OpenAI 开源 GPT-oss 模型:从闭源到开源的模型架构创新之路
在大型语言模型 (LLM) 日益加速发展的时代,OpenAI 作为闭源模型的鼻祖,首次开源自家模型,这才是 OpenAI 吧。这是自 GPT-2以来,OpenAI 首次分享大型、完全开放权重的模型。早期的 GPT 模型展示了 Transformer 架构的可扩展性。2022 年发布的 ChatGPT 版本通过展示其在写作和问答,编码任务中的强大实用性,使ChatGPT 一炮而红。也真正把 Transformer 模型带到了一个更高的高度。
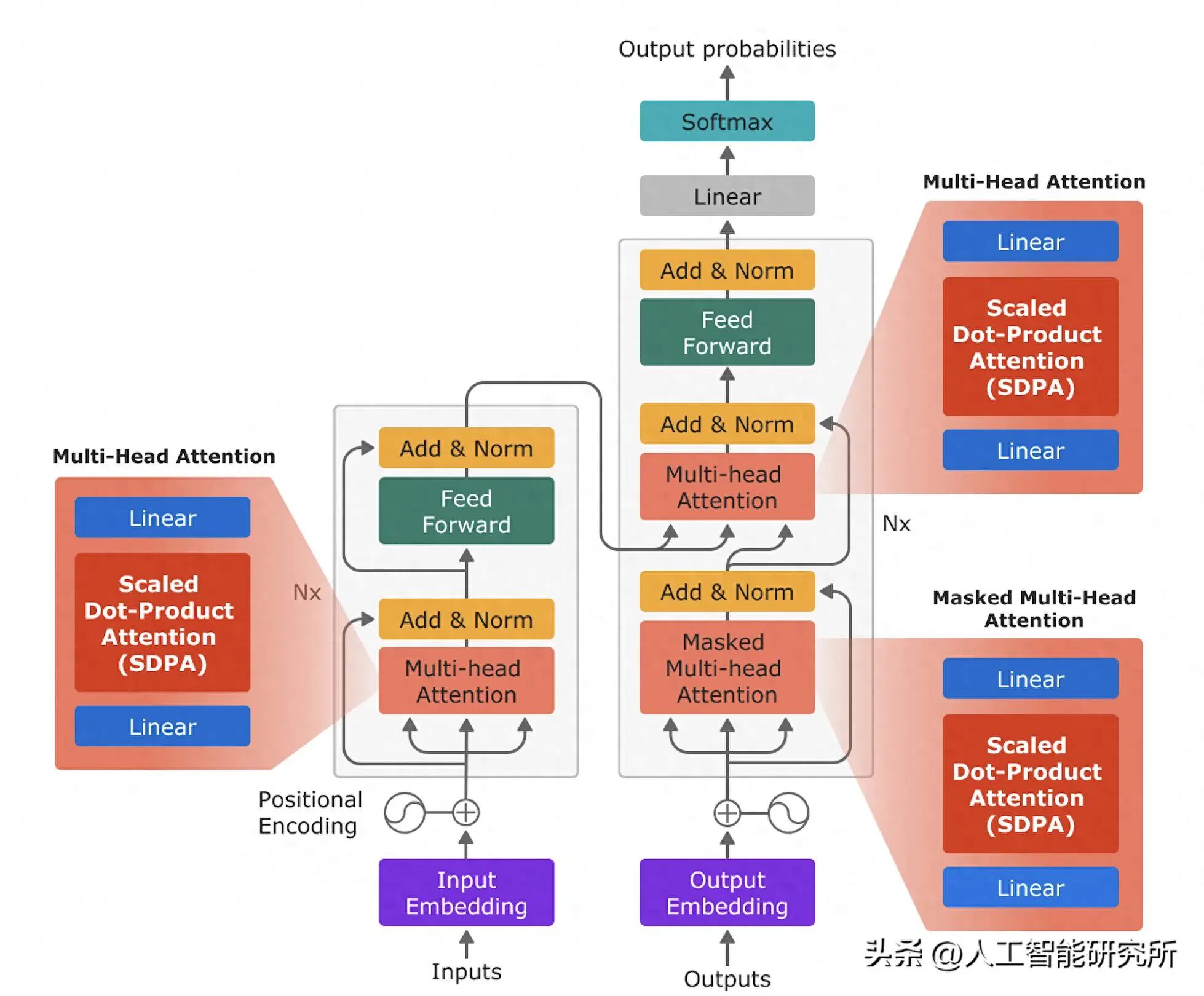
2017 年谷歌发布的 Transformer 模型
OpenAI 开源的gpt-oss-120b 和 gpt-oss-20b 模型标志着OpenAI 转型开源模型的关键时刻。这些仅限文本的、Apache 2.0 许可的开放权重模型——因其开放权重特性而被称为“gpt-oss”——代表了 OpenAI 首次大规模涉足完全可自定义的高能力推理引擎,这些引擎可以无缝集成到代理工作流中。
模型框架
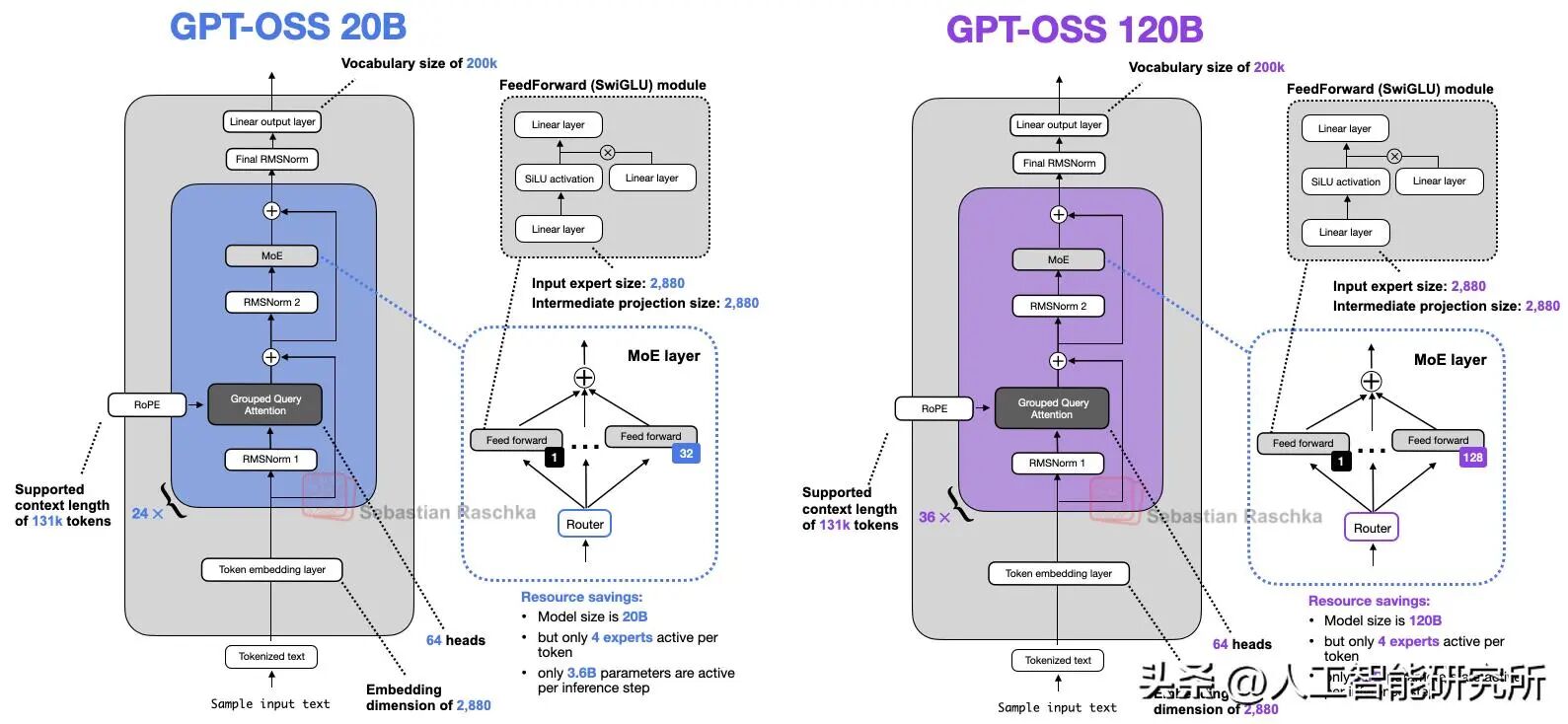
它们分别拥有 1168 亿和 209 亿总参数,每个 token 的活跃参数低至 51 亿和 36 亿,gpt-oss 通过混合专家模型(MoE) 设计强调推理效率。它们支持高级功能,如可变努力链式思考 (CoT) 推理、工具使用(例如网页搜索和 Python 代码执行),以及一种新型的“Harmony Chat Format”用于结构化交互。
但真正让 gpt-oss 脱颖而出的是它明确定位为 GPT 系列的演化版本。正如模型框架,它“建立在 GPT-2 和 GPT-3 架构之上”,融入了数十年 Transformer 模型优化的经验教训,同时解决了早期全局注意力机制模型困扰的可扩展性和安全挑战。
GPT系列模型与gpt-oss 模型框架对比
若要领略 GPT - OSS 的魅力,我们需回溯 GPT 家族的架构发展脉络。GPT 模型是都是基于 Transformer 模型发展而来的模型,而GPT - 2 堪称decoder only架构的重大突破,它是一个纯粹的自回归模型。此模型在 40GB 的互联网文本数据上进行训练,参数规模扩展至 15 亿,跨越 48 层。它有力地证明了无监督预训练能够实现连贯的文本生成。
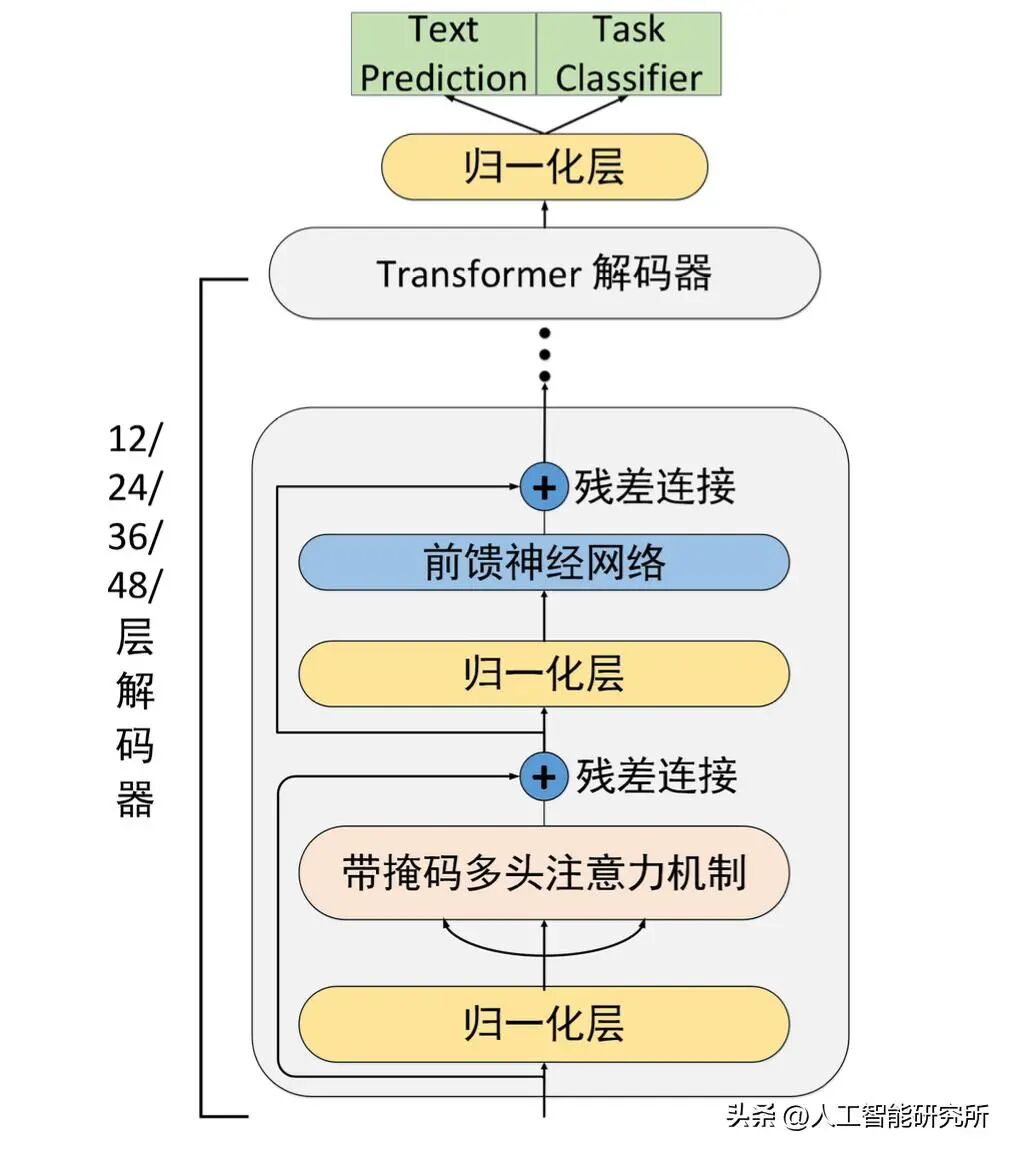
GPT2 模型框架
然而,GPT - 2 采用的全局注意力机制架构存在局限。在这种架构中,每个参数会为每个词元(token)进行注意力机制的计算,这极大地限制了其可扩展性。即便在中等配置的硬件上进行推理,计算量也颇为庞大,且上下文长度被限制在 1024 个token。
GPT - 3 则彻底颠覆了这一传统范式。它的参数规模急剧膨胀至 1750 亿,跨越 96 层,且依旧采用全局注意力机制的架构。为缓解自注意力机制中的二次复杂度问题,它引入了稀疏注意力模式(交替的局部窗口和全局头),从而催生了诸如少样本学习等涌现能力。但不可忽视的是,GPT - 3 的全局性导致了高昂的计算成本。据估计,其训练所需的计算量高达 3640 petaflop/s - days。此外,它仅支持文本处理,采用学习得到的位置嵌入,在处理长上下文时显得力不从心。
全局注意力模型与 MoE 混合专家模型对比
GPT - 4 则将重点转向了效率提升。传闻它采用了混合专家(MoE)架构,总参数约为 1.76 万亿,但每次前向传播时仅有 2200 亿参数处于活跃状态,每层使用 8 - 16 个专家。这种稀疏激活方式使得推理成本相较于等效的全局模型降低了 50 - 70%。同时,它引入了多模态功能(文本 + 视觉)以及 128k 词元的上下文窗口,并采用了高级位置编码技术。为提高稳定性,归一化方法可能演变为 RMSNorm;为实现更平滑的梯度,激活函数采用了 SwiGLU。这些变革使得 GPT - 4 不仅在规模上更为庞大,在性能上也更为出色。在 MMLU 等基准测试中,其表现比 GPT - 3.5 高出 40%,这得益于更优的缩放定律和后训练对齐技术。
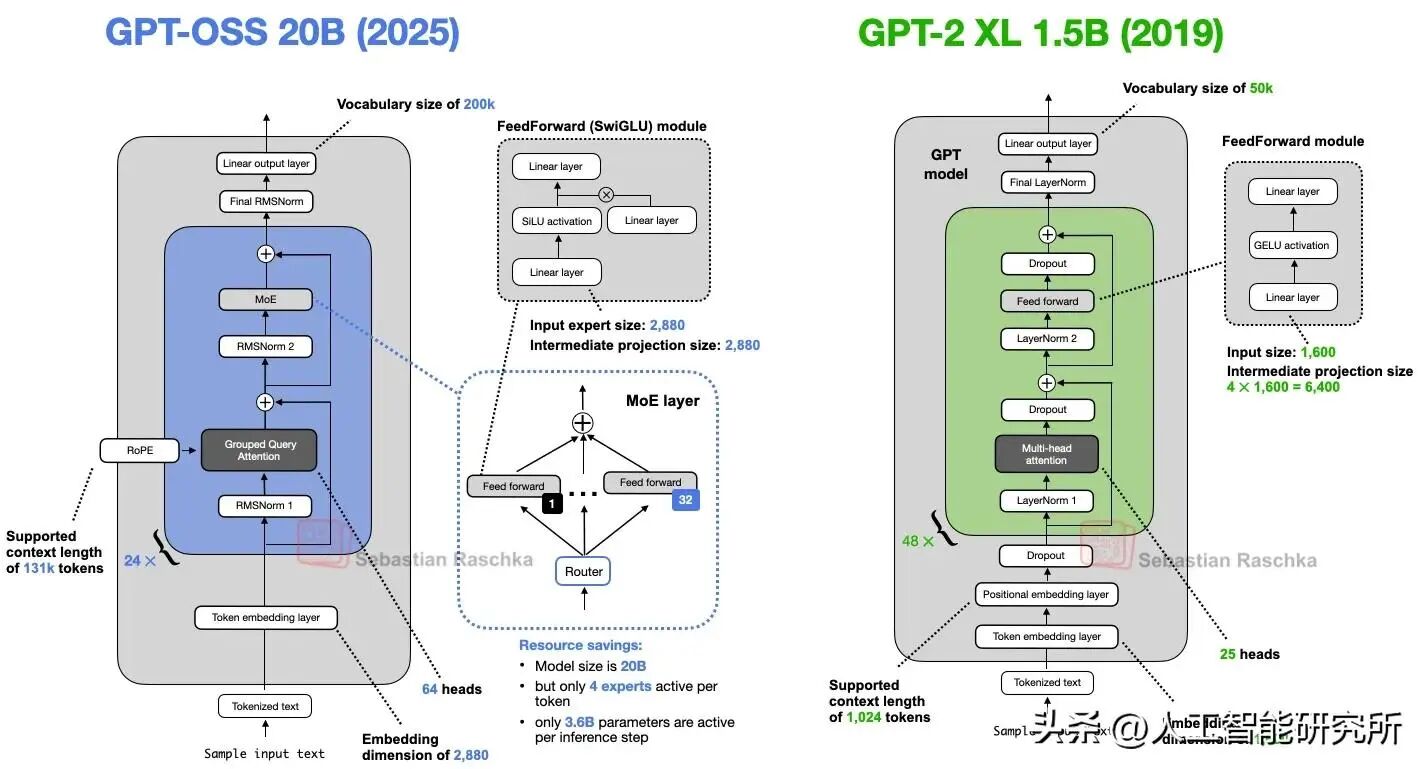
模型框架对比
接下来,让我们聚焦 GPT - OSS。它是一个仅处理文本的 MoE 混合专家模型(decoder only),巧妙地弥合了 GPT - 2/3 稠密架构与 GPT - 4 稀疏架构之间的差距。它拥有 36 层(120b)或 24 层(20b),每个toekn仅激活 4 - 5%的参数,通过量化技术可将 120b 模型适配到单个 80GB 的 GPU 上。与 GPT - 4 专有的多模态权重不同,GPT - OSS 更注重开放自定义,以满足代理任务的需求。它会对预训练数据进行过滤,确保安全性(例如避免涉及化学、生物、放射性和核危害相关内容),并着重关注 STEM 领域和编码能力。
那么,其成效如何呢?该模型在数学(美国数学邀请赛 AIME:借助工具时准确率达 98.7%)和编码(SWE - Bench:准确率达 67.8%)方面的表现可与封闭的 o4 - mini 相媲美,而运行成本却仅为其几分之一。
这一发展演变凸显了核心改进之处:通过引入稀疏性来实现可扩展性,使得开放模型在无需像稠密大型模型那样产生大量计算成本的情况下,也能接近专有模型的性能。
取消 Dropout
Dropout(2012)是一种传统的防止过拟合的技术,通过在训练过程中随机“丢弃”(即将其设置为零)一部分层激活值或注意力分数来实现。然而,Dropout 在现代 LLM 中很少使用,GPT-2 之后的大多数模型都已将其丢弃。
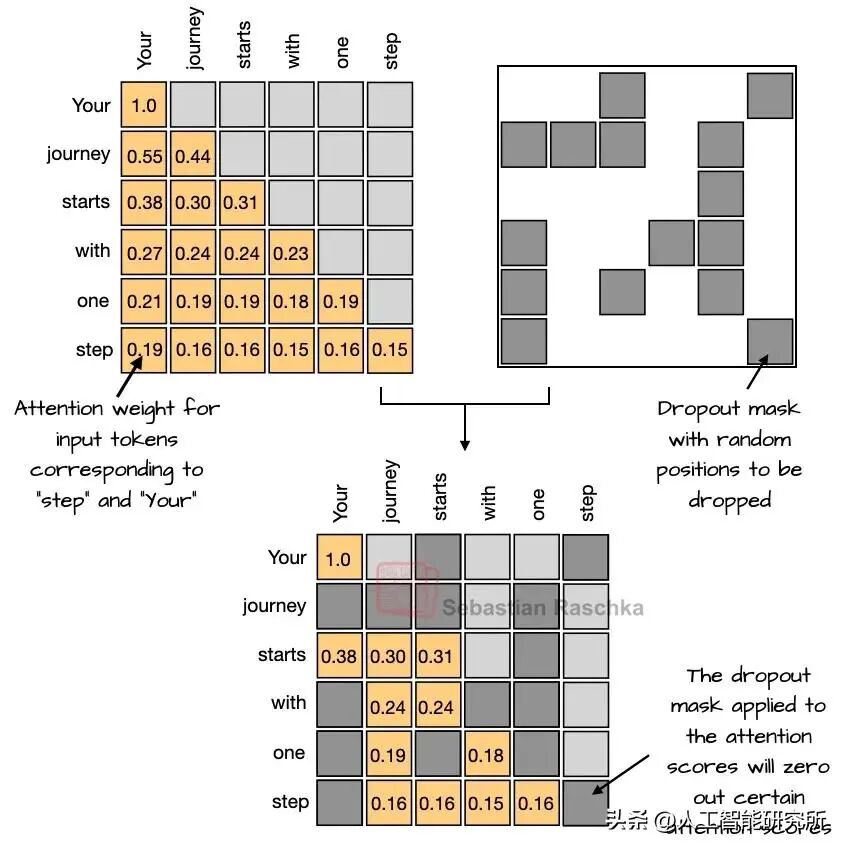
Dropout操作
Dropout 作为一种在深度学习领域广泛应用的正则化技术,最早是为了应对神经网络中的过拟合问题而被提出。推测 Dropout 最初在 GPT - 2 中被使用,其根源很可能在于 GPT - 2 继承自原始的 Transformer 架构。原始的 Transformer 架构在自然语言处理领域是一个具有开创性的模型,它为后续诸多语言模型的发展奠定了基础。许多后续的模型在设计时,都会参考和借鉴原始 Transformer 的结构和技术。GPT - 2 作为基于 Transformer 架构的模型,很自然地就沿用了 Dropout 技术。就如同建筑设计师在建造新建筑时,往往会参考经典建筑的某些设计元素一样,研究人员在开发 GPT - 2 时,遵循了 Transformer 架构的一些既定模式,将 Dropout 纳入其中。
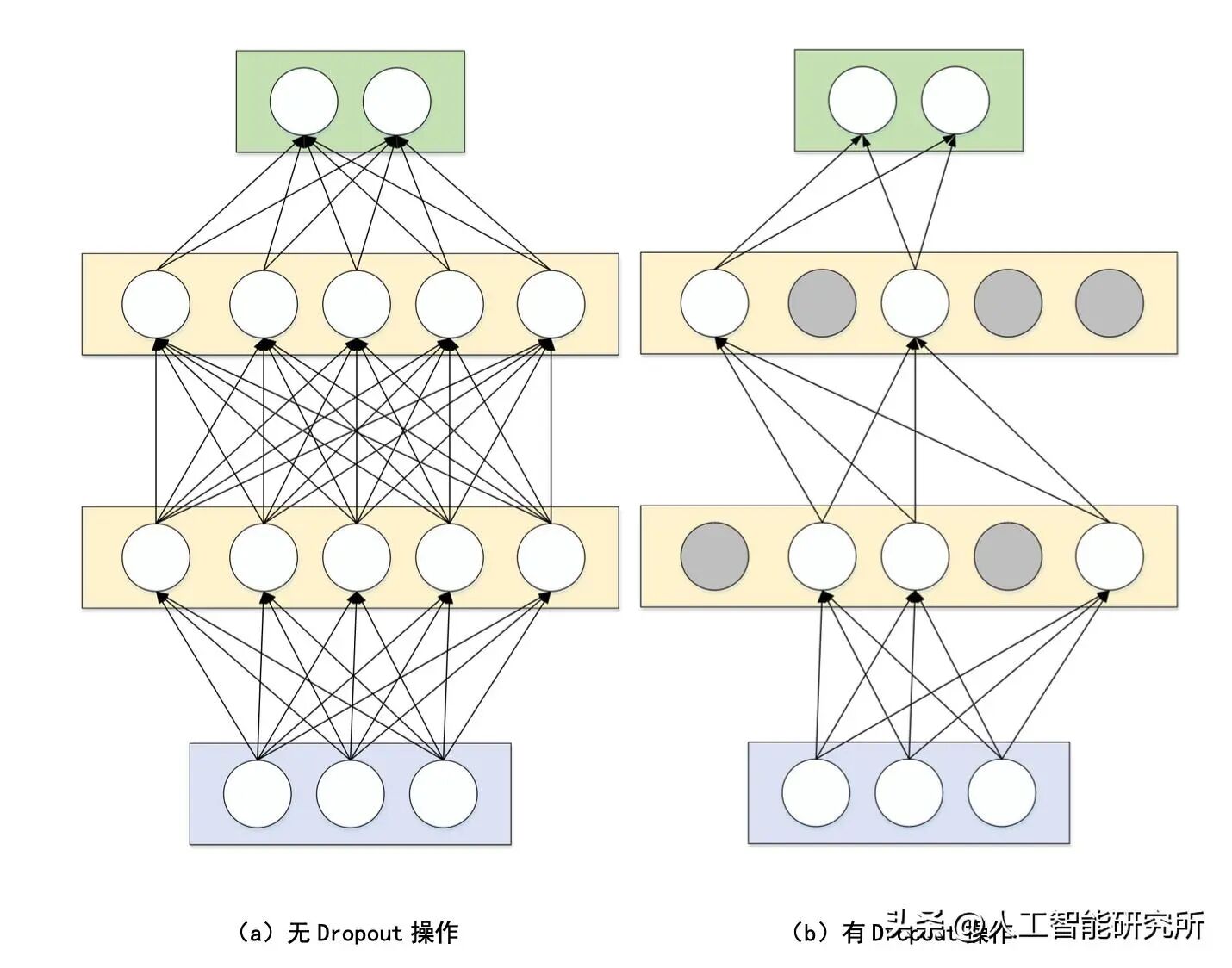
然而,随着研究的深入,研究人员可能逐渐注意到,Dropout 并没有真正提升 LLM 的性能。这一现象背后存在着深层次的原因。LLM 通常的训练方式与 Dropout 最初引入时的训练方案有着显著的差异。Dropout 最初被提出时,对应的训练场景往往是在相对较小的数据集上进行数百轮的训练。在这种训练模式下,模型有较多的机会去学习数据中的特征和规律,但同时也面临着过拟合的高风险。因为在多次重复训练过程中,模型可能会过度适应训练数据中的噪声和局部特征,从而导致在面对新数据时表现不佳。而 Dropout 通过随机忽略一部分神经元,迫使模型学习更具鲁棒性的特征,从而减少过拟合的可能性。
与之形成鲜明对比的是,LLM 通常是在海量数据集上进行单轮训练。以当前的一些大型语言模型为例,它们所使用的训练数据量可能达到数十亿甚至上百亿的文本词元(tokens)。在这种大规模的数据环境下,模型在单轮训练过程中就能够接触到丰富多样的语言模式和特征。每一个词元都代表着一种独特的语言信息,海量的数据使得模型有足够的机会去学习到通用的语言规律,而不是局限于特定数据的局部特征。的效果。这也促使研究人员在后续的模型开发中,不断探索和尝试新的技术和方法,以进一步提升大语言模型的性能和效率。
RoPE 取代绝对位置嵌入
在基于 Transformer 架构的大语言模型(LLM)里,鉴于注意力机制的特性,位置编码显得不可或缺。在默认情形下,注意力机制会把输入的词元(token)当作无序元素来处理。
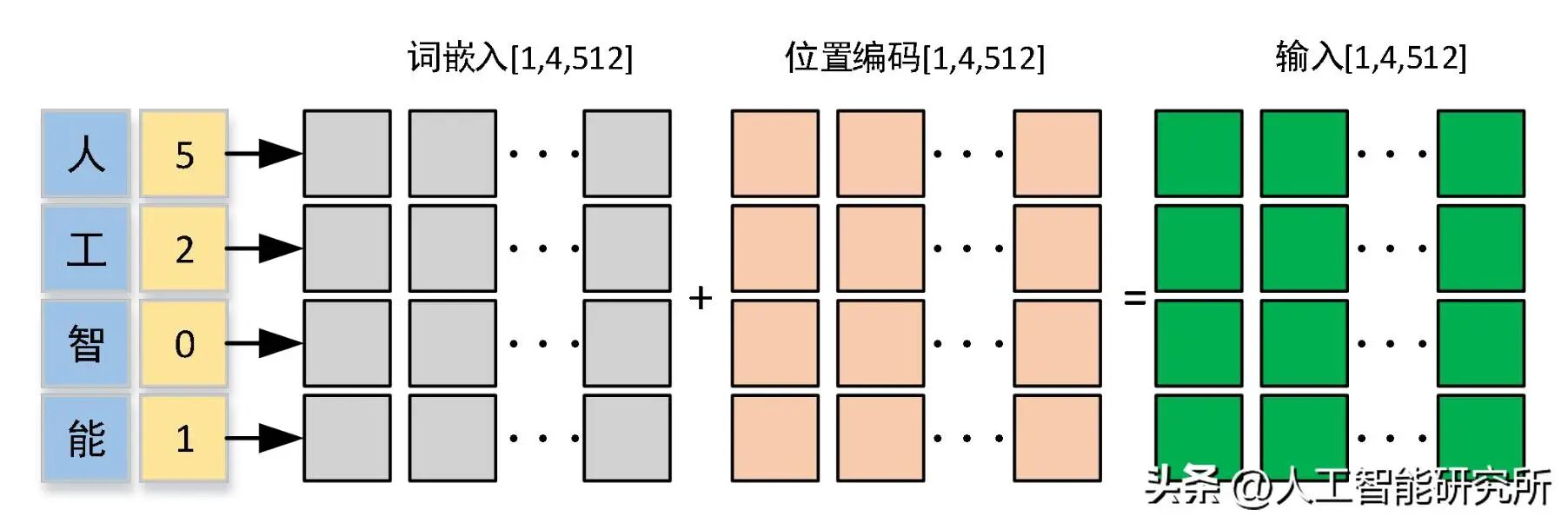
位置编码
在最初的 GPT 架构中,绝对位置嵌入通过为序列中的每个位置增添一个经过学习得到的嵌入向量来化解这一难题。随后,将该向量与词元嵌入相加,以此赋予模型位置感知能力。
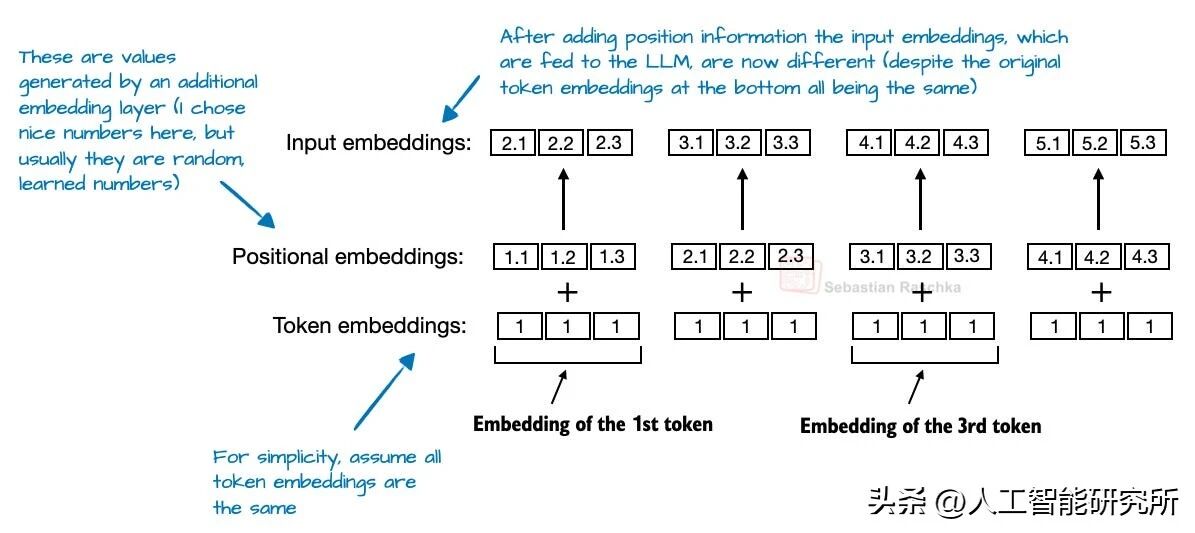
绝对位置编码
旋转位置嵌入(RoPE)则引入了别具一格的方法:它并非把位置信息作为单独的嵌入添加进去,而是依据每个标记的位置对查询向量和键向量进行旋转操作,进而实现位置编码。RoPE 这种独特的位置编码方式具有诸多优势。一方面,它能够有效地保留向量的几何结构,使得模型在处理长序列时能够更好地捕捉元素之间的相对位置关系。另一方面,RoPE 的计算效率相对较高,在大规模的语言模型训练和推理过程中,能够减少计算资源的消耗。
RoPE 于 2021 年首次问世,但在当时并没有立即引起广泛的关注和应用。这可能是因为在那个时候,学术界和工业界对于传统的位置编码方法已经有了一定的依赖,并且新的技术需要一定的时间来进行验证和推广。然而,到了 2023 年,随着原始 Llama 模型的发布,RoPE 迎来了它的高光时刻。
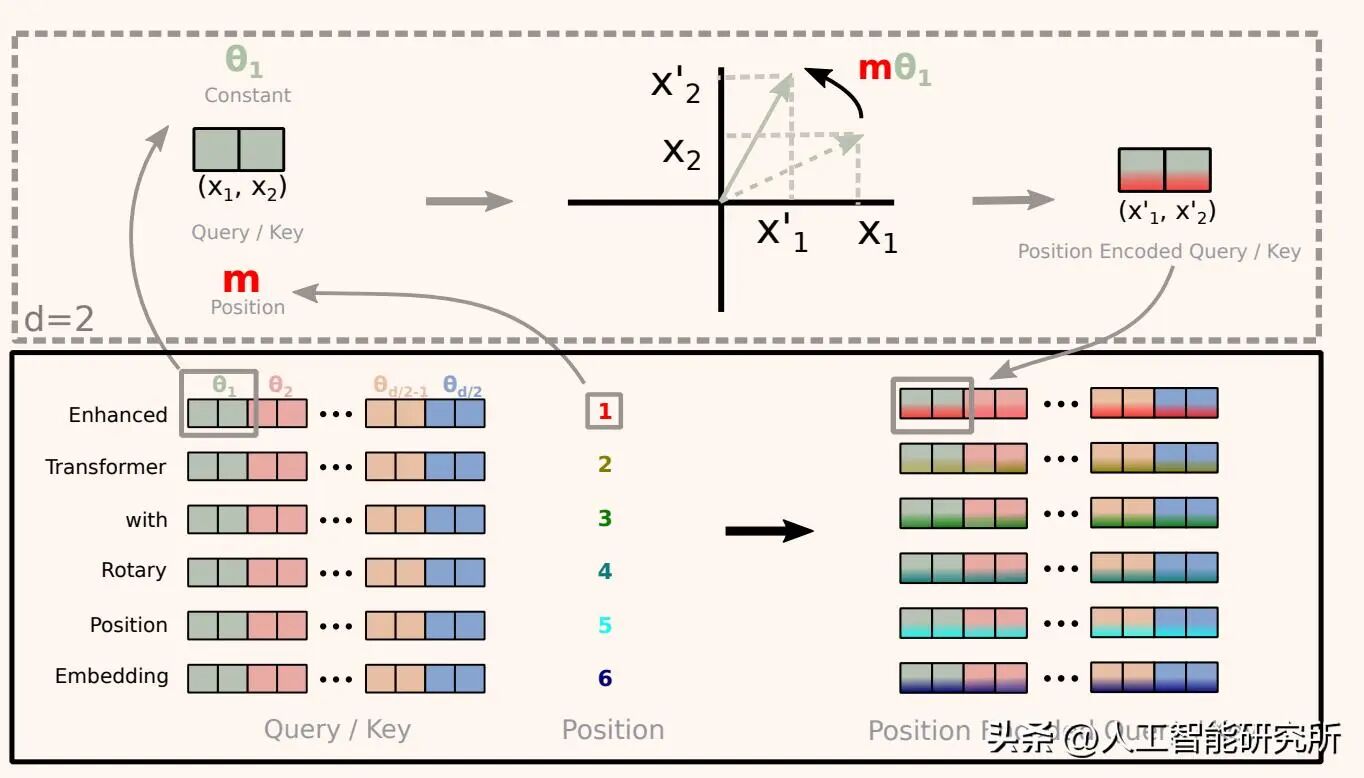
旋转位置编码
Llama 模型作为当时具有代表性的大语言模型,采用了 RoPE 作为其位置编码方案。由于 Llama 模型在性能和效果上表现出色,吸引了众多研究者和开发者的关注。随之而来的是,RoPE 也得到了广泛的应用和研究。越来越多的大语言模型开始借鉴和采用 RoPE 技术,它逐渐成为了现代大语言模型的关键组成部分。
Swish/SwiGLU 取代 GELU
早期的 GPT 架构采用 GELU 激活函数。如今,为何人们更倾向于使用 Swish 而非 GELU 呢?Swish(亦被称作 S 型线性单元或 SiLU),被认为在计算成本上略低一筹。
曾经,激活函数是深度学习领域备受热议的话题。直至十多年前,深度学习社区基本选定了 ReLU 函数。自那时起,研究人员相继提出并尝试了诸多类似 ReLU 且曲线更为平滑的变体,其中 GELU 和 Swish成为了最为人们青睐的选择。
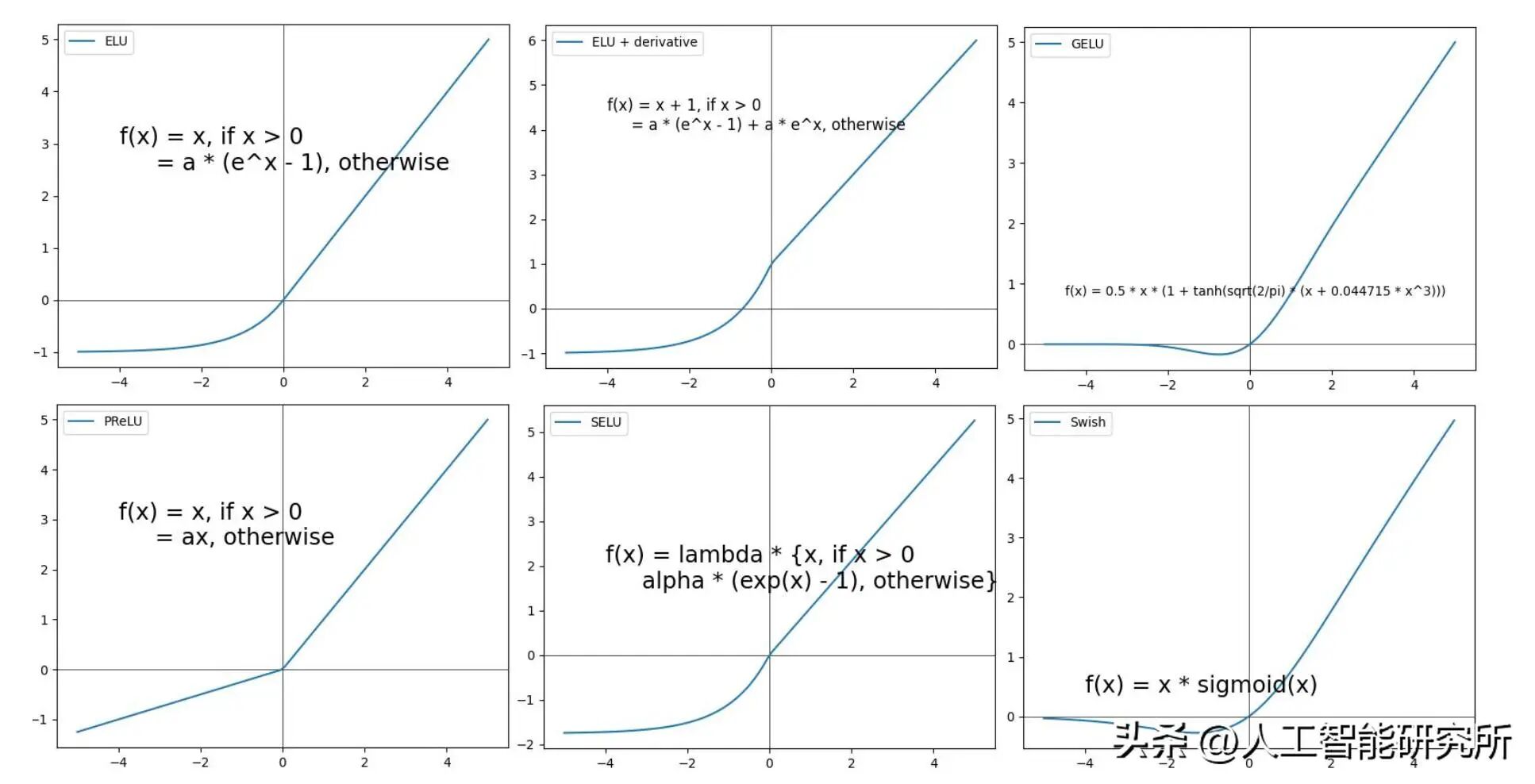
激活函数对比
早期的 GPT 架构选用 GELU,其定义为 0.5x * [1 + erf(x / sqrt(2))]。此处的 erf(误差函数的缩写)属于高斯积分,在计算时需运用高斯积分的多项式近似,这使得 GELU 的计算成本相较于 Swish 中所使用的 S 形函数要高。Swish 的表达式为 x * sigmoid(x),实际上,其计算成本略低于 GELU,这或许正是它在大多数新模型中取代 GELU 的主要缘由。
如今,大多数架构都已采用 Swish 激活函数。不过,GELU 并未被彻底遗忘。例如,谷歌的 Gemma 模型依旧在使用 GELU。更为值得关注的是,前馈模块(一个小型多层感知器)已被门控“GLU”模块所取代。GLU 是门控线性单元的缩写,它是在 2020 年的一篇论文中被提出的。具体而言,原本的 2 个全连接层被 3 个全连接层所替代。
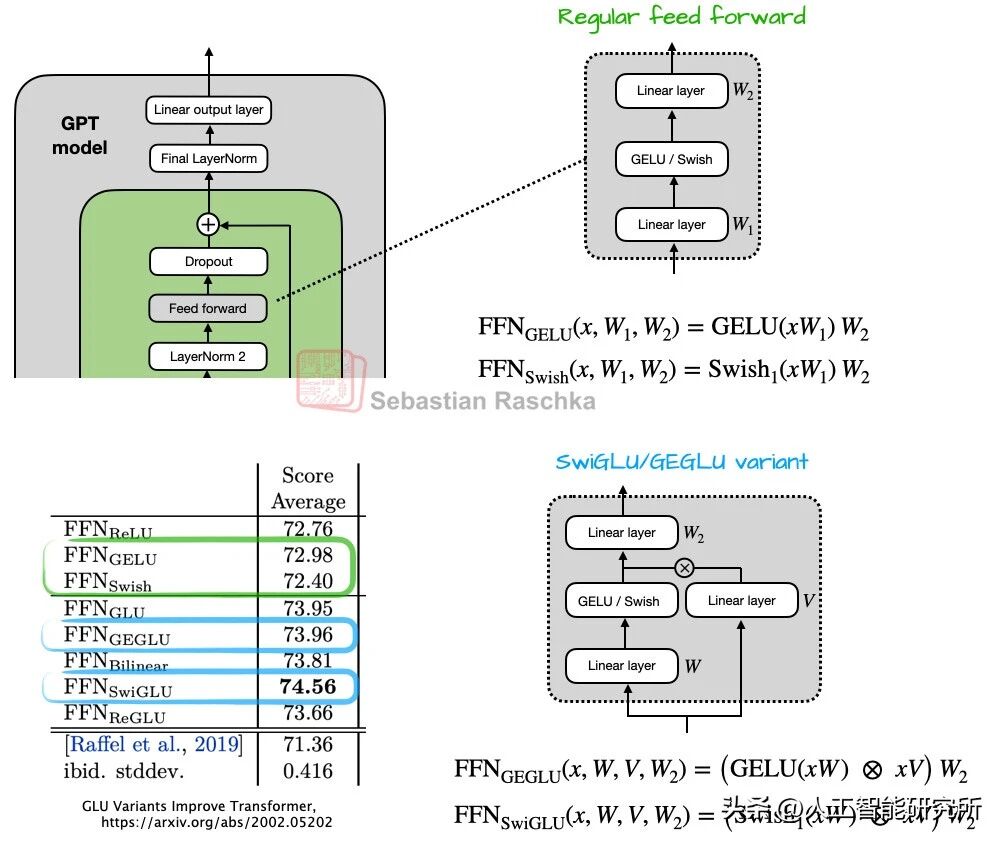
GLU
总体而言,使用 GLU 变体能够在减少参数数量的同时,提升模型性能。性能得以提升的原因在于,这些 GLU 变体提供了额外的乘法交互,从而增强了模型的表达能力(同理,若训练得当,深层细长的神经网络在性能上会优于浅层宽广的神经网络)。
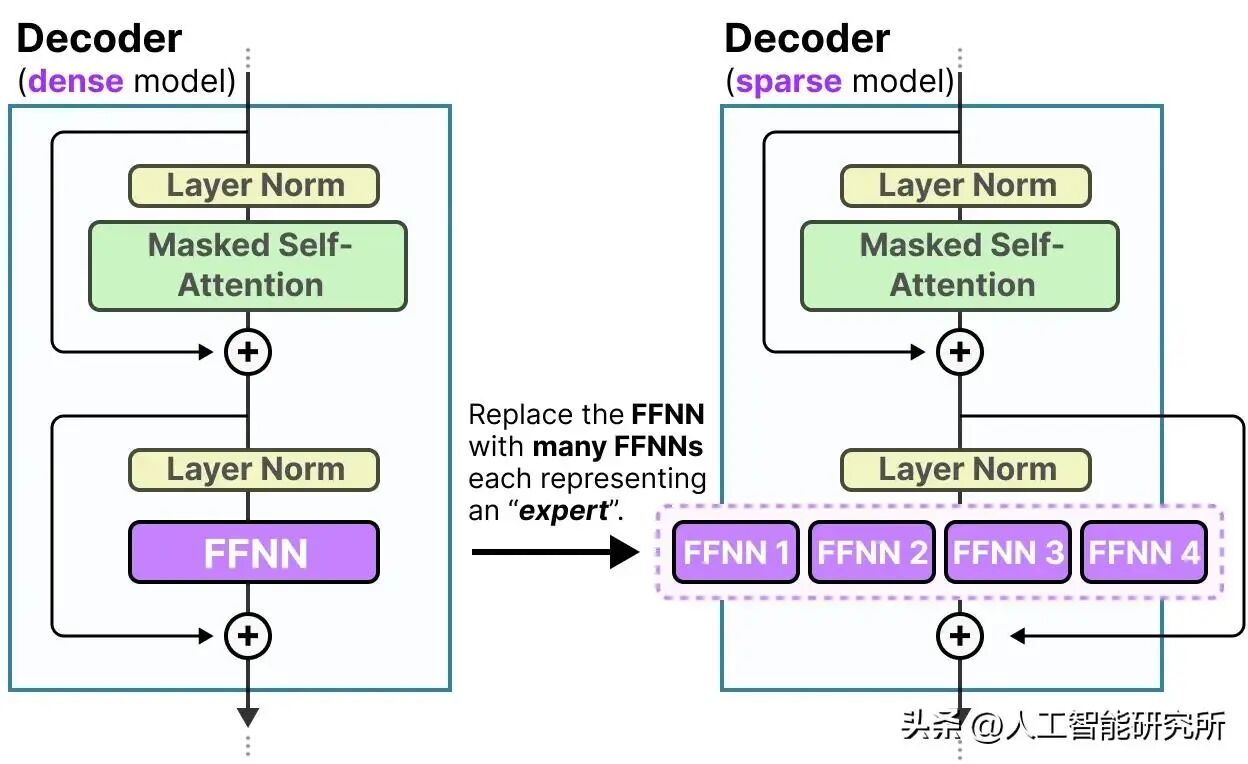
混合专家模型取代单一前馈模块
除了把前馈模块升级为 SwiGLU 之外,GPT - OSS 还以多个前馈模块替代了单个前馈模块,在每个词元(token)生成步骤中仅运用其中一个子集。这种方法被称作混合专家模型(MoE)。
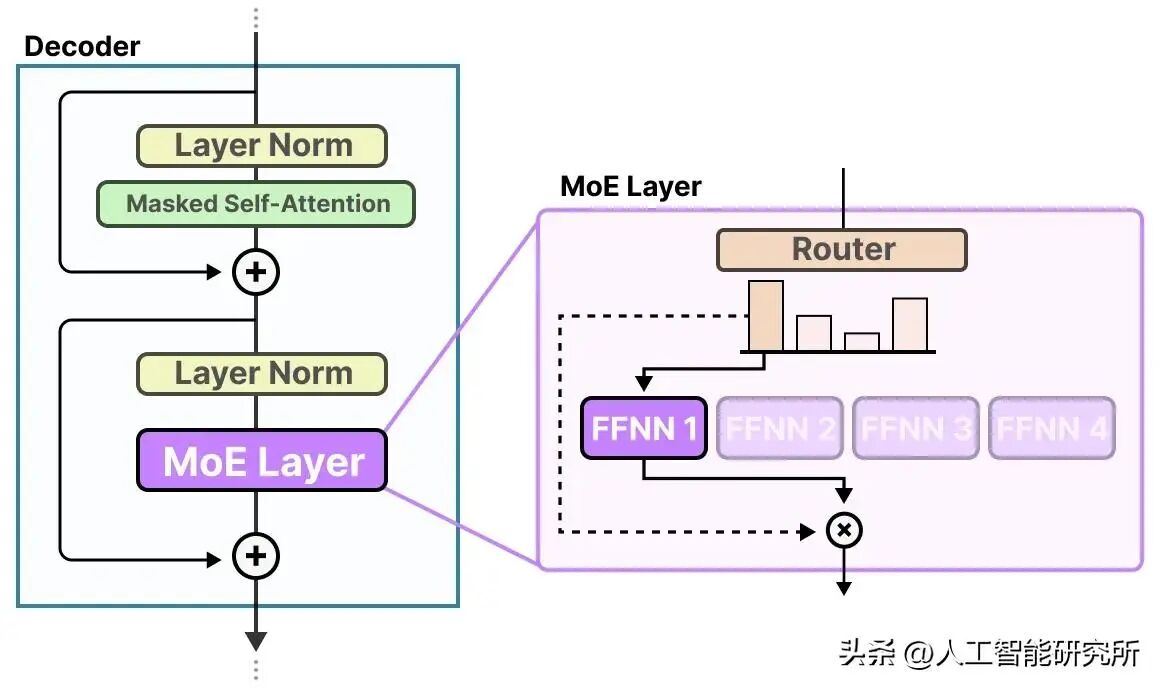
混合专家模型
将单个前馈模块替换为多个前馈模块,会显著增加模型的总参数数量。但关键之处在于,我们并非为每个词元“激活”所有专家。相反,路由网络会为每个词元仅挑选一小部分专家。
由于每次仅有少数专家处于激活状态,所以 MoE 模块通常被称为稀疏模块,这与始终使用完整参数集的密集模块形成鲜明对照。借助 MoE 所增加的大量参数,提升了大语言模型(LLM)的容量,这意味着模型在训练期间能够吸纳更多知识。同时,稀疏性确保了推理过程的高效性,因为我们不会同时启用所有参数。
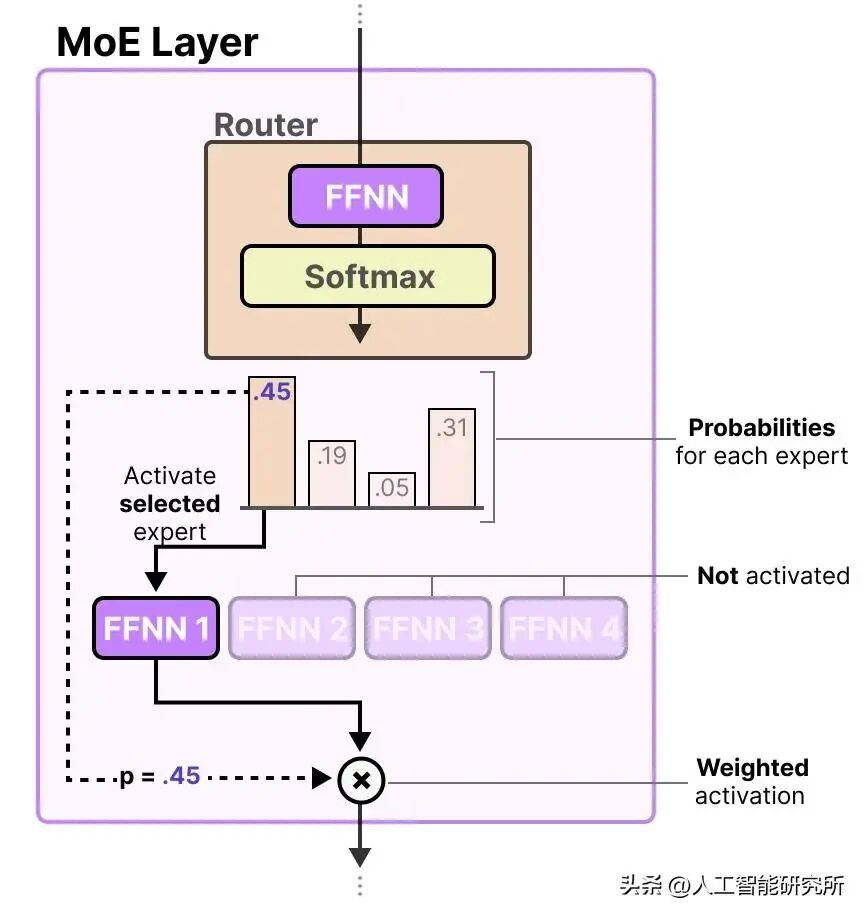
激活部分专家
分组查询注意力机制取代多头注意力机制
分组查询注意力(GQA)近年来已成为多头注意力(MHA)更高效的计算和参数替代方案。在 MHA 中,每个 head 都有自己的一组键和值。GQA 通过将多个 head 分组以共享相同的键和值投影来减少内存使用量。
如果有 2 个键值组和 4 个注意力头,则注意力头 1 和 2 可能共享一组键值对,而注意力头 3 和 4 则共享另一组键值对。根据消融研究,这种分组减少了键值对的计算总量,从而降低了内存使用量并提高了效率,同时对建模性能没有显著影响。
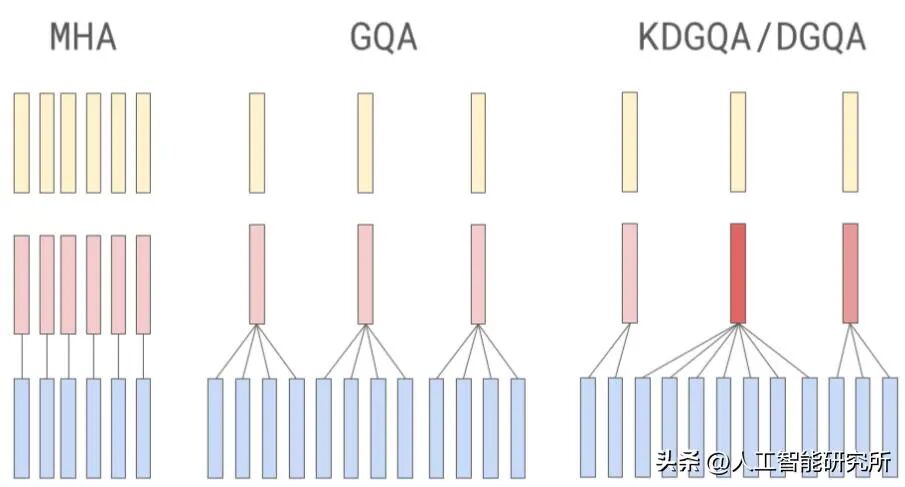
MHA 与 GQA 的比较。
因此,GQA 的核心思想是通过在多个查询头之间共享键值头来减少键值头的数量。这可以降低模型的参数数量,还可以减少推理过程中键值张量的内存带宽占用,因为需要存储和从键值缓存中检索的键值更少。
虽然 GQA 主要是 MHA 的一种计算效率解决方法,但消融研究(例如原始 GQA 论文和Llama 2 论文中的研究)表明,就 LLM 建模性能而言,它的表现与标准 MHA 相当。
滑动窗口注意力
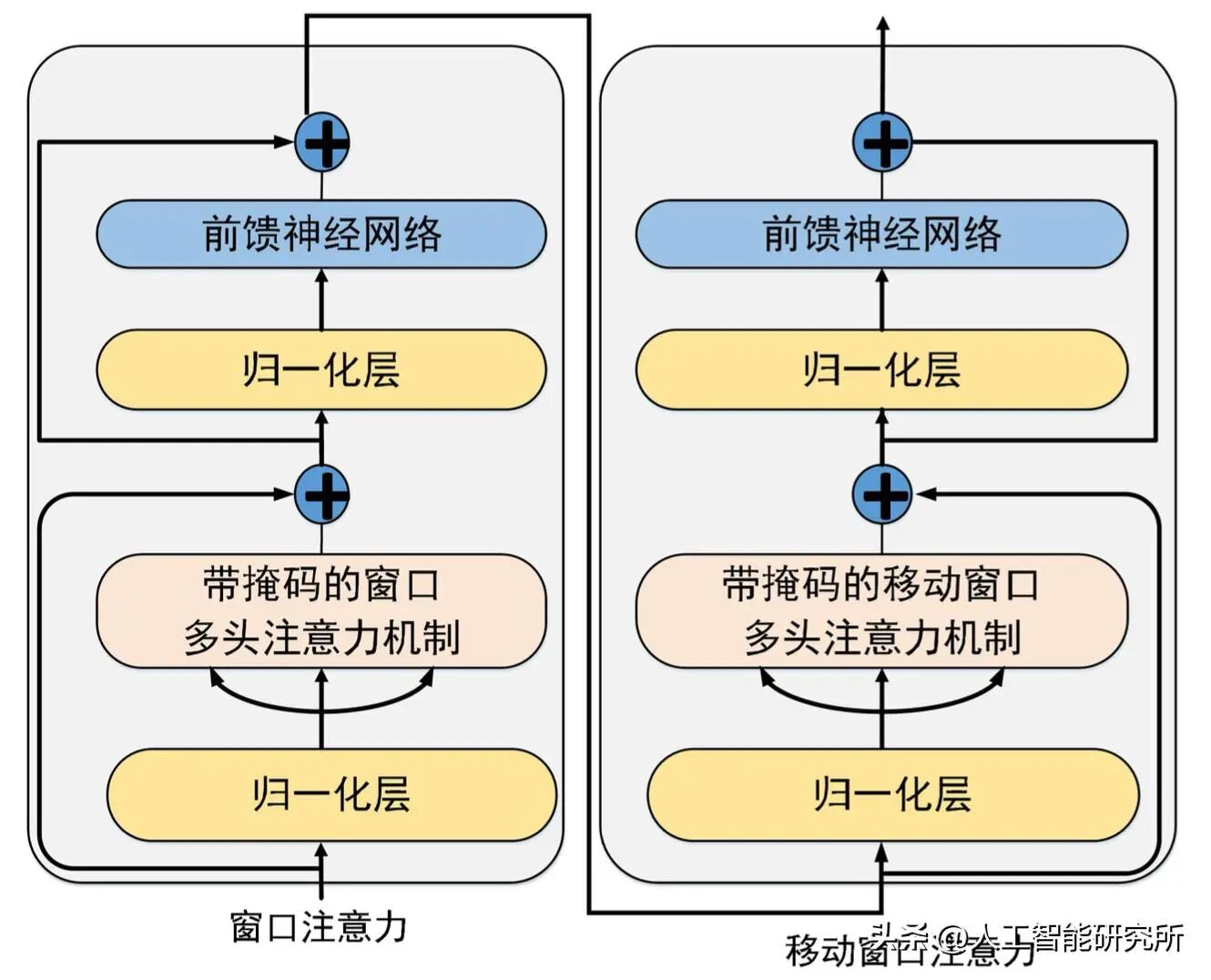
swin transformer 模型的移动窗口
滑动窗口注意力机制最早在LongFormer 论文(2020 年)中提出,后来由 Mistral 推广。窗口注意力机制,我们前期介绍 swin transformer模型也有详细的介绍。有趣的是,GPT-OSS 每隔一层就应用一次滑动窗口注意力机制。你可以将其视为多头注意力机制一种变体,其中注意力上下文被限制在一个较小的窗口中,从而同时降低了内存使用量和计算成本。
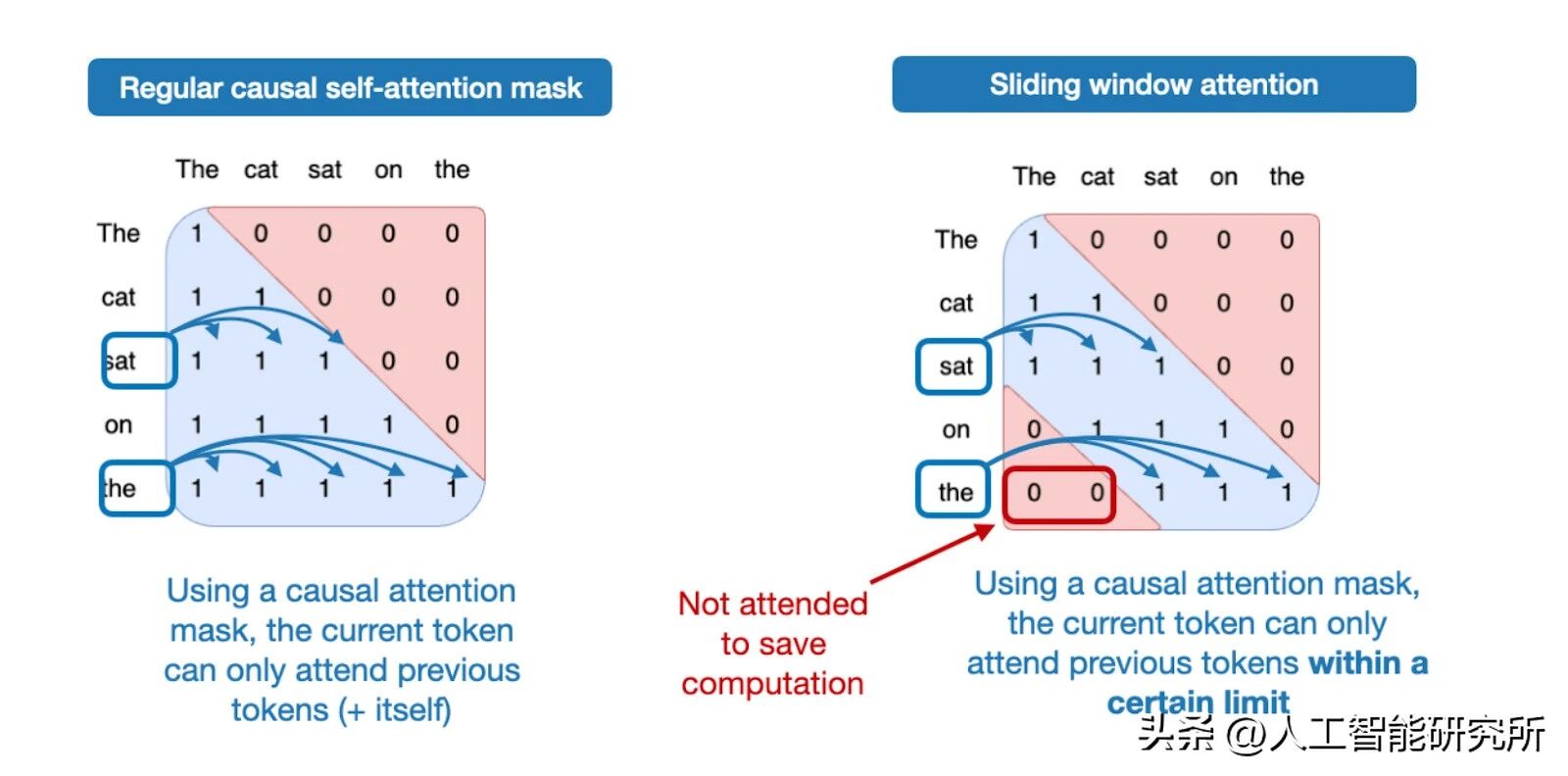
常规注意力(左)和滑动窗口注意力(右)的比较。
具体来说,gpt-oss 在关注完整上下文的 GQA 层和滑动窗口限制为 128 个标记的 GQA 层之间交替。Gemma 2 (2024)采用了类似的 1:1 比例。Gemma 3则更进一步,改为 5:1 的比例,这意味着每五个滑动窗口(局部)注意力层对应一个全注意力层。
根据 Gemma 的消融研究,滑动窗口注意力机制对建模性能的影响微乎其微。需要注意的是,Gemma 2 中的窗口大小为 4096 个 token,而 Gemma 3 中将其缩减至 1024 个。在 GPT-OSS 中,窗口大小仅为 128 个 token,非常小。
RMSNorm取代LayerNorm
最后,GPT - 2 做出的最后一项细微调整是,以均方根归一化(RMSNorm,2019 年提出)取代了层归一化(LayerNorm,2016 年提出),这也是近年来颇为普遍的趋势。正如用 Swish 和 SwiGLU 替换 GELU 一样,RMSNorm 属于这类虽小却卓有成效的效率改进举措之一。
RMSNorm 与 LayerNorm 颇为相似,二者的目标均是对层激活进行归一化处理。不久之前,批量归一化(BatchNorm)还是此项任务的首选方法。然而,后来它逐渐不再受青睐,主要原因在于,它在有效并行化方面存在困难(这是由于均值和方差的批次统计数据所致),并且在小批量数据的情况下表现欠佳。
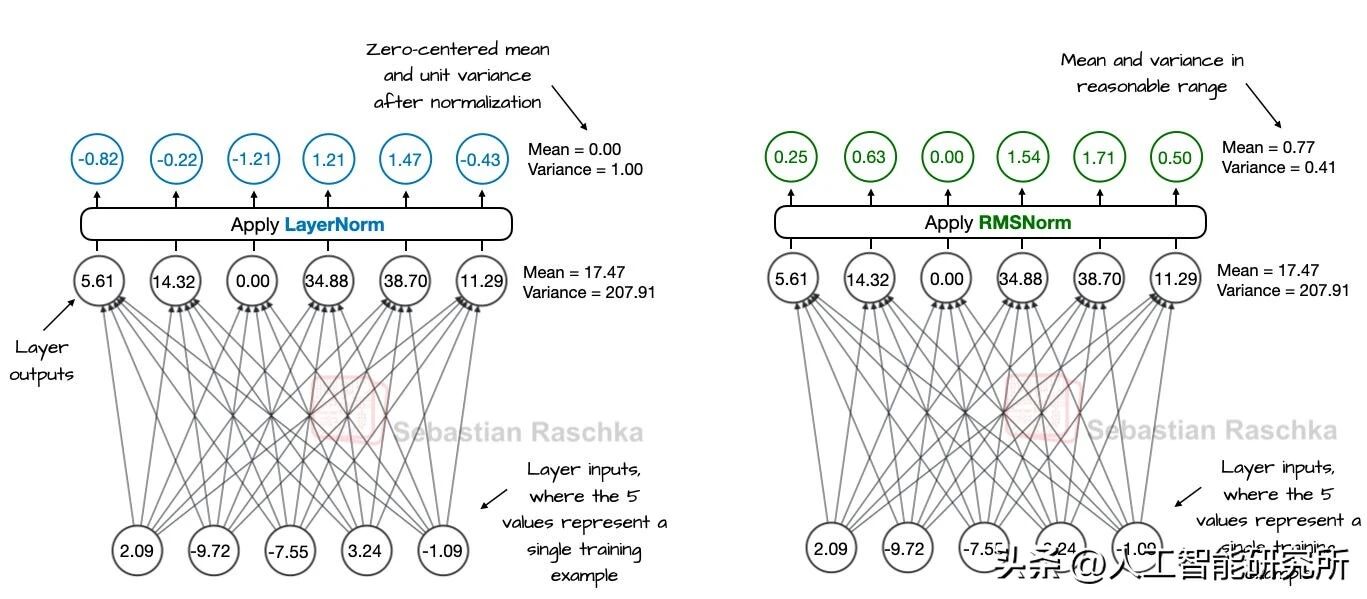
小型线性层的 LayerNorm(左)和 RMSNorm(右)的比较。
层归一化(LayerNorm)与均方根归一化(RMSNorm)皆可稳定激活尺度,优化训练效果。然而,在大规模大语言模型(LLM)的应用场景中,RMSNorm 往往更胜一筹,备受青睐,究其根源在于其具备更低的计算成本。
相较于 LayerNorm,RMSNorm 摒弃了偏差(移位)项,巧妙地将复杂且成本高昂的均值与方差计算过程,简化为单一的均方根运算。这一精妙的设计,使得跨特征约简的次数从两次锐减至一次。如此一来,图形处理器(GPU)在数据通信时的开销得以显著降低,模型训练效率也随之大幅提升。
写在最后
在研习大语言模型(LLM)之际,Transformer 模型堪称绝佳的入门架构。它的结构简洁明晰,能让学习者免于在纷繁复杂的层层优化技巧中迷失方向;同时,其复杂程度又恰到好处,足以使学习者扎实掌握现代 Transformer 模型的运行原理。
借助该模型,学习者能够聚焦于基础知识,如注意力机制、位置嵌入、规范化操作以及整体训练流程,而不会被新架构里的额外功能与调整所干扰、淹没。
无论是迫于舆论压力,还是为了得到开源论坛的支持,OpenAI 能够开源自家模型,也是给开源爱好者提供了一个研究的方向。
更多transformer,VIT,swin tranformer
参考头条号:人工智能研究所
v号:人工智能研究Suo, 启示AI科技动画详解transformer 在线视频教程

