SpringCloudStream:消息驱动组件
目录
一、概念
1.1 概念
1.2 核心价值
1.3 能力边界
1.4 应用场景
二、架构与原理
2.1 核心架构
2.2 工作原理与流程
三、使用
3.1 两种编程模型
3.2 使用示例
3.2.1 创建项目与依赖管理
3.2.2 配置文件设置
3.2.3 核心代码开发
3.3 核心概念与RabbitMQ对应关系
3.4 配置详解
一、概念
1.1 概念
Spring Cloud Stream 是一个用于构建高度可扩展的事件驱动和消息驱动的微服务框架,其核心是简化消息中间件在 Spring 应用程序中的集成。
可以把它理解为一个 “消息中间件的抽象层” 或 “连接器”。它本身不处理消息队列的具体实现,而是提供了一套统一的编程模型,让应用程序代码能够与各种不同的消息中间件(如 Kafka, RabbitMQ, RocketMQ)进行交互,而无需修改代码。
Spring Cloud Stream 的设计哲学是 “约定大于配置”。它通过定义一套统一的编程模型,使得应用程序可以轻松地连接到各种消息中间件,并在它们之间进行切换,而代码几乎不需要改动。
-
开发阶段:你使用 SCSt 提供的标准注解(如
@StreamListener,@Input,@Output) 来编写发送和接收消息的代码。 -
部署阶段:通过引入不同的 Binder 依赖和修改配置文件,你的同一份代码就可以轻松地在 Kafka 或 RabbitMQ 等不同的消息平台上运行。
1.2 核心价值
-
解耦与可移植性:
-
业务代码与中间件解耦: 开发人员无需学习特定消息中间商的复杂 API(如 Kafka Producer/Consumer API, RabbitMQ 的 Channel/QueueDeclare 等)。他们只需要使用 Spring 提供的
@StreamListener,@EnableBinding(旧版) 或函数式编程模型(新版)即可。 -
中间件切换成本极低: 如果你想从 RabbitMQ 迁移到 Kafka,理论上只需要更换 Binder 的依赖和调整配置文件即可,业务代码无需改动。这在技术选型、测试(比如用 RabbitMQ 做测试,Kafka 做生产)、和应对厂商变化时极具价值。
-
-
简化开发,提升效率:
-
提供了开箱即用的配置,如消息序列化/反序列化(支持 JSON, Avro 等)、重试机制、错误处理、消费组、分区等复杂功能。
-
通过与 Spring Boot Actuator 和 Spring Cloud 生态(如 Service Discovery, Config)集成,可以轻松实现监控和管理。
-
-
声明式编程模型:
-
新版(3.x+)基于 Spring Cloud Function,提供了极简的函数式编程模型。只需要定义一个
java.util.function.[Supplier/Function/Consumer],并通过配置将其绑定到消息目标,框架就会自动处理消息的收发。 -
示例:定义一个
Consumer<String>并命名为myInput,然后在配置中指定myInput-in-0绑定到orderTopic,它就自动成为一个消息消费者。
-
-
强大的企业级特性:
-
消费组: 自动实现消息的负载均衡。同一条消息只会被同一个消费组内的一个实例消费,从而天然支持服务的水平扩展。
-
消息分区: 保证具有相同分区键的消息总是被同一个消费者实例处理,这对于保证消息顺序性或状态处理至关重要。
-
消息回溯与重播: 通过绑定到具有持久化能力的消息中间件,可以轻松实现消息的重放,便于调试和修复问题。
-
1.3 能力边界
-
它不是消息中间件:
-
Spring Cloud Stream 不提供消息代理(Broker)本身。它依赖于 Kafka, RabbitMQ, RocketMQ 等来提供核心的消息传递、持久化、高可用能力。必须单独部署和管理这些中间件集群。
-
-
不是万能抽象:
-
虽然它抽象了通用概念,但高级、特定于某个中间件的功能可能无法通过标准 API 使用。例如,RabbitMQ 的 Per-Message TTL、Kafka 的 Compacted Topic 等。虽然它通常提供了扩展机制(如
RabbitMessageChannelBinder的特殊配置)来访问这些特性,但这会破坏可移植性。
-
-
性能与控制力的权衡:
-
抽象层不可避免地会带来极小的性能开销(通常可忽略不计)。
-
更主要的是,它隐藏了底层细节,当需要针对特定场景进行极致的性能调优或故障排查时,仍然需要深入理解底层中间件的原理,有时甚至会觉得框架的封装是一种阻碍。
-
-
学习曲线:
-
虽然简化了中间件 API 的学习,但开发者需要学习 Spring Cloud Stream 自身的编程模型、配置项和行为,这本身也有一定的复杂度。特别是其配置项繁多,需要仔细理解。
-
-
错误处理虽强大但需深入理解:
-
提供了多种错误处理策略(如重试、DLQ - 死信队列),但配置不当可能导致消息丢失或重复消费。正确配置和使用这些特性需要深入理解。
-
1.4 应用场景
Spring Cloud Stream 非常适合构建事件驱动架构(EDA) 的微服务系统。典型场景包括:
-
微服务间异步通信:
-
服务 A 完成操作后,发布一个“事件消息”(如
OrderCreatedEvent),服务 B 和 C 订阅该事件并执行各自的操作(如扣减库存、发送通知)。这比同步的 HTTP 调用更能提高系统的吞吐量和解耦程度。
-
-
实时数据管道和流处理:
-
将应用程序产生的日志、用户行为、传感器数据等作为事件流发布到消息中间件。
-
下游的流处理服务(可以使用 Spring Cloud Stream 结合 Spring Cloud Function 或 Spring Cloud Data Flow)订阅这些数据流,进行实时分析、聚合、转换和入库。
-
示例:实时计算网站 PV/UV、实时风控检测。
-
-
事件溯源(Event Sourcing)与 CQRS:
-
将所有状态变化的事件持久化到消息日志(如 Kafka)中。Spring Cloud Stream 是发布这些事件的理想工具。
-
查询端(CQRS 中的 Query Side)订阅这些事件流,来构建物化视图,与命令端(Command Side)实现分离。
-
-
广播通知/配置刷新:
-
当一个配置发生变更时,向一个 Topic 发布一条消息,所有订阅该 Topic 的服务实例都会收到通知并刷新本地配置。Spring Cloud Bus(基于 Spring Cloud Stream)正是利用这一机制来实现分布式系统的配置刷新。
-
-
削峰填谷:
-
在流量高峰时段,将突如其来的请求转换为消息存入队列,后端的服务按照自己的能力匀速消费,避免服务被瞬间压垮。例如,秒杀系统中的订单处理。
-
二、架构与原理
2.1 核心架构
SCSt 的架构遵循发布-订阅模式,主要由以下三个核心组件构成:
-
Destination Binders (目标绑定器)
-
角色:这是整个架构中最核心的抽象层,是连接应用程序与消息中间件的“桥梁”。
-
职责:
-
负责与消息中间件交互,实现消息的生产(发送)和消费(接收)。
-
提供隔离:应用程序只与 Binder 交互,而不直接与特定中间件的 API 耦合。
-
不同的消息中间件需要不同的 Binder 实现,例如:
-
spring-cloud-stream-binder-kafkafor Apache Kafka -
spring-cloud-stream-binder-rabbitfor RabbitMQ -
spring-cloud-stream-binder-rocketmqfor RocketMQ
-
-
-
-
Bindings (绑定)
-
角色:这是一组接口,是连接应用程序代码(业务逻辑)与 Binder 的“管道”。
-
类型:
-
Input Binding (输入通道):用于消费消息。对应一个
SubscribableChannel。-
注解:
@Input,@StreamListener(旧版),@Bean(函数式编程)
-
-
Output Binding (输出通道):用于生产消息。对应一个
MessageChannel。-
注解:
@Output,@Bean(函数式编程)
-
-
-
在配置文件中定义的
spring.cloud.stream.bindings.[channelName].destination就会映射到这些 Binding 接口上。 -
Message Channel(消息通道):对消息队列的抽象,应用程序通过它发送和接收消息。输入通道(
@Input)用于消费,输出通道(@Output)用于生产。
-
-
Messages (消息)
-
角色:通信的载体,是 Spring Framework 的
Message抽象的一个封装。 -
结构:
-
Payload (消息体):携带的实际业务数据,可以是任何对象(如 String, JSON, POJO)。
-
Headers (消息头):键值对形式的元数据,用于传递附加信息,如
contentType,messageId等。
-
-
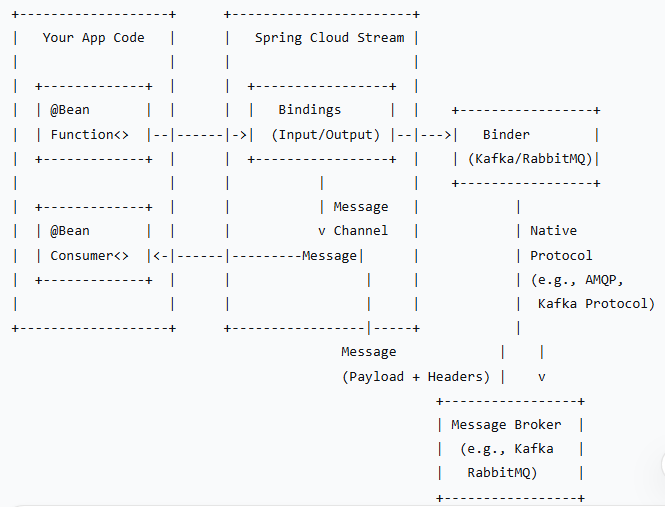
应用程序代码 -> [MessageChannel] <-(通过Binder绑定)-> [Kafka Topic / RabbitMQ Exchange]
代码只与抽象的 MessageChannel 交互,Binder 负责将通道上的消息路由到正确的消息中间件目标。
2.2 工作原理与流程
1. 启动阶段 (Binding and Binding)
-
依赖引入与自动配置:当引入了
spring-cloud-stream和某个特定的 Binder(如binder-kafka)的依赖后,Spring Boot 的自动配置机制会生效。 -
发现 Binder:SCSt 会在 classpath 下寻找可用的 Binder 实现。
-
创建 Binding:SCSt 会根据配置(
application.yml)和代码中的 Binding 定义(如@Bean方法),创建对应的MessageChannel(Output) 和SubscribableChannel(Input)。 -
Binder 连接中间件:Binder 获取配置,与真实的消息代理(Broker)建立连接(如创建 Kafka Producer/Consumer, RabbitMQ Connection/Channel)。
-
绑定通道与目的地:Binder 将应用程序中的
MessageChannel绑定到消息中间件上特定的 Destination(在 Kafka 中叫 Topic,在 RabbitMQ 中可能是 Exchange 或 Queue)。
2. 运行时阶段 (Message Flow)
发送消息 (Producer Side):
-
业务代码通过调用
StreamBridge.send()或向 Output Binding 发送消息。 -
消息进入
MessageChannel。 -
Binder 监听到通道中的消息,拦截它,并使用其内部的消息发送模板(如
KafkaTemplate,RabbitTemplate)将 SpringMessage对象转换为中间件原生协议的消息。 -
消息被发送到消息代理(Broker)上指定的目标(Topic/Exchange)。
接收消息 (Consumer Side):
-
消息代理(Broker)上有新消息到达。
-
Binder 的监听器(如
KafkaMessageListenerContainer,RabbitListenerContainer)监听到该消息。 -
Binder 将原生协议的消息反序列化,包装成一个 Spring
Message对象。 -
Binder 将这个
Message对象发布到对应的SubscribableChannel(Input Binding) 中。 -
定义的消费函数(如
@Bean Consumer<Message<?>>)会从该通道接收到消息并进行处理。
三、使用
3.1 两种编程模型
-
注解驱动模式 (Legacy, 已不推荐)
-
使用
@EnableBinding注解开启绑定。 -
使用
@Input和@Output注解定义通道。 -
使用
@StreamListener注解来监听输入通道。 -
缺点:基于注解,灵活性较差,测试较麻烦。
-
-
函数式编程模型 (当前推荐)
-
这是目前官方推荐且主流的模型,基于 Spring Cloud Function 项目。
-
核心概念:消息处理逻辑就是一个
Function,Consumer, 或Supplier。-
Function<I, O>:处理输入消息,产生输出消息(即有输入和输出)。对应一个Processor。 -
Consumer<I>:消费输入消息,没有输出(即只进不出)。对应一个Sink。 -
Supplier<O>:不接收输入,只提供输出(即只出不进)。对应一个Source。
-
-
配置方式:在
application.yml中通过spring.cloud.stream.function.definition来声明要绑定的函数名。 -
优点:更简洁,易于测试(纯函数),与 Serverless 理念结合更好。
-
示例 (函数式):
import org.springframework.context.annotation.Bean;
import org.springframework.stereotype.Component;
import java.util.function.Function;@Component
public class StreamFunctions {// 定义一个既是消费者也是生产者的处理逻辑@Beanpublic Function<String, String> myProcessor() {return input -> {System.out.println("Received: " + input);return input.toUpperCase(); // 处理后将消息发送到输出通道};}// 定义一个纯消费者@Beanpublic Consumer<String> log() {return message -> System.out.println("Received message: " + message);}
}spring:cloud:stream:binders: # 配置BinderdefaultRabbit: # 自定义Binder名称type: rabbit # 中间件类型environment: # 中间件连接信息spring:rabbitmq:host: localhostport: 5672username: guestpassword: guestbindings: # 绑定配置myProcessor-in-0: # 函数式输入通道(函数名 + -in- + 索引)destination: my-exchange # 对应的交换器或主题content-type: application/json # 消息类型binder: defaultRabbit # 使用的Bindergroup: myGroup # 消费者组myProcessor-out-0: # 函数式输出通道destination: my-output-exchangebinder: defaultRabbitfunction:definition: myProcessor # 声明函数式Bean的名称-
destination:对应 RabbitMQ 中的 Exchange 或 Kafka 中的 Topic。 -
group:消费者组名,通常用于避免重复消费和实现持久化。当部署多个服务实例时,默认情况下所有实例都会收到相同的消息(发布-订阅模式)。通过设置 消费者组(Consumer Group),可以确保同一消息只被组内的一个实例消费,实现负载均衡。 -
函数式编程模型中,Binding 的命名规则为
函数名 + -in- + 索引(输入)和函数名 + -out- + 索引(输出)。
3.2 使用示例
3.2.1 创建项目与依赖管理
使用 Spring Initializr 初始化一个 Spring Boot 项目,并添加 Spring Cloud Stream 及相关 Binder(如 RabbitMQ)的依赖。
<dependencies><!-- Web 功能(可选) --><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency><!-- Spring Cloud Stream RabbitMQ Binder --><dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-stream-rabbit</artifactId><version>2.2.1.RELEASE</version> <!-- 请根据实际情况选择版本 --></dependency>
</dependencies>也可以使用其他 Binder,例如 Kafka:
<dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-stream-kafka</artifactId>
</dependency>3.2.2 配置文件设置
在 application.yml 中配置消息中间件连接信息和绑定规则。
server:port: 8090
spring:application:name: spring-cloud-stream-apprabbitmq: # 以RabbitMQ为例host: 192.168.1.1port: 5672username: your_usernamepassword: your_passwordvirtual-host: / # 可选,默认为/cloud:stream:bindings:myInput: # 输入通道名称,与接口中定义的一致destination: myExchange # 对应的MQ交换机名称group: myConsumerGroup # 消费者组名(可选,用于避免重复消费)content-type: application/json # 消息类型(可选)myOutput: # 输出通道名称destination: myExchange # 发送消息到的交换机名称content-type: application/json3.2.3 核心代码开发
定义消息通道接口:创建一个接口,使用 @Input 和 @Output 注解来定义输入和输出通道。
import org.springframework.cloud.stream.annotation.Input;
import org.springframework.cloud.stream.annotation.Output;
import org.springframework.messaging.MessageChannel;
import org.springframework.messaging.SubscribableChannel;public interface MyCustomChannels {String INPUT = "myInput";String OUTPUT = "myOutput";@Input(INPUT) // 定义输入通道SubscribableChannel myInput();@Output(OUTPUT) // 定义输出通道MessageChannel myOutput();
}Spring Cloud Stream 也提供了预定义的接口 Source(单输出)、Sink(单输入)和 Processor(输入输出)。
// 内置接口示例
import org.springframework.cloud.stream.messaging.Source;
import org.springframework.cloud.stream.messaging.Sink;编写消息消费者:使用 @EnableBinding 激活通道绑定,并用 @StreamListener 监听指定通道的消息。
import org.springframework.cloud.stream.annotation.EnableBinding;
import org.springframework.cloud.stream.annotation.StreamListener;
import org.springframework.stereotype.Component;@Component
@EnableBinding(MyCustomChannels.class) // 绑定自定义通道接口
// 也可以使用 @EnableBinding(Sink.class) 绑定内置接口
public class MyMessageConsumer {// 监听输入通道 "myInput"@StreamListener(MyCustomChannels.INPUT)public void handleMessage(String messagePayload) {System.out.println("Received message: " + messagePayload);// 在这里处理你的业务逻辑}// 如果需要处理对象(JSON自动反序列化)@StreamListener(MyCustomChannels.INPUT)public void handlePersonMessage(Person person) {System.out.println("Received person: " + person.getName());}
}编写消息生产者:注入消息通道并使用 MessageChannel 发送消息。
import org.springframework.cloud.stream.annotation.EnableBinding;
import org.springframework.integration.support.MessageBuilder;
import org.springframework.messaging.MessageChannel;
import org.springframework.stereotype.Component;
import org.springframework.beans.factory.annotation.Autowired;@Component
@EnableBinding(MyCustomChannels.class) // 同样需要绑定
public class MyMessageProducer {@Autowiredprivate MessageChannel myOutput; // 注入输出通道public void sendMessage(String content) {// 构建并发送消息boolean isSent = myOutput.send(MessageBuilder.withPayload(content).build());// 实际生产环境中最好添加发送结果检查}// 发送对象(通常会被自动序列化为JSON)public void sendPerson(Person person) {myOutput.send(MessageBuilder.withPayload(person).build());}
}在 Controller 中调用生产者:
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RestController;@RestController
public class TestController {private final MyMessageProducer messageProducer;public TestController(MyMessageProducer messageProducer) {this.messageProducer = messageProducer;}@GetMapping("/send")public String sendMessage() {messageProducer.sendMessage("Hello from Spring Cloud Stream!");return "Message sent!";}
}3.3 核心概念与RabbitMQ对应关系
| Spring Cloud Stream 概念 | 在 RabbitMQ 中的大致对应 | 说明 |
|---|---|---|
Binder | 整个 RabbitMQ 客户端/连接管理 | 负责与 RabbitMQ 服务器建立连接、创建交换器、队列等。 |
Binding | 交换器 (Exchange) 与队列 (Queue) 的绑定 | 连接应用程序的输入/输出通道与 RabbitMQ 的交换器。 |
Destination | 交换器 (Exchange) | 在配置中指定,消息发送到的目标或接收自的源。 |
Group | 队列 (Queue) 的名称 | 指定 group 后,同组消费者共享一个持久化队列,避免重复消费。 |
Message | 消息 (Message) | 包含消息头 (Headers) 和消息体 (Payload)。 |
Message Channel | 不直接对应 | 应用程序代码中用于发送和接收消息的抽象接口。 |
3.4 配置详解
全局配置:作用于整个 Spring Cloud Stream 应用。
| 配置项 | 说明 | 默认值 |
|---|---|---|
spring.cloud.stream.instanceCount | 应用部署的实例数量,分区功能必须 | 1 |
spring.cloud.stream.instanceIndex | 当前实例的索引(从0开始),分区功能必须 | null |
spring.cloud.stream.dynamicDestinations | 允许动态绑定的目的地列表 | 空 |
spring.cloud.stream.defaultBinder | 当配置多个绑定器时,指定默认使用的绑定器类型 | null |
spring.cloud.stream.overrideCloudConnectors | 在 Cloud 环境中是否忽略绑定的服务,转而使用 Spring Boot 属性配置 | false |
绑定通道配置:通道配置是核心,格式通常为 spring.cloud.stream.bindings.<channelName>.<property>。其中 <channelName> 是定义的通道名称(如 input, output 或自定义通道)。
| 配置项 | 说明 | 默认值 |
|---|---|---|
destination | 消息中间件上的目标目的地(如 Kafka 的 Topic、RabbitMQ 的 Exchange) | 通道名称 |
group | 消费者组。指定后,同一组内多个实例竞争消费,实现负载均衡;不指定则为匿名消费者(可能重复消费) | null (匿名) |
contentType | 该通道消息的内容类型(如 application/json) | null |
binder | 该绑定通道使用的绑定器类型 | null (默认) |
消费者特定配置:消费者配置的前缀为 spring.cloud.stream.bindings.<channelName>.consumer.**。
| 配置项 | 说明 | 默认值 |
|---|---|---|
concurrency | 消费者的并发线程数 | 1 |
partitioned | 是否启用分区支持,表示消费者是否从分区生产者接收数据 | false |
maxAttempts | 消息处理失败后的最大重试次数(包括第一次尝试) | 3 |
backOffInitialInterval | 重试时退避策略的初始间隔(毫秒) | 1000 |
backOffMaxInterval | 重试时退避策略的最大间隔(毫秒) | 10000 |
backOffMultiplier | 重试时退避策略的乘数 | 2.0 |
instanceIndex | 覆盖全局的实例索引,用于分区 | -1 (使用全局配置) |
instanceCount | 覆盖全局的实例数量,用于分区 | -1 (使用全局配置) |
生产者特定配置:生产者配置的前缀为 spring.cloud.stream.bindings.<channelName>.producer.**。
| 配置项 | 说明 | 默认值 |
|---|---|---|
partitionKeyExpression | 用于计算分区键的 SpEL 表达式(如 payload.userId) | null |
partitionKeyExtractorClass | 自定义分区键提取策略的类,与 partitionKeyExpression 互斥 | null |
partitionSelectorClass | 自定义分区选择策略的类,与 partitionSelectorExpression 互斥 | null |
partitionSelectorExpression | 用于自定义分区选择的 SpEL 表达式 | null |
partitionCount | 目标分区数量 | 1 |
requiredGroups | 必须确保消息送达的消费者组列表(逗号分隔),即使这些组在消息发送后才创建 | 空 |
headerMode | 头信息处理模式(如 embeddedHeaders, raw) | embeddedHeaders |
绑定器配置:以 RabbitMQ Binder 为例 [citation:7],配置前缀通常为 spring.cloud.stream.binders.<binderName>.**。
| 配置项 | 说明 | 默认值 |
|---|---|---|
type | 绑定器类型(如 rabbit, kafka) | 无 |
environment.spring.rabbitmq.** | RabbitMQ 连接信息(主机、端口、用户名、密码等)[citation:7] | 无 |
defaultCandidate | 是否作为默认绑定器候选 | true |
-
使用
group是避免消息被重复消费(尤其是在消费者多个实例时)的常见做法 [`citation:3]。 -
分区 (
partitioned,partitionCount,partitionKeyExpression) 对于保证具有相同特征的消息(如同一个用户ID的订单)按顺序被处理非常有用。 -
如果遇到消息转换问题,注意检查
contentType属性。 -
生产环境中,务必配置
group以实现持久化订阅和负载均衡。