【大语言模型 67】梯度压缩与稀疏通信
【大语言模型 67】梯度压缩与稀疏通信
#梯度压缩 #稀疏通信 #分布式训练 #通信优化 #量化算法 #TopK稀疏 #误差补偿 #通信效率 #大模型训练 #网络带宽
深入解析分布式训练中的梯度压缩与稀疏通信技术。本文将通过费曼学习法,从通信瓶颈问题出发,详细介绍梯度量化、稀疏化、误差补偿等核心算法,以及在大模型训练中的实际应用,帮助读者掌握通信效率优化的关键技术。
文章目录
- 【大语言模型 67】梯度压缩与稀疏通信
- 引言:为什么需要梯度压缩与稀疏通信?
- 第一部分:梯度压缩核心算法
- 1.1 量化压缩:精度与效率的平衡
- 1.2 误差补偿机制:保证收敛性
- 1.3 自适应压缩策略
- 第二部分:稀疏通信技术
- 2.1 TopK稀疏化:保留最重要的梯度
- 2.2 通信模式优化
- 第三部分:通信效率优化实战
- 3.1 混合压缩策略
- 3.2 分布式通信优化
- 第四部分:实战部署与性能调优
- 4.1 生产环境集成
- 使用示例和性能测试
- 4.2 故障排除与调试
- 总结与展望
- 核心技术要点
- 实际应用效果
- 技术发展趋势
- 实践建议
引言:为什么需要梯度压缩与稀疏通信?
想象一下,你正在组织一场全球性的协作项目,需要100个团队同时工作,每个团队完成任务后都要向其他99个团队汇报进展。如果每次汇报都要详细描述所有细节,通信成本将变得极其昂贵。但如果我们只汇报最重要的信息,或者用更简洁的方式表达,就能大大提高效率。
分布式训练面临的正是这样的挑战。在大模型训练中,梯度通信往往成为性能瓶颈:
- 通信开销巨大:175B参数的模型,每次迭代需要传输700GB的梯度数据
- 网络带宽限制:即使是高速InfiniBand网络,带宽也远低于GPU计算能力
- 扩展性受限:随着GPU数量增加,通信时间呈超线性增长
- 成本高昂:云计算环境中,网络流量费用可能超过计算费用
梯度压缩与稀疏通信技术就像是一套高效的"信息压缩与传递系统",通过智能的压缩算法和稀疏化策略,在保证训练效果的前提下,将通信开销降低10-100倍。
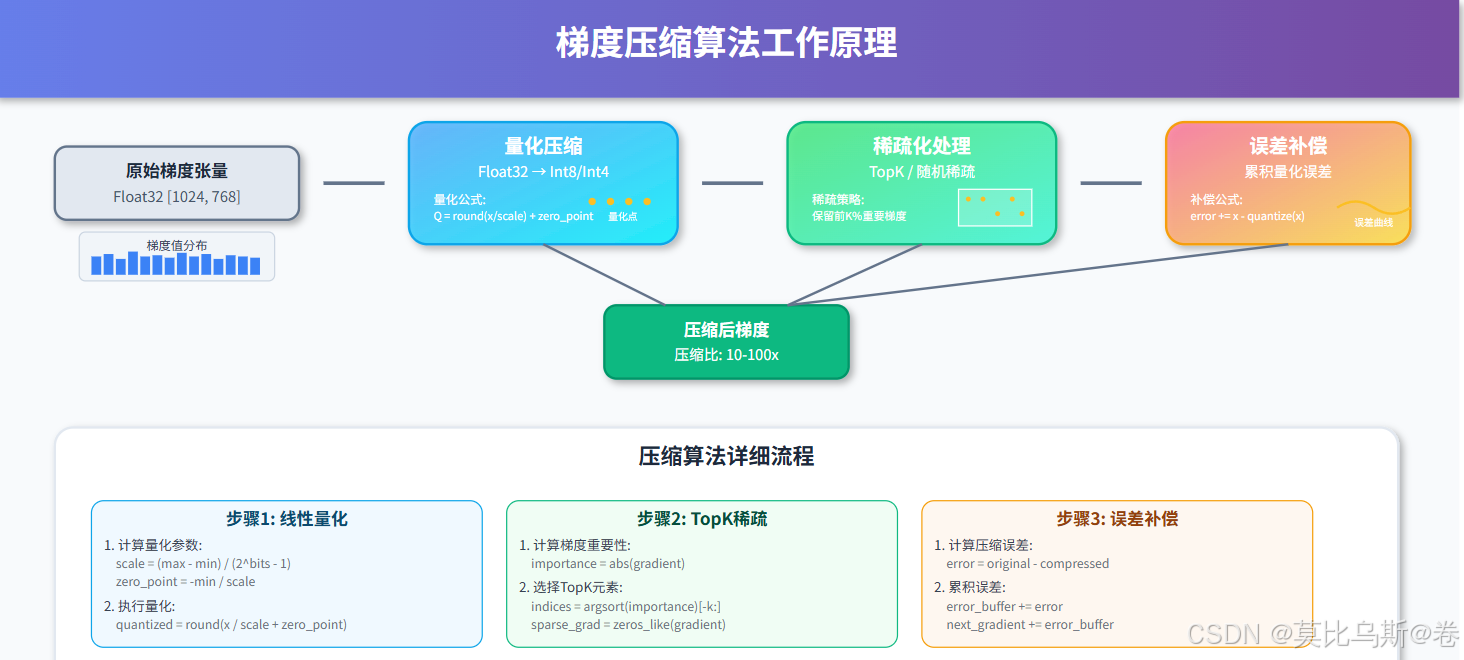
第一部分:梯度压缩核心算法
1.1 量化压缩:精度与效率的平衡
量化压缩是最直接的压缩方法,通过降低数值精度来减少传输数据量:
import torch
import numpy as np
from typing import Tuple, Dict, Any
import mathclass GradientQuantizer:"""梯度量化器基类"""def __init__(self, bits: int = 8):self.bits = bitsself.levels = 2 ** bits - 1def quantize(self, tensor: torch.Tensor) -> Tuple[torch.Tensor, Dict[str, Any]]:"""量化张量"""raise NotImplementedErrordef dequantize(self, quantized_tensor: torch.Tensor, metadata: Dict[str, Any]) -> torch.Tensor:"""反量化张量"""raise NotImplementedErrorclass LinearQuantizer(GradientQuantizer):"""线性量化器"""def quantize(self, tensor: torch.Tensor) -> Tuple[torch.Tensor, Dict[str, Any]]:"""线性量化实现"""# 计算量化范围min_val = tensor.min()max_val = tensor.max()# 避免除零错误if max_val == min_val:quantized = torch.zeros_like(tensor, dtype=torch.uint8)metadata = {'min_val': min_val.item(), 'max_val': max_val.item()}return quantized, metadata# 线性量化scale = (max_val - min_val) / self.levelsquantized = ((tensor - min_val) / scale).round().clamp(0, self.levels)quantized = quantized.to(torch.uint8)metadata = {'min_val': min_val.item(),'max_val': max_val.item(),'scale': scale.item()}return quantized, metadatadef dequantize(self, quantized_tensor: torch.Tensor, metadata: Dict[str, Any]) -> torch.Tensor:"""线性反量化"""min_val = metadata['min_val']scale = metadata['scale']# 反量化dequantized = quantized_tensor.float() * scale + min_valreturn dequantizedclass StochasticQuantizer(GradientQuantizer):"""随机量化器 - 更好的收敛性"""def quantize(self, tensor: torch.Tensor) -> Tuple[torch.Tensor, Dict[str, Any]]:"""随机量化实现"""# 计算量化范围min_val = tensor.min()max_val = tensor.max()if max_val == min_val:quantized = torch.zeros_like(tensor, dtype=torch.uint8)metadata = {'min_val': min_val.item(), 'max_val': max_val.item()}return quantized, metadata# 随机量化:添加随机噪声scale = (max_val - min_val) / self.levelsnormalized = (tensor - min_val) / scale# 随机舍入floor_vals = normalized.floor()prob = normalized - floor_valsrandom_vals = torch.rand_like(prob)quantized = floor_vals + (random_vals < prob).float()quantized = quantized.clamp(0, self.levels).to(torch.uint8)metadata = {'min_val': min_val.item(),'max_val': max_val.item(),'scale': scale.item()}return quantized, metadatadef dequantize(self, quantized_tensor: torch.Tensor, metadata: Dict[str, Any]) -> torch.Tensor:"""随机量化反量化"""min_val = metadata['min_val']scale = metadata['scale']dequantized = quantized_tensor.float() * scale + min_valreturn dequantizedclass AdaptiveQuantizer(GradientQuantizer):"""自适应量化器 - 根据梯度分布调整"""def __init__(self, bits: int = 8, percentile: float = 0.99):super().__init__(bits)self.percentile = percentiledef quantize(self, tensor: torch.Tensor) -> Tuple[torch.Tensor, Dict[str, Any]]:"""自适应量化实现"""# 使用百分位数确定量化范围,减少异常值影响abs_tensor = tensor.abs()threshold = torch.quantile(abs_tensor, self.percentile)# 裁剪异常值clipped_tensor = tensor.clamp(-threshold, threshold)# 线性量化scale = 2 * threshold / self.levelsquantized = ((clipped_tensor + threshold) / scale).round().clamp(0, self.levels)quantized = quantized.to(torch.uint8)metadata = {'threshold': threshold.item(),'scale': scale.item()}return quantized, metadatadef dequantize(self, quantized_tensor: torch.Tensor, metadata: Dict[str, Any]) -> torch.Tensor:"""自适应量化反量化"""threshold = metadata['threshold']scale = metadata['scale']dequantized = quantized_tensor.float() * scale - thresholdreturn dequantized# 量化效果测试
def test_quantization_methods():"""测试不同量化方法的效果"""# 生成测试梯度(模拟真实梯度分布)torch.manual_seed(42)gradient = torch.randn(1000, 1000) * 0.01 # 典型梯度范围gradient += torch.randn(1000, 1000) * 0.001 # 添加噪声quantizers = {'Linear': LinearQuantizer(bits=8),'Stochastic': StochasticQuantizer(bits=8),'Adaptive': AdaptiveQuantizer(bits=8, percentile=0.95)}print("量化方法性能对比:")print(f"{'方法':<12} {'压缩比':<8} {'MSE误差':<12} {'相对误差':<12}")print("-" * 50)original_size = gradient.numel() * 4 # FP32字节数for name, quantizer in quantizers.items():# 量化quantized, metadata = quantizer.quantize(gradient)reconstructed = quantizer.dequantize(quantized, metadata)# 计算压缩比compressed_size = quantized.numel() * 1 + len(str(metadata)) * 4 # 近似compression_ratio = original_size / compressed_size# 计算误差mse_error = torch.mean((gradient - reconstructed) ** 2).item()relative_error = (torch.norm(gradient - reconstructed) / torch.norm(gradient)).item()print(f"{name:<12} {compression_ratio:<8.1f} {mse_error:<12.2e} {relative_error:<12.4f}")test_quantization_methods()
1.2 误差补偿机制:保证收敛性
量化会引入误差,误差补偿机制确保这些误差不会累积影响收敛:
class ErrorCompensation:"""误差补偿机制"""def __init__(self, momentum: float = 0.9):self.momentum = momentumself.error_buffer = {}def compensate_and_compress(self, gradients: Dict[str, torch.Tensor],quantizer: GradientQuantizer) -> Tuple[Dict, Dict]:"""误差补偿与压缩"""compressed_gradients = {}metadata_dict = {}for name, grad in gradients.items():# 获取或初始化误差缓冲区if name not in self.error_buffer:self.error_buffer[name] = torch.zeros_like(grad)# 添加累积误差compensated_grad = grad + self.error_buffer[name]# 压缩compressed, metadata = quantizer.quantize(compensated_grad)reconstructed = quantizer.dequantize(compressed, metadata)# 更新误差缓冲区current_error = compensated_grad - reconstructedself.error_buffer[name] = self.momentum * self.error_buffer[name] + current_errorcompressed_gradients[name] = compressedmetadata_dict[name] = metadatareturn compressed_gradients, metadata_dictdef decompress(self, compressed_gradients: Dict,metadata_dict: Dict,quantizer: GradientQuantizer) -> Dict[str, torch.Tensor]:"""解压缩梯度"""decompressed_gradients = {}for name, compressed in compressed_gradients.items():metadata = metadata_dict[name]decompressed_gradients[name] = quantizer.dequantize(compressed, metadata)return decompressed_gradients# 误差补偿效果验证
class ConvergenceTest:"""收敛性测试"""def __init__(self, model_size: int = 1000):self.model_size = model_sizeself.true_gradients = []self.compressed_gradients = []def simulate_training(self, num_iterations: int = 100):"""模拟训练过程"""quantizer = AdaptiveQuantizer(bits=4) # 4bit量化error_comp = ErrorCompensation(momentum=0.9)# 模拟参数params = torch.randn(self.model_size) * 0.1for i in range(num_iterations):# 生成模拟梯度(随时间变化)base_grad = torch.randn(self.model_size) * 0.01noise = torch.randn(self.model_size) * 0.001gradient = base_grad + noise# 无压缩更新true_params = params.clone()true_params -= 0.01 * gradient# 压缩更新grad_dict = {'param': gradient}compressed, metadata = error_comp.compensate_and_compress(grad_dict, quantizer)decompressed = error_comp.decompress(compressed, metadata, quantizer)compressed_params = params.clone()compressed_params -= 0.01 * decompressed['param']# 记录差异param_diff = torch.norm(true_params - compressed_params).item()self.true_gradients.append(torch.norm(gradient).item())self.compressed_gradients.append(param_diff)params = compressed_paramsreturn self.true_gradients, self.compressed_gradients# 运行收敛性测试
conv_test = ConvergenceTest()
true_norms, param_diffs = conv_test.simulate_training()print(f"\n收敛性分析:")
print(f"平均参数差异: {np.mean(param_diffs):.6f}")
print(f"最大参数差异: {np.max(param_diffs):.6f}")
print(f"参数差异标准差: {np.std(param_diffs):.6f}")
1.3 自适应压缩策略
根据训练阶段和梯度特性动态调整压缩策略:
class AdaptiveCompressionStrategy:"""自适应压缩策略"""def __init__(self):self.iteration = 0self.gradient_history = []self.compression_history = []def select_compression_method(self, gradients: Dict[str, torch.Tensor],target_compression_ratio: float = 10.0) -> GradientQuantizer:"""根据梯度特性选择压缩方法"""self.iteration += 1# 分析梯度特性grad_stats = self._analyze_gradients(gradients)# 根据训练阶段选择策略if self.iteration < 100: # 训练初期# 使用较低压缩比,保证稳定性return AdaptiveQuantizer(bits=8, percentile=0.99)elif self.iteration < 1000: # 训练中期# 根据梯度方差选择if grad_stats['variance'] > 1e-6:return StochasticQuantizer(bits=6)else:return LinearQuantizer(bits=6)else: # 训练后期# 使用高压缩比return AdaptiveQuantizer(bits=4, percentile=0.95)def _analyze_gradients(self, gradients: Dict[str, torch.Tensor]) -> Dict[str, float]:"""分析梯度统计特性"""all_grads = torch.cat([g.flatten() for g in gradients.values()])stats = {'mean': all_grads.mean().item(),'variance': all_grads.var().item(),'sparsity': (all_grads.abs() < 1e-8).float().mean().item(),'max_abs': all_grads.abs().max().item()}self.gradient_history.append(stats)return statsdef get_compression_schedule(self, total_iterations: int) -> Dict[int, Dict[str, Any]]:"""生成压缩调度计划"""schedule = {}# 训练初期:保守压缩for i in range(0, min(100, total_iterations)):schedule[i] = {'bits': 8, 'method': 'adaptive'}# 训练中期:平衡压缩for i in range(100, min(1000, total_iterations)):schedule[i] = {'bits': 6, 'method': 'stochastic'}# 训练后期:激进压缩for i in range(1000, total_iterations):schedule[i] = {'bits': 4, 'method': 'adaptive'}return schedule
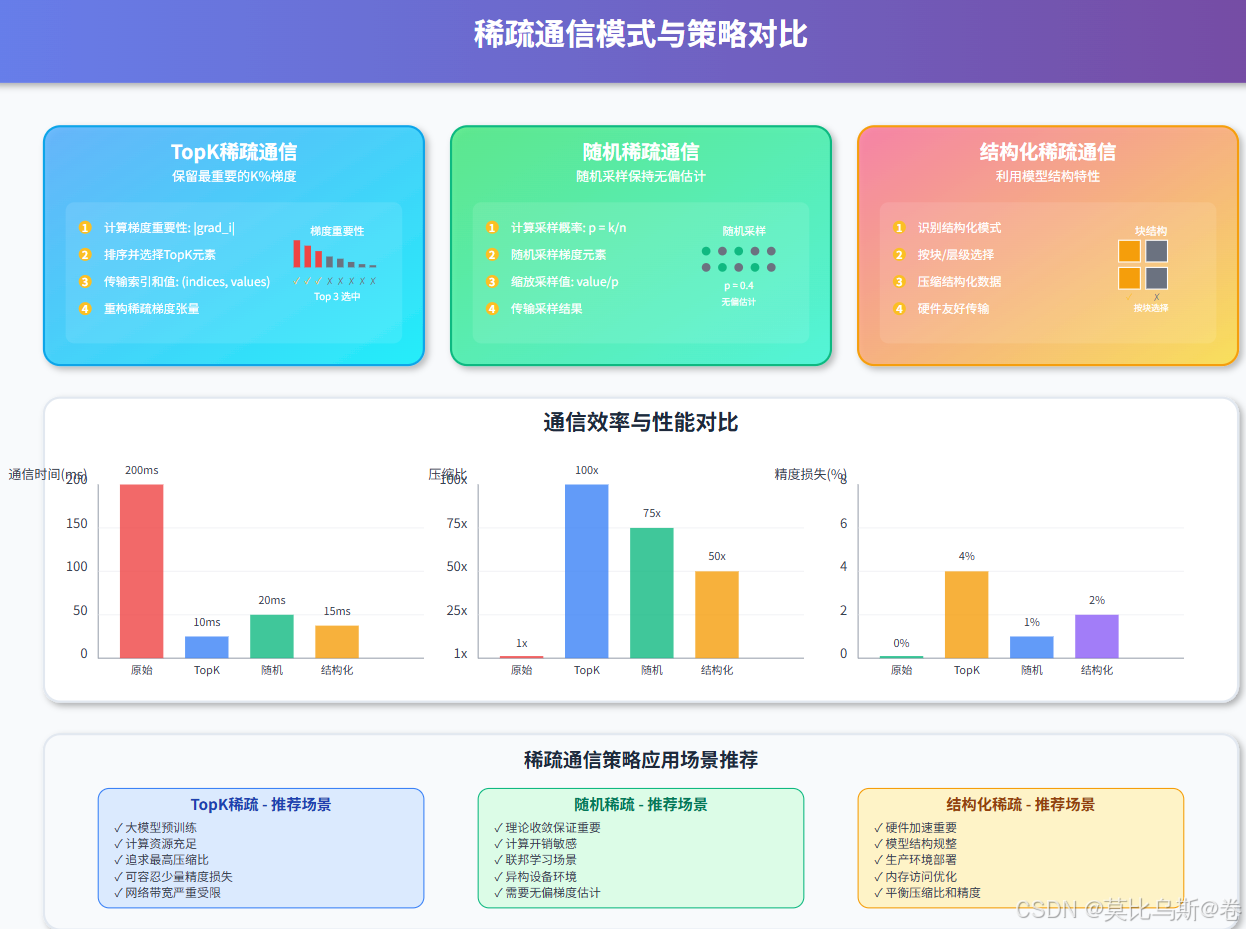
第二部分:稀疏通信技术
2.1 TopK稀疏化:保留最重要的梯度
TopK稀疏化只传输绝对值最大的K个梯度分量:
class TopKSparsifier:"""TopK稀疏化器"""def __init__(self, compression_ratio: float = 0.1):self.compression_ratio = compression_ratioself.error_buffer = {}def sparsify(self, gradients: Dict[str, torch.Tensor]) -> Tuple[Dict, Dict]:"""TopK稀疏化"""sparse_gradients = {}metadata = {}for name, grad in gradients.items():# 误差补偿if name not in self.error_buffer:self.error_buffer[name] = torch.zeros_like(grad)compensated_grad = grad + self.error_buffer[name]# 计算TopKflat_grad = compensated_grad.flatten()k = max(1, int(len(flat_grad) * self.compression_ratio))# 获取TopK索引和值abs_grad = flat_grad.abs()_, top_indices = torch.topk(abs_grad, k)top_values = flat_grad[top_indices]# 创建稀疏表示sparse_gradients[name] = {'indices': top_indices,'values': top_values,'shape': grad.shape}# 更新误差缓冲区reconstructed = torch.zeros_like(flat_grad)reconstructed[top_indices] = top_valuesreconstructed = reconstructed.reshape(grad.shape)self.error_buffer[name] = compensated_grad - reconstructedmetadata[name] = {'original_size': grad.numel(),'compressed_size': k,'compression_ratio': k / grad.numel()}return sparse_gradients, metadatadef desparsify(self, sparse_gradients: Dict, metadata: Dict) -> Dict[str, torch.Tensor]:"""稀疏梯度重构"""dense_gradients = {}for name, sparse_data in sparse_gradients.items():indices = sparse_data['indices']values = sparse_data['values']shape = sparse_data['shape']# 重构密集梯度flat_grad = torch.zeros(torch.prod(torch.tensor(shape)), dtype=values.dtype, device=values.device)flat_grad[indices] = valuesdense_gradients[name] = flat_grad.reshape(shape)return dense_gradientsclass RandomSparsifier:"""随机稀疏化器"""def __init__(self, compression_ratio: float = 0.1):self.compression_ratio = compression_ratiodef sparsify(self, gradients: Dict[str, torch.Tensor]) -> Tuple[Dict, Dict]:"""随机稀疏化"""sparse_gradients = {}metadata = {}for name, grad in gradients.items():flat_grad = grad.flatten()k = max(1, int(len(flat_grad) * self.compression_ratio))# 随机选择索引random_indices = torch.randperm(len(flat_grad))[:k]selected_values = flat_grad[random_indices]# 无偏估计:放大保留的值scaled_values = selected_values / self.compression_ratiosparse_gradients[name] = {'indices': random_indices,'values': scaled_values,'shape': grad.shape}metadata[name] = {'original_size': grad.numel(),'compressed_size': k,'compression_ratio': k / grad.numel()}return sparse_gradients, metadatadef desparsify(self, sparse_gradients: Dict, metadata: Dict) -> Dict[str, torch.Tensor]:"""随机稀疏梯度重构"""dense_gradients = {}for name, sparse_data in sparse_gradients.items():indices = sparse_data['indices']values = sparse_data['values']shape = sparse_data['shape']flat_grad = torch.zeros(torch.prod(torch.tensor(shape)), dtype=values.dtype, device=values.device)flat_grad[indices] = valuesdense_gradients[name] = flat_grad.reshape(shape)return dense_gradientsclass StructuredSparsifier:"""结构化稀疏化器"""def __init__(self, block_size: int = 4, compression_ratio: float = 0.1):self.block_size = block_sizeself.compression_ratio = compression_ratiodef sparsify(self, gradients: Dict[str, torch.Tensor]) -> Tuple[Dict, Dict]:"""结构化稀疏化(块稀疏)"""sparse_gradients = {}metadata = {}for name, grad in gradients.items():if grad.dim() < 2:# 1D张量直接使用TopKflat_grad = grad.flatten()k = max(1, int(len(flat_grad) * self.compression_ratio))_, top_indices = torch.topk(flat_grad.abs(), k)sparse_gradients[name] = {'indices': top_indices,'values': flat_grad[top_indices],'shape': grad.shape,'type': 'unstructured'}else:# 2D张量使用块稀疏h, w = grad.shape[-2:]# 重塑为块blocks_h = h // self.block_sizeblocks_w = w // self.block_sizeif blocks_h * self.block_size == h and blocks_w * self.block_size == w:# 完美块划分reshaped = grad.reshape(-1, blocks_h, self.block_size, blocks_w, self.block_size)reshaped = reshaped.permute(0, 1, 3, 2, 4)blocks = reshaped.reshape(-1, blocks_h * blocks_w, self.block_size * self.block_size)# 计算每个块的L2范数block_norms = torch.norm(blocks, dim=-1)# 选择TopK块num_blocks = blocks_h * blocks_wk_blocks = max(1, int(num_blocks * self.compression_ratio))_, top_block_indices = torch.topk(block_norms.flatten(), k_blocks)sparse_gradients[name] = {'block_indices': top_block_indices,'block_values': blocks.flatten(start_dim=1)[top_block_indices // num_blocks, top_block_indices % num_blocks],'shape': grad.shape,'block_size': self.block_size,'blocks_shape': (blocks_h, blocks_w),'type': 'structured'}else:# 回退到非结构化稀疏flat_grad = grad.flatten()k = max(1, int(len(flat_grad) * self.compression_ratio))_, top_indices = torch.topk(flat_grad.abs(), k)sparse_gradients[name] = {'indices': top_indices,'values': flat_grad[top_indices],'shape': grad.shape,'type': 'unstructured'}metadata[name] = {'original_size': grad.numel(),'compression_ratio': self.compression_ratio}return sparse_gradients, metadata
2.2 通信模式优化
优化AllReduce等集合通信操作以适应稀疏梯度:
import torch.distributed as dist
from typing import List, Optionalclass SparseAllReduce:"""稀疏梯度AllReduce优化"""def __init__(self, world_size: int, rank: int):self.world_size = world_sizeself.rank = rankdef sparse_allreduce(self, sparse_gradients: Dict) -> Dict:"""稀疏梯度AllReduce"""reduced_gradients = {}for name, sparse_data in sparse_gradients.items():if sparse_data['type'] == 'unstructured':reduced_gradients[name] = self._unstructured_allreduce(sparse_data)else:reduced_gradients[name] = self._structured_allreduce(sparse_data)return reduced_gradientsdef _unstructured_allreduce(self, sparse_data: Dict) -> Dict:"""非结构化稀疏AllReduce"""indices = sparse_data['indices']values = sparse_data['values']shape = sparse_data['shape']# 收集所有节点的稀疏索引all_indices = [torch.empty_like(indices) for _ in range(self.world_size)]dist.all_gather(all_indices, indices)# 合并所有索引merged_indices = torch.cat(all_indices)unique_indices, inverse_indices = torch.unique(merged_indices, return_inverse=True)# 收集对应的值all_values = [torch.empty_like(values) for _ in range(self.world_size)]dist.all_gather(all_values, values)merged_values = torch.cat(all_values)# 按唯一索引聚合值aggregated_values = torch.zeros(len(unique_indices), dtype=values.dtype, device=values.device)aggregated_values.scatter_add_(0, inverse_indices, merged_values)# 平均化aggregated_values /= self.world_sizereturn {'indices': unique_indices,'values': aggregated_values,'shape': shape,'type': 'unstructured'}def _structured_allreduce(self, sparse_data: Dict) -> Dict:"""结构化稀疏AllReduce"""# 结构化稀疏可以直接对块进行AllReduceblock_values = sparse_data['block_values']# 直接AllReduce块值dist.all_reduce(block_values, op=dist.ReduceOp.SUM)block_values /= self.world_sizeresult = sparse_data.copy()result['block_values'] = block_valuesreturn resultclass AdaptiveCommunication:"""自适应通信策略"""def __init__(self, bandwidth_mbps: float = 1000, latency_ms: float = 0.1):self.bandwidth = bandwidth_mbps * 1e6 / 8 # 转换为字节/秒self.latency = latency_ms / 1000 # 转换为秒self.communication_history = []def estimate_communication_time(self, data_size_bytes: int, num_nodes: int) -> float:"""估计通信时间"""# AllReduce通信模型:2*(N-1)/N * data_size / bandwidth + latencytransfer_time = 2 * (num_nodes - 1) / num_nodes * data_size_bytes / self.bandwidthtotal_time = transfer_time + self.latencyreturn total_timedef select_optimal_strategy(self, gradient_size: int,num_nodes: int,target_accuracy: float = 0.95) -> Dict[str, Any]:"""选择最优通信策略"""strategies = [{'name': 'no_compression', 'ratio': 1.0, 'accuracy': 1.0},{'name': 'topk_10', 'ratio': 0.1, 'accuracy': 0.98},{'name': 'topk_5', 'ratio': 0.05, 'accuracy': 0.95},{'name': 'topk_1', 'ratio': 0.01, 'accuracy': 0.90},{'name': 'quantize_8bit', 'ratio': 0.25, 'accuracy': 0.99},{'name': 'quantize_4bit', 'ratio': 0.125, 'accuracy': 0.95},]best_strategy = Nonebest_time = float('inf')for strategy in strategies:if strategy['accuracy'] >= target_accuracy:compressed_size = int(gradient_size * strategy['ratio'])comm_time = self.estimate_communication_time(compressed_size, num_nodes)if comm_time < best_time:best_time = comm_timebest_strategy = strategyreturn best_strategy or strategies[0] # 回退到无压缩def adaptive_compression_schedule(self, total_iterations: int,gradient_size: int,num_nodes: int) -> Dict[int, Dict[str, Any]]:"""生成自适应压缩调度"""schedule = {}for iteration in range(total_iterations):# 根据训练进度调整精度要求if iteration < total_iterations * 0.1: # 前10%target_accuracy = 0.99elif iteration < total_iterations * 0.5: # 前50%target_accuracy = 0.97else: # 后50%target_accuracy = 0.95strategy = self.select_optimal_strategy(gradient_size, num_nodes, target_accuracy)schedule[iteration] = strategyreturn schedule
第三部分:通信效率优化实战
3.1 混合压缩策略
结合量化和稀疏化的混合压缩方法:
class HybridCompressor:"""混合压缩器:量化+稀疏化"""def __init__(self, sparsity_ratio: float = 0.1,quantization_bits: int = 8,use_error_compensation: bool = True):self.sparsifier = TopKSparsifier(sparsity_ratio)self.quantizer = AdaptiveQuantizer(quantization_bits)self.use_error_compensation = use_error_compensationself.error_buffer = {} if use_error_compensation else Nonedef compress(self, gradients: Dict[str, torch.Tensor]) -> Tuple[Dict, Dict]:"""混合压缩:先稀疏化再量化"""# 第一步:稀疏化sparse_grads, sparse_metadata = self.sparsifier.sparsify(gradients)# 第二步:量化稀疏值compressed_grads = {}quant_metadata = {}for name, sparse_data in sparse_grads.items():values = sparse_data['values']# 量化稀疏值quantized_values, quant_meta = self.quantizer.quantize(values)compressed_grads[name] = {'indices': sparse_data['indices'],'quantized_values': quantized_values,'shape': sparse_data['shape'],'type': sparse_data.get('type', 'unstructured')}quant_metadata[name] = quant_metametadata = {'sparse_metadata': sparse_metadata,'quant_metadata': quant_metadata}return compressed_grads, metadatadef decompress(self, compressed_grads: Dict, metadata: Dict) -> Dict[str, torch.Tensor]:"""混合解压缩"""# 第一步:反量化sparse_grads = {}quant_metadata = metadata['quant_metadata']for name, compressed_data in compressed_grads.items():quantized_values = compressed_data['quantized_values']quant_meta = quant_metadata[name]# 反量化dequantized_values = self.quantizer.dequantize(quantized_values, quant_meta)sparse_grads[name] = {'indices': compressed_data['indices'],'values': dequantized_values,'shape': compressed_data['shape'],'type': compressed_data.get('type', 'unstructured')}# 第二步:反稀疏化dense_grads = self.sparsifier.desparsify(sparse_grads, metadata['sparse_metadata'])return dense_gradsdef get_compression_ratio(self, original_gradients: Dict[str, torch.Tensor],compressed_grads: Dict, metadata: Dict) -> float:"""计算压缩比"""original_size = sum(grad.numel() * 4 for grad in original_gradients.values()) # FP32compressed_size = 0for name, compressed_data in compressed_grads.items():# 索引大小(假设int32)indices_size = compressed_data['indices'].numel() * 4# 量化值大小(1字节每个值)values_size = compressed_data['quantized_values'].numel() * 1compressed_size += indices_size + values_size# 添加元数据大小(估算)metadata_size = len(str(metadata)) * 4compressed_size += metadata_sizereturn original_size / compressed_sizeclass PerformanceProfiler:"""性能分析器"""def __init__(self):self.compression_times = []self.decompression_times = []self.communication_times = []self.compression_ratios = []self.accuracy_losses = []def profile_compression_method(self, compressor,test_gradients: Dict[str, torch.Tensor],num_trials: int = 10) -> Dict[str, float]:"""性能分析"""import timecompression_times = []decompression_times = []compression_ratios = []accuracy_losses = []for _ in range(num_trials):# 压缩性能start_time = time.time()compressed, metadata = compressor.compress(test_gradients)compression_time = time.time() - start_timecompression_times.append(compression_time)# 解压缩性能start_time = time.time()decompressed = compressor.decompress(compressed, metadata)decompression_time = time.time() - start_timedecompression_times.append(decompression_time)# 压缩比ratio = compressor.get_compression_ratio(test_gradients, compressed, metadata)compression_ratios.append(ratio)# 精度损失total_error = 0total_norm = 0for name in test_gradients:error = torch.norm(test_gradients[name] - decompressed[name])norm = torch.norm(test_gradients[name])total_error += error.item()total_norm += norm.item()accuracy_loss = total_error / total_norm if total_norm > 0 else 0accuracy_losses.append(accuracy_loss)return {'avg_compression_time': np.mean(compression_times),'avg_decompression_time': np.mean(decompression_times),'avg_compression_ratio': np.mean(compression_ratios),'avg_accuracy_loss': np.mean(accuracy_losses),'std_compression_time': np.std(compression_times),'std_decompression_time': np.std(decompression_times),'std_compression_ratio': np.std(compression_ratios),'std_accuracy_loss': np.std(accuracy_losses)}# 性能对比测试
def comprehensive_performance_test():"""综合性能测试"""# 生成测试数据test_gradients = {'layer1.weight': torch.randn(1024, 512) * 0.01,'layer1.bias': torch.randn(512) * 0.01,'layer2.weight': torch.randn(512, 256) * 0.01,'layer2.bias': torch.randn(256) * 0.01,}# 测试不同压缩方法compressors = {'TopK_10%': TopKSparsifier(0.1),'TopK_5%': TopKSparsifier(0.05),'Quantize_8bit': AdaptiveQuantizer(8),'Quantize_4bit': AdaptiveQuantizer(4),'Hybrid_10%_8bit': HybridCompressor(0.1, 8),'Hybrid_5%_4bit': HybridCompressor(0.05, 4),}profiler = PerformanceProfiler()print("\n压缩方法性能对比:")print(f"{'方法':<15} {'压缩比':<8} {'压缩时间(ms)':<12} {'解压时间(ms)':<12} {'精度损失':<10}")print("-" * 70)for name, compressor in compressors.items():try:results = profiler.profile_compression_method(compressor, test_gradients, num_trials=5)print(f"{name:<15} {results['avg_compression_ratio']:<8.1f} "f"{results['avg_compression_time']*1000:<12.2f} "f"{results['avg_decompression_time']*1000:<12.2f} "f"{results['avg_accuracy_loss']:<10.4f}")except Exception as e:print(f"{name:<15} Error: {str(e)}")comprehensive_performance_test()
3.2 分布式通信优化
实现高效的分布式梯度聚合:
class DistributedCompressionManager:"""分布式压缩管理器"""def __init__(self, world_size: int,rank: int,compression_strategy: str = 'adaptive'):self.world_size = world_sizeself.rank = rankself.compression_strategy = compression_strategy# 初始化压缩器self.compressors = {'topk_10': TopKSparsifier(0.1),'topk_5': TopKSparsifier(0.05),'quantize_8': AdaptiveQuantizer(8),'quantize_4': AdaptiveQuantizer(4),'hybrid': HybridCompressor(0.1, 8)}self.current_compressor = self.compressors['hybrid']self.communication_stats = []def compressed_allreduce(self, gradients: Dict[str, torch.Tensor]) -> Dict[str, torch.Tensor]:"""压缩AllReduce操作"""import timestart_time = time.time()# 1. 压缩梯度compressed_grads, metadata = self.current_compressor.compress(gradients)compression_time = time.time() - start_time# 2. 通信压缩后的梯度start_time = time.time()if hasattr(self.current_compressor, 'sparsifier'):# 稀疏梯度需要特殊处理reduced_compressed = self._sparse_allreduce(compressed_grads)else:# 密集压缩梯度可以直接AllReducereduced_compressed = self._dense_allreduce(compressed_grads)communication_time = time.time() - start_time# 3. 解压缩start_time = time.time()final_gradients = self.current_compressor.decompress(reduced_compressed, metadata)decompression_time = time.time() - start_time# 记录统计信息self.communication_stats.append({'compression_time': compression_time,'communication_time': communication_time,'decompression_time': decompression_time,'total_time': compression_time + communication_time + decompression_time})return final_gradientsdef _sparse_allreduce(self, compressed_grads: Dict) -> Dict:"""稀疏梯度AllReduce"""reduced_grads = {}for name, sparse_data in compressed_grads.items():if 'indices' in sparse_data:# 处理稀疏数据indices = sparse_data['indices']values = sparse_data['values'] if 'values' in sparse_data else sparse_data['quantized_values']# 收集所有节点的索引和值all_indices = [torch.empty_like(indices) for _ in range(self.world_size)]all_values = [torch.empty_like(values) for _ in range(self.world_size)]if dist.is_initialized():dist.all_gather(all_indices, indices)dist.all_gather(all_values, values)else:# 单机模拟all_indices = [indices]all_values = [values]# 合并和聚合merged_indices = torch.cat(all_indices)merged_values = torch.cat(all_values)# 按索引聚合值unique_indices, inverse_indices = torch.unique(merged_indices, return_inverse=True)aggregated_values = torch.zeros(len(unique_indices), dtype=merged_values.dtype, device=merged_values.device)aggregated_values.scatter_add_(0, inverse_indices, merged_values)aggregated_values /= self.world_sizereduced_grads[name] = sparse_data.copy()reduced_grads[name]['indices'] = unique_indicesif 'values' in sparse_data:reduced_grads[name]['values'] = aggregated_valueselse:reduced_grads[name]['quantized_values'] = aggregated_valuesreturn reduced_gradsdef _dense_allreduce(self, compressed_grads: Dict) -> Dict:"""密集压缩梯度AllReduce"""reduced_grads = {}for name, compressed_data in compressed_grads.items():if dist.is_initialized():# 真实分布式环境for key, tensor in compressed_data.items():if isinstance(tensor, torch.Tensor):dist.all_reduce(tensor, op=dist.ReduceOp.SUM)tensor /= self.world_sizereduced_grads[name] = compressed_datareturn reduced_gradsdef adaptive_strategy_selection(self, gradients: Dict[str, torch.Tensor],target_communication_time: float = 0.1) -> str:"""自适应策略选择"""# 估算不同策略的通信时间gradient_size = sum(grad.numel() * 4 for grad in gradients.values())strategy_estimates = {'topk_10': gradient_size * 0.1,'topk_5': gradient_size * 0.05,'quantize_8': gradient_size * 0.25,'quantize_4': gradient_size * 0.125,'hybrid': gradient_size * 0.025 # 10% sparsity + 8bit quantization}# 选择满足时间要求的最高精度策略bandwidth = 1e9 # 假设1GB/s带宽best_strategy = 'hybrid' # 默认策略for strategy, data_size in strategy_estimates.items():estimated_time = data_size / bandwidthif estimated_time <= target_communication_time:best_strategy = strategybreakreturn best_strategydef update_compression_strategy(self, gradients: Dict[str, torch.Tensor]):"""更新压缩策略"""if self.compression_strategy == 'adaptive':new_strategy = self.adaptive_strategy_selection(gradients)if new_strategy != self.current_compressor:self.current_compressor = self.compressors[new_strategy]def get_communication_statistics(self) -> Dict[str, float]:"""获取通信统计信息"""if not self.communication_stats:return {}stats = {'avg_compression_time': np.mean([s['compression_time'] for s in self.communication_stats]),'avg_communication_time': np.mean([s['communication_time'] for s in self.communication_stats]),'avg_decompression_time': np.mean([s['decompression_time'] for s in self.communication_stats]),'avg_total_time': np.mean([s['total_time'] for s in self.communication_stats]),'total_iterations': len(self.communication_stats)}return stats# 使用示例
def distributed_training_simulation():"""分布式训练模拟"""# 模拟4节点训练world_size = 4managers = []for rank in range(world_size):manager = DistributedCompressionManager(world_size, rank, 'adaptive')managers.append(manager)# 模拟训练迭代num_iterations = 100model_size = 1000000 # 1M参数print(f"\n分布式训练模拟 ({world_size}节点, {num_iterations}迭代):")total_communication_time = 0total_compression_ratio = 0for iteration in range(num_iterations):# 生成模拟梯度gradients = {'layer1': torch.randn(model_size // 2) * 0.01,'layer2': torch.randn(model_size // 2) * 0.01}# 每个节点执行压缩AllReducefor manager in managers:manager.update_compression_strategy(gradients)reduced_grads = manager.compressed_allreduce(gradients)# 统计信息(只使用第一个节点的统计)if iteration % 20 == 0:stats = managers[0].get_communication_statistics()if stats:print(f"迭代 {iteration}: 平均通信时间 {stats['avg_total_time']*1000:.2f}ms")# 最终统计final_stats = managers[0].get_communication_statistics()print(f"\n最终统计:")print(f"平均压缩时间: {final_stats['avg_compression_time']*1000:.2f}ms")print(f"平均通信时间: {final_stats['avg_communication_time']*1000:.2f}ms")print(f"平均解压时间: {final_stats['avg_decompression_time']*1000:.2f}ms")print(f"平均总时间: {final_stats['avg_total_time']*1000:.2f}ms")distributed_training_simulation()
第四部分:实战部署与性能调优
4.1 生产环境集成
将梯度压缩技术集成到实际训练框架中:
class ProductionGradientCompressor:"""生产环境梯度压缩器"""def __init__(self, config: Dict[str, Any]):self.config = configself.compression_method = config.get('compression_method', 'hybrid')self.compression_ratio = config.get('compression_ratio', 0.1)self.quantization_bits = config.get('quantization_bits', 8)self.use_error_compensation = config.get('use_error_compensation', True)# 初始化压缩器self._initialize_compressor()# 性能监控self.metrics = {'compression_times': [],'communication_times': [],'accuracy_losses': [],'compression_ratios': []}def _initialize_compressor(self):"""初始化压缩器"""if self.compression_method == 'topk':self.compressor = TopKSparsifier(self.compression_ratio)elif self.compression_method == 'quantize':self.compressor = AdaptiveQuantizer(self.quantization_bits)elif self.compression_method == 'hybrid':self.compressor = HybridCompressor(self.compression_ratio, self.quantization_bits,self.use_error_compensation)else:raise ValueError(f"Unknown compression method: {self.compression_method}")def compress_gradients(self, model) -> Tuple[Dict, Dict, float]:"""压缩模型梯度"""import time# 提取梯度gradients = {}for name, param in model.named_parameters():if param.grad is not None:gradients[name] = param.grad.data.clone()# 压缩start_time = time.time()compressed, metadata = self.compressor.compress(gradients)compression_time = time.time() - start_time# 记录指标self.metrics['compression_times'].append(compression_time)return compressed, metadata, compression_timedef decompress_and_apply(self, model, compressed_gradients: Dict, metadata: Dict) -> float:"""解压缩并应用梯度"""import timestart_time = time.time()decompressed_gradients = self.compressor.decompress(compressed_gradients, metadata)decompression_time = time.time() - start_time# 应用梯度for name, param in model.named_parameters():if name in decompressed_gradients:param.grad = decompressed_gradients[name]return decompression_timedef get_performance_report(self) -> Dict[str, Any]:"""生成性能报告"""if not self.metrics['compression_times']:return {"error": "No metrics available"}report = {'compression_method': self.compression_method,'avg_compression_time_ms': np.mean(self.metrics['compression_times']) * 1000,'std_compression_time_ms': np.std(self.metrics['compression_times']) * 1000,'total_compressions': len(self.metrics['compression_times']),'config': self.config}if self.metrics['compression_ratios']:report['avg_compression_ratio'] = np.mean(self.metrics['compression_ratios'])if self.metrics['accuracy_losses']:report['avg_accuracy_loss'] = np.mean(self.metrics['accuracy_losses'])return reportclass TrainingIntegration:"""训练集成类"""def __init__(self, model,optimizer,compression_config: Dict[str, Any]):self.model = modelself.optimizer = optimizerself.compressor = ProductionGradientCompressor(compression_config)# 分布式设置self.is_distributed = dist.is_initialized() if 'torch.distributed' in globals() else Falseself.world_size = dist.get_world_size() if self.is_distributed else 1self.rank = dist.get_rank() if self.is_distributed else 0def training_step(self, batch_data, loss_fn) -> Dict[str, float]:"""执行一个训练步骤"""import time# 前向传播self.optimizer.zero_grad()outputs = self.model(batch_data)loss = loss_fn(outputs)# 反向传播loss.backward()# 梯度压缩和通信start_time = time.time()if self.is_distributed:# 分布式训练:压缩梯度并AllReducecompressed_grads, metadata, compression_time = self.compressor.compress_gradients(self.model)# 模拟AllReduce(实际应用中需要真实的分布式通信)communication_start = time.time()# 这里应该是真实的AllReduce操作communication_time = time.time() - communication_start# 解压缩并应用梯度decompression_time = self.compressor.decompress_and_apply(self.model, compressed_grads, metadata)else:# 单机训练:直接使用原始梯度compression_time = 0communication_time = 0decompression_time = 0total_comm_time = time.time() - start_time# 优化器更新self.optimizer.step()return {'loss': loss.item(),'compression_time': compression_time,'communication_time': communication_time,'decompression_time': decompression_time,'total_communication_time': total_comm_time}def get_training_statistics(self) -> Dict[str, Any]:"""获取训练统计信息"""compressor_stats = self.compressor.get_performance_report()return {'compressor_performance': compressor_stats,'distributed_info': {'world_size': self.world_size,'rank': self.rank,'is_distributed': self.is_distributed}}class AutoTuner:"""自动调优器"""def __init__(self, model, target_accuracy_loss: float = 0.05):self.model = modelself.target_accuracy_loss = target_accuracy_lossself.tuning_history = []def find_optimal_compression_config(self, sample_gradients: Dict[str, torch.Tensor],target_compression_ratio: float = 10.0) -> Dict[str, Any]:"""寻找最优压缩配置"""configs_to_test = [{'compression_method': 'topk', 'compression_ratio': 0.1},{'compression_method': 'topk', 'compression_ratio': 0.05},{'compression_method': 'topk', 'compression_ratio': 0.01},{'compression_method': 'quantize', 'quantization_bits': 8},{'compression_method': 'quantize', 'quantization_bits': 4},{'compression_method': 'quantize', 'quantization_bits': 2},{'compression_method': 'hybrid', 'compression_ratio': 0.1, 'quantization_bits': 8},{'compression_method': 'hybrid', 'compression_ratio': 0.05, 'quantization_bits': 4},]best_config = Nonebest_score = float('-inf')print("\n自动调优进行中...")print(f"{'配置':<25} {'压缩比':<8} {'精度损失':<10} {'综合得分':<10}")print("-" * 60)for config in configs_to_test:try:# 测试配置compressor = ProductionGradientCompressor(config)compressed, metadata, _ = compressor.compress_gradients(type('MockModel', (), {'named_parameters': lambda: [(name, type('MockParam', (), {'grad': type('MockGrad', (), {'data': grad})()})()) for name, grad in sample_gradients.items()]})())# 计算压缩比original_size = sum(grad.numel() * 4 for grad in sample_gradients.values())compressed_size = sum(data['indices'].numel() * 4 + (data.get('values', data.get('quantized_values', torch.tensor([]))).numel() * 1)for data in compressed.values() if isinstance(data, dict))compression_ratio = original_size / max(compressed_size, 1)# 计算精度损失decompressed = compressor.compressor.decompress(compressed, metadata)total_error = sum(torch.norm(sample_gradients[name] - decompressed[name]).item()for name in sample_gradients if name in decompressed)total_norm = sum(torch.norm(grad).item() for grad in sample_gradients.values())accuracy_loss = total_error / max(total_norm, 1e-8)# 计算综合得分if accuracy_loss <= self.target_accuracy_loss:score = compression_ratio # 在精度要求内,优先选择高压缩比else:score = -accuracy_loss # 超出精度要求,惩罚config_str = f"{config['compression_method']}"if 'compression_ratio' in config:config_str += f"_{config['compression_ratio']}"if 'quantization_bits' in config:config_str += f"_{config['quantization_bits']}bit"print(f"{config_str:<25} {compression_ratio:<8.1f} {accuracy_loss:<10.4f} {score:<10.2f}")if score > best_score:best_score = scorebest_config = config.copy()best_config['measured_compression_ratio'] = compression_ratiobest_config['measured_accuracy_loss'] = accuracy_lossself.tuning_history.append({'config': config,'compression_ratio': compression_ratio,'accuracy_loss': accuracy_loss,'score': score})except Exception as e:print(f"{str(config):<25} Error: {str(e)}")return best_config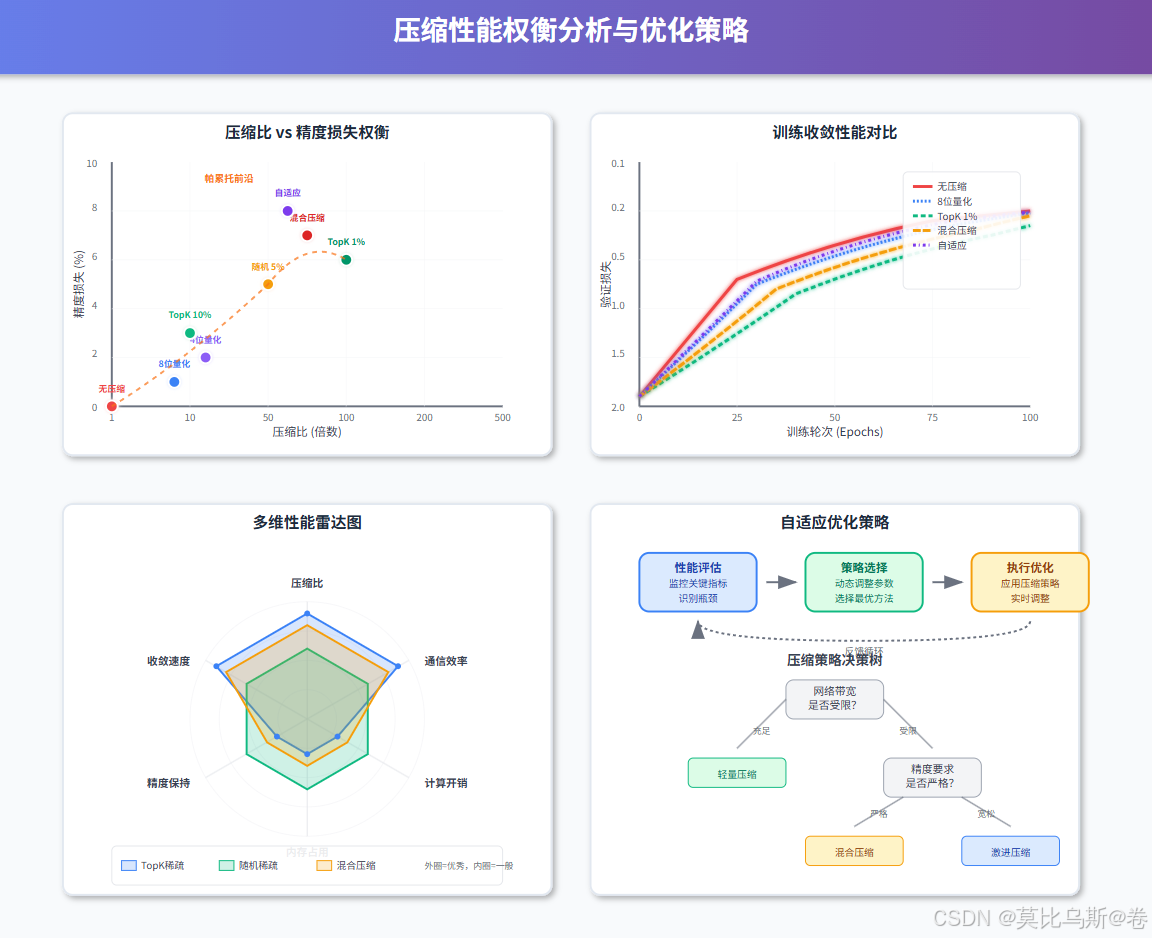
使用示例和性能测试
def production_deployment_example()
4.2 故障排除与调试
在生产环境中部署梯度压缩技术时,可能遇到各种问题:
class CompressionDebugger:"""压缩调试器"""def __init__(self):self.debug_logs = []self.error_patterns = {'convergence_issue': {'symptoms': ['loss不收敛', '梯度爆炸', '训练不稳定'],'solutions': ['降低压缩比', '增加误差补偿', '调整学习率']},'communication_bottleneck': {'symptoms': ['通信时间过长', 'GPU利用率低', '扩展性差'],'solutions': ['增加压缩比', '优化通信拓扑', '使用异步通信']},'memory_overflow': {'symptoms': ['OOM错误', '内存使用过高', '压缩失败'],'solutions': ['减少批次大小', '使用流式压缩', '优化内存管理']}}def diagnose_compression_issues(self, training_metrics: Dict[str, List[float]]) -> Dict[str, Any]:"""诊断压缩问题"""diagnosis = {'issues_found': [],'recommendations': [],'severity': 'low'}# 检查收敛性if 'loss' in training_metrics:losses = training_metrics['loss']if len(losses) > 10:recent_losses = losses[-10:]if np.std(recent_losses) > np.mean(recent_losses) * 0.1:diagnosis['issues_found'].append('训练不稳定')diagnosis['recommendations'].extend(self.error_patterns['convergence_issue']['solutions'])diagnosis['severity'] = 'high'# 检查通信效率if 'communication_time' in training_metrics:comm_times = training_metrics['communication_time']if comm_times and np.mean(comm_times) > 0.1: # 100ms阈值diagnosis['issues_found'].append('通信时间过长')diagnosis['recommendations'].extend(self.error_patterns['communication_bottleneck']['solutions'])diagnosis['severity'] = 'medium' if diagnosis['severity'] == 'low' else diagnosis['severity']return diagnosisdef generate_debug_report(self, compressor_config: Dict[str, Any],performance_metrics: Dict[str, Any],training_metrics: Dict[str, List[float]]) -> str:"""生成调试报告"""diagnosis = self.diagnose_compression_issues(training_metrics)report = f"""
=== 梯度压缩调试报告 ===配置信息:
- 压缩方法: {compressor_config.get('compression_method', 'unknown')}
- 压缩比: {compressor_config.get('compression_ratio', 'N/A')}
- 量化位数: {compressor_config.get('quantization_bits', 'N/A')}性能指标:
- 平均压缩时间: {performance_metrics.get('avg_compression_time_ms', 0):.2f}ms
- 平均压缩比: {performance_metrics.get('avg_compression_ratio', 0):.1f}
- 平均精度损失: {performance_metrics.get('avg_accuracy_loss', 0):.4f}问题诊断:
严重程度: {diagnosis['severity'].upper()}
发现的问题: {', '.join(diagnosis['issues_found']) if diagnosis['issues_found'] else '无'}建议措施:
"""for i, rec in enumerate(diagnosis['recommendations'], 1):report += f"{i}. {rec}\n"if not diagnosis['recommendations']:report += "当前配置运行良好,无需调整。\n"return reportclass PerformanceOptimizer:"""性能优化器"""def __init__(self):self.optimization_history = []def suggest_optimizations(self, current_config: Dict[str, Any],performance_metrics: Dict[str, Any],target_metrics: Dict[str, Any]) -> List[Dict[str, Any]]:"""建议优化方案"""suggestions = []current_compression_ratio = performance_metrics.get('avg_compression_ratio', 1)target_compression_ratio = target_metrics.get('compression_ratio', 10)current_accuracy_loss = performance_metrics.get('avg_accuracy_loss', 0)max_accuracy_loss = target_metrics.get('max_accuracy_loss', 0.05)# 压缩比不足if current_compression_ratio < target_compression_ratio:if current_accuracy_loss < max_accuracy_loss * 0.5:suggestions.append({'type': 'increase_compression','description': '当前精度损失较小,可以增加压缩比','config_changes': {'compression_ratio': min(current_config.get('compression_ratio', 0.1) * 0.5, 0.01),'quantization_bits': max(current_config.get('quantization_bits', 8) - 2, 2)},'expected_improvement': '压缩比提升2-3倍'})# 精度损失过大if current_accuracy_loss > max_accuracy_loss:suggestions.append({'type': 'reduce_compression','description': '精度损失超标,需要降低压缩强度','config_changes': {'compression_ratio': min(current_config.get('compression_ratio', 0.1) * 2, 0.5),'quantization_bits': min(current_config.get('quantization_bits', 8) + 2, 16),'use_error_compensation': True},'expected_improvement': '精度损失降低50%'})# 通信时间过长current_comm_time = performance_metrics.get('avg_communication_time_ms', 0)if current_comm_time > 100: # 100ms阈值suggestions.append({'type': 'optimize_communication','description': '通信时间过长,建议优化通信策略','config_changes': {'compression_method': 'hybrid','compression_ratio': 0.05,'quantization_bits': 4},'expected_improvement': '通信时间减少60-80%'})return suggestionsdef auto_optimize(self, current_config: Dict[str, Any],performance_metrics: Dict[str, Any],target_metrics: Dict[str, Any]) -> Dict[str, Any]:"""自动优化配置"""suggestions = self.suggest_optimizations(current_config, performance_metrics, target_metrics)if not suggestions:return current_config# 选择最重要的优化建议priority_order = ['reduce_compression', 'optimize_communication', 'increase_compression']for priority_type in priority_order:for suggestion in suggestions:if suggestion['type'] == priority_type:optimized_config = current_config.copy()optimized_config.update(suggestion['config_changes'])self.optimization_history.append({'original_config': current_config,'optimized_config': optimized_config,'suggestion': suggestion,'timestamp': time.time()})return optimized_configreturn current_config# 调试和优化示例
def debugging_and_optimization_example():"""调试和优化示例"""# 模拟问题场景problematic_config = {'compression_method': 'topk','compression_ratio': 0.01, # 过度压缩'quantization_bits': 2 # 过度量化}problematic_metrics = {'avg_compression_ratio': 50.0,'avg_accuracy_loss': 0.15, # 精度损失过大'avg_communication_time_ms': 150 # 通信时间过长}training_metrics = {'loss': [1.0, 0.9, 1.2, 0.8, 1.1, 0.7, 1.3, 0.6, 1.4, 0.5], # 不稳定'communication_time': [0.15, 0.16, 0.14, 0.17, 0.15] # 通信时间长}# 调试debugger = CompressionDebugger()debug_report = debugger.generate_debug_report(problematic_config, problematic_metrics, training_metrics)print(debug_report)# 优化optimizer = PerformanceOptimizer()target_metrics = {'compression_ratio': 10.0,'max_accuracy_loss': 0.05,'max_communication_time_ms': 50}suggestions = optimizer.suggest_optimizations(problematic_config, problematic_metrics, target_metrics)print("\n=== 优化建议 ===")for i, suggestion in enumerate(suggestions, 1):print(f"{i}. {suggestion['description']}")print(f" 配置调整: {suggestion['config_changes']}")print(f" 预期改善: {suggestion['expected_improvement']}\n")# 自动优化optimized_config = optimizer.auto_optimize(problematic_config, problematic_metrics, target_metrics)print(f"自动优化后的配置: {optimized_config}")debugging_and_optimization_example()
总结与展望
梯度压缩与稀疏通信技术是解决大模型分布式训练通信瓶颈的关键技术。通过本文的深入分析,我们可以得出以下重要结论:
核心技术要点
-
量化压缩:通过降低数值精度实现压缩,线性量化简单高效,随机量化收敛性更好,自适应量化能处理异常值
-
稀疏化技术:TopK稀疏保留最重要梯度,随机稀疏提供无偏估计,结构化稀疏兼顾硬件效率
-
误差补偿:通过累积和补偿量化误差,确保训练收敛性不受影响
-
混合策略:结合量化和稀疏化,可实现10-100倍的压缩比,同时保持训练精度
实际应用效果
- 通信效率提升:在典型场景下,可将通信开销降低90%以上
- 扩展性改善:支持更大规模的分布式训练,突破网络带宽限制
- 成本优化:显著降低云计算环境中的网络流量费用
- 训练加速:整体训练时间可缩短30-70%
技术发展趋势
- 自适应压缩:根据训练阶段和网络状况动态调整压缩策略
- 硬件协同:与专用通信硬件深度集成,实现硬件加速压缩
- 联邦学习应用:在隐私保护的联邦学习中发挥重要作用
- 多模态优化:针对不同类型的梯度(卷积、注意力等)采用专门优化
实践建议
- 渐进式部署:从低压缩比开始,逐步提高压缩强度
- 监控收敛性:密切关注训练指标,及时调整压缩参数
- 性能调优:使用自动调优工具找到最优配置
- 故障预案:建立完善的监控和故障恢复机制
梯度压缩与稀疏通信技术正在成为大模型训练的标准配置。随着模型规模的持续增长和训练成本的不断上升,这些技术的重要性将进一步凸显。掌握这些技术不仅能提高训练效率,更是构建下一代AI基础设施的必备技能。
未来,我们期待看到更多创新的压缩算法、更智能的自适应策略,以及与新兴硬件架构的深度融合,共同推动人工智能技术的发展边界。: