PyTorch 中 AlexNet 的构建与核心技术解析
在深度学习的发展历程中,AlexNet 无疑是具有里程碑意义的模型。2012 年,它以高出第二名 10 多个百分点的准确率斩获 ImageNet 分类任务冠军,一举开创了卷积神经网络的新时代。今天,我们就来深入剖析在 PyTorch 中如何构建 AlexNet,并解读其核心技术特点。
一、AlexNet 的历史地位与核心价值
在 AlexNet 出现之前,卷积神经网络虽有理论基础,但受限于计算资源和训练技巧,并未在大规模图像分类任务中展现出统治力。AlexNet 的横空出世,不仅证明了深度卷积神经网络在复杂视觉任务上的强大能力,更带来了一系列创新技术,为后续的 VGG、ResNet 等经典模型奠定了基础,推动了深度学习在计算机视觉领域的爆发式发展。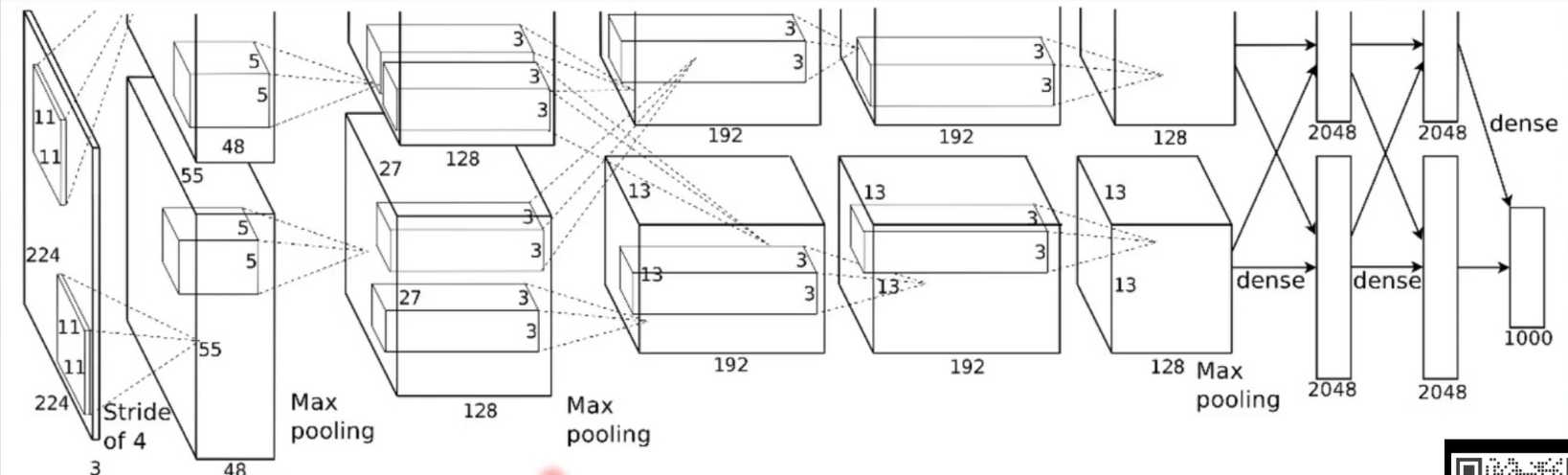
二、PyTorch 中 AlexNet 的构建
下面我们通过 PyTorch 代码来构建 AlexNet,感受其网络结构的设计思路。
在整个前向传播的过程中可以分成features+classifier此处构建AlexNet用的是nn.Sequential:按顺序封装网络层具体可以看此链接,介绍了Pytorch容器类。https://blog.csdn.net/sweet_ran/article/details/151896071?fromshare=blogdetail&sharetype=blogdetail&sharerId=151896071&sharerefer=PC&sharesource=sweet_ran&sharefrom=from_link![]() https://blog.csdn.net/sweet_ran/article/details/151896071?fromshare=blogdetail&sharetype=blogdetail&sharerId=151896071&sharerefer=PC&sharesource=sweet_ran&sharefrom=from_link
https://blog.csdn.net/sweet_ran/article/details/151896071?fromshare=blogdetail&sharetype=blogdetail&sharerId=151896071&sharerefer=PC&sharesource=sweet_ran&sharefrom=from_link
import torch
import torch.nn as nn
import torch.nn.functional as Fclass AlexNet(nn.Module):def __init__(self, num_classes=1000):super(AlexNet, self).__init__()# 特征提取部分self.features = nn.Sequential(# 第一层卷积:输入通道3(RGB图像),输出通道64,卷积核大小11×11,步长4,填充2nn.Conv2d(3, 64, kernel_size=11, stride=4, padding=2),nn.ReLU(inplace=True), # 采用ReLU激活函数,减轻梯度消失# 第一层池化:最大池化,核大小3×3,步长2nn.MaxPool2d(kernel_size=3, stride=2),# 局部响应归一化,对数据归一化,减轻梯度消失nn.LocalResponseNorm(5),# 第二层卷积:输入通道64,输出通道192,卷积核大小5×5,填充2nn.Conv2d(64, 192, kernel_size=5, padding=2),nn.ReLU(inplace=True),nn.MaxPool2d(kernel_size=3, stride=2),nn.LocalResponseNorm(5),# 第三层卷积:输入通道192,输出通道384,卷积核大小3×3,填充1nn.Conv2d(192, 384, kernel_size=3, padding=1),nn.ReLU(inplace=True),# 第四层卷积:输入通道384,输出通道256,卷积核大小3×3,填充1nn.Conv2d(384, 256, kernel_size=3, padding=1),nn.ReLU(inplace=True),# 第五层卷积:输入通道256,输出通道256,卷积核大小3×3,填充1nn.Conv2d(256, 256, kernel_size=3, padding=1),nn.ReLU(inplace=True),nn.MaxPool2d(kernel_size=3, stride=2),nn.LocalResponseNorm(5),)# 分类器部分self.classifier = nn.Sequential(# Dropout,提高全连接层的鲁棒性,增加网络泛化能力nn.Dropout(),# 第一层全连接nn.Linear(256 * 6 * 6, 4096),nn.ReLU(inplace=True),nn.Dropout(),# 第二层全连接nn.Linear(4096, 4096),nn.ReLU(inplace=True),# 输出层,对应分类类别数nn.Linear(4096, num_classes),)def forward(self, x):# 特征提取x = self.features(x)# 展平,以便输入全连接层x = torch.flatten(x, 1)# 分类x = self.classifier(x)return x三、AlexNet 核心技术特点解析
1. 采用 ReLU 激活函数
在 AlexNet 之前,Sigmoid 和 Tanh 等饱和激活函数较为常用。但饱和激活函数存在梯度消失的问题,当输入值较大或较小时,梯度会趋近于 0,导致网络深层的参数难以更新。而 ReLU(Rectified Linear Unit)激活函数为max(0, x),在输入为正的时候,梯度为 1,有效减轻了梯度消失问题,使得深层网络的训练成为可能。在代码中,我们可以看到多处使用了nn.ReLU(inplace=True),inplace=True表示直接在原张量上进行操作,节省内存。
2. 采用 LRN(Local Response Normalization)
局部响应归一化(LRN)的作用是对数据进行归一化,进一步减轻梯度消失。它模拟了生物神经系统的 “侧抑制” 机制,对局部神经元的活动创建竞争环境,使得其中响应比较大的值变得相对更大,从而增强模型的泛化能力。在代码中,nn.LocalResponseNorm(5)实现了这一功能,参数5表示归一化的窗口大小。不过,后续的研究发现,Batch Normalization(BN)在效果上往往优于 LRN,所以在现代的一些网络中,LRN 使用得越来越少,但在 AlexNet 所处的时代,LRN 是一项重要的创新。
3. Dropout 技术
Dropout 是一种有效的正则化手段,它在训练过程中随机将一部分神经元的输出置为 0。这样做可以提高全连接层的鲁棒性,因为网络不会过度依赖某些特定的神经元,从而增加了网络的泛化能力,减少过拟合。在 AlexNet 的分类器部分,我们可以看到nn.Dropout()的使用,它随机丢弃部分神经元,迫使网络学习更鲁棒的特征。
4. 数据增强(Data Augmentation)
为了缓解过拟合,增加训练数据的多样性,AlexNet 采用了数据增强技术。比如 TenCrop,即对图像进行十种不同的裁剪(中心裁剪以及四个角的裁剪,再加上它们的水平翻转),然后对这十张裁剪后的图像进行预测,取平均结果。此外,还进行了色彩修改,如调整图像的亮度、对比度、饱和度等。虽然在上述代码中没有直接体现数据增强的操作,但在实际训练 AlexNet 时,数据增强是必不可少的步骤,PyTorch 的torchvision.transforms模块提供了丰富的数据增强工具来实现这些操作。
四、总结
AlexNet 作为深度学习发展史上的经典模型,其创新的技术点为后续的网络设计提供了重要的借鉴。在 PyTorch 中,我们可以通过简洁的代码构建出 AlexNet,体会其结构设计的精妙之处。从 ReLU 激活函数解决梯度消失,到 LRN 的局部归一化,再到 Dropout 的正则化以及数据增强技术,这些都共同促成了 AlexNet 在 ImageNet 竞赛中的辉煌成绩,也为卷积神经网络的发展拉开了新的序幕。