小红书数据分析面试题及参考答案
如何在 Python 中计算标准差(要求:不能使用任何现成的函数,需手动实现)?
计算标准差的核心是衡量数据集中各个数据点与数据集平均值之间的离散程度,手动实现需严格遵循数学公式。首先需明确标准差分为总体标准差和样本标准差,二者的主要区别在于分母:总体标准差除以数据个数N,样本标准差除以N-1(为了修正样本对总体的估计偏差)。
具体实现步骤如下:第一步,计算数据集的平均值,即所有数据之和除以数据个数;第二步,计算每个数据点与平均值的偏差(差值);第三步,求每个偏差的平方(避免正负抵消);第四步,计算平方偏差的平均值(总体标准差用总和除以N,样本标准差用总和除以N-1);第五步,对平方偏差的平均值开平方,得到标准差。
在代码实现时,需注意边界条件:若数据集为空,需抛出异常;若数据集中只有一个数据点,样本标准差会出现除以0的情况,需特殊处理。以下是具体代码示例:
import mathdef calculate_std(data, is_population=True):# 检查数据是否为空if not data:raise ValueError("数据集不能为空")n = len(data)# 计算平均值mean = sum(data) / n# 计算平方偏差总和squared_deviations = [(x - mean) **2 for x in data]sum_squared = sum(squared_deviations)# 计算方差(总体或样本)if is_population:variance = sum_squared / nelse:if n == 1:raise ValueError("样本数据至少需要2个数据点")variance = sum_squared / (n - 1)# 开平方得到标准差return math.sqrt(variance)
面试关键点:需清晰区分总体与样本标准差的差异;处理异常情况(空数据、样本量不足)体现代码健壮性;理解每一步计算的数学意义,而非单纯实现步骤。
记忆法:可采用“流程记忆法”,按“均值计算→偏差平方→平方和平均→开方”的步骤链记忆,同时用“N与N-1”的差异点区分总体与样本。
手撕快速排序算法。
快速排序是一种高效的排序算法,基于分治法思想,核心流程为“选择基准值→分区→递归排序”。其时间复杂度平均为O(n log n),最坏情况为O(n²),但通过合理选择基准值可避免最坏情况。
具体实现步骤:第一步,选择一个基准值(通常可选数组第一个元素、最后一个元素或中间元素,此处选择第一个元素);第二步,分区操作,将数组中小于基准值的元素放在基准值左侧,大于基准值的元素放在右侧,等于基准值的元素可放任意一侧;第三步,对基准值左侧和右侧的子数组分别递归执行快速排序,直至子数组长度小于等于1(递归终止条件)。
代码实现需注意:分区操作需高效,可通过双指针(左右指针)交换元素实现;处理重复元素时需避免不平衡分区;递归终止条件需明确(子数组长度≤1)。以下是完整代码:
def quick_sort(arr):# 递归终止条件:数组长度小于等于1时无需排序if len(arr) <= 1:return arrelse:# 选择第一个元素作为基准值pivot = arr[0]# 分区:小于基准的元素放left,大于等于的放rightleft = [x for x in arr[1:] if x < pivot]right = [x for x in arr[1:] if x >= pivot]# 递归排序左右子数组,并与基准值合并return quick_sort(left) + [pivot] + quick_sort(right)
上述代码为简洁版,实际面试中可优化分区方式(如双指针原地分区)以减少空间复杂度。原地分区实现如下:
def quick_sort_in_place(arr, low=0, high=None):if high is None:high = len(arr) - 1# 递归终止条件if low >= high:return# 分区操作,返回基准值最终位置pivot_index = partition(arr, low, high)# 递归排序左右子数组quick_sort_in_place(arr, low, pivot_index - 1)quick_sort_in_place(arr, pivot_index + 1, high)def partition(arr, low, high):# 选择最右侧元素作为基准值pivot = arr[high]# i指向小于基准区域的右边界i = low - 1# 遍历除基准外的元素for j in range(low, high):if arr[j] <= pivot:i += 1# 交换元素到小于基准区域arr[i], arr[j] = arr[j], arr[i]# 将基准值放到最终位置(i+1)arr[i + 1], arr[high] = arr[high], arr[i + 1]return i + 1
面试关键点:理解分治法思想;说明基准值选择对性能的影响(如随机选择基准可避免最坏情况);区分普通实现与原地排序的空间复杂度差异(前者O(n),后者O(log n)递归栈)。
记忆法:采用“三字诀记忆法”——“选基准、分左右、再递归”,对应快速排序的核心步骤,帮助快速回忆算法框架。
你使用 Python 的熟练程度如何?常用的 Python 模块有哪些?
在 Python 使用熟练程度上,可从实际应用场景、问题解决能力和代码优化能力三方面描述:能独立完成从数据获取、清洗、分析到可视化的全流程任务;熟练运用函数式编程、面向对象编程思想,编写可复用、易维护的代码;能针对性能瓶颈(如大数据处理)进行优化,例如使用生成器减少内存占用、通过向量化操作替代循环等;熟悉常见错误处理和调试技巧,能快速定位并解决问题。
常用 Python 模块可按数据分析工作流分类:
数据获取与预处理模块:pandas 是核心工具,提供 Series、DataFrame 数据结构,支持缺失值处理(fillna)、重复值删除(drop_duplicates)、数据类型转换(astype)等;numpy 用于数值计算,提供高效数组操作,支持广播机制和矩阵运算,是 pandas 的底层依赖;xlrd/xlwt/openpyxl 用于读写 Excel 文件;requests 用于发送 HTTP 请求获取网页数据;json 用于解析 JSON 格式数据。
数据分析与统计模块:scipy 包含线性代数、概率统计、优化等工具,如 scipy.stats 可进行正态性检验、t检验等;statsmodels 专注于统计建模,支持线性回归、逻辑回归、时间序列分析(如ARIMA)等,输出详细的统计量(p值、R²等);pandas 也内置了基础统计函数(如mean、std、corr)。
数据可视化模块:matplotlib 是基础可视化库,支持折线图、柱状图、散点图等,可高度定制图表样式;seaborn 基于 matplotlib,简化了复杂图表绘制(如热力图、小提琴图),且默认样式更美观;plotly 支持交互式可视化,适合制作可缩放、悬停显示细节的图表,便于网页展示。
数据库交互模块:sqlalchemy 提供统一的数据库接口,支持 MySQL、PostgreSQL 等多种数据库,可通过 ORM 操作数据,也可执行原生 SQL;pymysql 用于直接连接 MySQL 数据库,执行 SQL 语句。
机器学习模块:scikit-learn 涵盖分类、回归、聚类等算法,提供数据预处理(标准化、归一化)、模型训练、评估(accuracy、F1-score)等功能,API 设计统一,易于使用;xgboost、lightgbm 用于梯度提升树模型,适合处理结构化数据,在竞赛中常用。
面试关键点:需结合具体项目经验说明模块使用场景(如“用 pandas 的 merge 函数处理多表关联,解决了用户行为数据与订单数据的匹配问题”);提及模块底层原理或优化技巧(如“pandas 中尽量使用内置方法而非 apply,因为内置方法基于 C 实现,速度更快”)可加分。
记忆法:采用“场景分类记忆法”,按“数据获取→清洗→分析→可视化→建模”的工作流程串联模块,每个环节对应2-3个核心模块,便于系统记忆。
请设计 SQL 语句,分析用户的登录时长相关数据(如计算用户日均登录时长、各时段登录时长分布等)。
分析用户登录时长需基于用户登录日志表,假设表名为user_login_log,包含字段:user_id(用户ID)、login_time(登录时间,datetime类型)、logout_time(登出时间,datetime类型)。若存在用户未主动登出的情况(如强制下线),需确保logout_time有默认值(如会话超时时间)。
计算用户日均登录时长:需先计算每次登录的时长(logout_time - login_time),转换为分钟或小时,再按user_id和登录日期分组,求每日总时长的平均值。SQL语句如下:
-- 计算用户日均登录时长(单位:分钟)
SELECT user_id,DATE(login_time) AS login_date,SUM(TIMESTAMPDIFF(MINUTE, login_time, logout_time)) AS daily_total_minutes,AVG(SUM(TIMESTAMPDIFF(MINUTE, login_time, logout_time))) OVER (PARTITION BY user_id) AS avg_daily_minutes
FROM user_login_log
WHERE logout_time IS NOT NULL -- 排除未登出的异常记录
GROUP BY user_id, DATE(login_time)
ORDER BY user_id, login_date;
各时段登录时长分布:将一天划分为多个时段(如每2小时一个时段),统计每个时段的总登录时长及占比。SQL语句如下:
-- 各时段登录时长分布(按2小时划分时段)
SELECT hour_segment,SUM(login_duration_min) AS total_duration_min,ROUND(SUM(login_duration_min) / SUM(SUM(login_duration_min)) OVER (), 4) AS proportion
FROM (-- 子查询:计算每次登录的时长及所属时段SELECT TIMESTAMPDIFF(MINUTE, login_time, logout_time) AS login_duration_min,-- 划分时段(0-2点、2-4点...22-24点)CONCAT(FLOOR(HOUR(login_time) / 2) * 2, '-', (FLOOR(HOUR(login_time) / 2) + 1) * 2, '点') AS hour_segmentFROM user_login_logWHERE logout_time IS NOT NULL
) AS login_details
GROUP BY hour_segment
ORDER BY hour_segment;
额外分析场景:用户登录时长的分布特征(如中位数、90分位数),可用于识别高频活跃用户:
-- 用户登录时长的分位数统计
SELECT PERCENTILE_CONT(0.5) WITHIN GROUP (ORDER BY login_duration_min) AS median_duration,PERCENTILE_CONT(0.9) WITHIN GROUP (ORDER BY login_duration_min) AS p90_duration
FROM (SELECT TIMESTAMPDIFF(MINUTE, login_time, logout_time) AS login_duration_minFROM user_login_logWHERE logout_time IS NOT NULL
) AS duration_details;
面试关键点:需明确表结构假设,说明时间函数的使用(如TIMESTAMPDIFF、HOUR);处理异常数据(如logout_time为空)体现数据清洗意识;结合业务场景解释指标意义(如时段分布可用于调整客服资源配置)。
记忆法:采用“指标-步骤”对应记忆法,每个分析指标(如日均时长)对应“计算单次时长→按用户和日期分组→聚合求平均”的步骤,便于快速构建SQL逻辑。
假设有两道 SQL 题目(如查询特定条件数据、统计汇总数据等),请先写出 SQL 语句,再说明如何对该 SQL 语句进行优化。
题目一:查询特定条件数据需求:从orders表(订单表)中查询2023年第四季度(10-12月),用户等级(user_level)为“VIP”且订单金额(amount)大于1000元的订单信息,包括order_id、user_id、order_time、amount。
SQL语句:
SELECT order_id, user_id, order_time, amount
FROM orders
WHERE user_level = 'VIP'AND amount > 1000AND order_time BETWEEN '2023-10-01 00:00:00' AND '2023-12-31 23:59:59';
优化方法:
- 索引优化:为查询条件中的字段创建联合索引
idx_user_level_time_amount(user_level,order_time,amount)。理由:WHERE子句中user_level是等值查询,order_time是范围查询,amount是范围查询,联合索引可加速条件过滤,且覆盖查询字段(无需回表查询)。 - 避免函数操作:若
order_time字段上有函数(如YEAR(order_time)),会导致索引失效,应直接使用BETWEEN进行范围查询。 - 限制返回字段:只查询需要的
order_id、user_id等字段,避免使用SELECT *,减少数据传输量。
题目二:统计汇总数据
需求:统计2023年每个月各地区(region)的订单总金额(total_amount)、订单数(order_count),并按月份和总金额降序排列。
SQL语句:
SELECT DATE_FORMAT(order_time, '%Y-%m') AS month,region,SUM(amount) AS total_amount,COUNT(order_id) AS order_count
FROM orders
WHERE order_time BETWEEN '2023-01-01 00:00:00' AND '2023-12-31 23:59:59'
GROUP BY month, region
ORDER BY month DESC, total_amount DESC;
优化方法:
- 索引优化:创建联合索引
idx_time_region_amount(order_time,region,amount)。理由:order_time用于过滤年份,region用于分组,amount用于聚合计算,索引可加速过滤和分组操作。 - 分组优化:若
region字段存在大量重复值(如只有少数几个地区),可考虑先过滤再分组;若order_time范围较大,可通过分区表(按时间分区)减少扫描范围。 - 排序优化:
ORDER BY使用的字段(month,total_amount)中,month可通过索引顺序获取,total_amount是聚合结果,可通过临时表或内存排序优化,避免磁盘排序(调整sort_buffer_size参数)。 - 避免全表扫描:确保
WHERE子句的order_time条件有效过滤数据,减少参与分组和聚合的行数。
面试关键点:优化需结合执行计划(通过EXPLAIN分析);索引设计需遵循“最左前缀原则”;区分不同场景下的优化优先级(如小表适合全表扫描,大表必须依赖索引)。
记忆法:采用“优化维度记忆法”,从“索引设计→过滤条件→聚合排序→资源配置”四个维度记忆SQL优化方向,每个维度对应具体操作(如索引设计考虑联合索引和覆盖索引)。
SQL 中 HAVING 子句和 WHERE 子句的区别是什么?
HAVING 子句和 WHERE 子句在 SQL 中均用于过滤数据,但二者的作用阶段、适用对象和功能有本质区别,具体差异可从以下几方面展开:
作用阶段不同。WHERE 子句用于在数据分组(GROUP BY)之前过滤行,仅保留满足条件的原始数据行进入分组阶段;而 HAVING 子句用于在数据分组之后过滤分组结果,仅保留符合条件的分组。例如,若要查询“订单金额大于 1000 元的订单所属的部门”,需先用 WHERE 过滤出金额>1000 的订单行,再按部门分组;若要查询“部门总订单金额大于 10000 元的部门”,则需先按部门分组计算总金额,再用 HAVING 过滤总金额>10000 的分组。
适用对象不同。WHERE 子句的过滤对象是原始数据行,只能使用表中的字段作为过滤条件,不能直接使用聚合函数(如 SUM、COUNT 等),因为聚合函数需要基于分组计算,而 WHERE 执行时分组尚未完成;HAVING 子句的过滤对象是分组后的结果,因此可以使用聚合函数作为过滤条件,也可使用分组字段(GROUP BY 后的字段)。例如,WHERE amount > 1000 是合法的(过滤单行金额),但 WHERE SUM(amount) > 10000 不合法;而 HAVING SUM(amount) > 10000 是合法的(过滤分组总金额)。
使用场景不同。WHERE 适用于筛选基础数据,减少进入分组阶段的数据量,提高效率;HAVING 适用于对分组结果进行二次筛选,常用于需要基于聚合结果做条件判断的场景。例如,“查询 2023 年注册且订单数大于 5 的用户”,需先用 WHERE register_time >= '2023-01-01' 筛选 2023 年注册用户,再按用户分组后用 HAVING COUNT(order_id) > 5 过滤订单数达标的用户。
面试关键点:需明确区分二者的执行顺序(WHERE 在前,HAVING 在后);强调 HAVING 与 GROUP BY 的绑定关系(无 GROUP BY 时,HAVING 相当于 WHERE,但不推荐);举例说明聚合函数在两种子句中的合法性差异。
记忆法:采用“阶段-对象”记忆法,即“WHERE 管行前过滤(分组前,针对行),HAVING 管组后过滤(分组后,针对组,可带聚合)”,通过阶段和对象的对应关系快速区分。
请说明 B 树和 B+ 树的区别。
常用的关系型数据库(如 MySQL、PostgreSQL)的索引主要采用 B+ 树作为数据结构,因其在磁盘 IO 效率、范围查询等方面的优势更适合数据库场景。B 树和 B+ 树均为多路平衡查找树,但在结构、功能和性能上有显著区别,具体如下:
结构差异。B 树的每个节点(包括非叶子节点和叶子节点)既存储索引键,也存储对应的数据记录;而 B+ 树的非叶子节点仅存储索引键(作为导航索引),只有叶子节点存储数据记录,且所有叶子节点通过双向链表连接,形成一个有序链表。例如,B 树的一个非叶子节点可能包含 (key1, data1), (key2, data2),而 B+ 树的非叶子节点只包含 (key1, pointer1), (key2, pointer2),指针指向子节点,叶子节点包含 (key1, data1), (key2, data2) 并通过链表相连。
查询效率。B 树的查询可能在非叶子节点终止(找到匹配的 key 即可返回数据),因此不同 key 的查询路径长度可能不同,效率不稳定;B+ 树的所有查询都必须遍历到叶子节点(因为数据只在叶子节点),因此查询效率更稳定,且由于非叶子节点仅存索引,相同大小的节点可存储更多 key,树的高度更低,减少磁盘 IO 次数(磁盘 IO 是数据库性能瓶颈)。
范围查询能力。B 树进行范围查询时,需从起始 key 开始,沿树的分支逐个查找,可能需要回溯,效率较低;B+ 树的叶子节点通过链表有序连接,范围查询只需找到起始叶子节点,然后沿链表顺序扫描即可,范围查询效率远高于 B 树。例如,查询 key 在 [10, 50] 的数据,B+ 树找到 key=10 的叶子节点后,直接沿链表遍历到 key=50 即可,而 B 树需多次回溯树结构。
存储密度。B 树的非叶子节点存储数据,导致相同空间下能存储的索引键数量较少,树的高度更高(通常 3-4 层);B+ 树的非叶子节点仅存索引键,存储密度更高,树的高度更低(通常 2-3 层),可减少磁盘 IO 次数(每次节点访问对应一次磁盘 IO)。
面试关键点:需明确数据库索引为何首选 B+ 树(稳定的查询效率、高效的范围查询、低磁盘 IO);强调叶子节点链表对范围查询的关键作用;对比二者在数据存储位置上的核心差异。
记忆法:采用“结构-功能”对应法,即“B 树节点存数据,查询快慢不确定;B+ 树数叶存数据,链表相连范围易,非叶只存索引键,层高更低 IO 低”,通过结构特点记忆功能优势。
请解释什么是假设检验?其核心逻辑是什么?
假设检验是一种基于样本数据推断总体特征的统计方法,用于判断样本信息是否足以支持对总体的某个假设。它广泛应用于数据分析中,如判断“新营销策略是否提高销售额”“两组用户的行为是否存在显著差异”等问题。
假设检验的核心逻辑是小概率反证法,即通过否定“原假设”来间接支持“备择假设”,具体可分解为以下步骤:
第一步,建立假设。明确原假设(H₀)和备择假设(H₁)。原假设是需要被检验的假设,通常表述为“无差异”“无效果”(如“新策略与旧策略的销售额无差异”);备择假设是原假设的对立面,表述为“有差异”“有效果”(如“新策略的销售额高于旧策略”)。假设需互斥且完备,即二者必居其一。
第二步,确定检验统计量。根据研究问题和数据类型选择合适的统计量,如均值检验用 z 统计量或 t 统计量,比例检验用卡方统计量等。统计量的作用是将样本数据转化为一个标准化的值,用于衡量样本与原假设的偏离程度。
第三步,设定显著性水平(α)。α 是预先设定的“小概率事件”的阈值,通常取 0.05(即 5%),表示在原假设成立的情况下,允许发生极端事件的最大概率。
第四步,计算 P 值。P 值是在原假设成立的前提下,观察到当前样本数据或更极端情况的概率。它反映了样本数据与原假设的不一致程度:P 值越小,说明原假设成立时出现当前情况的可能性越小。
第五步,做出结论。将 P 值与显著性水平 α 比较:若 P ≤ α,则认为“原假设成立时发生当前情况是小概率事件”,根据小概率原理(小概率事件在一次试验中几乎不发生),拒绝原假设,接受备择假设;若 P > α,则无法拒绝原假设(注意:不是接受原假设,而是证据不足)。
例如,检验“新策略的销售额是否高于旧策略”:H₀为“新策略销售额≤旧策略”,H₁为“新策略销售额>旧策略”。计算样本中两组销售额的差异,得到 P 值=0.03(<0.05),则拒绝 H₀,认为新策略显著提高了销售额。
面试关键点:需强调原假设的“无差异”特性;解释 P 值的含义(不是原假设为真的概率,而是数据与原假设的不一致程度);区分“拒绝 H₀”和“接受 H₁”的逻辑关系。
记忆法:采用“步骤-逻辑”链记忆法,按“建假设→选统计量→设α→算P值→下结论”的步骤,核心记住“小概率反证”:通过小概率事件是否发生,反推原假设是否成立。
请分别说明 t 检验和 z 检验的适用场景及区别。
t 检验和 z 检验均为用于检验总体均值的参数统计方法,但二者的适用场景、前提条件和计算方式有明显区别,具体如下:
适用场景不同。z 检验适用于以下情况:1. 大样本数据(通常样本量 n≥30),此时根据中心极限定理,样本均值近似服从正态分布,无论总体分布如何;2. 小样本数据(n<30)但总体标准差(σ)已知,且总体服从正态分布。例如,检验“某中学学生身高均值是否为 170cm”,若已知全国中学生身高标准差(σ=5cm),即使样本量为 20(小样本),仍可用 z 检验。
t 检验适用于以下情况:1. 小样本数据(n<30)且总体标准差(σ)未知,需用样本标准差(s)估计总体标准差;2. 总体需近似服从正态分布(小样本时对正态性较敏感)。例如,检验“某班级 25 名学生的数学平均分是否高于 80 分”,由于班级人数少(小样本)且未知全校数学成绩的标准差,需用 t 检验。
核心区别体现在以下方面:
- 样本量依赖:z 检验对大样本更友好,t 检验是小样本(σ未知)的首选。
- 标准差已知性:z 检验需已知总体标准差(σ),t 检验用样本标准差(s)替代σ。
- 检验统计量:z 检验计算 z 值,公式为 z=(x̄-μ)/(σ/√n)(x̄为样本均值,μ为总体均值假设值);t 检验计算 t 值,公式为 t=(x̄-μ)/(s/√n),t 值的分布依赖自由度(df=n-1)。
- 分布特性:z 统计量服从标准正态分布(均值 0,标准差 1);t 分布是一簇分布,随自由度增大逐渐接近标准正态分布(自由度→∞时,t 分布≈正态分布)。
- 临界值差异:相同显著性水平下,小样本时 t 检验的临界值大于 z 检验(因 t 分布尾部更厚),导致 t 检验更“严格”,更难拒绝原假设。
举例说明:比较两组数据均值差异时,若样本量均为 50(大样本),用 z 检验;若样本量均为 15 且未知总体标准差,用 t 检验(独立样本 t 检验)。
面试关键点:需明确区分“样本量大小”和“总体标准差是否已知”这两个核心判断标准;说明 t 分布与自由度的关系;强调小样本时 t 检验对正态性的要求。
记忆法:采用“条件-检验”对应法,即“大样本或σ已知用 z 检,小样本且σ未知用 t 检;z 靠正态 t 靠自由度,样本越小 t 越严”,通过核心条件快速匹配适用检验方法。
在使用 z 检验时,如何确定所需的样本量?
在 z 检验中确定样本量是确保检验具有足够统计功效(能正确检测出真实效应)的关键步骤,核心需围绕“效应量”“显著性水平”“统计功效”三个核心参数展开,具体步骤及逻辑如下:
首先,明确三个核心输入参数的定义与取值逻辑。一是效应量(Effect Size),即研究者希望检测出的最小真实差异(如两组均值差、比例差),需结合业务实际设定(例如比较两种营销策略的转化率差异时,若业务认为转化率差≥5%才有实际意义,则效应量设为5%);二是显著性水平(α),通常默认取0.05(对应95%置信度),代表“将无差异误判为有差异”的一类错误概率,需根据业务风险调整(如医疗场景需严格控制错误,α可设为0.01);三是统计功效(1-β),通常默认取0.8(或0.9),代表“能正确检测出真实差异”的概率,β为“将有差异误判为无差异”的二类错误概率,功效越高,所需样本量越大。
其次,根据 z 检验的类型(单样本、两样本)选择对应公式计算样本量。以常用的“两独立样本 z 检验(比较两组比例差异)”为例,公式为:n=(p1−p2)2(z1−α/2+z1−β)2×[p1(1−p1)+p2(1−p2)]其中,z1−α/2 和 z1−β 是标准正态分布下的分位数(如α=0.05时,z1−α/2=1.96;β=0.2时,z1−β=0.84),p1 和 p2 是两组的预期比例(可通过历史数据或预实验估算,若未知则取0.5以最大化样本量,确保结果保守)。例如,若效应量为5%(p1−p2=0.05),α=0.05,1-β=0.8,p1=p2=0.5,代入公式可得每组样本量约为1537。
最后,需考虑实际操作中的“样本损耗”,在计算结果基础上额外增加10%-20%样本量(如用户流失、数据缺失等情况),确保最终有效样本量满足要求。
面试关键点:需明确样本量计算的三个核心参数,能解释公式中各变量的含义,且能结合业务场景说明效应量的设定逻辑(避免仅说“按公式计算”,需体现业务思维)。记忆法:采用“参数-公式-调整”三步记忆法,先记“效应量、α、功效”三个必选参数,再对应检验类型记公式(如两样本比例检验需包含两组比例的方差项),最后补“样本损耗调整”,形成完整逻辑链;同时可联想“参数越大,样本量越大”的规律(如α越小、功效越高、效应量越小,均需更大样本),辅助记忆参数对样本量的影响方向。
在 A/B 测试中,哪些因素会影响两个样本的均值差异?从产品角度看,将两个样本的样本量设置为各占总样本量的一半是否可行?为什么?
一、影响 A/B 测试样本均值差异的因素
A/B 测试中样本均值差异(如用户点击率、留存率的均值差)受“真实效应”“随机误差”“干扰因素”三类因素影响,具体如下:
真实效应(核心因素):即版本 A 与版本 B 本身的差异(如按钮颜色变化对点击率的真实提升),是均值差异的“信号”。若产品改动(如优化支付流程)确实提升了用户转化,则两组均值差异会显著;若改动无实际效果,真实效应为0,均值差异多由随机误差导致。
随机误差(不可避免因素):即使两组样本来自同一总体(无真实效应),由于抽样随机性(如某组恰好抽到更多高活跃用户),也会出现均值差异,是均值差异的“噪声”。随机误差的大小与样本量负相关:样本量越小,随机波动越大(如每组仅10个用户时,单个高活跃用户会大幅拉高均值);样本量越大,随机误差越小,均值差异越接近真实效应。
干扰因素(需控制的因素):若样本分组不随机或存在额外变量,会导致均值差异偏离真实效应。常见干扰因素包括:
- 分组偏差:如将“新用户”全部分到 A 组、“老用户”全部分到 B 组,此时均值差异可能是“用户类型”导致,而非版本差异;
- 时间干扰:如测试期间 A 组遭遇“大促活动”,B 组未参与,点击率差异由“活动”而非版本导致;
- 用户行为惯性:如老用户对版本 A 有使用习惯,短期内拒绝切换到 B 组,导致均值差异被低估。
二、产品角度:样本量各占一半是否可行?
从产品角度看,“两组样本量各占总样本量的一半(1:1分配)”是可行且推荐的方案,核心原因如下:
最大化统计功效,降低决策风险:在总样本量固定时,1:1分配能最小化“标准误”(衡量均值差异的波动程度),从而最大化统计功效(1-β)。根据统计学原理,对于两样本均值检验,当两组样本量比例为1:1时,在相同总样本下,标准误最小(公式为 SE=n1σ2+n2σ2,当 n1=n2 时,SE 最小)。功效越高,越容易检测出真实效应,避免因“功效不足”错过有效产品改动(如明明 B 版本更好,却因样本分配不均导致未检测出差异),符合产品“快速验证改动价值”的需求。
平衡用户体验与风险:从产品角度,需避免某一版本承担过多用户风险(如新版本 B 可能存在 bug,若分配90%用户到 B 组,会导致大量用户受影响)。1:1分配能将风险均摊:即使 B 版本有问题,仅50%用户受影响,降低业务损失;同时,50%用户使用旧版本 A,也能保证核心用户体验稳定,避免因“过度倾斜新版本”导致整体用户流失。
简化分析与决策,降低沟通成本:1:1分配的样本结构对称,后续计算均值差异、显著性检验时无需额外调整“样本量权重”,结果更直观(如“B 组点击率比 A 组高3%”可直接解读为版本差异,无需考虑“B 组样本量少导致偏差”)。对产品经理而言,对称样本的分析结果更易向团队解释,减少因“样本分配不均”引发的决策争议。
特殊场景下可调整比例(如新版本风险极高时,将 B 组样本量设为20%,A 组设为80%),但需以“牺牲部分统计功效”为代价,且需提前通过样本量计算工具验证功效是否满足要求(如1:4分配时,总样本量需比1:1时多20%才能达到相同功效)。
面试关键点:需分“因素影响”和“样本分配可行性”两部分回答,因素部分要区分“真实效应”与“干扰因素”,样本分配部分需结合“统计功效”和“产品风险”双维度分析,避免仅从技术或业务单一角度回答。记忆法:影响因素用“信号-噪声-干扰”记忆法(真实效应是信号,随机误差是噪声,干扰因素是杂音);样本分配用“功效-风险-简化”记忆法(1:1分配对应“高功效、低风险、易分析”,三个优势对应产品核心需求)。
中位数和平均数的区别是什么?在什么情形下适合用中位数代表数据的平均水平,什么情形下适合用平均数?
一、中位数和平均数的核心区别
中位数(Median)和平均数(Mean,通常指算术平均数)是描述数据“集中趋势”的两类统计量,核心区别体现在“计算逻辑”“对极端值的敏感性”“数据分布适配性”三个维度,具体对比如下:
| 对比维度 | 中位数(Median) | 平均数(Mean) |
|---|---|---|
| 计算逻辑 | 将数据按从小到大排序后,位于中间位置的数值(若数据个数为偶数,取中间两个数的均值) | 所有数据之和除以数据个数(xˉ=n∑xi) |
| 对极端值的敏感性 | 不敏感(极端值仅影响排序位置,不直接参与数值计算) | 敏感(极端值会直接拉高或拉低结果,如极大值会使均值偏大) |
| 数据分布适配性 | 适用于偏态分布、有异常值的数据 | 适用于对称分布、无异常值的数据 |
| 数据类型要求 | 适用于有序数据(如满意度评分1-5分)、连续数据 | 仅适用于连续数据或可量化的离散数据(如销售额) |
二、适合用中位数代表平均水平的情形
当数据存在“极端值”或呈“偏态分布”时,中位数能更客观反映数据的“典型水平”,避免被极端值误导,常见场景如下:
数据含极端值的场景:典型如“收入分布”“房价数据”。例如某公司10名员工的月薪为:3k、4k、4k、5k、5k、5k、6k、6k、7k、50k(CEO 月薪50k为极端值)。此时平均数为(3+4+4+5+5+5+6+6+7+50)/10 = 9.5k,远高于多数员工月薪;而中位数为(5+5)/2 = 5k,更贴近80%员工的实际月薪水平。类似场景还包括“用户消费金额”(少数高消费用户拉高均值)、“APP 单次使用时长”(少数用户长时间挂机导致均值偏大),此时中位数是更合理的“平均水平”指标。
数据呈偏态分布的场景:偏态分布指数据集中在一侧,另一侧有长尾(如右偏分布:多数数据小,少数数据极大;左偏分布:多数数据大,少数数据极小)。以“企业利润数据”为例,多数中小企业利润在100万-500万,少数大型企业利润达1亿以上,数据呈右偏分布:此时平均数会被长尾的大企业利润拉高(如均值为800万),而中位数(如300万)更接近多数企业的利润水平。同理,“学生考试分数”若出现少数极低分(左偏分布),中位数也比平均数更能代表班级整体水平。
有序分类数据场景:当数据为“非量化的有序类别”时,无法计算平均数,仅能用中位数描述集中趋势。例如“用户满意度评分”(1=非常不满意,2=不满意,3=一般,4=满意,5=非常满意),若直接计算平均数(如均值3.2),虽可操作,但“0.2分”无实际业务意义;而中位数(如中位数=3)能直接解读为“一半用户满意度≥3,一半≤3”,更贴合分类数据的解读逻辑。类似场景还包括“商品评价等级”“员工绩效评级”等。
三、适合用平均数代表平均水平的情形
当数据“无极端值”且呈“对称分布”(如正态分布)时,平均数能充分利用所有数据信息,且与标准差、方差等离散指标配合,更全面描述数据特征,常见场景如下:
数据呈对称分布(尤其是正态分布)的场景:对称分布中,平均数、中位数、众数三者重合(或接近重合),此时平均数能准确反映数据中心。例如“成年人身高”“学生考试分数(无极端值时)”:以某班学生数学成绩为例,分数分布为65、70、75、80、85、90、95,呈对称分布,平均数=80,中位数=80,两者一致,此时用平均数描述“班级平均成绩”更直观,且可结合标准差(如标准差=10)进一步说明“多数学生分数在70-90之间”,信息更丰富。
需要后续统计分析的场景:在多数统计模型(如回归分析、方差分析)中,平均数是核心输入指标,且具有“可加性”“可导性”等数学性质,便于计算和推导。例如在 A/B 测试中比较两组用户的“平均点击次数”,需用平均数计算两组差异(如 A 组均值2.5,B 组均值3.2,差异0.7),再通过 z 检验或 t 检验判断差异是否显著;若用中位数,无法直接进行此类统计检验,会限制分析深度。
业务场景需体现“总量平均”的情形:当业务关注“总资源在个体间的平均分配”时,平均数更贴合需求。例如某平台“日均活跃用户数(DAU)为100万,日均总互动次数为500万”,此时“用户平均互动次数=5次”(平均数)能直接反映“平台资源的平均使用效率”,若用中位数(如中位数=3次),则无法体现“总互动量与总用户数的关联”,不符合业务决策需求。
面试关键点:需先明确两者的核心区别(尤其是极端值敏感性),再结合“数据特征(有无极端值、分布形态)”和“业务场景(是否需后续分析、解读逻辑)”分类说明适用情形,避免仅说“偏态用中位数,对称用平均数”的片面结论。记忆法:区别用“计算-敏感-分布”三词记忆(中位数按位置算、对极端值不敏感、适配偏态;平均数按总和算、对极端值敏感、适配对称);适用场景用“数据特征+业务需求”绑定记忆(如“极端值+描述个体典型水平”→中位数,“对称分布+后续统计分析”→平均数)。
如何判断逻辑回归模型拟合的好坏?ROC 曲线的横轴和纵轴分别代表什么?
一、判断逻辑回归模型拟合好坏的核心指标与方法
逻辑回归模型的拟合效果需从“模型预测准确性”“模型泛化能力”“模型合理性”三个维度评估,避免仅依赖单一指标,具体可通过以下几类方法和指标判断:
分类准确性相关指标(基础维度):适用于评估模型对“类别标签”(如“用户是否流失”:0=未流失,1=流失)的预测准确性,核心指标包括:
- 混淆矩阵与衍生指标:混淆矩阵通过“真实标签”与“预测标签”的交叉分类,生成“真正例(TP,真实1且预测1)”“假正例(FP,真实0但预测1)”“真负例(TN,真实0且预测0)”“假负例(FN,真实1但预测0)”四个核心值,再衍生出关键指标:
- 精确率(Precision)= TP/(TP+FP):预测为1的样本中实际为1的比例,适用于“避免误判正例”的场景(如预测“高价值用户”时,需减少将普通用户误判为高价值用户的情况);
- 召回率(Recall/Sensitivity)= TP/(TP+FN):真实为1的样本中被正确预测的比例,适用于“避免漏判正例”的场景(如预测“欺诈交易”时,需尽可能找出所有欺诈交易,减少漏判);
- F1分数 = 2×(Precision×Recall)/(Precision+Recall):综合精确率和召回率的调和平均数,解决两者“此消彼长”的矛盾(如提高精确率可能降低召回率),适用于需平衡两者的场景。
- 准确率(Accuracy)= (TP+TN)/(TP+FP+TN+FN):所有样本中预测正确的比例,是最直观的指标,但在“数据不平衡”场景下失效(如样本中90%为0,模型全预测0时准确率仍为90%,但无实际价值),需结合混淆矩阵使用。
- 混淆矩阵与衍生指标:混淆矩阵通过“真实标签”与“预测标签”的交叉分类,生成“真正例(TP,真实1且预测1)”“假正例(FP,真实0但预测1)”“真负例(TN,真实0且预测0)”“假负例(FN,真实1但预测0)”四个核心值,再衍生出关键指标:
概率预测准确性指标(核心维度):逻辑回归的输出是“样本属于正类的概率(如用户流失概率=0.7)
除了决策树和逻辑回归,你还熟悉哪些算法(如 SVM 等)?请简要说明。
在数据分析和机器学习领域,除决策树与逻辑回归外,常用算法还包括支持向量机(SVM)、随机森林、K近邻(KNN)、朴素贝叶斯、线性回归及神经网络等,不同算法的核心原理、适用场景与优缺点存在显著差异,以下从核心逻辑、适用场景、优势与局限三方面展开说明:
首先是支持向量机(SVM),其核心原理是在特征空间中寻找一个“最优超平面”,使超平面与两类样本(二分类场景)的距离(即“间隔”)最大化,且仅依赖距离超平面最近的“支持向量”决策,对非支持向量的样本变化不敏感。从适用场景看,SVM既适用于线性可分数据(线性核函数),也可通过核函数(如RBF径向基核、多项式核)将非线性数据映射到高维空间实现分类,常见于文本分类(如垃圾邮件识别)、图像识别(如手写数字识别)等场景。其优势是泛化能力强、对小样本数据鲁棒性好,不易过拟合;局限是处理超大规模数据(如百万级样本)时计算效率低,且对缺失值敏感,需提前做数据清洗。
其次是随机森林,它属于集成学习中的“Bagging(装袋)”算法,核心是通过“随机采样样本+随机选择特征”构建多棵独立决策树,最终以多数投票(分类任务)或均值(回归任务)输出结果。适用场景广泛,可处理分类与回归问题,例如用户流失预测(分类)、商品销量预测(回归),尤其适合特征维度高、存在非线性关系的数据。优势在于抗过拟合能力强(多棵树投票降低单棵树的随机性)、无需手动特征选择(算法自动筛选重要特征)、对缺失值和异常值容忍度高;局限是模型可解释性差(“黑箱”特性,无法清晰说明决策逻辑),训练大规模森林时耗时较长。
再者是K近邻(KNN),属于“惰性学习”算法,核心逻辑是“近朱者赤,近墨者黑”:对新样本,计算其与训练集中所有样本的距离(如欧氏距离、曼哈顿距离),选取距离最近的K个样本(“邻居”),以这K个样本的多数类别(分类)或均值(回归)作为新样本的预测结果。适用场景包括简单的分类任务(如鸢尾花品种分类)、推荐系统(如基于用户行为相似度的商品推荐),尤其适合数据分布不规律、无明显线性/非线性关系的场景。优势是原理简单、易实现、无需训练过程(新样本直接计算距离);局限是对高维数据(如上千维特征)“距离失效”(维数灾难),计算量大(需遍历所有训练样本),对异常值敏感(异常值可能被选为近邻)。
最后是朴素贝叶斯,基于贝叶斯定理与“特征条件独立”假设(即各特征之间互不影响),核心是通过训练数据计算先验概率(如某类别的出现概率)和条件概率(如某特征在某类别下的出现概率),再利用贝叶斯公式计算新样本属于各类别的后验概率,取概率最大的类别作为预测结果。适用场景以文本处理为主(如情感分析、新闻分类),也可用于小样本、高维数据的分类任务。优势是计算速度快(仅需统计概率)、对小样本数据表现好、对缺失值不敏感;局限是“特征独立假设”在现实中多不成立(如文本中“下雨”和“雨伞”特征存在关联),可能导致预测精度下降,对样本分布不均衡敏感(如某类别样本极少,先验概率计算偏差大)。
面试加分点:回答时需结合具体业务场景(如“文本分类用朴素贝叶斯,大规模数据分类用随机森林”),而非仅罗列算法;若能提及算法的优化方向(如SVM用SMO算法加速、KNN用KD树减少计算量),可进一步体现专业性。
记忆法:采用“场景-核心-优缺点”关联记忆法,例如将“文本分类”与“朴素贝叶斯”绑定,同时记住其“快但依赖独立假设”的特点;将“小样本、高维分类”与“SVM”绑定,记住其“泛化强但慢”的特点,通过场景锚定算法,避免混淆。
准确率和召回率的定义分别是什么?二者有什么关系?
在分类任务(尤其是二分类,如“判断邮件是否为垃圾邮件”“检测肿瘤是否为恶性”)中,准确率(Precision)和召回率(Recall)是评估模型性能的核心指标,二者均基于“混淆矩阵”(Confusion Matrix)计算,需先明确混淆矩阵的四个核心概念:真阳性(TP,模型预测为正类且实际为正类)、假阳性(FP,模型预测为正类但实际为负类,即“误判”)、真阴性(TN,模型预测为负类且实际为负类)、假阴性(FN,模型预测为负类但实际为正类,即“漏判”)。
一、准确率(Precision)的定义
准确率又称“精确率”,核心衡量“模型预测为正类的样本中,实际为正类的比例”,反映模型对正类预测的“精准度”,避免将负类误判为正类。其计算公式为:准确率 = TP / (TP + FP)例如在垃圾邮件识别任务中,TP是“预测为垃圾邮件且实际是垃圾邮件”的数量,FP是“预测为垃圾邮件但实际是正常邮件”的数量,准确率越高,说明用户正常邮件被误判为垃圾邮件的概率越低,可减少“误删正常邮件”的问题。
二、召回率(Recall)的定义
召回率又称“查全率”,核心衡量“实际为正类的样本中,被模型预测为正类的比例”,反映模型对正类样本的“覆盖能力”,避免遗漏正类样本。其计算公式为:召回率 = TP / (TP + FN)仍以垃圾邮件识别为例,FN是“实际是垃圾邮件但被预测为正常邮件”的数量,召回率越高,说明垃圾邮件被漏判为正常邮件的概率越低,可减少“垃圾邮件进入 inbox”的问题;在更关键的医疗场景(如肿瘤检测)中,召回率尤为重要——若召回率低,可能导致“实际患癌但被漏判”,延误治疗,此时需优先保证高召回率。
三、准确率与召回率的关系
二者的核心关系是“此消彼长的trade-off(权衡)”,即提高其中一个指标,往往会导致另一个指标下降,具体可通过“分类阈值调整”理解:在逻辑回归等模型中,预测结果需通过阈值(如默认0.5)判断类别——若预测概率≥阈值则为正类,否则为负类。
- 当提高阈值(如从0.5调整为0.8):模型仅将“高度确信为正类”的样本预测为正类,FP会减少(误判减少),因此准确率提高;但同时,部分“中等确信为正类”的真实正类样本会被预测为负类,FN增加(漏判增加),因此召回率下降。
- 当降低阈值(如从0.5调整为0.2):模型将更多样本预测为正类,FN会减少(漏判减少),因此召回率提高;但同时,部分“低度确信为正类”的真实负类样本会被预测为正类,FP增加(误判增加),因此准确率下降。
此外,二者需结合使用,不可单独依赖某一指标:
- 若仅看准确率:假设模型将所有样本预测为负类,此时FP=0,准确率=TN/(TN+0)=100%,但召回率=TP/(TP+FN)=0(所有正类均被漏判),模型完全无效。
- 若仅看召回率:假设模型将所有样本预测为正类,此时FN=0,召回率=TP/(TP+0)=100%,但准确率=TP/(TP+FP)=正类占比(若正类仅占10%,准确率仅10%),模型同样无效。因此,实际场景中需根据业务目标选择“优先指标”:例如金融反欺诈(漏判欺诈交易损失大)需优先高召回率,电商推荐(误推非兴趣商品影响用户体验)需优先高准确率;若需综合评估,可使用F1分数(准确率与召回率的调和平均数,F1=2*(Precision*Recall)/(Precision+Recall)),避免极端情况。
面试加分点:回答时需结合混淆矩阵推导公式,而非直接背诵;若能举例说明“不同业务场景下的指标优先级”(如医疗优先召回率、推荐优先准确率),可体现对业务的理解;提及F1分数作为二者的调和指标,可展示知识完整性。
记忆法:采用“关键词联想记忆法”——“准确率”对应“精准”,关注“预测正类里对了多少”(TP/(TP+FP)),联想“少误判”;“召回率”对应“召回”,关注“真实正类里抓回多少”(TP/(TP+FN)),联想“少漏判”;二者关系记“调阈值,此消彼长”,避免死记硬背。
你对梯度下降算法有了解吗?请简要说明梯度下降的基本原理。
梯度下降是机器学习中最常用的“优化算法”,核心目标是通过迭代更新模型参数,最小化损失函数(如线性回归的均方误差、逻辑回归的交叉熵损失),找到使模型预测误差最小的最优参数。其本质是“沿着损失函数的梯度方向,逐步靠近最小值点”,类似“人从山坡上沿着最陡的下坡路,一步步走到山底”,以下从核心概念、基本原理、迭代步骤、关键参数四方面展开说明:
一、核心前置概念
在理解梯度下降前,需明确两个关键概念:
- 损失函数(Loss Function):衡量模型预测值与真实值的差异,记为L(θ),其中θ是模型参数(如线性回归的权重w和偏置b)。损失函数值越大,模型误差越大;目标是找到θ*,使L(θ*)最小。
- 梯度(Gradient):损失函数对参数θ的偏导数向量(记为∇L(θ)),其方向是损失函数“上升最快”的方向,而负梯度方向(-∇L(θ))则是损失函数“下降最快”的方向——这是梯度下降的核心理论依据,即沿着负梯度方向更新参数,能最快降低损失函数值。
二、基本原理
梯度下降的核心逻辑可概括为“三步循环”:初始化参数→计算梯度→更新参数,直至损失函数收敛(即损失值不再明显下降,或达到预设迭代次数)。具体可通过“下山”类比:
- 假设你站在山坡上(对应“初始参数θ₀”),山坡的高度对应“损失函数值L(θ₀)”;
- 你需要找到“最陡的下坡方向”(对应“负梯度方向-∇L(θ₀)”),这个方向能让你最快走到山底(对应“最小损失值”);
- 你沿着这个方向走一小步(步长由“学习率”控制),到达新位置(对应“更新后的参数θ₁”);
- 重复上述过程,每次都根据当前位置的梯度调整方向和步长,直到走到山底(对应“损失函数收敛,得到最优参数θ*”)。
三、具体迭代步骤(以单参数为例)
以线性回归模型y=wx+b(仅关注参数w,损失函数为均方误差L(w)=1/n Σ(yᵢ - wxᵢ - b)²)为例,梯度下降的迭代步骤如下:
- 参数初始化:随机设置初始参数w₀(如w₀=0或随机小值),设置学习率α(如0.01)和最大迭代次数(如1000次),初始化迭代次数k=0。
- 计算损失函数对参数的梯度:求损失函数L(w)对w的偏导数,即梯度∇L(wₖ) = dL(w)/dw |_{w=wₖ} = -2/n Σ(yᵢ - wₖxᵢ - b)xᵢ——该梯度反映“当前参数wₖ下,损失函数上升的速度和方向”。
- 更新参数:沿着负梯度方向更新参数,公式为:wₖ₊₁ = wₖ - α * ∇L(wₖ)。其中,α是学习率,控制“每一步走多大”:α过大会导致参数更新幅度过大,可能跳过最小值点(损失函数震荡不收敛);α过小会导致迭代速度过慢,需大量迭代才能收敛。
- 判断收敛:计算更新后的损失值L(wₖ₊₁),若L(wₖ₊₁)与L(wₖ)的差值小于预设阈值(如1e-6),说明损失函数已基本稳定,达到最小值,停止迭代;若未收敛且k<最大迭代次数,令k=k+1,返回步骤2继续迭代。
四、关键参数与常见类型
- 学习率(α):梯度下降的核心超参数,需手动调优。常见调优方式包括“试错法”(从0.1、0.01、0.001等开始测试)、“学习率衰减”(随着迭代次数增加,逐渐减小学习率,如α=α₀/(1+kt),t为迭代次数),避免后期震荡。
- 常见类型:根据样本使用方式,梯度下降可分为三类:
- 批量梯度下降(BGD):每次迭代使用全部训练样本计算梯度,优点是梯度稳定,收敛方向明确;缺点是处理大规模数据(如百万级样本)时,计算量极大,迭代速度慢。
- 随机梯度下降(SGD):每次迭代使用单个随机样本计算梯度,优点是计算速度快,适合大规模数据;缺点是梯度波动大,损失函数震荡明显,收敛路径曲折。
- 小批量梯度下降(MBGD):每次迭代使用一小批样本(如32、64、128个样本)计算梯度,兼顾BGD的稳定性和SGD的速度,是工业界最常用的类型。
面试加分点:回答时需结合具体公式(如损失函数的梯度计算、参数更新公式),而非仅讲定性概念;提及“学习率对收敛的影响”和“三种梯度下降的区别与适用场景”,可体现对算法细节的掌握;若能说明“梯度消失/梯度爆炸”的问题(如深层神经网络中,梯度经过多轮反向传播后趋近于0或无穷大,导致参数无法更新),可进一步展示深度。
记忆法:采用“类比记忆法+步骤记忆法”——将“梯度下降”类比为“下山”,“参数”是位置,“梯度”是下坡方向,“学习率”是步长,“收敛”是到达山底;步骤记“初始化→算梯度→更参数→判收敛”四步,每步对应下山的一个动作,逻辑清晰且易联想。
请讲解一下交叉验证的概念、常用方法及主要作用。
交叉验证(Cross-Validation,简称CV)是机器学习中用于“评估模型泛化能力”和“优化模型超参数”的核心方法,其本质是通过“将训练数据拆分、重复利用”,避免传统“train-test拆分”(仅一次拆分训练集和测试集)导致的评估结果不稳定问题,确保模型在 unseen(未见过)的数据上仍有良好表现。以下从概念定义、常用方法、核心作用三方面详细说明:
一、交叉验证的核心概念
在机器学习模型训练中,若直接用全部数据训练模型,再用同一批数据评估性能,会导致“过拟合评估”(模型在训练数据上表现极好,但在新数据上表现差);若简单将数据拆分为“训练集(如70%)”和“测试集(如30%)”,评估结果会受“拆分方式”影响(如某次拆分的测试集恰好是模型擅长的数据,评估结果偏高;下次拆分则偏低)。
交叉验证的解决思路是:将数据集多次拆分為不同的训练集和验证集,用训练集训练模型,用验证集评估模型性能,最终取多次评估结果的平均值作为模型的最终性能指标。其中,“验证集”的作用是模拟“测试集”,用于在训练过程中评估模型泛化能力,避免测试集被提前使用(测试集需留到最后,用于最终验证模型)。
二、交叉验证的常用方法
不同方法的核心差异在于“数据拆分方式”和“迭代次数”,以下是工业界最常用的4种方法:
- K折交叉验证(K-Fold Cross Validation)这是最经典的交叉验证方法,步骤如下:
- 第一步:将数据集随机打乱后,平均拆分为K个互不重叠的子集(称为“折”,Fold),每个子集的样本量大致相等(如数据集共1000个样本,K=5,则每个折含200个样本)。
- 第二步:进行K轮迭代,每轮迭代中,用“K-1个折”作为训练集,用“剩余1个折”作为验证集;例如第1轮用折1-4训练,折5验证;第2轮用折1-3、
若旅游类笔记的点击率出现下降,该如何进行分析以定位原因?
分析旅游类笔记点击率下降需遵循 “数据确认→多维度拆解→假设验证→根因定位” 的结构化思路,结合旅游行业特性(如季节性、场景化需求)展开,具体步骤如下:
首先,确认点击率下降的真实性与范围。需明确点击率的定义(点击率 = 点击量 ÷ 曝光量),排除数据统计误差(如埋点错误、曝光量重复计算);对比历史同期数据,判断是短期波动(如节假日后正常回落)还是持续性下降(连续 7 天以上走低);同时确认是否全平台下降,还是仅特定端(如 APP、小程序)或特定版本(如 iOS 15 以上)下降,缩小问题范围。
其次,按核心维度拆解点击率,定位异常环节:
- 用户维度:拆分新老用户、地域、年龄、兴趣标签等。例如,若仅新用户点击率下降,可能是新用户对平台内容不熟悉,或首页推荐的笔记与新用户兴趣匹配度低;若某地域(如北方冬季)点击率下降,可能是该地区用户旅游需求随季节减弱(如冬季北方用户更倾向室内活动,对户外旅游笔记兴趣降低)。
- 内容维度:按笔记类型(如攻略、美图、vlog)、目的地(如国内 / 国外、热门 / 小众)、发布时间(如近期是否新增大量低质笔记)拆解。例如,若 “小众目的地攻略” 点击率骤降,可能是平台近期推荐算法调整,导致这类笔记曝光量虽高但内容质量下降(如攻略信息过时);若某热门目的地(如三亚)笔记点击率下降,可能是该目的地近期出现负面新闻(如宰客事件),降低用户兴趣。
- 曝光场景 / 入口维度:分析笔记曝光的主要场景(如首页推荐、搜索结果、分类频道、关注列表)。例如,若仅 “首页推荐” 场景点击率下降,可能是推荐算法过度追求曝光量,推送了大量与用户兴趣不符的笔记(如给亲子用户推送徒步笔记);若 “搜索结果” 点击率下降,可能是搜索关键词与笔记内容匹配度低(如用户搜 “亲子酒店”,结果多为 “情侣民宿”)。
- 外部因素:排查同期是否有竞品动作(如竞品推出旅游内容补贴,分流用户注意力)、行业事件(如疫情反复导致用户旅游意愿下降)、平台活动(如平台近期主推电商内容,挤压旅游笔记曝光)。
接着,提出假设并验证。例如,假设 “点击率下降是因近期新增笔记内容质量下降”,可通过对比点击率下降前后的笔记平均互动率(评论、收藏)、内容原创率、用户举报量验证;若假设 “推荐算法偏差”,可分析用户画像与笔记标签的匹配度(如匹配度从 80% 降至 50%),或 A/B 测试不同推荐策略(如恢复旧版算法后点击率是否回升)。
最后,定位根因并输出结论。常见根因可能包括:内容供给侧质量下滑(如大量搬运笔记)、推荐算法对旅游场景适配不足、用户需求季节性转移(如从户外转向室内)、入口 UI 改版导致点击按钮不明显等。
面试加分点:分析时需结合旅游行业的强季节性、场景化特征(如节假日、气候对用户兴趣的影响),避免泛泛而谈;强调用数据验证假设(如通过 A/B 测试验证算法问题),而非主观判断;提及 “点击率 = 曝光有效性 × 内容吸引力” 的底层逻辑,从 “曝光是否精准” 和 “内容是否优质” 双角度切入。
记忆法:采用 “确认 - 拆解 - 验证 - 定位” 四步记忆法,每步对应具体动作(确认真实性→按用户 / 内容 / 场景拆解→用数据验证假设→锁定根因),逻辑链清晰且易落地。
某 APP 的次日留存率出现下降,已知该 APP 有安卓 5 个渠道和 iOS 10 个渠道,其中安卓渠道的次留下降,iOS 渠道的次留无变化。如何分析次留下降是渠道原因导致的,还是用户结构原因导致的?
要区分安卓渠道次留下降是 “渠道原因” 还是 “用户结构原因”,需通过 “数据拆分→特征对比→控制变量” 的逻辑链分析,核心是明确二者的本质差异:渠道原因指渠道本身质量下降(如渠道推广素材误导用户),用户结构原因指安卓新用户中低留存特征用户占比增加(如年龄、地域等特征变化)。具体步骤如下:
第一步,确认数据准确性与下降范围。需验证安卓次留计算口径(次日留存 = 次日活跃的新增用户 ÷ 当日新增用户)是否与 iOS 一致,排除统计错误(如安卓新增用户定义错误,包含了回流用户);拆分安卓 5 个渠道的次留,判断是 “全渠道下降”(5 个渠道均下降)还是 “部分渠道下降”(如仅渠道 A、B 下降),若仅部分渠道下降,优先排查这些渠道的异常。
第二步,分析渠道质量指标,排查渠道原因。渠道原因的核心是 “渠道获取的用户与 APP 定位匹配度下降”,需对比次留下降前后的渠道数据:
- 推广素材与落地页:检查安卓渠道近期是否更换推广素材(如从 “工具类功能” 改为 “娱乐类功能”),导致用户预期与 APP 实际功能不符(如用户因 “免费游戏” 素材下载,实际 APP 是办公工具,次日自然流失);
- 渠道来源类型:区分渠道是自然量(如应用商店搜索)、付费广告(如信息流广告)、换量合作等,若付费广告渠道占比上升,且这些渠道的次留本身低于自然量,可能导致整体安卓次留下降;
- 渠道用户质量前置指标:分析新增用户的首次使用时长(如从平均 5 分钟降至 2 分钟)、核心功能触发率(如注册完成率从 80% 降至 50%),若前置指标变差,说明渠道引入的用户对 APP 兴趣低,是渠道质量问题。
第三步,分析用户结构特征,排查用户结构原因。用户结构原因的核心是 “安卓新增用户中,本身次留低的特征用户占比增加”,需对比次留下降前后的安卓新用户特征:
- 基础属性:年龄(如 18 岁以下用户占比从 10% 升至 30%,而该群体次留本身低于其他年龄)、地域(如三四线城市用户占比上升,而 APP 在这些地区服务覆盖不足)、设备型号(如低端安卓机型占比增加,APP 在这类设备上体验差);
- 行为特征:新增用户的来源场景(如从 “主动搜索下载” 变为 “误触广告下载”)、首次使用的入口(如从 “核心功能页” 进入变为 “广告跳转页”),若被动下载用户占比上升,次留自然偏低;
- 与 iOS 用户对比:若安卓新增用户中某特征(如年龄 < 18 岁)占比显著高于 iOS,且该特征在 iOS 用户中的次留同样低,说明是用户结构问题(该特征用户本身次留低),而非渠道问题。
第四步,控制变量验证。选取 “相同用户结构” 的安卓用户,对比渠道次留:例如,筛选年龄 25-35 岁、一二线城市、主动下载的安卓用户,若其在各渠道的次留仍下降,说明渠道本身有问题(如渠道推送的版本有 bug);若次留未下降,则确认是用户结构变化导致(新增用户中低留存特征占比增加)。
面试加分点:强调 “控制变量法” 的核心作用(排除用户结构干扰,孤立渠道影响);结合安卓与 iOS 的差异(如安卓渠道更多样、机型更复杂)分析可能的渠道问题(如某渠道适配的安卓版本有兼容性问题);避免将 “渠道原因” 和 “用户结构原因” 完全割裂(实际可能并存,需量化各自影响比例)。
记忆法:采用 “渠道拆分 - 结构对比 - 控制变量” 三步记忆法,第一步定位异常渠道,第二步分析用户特征变化,第三步通过相同结构用户验证,逻辑层层递进,快速锁定原因。
某一天某 APP 的日活(DAU)中,新客为 50 万、老客为 200 万;第二天的日活中,新客为 10 万、老客数据未提及。请预测该 APP 后续 1 天、后续 7 天、后续 28 天的日活数据,并说明预测逻辑。
预测日活(DAU = 新客 + 老客)需基于 “用户留存规律” 和 “新客增长趋势”,核心是区分新客与老客的活跃特征(新客留存随时间衰减快,老客留存相对稳定),具体预测逻辑及结果如下:
核心假设(基于行业常规数据)
- 新客留存:次日留存 30%(新增后第 2 天活跃)、3 日留存 20%、7 日留存 10%、28 日留存 5%(留存率随时间递减,符合用户生命周期规律);
- 老客留存:非新增用户的日留存率 70%(即前一天的老客中,70% 会在次日活跃);
- 新客增长:第二天新客 10 万,假设无特殊事件(如推广停止、版本迭代),后续新客稳定在 10 万 / 天(避免过度推测未提及的增长波动)。
后续 1 天(第三天)的日活预测
- 新客:按...
日活(DAU)/ 月活(MAU)这个指标有什么意义?对公司来说,该指标是否越高越好?微信的 DAU/MAU 指标大致是什么水平?
日活(DAU)指单日活跃用户数,月活(MAU)指单月活跃用户数,二者的比值(DAU/MAU)核心意义是衡量用户对产品的 “粘性与高频使用意愿”,本质是反映月活跃用户中,平均有多少比例的用户会每天打开产品 —— 比值越高,说明用户对产品的依赖度越强、使用频率越高,反之则说明用户可能仅偶尔使用,粘性较弱。从业务视角看,该指标还能辅助判断产品定位是否匹配用户需求:例如社交、工具类产品(如微信、支付宝)天然需要高粘性,DAU/MAU 是核心健康度指标;而低频工具类产品(如租房 APP、违章查询 APP)则无需追求高比值,此时更应关注 “有需求时用户是否会优先使用”。
对公司而言,DAU/MAU 并非 “越高越好”,需结合产品定位、用户需求和业务目标综合判断。首先,高比值可能伴随 “用户过度使用” 的潜在风险:例如短视频、游戏类产品,若 DAU/MAU 过高(如接近 1),可能意味着用户陷入 “沉迷”,长期可能引发监管关注或用户反感,反而损害品牌形象;其次,部分产品的用户需求本身是低频的,强行追求高比值会偏离核心价值 —— 例如婚礼策划 APP,用户仅在有婚礼需求时才会使用,月活中每天活跃的用户比例本就极低,若为提升 DAU/MAU 强制推送无关内容,反而会打扰用户,导致核心用户流失;最后,高比值可能掩盖 “用户结构单一” 的问题:例如某社区 APP 的 DAU/MAU 很高,但活跃用户集中在某一细分群体(如学生),缺乏其他群体的覆盖,长期会限制用户规模增长,此时更应优先优化 MAU 而非 DAU。此外,DAU/MAU 需与其他指标联动分析:若比值高但 DAU、MAU 均持续下降,说明 “仅存的用户粘性高,但整体用户在流失”,仍需警惕业务衰退。
从行业数据来看,微信的 DAU/MAU 长期处于0.75-0.85 的区间(截至 2024 年 5 月公开数据及行业报告估算),是全球范围内用户粘性最高的社交产品之一。这一高比值的核心原因是微信的 “全场景覆盖”:从即时通讯、社交互动(朋友圈、视频号)到工具功能(支付、打车、挂号、小程序),几乎渗透用户日常生活的所有环节,用户每天需多次打开处理消息、完成服务,自然形成高频使用习惯。但即便如此,微信的 DAU/MAU 也未达到 1,因为仍有部分用户(如老年群体、低频社交用户)虽每月活跃,但不会每天打开,这也符合其 “全民级产品” 的用户结构特点。
回答关键点与面试加分点:需明确指标定义的同时,结合 “产品定位差异” 分析 “是否越高越好”,避免绝对化表述;提及微信的具体数值时,需说明 “估算区间” 及背后的业务逻辑(如场景覆盖),而非单纯报数;若能举例对比不同类型产品的 DAU/MAU 合理范围(如短视频 APP 约 0.6-0.7,低频工具 APP 约 0.1-0.2),可进一步体现对行业的理解。
记忆法:采用 “定义 - 意义 - 辩证判断 - 案例” 的逻辑链记忆法,先记住 “DAU/MAU = 粘性” 的核心定义,再按 “为什么重要→为什么不是越高越好(分定位、风险、结构)→微信案例” 的顺序串联;同时用 “场景联想记忆法”,将 “高比值产品” 与 “每天必用” 的场景(如微信、支付宝)绑定,“低比值产品” 与 “有需求才用” 的场景(如租房 APP)绑定,避免混淆。
请估计上海地铁从 A 站进站、B 站出站的人流量(需说明估算逻辑和假设条件,A 站、B 站可假设为上海任意具体站点)
假设 A 站为 “人民广场站”(上海地铁 1、2、8 号线换乘站,位于市中心核心商圈,毗邻南京路步行街、人民广场,周边有大量写字楼、商场和居民区),B 站为 “徐家汇站”(1、9、11 号线换乘站,同样是市中心商圈,周边有徐家汇商圈、高校(如上海交通大学)、写字楼及中高端居民区),两站均为上海地铁 “核心换乘枢纽”,估算逻辑需围绕 “站点属性、时段划分、人群用途、换乘比例” 四大维度展开,同时明确假设条件以保证估算合理性。
首先明确核心假设条件,这是估算的基础:
- 时间维度:选取工作日(如周二)作为估算基准日,排除周末、节假日(人流量波动大);
- 运营时段:上海地铁常规运营时间为 5:30-23:30,共 18 小时,划分为 3 个关键时段:早高峰(7:30-9:30,2 小时)、晚高峰(17:30-19:30,2 小时)、平峰时段(其余 14 小时,含早高峰前、午间、晚高峰后);
- 站点规模:人民广场站、徐家汇站均为 3 条线路换乘,各站均有 8-10 个出入口,早高峰单站总进站量约 12 万人次 / 日(参考上海地铁公开的 “重点枢纽高峰人流量数据”),午间平峰单站进站量约 3000 人次 / 小时,晚高峰后平峰约 2000 人次 / 小时;
- 换乘与直达比例:两站间可通过 1 号线直达(人民广场→徐家汇,约 6 站,耗时 15 分钟),也可通过其他线路换乘(如 2 号线转 9 号线),假设 “直达(1 号线)占比 70%,换乘占比 30%”,且仅统计 “从人民广场进站后,直接从徐家汇出站” 的流量,不包含 “徐家汇站内换乘其他线路” 的用户;
- 人群用途拆分:工作日流量以 “通勤(上班、下班)” 为主(占比 70%),“购物 / 休闲” 为辅(占比 20%),“其他(如就医、办事)” 占比 10%,不同用途人群的时段分布不同(通勤集中在早晚高峰,购物集中在午间和平峰)。
具体估算步骤如下:
- 计算人民广场站各时段进站总量:早高峰(2 小时)按 12 万人次 / 日的 60% 计算(高峰集中),即 12 万 ×60%=7.2 万人次;晚高峰(2 小时)按 12 万 ×30% 计算,即 3.6 万人次;平峰(14 小时)按午间 3000 人次 / 小时、晚高峰后 2000 人次 / 小时拆分,午间(10:00-17:00,7 小时)为 7×3000=2.1 万人次,晚高峰后(19:30-23:30,4 小时)为 4×2000=0.8 万人次,早高峰前(5:30-7:30,2 小时)为 2×1000=0.2 万人次,平峰总计 2.1+0.8+0.2=3.1 万人次;全天进站总量 = 7.2+3.6+3.1=13.9 万人次(与假设的 12 万基准接近,误差为合理波动)。
- 筛选 “人民广场→徐家汇” 的目标人群比例:两站均为市中心商圈,且 1 号线直达,属于 “高频通勤 + 高频消费” 线路,假设人民广场进站用户中,10% 的目的地是徐家汇(参考上海地铁 “核心商圈间直达线路流量占比” 行业经验值)。
- 按时段拆分目标流量:早高峰(通勤上班)占目标流量的 40%,即 13.9 万 ×10%×40%=0.556 万人次;晚高峰(通勤下班 + 购物返程)占 35%,即 13.9 万 ×10%×35%=0.4865 万人次;平峰(购物、办事)占 25%,即 13.9 万 ×10%×25%=0.3475 万人次。
- 最终估算结果:上海地铁人民广场站(A 站)进站、徐家汇站(B 站)出站的全天人流量约为 0.556+0.4865+0.3475≈1.39 万人次,即约 1.4 万人次 / 工作日。
回答关键点与面试加分点:估算需明确 “假设条件”(如时间、站点属性、比例假设),避免 “无依据拍数”;逻辑需分层(先算总进站量→再筛目标比例→最后按时段拆分),体现 “从整体到局部” 的分析思路;若能提及 “数据校准”(如总进站量与公开数据对标),可进一步体现严谨性;需说明 “估算局限性”(如未考虑节假日、极端天气影响),避免绝对化。
记忆法:采用 “假设 - 拆分 - 汇总” 的三步记忆法,先记住 “选核心换乘站 + 工作日” 的基础假设,再按 “总进站量→目标比例→时段拆分” 的步骤拆解,最后汇总结果;同时用 “数字锚定记忆法”,将关键比例(如目标人群 10%、通勤占 70%)与 “核心商圈直达线路” 的场景绑定,避免比例混淆。
TCP 协议和 UDP 协议的区别是什么?
TCP(传输控制协议)和 UDP(用户数据报协议)均是 TCP/IP 协议簇中位于 “传输层” 的核心协议,二者的区别主要围绕 “连接方式、可靠性、传输效率、数据顺序、适用场景” 五大维度展开,本质是 “可靠性与效率” 的取舍 ——TCP 以牺牲部分效率为代价保证数据可靠传输,UDP 则以放弃可靠性为代价追求高效传输。
从具体维度对比,可通过下表清晰呈现:
| 对比维度 | TCP 协议 | UDP 协议 |
|---|---|---|
| 连接方式 | 面向连接(需先建立连接才能传输数据) | 无连接(无需建立连接,直接发送数据) |
| 可靠性 | 可靠传输(通过确认、重传、流量控制等机制) | 不可靠传输(无确认、重传机制,数据可能丢失、乱序) |
| 传输效率 | 效率较低(需处理连接、确认、重传等逻辑,开销大) | 效率极高(无额外开销,数据直接封装发送) |
| 数据顺序 | 保证数据顺序(接收端按发送端顺序接收) | 不保证数据顺序(接收端可能乱序接收) |
| 数据边界 | 面向字节流(无明确数据边界,需应用层处理) | 面向数据报(每个数据报独立,有明确边界) |
| 流量控制与拥塞控制 | 支持(通过滑动窗口实现流量控制,通过拥塞窗口实现拥塞控制) | 不支持(无流量、拥塞控制,可能导致网络拥塞) |
| 适用场景 | 需可靠传输的场景(如文件传输、网页加载) | 需高效 / 实时传输的场景(如视频通话、直播) |
从核心机制差异来看,TCP 的 “可靠性” 依赖三大关键机制:一是三次握手建立连接,确保发送端和接收端均能正常通信;二是确认应答(ACK)与重传机制,接收端收到数据后需向发送端返回确认信息,若发送端未收到确认则重传数据;三是滑动窗口机制,既实现流量控制(避免接收端处理能力不足导致数据丢失),也通过 “累计确认” 提升传输效率。此外,TCP 还通过 “拥塞控制”(如慢启动、拥塞避免算法)减少网络拥塞对传输的影响,这些机制共同导致 TCP 的传输开销较高。
而 UDP 的 “高效性” 源于其 “极简设计”:发送端无需与接收端建立连接,直接将数据封装成 “数据报”(包含源端口、目的端口、数据长度、校验和)后发送至网络;接收端收到数据报后,仅校验数据是否完整(通过校验和),若不完整则直接丢弃,无需向发送端返回确认,也不处理重传、顺序问题。这种设计使得 UDP 的头部开销远小于 TCP(UDP 头部仅 8 字节,TCP 头部最小 20 字节),传输延迟极低,适合对实时性要求高的场景。
从适用场景来看,TCP 的典型应用包括:HTTP/HTTPS(网页加载需确保内容完整,不能丢失代码或图片)、FTP(文件传输需保证文件无损坏)、邮件发送(邮件内容不能丢失);UDP 的典型应用包括:视频通话 / 直播(偶尔丢失一帧数据不影响整体观看,但若延迟过高则体验极差)、DNS 查询(域名解析需快速响应,即使偶尔失败可重试)、游戏(游戏数据需实时传输,延迟比丢失少量数据更影响体验)。
回答关键点与面试加分点:需从 “机制→结果→场景” 三层逻辑展开,而非单纯罗列区别;对比时需点明 “可靠性与效率的取舍” 这一核心矛盾,体现对协议设计本质的理解;若能举例说明具体应用场景(如 HTTP 用 TCP、DNS 用 UDP),可进一步验证对区别的掌握;提及 TCP 的核心机制(如三次握手、滑动窗口)和 UDP 的头部开销差异,可提升回答深度。
记忆法:采用 “核心矛盾 + 场景联想” 的记忆法,先记住 “TCP 求可靠、UDP 求快” 的核心矛盾,再对应场景 ——“需要完整的用 TCP(文件、网页),需要快的用 UDP(视频、游戏)”;同时用 “关键词对比记忆法”,将 “连接(有 vs 无)、可靠(是 vs 否)、顺序(保 vs 不保)” 三个关键维度的区别串联,避免混淆。
请解释 TCP 协议的三次握手过程和四次挥手过程,及其各自的目的。
TCP 协议是面向连接的传输层协议,“三次握手” 是建立连接的过程,目的是确保发送端和接收端的 “发送能力” 与 “接收能力” 均正常,避免因 “一方能力异常” 导致连接无效;“四次挥手” 是断开连接的过程,目的是确保双方均已完成所有数据传输,避免数据丢失或残留,二者均是 TCP 实现 “可靠传输” 的基础机制。
一、三次握手过程及目的
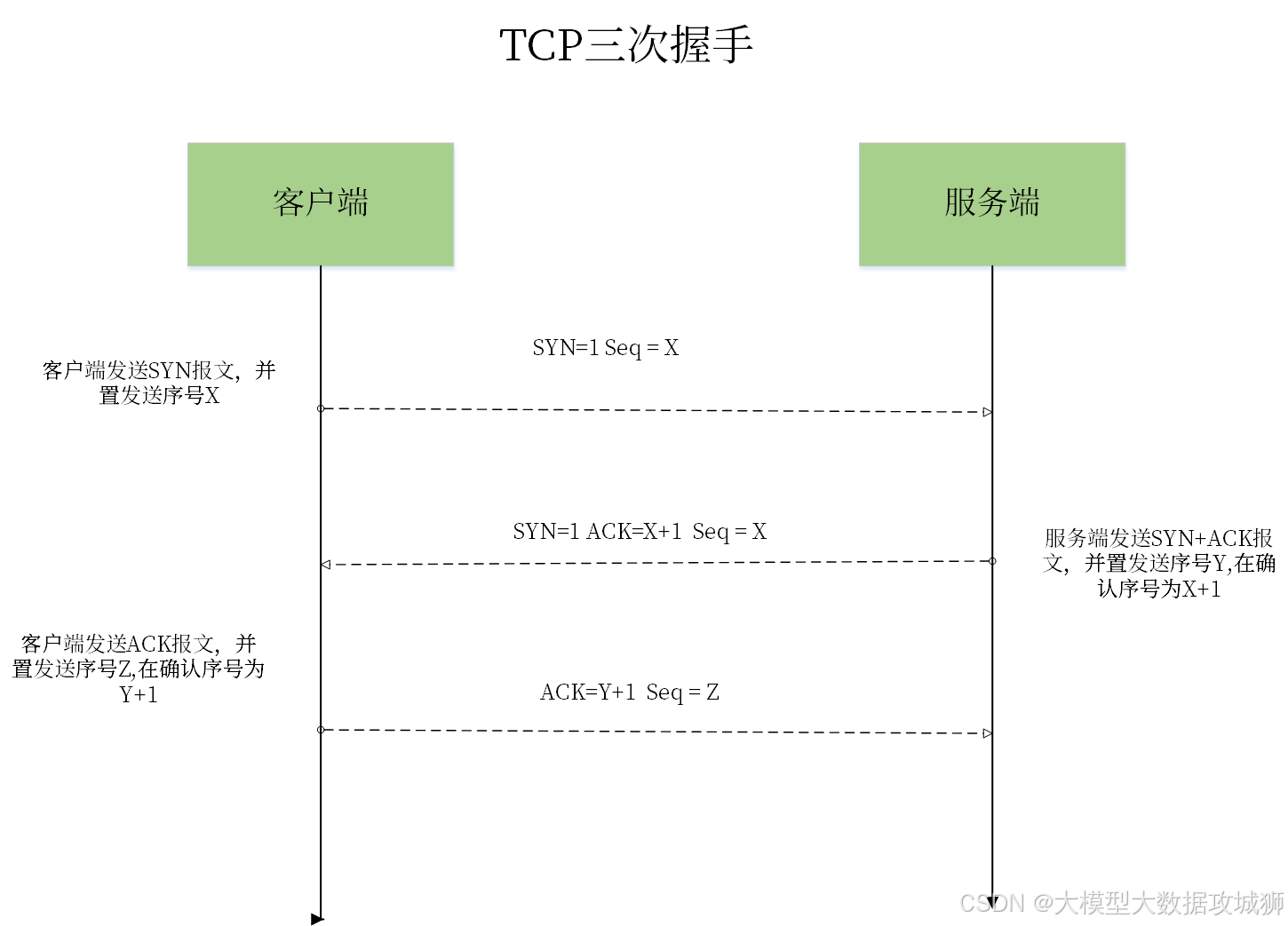
三次握手的核心是 “双向确认”—— 发送端确认接收端能接收,接收端确认发送端能发送且自己能接收,发送端再确认接收端已知道自己能发送,最终建立双向通信通道。假设 “客户端” 主动发起连接,“服务器” 被动接受连接,具体过程如下:
第一次握手(客户端→服务器,发送 SYN 报文):客户端向服务器发送一个 “同步报文段(SYN 报文)”,报文中包含 “客户端的初始序列号(Seq=x)”,此时客户端进入 “SYN_SENT” 状态(等待服务器确认)。这一步的目的是:客户端向服务器 “发起连接请求”,并告知服务器 “我将用 Seq=x 作为后续数据的起始序列号,请你记录”。
第二次握手(服务器→客户端,发送 SYN+ACK 报文):服务器收到客户端的 SYN 报文后,若同意建立连接,会向客户端发送 “同步 + 确认报文段(SYN+ACK 报文)”。该报文中包含两个关键信息:一是 “服务器对客户端 SYN 的确认号(Ack=x+1)”(表示 “我已收到你 Seq=x 的报文,下次请从 x+1 开始发送”),二是 “服务器的初始序列号(Seq=y)”(告知客户端 “我将用 Seq=y 作为后续数据的起始序列号,请你记录”),此时服务器进入 “SYN_RCVD” 状态(等待客户端最终确认)。这一步的目的是:服务器向客户端 “确认收到连接请求”,同时向客户端发起自己的连接请求(同步序列号),完成 “单向确认”(客户端已知服务器能接收和发送)。
第三次握手(客户端→服务器,发送 ACK 报文):客户端收到服务器的 SYN+ACK 报文后,会向服务器发送 “确认报文段(ACK 报文)”,报文中包含 “客户端对服务器 SYN 的确认号(Ack=y+1)”(表示 “我已收到你 Seq=y 的报文,下次请从 y+1 开始发送”),此时客户端进入 “ESTABLISHED” 状态(连接已建立,可传输数据);服务器收到 ACK 报文后,也进入 “ESTABLISHED” 状态。这一步的目的是:客户端向服务器 “确认收到其连接请求”,完成 “双向确认”—— 此时双方均已知对方的发送能力和接收能力正常,可正式开始数据传输。
三次握手的核心目的是避免 “无效连接”:若仅用两次握手,假设客户端发送的 SYN 报文因网络延迟被滞留,客户端超时后会重新发送 SYN 报文并建立正常连接;但滞留的 SYN 报文后续到达服务器时,服务器会误以为是新的连接请求,向客户端发送 SYN+ACK 报文,而此时客户端已处于连接状态,不会理会该报文,服务器会一直等待客户端的 ACK,导致资源浪费。三次握手通过 “客户端最终确认”,可避免这种情况。
二、四次挥手过程及目的
四次挥手的核心是 “双向释放”—— 由于 TCP 是全双工通信(双方可同时发送数据),断开连接时需双方分别确认 “自己已无数据要发送”,并确认 “对方已收到自己的断开请求”,最终释放连接。同样以 “客户端主动发起断开” 为例,过程如下:
第一次挥手(客户端→服务器,发送 FIN 报文):客户端完成数据传输后,向服务器发送 “结束报文段(FIN 报文)”,报文中包含 “客户端的当前序列号(Seq=u)”,表示 “我已无数据要发送给你,请准备断开连接”,此时客户端进入 “FIN_WAIT_1” 状态(等待服务器确认)。
第二次挥手(服务器→客户端,发送 ACK 报文):服务器收到 FIN 报文后,向客户端发送 “确认报文段(ACK 报文)”,包含 “确认号(Ack=u+1)”(表示 “我已收到你要断开的请求,正在处理剩余数据,请你等待”),此时服务器进入 “CLOSE_WAIT” 状态(客户端进入 “FIN_WAIT_2” 状态,等待服务器的 FIN 报文)。这一步的关键是:服务器可能仍有未传输完的数据,因此不能立即发送 FIN 报文,需先确认 “收到客户端的断开请求”,同时继续传输剩余数据。
第三次挥手(服务器→客户端,发送 FIN 报文):服务器完成所有数据传输后,向客户端发送 “结束报文段(FIN 报文)”,包含 “服务器的当前序列号(Seq=v)” 和 “确认号(Ack=u+1)”,表示 “我已无数据要发送给你,你可以断开连接了”,此时服务器进入 “LAST_ACK” 状态(等待客户端确认)。
第四次挥手(客户端→服务器,发送 ACK 报文):客户端收到 FIN 报文后,向服务器发送 “确认报文段(ACK 报文)”,包含 “确认号(Ack=v+1)”,表示 “我已收到你要断开的请求,等待一段时间后会释放连接”,此时客户端进入 “TIME_WAIT” 状态(等待 2MSL,MSL 为报文最大生存时间);服务器收到 ACK 报文后,进入 “CLOSED” 状态(连接释放);客户端等待 2MSL 后,未收到服务器重发的 FIN 报文,确认服务器已收到 ACK,也进入 “CLOSED” 状态。
四次挥手的核心目的是确保双方数据均已传输完成,避免数据丢失:一是服务器需时间处理剩余数据,因此分 “确认断开请求” 和 “发送断开请求” 两步;二是客户端的 “TIME_WAIT” 状态可避免 “滞留的 ACK 报文” 导致服务器重发 FIN—— 若客户端发送 ACK 后立即释放连接,该 ACK 报文若丢失,服务器会重发 FIN,但此时客户端已无对应状态,会向服务器发送 RST 报文,导致服务器误以为连接异常,而 2MSL 的等待时间可确保滞留报文被处理或超时消失。
回答关键点与面试加分点:需明确 “三次握手是建立双向通信能力,四次挥手是释放双向通信通道”;过程描述需包含 “报文类型(SYN/FIN/ACK)、序列号 / 确认号含义、状态变化”,体现对细节的掌握;解释目的时需结合 “可靠性”,如三次握手避免无效连接、四次挥手避免数据丢失;若能说明 “TIME_WAIT” 的作用,可进一步体现深度。
记忆法:三次握手用 “双向确认记忆法”,记住 “客户端请求→服务器确认 + 请求→客户端确认” 的三步逻辑,对应 “我能发→你能收也能发→我知道你能发”;四次挥手用 “全双工释放记忆法”,记住 “客户端说要断→服务器说知道了(还在传数据)→服务器说我也断了→客户端说知道了(等会儿再断)”,对应 “单向请求→单向确认→反向请求→反向确认” 的四步逻辑。