大模型微调之 用LoRA微调Llama2(附代码)——李宏毅2025大模型作业5笔记-上
目录
一、LoRA原理 & 为什么要用LoRA
1)LoRA(Low-Rank Adaptation)原理
2)为什么要用LoRA
二、LoRA的参数含义
1)LoRA Rank
2)LoRA Alpha
三、代码(模型选型 + 源代码说明)
1)加载环境
2)加载预训练模型
3)不同参数解读
4)参数r调整前后结果
一、LoRA原理 & 为什么要用LoRA
1)LoRA(Low-Rank Adaptation)原理
在原始权重矩阵基础上,添加两个低秩矩阵 A 和 B。不再学习尺寸为 d×d 的完整权重更新矩阵 ΔW,而是学习尺寸为 d×r 和 r×d(其中 r≪d,r 为矩阵的秩)的两个更小矩阵。且仅训练 A 和 B 这两个矩阵,最终新权重:
训练时,把A初始化为
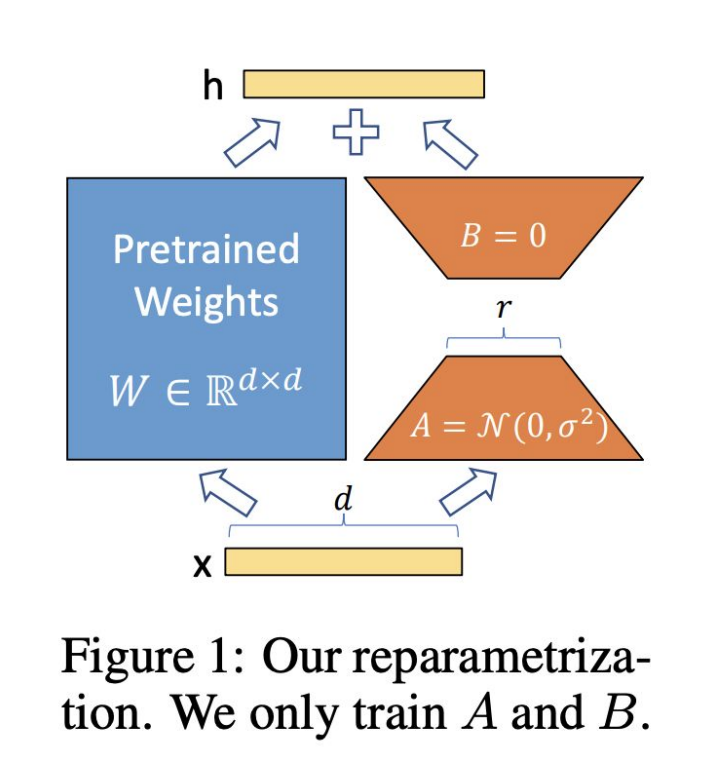
2)为什么要用LoRA
- 现代大型语言模型(LLM)有着数千亿的参数,对其进行微调的成本很高。
- LoRA 通过仅让一部分参数(即低秩矩阵 A 和 B)在训练时可学习,有效解决了大型模型微调成本高昂的问题,因此被称作参数高效微调(PEFT,Parameter-Efficient Fine-Tuning)技术。
参考论文:LoRA: Low-Rank Adaptation of Large Language Models
二、LoRA的参数含义
1)LoRA Rank
- 定义:低质矩阵的维度,决定了待更新参数的大小
- 较低的秩:参数更少,训练更快,但有欠拟合的风险。
- 较高的秩:参数更多,可能有更好的性能,但有过拟合的风险。
2)LoRA Alpha
- 低秩适应对原始权重矩阵影响的强度
- 较小的 alpha:降低 LoRA 更新的影响,防止权重发生较大变化。
- 较大的 alpha:增加更新幅度,如果模型欠拟合,可能会提高性能,但如果设置得太高,可能会过拟合或使训练不稳定。
三、代码(模型选型 + 源代码说明)
- 作业目标:对 LoRA 的超参数做小幅调整(比如 r、lora_alpha、lora_dropout、target_modules 等),以获得更好的效果或更稳的训练
- 使用的预训练模型& 模型简介:Llama-2-7b-bnb-4bit
- Llama-2-7b:基于 Meta 发布的开源大语言模型 Llama-2 的 70 亿参数版本构建,Llama-2 在自然语言处理任务中具备一定的语言理解和生成能力,如文本生成、问答、对话等。
- bnb-4bit:利用 bitsandbytes 库,将模型量化为 4bit 精度。这种量化方式大大减少了模型参数存储所需的空间,降低了运行时对显存等计算资源的需求。 相比全精度(如 16bit 或 32bit)模型,4bit 量化后的模型在推理时能够更快速地处理数据,且可以在显存较小的设备上部署运行。
- 资源:使用Google Colab 提供免费的GPU 计算资源,助教提供的代码链接(但是,这个代码链接的环境已经不能用了,跑下来会报错,可以看我接下来的代码)
假设用jupyter跑:
1)加载环境
# 安装环境,这步很重要,不然会频繁报错orz
%%capture # 不打印日志,可以注释掉,让日志打印出来
# Temporarily as of Jan 31st 2025, Colab has some issues with Pytorch
# Using pip install unsloth will take 3 minutes, whilst the below takes <1 minute:
!pip install --no-deps bitsandbytes accelerate xformers==0.0.29 peft trl==0.8.5 triton
!pip install --no-deps cut_cross_entropy
!pip install sentencepiece protobuf datasets huggingface_hub hf_transfer
!pip install unsloth==2025.2.15 unsloth_zoo==2025.2.7
!pip install transformers>=4.46.1!git clone https://github.com/ericsunkuan/ML_Spring2025_HW5.git2)加载预训练模型
model_name:指定要加载的预训练模型名称,这里是unsloth/Llama-2-7b-bnb-4bit,这是一个经过 4 位量化(bnb-4bit)的 Llama - 2 70 亿参数模型,由 Unsloth 项目提供。max_seq_length:设置模型处理的最大序列长度,决定模型能处理的文本长度上限。dtype:指定模型参数的数据类型,影响模型的精度和计算效率等。load_in_4bit:设置是否以 4 位量化的方式加载模型,4 位量化可以减少模型占用的内存和显存,加快推理速度,同时尽可能保持模型性能。token(可选):如果加载的是受 gated 限制的模型(如meta - llama/Llama - 2 - 7b - hf),需要提供对应的 Hugging Face 访问令牌。
from unsloth import FastLanguageModel
import torch# from unsloth import FastLanguageModel
# import torch
max_seq_length = 2048 # Choose any! We auto support RoPE Scaling internally!
dtype = None # None for auto detection. Float16 for Tesla T4, V100, Bfloat16 for Ampere+
load_in_4bit = False # 当设置为'True'的时候,报错太多了,含义是用4bit quantization 减少内存使用率model, tokenizer = FastLanguageModel.from_pretrained(model_name = "unsloth/Llama-2-7b-bnb-4bit", ### Do not change the model for any other models or quantization versionsmax_seq_length = max_seq_length,dtype = dtype,load_in_4bit = load_in_4bit,# token = "hf_...", # 这里可以不用huggingface的token, use one if using gated models like meta-llama/Llama-2-7b-hf
)跑出来的日志如下
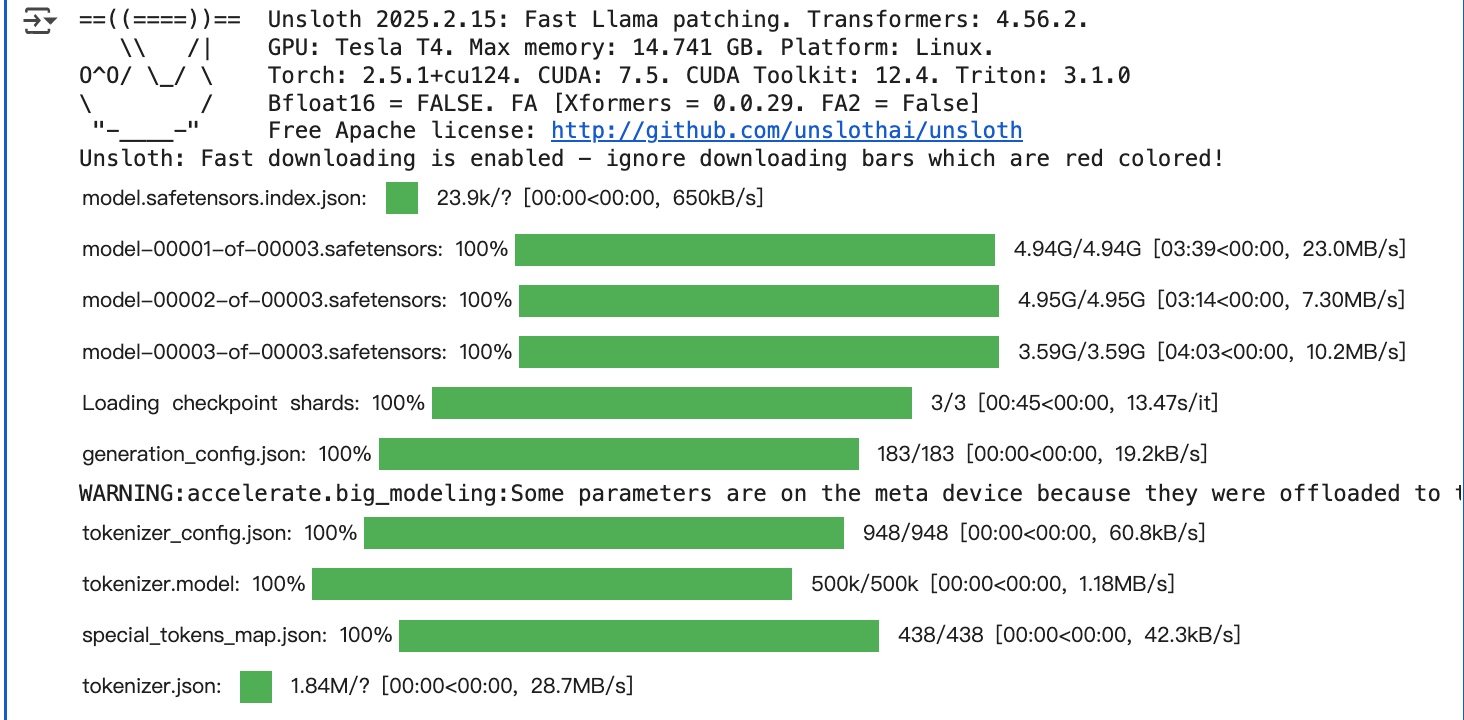 解读
解读
- 版本与环境信息:
Unsloth 2025.2.15: Fast Llama patching. Transformers: 4.56.2.:Unsloth 工具的版本是 2025.2.15,使用的 Transformers 库版本是 4.56.2,且有针对 Llama 模型的快速补丁。GPU: Tesla T4. Max memory: 14.741 GB. Platform: Linux.:运行环境的 GPU 是 Tesla T4,显存最大为 14.741GB,操作系统是 Linux。Torch: 2.5.1+cu124. CUDA: 7.5. CUDA Toolkit: 12.4. Triton: 3.1.0:PyTorch 版本是 2.5.1 + cu124(支持 CUDA),CUDA 版本相关信息以及 Triton 版本为 3.1.0,这些是深度学习计算的基础环境组件。Bfloat16 = FALSE. FA [Xformers = 0.0.29. FA2 = False]:未使用 Bfloat16 数据类型,Xformers 版本是 0.0.29,且相关的优化选项(FA、FA2)为关闭状态。Free Apache license: http://github.com/unslothai/unsloth:Unsloth 项目使用 Apache 开源许可证,提供了项目的 GitHub 地址。
- 下载与加载过程:
- 各类模型相关文件(如
model.safetensors.index.json、model - 00001 - of - 00003.safetensors等)的下载进度条,显示了文件的下载大小、速度和耗时等,表明正在从仓库下载模型的各个分片文件。 Loading checkpoint shards: 100% 3/3 [00:45<00:00, 13.47s/it]:表示正在加载模型的检查点分片,共 3 个分片,已全部加载完成,耗时约 45 秒,平均每个分片加载耗时约 13.47 秒。- 后续
generation_config.json、tokenizer_config.json、tokenizer.model、special_tokens_map.json、tokenizer.json等文件的下载进度,这些是与模型分词器(tokenizer)和生成配置相关的文件,用于模型的文本处理和生成任务设置,下载完成后模型和分词器才能正常工作。
- 各类模型相关文件(如
3)不同参数解读
代码解读:
- 利用 Unsloth 库的
get_peft_model方法来构建一个支持参数高效微调(PEFT)的模型,具体是应用 LoRA(Low-Rank Adaptation,低秩适应)技术对模型进行微调配置。下面对各参数进行详细解释 model:要进行 LoRA 微调的基础模型,这里是之前通过FastLanguageModel.from_pretrained加载的模型。r:LoRA 的秩(rank),表示用于近似权重更新的低秩矩阵的维度。注释中提到可以选择大于 0 的数值,常见值为 4、8、16、32、64、128 等。lora_alpha:LoRA 的缩放因子,用于控制低秩适应对原始权重矩阵影响的强度。
target_modules:指定要应用 LoRA 技术的目标模块。这里列出了"q_proj"(查询投影)、"k_proj"(键投影)、"v_proj"(值投影)、"o_proj"(输出投影)、"gate_proj"(门控投影)、"up_proj"(上投影)、"down_proj"(下投影)等模块,这些都是 Transformer 模型中注意力机制和前馈网络部分的关键模块,对这些模块应用 LoRA 可以bias:指定是否对偏置项进行微调。设置为"none",表示不对偏置项应用 LoRA 微调,注释也提到这是经过优化的设置。use_gradient_checkpointing:是否使用梯度检查点技术。设置为"unsloth"(也可设为True),用于处理非常长的上下文,能够在训练长序列时节省内存。random_state:随机种子,设置为 3407,用于确保实验的可重复性,使得每次运行代码时,涉及随机操作(如参数初始化等)的结果保持一致。use_rslora:是否使用秩稳定 LoRA(Rank Stabilized LoRA),这里设置为False,即不使用该特性。loftq_config:LoftQ(LoRA - based Quantization)的配置,这里设为None,表示不使用 LoftQ 量化相关的配置。- 针对性地调整模型在这些核心部分的表现。
model = FastLanguageModel.get_peft_model(model,r = 16, ### TODO : Choose any number > 0 ! Common values are 4, 8, 16, 32, 64, 128. Higher ranks allow more expressive power but also increase parameter count.lora_alpha = 16, ### TODO : Choose any number > 0 ! Suggested 4, 8, 16, 32, 64, 128target_modules = ["q_proj", "k_proj", "v_proj", "o_proj","gate_proj", "up_proj", "down_proj",],lora_dropout = 0, # Supports any, but = 0 is optimizedbias = "none", # Supports any, but = "none" is optimizeduse_gradient_checkpointing = "unsloth", # True or "unsloth" for very long contextrandom_state = 3407,use_rslora = False, # We support rank stabilized LoRAloftq_config = None, # And LoftQ
)4)参数r调整前后结果
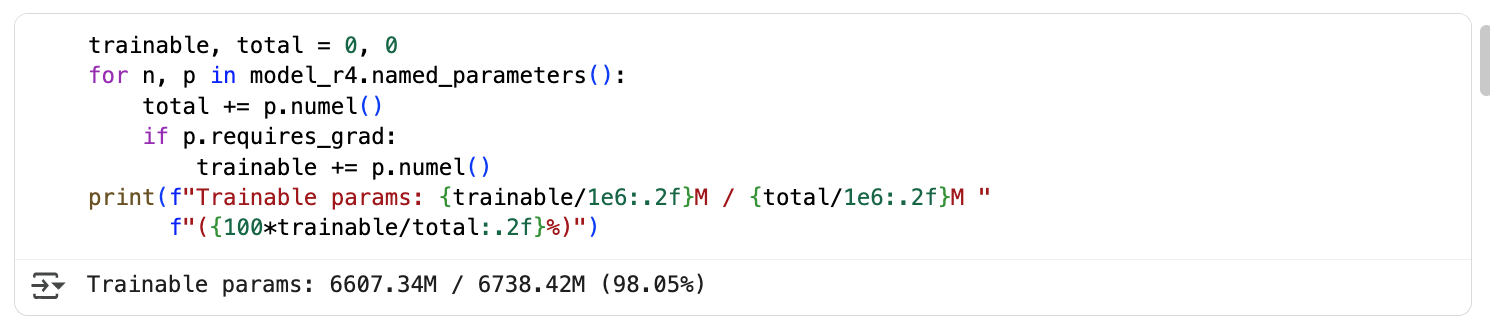
设置LoRA前,可以训练的参数为66.073亿,占总参数的98.05%
设置参数 r = 16 后,可调整参数变为3998万,占总参数的0.59%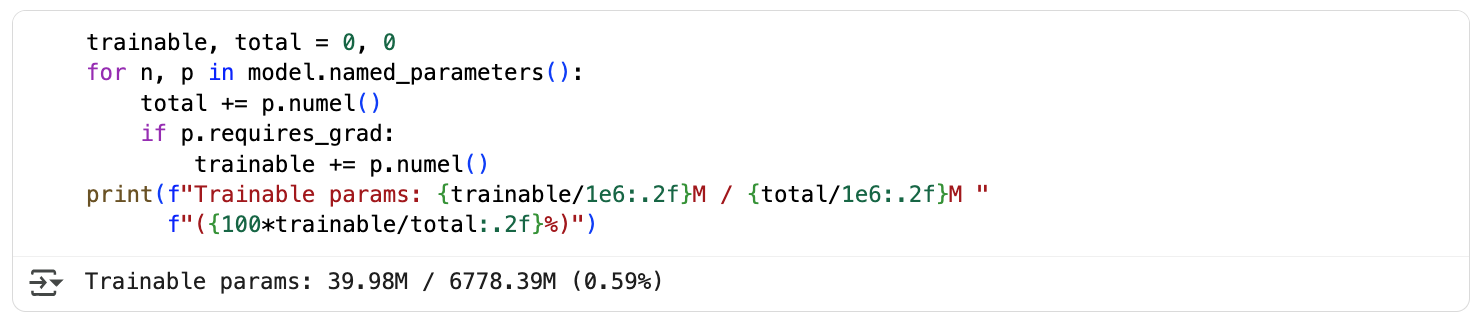
设置参数 r = 4 后,可调整参数变为999万,占总参数的0.15%,说明r越小,需要调整的参数越小

trainable, total = 0, 0
for n, p in model.named_parameters():total += p.numel()if p.requires_grad:trainable += p.numel()
print(f"Trainable params: {trainable/1e6:.2f}M / {total/1e6:.2f}M "f"({100*trainable/total:.2f}%)")