联邦学习论文分享:FedKTL
摘要
研究背景与挑战:
研究领域是 异构联邦学习(HtFL),即在不同客户端使用不同模型架构(如 CNN 和 ViT)的情况下进行协作训练。
主要难点是 数据异构性 和 模型异构性,导致知识迁移困难。
提出的方法:
作者提出了一种新的 高效上传的知识迁移方案 —— Federated Knowledge-Transfer-Loop (FedKTL)。
核心思路是利用一个 公开的预训练生成器(如 StyleGAN 或 Stable Diffusion) 作为桥梁。
服务器通过生成器推理得到 任务相关的“原型图像-向量对”,然后各客户端利用这些数据进行额外的监督学习任务,从而将公共知识迁移到本地模型中。
实验与结果:
在四个数据集、两类数据异构条件下,涉及 14 种不同模型(包括 CNN 和 ViT)进行验证。
结果显示 FedKTL 的性能比 7 种最新方法最高提升 7.31%。
方法还能在 云-边场景 中应用,即使只有一个边缘客户端也可用。
引言
1. 研究背景与问题
越来越多公司在开发 定制化模型,但常常受到 数据不足 的困扰(例如医疗领域)。
联邦学习(FL) 允许多方在保证隐私的前提下协作训练模型。
传统联邦学习(tFL) 训练一个共享的全局模型,但无法满足每个客户端的个性化需求。
个性化联邦学习(pFL) 试图解决这个问题,但大多数方法假设客户端模型同构(结构相同),限制了实际应用。
同时,随着模型变大,传输模型参数带来 高通信开销,也引发 隐私与知识产权泄露风险。
因此,出现了 异构联邦学习(HtFL),既考虑数据异构,也考虑模型异构。
2. 现有 HtFL 知识迁移方法的不足

大多数基于 知识蒸馏(KD),但各有缺陷:
依赖全局数据集 → 数据可用性、质量与相关性受限。
借助全局辅助模型 → 带来巨大的通信开销。
使用全局类别原型 → 信息有限,且不同模型提取的原型存在偏差,难以保证一致性。
直接用预训练生成器代替数据集 → 生成的图像通常无标签,难以满足客户端任务需求。
3. 提出的解决方案:FedKTL
作者提出 Federated Knowledge-Transfer-Loop (FedKTL),特点:
上传高效:客户端上传少量的原型,而非整个模型参数。
利用预训练生成器(如 StyleGAN/Stable Diffusion):作为知识共享的桥梁。
三大核心问题 (Q1–Q3):
Q1:如何上传无偏原型且保持高效?
用 ETF 分类器 替代客户端分类器,确保生成的原型无偏,再上传到服务器。
Q2:如何让生成器适应客户端任务而不用微调?
原型和生成器潜在空间不自然对齐 → 服务器引入 轻量级特征变换器,将原型转化为生成器可用的有效向量。
Q3:如何将生成器的知识传递给客户端模型?
服务器生成 原型诱导的图像-向量对,作为额外监督任务,增强客户端的特征提取能力,而无需保证生成图像和本地数据的强语义一致性。
4. 实验与结果
在四个数据集、两种异构场景、14 种模型架构上验证(含 CNN 与 ViT)。
使用 StyleGAN 或 Stable Diffusion 作为生成器。
结果:FedKTL 在准确率上最多比 7 种 SOTA 方法高 7.31%。
证明其 上传高效:每类只需一个“原型图像-向量对”即可完成知识迁移,且服务器端生成器推理开销极低。
相关工作
异构联邦学习
总体介绍
HtFL 的目标:
保持 隐私(不共享原始数据)、
保持 模型知识产权(IP)、
同时满足 不同客户端对模型结构的个性化需求。
分类:三种异构程度
Group heterogeneity(组异构)
客户端被分为若干组,每组内用相同的模型。
分组方式通常是从服务器的大模型里抽取子模型。
缺点:对 IP 保护和客户端个性化有限制。
本文不考虑这一类。
Partial heterogeneity(部分异构)
客户端模型的大部分结构可以不同,但有一个小部分必须相同(共享的“全局部分”)。
例子:LG-FedAvg、FedGen、FedGH。
缺点:
客户端主要模型部分(如特征提取器)得不到足够的全局知识;
数据不足问题仍然存在。
Full heterogeneity(完全异构)
客户端模型结构完全自由,不需要有相同部分。
典型方法:基于知识蒸馏(KD)。
有些方法需要一个 全局数据集,但现实中很难获得。
另一类方法(如 FML、FedKD)用 互相蒸馏,但早期阶段可能传递的是“没用的知识”。
还有方法共享 类原型(class prototypes)(如 FedDistill、FedProto、FedPCL),但在异构数据和模型下会产生 分类器偏差(classifier bias),导致全局知识聚合困难。
ETF 分类器(Equiangular Tight Frame Classifier)
背景:Neural Collapse
在平衡数据下训练到最后阶段时,会出现 神经坍塌(Neural Collapse) 现象:
特征原型(prototypes)和分类器的权重向量会收敛成 simplex ETF 结构。
ETF 的特点:向量归一化、两两夹角相等且尽可能大。
这被认为是 理想分类器的几何形态。
中心化方法中的应用
一些集中式方法(62, 63)提出:
直接用一个 随机生成的 simplex ETF 矩阵 来替代原始分类器。
用它来固定分类器,从而引导特征提取器训练,解决 类别不平衡 的问题。
联邦学习中的应用
FedETF [34]:
也用固定的 ETF 分类器替代原始分类器。
好处:减少客户端在数据异质性下产生的偏差。
但它假设客户端模型是 同构 的,并且依赖 FedAvg 进行全局知识聚合。
本文的思路
借鉴 ETF 分类器的思想:
让 异构模型 的客户端也能生成 无偏的类别原型(unbiased prototypes)。
这样在服务器端可以更好地进行 按类别的全局知识聚合。
总结
这一段主要讲:ETF 分类器在神经坍塌现象下代表理想分类器结构,被用于解决类别不平衡与数据异质性问题。FedETF 将其引入联邦学习,但只适用于同构模型;本文进一步扩展到异构模型场景,以便生成无偏原型并提升全局知识聚合。
补充
1. 普通分类器是怎么工作的?
在神经网络里,最后一层分类器通常是一个 全连接层,不同类别对应不同的权重向量(比如猫、狗、鸟各一根“指针”)。
训练目标:让输入特征和“对的类别向量”对齐,和“错的类别向量”远离。
但是在数据 不平衡 或 分布不一样 的情况下:
有些类别的向量可能特别“靠近”彼此,导致分类器更容易偏向某些类 → 分类偏差。
2. ETF 分类器的核心想法
ETF = 等角紧框架(Equiangular Tight Frame),名字很学术,但意思其实就是:
把所有类别的向量摆放成间距完全均匀的样子。
换句话说:
每个类别的向量都归一化成一样长。
类别与类别之间的角度都相等,互相“平均分散开”。
就像把几个点放在球面上,彼此尽可能“拉开距离”,形成一个对称图形(类似正三角形、正四面体、正多面体的结构)。
这样做的好处:
没有哪个类别“更近”,也没有哪个类别“更远”,保证分类器对所有类别一视同仁。
避免了因为数据不平衡、模型异质性带来的偏差。
3. 直观比喻
普通分类器:像教室里几个学生随便站,有些站得特别近,有些隔得远,容易“拉帮结派”。
ETF 分类器:老师要求大家 围成一个规则的圆圈,每个人之间的距离都一样远 → 公平、对称。
4. 应用在联邦学习里
在联邦学习(FL)中,不同客户端的数据分布可能不一样,普通分类器容易学出偏差的“类别原型”。
用 ETF 分类器,就能让不同客户端的类别向量保持一致、均匀分布。
这样服务器端聚合时更容易得到 无偏的全局知识。
方法
前提知识
1. 生成器的两大组件
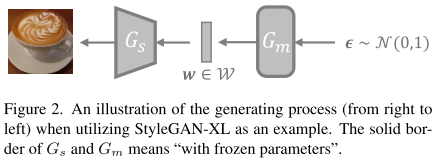
大部分 StyleGAN 系列模型 都分为两部分:
Gm(Mapping Network,映射网络):把输入的随机噪声向量 ϵ(通常是正态分布的随机数)转换成一个更“有意义”的潜在向量 w。
Gs(Synthesis Network,合成网络):把 w 转换成一张真实感很强的图像 I。
公式:
w = Gm(ϵ) → 得到潜在向量
I = Gs(w) → 生成图像
2. W 空间的概念
ϵ 最开始是在 R^H 空间里(高维随机噪声),但是并不是所有向量都能生成有意义的图。
Gm 把 ϵ 映射到一个新的空间 → W 空间。
在 W 空间 里的向量 w,才是决定生成图像内容的真正关键因素。
W 空间的向量比原始噪声空间更“整洁”、更有用,能够生成清晰且信息丰富的图像
问题陈述
场景描述
系统中有 1 个服务器 和 N 个客户端。
任务是一个 多分类问题,类别数为 C。
每个客户端 i 拥有 私有数据 Di,并基于这些数据训练一个 客户端模型 gi,模型参数记作 Wi。
每个客户端可以有 不同的模型架构(customized architecture),这就是“异构”的含义。
优化目标
客户端希望最小化 本地损失函数 Li(Wi, Di)。
全局目标是 加权平均所有客户端的损失:
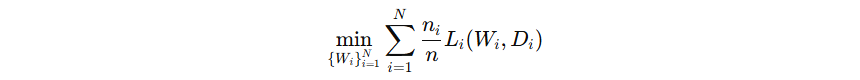
其中:
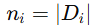 表示客户端 i 的数据量
表示客户端 i 的数据量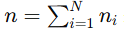 表示所有客户端数据总量
表示所有客户端数据总量加权方式是按数据量比例加权,保证数据量大的客户端对全局模型贡献更大
总结
这一段主要在讲 HtFL 的问题定义:多个客户端各自用自己的数据和模型训练本地模型,然后通过一种加权方式最小化全局损失。
核心点:客户端模型异构、数据私有、目标是全局加权损失最小化。
本文算法
概览
1. 流程概述
文本中提到 六个关键步骤,核心思路是:客户端在本地训练得到特征原型 → 上传服务器 → 服务器进行特征对齐和生成 → 返回给客户端 → 客户端再利用这些知识进行本地增强训练。
2. 六个步骤解析
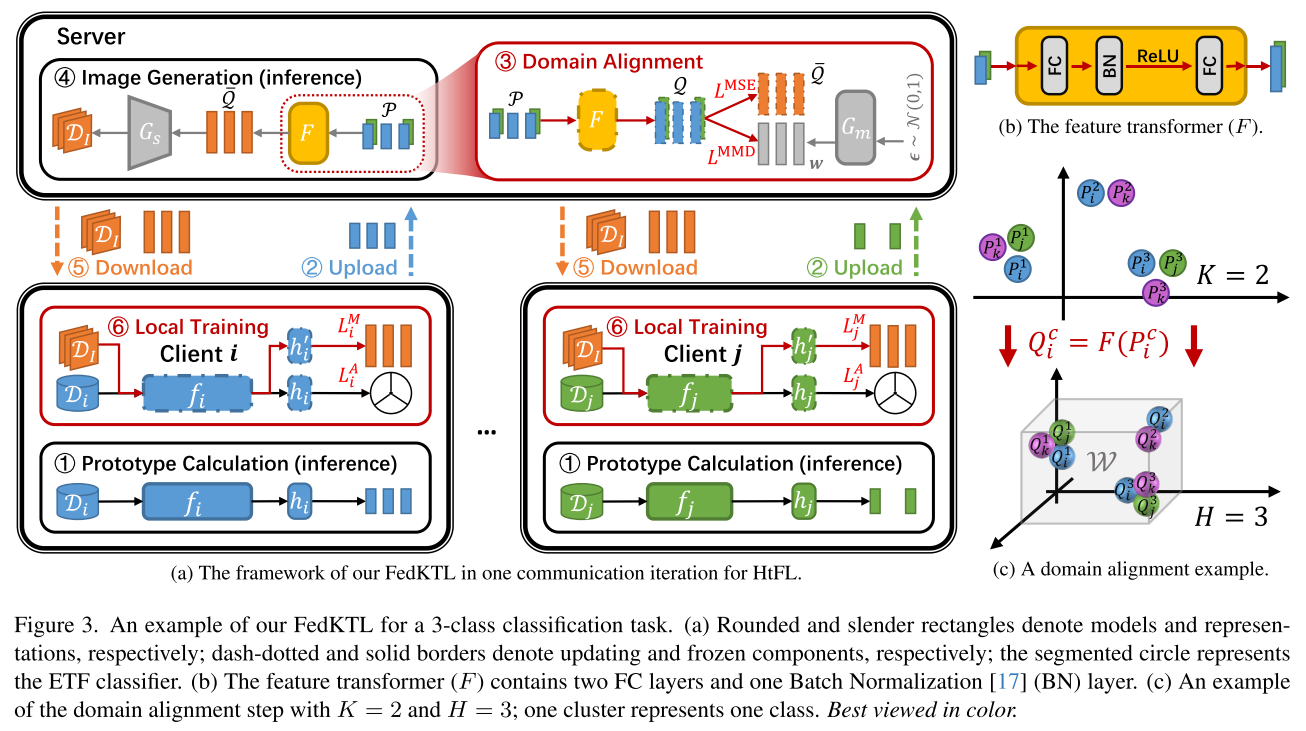
本地训练并生成类原型
每个客户端完成本地模型训练后,生成 class-wise prototypes(每个类别的特征原型)。
这些原型是每个类别的特征向量,概括了该类别的典型特征。
上传原型到服务器
每个客户端将这些类原型上传给服务器,用于全局知识整合。
服务器训练特征变换器 F
服务器训练一个 feature transformer F(参数 WF),将不同客户端的原型映射到 统一的潜在空间(latent space)。
目的是 对齐各客户端的特征分布,解决异构模型和数据分布差异的问题。
生成类中心与图像
使用训练好的 F,服务器先计算 每类的潜在向量均值 Qˉ(latent centroid)。
再将 Qˉ 输入到生成器 Gs 中,生成 原型图像 DI。
这里 Qˉ 表示特征,DI 表示生成的图像。
客户端下载原型-图像对
每个客户端从服务器获取
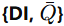 。
。注意这里
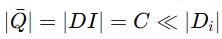 ,即每类只生成一个原型样本,数量远小于原始数据。
,即每类只生成一个原型样本,数量远小于原始数据。
客户端增强训练
客户端使用原始数据 Di 和服务器返回的原型数据 DI,Qˉ 进行 本地训练。
引入了 额外的线性投影层 hi′(参数
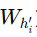 ),用于调整特征表示维度。
),用于调整特征表示维度。
3. 核心意义
知识迁移:通过类原型和生成的图像把全局知识传回客户端。
数据效率:只传输每类少量原型,而不是全部原始数据。
异构适配:特征变换器 F 对齐不同客户端的特征空间,使得异构模型也能共享知识。
联邦学习场景下的ETF分类器的用法
本地损失函数 Li 的组成
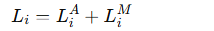
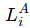 :和客户端本地数据集 DiD_iDi 相关的损失(这里重点描述)。
:和客户端本地数据集 DiD_iDi 相关的损失(这里重点描述)。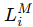 :知识迁移相关的损失(在后续章节 3.3.4 描述)。
:知识迁移相关的损失(在后续章节 3.3.4 描述)。
ETF 分类器替换原有分类器
问题:不同客户端的分类器会导致 偏置的原型 (biased prototype),影响聚合效果。
解决:借鉴 FedETF 的思路,
用 相同的 ETF 分类器 替换各模型的原始分类头。
在特征提取器后加一层 线性投影层 (FC 层),保证本地模型生成的特征能和全局 ETF 分类器对齐。
ETF 的构造
构造一个 等角紧框架 (ETF) 向量集合 V,即:
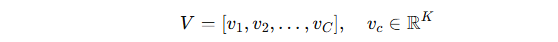
性质:
向量两两之间夹角相等(cos θ = -1/(C-1))。
向量均匀分布在空间中(等间隔地分布在球面上)。
向量单位化 (
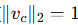 )。
)。
这样可以保证 全局分类器方向一致,不受客户端差异影响。
本地训练过程 (使用 ArcFace 损失)
对输入样本 x,用本地模型 gi(x) 计算特征,与 ETF 向量集合 V 做余弦相似度得到分类 logits。
使用 ArcFace 损失函数(在余弦相似度基础上加 margin m 和缩放因子 s)增强区分性
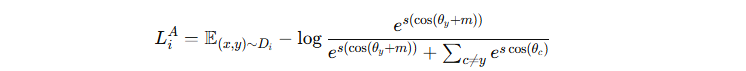
原型生成与上传
本地训练后,固定 gig_igi,为每个类别计算该类别的 原型向量 PicP^c_iPic:
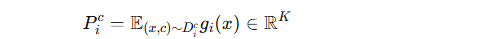
即每一类的特征中心点。
客户端上传原型集合 PiP_iPi 到服务器,而不是上传模型参数。
通信开销仅为 ∣Ci∣×K个数值,比直接上传整个模型参数小很多。
总结
为了解决联邦学习中由于数据分布不一致导致本地分类器产生“偏差原型”的问题,作者借鉴 FedETF,用全局一致的 ETF 分类器替代原有分类器,并通过 ArcFace 损失训练,使本地模型特征对齐到统一的 ETF 空间。在此空间中,每个客户端上传各类的“原型向量”而不是整个模型,从而降低通信开销并保证聚合时的一致性
补充
原型向量的定义
原型向量就是某一类样本在特征空间中的“中心点”或“代表向量”。
假设某个客户端有类别 ccc 的样本集合 Dic,每个样本经过模型的特征提取器 gi(x) 得到一个特征向量。
那么 原型向量 Pic就是这些特征向量的平均:
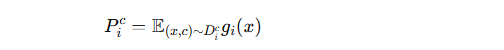
也就是说:原型向量代表了类别 c 的整体特征特征分布中心。
例子
类别 “猫” 的样本:猫 A、猫 B、猫 C
特征提取后分别是向量 (0.8, 0.2), (0.9, 0.1), (0.7, 0.3)
取平均:
P猫=(0.8,0.2)P_{\text{猫}} = (0.8, 0.2)P猫=(0.8,0.2)这就是“猫”的原型向量。
这样,模型在推理时只要比较输入样本的特征和 各类原型向量 的相似度,就能判断样本属于哪个类别。
在联邦学习中的作用
通信高效
不需要上传整个模型参数,只要上传每个类别的原型向量。
通信量从上百万参数降到几十/几百维(∣Ci∣×K|C_i|\times K∣Ci∣×K)。
解决分布不均衡
不同客户端的数据分布差异大,直接聚合模型会有偏差。
用原型向量表示类别中心,可以减少这种偏差。
知识共享
服务器聚合各客户端的原型,得到更稳健的“全局原型”。
弱客户端(数据少)也能通过全局原型提升分类能力。
原型向量转为统一潜在空间
主要内容分解
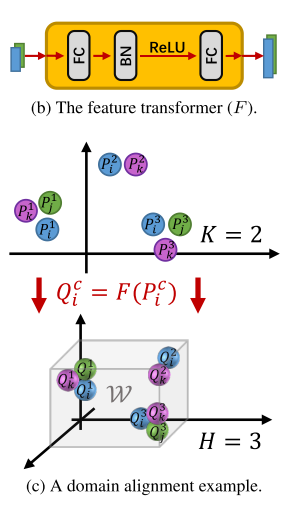
输入:客户端上传的原型集合
每个客户端上传自己的类原型 Pic。
服务器收集所有原型 P={Pic}。
训练一个特征变换器 F
目标:把原型 Pic 映射到生成模型 Gs 的潜在空间 W,得到新的向量 Qic=F(Pic)
这样保证原型能被用来驱动生成模型,生成有效图像。
两个训练目标(保持判别性 + 域对齐)
(1) 保持类间判别性
定义每个类的全局中心 Qc,即所有客户端该类的 F(Pic) 的平均。
用 MSE 损失让 F(Pic) 尽量接近全局中心 Qc,保持类别之间的可分性。
公式:
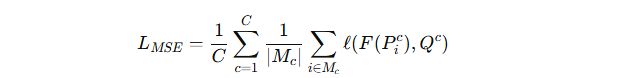
(2) 域对齐 (Domain Alignment)
用最大均值差异(MMD)损失,让 Q 的分布与生成模型潜在空间 W 的分布对齐。
公式:
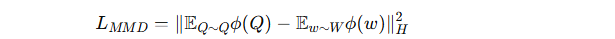
最终的服务器损失函数:
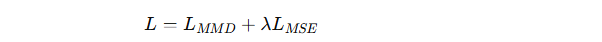
图像生成与分发
训练好 F 后,取每个类的全局中心 Qc,输入生成器 Gs。
每类生成一张合成图像 Ic=Gs(Qc)。
得到集合
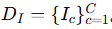
把 (Ic,Qc) 对发回各客户端,作为额外的有监督训练数据。
总结
服务器端把各客户端上传的原型向量,通过一个可训练的特征变换器 F,映射到生成模型的潜在空间,并用 MSE + MMD 损失保证类别区分性和分布对齐;然后用生成器 Gs 合成每个类别的辅助图像,分发给客户端,帮助它们在保持隐私的前提下增强本地训练。
全局知识分发给客户端
关键点分解
本地训练目标函数
![]()
LAi:客户端自己的常规训练损失(基于本地数据)。
LMi:知识迁移损失,用于吸收来自全局生成器的知识。
μ:权衡两者的超参数。
2.知识迁移损失 LMiL_M^iLMi 的定义
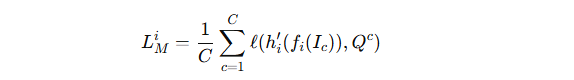
输入:服务器生成的辅助图像 Ic。
本地模型经过特征提取器 fi,再通过线性投影层 hi′。
输出与全局原型 Qc对齐。
这样,客户端学习如何从图像 Ic中提取出与全局知识一致的特征。
3.什么要引入 hi′
hi′ 是一个简单的线性层,作用是 维度变换(把 fi的特征映射到生成器的潜在空间维度 H)。
它不是用来学习知识的,所以在每轮迭代里,所有客户端的 hi′ 参数 统一初始化。
好处:
避免 hi′ 学到带偏的“私有知识”。
确保知识迁移的焦点在 fi(客户端的特征提取器)。
不增加额外的通信开销。
总结
在本地训练时,客户端除了优化自己的任务损失外,还通过一个知识迁移损失,把服务器生成的图像 Ic与全局原型 Qc 对齐,从而把全局共享知识注入到本地特征提取器中。为了防止偏差,这个过程借助一个统一初始化的线性投影层 hi′h'_ihi′ 来完成维度匹配,而不会额外增加通信负担。
隐私保护
主要内容分解
使用统一的 ETF 分类器
所有客户端用相同的 ETF 分类器生成“原型向量”。
这些原型向量只保留类别区分信息,不含用户的原始数据细节,因此不会泄露隐私。
服务器生成的图像不等于客户端原始数据

生成器输出的图片来自它自己的潜在空间,不会还原或接近客户端的本地数据分布。
所以,即便共享这些生成图像,也不会暴露用户的真实数据。
模型参数本地保存
客户端的模型权重(特别是特征提取器的参数)从不上传。
避免了参数泄露导致的反向推理攻击。
实验
实验设置
主要内容分解
数据集与对比基线方法
数据集:CIFAR10、CIFAR100、Tiny-ImageNet、Flowers102。
对比方法:7 种主流的异构联邦学习(HtFL)方法,包括 LG-FedAvg、FedGen、FedGH、FML、FedKD、FedDistill、FedProto。
模型异构性 (HtFE)
有些方法(如 LG-FedAvg, FedGen, FedGH)要求分类器相同,但 FedKTL 考虑更一般的“特征提取器异构”。
定义 HtFEX:表示异构程度,用 X 种不同的模型架构分配给 N 个客户端。
默认实验使用 HtFE8,包含 8 种模型:4-layer CNN、GoogleNet、MobileNet v2、ResNet18/34/50/101/152。
这些模型的特征维度不同,统一通过加平均池化层,输出固定维度 K′=512K'=512K′=512。
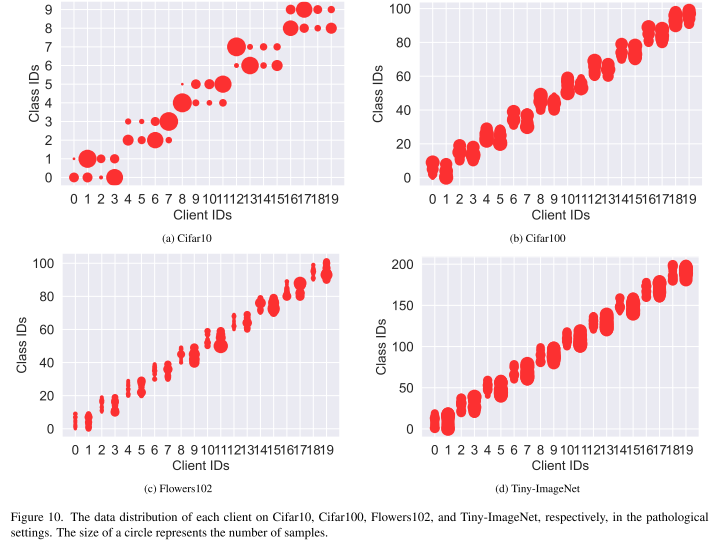
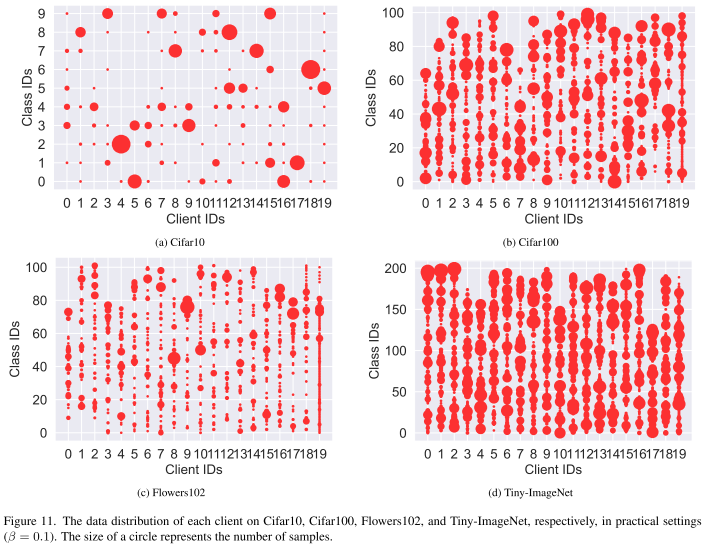
数据异构性
病态设定 (pathological setting):每个客户端分到不平衡的不同类别子集(如 CIFAR10 分配 2/10/10/20 类)。
实际设定 (practical setting):按照 Dirichlet 分布(β=0.1)划分,使客户端数据分布更贴近真实场景。
实验通用设置
本地数据:训练集:测试集 = 3:1。
评估指标:客户端测试集准确率,取平均。
训练配置:批大小=10,学习率=0.01,每轮 1 epoch,总通信轮次=1000。
客户端数量:主要在 20 个客户端上模拟(全参与 ρ=1),也在 50/100/200 客户端下实验(部分参与 ρ=0.5)。
所有实验重复 3 次,报告均值和标准差。
FedKTL 的实现细节
超参数:µ=50,λ=1,K=C,服务器学习率=0.01,批大小=100,epoch=100。
优化器:服务器端特征转换器 F 用 Adam。
分类器训练:ArcFace loss 参数 s=64,m=0.5s=64, m=0.5s=64,m=0.5。
生成器:使用 预训练 StyleGAN-XL(1.3 亿参数,基于 ImageNet 训练,输出 64×64 图像)。
为保证兼容性,服务器会调整生成图像分辨率以匹配客户端数据。
还在附录里测试了替代生成器(如 Stable Diffusion)或单边缘客户端的场景。
效果比较
主要内容分解
整体表现
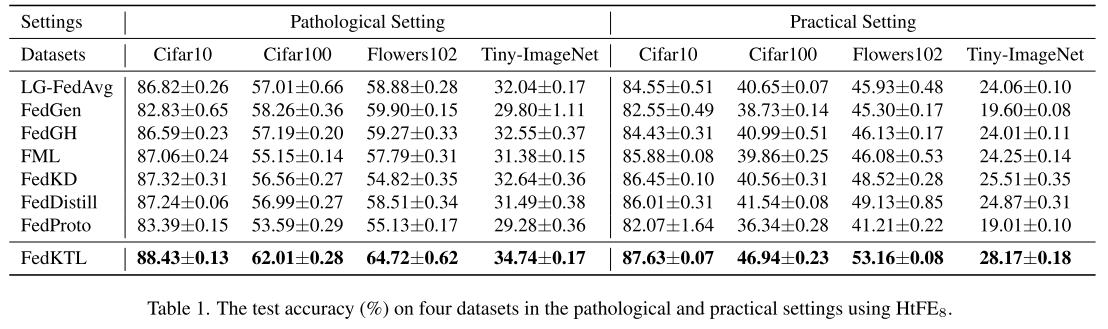
在四个数据集(CIFAR10、CIFAR100、Flowers102、Tiny-ImageNet)上的测试准确率对比实验表明:
FedKTL 在异构联邦学习 (HtFL) 场景下优于所有基线方法。
最突出的结果
在 CIFAR100 的实际分布 (practical setting) 中,FedKTL 的准确率比对手 最高提升 5.40%。
实际场景 vs 病态场景
FedKTL 在 实际分布场景 下的优势更明显,说明它在更接近真实数据分布的情况下更有效。
生成图像数量与效果
生成图像的数量与类别数一致,即:
CIFAR10 → 10 张
CIFAR100 → 100 张
Flowers102 → 102 张
Tiny-ImageNet → 200 张
即便只有 10 张图像(CIFAR10),FedKTL 依然能在两种异构场景下保持优秀表现。
高异构场景
实验设计:不同程度的模型异构性
定义了 5 种新的异构场景:
HtFE2:4-layer CNN + ResNet18
HtFE3:ResNet10、ResNet18、ResNet34
HtFE4:4-layer CNN、GoogleNet、MobileNet v2、ResNet18
HtFE9:9 种 ResNet 变体(从 ResNet4 到 ResNet152)
HtM10:在 HtFE8 的基础上再加两个 ViT 模型(ViT-B/16、ViT-B/32),且分类器也异构
注意:由于 HtM10 包含 ResNet 和 ViT,所以部分基线方法(LG-FedAvg, FedGen, FedGH)不能应用。
实验结果(表2)
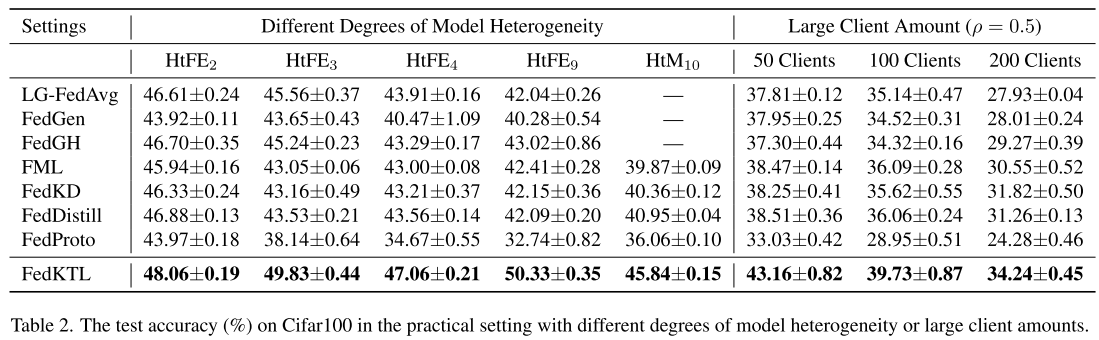
大多数基线方法:随着模型异构性增加,性能下降严重,从 HtFE2 到 HtFE9,准确率至少下降 3.53%。
FedKTL 的表现:不仅没有下降,反而在 HtFE9 取得最佳性能,相比基线方法 最高领先 7.31%。
多客户端场景
实验设计
在 HtFE8(8 种模型异构)场景下,分别模拟 50、100、200 个客户端。
数据集:CIFAR100,不同客户端数时通过不同划分方式拆分。
在 200 客户端时,每个类别平均只有 8 个训练样本,数据极度稀疏。
采用 部分客户端参与,即每一轮只有 50% (ρ=0.5) 的客户端参与训练。
结果说明
不同客户端数量的场景数据分布不同,因此不能直接横向比较准确率。
但实验结果(表2)显示:
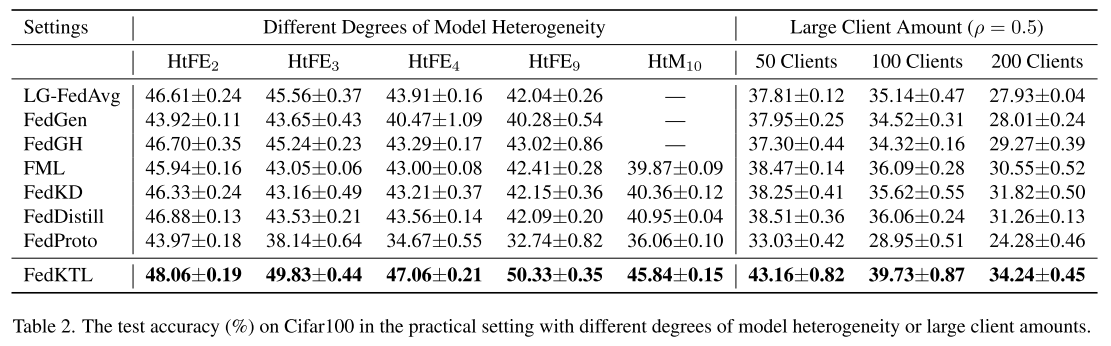
即使在客户端数量很多、数据极少、且部分参与的情况下,FedKTL 依然保持优于基线方法的性能优势。
客户端训练轮数影响
实验目的
在联邦学习中,如果客户端在上传前多训练几轮,可以减少通信轮次,从而 节省通信资源。
本实验研究:当增加本地训练轮数 E 时,各方法性能的变化。
实验结果(表3)
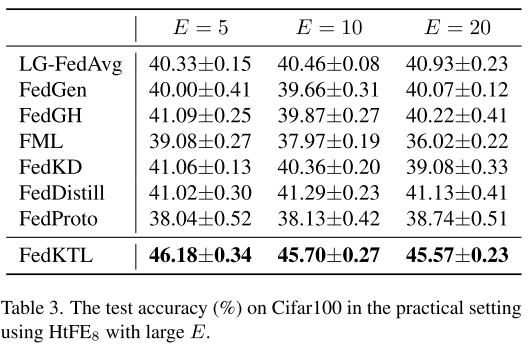
大部分方法(除了 FML 和 FedKD)在较大 E 下依然能维持性能。
FedKTL 在不同 E 设置下始终保持优越性能。
特殊情况(FML & FedKD)
FML 和 FedKD 依赖于辅助模型(auxiliary model)进行知识传递。
当 EEE 较大时,辅助模型在本地训练中会学到更多 偏置信息,
→ 聚合时效果更差,导致整体性能下降。
特征维度的影响
实验目的
研究不同的特征维度 K′ (即分类器前的特征表示维度)对测试精度的影响。
实验结果
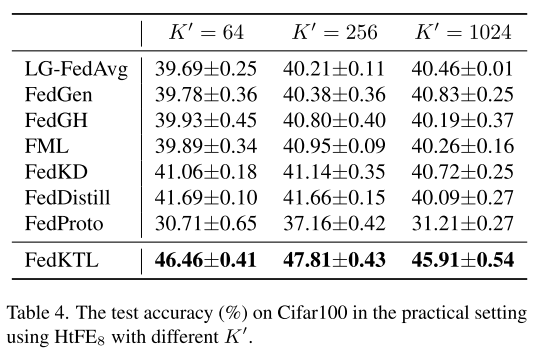
大多数方法在 K′=256 时表现最好。
但对共享分类器的方法(如 LG-FedAvg、FedGen),效果没有明显依赖。
方法差异
FedProto:直接用 K'维度生成原型并上传,维度越大,上传的信息量越多。
FedKTL:在投影层 hi 后生成原型,维度设为 K=C,即等于类别数。
例如在 Cifar100 上,类别数为 100,因此 K=100<K′。
这个维度固定,不会随 K′变化,减少了上传复杂度和冗余信息。
通信成本
总体表现
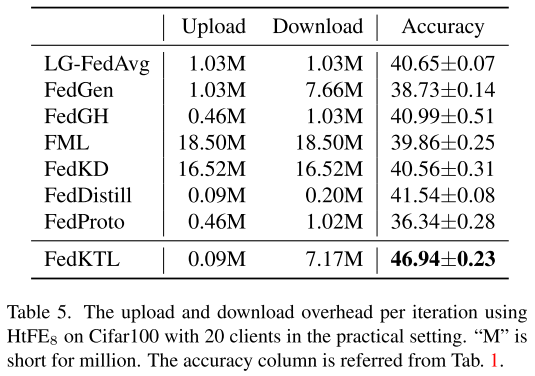
FedKTL 在保持优越性能的同时,通信成本 相对较低(表5)。
与基线方法对比
上传和下载成本都低于 FedGen、FML、FedKD。
上传成本最低,因为 FedKTL 将原型维度设为 K = C(类别数),避免上传冗余高维信息。
上传与下载开销对比
上传开销明显低于下载开销,符合实际网络环境:
现实中,上行带宽通常比下行带宽慢。
因此 FedKTL 适合真实场景中的知识传递。
不同生成器
默认生成器与替代生成器
默认使用 StyleGAN-XL 作为服务器端生成器。
也可以使用其他 StyleGAN,如 StyleGAN3(参数量约为 StyleGAN-XL 的 1/3)。
实验设置
采用多个公开预训练 StyleGAN3:
AFHQv2 (512×512)
Benches (512×512)
FFHQ-U (256×256)
WikiArt (1024×1024)
对不同生成器,需要重新调节超参数 λ。
实验结果

即便使用不同生成器和预训练数据集,FedKTL 依然保持出色性能(表1 和表6)。
知识迁移原则
FedKTL 更关注生成图像的 类别可区分性,而不是语义内容与客户端数据的完全匹配。
只要生成图像可以按类别区分,就能有效进行知识迁移循环(knowledge-transfer-loop)。
域对齐
迭代性质
异构联邦学习 (HtFL) 的训练是 迭代的,
FedKTL 的 域对齐(domain alignment) 同样是一个迭代过程。
早期迭代
初期生成的图像 DIDIDI 对应全局类中心 Qˉ\bar{Q}Qˉ 看起来 相似且不够区分,
原因:客户端生成的原型尚不具备区分性。
训练进行中

随着迭代继续,生成图像 逐渐清晰、类别可区分。
图像在迭代 110、120、130 时几乎不再变化,
→ 表明 特征转换器 F 和客户端模型训练趋于收敛。
消融实验
消融实验设置
分别移除或替换 FedKTL 的关键组件,创建以下变体:
-LMi:移除本地知识迁移损失 LM_i,只训练本地数据 Di。-LMMD:移除 MMD 域对齐损失。-LMSE:移除均方误差损失 LMSE。-ETF:移除 hi 投影层,替换 ETF 分类器为原始分类器。-Q¯:移除全局类中心 Q¯,仅用生成数据 DI。+CS:使用 Conditional StyleGAN-XL,直接生成任意 ImageNet 类别图像,不进行域对齐或上传。
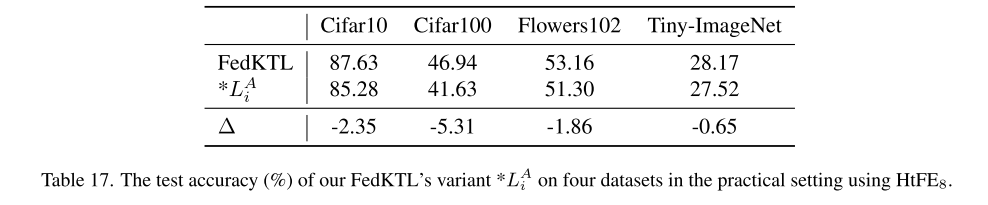
消融实验结果

-LMi:仅用本地数据训练,准确率下降 3.78%,生成图像失真。
-LMSE:生成图像不可区分,误导特征提取器,准确率下降 6.47%。
-LMMD:缺少域对齐,Q¯ 无法作为有效潜在向量,生成模糊图像,性能下降明显。
-ETF:使用偏置分类器,原型重叠,生成图像失去类别可区分性。
-Q¯:缺少全局类中心,DI 无法有效传递知识,生成图像语义异常,性能下降。
+CS:生成的图像与客户端任务不匹配,训练受到负面影响,准确率轻微下降(0.26%)。
关键发现
某些变体(-LMSE, -LMMD, -ETF, -Q¯)表现甚至比
-LMi更差,说明 每个关键组件都是不可或缺的,并且彼此协同提升性能。
附录
单客户端场景
背景与动机
传统联邦学习 (FL) 依赖于全局聚合模型来共享知识。
FedKTL 除了聚合客户端知识外,还利用 服务器端预训练生成器(如 StyleGAN-XL)提供 通用且有价值的知识。
这一机制尤其适用于 数据稀缺的边缘设备,甚至适用于只有一个服务器和一个客户端的场景(云-边缘场景)。
KTL 在单客户端的执行方式
聚合步骤无效(只有一个客户端),直接进行 迭代知识传递:
客户端发送原型(prototypes)到服务器
服务器返回生成的图像-向量对
客户端将返回结果作为额外监督任务,促进本地训练
每个训练 epoch 都执行这一过程,直到客户端模型收敛。
实验设置(少样本场景)
边缘客户端数据极少:
100-way 23-shot(每类 23 张)
100-way 9-shot(每类 9 张)
100-way 2-shot(每类 2 张)
数据划分:训练集 75%,测试集 25%
实验结果
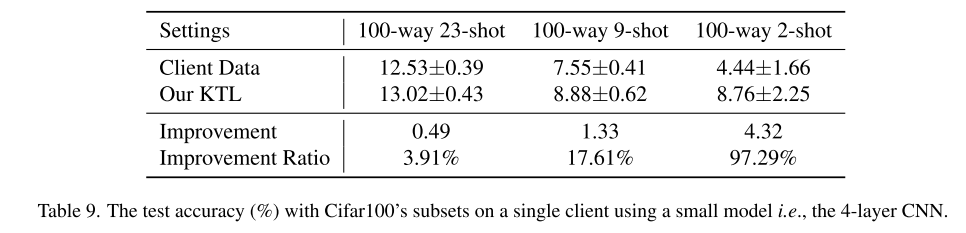
当客户端数据非常稀缺时,KTL 能显著提升性能(表9)。
当客户端数据相对充足(23-shot)时,仅使用预训练生成器而不与其他客户端协作,提升效果有限。
关键结论
KTL 能将服务器端预训练模型的知识有效迁移到边缘设备,尤其在 极少样本 情况下效果明显。
实验设置细节
数据集与预训练生成器
使用的四个数据集:Cifar10、Cifar100、Flowers102、Tiny-ImageNet。
使用的预训练生成器:
StyleGAN-XL
StyleGAN3(预训练在 AFHQv2、Benches、FFHQ-U、WikiArt)
Stable Diffusion v1.5
实验环境
机器配置:
64 核 Intel Xeon Platinum 8362 CPU
256GB 内存
8 × NVIDIA 3090 GPU
Ubuntu 20.04.4 LTS
超参数设置
FedKTL:
K = C, µ = 50, λ = 1, ηS = 0.01, BS = 100, ES = 100
通过网格搜索在 Tiny-ImageNet 上调参,探索范围:
µ: {1, 10, 20, 50, 80, 100, 200}
λ: {0.005, 0.01, …, 100}
ηS: {0.0001, 0.001, 0.01, 0.1, 1}
BS: {1, 10, 50, 100, 200, 500}
ES: {1, 10, 50, 100, 200, 500, 1000}
使用 Adam 优化器训练 F
ArcFace loss 超参数 s = 64, m = 0.5
LMMD 使用 RBF 核函数
对比方法(LG-FedAvg、FedGen、FedGH、FML、FedKD、FedDistill、FedProto)
各方法超参数根据原论文设置,例如 FedGen 的生成器 lr=0.1、噪声维度=32、服务器训练轮数=100 等
辅助模型设计(FML 和 FedKD)
辅助模型尽量小,以减少通信开销
在任何模型异构场景中,均使用最小模型作为辅助模型
隐私保护
客户端无法恢复他人数据
即使客户端接收到来自其他客户端的 全局知识(包括它从未见过的类别),
仍无法确定每个图像-向量对属于哪个客户端或客户端组,
因此无法泄露其他客户端的本地数据。
基于类别的原型传输
FedKTL 仅传输 类级别的原型(class-level prototypes),这是一种常见的 FL 隐私保护策略(如 FedProto)。
设计哲学支撑隐私
在 §3.3.5 中列出了三条理由,支持 FedKTL 的隐私保护能力。
兼容隐私增强技术
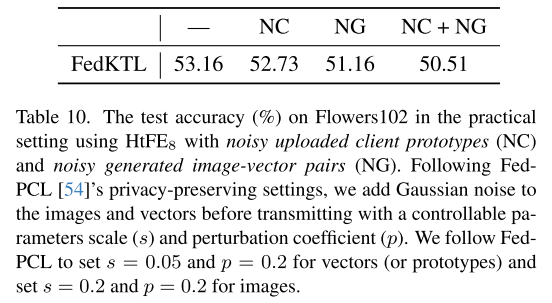
FedKTL 可以结合如 添加噪声等隐私技术,
仅会导致精度略微下降(见表 10)。
收敛分析
训练误差曲线
通过图 9 展示 FedKTL 在客户端训练集上的训练误差变化情况,
计算方式与主文中测试精度的计算方式一致。
收敛过程
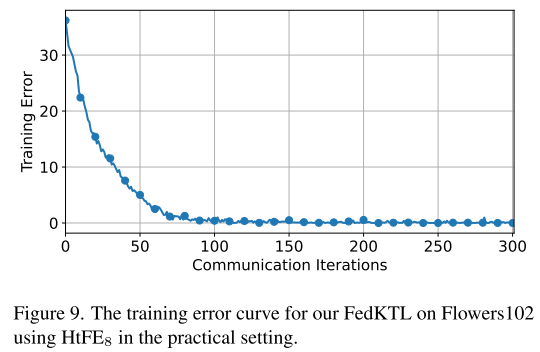
前 80 次迭代:训练误差下降迅速 → 快速优化阶段
之后迭代:训练误差逐渐稳定 → 逐步收敛阶段
大约在第 120 次迭代后,模型训练误差和性能保持稳定 → 收敛完成
超参数及调优
实验方式
逐个调整 FedKTL 的超参数,保持其他参数固定,观察对性能的影响。
调参基准数据集为 Tiny-ImageNet。
关键发现
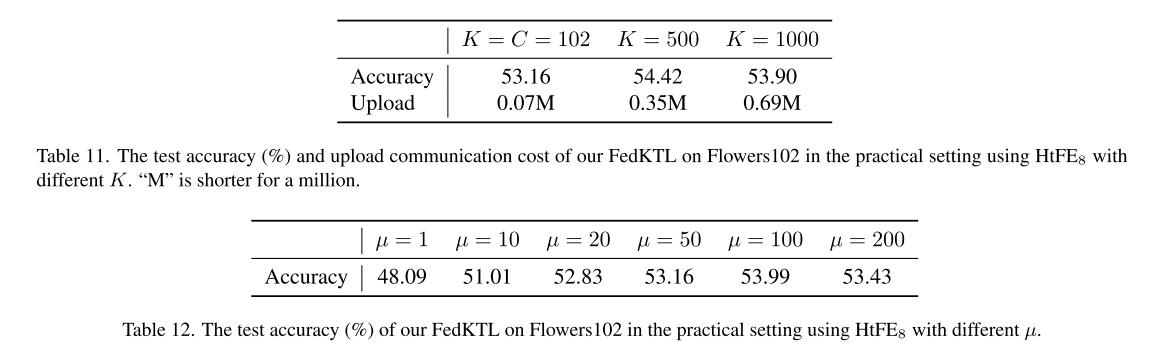
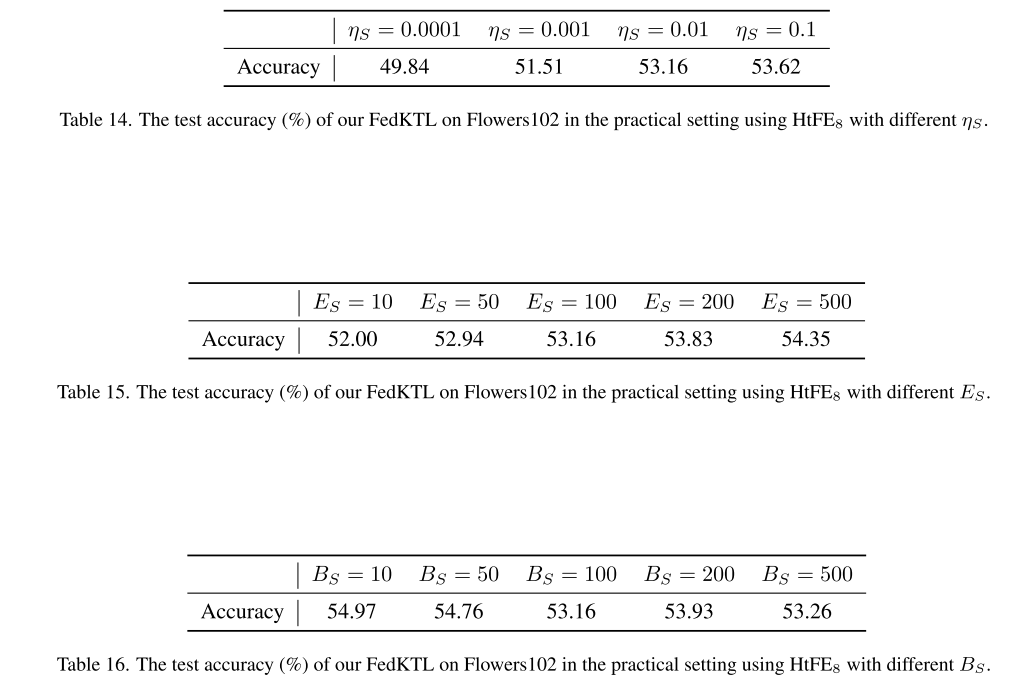
ETF 维度 K:
K 越大 → 传输更多客户端知识 → 精度提高
但通信开销也增加 → 实践中设置 K = C 以平衡精度和通信成本
µ(LMi 权重):
µ > 50 → 精度可超过 53%,说明 LMi 重要性需强调
µ 过大 → 可能导致精度下降
λ(服务器域对齐权重):
最优通常 < 10(以 Flowers102 为例)
λ 过大 → 弱化域对齐效果
服务器学习率 ηS 和训练轮数 ES:
较大值 → 性能更好
服务器批量大小 BS:
较小值 → 性能更好
跨数据集调参
Tiny-ImageNet 上的最佳组合未必适用于 Flowers102
默认超参数表现良好,但对新数据集可能需要重新调优
客户端损失函数

数据分布
服务端不同生成器
超参数调优
由于生成器从 StyleGAN-XL 换成 Stable Diffusion,需要重新调节部分超参数:
ηS = 0.1、λ = 0.01、µ = 100
其他参数保持不变。
Stable Diffusion 的适用性

Stable Diffusion 也能有效支持 FedKTL
生成图像质量优秀
挑战:潜在向量维度为 16384,而客户端原型维度仅 10(Cifar10),低维向高维映射需更深的特征变换器(feature transformer)
生成图像观察

随着 HtFL 迭代次数增加,生成图像越来越清晰、信息更丰富
同语义标签(如“airplane”、“automobile”、“ship”、“truck”)生成的图像特征相似,说明模型能捕捉类别间语义关系
补充
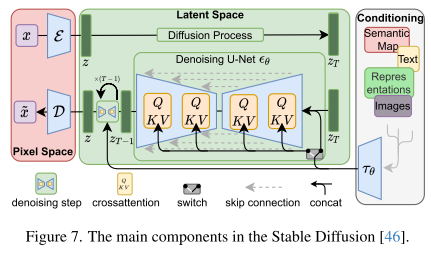
1. Stable Diffusion 的构造
Stable Diffusion 是一种 扩散模型(Diffusion Model),用于生成图像。它的核心构造包括以下组件:
潜在空间(Latent Space)
Stable Diffusion 不直接在像素空间生成图像,而是先在一个低维潜在空间(latent space)生成潜在表示,然后再解码成图像。
这样做可以大幅降低计算量,同时保持生成图像的质量。
噪声添加与去噪过程(Diffusion / Denoising Process)
正向扩散(Forward Diffusion):将真实图像逐步加噪声,直到变成纯噪声。
反向扩散(Reverse Diffusion):训练一个网络(通常是 U-Net)来逐步去噪,从随机噪声恢复出清晰图像。
条件信息(Conditioning / Guidance)
可以通过文本、标签或其他条件信息指导图像生成。
在文本到图像任务中,文本经过一个 文本编码器(如 CLIP) 转成向量,作为生成器的条件输入。
解码器(Decoder)
将潜在表示解码成最终的 RGB 图像。
通常使用 VAE(Variational Autoencoder) 的解码器结构。
训练目标(Loss Function)
模型训练的核心是 预测噪声。网络学会从“带噪声”的潜在向量中预测原始的潜在表示,然后经过解码器生成图像。
2. Stable Diffusion 的工作流程(通俗解释)
可以把 Stable Diffusion 的流程比作 从杂乱噪声“慢慢雕刻出图像”:
准备噪声
先生成一张完全随机的噪声图(就像一张静态雪花电视屏幕)。
迭代去噪
模型一层一层地去掉噪声。
每一步都参考潜在空间中的信息(潜在向量)和条件信息(比如文本描述“一个蓝色的海滩”),让图像越来越接近目标。
生成潜在表示
每次去噪都产生一个潜在图像(还不是最终的 RGB 图像),这个潜在图像包含了图像的整体结构和细节信息。
解码成图像
去噪完成后,潜在表示通过解码器变成最终的高清彩色图像。