Redis核心面试知识点汇总
文章目录
- Redis核心面试知识点大全
- 1. 常用命令与数据结构应用场景
- 2. 持久化机制深入
- 1. RDB (Redis DataBase) - 内存快照
- 2. AOF (Append Only File) - 命令日志
- 3. Redis快的原因(深度解析)
- 1. 基于内存操作 (最关键的因素)
- 2. 高效的数据结构 (算法的力量)
- 3. 单线程架构与 I/O 多路复用 (设计的艺术)
- 为什么采用单线程?
- I/O 多路复用 (I/O Multiplexing)
- 4. 其他优化
- 5. 快速总结
- 4. 部署方式选型指南
- 5. 缓存问题解决方案详解
- 缓存穿透 (Cache Penetration)
- 缓存击穿 (Cache Breakdown)
- 缓存雪崩 (Cache Avalanche)
- 6. 过期策略与内存淘汰
- 7. 分布式锁进阶 (Redisson)
- 8. 保证数据一致性方案对比
Redis核心面试知识点大全
1. 常用命令与数据结构应用场景
Redis的强大源于其丰富的数据结构,每种结构都对应着典型的应用场景。
| 数据类型 | 核心命令 | 详细描述与示例 | 典型应用场景 |
|---|---|---|---|
| String | SETEX key seconds value | 设置键值对并指定过期时间,e.g. SETEX sms:13800138000 60 123456 | 1. 缓存: 缓存Session、对象、HTML片段等。 2. 计数器: INCR article:readcount:1001 文章阅读量。3. 限时控制: 手机验证码、登录token( SETEX)。4. 分布式锁: SET lock:order NX EX 10(见第七节)。 |
| Hash | HMSET user:1000 name "John" age 30HGETALL user:1000 | 类似Java的Map<String, String>,适合存储对象。 | 1. 存储对象: 存储用户信息、商品信息等。相比String将整个对象序列化成JSON,Hash可以单独获取/修改某个字段,更节省网络流量和内存。 2. 购物车: Key=cart:userId, Field=productId, Value=quantity。HINCRBY cart:1001 5001 1 轻松实现商品数量增减。 |
| List | LPUSH/RPUSHLPOP/RPOPBRPOP key timeout | 双向链表。BRPOP 是阻塞版本,如果没有元素则会等待,是实现简单消息队列的关键。 | 1. 消息队列: LPUSH生产消息,BRPOP消费消息(但更推荐用专业的RabbitMQ/Kafka)。2. 时间线/文章列表: LPUSH user:1000:timeline 1001 发布新微博,LRANGE user:1000:timeline 0 9 获取最新10条。3. 排行榜(非实时): 每天凌晨 LRANGE hotnews:20231027 0 9 获取昨天最热的10条新闻。 |
| Set | SADDSINTERSISMEMBER | 无序集合,提供交集、并集、差集等操作。 | 1. 抽奖/点赞/收藏: SADD lottery:1001 user1 user2 user3 添加参与用户,SMEMBERS lottery:1001 查看所有参与者。2. 共同关注/好友推荐: SINTER user:1000:follows user:1001:follows 计算用户1000和1001的共同关注。3. 标签系统: SADD product:1000:tags 手机 5G 华为 给商品打标签,SADD tag:5G:products 1000 1002 建立标签到商品的索引。 |
| ZSet | ZADD key score memberZREVRANGE key 0 9 WITHSCORES | 有序集合,每个成员关联一个分数(score),按分数排序。 | 1. 实时排行榜: ZINCRBY hotRank 1 article:1001 文章热度+1,ZREVRANGE hotRank 0 9 WITHSCORES 获取Top10。2. 延迟队列: 用时间戳作为score, ZADD delay_queue <future_timestamp> task_data,工作线程用ZRANGEBYSCORE delay_queue 0 <current_timestamp>获取到期的任务。3. 带权重的消息队列: VIP用户优先处理。 |
2. 持久化机制深入
1. RDB (Redis DataBase) - 内存快照
流程详解:
- 主进程收到
BGSAVE命令或达到save配置阈值。 - 主进程调用
fork()系统调用,创建一个子进程。注意: 子进程与父进程共享内存空间(在Linux中通过Copy-On-Write机制实现)。 - 子进程将共享的内存数据遍历并序列化到临时的RDB文件(
temp-.rdb)。 - 子进程完成写盘后,用新文件原子替换旧的RDB文件。
- 子进程退出,通知主进程。
Copy-On-Write (写时复制) 示意图:
说明:Fork出的子进程共享主进程的内存数据。只有当主进程要修改某一块数据时,操作系统才会将该块数据复制一份出来供主进程修改。这意味着子进程的持久化快照是Fork那一刻的冻结数据。如果在此期间主进程有大量写操作,会导致内存占用翻倍。
2. AOF (Append Only File) - 命令日志
重写(Rewrite)机制详解:
为什么需要重写?例如:
SET k1 v1
DEL k1
SET k2 v2
SET k2 v3
这些命令最终状态是k2=v3,但AOF文件里记录了4条命令。重写就是根据当前数据库状态,生成一条等效的、最简洁的命令序列(例如直接生成一条SET k2 v3),写入一个新的AOF文件。
混合持久化 (AOF + RDB) 后的文件结构:
+-------------------------------+
| [RDB Format - 快照数据] |
+-------------------------------+
| [AOF Format - 增量命令] |
+-------------------------------+
优点:结合了RDB快速恢复和AOF数据不丢失的优点。重启时先加载RDB部分,再重放增量AOF,速度大幅提升。
3. Redis快的原因(深度解析)
- 基于内存操作
- 高效的数据结构
- 单线程架构与 I/O 多路复用
- 其他优化
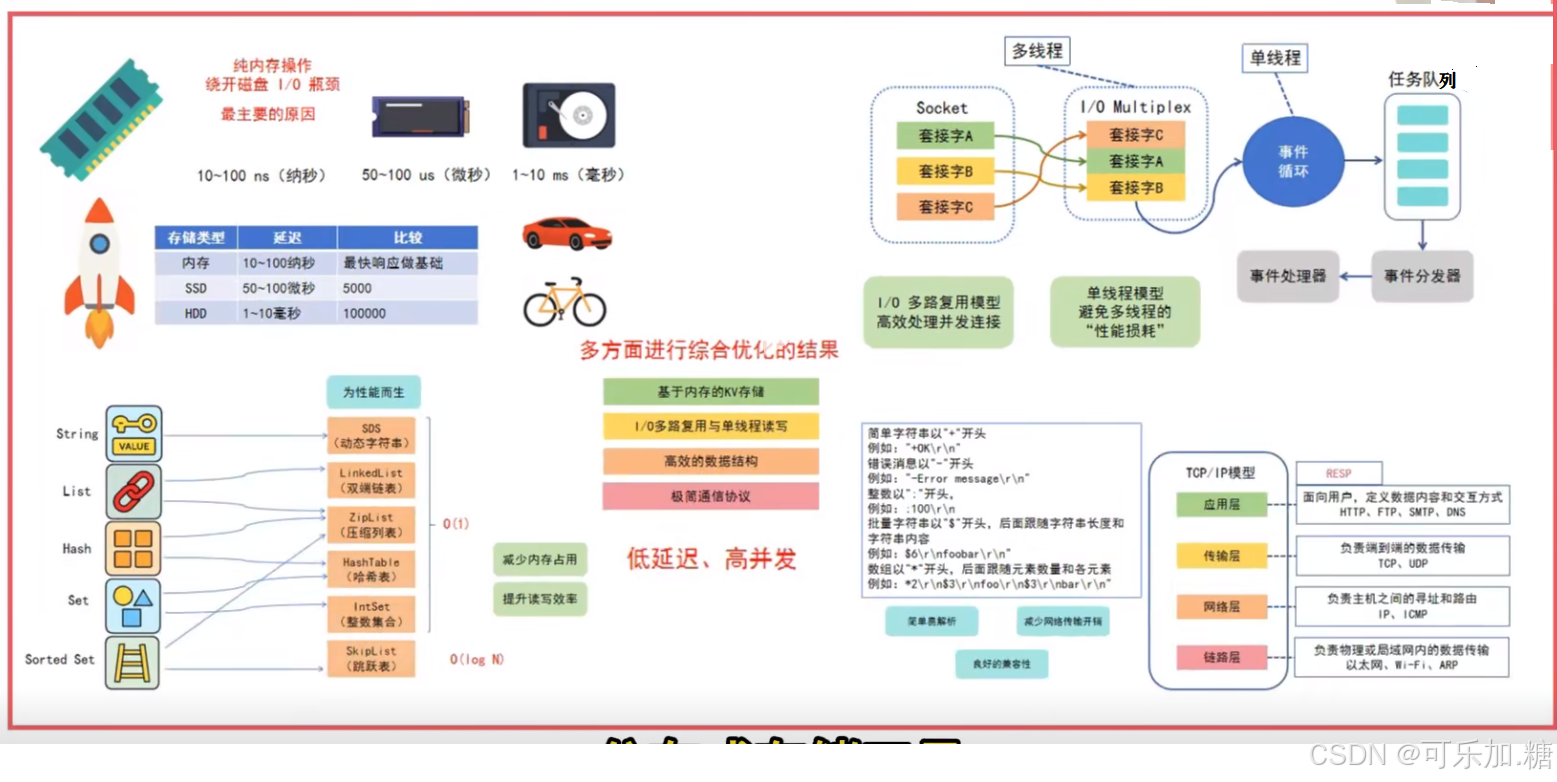
为了更直观地理解这些因素如何协同工作,下图描绘了 Redis 处理一个请求的完整高效旅程:
下面,我们来逐一拆解图中的每一个关键环节。
1. 基于内存操作 (最关键的因素)
这是最根本的原因。所有数据都存放在内存中。
- 速度差距:内存的读写速度在 纳秒 (ns) 级别,而即使是速度最快的 SSD,其随机读写的速度也在 微秒 (μs) 级别。1 μs = 1000 ns。这意味着内存的访问速度比磁盘快几个数量级。
- 无磁盘 I/O 瓶颈:Redis 完全避免了传统数据库最大的性能瓶颈——磁盘 I/O。没有昂贵的寻道时间、旋转延迟和数据传输延迟。
结论:就像从你桌上的笔记本里拿一张纸(内存)和从图书馆的书架上找一本书(磁盘)的区别。
2. 高效的数据结构 (算法的力量)
Redis 不仅仅是简单的 Key-Value 存储,它的 Value 可以是多种数据结构。每种结构都经过精心设计和优化。
- 动态字符串 (SDS, Simple Dynamic String):
- O(1) 获取长度:C 语言原生字符串需要遍历才能计算长度,SDS 直接在结构体中存储了长度信息。
- 避免缓冲区溢出:API 是安全的,会自动检查空间。
- 二进制安全:可以存储任何二进制数据,而不仅仅是字符串。
- 压缩列表 (ZipList):为节省内存而设计,将多个元素紧挨着存储在一起,适用于小数据量的 Hash 和 List。
- 快速列表 (QuickList):Redis 3.2 后 List 的底层实现。它是 双向链表和压缩列表的结合体。将多个 ZipList 节点用链表连接起来,在空间效率和性能之间取得了完美平衡。
- 跳跃表 (SkipList):ZSet(有序集合)的底层实现之一。通过建立多级索引,实现了平均 O(log N) 复杂度的查找、插入和删除,且实现比平衡树更简单。
- 哈希表 (Dict):使用高效的哈希算法,并通过渐进式 rehash 策略在扩容时避免大的性能抖动。
结论:Redis 用“精妙的算法”配合“对硬件的深刻理解”,最大限度地压榨了硬件的性能。
3. 单线程架构与 I/O 多路复用 (设计的艺术)
这是最容易误解的一点。Redis 的核心网络模型和命令处理是单线程的。
为什么采用单线程?
- 避免上下文切换和竞争开销:多线程虽然能利用多核,但会带来巨大的上下文切换消耗和同步开销(如锁)。锁竞争不仅不能提高速度,有时反而会降低性能,并增加系统复杂度。
- CPU 不是瓶颈:对于内存操作来说,速度已经极快,瓶颈更可能在于网络 I/O。单线程模型已经足以高效处理海量的网络请求。
- 保证原子性操作:单线程使得所有命令都是串行执行的,每个命令在执行过程中都是不可分割的,天然避免了并发问题,简化了开发。
I/O 多路复用 (I/O Multiplexing)
单线程如何同时处理成千上万个网络连接?答案就是 I/O 多路复用技术。
- 工作原理:Redis 使用
epoll(Linux)、kqueue(BSD/MacOS) 这样的系统调用。它允许一个线程监听多个 Socket 上的事件(如连接到来、数据可读、可写)。 - 事件驱动:当某个 Socket 有事件发生(例如客户端发送了命令数据),
epoll会通知 Redis 主线程。主线程将该事件放入一个队列,然后依次、同步地处理这些事件。 - 高效之处:这个过程避免了为每个连接创建一个线程的巨大开销,也避免了不必要的忙等待(busy-waiting)。它让单个线程高效地管理了所有连接。
注意:Redis 6.0 的多线程:Redis 6.0 引入了多线程 I/O,但这仅用于处理网络数据的读写和解析,而不是用于执行命令。命令的执行仍然是由主线程串行进行的。这主要是为了减轻主线程在网络 I/O 上的负担,对于真正耗时的命令执行本身,依然是单线程的。这进一步提升了性能,但核心原理未变。
4. 其他优化
- 虚拟内存机制:虽然已不推荐使用,但其设计思路体现了对性能的极致追求。
- 精心编码的源码:代码简洁、高效。
- 管道 (Pipeline):客户端可以将多个命令一次性发送给 Redis,减少了网络往返时间 (RTT),极大提升了批量操作的性能。
- 事务:通过将多个命令打包,确保其被连续执行,减少了网络开销。
5. 快速总结
Redis 的快是一个系统工程的结果:
- 纯内存访问:内存的随机访问延迟在几十纳秒级别,而SSD的随机访问延迟在几十微秒级别,相差1000倍。
- I/O多路复用 (Reactor模型):
- 传统BIO模型:一个线程处理一个连接,万级连接需要万级线程,上下文切换开销巨大。
- Redis使用单线程的Reactor模型,通过epoll等系统调用监听所有套接字。
- 当某个连接有数据到达时,epoll会通知主线程,主线程将该事件放入队列,并依次处理。整个过程避免了不必要的线程切换和锁竞争。
- 高效的数据结构:
- SDS (Simple Dynamic String):相比C原生字符串,获取长度复杂度为O(1);可存储二进制数据;预分配空间减少内存分配次数。
- ZipList (压缩列表):为节省内存而设计,将多个元素紧挨着存储,适用于小数据量的Hash和List。
- QuickList:Redis 3.2后List的底层实现,是ZipList和LinkedList的混合体,将多个ZipList用双向链表连接起来,平衡了内存效率和性能。
- SkipList (跳跃表):ZSet的底层实现之一,插入、删除、查找的时间复杂度都是O(log N),且实现简单,无需复杂的平衡操作。
以上几者相辅相成,共同造就了 Redis 无与伦比的性能。当被问到这个问题时,你可以回答:“Redis 之所以快,主要是因为它基于内存操作,并且采用了单线程架构和 I/O 多路复用来避免不必要的性能损耗,同时其高效的数据结构也功不可没。”
详细如图
4. 部署方式选型指南
| 模式 | 适用场景 | 优缺点 |
|---|---|---|
| 单机 | 开发、测试、学习。数据量小,且可容忍宕机。 | 优: 简单。 缺: 存在单点故障和数据容量瓶颈。 |
| 主从+哨兵 | 读多写少的业务。如:电商网站的商品详情、新闻App的文章展示。需要高可用但数据量未达到单机极限。 | 优: 读写分离提升读性能;哨兵实现自动故障转移,高可用。 缺: 写操作仍在单点;存储容量受单机限制;故障转移期间数据可能丢失。 |
| 集群 | 海量数据+高并发+高可用场景。如:大型社交平台的 feed 流、海量用户会话缓存。 | 优: 数据分片存储,容量可水平扩展;写操作也可负载均衡;具备高可用性。 缺: 客户端实现复杂;不支持跨节点事务和多键操作(除非在同一个slot);运维复杂度高。 |
5. 缓存问题解决方案详解
缓存穿透 (Cache Penetration)
场景:恶意攻击者频繁请求系统不存在的数据,如数据库ID为负数的订单。
解决方案:
- 布隆过滤器 (Bloom Filter):一个空间效率极高的概率型数据结构,用于判断一个元素是否一定不存在或可能存在于集合中。
- 写入:当数据写入数据库后,将其key也同步到布隆过滤器中。
- 查询:访问Redis前,先通过布隆过滤器判断key是否存在。如果不存在,直接返回空,避免访问数据库。
- 特点:有一定的误判率(判断为存在时可能实际不存在),但绝不会错杀(判断为不存在则一定不存在)。适用于可容忍极低误判率的场景。
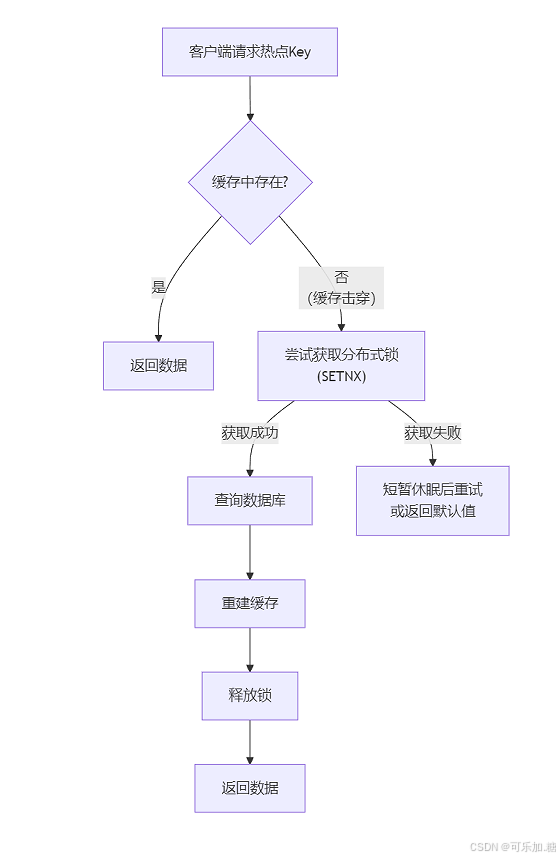
缓存击穿 (Cache Breakdown)
场景:一个热点Key(如首页大促活动信息)在过期瞬间,大量请求同时到来,未从缓存中获取到数据,同时去访问数据库。
解决方案流程图:
缓存雪崩 (Cache Avalanche)
场景:1) 大量Key在同一时间点过期。2) Redis集群宕机。
解决方案:
- 对于大量Key过期:
- 差异化过期时间:在设置过期时间时,使用基础时间 + 随机偏移量(如
3600 + Math.random() * 300),避免集体失效。
- 差异化过期时间:在设置过期时间时,使用基础时间 + 随机偏移量(如
- 对于Redis宕机:
- 事前:搭建高可用Redis集群(哨兵或Cluster模式),防止单点故障。
- 事中:启用服务熔断机制(如Hystrix)。当检测到数据库访问超时或失败比例过高时,自动熔断,直接返回降级内容(如默认值、空白页、友好提示),防止数据库被拖垮。
- 事后:做好Redis的持久化,以便故障恢复后能快速重启并加载数据。
6. 过期策略与内存淘汰
内存淘汰机制 (Eviction Policies) 选择建议:
volatile-lru:如果你的应用中有明显区分热点数据和冷数据,且希望保留未设置过期时间的关键数据(如基础配置),这是最佳选择。allkeys-lru:最常用的策略。如果你无法明确区分哪些Key该设置过期时间,希望系统自动淘汰最不常用的数据。volatile-ttl:优先淘汰即将过期的数据,可能无法保留热点数据。noeviction:不推荐用于生产环境,除非你的数据绝对不允许丢失,且你有其他运维手段来保证内存不溢出。
7. 分布式锁进阶 (Redisson)
使用SETNX实现分布式锁存在几个问题:
- 锁过期时间不好设置:设置短了,业务没执行完锁就释放了;设置长了,客户端宕机后需要等待很久。
- 非阻塞:获取锁失败需要客户端自己重试。
- 不可重入:同一个线程无法再次获取同一把锁。
推荐使用 Redisson 框架,它提供了完善的分布式锁实现:
- 看门狗 (Watchdog) 机制:Redisson会为锁默认设置30秒过期时间,并启动一个后台线程(看门狗),每10秒检查一次客户端是否还持有锁,如果是则自动将锁的过期时间重置为30秒。解决了锁的自动续期问题。
- 可重入锁 (Reentrant Lock):允许同一个线程多次加锁。
- 锁的自动释放:通过Lua脚本保证原子性。
- 多种锁类型:提供公平锁、联锁、红锁等多种分布式锁方案。
8. 保证数据一致性方案对比
| 策略 | 描述 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|---|
| 先更新DB,再删Cache | 1. 更新数据库 2. 删除缓存Key | 逻辑简单。 并发问题概率低(因为删缓存很快)。 | 删除缓存失败会导致不一致。 极端时序下仍可能产生脏数据(概率极低)。 | 最常用、最推荐的方案。配合消息队列重试删除操作。 |
| 先删Cache,再更新DB | 1. 删除缓存Key 2. 更新数据库 | - | 在“删Cache”和“更新DB”之间,其他线程可能把旧数据又读回缓存,导致长时间不一致。 | 不推荐。如需使用,可通过延迟双删(更新DB后,sleep几百ms再删一次Cache)来缓解。 |
| 基于Binlog的异步淘汰 | 1. 更新数据库 2. 数据库的Binlog被捕获 3. 由中间件(如Canal)解析Binlog,并删除缓存 | 业务代码解耦,无需关注缓存失效逻辑。 保证最终一致性。 | 架构复杂,有额外组件。 延迟比方案一高。 | 对一致性要求不是强一致,而是最终一致的超大系统。 |
最终建议:
- 对于绝大多数应用,选择
先更新数据库,再删除缓存。 - 为应对删除失败,可将删除操作放入消息队列进行重试,直到成功。
- 为应对极端情况,给缓存数据设置一个不太长的过期时间作为最终兜底方案。