Kafka学习笔记(p1-p14)
(一)
1.kafka特性
kafka用的是scale语言开发的1个多分区、多副本并且基于Zookeeper协调的分布式消息系统。
kafka是分布式流平台,以高吞吐、可持久、可水平扩展、支持流式处理被广泛应用。
apache kafka是分布式的发布-订阅系统,支持海量数据的传递。在离线和实时的消息处理业务系统中,kafka将消息持久化到磁盘中,对消息创建了备份,并保证了数据的安全。
2.总结特性
(1)高吞吐量、低延迟、kafka每秒可以处理几十万条消息,它的延迟最低只有几毫秒,每个主题可以分多个分区,消费者对分区进行消费操作。
(2)可扩展性:kafka集群支持热扩展。
(3)可持久性、可靠性:消息被持久化到本地磁盘,并且支持数据备份防止数据丢失。
(4)容错性:运行集群中的结点失败(如果副本数量为n,允许n-1个节点失败)
(5)高并发:支持数钱个客户端同时读写。
3.使用场景
(1)日志场景:一个公司可以用kafka收集各种服务的log,通过kafka以统一的借口服务的方式开放给各种consumer,如hadoop、hbase等
(2)消息系统:解藕生产者和消费者,缓存消息
(3)用户活动跟踪:kafka经常被用用来记录web用户和app用户的各种活动,如浏览网页、搜索、点击等活动,这些活动信息被各个服务器发布到kafka的topic中,订阅者通过订阅这些topic来做实时监控分析,或者装载到hadoop、数据仓库做离线分析和挖掘。
(4)运营指标:kafka记录运营监控数据,收集各种分布式应用的数据,生产各种操作的反馈,比如报警和报告。
4.技术优势
可伸缩性:
(1)kafka集群在运行期间可以轻松的扩展或收缩,不会宕机
(2)扩展1个kafka主题包含更多的分区,因为一个分区无法扩展到多个代理,所以容量收到磁盘空间的限制。增加分区的数量意味着单个主题可以存储的数据量没有限制。
(3)容错性和可靠性:kafka的设计使某个代理的故障能够被集群中的其他代理检测懂到。因为每个主题可以在多个代理复制,集群可以在不中断服务的情况下,从此类故障恢复并且继续运行。
(4)吞吐量:代理以超快的速度存储和检索数据。
(二)Kafaka
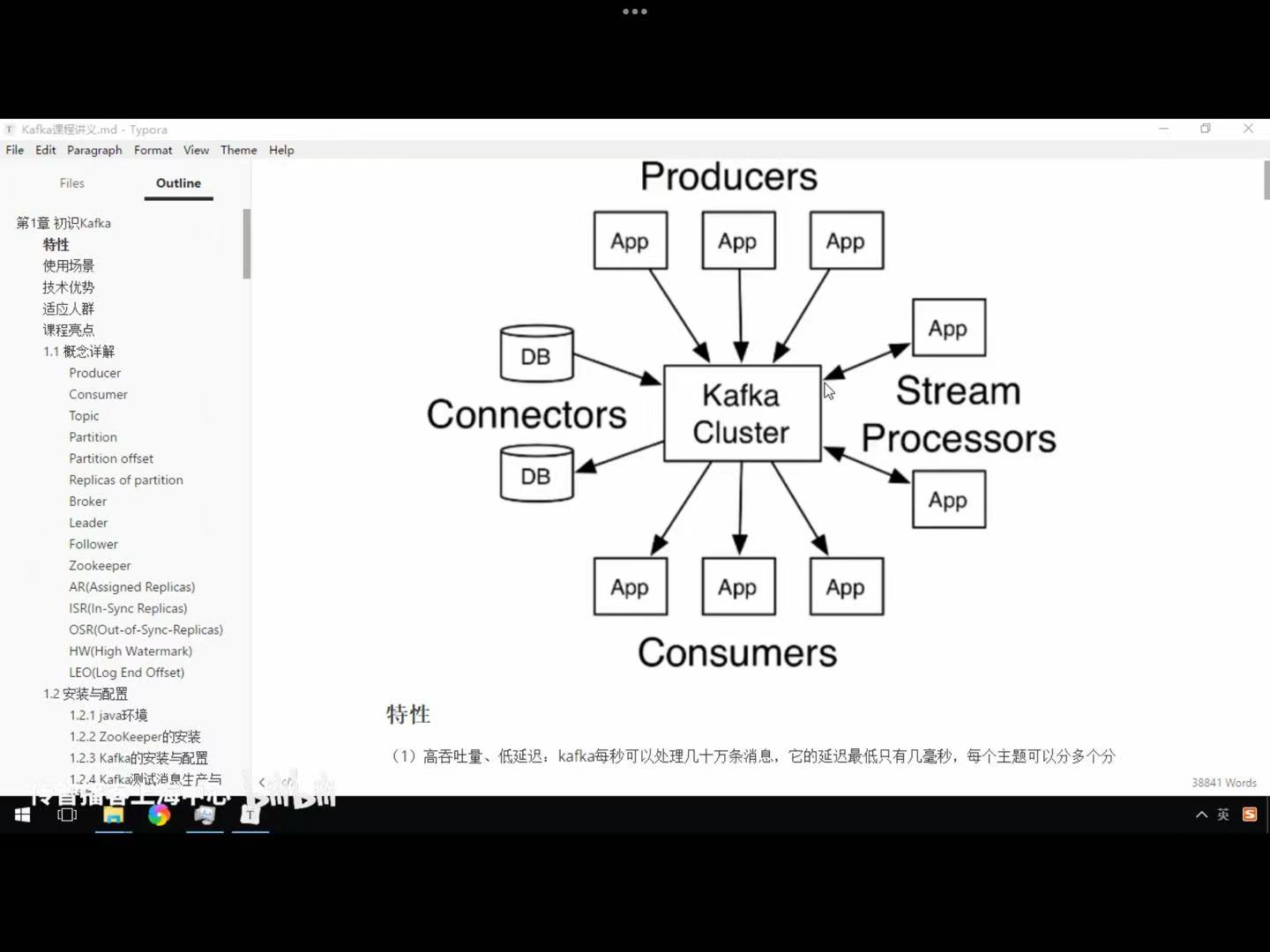
(1)生产者:该角色将消息发布到kafka的 topic中。broker接收到生产者发送的消息后,broker将消息追加到数据的segment文件。生产者发送消息,存储到1个partition中。生产者页可以指定数据存储的partition。
(2)消费者:从broker中读取数据,消费者可以消费多个topic中的数据。
(3)topc:在kafka中,用1个类别属性来划分数据的所属类,划分数据的这个类称为topic。如果把kafka看作1个数据库,topic可以理解为数据库中的1张表,topic为表名。
(4)partition:topic中的数据分割为1个或多个partition。每个topic至少用1个partition。每个partition中的数据使用多个segment文件存储。partition中的数据是有序的。如果partition间的数据丢失了数据的顺序。如果topic有多个partition,消费数据就不能保证数据的顺序。保证消息的消费顺序场景下,需要将partition的树木设为1.
(5)partition offset:
每条消息都有一个当前Partition下唯一的64字节的offset,指明了这条消息的起始位置。
(6)replicas of partition
副本是1个分区的备份,副本不会被消费者消费,副本用来防止数据的丢失。消费者不从 foller的partition中消费数据,而是从为leader的partition中读取数据,副本之间是一主多从的关系。
(7)broker:kafka集群中包含1个或多个服务器,服务器节点成为broker。broker中存储topic的数据。如果某topic有N个partition,集群有N个broker,那么其中有N个broker存该topic的1个partition。
如果某topic有N个partition,集群就有(N+M)个broker,其中有N个broker中存该topic得1个partition,剩下的M个Broker不存储该topic的的partition数据。如果某topic有N个partition,集群中broker数目少于N个,那么1个broker存储该topic的1个或多个partition。在实际生产环境,要尽量避免该情况的发生,这种情况会造成Kafaka集群数据的不均衡。



(8)leader:每个partition有多个副本,其中有且1个作为Leader,Leader是当前负责数据的读写的partition。
(9)follower:flower跟随leader,所有的写请求通过leader路由,数据变更会广播给所有的follower。follower与leader保持数据同步。如果leader失效,我们从follower中选举出1个新的leader。当follower与leaer都挂掉、卡住或者同步太慢,leader会把这个follower从in sync replicas(ISR)列表删除,重新创建1个follower。
(10)zookeeper
zookeeper负责维护和协调broker,当kafka系统新增了broker或者某个broker发生故障失效时,**由zookeeper通知生产者和消费者。**生产者和消费者依据zookeeper的broker状态信息与broker协调数据的发布和订阅任务。
(补充:Zookeeper说安装Kafka集群的必要组件,Kafka通过zookeeper来实施对元数据信息的管理,包括集群、主题、分区)
(10)AR(Assigned Replicas)
分区所有的副本统称AR
(11)ISR(in-Sync replicas)
所有与Leader部分保持一定同步程度的副本(包括Leader副本在内)组成的ISR。
前和 Leader 保持“同步程度可接受”的副本集合(包括 Leader 自身)。
(12)OSR(out-of-sync-replicas)
与Leader副本同步滞后过多的副本/
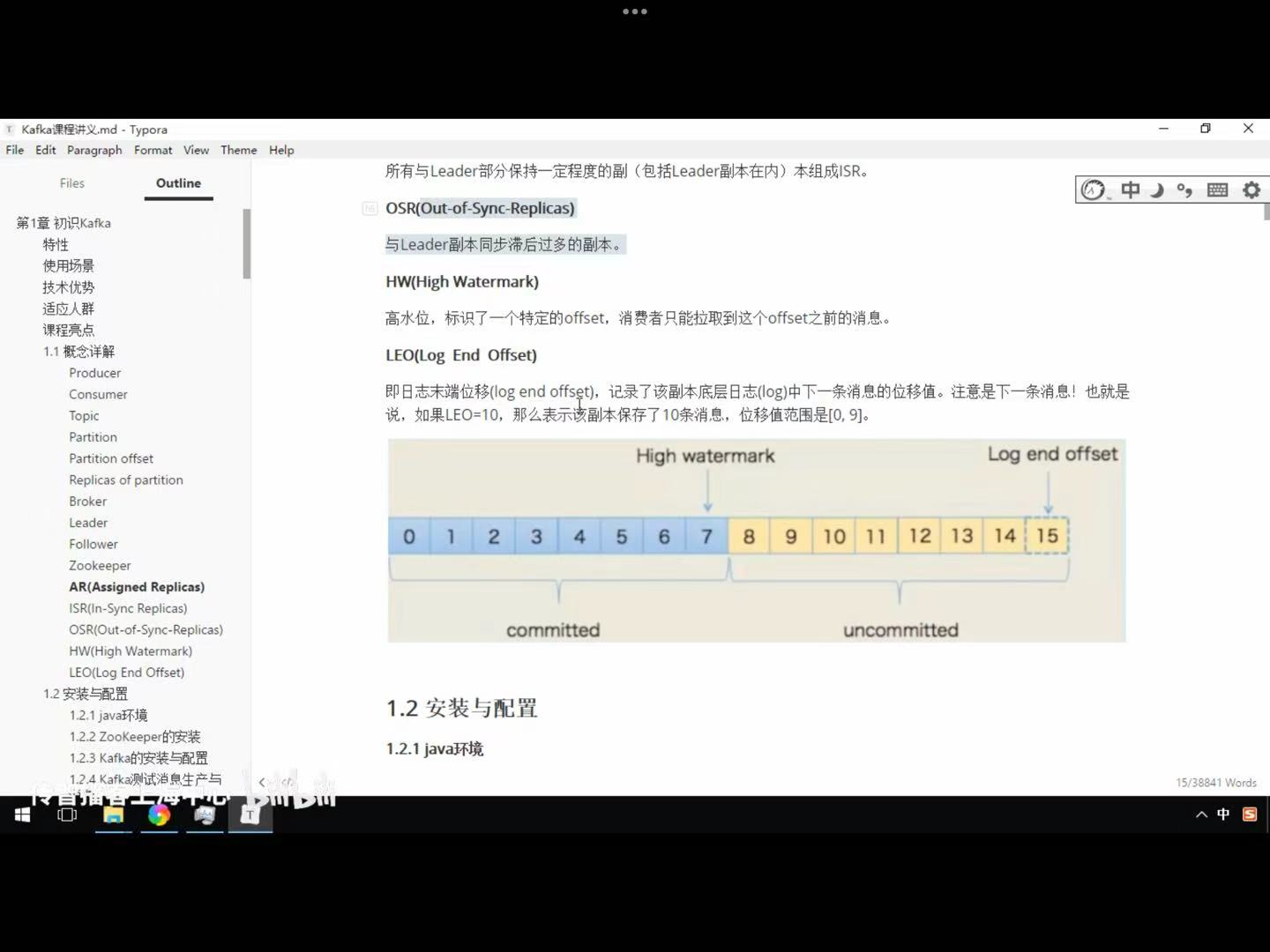
(13)HW(High Watermark)
高水位,标识1个特定的offset,消费者只能拉取这个offset之前的消息。
(14)LEO(Log End offset)
日志末端位移(log end offset),记录了该副本底层日志(log)中,下一条消息的位移值。如果Leo=10,说明该副本保存10条消息,位移范围是[0,9]
(三)消息的生产与消费
(1) ps -ef | grep java 的意思是:先执行 ps -ef → 输出所有进程。再通过 grep java → 过滤出含 “java” 的进程。
ps:process status,用来查看系统进程。
参数:-e → 显示所有进程(等价于 -A)。
-f → 显示“完整格式”(full format),包括 UID、PID、PPID、启动时间、命令等。
(2)jps -l:→ 显示 **进程的 PID + 完整类名或 jar 路径
(3)创建1个主题
bin/kafka-topics