SQL查询基础常用攻略
目录
主要类型
查询
查询SELECT
去掉重复值DISTINCT
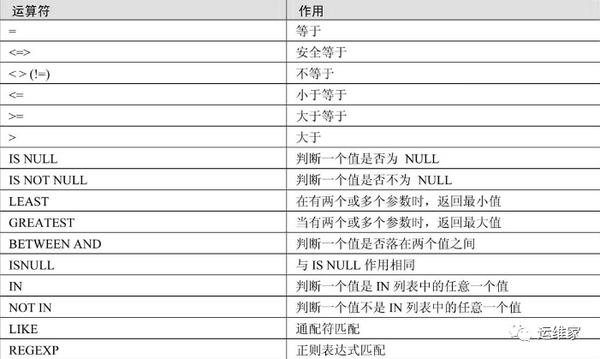
条件查询WHERE
运算符AND\OR
排序ORDER BY
模糊查询LIKE
指定范围查询BETWEEN AND
提取数据LIMIT
连接查询JOIN
子查询SELECT(SELECT)
标量子查询(返回一行一列)
列子查询(返回一列多行)
行子查询(返回一行多列)
操作
新增数据INSERT INTO
修改数据UPDATE SET
删除数据DELETE
聚合函数
计算行数COUNT()
求最大值MAX()
求最小值MIN()
求和SUM()
数据分组GROUP BY
分组后按条件查询HAVING
窗口函数
对数据排名RANK()
按照列排名(ORDER BY,在窗口内按指定列排序)
名次重复时保留名次空缺
名词重复时合并名次
按照分组排序(PARPATITON BY,将数据分成多个分区,窗口函数在每个分区内独立计算)
名次有重复值
名次没有重复值
窗口函数与聚合函数
流程函数
CASE函数
日期函数
提取时间DATE_FORMAT
天数差DATEDIFF
精确差TIMESTAMPDIFF
获取当前日期CURDATE
主要类型
DQL(Data Query Language):数据查询语句,用于对数据进行查询,如select;
DML(Data Manipulation Language):数据操作语句,用于对数据进行增加、修改、删除,如insert、update、delete;
TPL:(Transaction Control Language):事务处理语句,用于对事务的处理,包括begin transaction、commit、rollback;
DCL:(Data Control Language):数据控制语句,用于进行授权与权限回收,如grant、revoke;
DDL:(Data Definition Language):用于进行数据库、表的管理等,如creat、drop;
CCL:(Cursor Control Language):指针控制语句,用于通过控制指针完成表的操作,如decalre cursor。
查询
查询SELECT
基本语法:SELECT 列名称 FROM 表名称
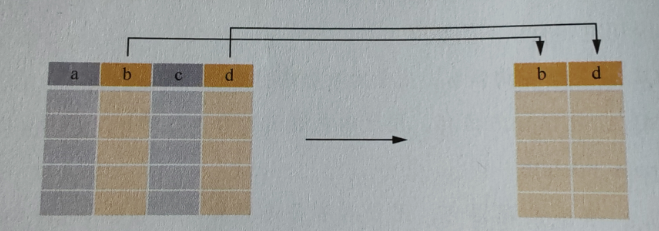
例如:
SELECT LastName, FirstName FROM Persons (查询两列数据)
SELECT * FROM Persons (“ * ”代替所有列,用来查询表中的所有数据)
去掉重复值DISTINCT
基本语法:SELECT DISTINCT 列名称 FROM 表名称
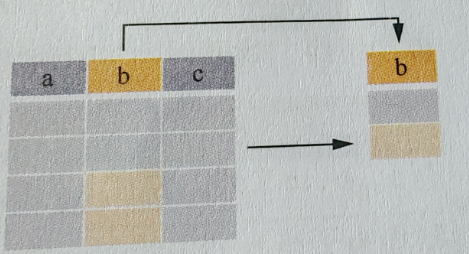
例如:
SELECT DISTINCT City FROM Persons
条件查询WHERE
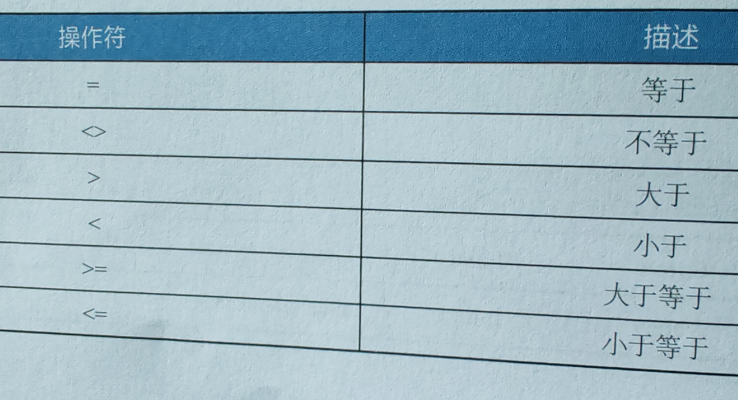
基本语法:SELECT 列名称 FROM 表名称 WHRER 列名称 运算符 值
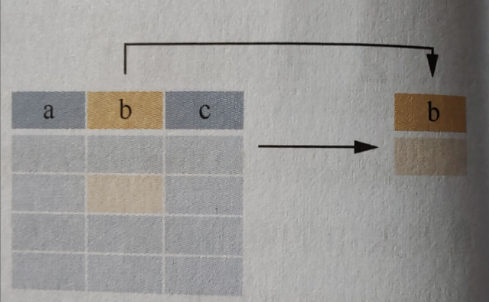
例如:
SELECT * FROM Persons
WHERE City = 'Beijing'
(文本类型添加英文格式的单引号或双引号)
SELECT * FROM Persons
WHERE Age > 29
(数值类型不需要添加引号)
运算符AND\OR
基本语法:SELECT 列名称 FROM 表名称 WHRER 条件1 AND\OR 条件2(同时满足两个条件的列\满足两个条件中的任意一个条件)
AND
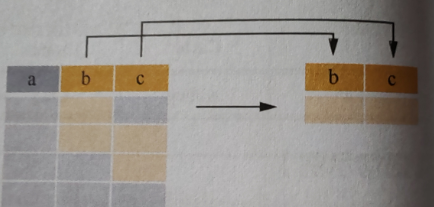
例如:
SELECT * FORM Persons WHERE City = 'Beijing' AND Age < 20
OR
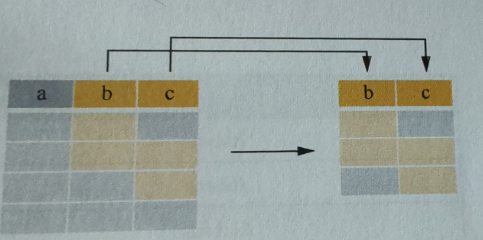
例如:
SELECT * FORM Persons WHERE City = 'Beijing' OR Age < 20
排序ORDER BY
基本语法:SELECT 列名称 FROM 表名称 ORDER BY 列名称 ASC\DESC (升序/降序)
例如:
SELECT LastName, Age FROM Persons
ORDER BY LastName, Age DESC
(LastName列按升序排序可省略,Age列按降序排序不可省略)
模糊查询LIKE
基本语法:SELECT 列名称 FROM 表名称 WHERE 列名称 LIKE 指定模式(%表示多个字符/_表示单个字符)
例如:
SELECT City FROM Persons
WHERE City LIKE 'B%'
(B%以B开头的任意字符串,%B表示以B结尾的任意字符串,%B%表示中间含B的所有字符串)
指定范围查询BETWEEN AND
基本语法:SELECT 列名称 FROM 表名称 WHRER 列名称 BETWEEN 值 AND 值
例如:
SELECT * FROM Persons
WHERE Age BETWEEN 18 AND 30
提取数据LIMIT
表示提取表格前若干行,一般用在ORDER BY 之后,用来提取表格排序后的前几行
基本语法:SELECT * FROM 表名 ORDER BY 列名 DESC LIMIT 数值
例如:
SELECT * FROM Ord
ORDER BY Ord_Price DESC
LIMIT 1
连接查询JOIN
基本语法:SELECT * FROM 表1 LEFT/RIGHT/INNER JOIN 表2 on 表1.列名 = 表2.列名
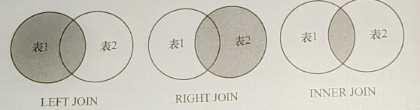
看图也可知
左连接,保留左表内容,右表去对应
右连接,保留右表内容,左表去对应
内连接,保留左右表公共部分(除了用INNER JOIN,还可用WHERE)
子查询SELECT(SELECT)
套娃,一个SELECT语句中嵌入了另一个SELECT语句,辅助主查询,可以充当条件也可以作为数据源
标量子查询(返回一行一列)
例如:
SELECT * FROM Student
WHERE Age > (SELECT AVG(Age) FROM Student)
列子查询(返回一列多行)
例如:
SELECT Name FROM Student
WHERE Id IN (SELECT Id FROM Score)
(IN表示在指定范围内,NOT IN相反)
行子查询(返回一行多列)
例如:
SELECT * FROM Student
WHERE Age = (SELECT MAX(Age) FROM Student)
操作
新增数据INSERT INTO
增加行数据
基本语法:INSERT INTO 表名称 VALUES (值1,值2,···)
例如:
INSERT INTO Persons VALUES (5,'Eric','Tom','Fanshen Road','Shenzhen',23)
增加列数据
基本语法:INSERT INTO 表名称 (列1,列2,···) VALUES (值1,值2,···)
例如:
INSERT INTO Persons (LastName,ShenZhen) VALUES ('Eric','ShenZhen')
修改数据UPDATE SET
基本语法:UPDATE 表名称 SET 列名称 = 新值 WHERE 列名称 = 某值
例如:
UPDATE Persons SET City = 'ShenZhen',Age=15
WHERE LastName = 'Abbey'
删除数据DELETE
基本语法:DELETE FROM 表名称 WHERE 列名称 = 值
例如:
DELETE FROM Persons WHERE City = 'Beijing'
聚合函数
计算行数COUNT()
COUNT(*)计算总行数与COUNT(1)的结果相同,COUNT(列名)不统计NULL所在的行
例如:
SELECT COUNT(*) AS 总人数 FROM Score
(AS是重命名,后面跟随名称,可省略AS)
求最大值MAX()
MAX(列名)表示求此列的最大值
例如:
SELECT MAX(MATH) AS 数学最高得分 FROM Score
求最小值MIN()
MIN(列名)表示求此列的最小值
例如:
SELECT MIN(Chinese) AS 语文最低得分 FROM Score
求和SUM()
SUM(列名)表示求此列的和
SELECT SUM(*) AS 英语总成绩 FROM Score
求平均值AVG()
AVG(列名)表示求此列的平均值
例如:
SELECT AVG(English) AS 英语平均成绩 FROM Score
数据分组GROUP BY
常与聚合函数一起使用,表示对分组后的数据进行计算。
基本语法:SELECT 列名,聚合函数 (列名 2) FROM 表明 GROUP BY 列名 1
例如:
SELECT Customer, SUM(Ord_Price) AS 总价格 FROM Ord
GROUP BY Customer
分组后按条件查询HAVING
类似与WHERE,但WHERE无法与聚合函数一起使用,而HAVING可以。
基本语法:SELECT 列名1,聚合函数(列名2)FROM 表名 GROUP BY 列名1 HAVING 聚合函数 (列名2) 运算符 值
例如:
SELECT Customer,SUM(Ord_Price) AS 总价格 FROM Ord
GROUP BY Customer
HAVING SUM(Ord_Price) >= 2000
窗口函数
对数据排名RANK()
按照列排名(ORDER BY,在窗口内按指定列排序)
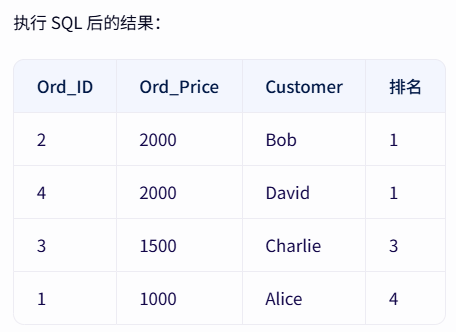
名次重复时保留名次空缺
RANK:并列排名,后续跳号,若两行并列第 2,下一名是第 4
基本语法:SELECT RANK() OVER(ORDER BY 列名) FROM 表名
例如:
SELECT *,RANK() OVER(ORDER BY Ord_Price DESC) 排名 FROM Ord
名词重复时合并名次
DENSE_RANK:并列排名,后续不跳号,若两行并列第 2,下一名是第 3
基本语法:SELECT DENSE_RANK() OVER(ORDER BY 列名 ) FROM 表名
例如:
SELECT *, DENSE_RANK() OVER(ORDER BY Ord_Price DESC) 排名 FROM Ord
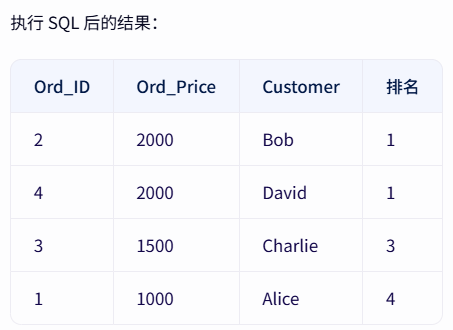
按照分组排序(PARPATITON BY,将数据分成多个分区,窗口函数在每个分区内独立计算)
名次有重复值
基本语法:SELECT RANK() OVER(PARTITION BY 列名 ORDER BY 列名) 排名 FROM Ord
例如:
SELECT RANK() OVER(PARTITION BY Customer ORDER BY Ord_Price DESC) 排名 FROM Ord
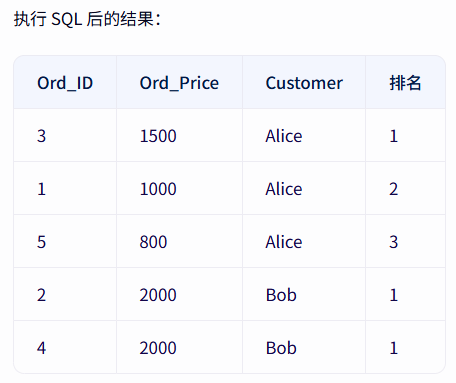
名次没有重复值
基本语法:SELECT ROW_NUMBER() OVER(PARTITON BY 列名 ORDER BY 列名) FROM 表名
例如:
SELECT *,ROW_NUMBER() OVER(PARTITION BY Customer ORDER BY Ord_Price DESC) 排名 FROM Ord
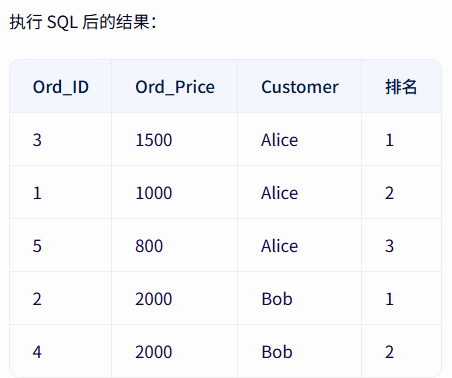
- 需要唯一序号 →
ROW_NUMBER() - 需要保留并列排名 →
RANK()或DENSE_RANK()
窗口函数与聚合函数
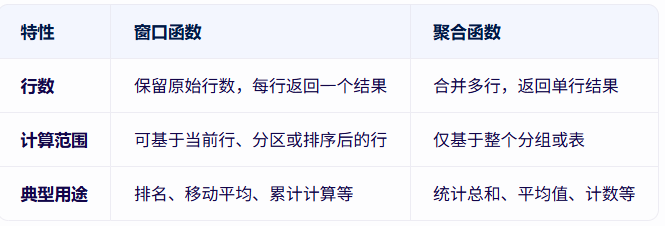
窗口函数(Window Function)是 SQL 中一种强大的分析工具,它允许你在不减少行数的前提下,对一组行(称为“窗口”)进行计算和分析。与传统的聚合函数不同,窗口函数不会将多行合并为一行,而是为每一行返回一个计算结果,同时保留原始数据的完整性。
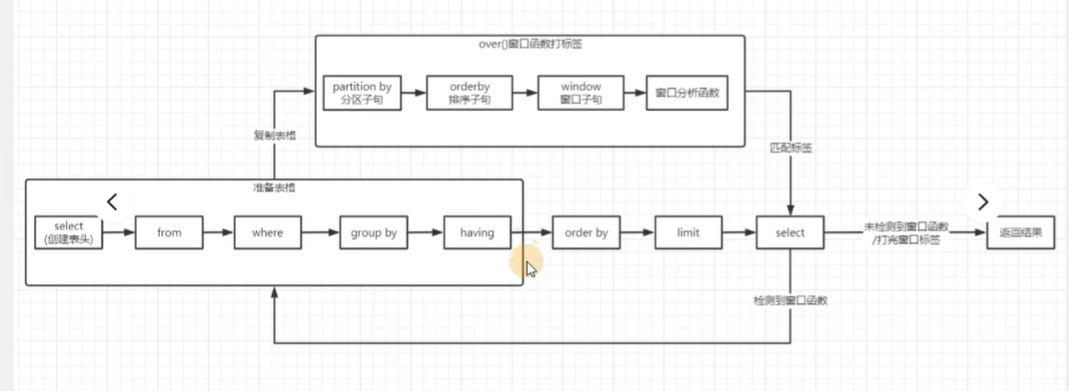
流程函数
CASE函数
1.简单CASE函数
基本语法:CASE 列名 WHEN 条件值1 THEN 表达式1 ...... ELSE 默认值 END
例如:
SELECT Id,
MAX(CASE Subject WHEN 'English' THEN Score ELSE 0 END) English,
MAX(CASE Subject WHEN 'Math' THEN Score ELSE 0 END) Math,
MAX(CASE Subject WHEN 'Chinese' THEN Score ELSE 0 END) Chinese,
AVG(Score) 平均分 FROM Sc
GROUP BY Id
ORDER BY 平均分 DESC
2.搜索CASE函数
基本语法:CASE WHEN 列名 = 条件值1 THEN 选择项 1......ELSE 默认值 END
例如:
SELECT Subject,
SUM(CASE WHEN Score >= 60 THEN 1 ELSE 0 END)/COUNT(*) AS 及格率,
SUM(CASE WHEN Score >= 70 AND Score < 80 THEN 1 ELSE 0 END)/COUNT(*) AS 中等率,
SUM(CASE WHEN Score >= 80 AND Score < 90 THEN 1 ELSE 0 END)/COUNT(*) AS 优良率,
SUM(CASE WHEN Score >= 90 THEN 1 ELSE 0 END)/COUNT(*) AS 优秀率
FROM Sc
GROUP BY Subject
日期函数
提取时间DATE_FORMAT
基本语法:DATE_FORMAT( 时间 ,'%Y%m%d')
一般的时间输出格式:

例如:
SELECT * FROM StudentWHERE WEEK(DATE_FORMAT(NOW(),'%Y%m%d'))= WEEK (Birth)
NOW()获取当前日期和时间,WEEK()获取给定日期的周数
天数差DATEDIFF
基本语法:DATEDIFF( 时间1,时间2)
例如:
SELECT DATEDIFF('2018-03-22 09 :00:00','2018-03-20 07:00:00') AS 相差天数
精确差TIMESTAMPDIFF
基本语法:TIMESTAMPDIFF( 时间格式,靠前的时间,靠后的时间 )
例如:
SELECT Id, Name,
TIMESTAMPDIFF(YEAR, Birth, CURDATE()) - (DATE_FORMAT(CURDATE(), '%m%d') < DATE_FORMAT(Birth, '%m%d')) AS Age
FROM Student
比较那里,若小于,则返回1,否则返回0
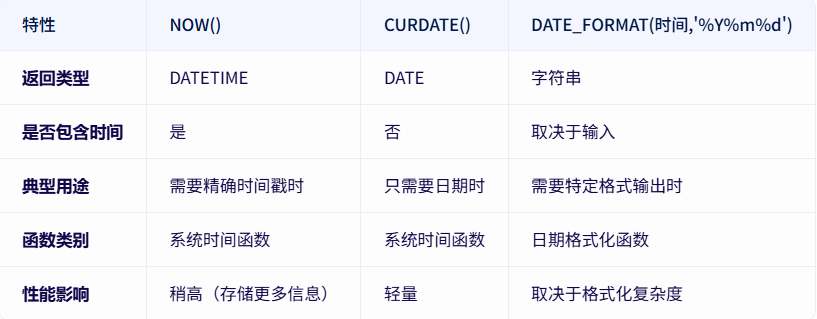
获取当前日期CURDATE
时间格式是年月日,用法已在上个例子中演示。
与NOW()、DATE_FORMAT(时间,'%Y%m%d')的区别:
书写顺序与执行顺序

更加详细看OneNote