ 13,13 });l1.push_back({ 14,14 });l1.push_back({ 15,15 });auto it = l1.begin();while (it != l1.end()){cout << *it << " ";++it;}
}
执行报错(因为当前operator*返回的是AA对象):

这里可以通过结构体的.进行访问,但是不符合指针的行为:
cout << (*it)._a1 << ":"<< (*it)._a2;
所以要在迭代器的类中进行重载:
//类中重载
T* operator->()
{return &_node->_data;
}//结构体指针访问
cout << it->_a1 << ":" << it->_a2;
但是这里会不会看着很怪?operator->返回的是数据的指针没错,但是it->_a1“好像”少了一个->,因为it->返回的是结构体指针,再来->才能访问到数据,这里其实是编译器的特殊处理,为了增加可读性,operator->在底层会先返回一个T*的临时对象在用->进行访问数据,底层机制:
cout << it.operator->()->_a1 << ":" << it.operator->()->_a2;
当重载了->的操作符,也要给普通迭代器和const迭代器进行区分,所以要再增加一个模板参数,到达这里你就知道为什么迭代要设计成三个模板参数了,引用,指针都算是一个新的类型:
//T:存储的数据类型
//Ref:reference(引用),operator*的返回值
//Ptr:pointer(指针/地址),operator->的返回值
template<class T,class Ref,class Ptr>struct list_iterator{typedef list_node<T> node;typedef list_iterator<T, Ref,Ptr> Self;node* _node;list_iterator(node* node):_node(node){}Ref operator*(){return _node->_data;}Ptr operator->(){return &_node->_data;}Self& operator++(){_node = _node->_next;return *this;}Self operator++(int){node* tmp(_node);++_node;return tmp;}Self& operator--(){_node = _node->_prev;return *this;}Self operator--(int){node* tmp(_node);--_node;return tmp;}bool operator!=(const Self& s){return _node != s._node;}bool operator==(const Self& s){return _node == s._node;}};//list类中
//注意注意:相应的模板参数也要加上!!! 初学很容易漏掉
typedef list_iterator<T,T&,T*> iterator;
typedef list_iterator<T, const T&, const T*> const_iterator;3.3.3 迭代器的分类
| 迭代器类别 | 对应容器 | 支持移动操作 |
|---|---|---|
| 单向迭代器 | forward_list,unordered_map,unordered_set, | ++ |
| 双向迭代器 | list,map,set | ++、– |
| 随机迭代器 | deque,string,vector | ++、–、+、- |
文档中将迭代器由行为进行继承:

也就是说:双向迭代器就是特殊的单向迭代器,随机迭代器又是特殊的双向迭代器
拓展:迭代器进一步划分还有两个类别:只读、只写迭代器,这里等到后续再进行详细展开
从支持移动操作就可以看出对应容器的访问和相互之间迭代器的兼容,有了迭代器分类的支撑对于我们理解算法库的方法有很大的帮助:

像算法库的sort要求是随机迭代器因为底层是快排要用到元素个数必须支持end()-begin()的操作,所以像list就用不了算法库的sort(双向迭代器没有指针相减的行为)

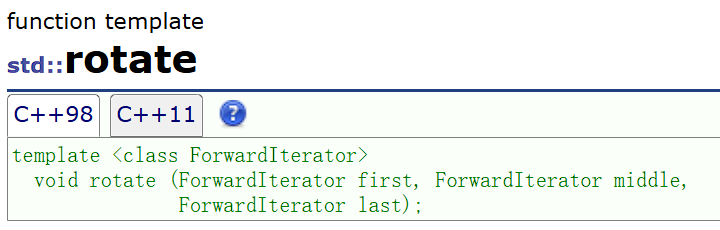
如何查看当前容器的迭代器类型(以list为例):
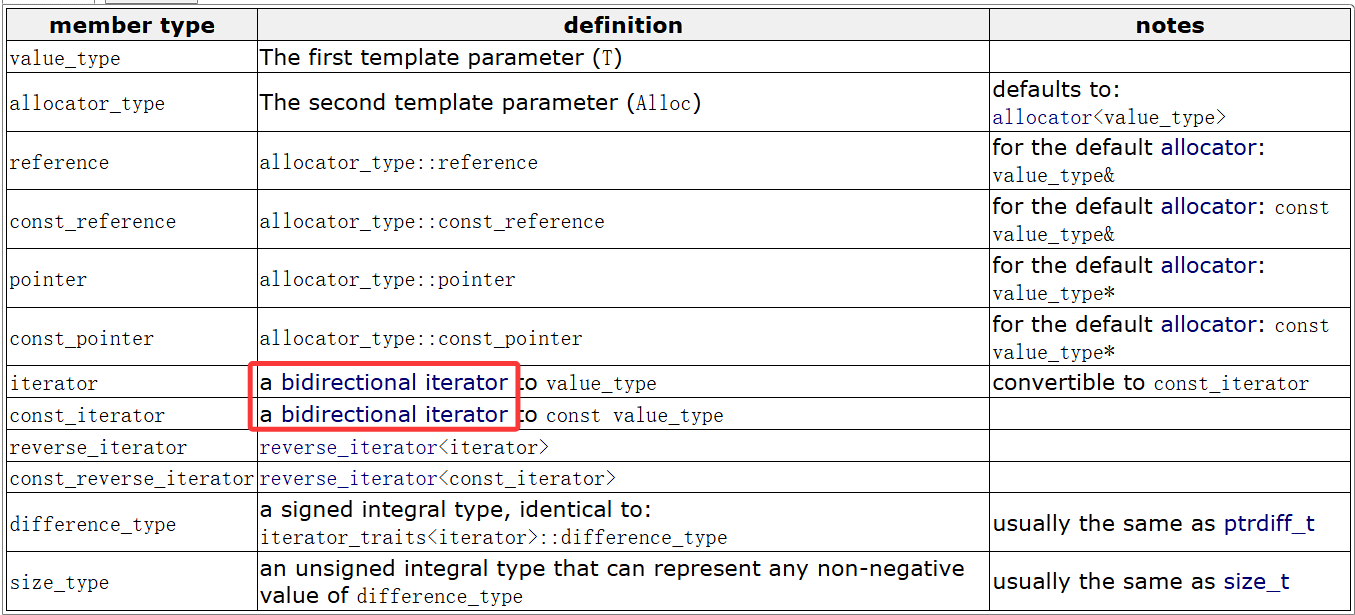
文档中对于list的迭代器就有说明:bidirectional(双向的)
注意:库里面的类型大多都经过typedef,对于不认识的类型查询即可
3.3.4 范围for和initializer_list的底层
当我们要查看某个语法的底层的时候,方法就是:瞅一眼汇编+代码验证
<1.范围for
范围for中的auto是在C98之前就有了,后面进行语法更近变为自动识别类型的标识符,来看底层:
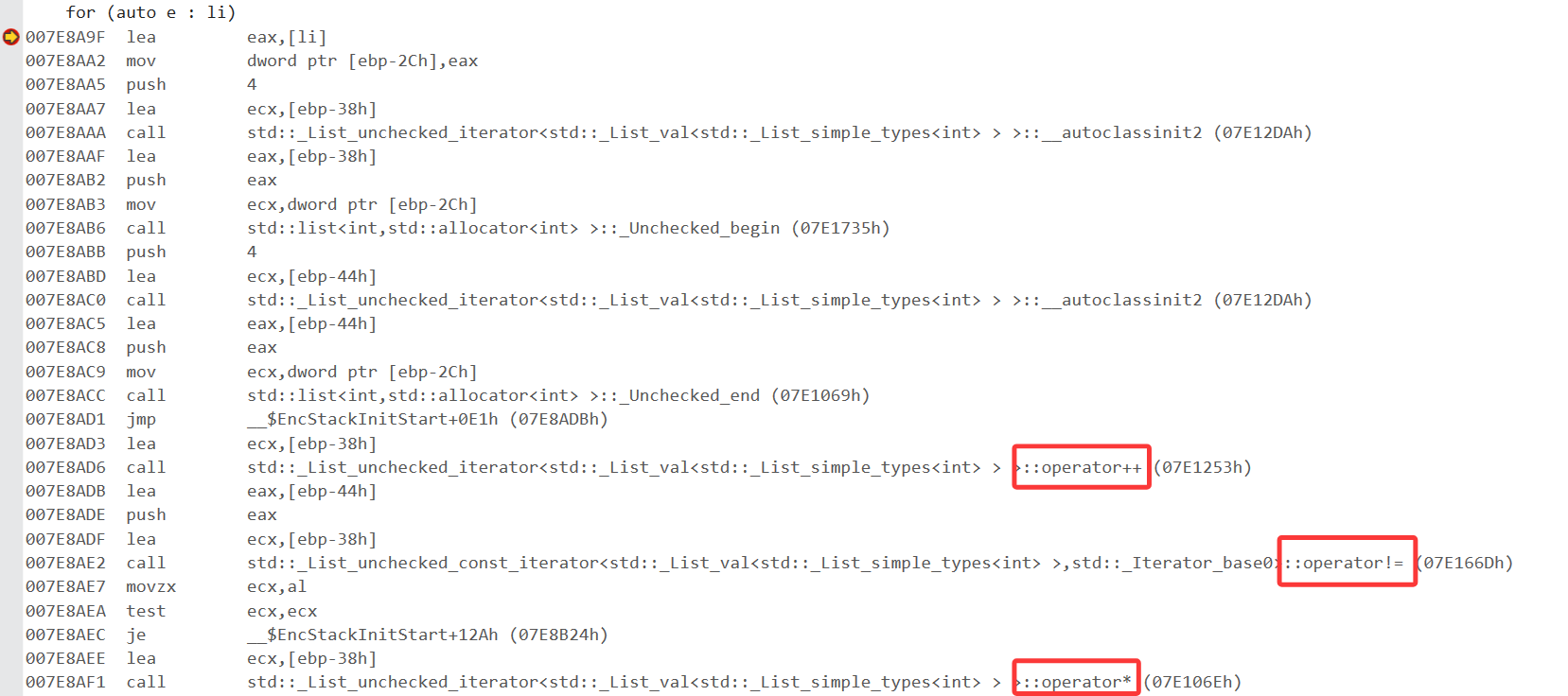
汇编代码中:范围for其实只是识别迭代器的begin和end然后让编译器用迭代器进行++,比较,访问等操作,只是写法上进行包装,底层还是让编译器做工作
验证(使用我们自己实现的list并进行迭代器屏蔽):
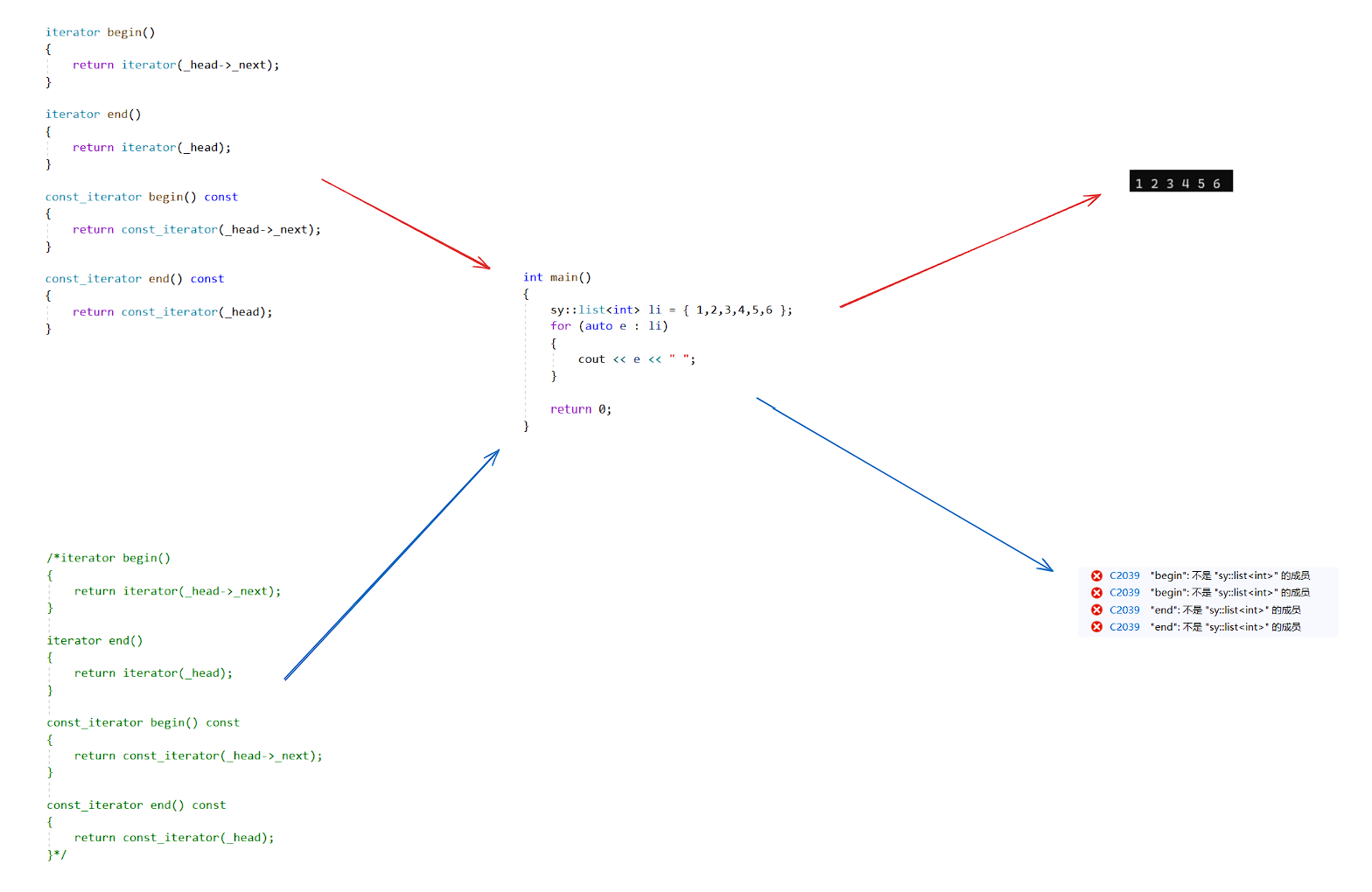
<2.initializer_list
C++11提供了一种新的初始化方式:initializer_list,支持用花括号的方式,写法:
int main()
{list<int> li = { 1,2,3,4,5,6 };return 0;
}
底层:
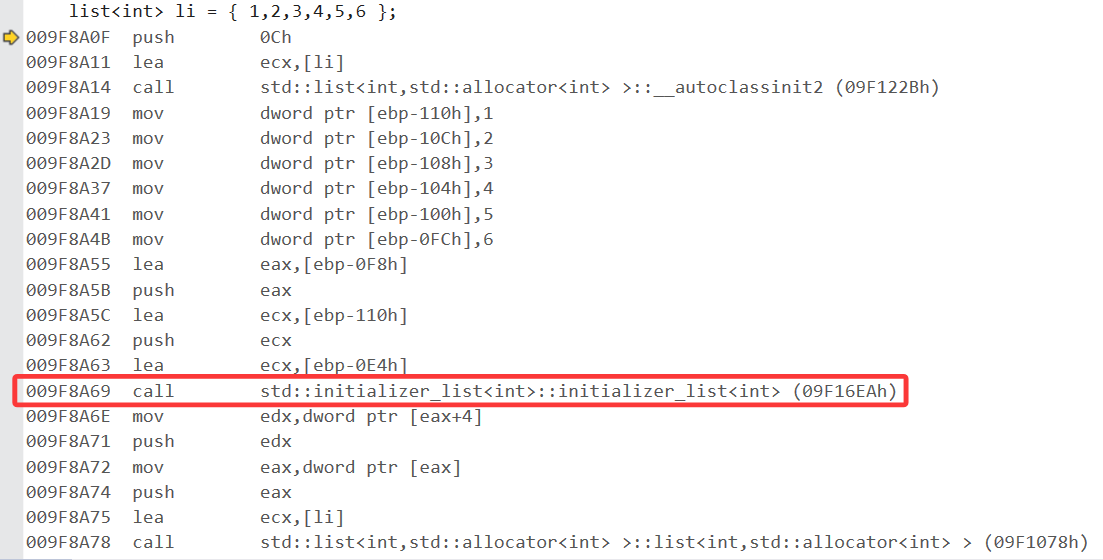
call其实就是函数调用,它会把函数的地址传过去进行调用,可以看到它同范围for类似,通过识别编译器来工作
实现一个我们自己的initializer_list,逻辑非常简单,调用push_back将形参依次插入:
list(initializer_list<T> li)
{for (auto& e : li){push_back(e);}
}
运行:
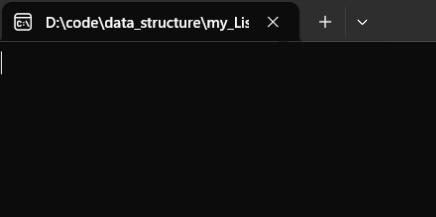
结果可以看到是崩溃了的,通过调试就可以看到,因为这里对于initializer_list的构造没有申请动态空间,导致链表本身为空,所以要将申请哨兵位结点单独封装成一个函数:
void initialize_node()
{_head = new node;_head->_next = _head;_head->_prev = _head;
}list()
{initialize_node();
}list(initializer_list<T> li)
{initialize_node();for (auto& e : li){push_back(e);}
}
此时再运行:
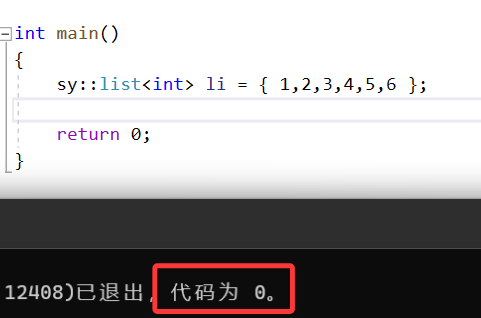
验证:
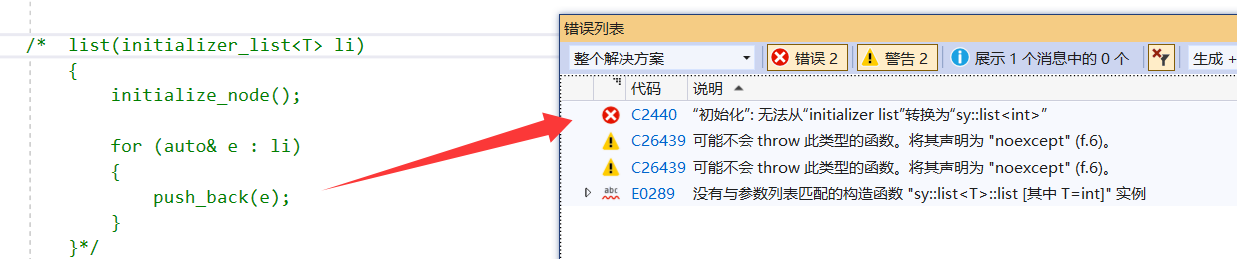
背后的设计理念:两者的底层都是通过提供对应的接口,让编译器做内置行为,使得代码简洁化,符合现代化写法的语法糖,——它能让代码更甜,但是营养价值(功能)不变
3.4 C++11的新接口
在官方文档中,针对容器的接口,提供新的版本:
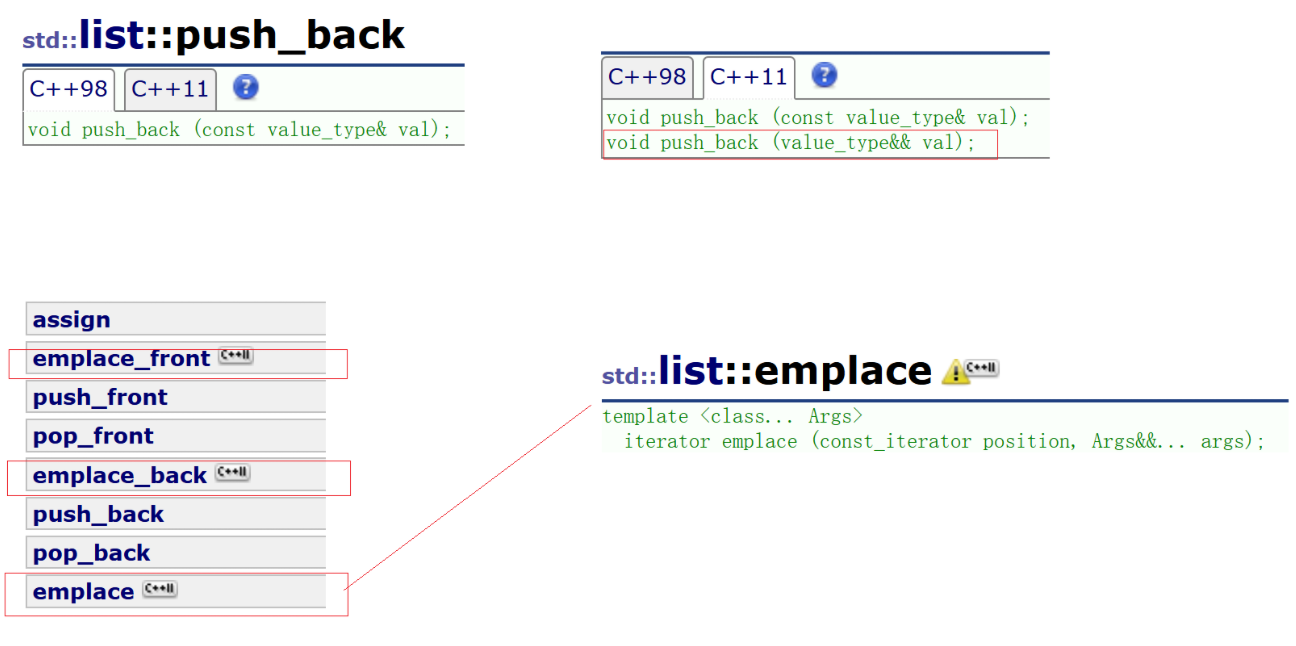
由于C++11的新语法产生的新接口,push_back重载了形参为右值的版本,还提供了emplace系列,在后面会讲底层实现
3.5 C++11的新语法
3.5.1 左值和右值
C++11之前就有左值和右值的定义:
- 左值(lvalue):可以进行取地址操作,在内存中可以找到相应的地址,并且可以进行修改;常见的有:栈上/堆上的变量,类实例化的对象
- 右值(rvalue):不可以进行取地址操作,语法层面来说没有对应的地址进行存储(但是通过右值引用绑定获得地址),不可以进行修改;常见的有:变量表达式,常量字符串,匿名对象
注意: lvalue和rvalue的首字母并不代表left,right;而是load(加载——有地址),read(可读)的含义
struct AA
{int _a1;int _a2;AA(int a1 = 10, int a2 = 20):_a1(a1), _a2(a2){}};int main()
{
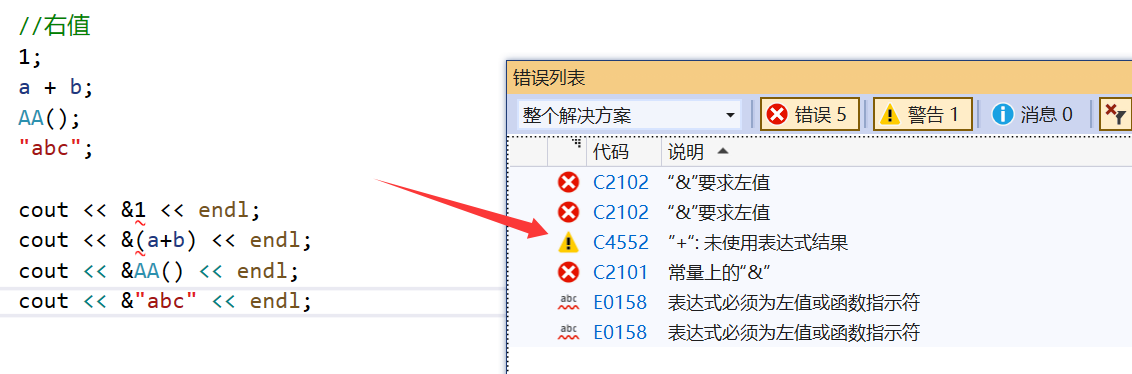
//左值int i1 = 0;double d1 = 2.2;int arr[] = { 0 };int* pi1 = new int(10);AA aa1;cout << &i1 << endl;cout << &d1 << endl;cout << &arr << endl;cout << &pi1 << endl;cout << &aa1 << endl;int a = 2, b = 3;//右值1;a + b;AA();"abc";//不可以进行取地址操作cout << &1 << endl;cout << &(a+b) << endl;cout << &AA() << endl;cout << &"abc" << endl;return 0;
}
编译结果:
3.5.2 右值引用和引用折叠
C++11新增了一个引用版本被称为——右值引用,也就是上面push_back重载的新版本。
右值引用:是引用的引用,对右值进行绑定,写法:在左值引用的基础上再加一个&
//右值1;a + b;AA();"abc";//右值引用int&& ri1 = 1;int&& r1 = a + b;AA&& raa = AA();string&& rs = "abc";//能否取地址?cout << &ri1 << endl;cout << &r1 << endl;cout << &raa << endl;cout << &rs << endl;
注意:右值引用后的变量是可以取地址的
为什么要设计右值引用呢 :
当前我用命名空间将自己模拟实现的string给封起来(容易观察底层的调用和官方库的string进行区分),这里string的拷贝赋值和拷贝构造建议使用传统写法(以免调用逻辑混乱),并实现一个字符串相加的函数:
#include<iostream>
#include<assert.h>
#include<string.h>
#include<algorithm>using namespace std;namespace sy
{class string{public:typedef char* iterator;typedef const char* const_iterator;iterator begin(){return _str;}iterator end(){return _str + _size;}const_iterator begin() const{return _str;}const_iterator end() const{return _str + _size;}string(const char* str = ""):_size(strlen(str)), _capacity(_size){cout << "string(char* str)-- 构造" << endl;_str = new char[_capacity + 1];strcpy(_str, str);}void swap(string& s){::swap(_str, s._str);::swap(_size, s._size);::swap(_capacity, s._capacity);}string(const string& s):_str(nullptr){cout << "string(const string& s) -- 拷贝构造" << endl; reserve(s._capacity);for (auto ch : s){push_back(ch);}}string& operator=(const string& s){cout << "string& operator=(const string& s) -- 拷贝赋值" <<endl;if (this != &s){_str[0] = '\0';_size = 0;reserve(s._capacity);for (auto ch : s){push_back(ch);}}return *this;}~string(){cout << "~string() -- 析构" << endl;delete[] _str;_str = nullptr;}char& operator[](size_t pos){assert(pos < _size);return _str[pos];}void reserve(size_t n){if (n > _capacity){char* tmp = new char[n + 1];if (_str){strcpy(tmp, _str);delete[] _str;}_str = tmp;_capacity = n;}}void push_back(char ch){if (_size >= _capacity){size_t newcapacity = _capacity == 0 ? 4 : _capacity *2;reserve(newcapacity);}_str[_size] = ch;++_size;_str[_size] = '\0';}string& operator+=(char ch){push_back(ch);return *this;}const char* c_str() const{return _str;}size_t size() const{return _size;}private:char* _str = nullptr;size_t _size = 0;size_t _capacity = 0;};string addStrings(string num1, string num2){string str;int end1 = num1.size() - 1, end2 = num2.size() - 1;int next = 0;while (end1 >= 0 || end2 >= 0){int val1 = end1 >= 0 ? num1[end1--] - '0' : 0;int val2 = end2 >= 0 ? num2[end2--] - '0' : 0;int ret = val1 + val2 + next;next = ret / 10;ret = ret % 10;str += ('0' + ret);}if (next == 1) str += '1';reverse(str.begin(), str.end());cout << "******************************" << endl;return str;}
}
注意当前进行字符串相加的函数的返回值机制——用的是在函数栈帧创建的局部变量进行返回,我们用一个变量s进行接受该函数的返回值:
sy::string s = sy::addStrings("11111","22222");
调用机制示意图:
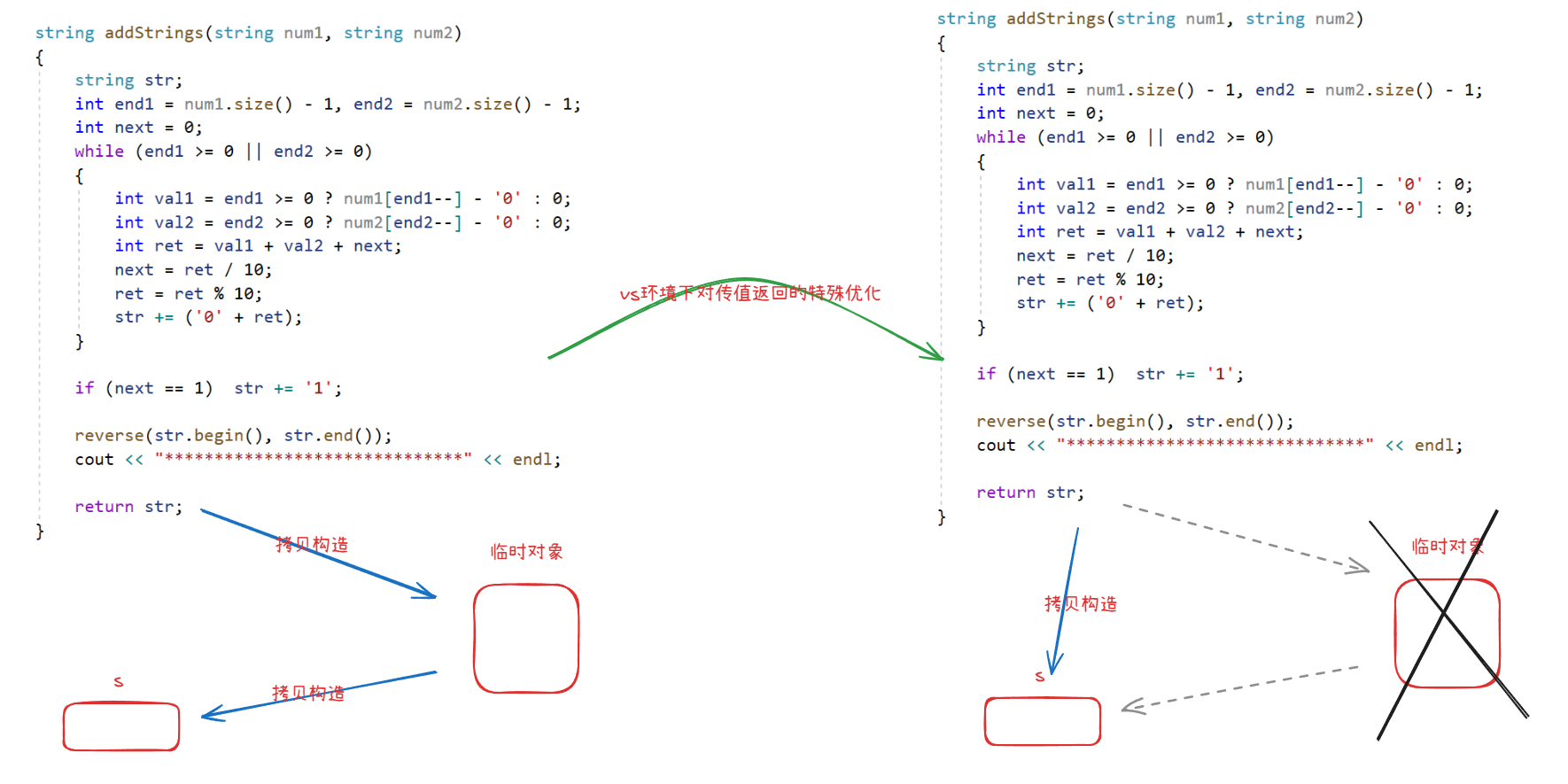
addStrings函数需要通过内部栈帧的变量返回两个字符串相加的结果,这就导致了一定要传值返回,但是对于编译器来说,不做优化时传值返回的机制:先用返回值拷贝构造出一个临时对象,再将临时对象拷贝构造给接受值s,对于VS环境下确实做了优化,但是这能作为代码在其他编译器下也能达到的效果吗?编译器的优化程度是不可预期的,并且在当前情况下,str作为出完栈帧就要销毁的变量,还需要拷贝不就显得非常鸡肋吗?于是就有了移动语义的语法。
vs环境下编译器的优化:
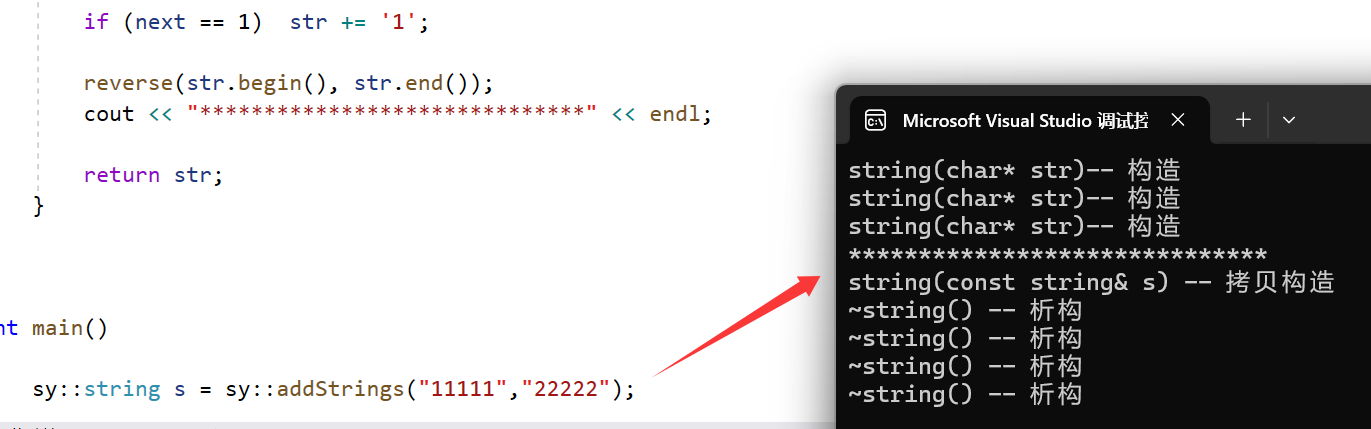
前两个构造是在函数形参的时候就调用的,C++11之前规定:只要是传值传参就要调用拷贝构造,但是这里编译器又进行优化了:构造+拷贝构造–>构造
Linux关闭拷贝构造优化的指令:
-fno-elide-constructors
验证:
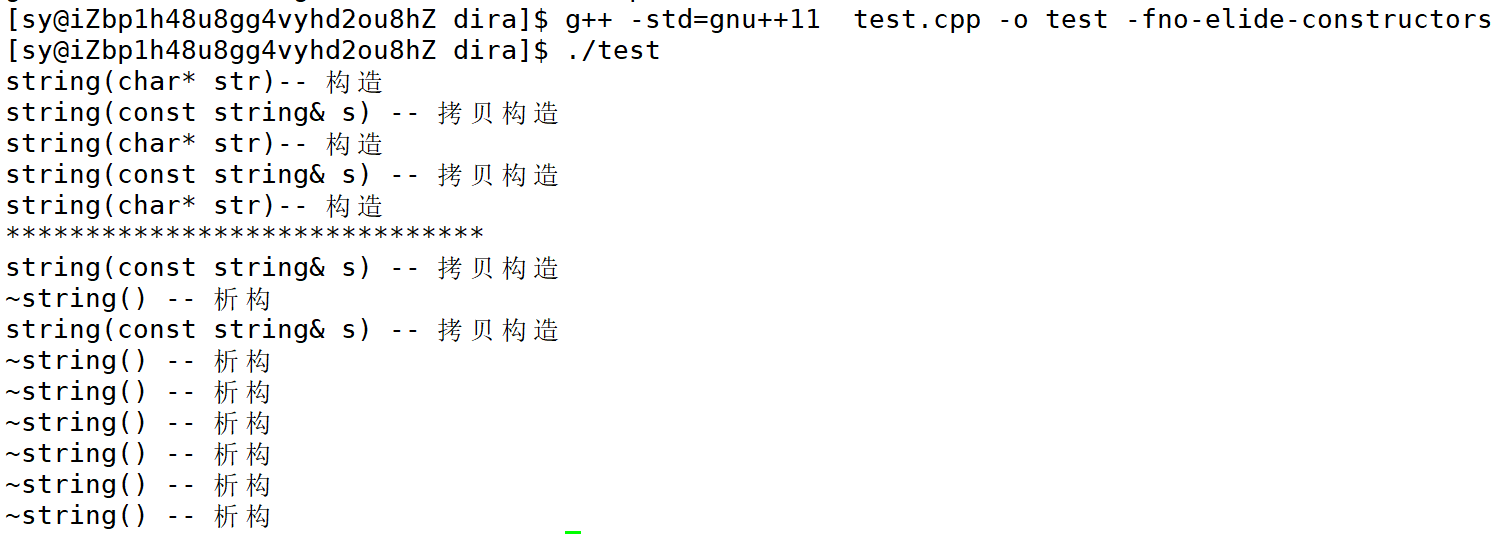
关闭优化后:传值传参的构造+拷贝构造,传值返回的两次拷贝构造
引用折叠:
当一个类没有写移动构造和移动赋值,对于右值只能进行拷贝构造和拷贝赋值,这是因为引用的规则:

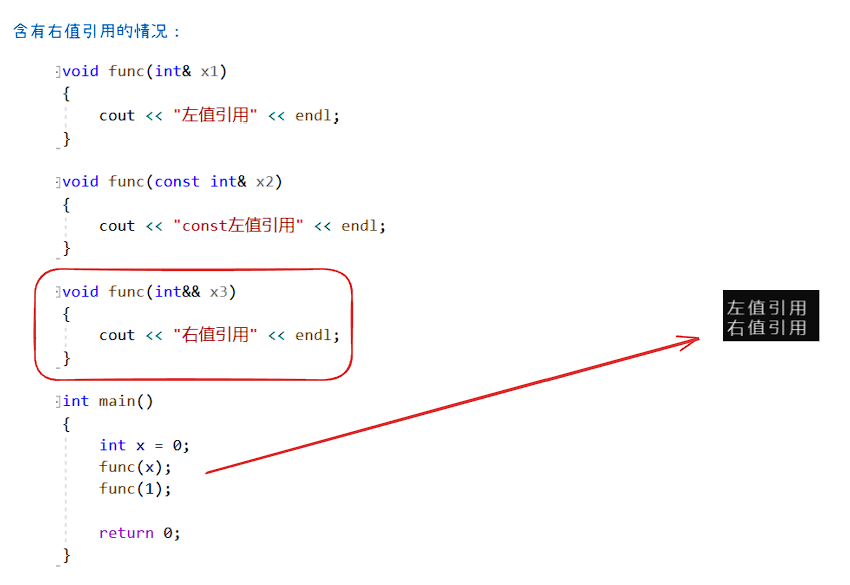
void func(int& x1)
{cout << "左值引用" << endl;
}void func(const int& x2)
{cout << "const左值引用" << endl;
}void func(int&& x3)
{cout << "右值引用" << endl;
}int main()
{int x = 0;func(x);func(1); return 0;
}
注意: 在函数匹配的时候,编译器会优先选择最匹配的,在有现成的函数在时如果还有同样的函数的模板,它还是会调用现成的函数
引用规则:
<1.const的左值引用可以引用右值
<2.右值引用可以引用move以后的左值
注:move是一个模板,用于类型转换,不建议使用,因为move了以后资源就会被转移
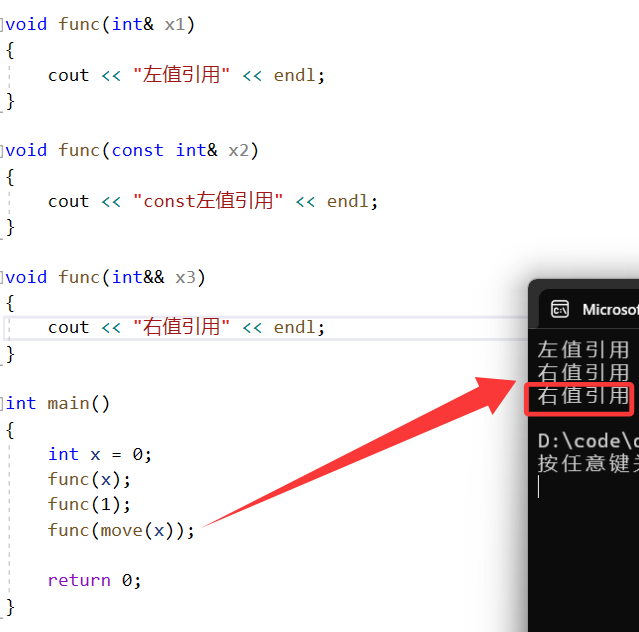
引用折叠能用同一个模板实现出左值引用版本和右值引用版本
template<class T>
void func(T&& x)
{}int main()
{int a1 = 1;int& la1 = a1;const int& la2 = a1;int&& r1 = 1;//没有折叠,实例化func(int&& x)func<int>(1);func<int>(a1); //报错func<int>(move(a1));//引用折叠,实例化func(int& x)func<int&>(la1);//func<int&>(la2); //权限放大,报错//func<int&>(1); //报错//折叠,实例化func(const int& x)func<const int&>(la1); //权限可以缩小func<const int&>(la2); func<const int&>(1); //折叠,实例化func(int&& x)func<int&&>(1);//func<int&&>(la1); //报错//func<int&&>(r1); //报错func<int&&>(move(a1));return 0;
}
记住引用折叠的规则:出现折叠的时候,只有传递右值,它才会实例化出右值引用的版本
细节1: 这里的T&&不是T类型的右值引用,而是被称为万能引用
细节2: 右值引用后的变量属于左值,这会导致另一些问题的产生(结合后续样例说明)
3.5.3 移动构造和移动赋值
在上述场景中,为了解决右值返回的情况,C++11为类新提出了两个默认成员函数:移动构造和移动语义。对于即将销毁的右值,不再进行拷贝,而是进行资源的转移 ,对于str它本身就是马上要销毁了,还不如对当前的str进行一次一次的资源转移交给接受变量s,这样很大程度地提高了效率,下面就来实现string的两个默认成员函数:
void swap(string& s){::swap(_str, s._str);::swap(_size, s._size);::swap(_capacity, s._capacity);} //移动构造————依附于swapstring(string&& s){cout << "string(string&& s) -- 移动构造" << endl;swap(s);}//移动赋值string& operator=(string&& s){cout << "string& operator=(string&& s) -- 移动赋值" << endl;swap(s);return *this;}
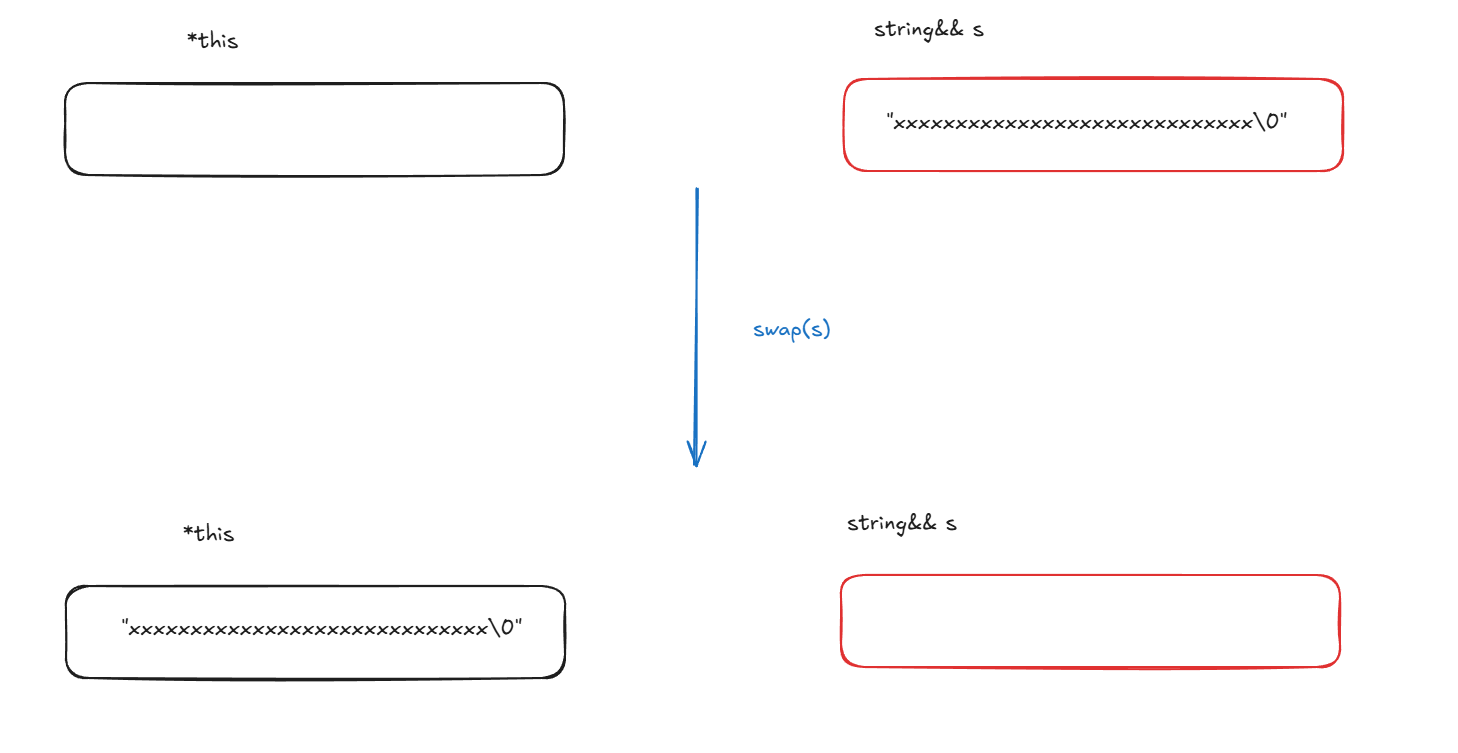
编译结果:
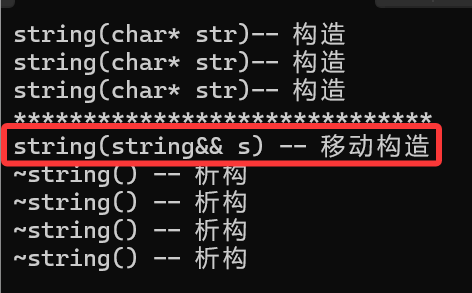
此时拷贝构造就变成了移动构造,当然这里是编译器优化的结果:移动构造+移动构造–>移动构造
Linux下关闭优化:
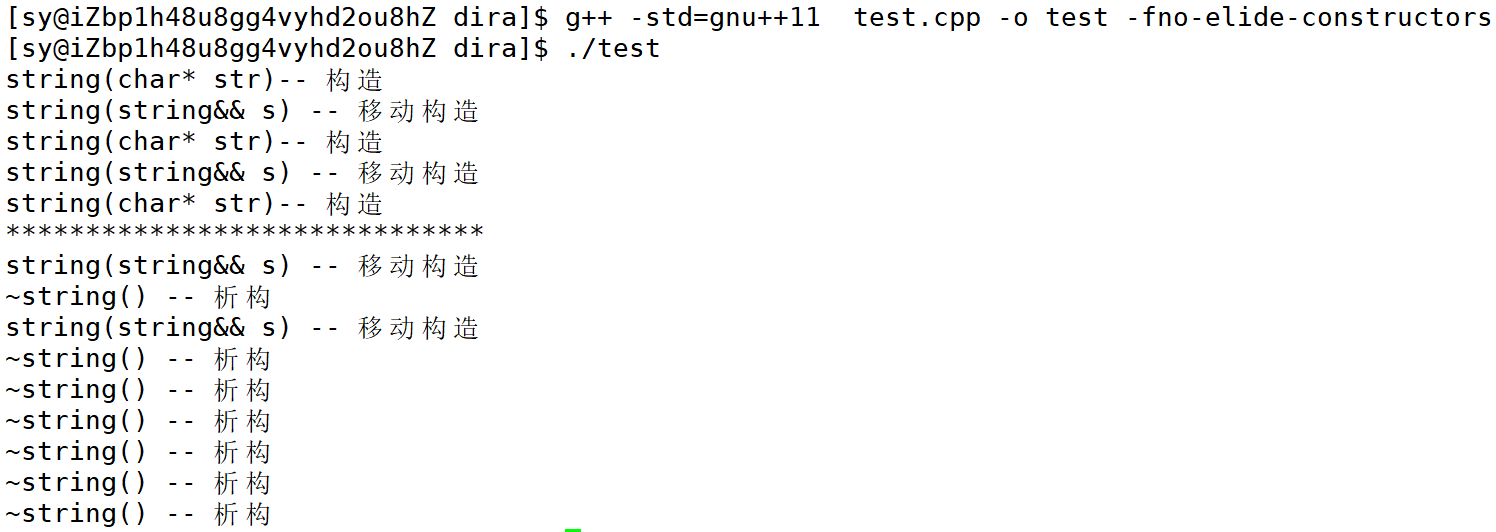
这里虽然关闭优化,传值返回是两次移动构造,但减少了拷贝次数变成了资源的两次转移,大大提高了效率。
此时再看官方库中的C++11之后提供的构造接口就能看懂了:

3.5.4 可变参数模板
C++11新提供了两个可变参数模板,它支持可变数量参数的类模板和函数模板,可变数目的参数被称为参数包,可以表示零个或多个模板参数,语法格式如下:
//注意在模板处...在类名的前面,形参处又在类型名的后面
template<class ...Args> void Func(Args... args) {};
template<class ...Args> void Func(Args&... args) {};
template<class ...Args> void Func(Args&&... args) {};
- 形参处也是根据折叠引用的规则实例化对应类型
- 可变参数模板的机制和普通模板一样,都是在实例化对应类型和个数的多个函数
- 用sizeof…运算符可以计算参数包中的参数个数
实例化过程:
template<class... Args>
void Cal_Args(Args... args)
{cout << sizeof...(args) << endl;
}int main()
{Cal_Args(1);Cal_Args(1,3.14);Cal_Args(1, 3.14,'x');return 0;
}

用途:
- 减少冗余的代码,在要进行多参数打印的时候,写一个模板传递不同参数就能做到
- 提高了容器的灵活性,基于可变参数包的机制,容器可以装在不同类型的元素
- 实现完美转发:将函数参数原封不动地(包括其值类别:左值、右值;以及 const/volatile 限定符)传递给另一个函数
3.6 C++11版本的push_back和emplace_back的实现
3.6.1 push_back
<1.重载右值引用的版本
//重载出右值版本
void push_back(const T& data)
{/*node* newnode = new node(data);node* cur = _head;while (cur->_next != _head){cur = cur->_next;}cur->_next = newnode;newnode->_prev = cur;newnode->_next = _head;*///复用insertinsert(end(), data);
}void push_back(T&& data)
{insert(end(), data);
}int main()
{//当前实现的string已经实现了移动构造和移动赋值了sy::list<sy::string> li;li.push_back("11111111111111");li.push_back("11111111111111");li.push_back("11111111111111");return 0;
}
运行:
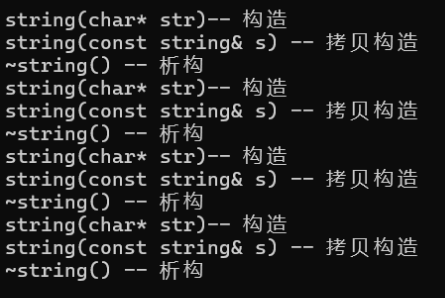
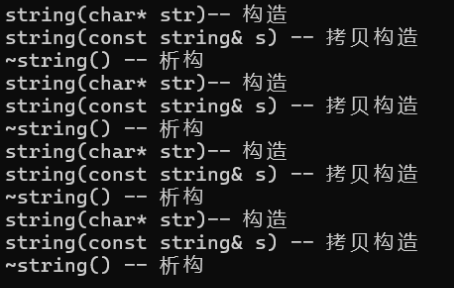
实际的右值版本调用的还是拷贝构造,这是为什么?
上述中我们谈到右值引用后的变量仍然是左值,右值引用的值是不可以修改的,但是如果不能修改,怎么移动?指向都不能改变还怎么进行相关的移动构造和移动赋值,所以才将右值引用后的变量作为左值,因为变量都是可以取地址的左值,这是符合语法规则的;但是这里又会有另一个问题,如果右值引用后还是左值那么,在传递右值时的那个参数如果辨别是左值还是右值?这里我们进行代码逻辑的调试看一下它是怎么初始化的:
右值版本调试
这里如果还提供了insert的右值版本还是会调不到,因为push_back的data引用右值后是左值,为了解决这一问题,C++11提供了一个新的语法:完美转发

- 完美转发是一个函数模板,对于右值引用后的变量表达式要使用完美转发才能保持原有的右值属性
- 实参为int的右值,被推导为int,内部强制性以右值引用进行返回;实参为左值,被推导为int&,内部强制性以左值引用进行返回

完美转发本质还是通过引用折叠通过C++规定的类型转换进行实现的,static_cast是一个强制类型转换的运算符,用于基本类型的转换
代码在push_back这一层的改变:

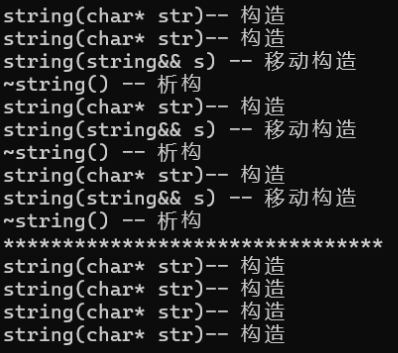
运行:
仍然没有调到移动构造,所以每一层都要处理干净,并给结点提供右值引用版本的构造:
template<class T>
struct list_node
{T _data;list_node* _next;list_node* _prev;list_node(const T& data):_data(data), _next(nullptr), _prev(nullptr){}list_node(T&& data = T()):_data(forward<T>(data)), _next(nullptr), _prev(nullptr){}};void push_back(const T& data)
{//复用insertinsert(end(), data);
}void push_back(T&& data)
{//保持右值属性insert(end(), forward<T>(data));
}void insert(iterator pos, const T& data)
{node* newnode = new node(data);//pos._node->_prev newnode pos._node pos._node->_prev->_next = newnode;newnode->_prev = pos._node->_prev;pos._node->_prev = newnode;newnode->_next = pos._node;
}void insert(iterator pos, T&& data)
{node* newnode = new node(forward<T>(data));//pos._node->_prev newnode pos._node pos._node->_prev->_next = newnode;newnode->_prev = pos._node->_prev;pos._node->_prev = newnode;newnode->_next = pos._node;
}细节1: 当在结点中提供了右值引用的构造时,缺省值给右值版本效率会更高,因为在链表构造哨兵位的时候也会new,new就会调用结点的构造
细节2: 对于传递右值引用的版本,每一层都要处理干净保证右值的属性不会丢失
<2.函数模板版本:
在学习到了引用折叠以后,对于push_back就不用以函数重载的方式,直接套用模板让编译器自己推导会方便很多,库里面实现的逻辑是再重载了右值引用的版本,因为要兼容以前的版本
template<class T>
struct list_node
{T _data;list_node* _next;list_node* _prev;list_node(const T& data):_data(data), _next(nullptr), _prev(nullptr){}list_node(T&& data = T()):_data(forward<T>(data)), _next(nullptr), _prev(nullptr){}};template<class X>
void push_back(X&& data)
{insert(end(), forward<X>(data));
}template<class X>
void insert(iterator pos, X&& data)
{node* newnode = new node(forward<X>(data));pos._node->_prev->_next = newnode;newnode->_prev = pos._node->_prev;pos._node->_prev = newnode;newnode->_next = pos._node;
}
3.6.2 emplace_back
- C++11为容器都提供了emplace系列,文档中emplace系列用了可变参数进行传参
- 在有些场景下emplace系列的效率较高,以后建议多多使用emplace系列
- 有emplace系列,兼容以前的insert和push_back系列,对于自定义类型的参数传递,emplace就像显示调用参数匹配的构造函数一样
实现emplace系列:
template<class T>
struct list_node
{T _data;list_node* _next;list_node* _prev;list_node(T&& data):_data(move(data)), _next(nullptr), _prev(nullptr){}template<class ...Args>list_node(Args&&... args):_data(forward<Args>(args)...), _next(nullptr), _prev(nullptr){}
};template<class ...Args>
void emplace_back(Args&&... args)
{emplace(end(), forward<Args>(args)...);
}template<class ...Args>
void emplace(iterator pos, Args&&... args)
{node* newnode = new node(forward<Args>(args)...);pos._node->_prev->_next = newnode;newnode->_prev = pos._node->_prev;pos._node->_prev = newnode;newnode->_next = pos._node;
}
注意:可变参数包在形参位置和配合完美转发时的语法格式,需要记忆一下
效率对比:
int main()
{sy::list<sy::string> li;li.push_back("11111111111111");li.push_back("11111111111111");li.push_back("11111111111111");cout << "********************************" << endl; sy::list<sy::string> li1;li1.emplace_back("11111111111111");li1.emplace_back("11111111111111");li1.emplace_back("11111111111111");return 0;
}
运行:
emplace当前场景直接构造的原因:

C++11产生的语法:完美转发+函数模板使得构造函数重载的多个模板得到了更多的复用,并且少产生临时对象
注意:只有在传递纯右值的时候emplace系列的效率比push_back略胜一筹,其他场景效率一致;纯右值是C++给左值和右值的进一步分类,可以自行下去了解
emplace_back传递自定义类型的场景:
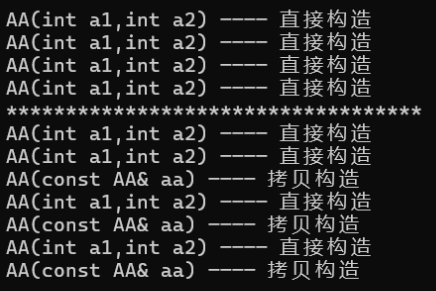
struct AA
{int _a1;int _a2;AA(int a1 = 1,int a2 = 1):_a1(a1),_a2(a2){cout << "AA(int a1,int a2) ———— 直接构造" << endl;}AA(const AA& aa){_a1 = aa._a1;_a2 = aa._a2;cout << "AA(const AA& aa) ———— 拷贝构造" << endl;}
};int main()
{sy::list<AA> li;li.emplace_back(1, 2);li.emplace_back(2, 3);li.emplace_back(3, 4);cout << "***********************************" << endl;sy::list<AA> li1;li1.push_back({ 1,2 });li1.push_back({ 2,3 });li1.push_back({ 3,4 });//报错,花括号会被编译器识别成initializer_list//li.emplace_back({ 1,2 });return 0;
}
运行: