Agent记忆:Memvid、Memary、MemoryOS
概述
AI、LLM、Agent实在是太火爆,关于为LLM增加记忆能力的开源项目也层出不穷。参考Agent记忆理论与实现:Mem0、MemU、MemOS,本文继续搜集整理一些项目。
Memvid
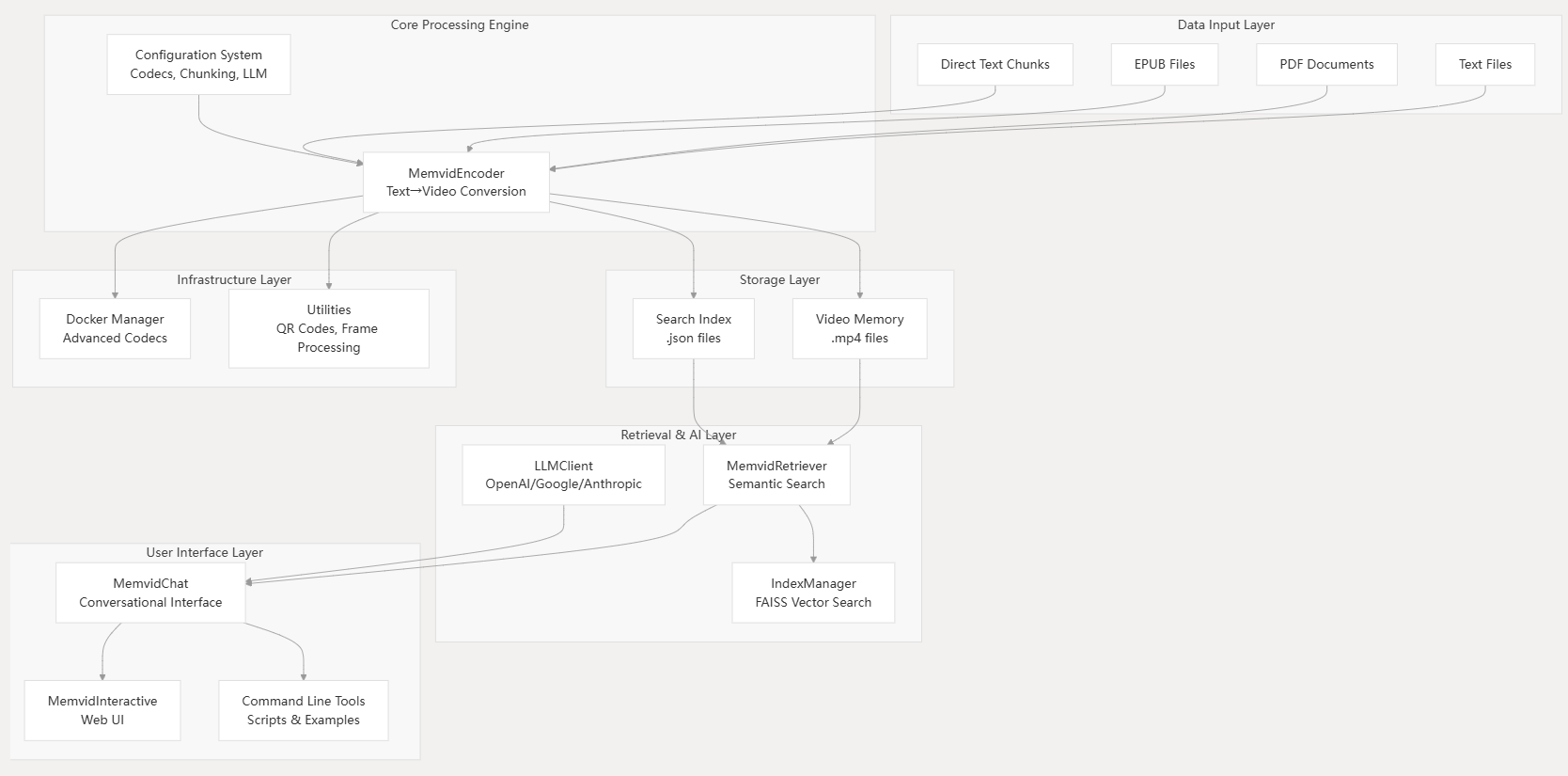
官网,开源(GitHub,8.3K Star,704 Fork),pip项目。
Memvid通过将文本数据编码成视频,革新AI记忆管理,实现对数百万文本块的闪电般语义搜索,检索时间仅需亚秒级。与传统消耗大量RAM和存储空间的向量数据库不同,Memvid将知识库压缩成紧凑的视频文件,同时保持对任何信息的即时访问。
原理:Text→QR→MP4,基于ffmpeg,能高效压缩文本,也能读取文本。
功能
- 视频数据库:将数百万个文本片段存储在一个MP4文件中
- 语义搜索:使用自然语言查询查找相关内容
- 内置聊天功能:具有上下文感知的对话界面
- 支持PDF:直接导入和索引PDF文档
- 快速检索:跨海量数据集实现亚秒级搜索
- 高效存储:与传统数据库相比压缩率提升10倍
- 可插拔LLMs:可与OpenAI或本地模型配合使用
- 离线优先:视频生成后无需互联网
- 简单API:只需3行代码即可开始使用
架构
基于视频的数据库对比向量数据库

Memary
官网,开源(GitHub,2.5K Star,182 Fork)记忆管理框架,通过模拟人类记忆的运作机制,为智能体注入持续学习和进化的能力,使其能够从每一次互动中成长,并提供更具上下文感知的个性化响应。
设计理念是,智能体的记忆应该像人类一样自动生成和更新,尽可能减少开发者手动实现。将复杂的记忆系统、知识图谱与智能体本身无缝集成,形成一个完整的认知闭环,极大地简化开发者的集成工作。
原理
Memary提供统一接口,将路由代理、知识图谱和记忆模块紧密集成到核心的ChatAgent类中。这种设计让所有核心功能高度集中,易于管理和使用。支持与多种主流模型以及图数据库(如FalkorDB)的无缝协作,让开发者可以在强大的生态系统中游刃有余。
智能体记忆系统深入到认知和知识层面:
- 记忆流与实体知识库:区分用户知识的广度(接触过的概念)和深度(熟悉的、高频的概念)。通过记忆流和实体知识库的协同工作,智能体能真正理解哪些信息对用户最重要;
- 高效知识检索:利用递归检索和多跳推理等高级技术,能够快速、精准地从庞大的知识图谱中提取信息,大大减少延迟,保证响应速度;
- 智能上下文管理:动态构建一个包含智能体响应、最相关实体和历史聊天摘要的新上下文窗口,确保每一次对话都基于对用户的深度理解和丰富的知识背景。
智能化的任务管理:内置许多自动化功能,极大提高智能体系统的鲁棒性和可维护性:
- 自动生成记忆:一旦初始化,智能体的记忆会随着每次互动自动更新。让所有记忆都能被轻松捕捉,并能方便地在仪表盘中展示;
- 用户偏好追踪:能够追踪并分析用户的偏好,并将这些信息在仪表盘上可视化,帮助开发者更好地了解用户;
- 系统自我改进:模仿人类记忆随时间演变和学习的过程,将提供智能体改进率的指标,帮助衡量其学习效果。
实战
安装:pip install memary
示例:
from memary.agent.chat_agent import ChatAgent# 配置文件
system_persona_txt = "data/system_persona.txt"
user_persona_txt = "data/user_persona.txt"
past_chat_json = "data/past_chat.json"
memory_stream_json = "data/memory_stream.json"
entity_knowledge_store_json = "data/entity_knowledge_store.json"chat_agent = ChatAgent("Personal Agent",memory_stream_json,entity_knowledge_store_json,system_persona_txt,user_persona_txt,past_chat_json,
)
query = "帮我找一下最近的咖啡馆"
response = chat_agent.query(query)
print(response)
MemoryOS
官网,开源(GitHub,718 Star,67 Fork),采用模块化架构设计,通过可插拔的存储后端和分层记忆管理机制,为AI助手提供持久化的记忆能力。
优势
- 可扩展性:模块化设计支持独立扩展,插件化存储适应不同场景需求
- 性能优化:分层存储策略、智能触发机制、并行LLM处理提升系统响应速度
- 数据隔离:用户级和助手级的数据隔离确保数据安全性
- 智能管理:基于热度的动态更新和容量管理实现资源的高效利用
架构
提供两种不同的存储策略:
文件存储版本(memoryos-pypi和memoryos-mcp)
- 存储方式:JSON文件+Faiss索引
- 数据组织:基于文件系统的目录结构
- 特点:简单直接,适合小规模数据
ChromaDB版本(memoryos-chromadb)
- 存储方式:ChromaDB向量数据库
- 数据组织:统一的向量存储和检索
- 特点:高性能向量检索,支持大规模数据
采用依赖注入模式实现可插拔存储架构:
# ChromaDB版本的存储提供者注入
class Memoryos:def __init__(self, ...):# 初始化存储提供者self.storage_provider = ChromaStorageProvider(path=data_storage_path,user_id=user_id,assistant_id=assistant_id,distance_function=distance_function)# 将存储提供者注入到各个记忆模块self.short_term_memory = ShortTermMemory(storage_provider=self.storage_provider,max_capacity=short_term_capacity)
记忆模块层次结构
职责分离:各记忆模块职责明确,ShortTermMemory负责临时存储,MidTermMemory负责会话管理,LongTermMemory负责知识沉淀
短期记忆
- 功能:存储最近的对话历史
- 特点:FIFO队列,满容量时自动转移到中期记忆;容量有限,默认10条
- 实现:使用
deque数据结构,实时检查容量状态触发处理流程
self.short_term_memory = ShortTermMemory(file_path=os.path.join(user_data_dir, "memory.json"),max_capacity=short_term_capacity
)
中期记忆
- 功能:存储经过处理的对话片段
- 特点:基于热度的管理,优先级排序;热度阈值触发长期记忆更新
- 实现:向量化存储和检索
self.mid_term_memory = MidTermMemory(file_path=os.path.join(user_data_dir, "mid_term_memory"),embedding_model_name=embedding_model_name
)
长期记忆
- 特点:基于重要性和时间的淘汰策略,向量化存储支持高效检索
- 场景:用户知识库:存储用户相关的长期知识;助手知识库:存储助手学习到的知识
self.user_long_term_memory = LongTermMemory(file_path=os.path.join(user_data_dir, "user_profiles"),embedding_model_name=embedding_model_name,max_capacity=long_term_knowledge_capacity
)
self.assistant_long_term_memory = LongTermMemory(file_path=os.path.join(assistant_data_dir, "assistant_knowledge"),embedding_model_name=embedding_model_name,max_capacity=long_term_knowledge_capacity
)
更新器(Updater)
- 职责:管理记忆的更新和转移
- 依赖:短期、中期、用户长期记忆
self.updater = Updater(short_term_memory=self.short_term_memory,mid_term_memory=self.mid_term_memory,user_long_term_memory=self.user_long_term_memory,openai_client=self.openai_client
)
检索器(Retriever)
- 职责:从各层记忆中检索相关信息
- 依赖:中期、用户长期、助手长期记忆
self.retriever = Retriever(mid_term_memory=self.mid_term_memory,user_long_term_memory=self.user_long_term_memory,assistant_long_term_memory=self.assistant_long_term_memory,retrieval_queue_capacity=retrieval_queue_capacity
)
实战
安装
pip install memoryos
# 或
git clone https://github.com/memoryos/memoryos.git
cd memoryos
pip install -e .
示例
from memoryos import Memoryosmemo = Memoryos(user_id="user123",openai_api_key="xx",data_storage_path="./memoryos_data",assistant_id="assistant",llm_model="gpt-4o-mini",short_term_capacity=20, # 短期记忆容量,默认10,适合对话mid_term_heat_threshold=3, # 热度更新阈值,默认5long_term_knowledge_capacity=500, # 长期知识容量,默认100embedding_model_name="text-embedding-3-large"
)
memo.add_memory(user_message="我喜欢喝咖啡,特别是拿铁",assistant_message="好的,我记住了您喜欢拿铁咖啡。"
)
resp = memo.get_response(user_message="推荐一些咖啡给我",assistant_message_context="根据用户的喜好推荐咖啡"
)
print(resp)
源码分析
基于memoryos.py,Memoryos类作为系统的核心入口点,采用以下设计模式:
- 门面模式:为复杂的记忆管理子系统提供统一接口
- 依赖注入:通过构造函数注入各种配置参数和依赖组件;提高模块间的解耦性和可测试性
- 模块化设计:将不同类型的记忆管理功能分离到独立模块
其构造函数包含14个参数:
- 身份标识:user_id、assistant_id
- API配置:openai_api_key、openai_base_url、llm_model
- 存储配置:data_storage_path、embedding_model_name、embedding_model_kwargs
- 记忆容量:short_term_capacity、mid_term_capacity、long_term_knowledge_capacity、retrieval_queue_capacity
- 智能触发:mid_term_heat_threshold、mid_term_similarity_threshold
智能配置机制
自适应嵌入模型配置,系统根据嵌入模型类型自动配置优化参数:
# 智能检测BGE-M3模型并自动配置FP16优化
if embedding_model_kwargs is None:if 'bge-m3' in self.embedding_model_name.lower():print("INFO: Detected bge-m3 model, defaulting embedding_model_kwargs to {'use_fp16': True}")self.embedding_model_kwargs = {'use_fp16': True}else:self.embedding_model_kwargs = {}
else:self.embedding_model_kwargs = embedding_model_kwargs
自动目录创建,系统自动创建用户和助手的数据存储目录:
# 定义用户和助手的数据存储路径
self.user_data_dir = os.path.join(self.data_storage_path, "users", self.user_id)
self.assistant_data_dir = os.path.join(self.data_storage_path, "assistants", self.assistant_id)ensure_directory_exists(user_short_term_path)
ensure_directory_exists(user_mid_term_path)
ensure_directory_exists(user_long_term_path)
ensure_directory_exists(assistant_long_term_path)
记忆添加接口
def add_memory(self, user_input: str, assistant_response: str):qa_pair = {"user_id": self.user_id, # Add user_id to qa_pair"user_input": user_input,"agent_response": agent_response,"timestamp": timestamp}self.short_term_memory.add_qa_pair(qa_pair)if self.short_term_memory.is_full():# 短期记忆处理为中期记忆self.updater.process_short_to_mid_term()# 触发智能更新self._trigger_profile_and_knowledge_update_if_needed()
响应生成接口
def get_response(self, query: str, relationship_with_user="friend", style_hint="", user_conversation_meta_data = None) -> str:"""Generates a response to the user's query, incorporating memory and context.""" # 1. Retrieve contextretrieval_results = self.retriever.retrieve_context(user_query=query,user_id=self.user_id# Using default thresholds from Retriever class for now)retrieved_pages = retrieval_results["retrieved_pages"]retrieved_user_knowledge = retrieval_results["retrieved_user_knowledge"]retrieved_assistant_knowledge = retrieval_results["retrieved_assistant_knowledge"]# 2. Get short-term historyshort_term_history = self.short_term_memory.get_all()history_text = "\n".join([f"User: {qa.get('user_input', '')}\nAssistant: {qa.get('agent_response', '')} (Time: {qa.get('timestamp', '')})"for qa in short_term_history])# 3. Format retrieved mid-term pages with dialogue chain inforetrieval_text_parts = []for p in retrieved_pages:# 获取页面的完整信息,包括meta_infopage_id = p.get('page_id', '')session_id = p.get('session_id', '')# 从JSON备份中获取meta_infometa_info = ""if page_id and session_id:full_page_info = self.storage_provider.get_page_full_info(page_id, session_id)if full_page_info:meta_info = full_page_info.get('meta_info', '')# 构建包含对话链信息的文本page_text = f"User: {p.get('user_input', '')}\nAssistant: {p.get('agent_response', '')}"if meta_info:page_text += f"\n Dialogue chain info: \n{meta_info}" retrieval_text_parts.append(page_text)retrieval_text="【Historical Memory】\n"retrieval_text += "\n\n".join(retrieval_text_parts)# 4. Get user profileuser_profile_data = self.user_long_term_memory.get_user_profile(self.user_id)user_profile_text = json.dumps(user_profile_data, indent=2, ensure_ascii=False) if user_profile_data else "No detailed profile available yet."# 5. Format retrieved user knowledgeuser_knowledge_background = ""if retrieved_user_knowledge:user_knowledge_background = "\n【Relevant User Knowledge】\n"for kn_entry in retrieved_user_knowledge:user_knowledge_background += f"- {kn_entry['text']}\n"background_context = f"【User Profile】\n{user_profile_text}\n{user_knowledge_background}"# 6. Format retrieved Assistant Knowledgeassistant_knowledge_text_for_prompt = "【Assistant Knowledge Base】\n"if retrieved_assistant_knowledge:for ak_entry in retrieved_assistant_knowledge:assistant_knowledge_text_for_prompt += f"- {ak_entry['text']}\n"else:assistant_knowledge_text_for_prompt += "- No relevant assistant knowledge found for this query.\n"# 7. Format user_conversation_meta_data (if provided)meta_data_text_for_prompt = "【Current Conversation Metadata】\n"if user_conversation_meta_data:try:meta_data_text_for_prompt += json.dumps(user_conversation_meta_data, ensure_ascii=False, indent=2)except TypeError:meta_data_text_for_prompt += str(user_conversation_meta_data)else:meta_data_text_for_prompt += "None provided for this turn."# 8. Construct Promptssystem_prompt_text = prompts.GENERATE_SYSTEM_RESPONSE_SYSTEM_PROMPT.format(relationship=relationship_with_user,assistant_knowledge_text=assistant_knowledge_text_for_prompt,meta_data_text=meta_data_text_for_prompt # Using meta_data_text placeholder for user_conversation_meta_data)user_prompt_text = prompts.GENERATE_SYSTEM_RESPONSE_USER_PROMPT.format(history_text=history_text,retrieval_text=retrieval_text,background=background_context,relationship=relationship_with_user,query=query)messages = [{"role": "system", "content": system_prompt_text},{"role": "user", "content": user_prompt_text}]# 9. Call LLM for responseresponse_content = self.client.chat_completion(model=self.llm_model, messages=messages, temperature=0.7, max_tokens=1500 # As in original main)# 10. Add this interaction to memoryself.add_memory(user_input=query, agent_response=response_content, timestamp=get_timestamp())return response_content