TenstoRT加速YOLOv11——python端加速
前言
本文介绍python语言下使用TenstoRT加速YOLOv11推理
如果你是新手,请结合TenstoRT加速YOLOv11——安装CUND和CUDNN-CSDN博客
一.下载TensorRT
下载地址: TensorRT 10.x Download | NVIDIA Developer
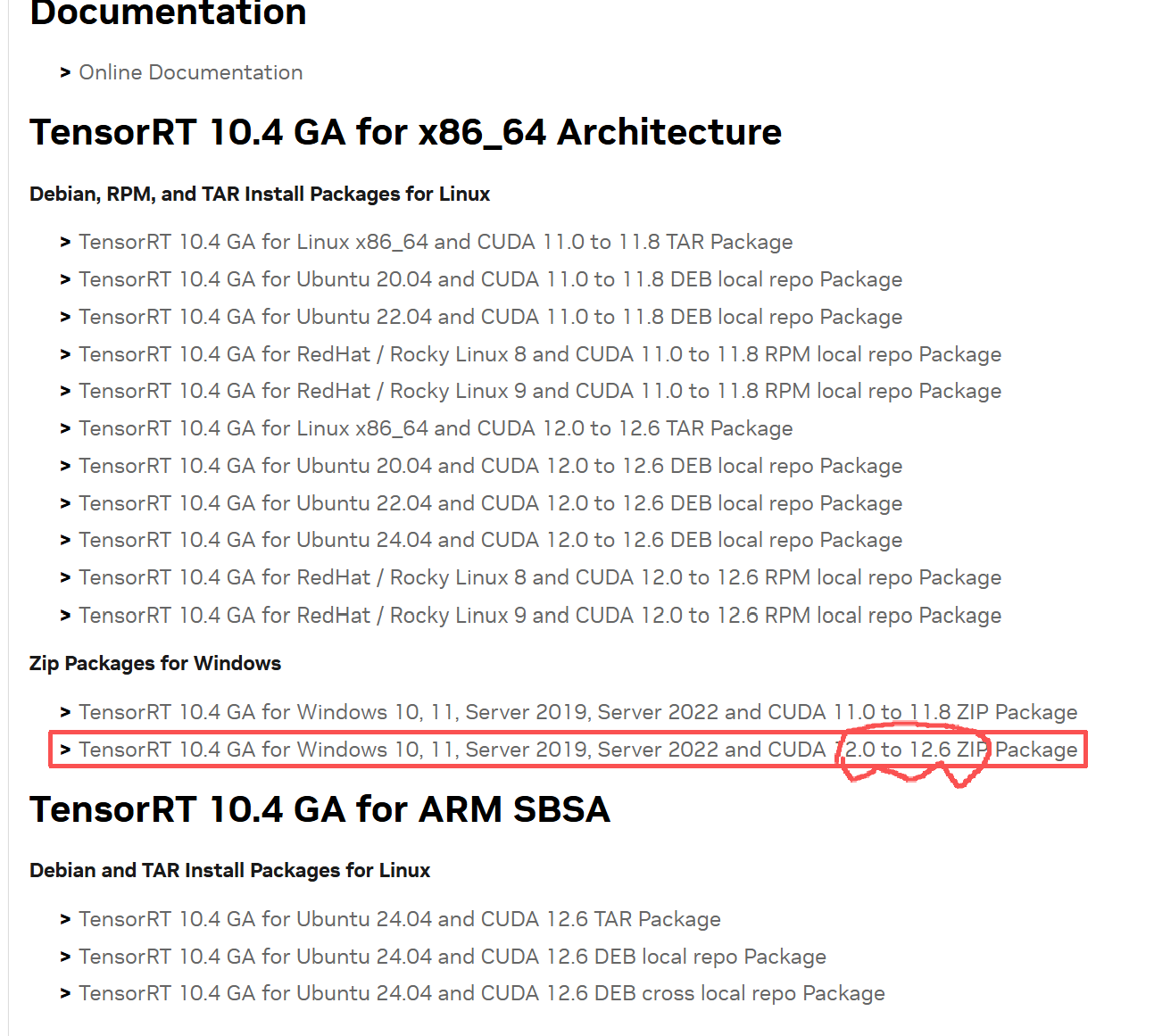
注意支持的CUDA版本,要对应
下载之后解压
二.将TenstoRT配置到YOLOv11环境中
点开python文件夹
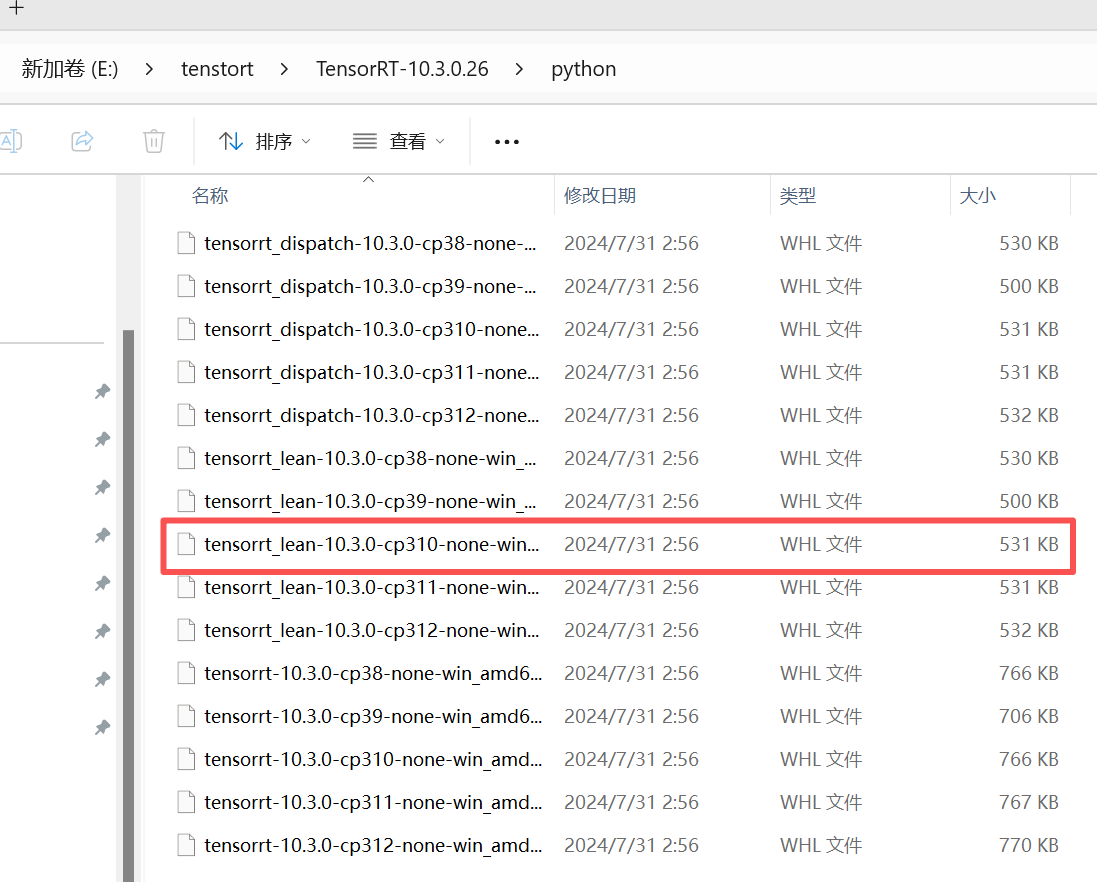
注意这里cp-310代表python的版本3.10,你要看看自己yolo环境中的python版本。
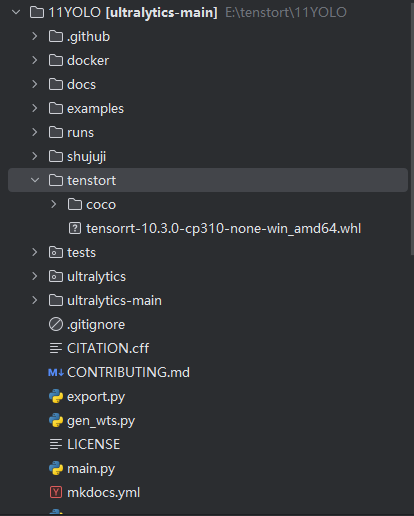
我们复制过来将文件
cd到文件夹下进行下载

没有报错就安装好了
import torch
from ultralytics import YOLO# 1. 加载 YOLOv11 的 pt 模型
model = YOLO(r"D:\yolov5-project\11YOLO\ultralytics-main\yolo11n.pt") # 你的权重文件路径# 2. 导出成 ONNX 格式
model.export(format="engine", # 导出为 ONNXopset=12, # ONNX opset 版本(12 或更高)dynamic=True, # 动态输入尺寸simplify=True # 尝试简化 ONNX 图)print("✅ YOLOv11 已成功导出为 ONNX 文件!")
这段代码是pt文件转为tensorrt所需的engine文件,填入pt文件,生成的engine文件会与pt文件在一个路径下。

将权重放入检测的代码就可以推理啦。
import cv2
import os
from ultralytics import YOLO# 加载 YOLOv8 模型
model = YOLO(r'E:\tenstort\11YOLO\yolo11n.engine') # 请根据需要选择不同的模型# 输入图片、视频文件或摄像头
input_source = r"0" # 输入图片路径、视频路径,或0(摄像头)# 指定保存结果的文件夹
output_folder = r"D:\yolov5-project\11YOLO\runs\detect"
os.makedirs(output_folder, exist_ok=True)# 判断输入源类型:图片、视频、摄像头
if input_source.lower().endswith(('.jpg', '.jpeg', '.png', '.bmp', '.tiff')):# 输入是图片image = cv2.imread(input_source)results = model(image)# 绘制结果annotated_frame = results[0].plot() # 绘制检测框output_image_path = os.path.join(output_folder, "result_imag e.jpg")cv2.imwrite(output_image_path, annotated_frame) # 保存检测结果# 显示结果cv2.imshow('YOLOv11 Detection', annotated_frame)cv2.waitKey(0)cv2.destroyAllWindows()elif input_source.isdigit() or input_source == "0":# 输入是摄像头(0为默认摄像头)cap = cv2.VideoCapture(0) # 使用摄像头while cap.isOpened():ret, frame = cap.read()if not ret:break# 使用模型进行推理results = model(frame)# 绘制结果annotated_frame = results[0].plot() # 绘制检测框# 显示结果cv2.imshow('YOLOv11 Detection', annotated_frame)# 按 'q' 键退出if cv2.waitKey(1) & 0xFF == ord('q'):break# 释放资源cap.release()cv2.destroyAllWindows()else:# 输入是视频文件cap = cv2.VideoCapture(input_source)video_name = os.path.basename(input_source).split('.')[0]output_video_path = os.path.join(output_folder, f"{video_name}_result.mp4")# 获取视频的宽度、高度和帧率fps = cap.get(cv2.CAP_PROP_FPS)width = int(cap.get(cv2.CAP_PROP_FRAME_WIDTH))height = int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT))# 设置视频编写器fourcc = cv2.VideoWriter_fourcc(*'mp4v') # 使用mp4格式out = cv2.VideoWriter(output_video_path, fourcc, fps, (width, height))while cap.isOpened():ret, frame = cap.read()if not ret:break# 使用模型进行推理results = model(frame)# 绘制结果annotated_frame = results[0].plot() # 绘制检测框# 写入处理后的帧到输出视频out.write(annotated_frame)# 显示结果cv2.imshow('YOLOv11 Detection', annotated_frame)# 按 'q' 键退出if cv2.waitKey(1) & 0xFF == ord('q'):break# 释放资源cap.release()out.release()cv2.destroyAllWindows()# 输出保存路径
print(f"Results saved to: {output_folder}")