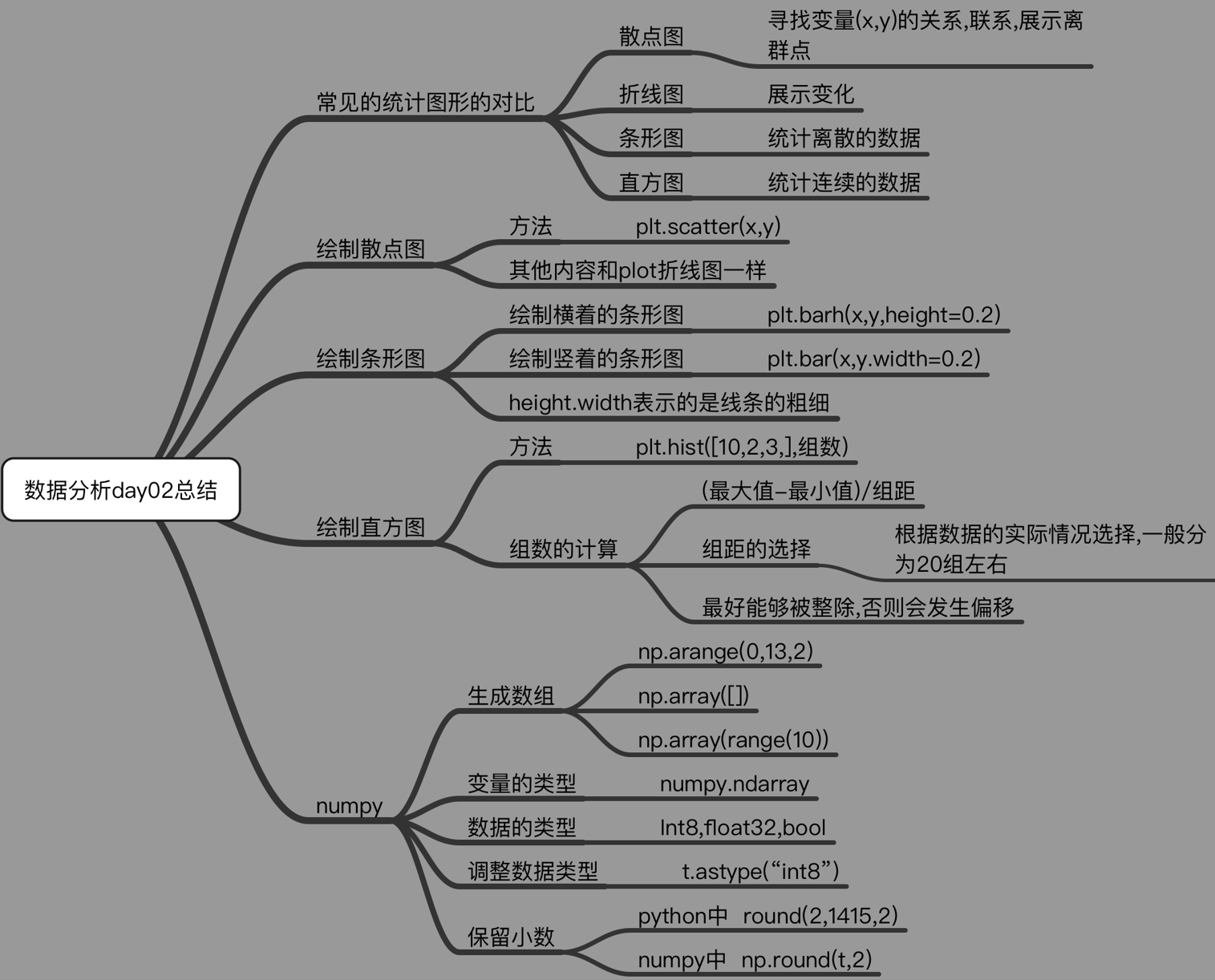
python基础数据分析与可视化
matplotlib
1.安装jupyter notebook
Jupyter Notebook是一个开源的Web应用程序,允许用户创建和共享包含实时代码、方程、可视化和解释性文本的文档。它最初由IPython团队开发,现在已经成为一个独立的项目,并广泛用于数据清理和转换、数值模拟、统计建模、数据可视化、机器学习等等。
安装jupyter notebook需要确保提前安装python
1.1使用 pip 安装 Jupyter Notebook
pip install jupyter
1.2启动Jupyter Notebook
安装成功

1.3安装pycharm
2024最新【PyCharm】史上最全PyCharm安装教程,图文教程(超详细)-CSDN博客
2.解决中文不显示的问题
import matplotlib.pyplot as plt
from matplotlib import font_manager
import matplotlib# 方法1:直接指定路径
fp = font_manager.FontProperties(fname=r"C:\Windows\Fonts\arial.ttf")# 方法2:通过字体名称查找
font_path = font_manager.findfont("SimHei") # 查找黑体
fp2 = font_manager.FontProperties(fname=font_path)# 方法3:列出所有可用字体
font_list = font_manager.findSystemFonts()
print(f"找到 {len(font_list)} 个字体文件")# 使用字体
plt.rcParams['font.family'] = ['SimHei'] # 设置全局字体
plt.plot([1, 2, 3, 4])
plt.title('测试标题')
plt.show()
import randomfrom matplotlib import pyplot as plt# 处理中文乱码问题
# 第一中方式
# import matplotlib
# font = {'family' : 'MicroSoft YaHei',
# 'weight' : 'bold',
# 'size' : '10'}
# matplotlib.rc("font",**font)
# 第二种方式
# from matplotlib import font_manager
# #需要将fp这个参数传入plt.xticks中才能针对x轴实现字体的应用,,fontproperties=fp
# fp = font_manager.FontProperties(fname=r"C:\Windows\Fonts\SimHei.ttf")
# # 方法3:列出所有可用字体
# font_list = font_manager.findSystemFonts()
# # print(f"找到 {len(font_list)} 个字体文件")
# print("可用的字体文件:", font_list[:10]) # 显示前5个字体文件
# # 选择其中一个字体
# if font_list:
# fp = font_list.FontProperties(fname=font_list[0])# 一直测试都没办法解决,通过AI辅助写代码,运行测试代码test_bold.Py,再迁移到该模块,问题得到解决
# 使用字体,一句代码解决,需要设置全局字体
plt.rcParams['font.family'] = ['SimHei'] # 设置全局字体x = range(0,120)
y = [random.randint(20,35) for i in range(120)]# 设置图像的大小
plt.figure(figsize=(16,8),dpi=80)# 绘制图片
plt.plot(x,y)# 设置x轴的坐标
_x = list(x)
_xticks_labels = ["10点{}分".format(i) for i in range(60)]
_xticks_labels += ["11点{}分".format(i) for i in range(60)]
# 取步长,数字和字符一一对应,数据的长度一样
plt.xticks(list(x)[::6],_xticks_labels[::6],rotation=45) # rotation表示旋转90度# 添加描述信息
plt.xlabel("时间")
plt.ylabel("温度 (℃)")
plt.title("10点-12点温度统计图")plt.show()
3.折线图
假设大家在30岁的时候,根据自己的实际情况,统计出来了从11岁到30岁每年交的女(男)朋友的数量如列表a,请绘制出该数据的折线图,以便分析自己每年交女(男)朋友的数量走势
a = [1,0,1,1,2,4,3,2,3,4,4,5,6,5,4,3,3,1,1,1]
要求:
y轴表示个数
x轴表示岁数,比如11岁,12岁等
from matplotlib import pyplot as plt# 使用字体
plt.rcParams['font.family'] = ['SimHei'] # 设置全局字体# 年龄
x = range(11,31)
# 设置个数
y = [1,0,1,1,2,4,3,2,3,4,4,5,6,5,4,3,3,1,1,1]# 设置图像大小
plt.figure(figsize=(16,8),dpi=80)# 绘制图片
plt.plot(x,y)# 设置x轴
_xticks_labels = ["{}岁".format(i) for i in x]
plt.xticks(x,_xticks_labels,rotation=45)
# 设置y轴
plt.yticks(range(0,9))# 图片描述
plt.xlabel("年龄")
plt.ylabel("个数")
plt.title("10岁至30岁谈男(女)朋友的数量")# 画出网格
# alpha=0.4设置透明度
plt.grid(alpha=0.2)# 显示图片
plt.show()

假设大家在30岁的时候,根据自己的实际情况,统计出来了你和你同桌各自从11岁到30岁每年交的女(男)朋友的数量如列表a和b,请在一个图中绘制出该数据的折线图,以便比较自己和同桌20年间的差异,同时分析每年交女(男)朋友的数量走势
a = [1,0,1,1,2,4,3,2,3,4,4,5,6,5,4,3,3,1,1,1]
b = [1,0,3,1,2,2,3,3,2,1 ,2,1,1,1,1,1,1,1,1,1]
要求:
y轴表示个数
x轴表示岁数,比如11岁,12岁等
from matplotlib import pyplot as plt# 使用字体
plt.rcParams['font.family'] = ['SimHei'] # 设置全局字体# 年龄
x = range(11,31)
# 设置个数
y1 = [1,0,1,1,2,4,3,2,3,4,4,5,6,5,4,3,3,1,1,1]
y2 = [1,0,3,1,2,2,3,3,2,1 ,2,1,1,1,1,1,1,1,1,1]# 设置图像大小
plt.figure(figsize=(16,8),dpi=80)# 绘制图片
# 为每条曲线增加图例 label="myself"
plt.plot(x,y1,label="myself",color = "orange",linestyle="--")
plt.plot(x,y2,label="classroom",color = "cyan")# 设置x轴
_xticks_labels = ["{}岁".format(i) for i in x]
plt.xticks(x,_xticks_labels,rotation=45)
# 设置y轴
plt.yticks(range(0,9))# 图片描述
plt.xlabel("年龄")
plt.ylabel("个数")
plt.title("10岁至30岁谈男(女)朋友的数量")# 画出网格
# alpha=0.4设置透明度
plt.grid(alpha=0.4,linestyle = ":")# 增加图例
plt.legend(loc='upper right')# 显示图片
plt.show()
总结
- 绘制了折线图(plt.plot)
- 设置了图片的大小和分辨率(plt.figure)
- 实现了图片的保存(plt.savefig)
- 设置了xy轴上的刻度和字符串(xticks)
- 解决了刻度稀疏和密集的问题(xticks)
- 设置了标题,xy轴的lable(title,xlable,ylable)
- 设置了字体(font_manager. fontProperties,matplotlib.rc)
- 在一个图上绘制多个图形(plt多次plot即可)
- 为不同的图形添加图例
对比统计图:
折线图:以折线的上升或下降来表示统计数量的增减变化的统计图
特点:能够显示数据的变化趋势,反映事物的变化情况。(变化)
直方图:由一系列高度不等的纵向条纹或线段表示数据分布的情况。 一般用横轴表示数据范围,纵轴表示分布情况。
特点:绘制连续性的数据,展示一组或者多组数据的分布状况(统计)
条形图:排列在工作表的列或行中的数据可以绘制到条形图中。
特点:绘制连离散的数据,能够一眼看出各个数据的大小,比较数据之间的差别。(统计)
散点图:用两组数据构成多个坐标点,考察坐标点的分布,判断两变量之间是否存在某种关联或总结坐标点的分布模式。
特点:判断变量之间是否存在数量关联趋势,展示离群点(分布规律)
4.散点图
不同条件(维度)之间的内在关联关系
观察数据的离散聚合程度
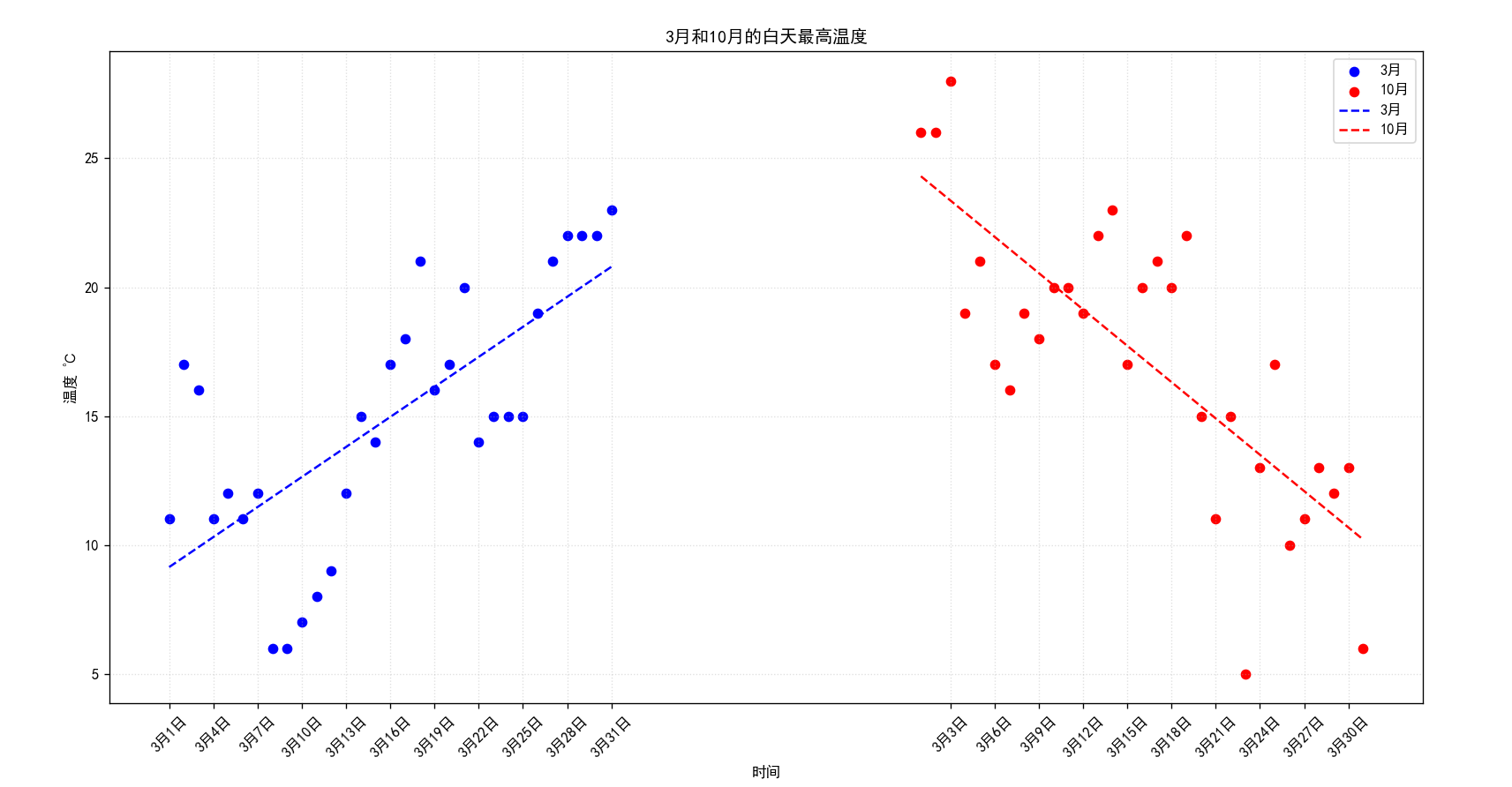
假设通过爬虫你获取到了北京2016年3,10月份每天白天的最高气温(分别位于列表a,b),那么此时如何寻找出气温和随时间(天)变化的某种规律?
a = [11,17,16,11,12,11,12,6,6,7,8,9,12,15,14,17,18,21,16,17,20,14,15,15,15,19,21,22,22,22,23]
b = [26,26,28,19,21,17,16,19,18,20,20,19,22,23,17,20,21,20,22,15,11,15,5,13,17,10,11,13,12,13,6]
数据来源: http://lishi.tianqi.com/beijing/index.html
from matplotlib import pyplot as plt
import numpy as np# 使用字体
plt.rcParams['font.family'] = ['SimHei'] # 设置全局字体# 3月最高气温
y_3 = [11,17,16,11,12,11,12,6,6,7,8,9,12,15,14,17,18,21,16,17,20,14,15,15,15,19,21,22,22,22,23]
# 10月最高气温
y_10 = [26,26,28,19,21,17,16,19,18,20,20,19,22,23,17,20,21,20,22,15,11,15,5,13,17,10,11,13,12,13,6]
# 设置时间
# x_1 = range(1,32)
# 创建天数列表(3月和10月都有31天)
days_3 = range(1, 32)
days_10 = range(52,83)# 设置图像大小
plt.figure(figsize=(16,8),dpi=80)# 绘制图片
# 绘制3月的图片
# 绘制散点图的方法scatter()
plt.scatter(days_3,y_3,color="blue",label="3月")
# 绘制10月的图片
plt.scatter(days_10,y_10,color="red",label="10月")# 为每个月份添加趋势线(线性拟合)
z3 = np.polyfit(days_3, y_3, 1) # 3月线性拟合
p3 = np.poly1d(z3)
plt.plot(days_3, p3(days_3), color='blue', linestyle='--', label='3月')
# 为每个月份添加趋势线(线性拟合)
z10 = np.polyfit(days_10, y_10, 1) # 3月线性拟合
p1 = np.poly1d(z10)
plt.plot(days_10, p1(days_10), color='red', linestyle='--', label='10月')# 调整x的刻度
days = list(days_3) + list(days_10)
_xtick_labels = ["3月{}日".format(i) for i in days_3]
_xtick_labels += ["3月{}日".format(i-51) for i in days_10]
plt.xticks(days[::3],_xtick_labels[::3],rotation=45)# 增加描述信息
plt.xlabel("时间")
plt.ylabel("温度 ℃")
plt.title("3月和10月的白天最高温度")
plt.legend()# 画出网格
plt.grid(alpha=0.4,linestyle=":")# 输出图片
plt.show()
运行效果图:
5.条形图
应用场景:
数量统计;频率统计(市场饱和度)
例题:
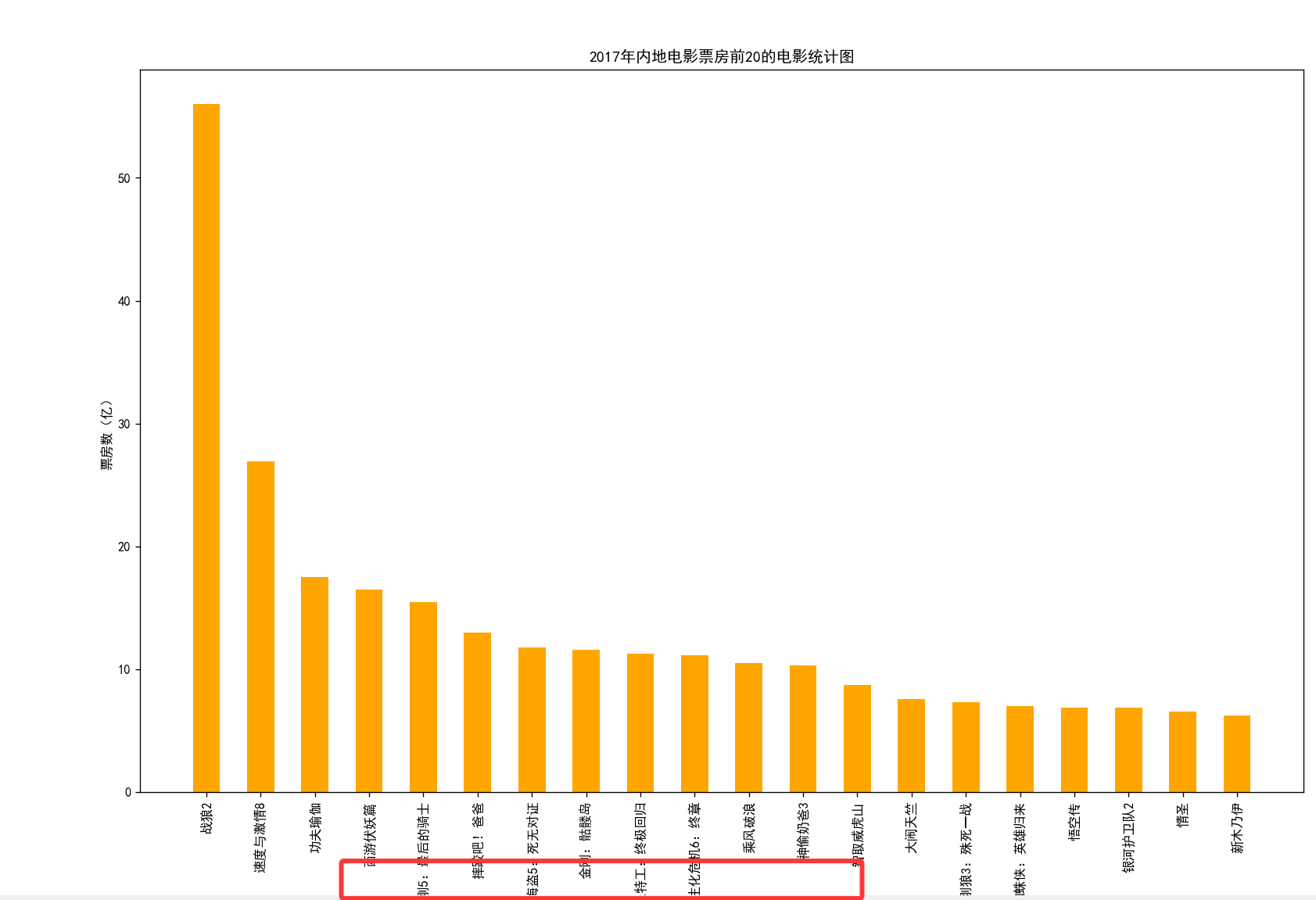
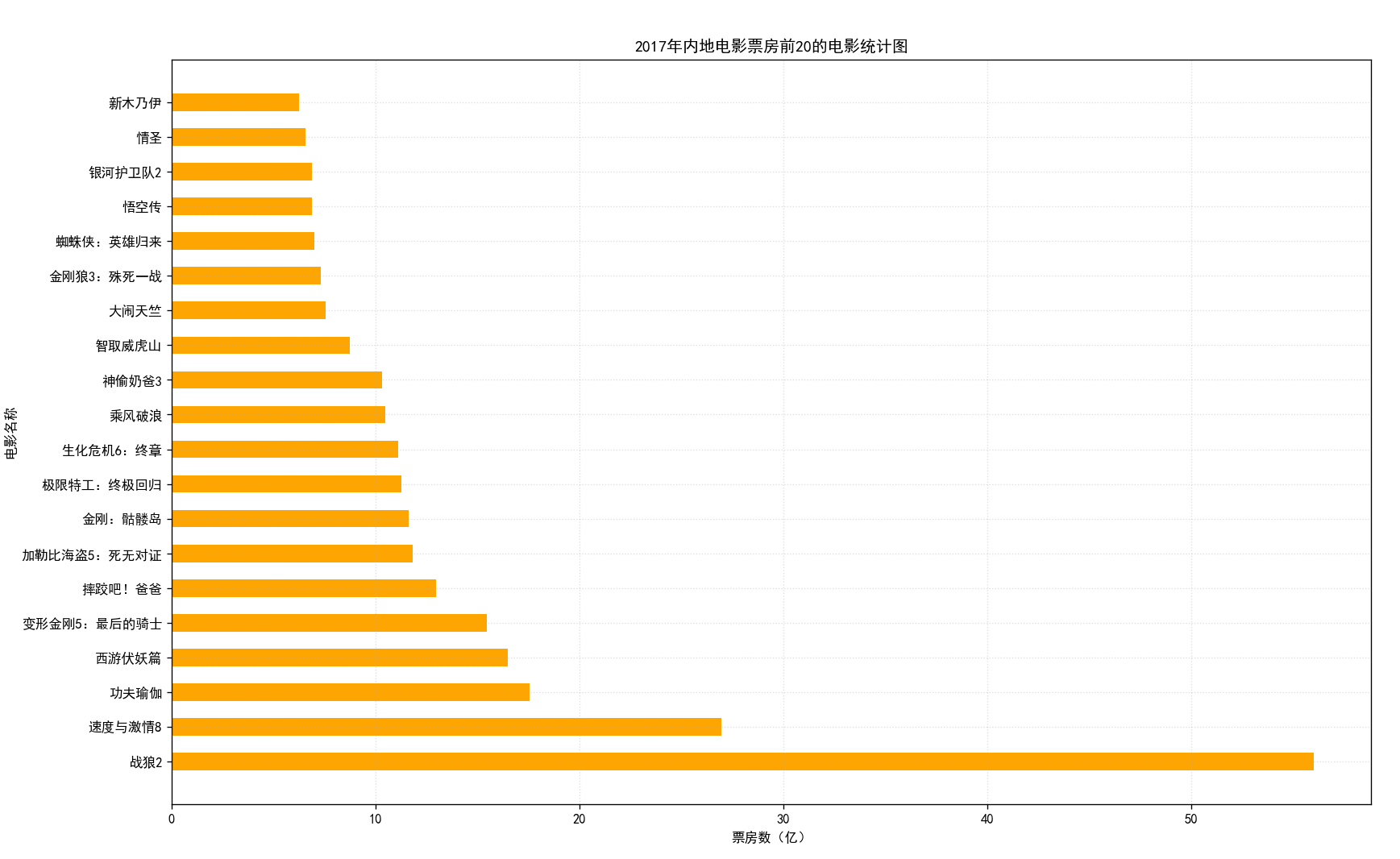
假设你获取到了2017年内地电影票房前20的电影(列表a)和电影票房数据(列表b),那么如何更加直观的展示该数据?
a = [“战狼2”,“速度与激情8”,“功夫瑜伽”,“西游伏妖篇”,“变形金刚5:最后的骑士”,“摔跤吧!爸爸”,“加勒比海盗5:死无对证”,“金刚:骷髅岛”,“极限特工:终极回归”,“生化危机6:终章”,“乘风破浪”,“神偷奶爸3”,“智取威虎山”,“大闹天竺”,“金刚狼3:殊死一战”,“蜘蛛侠:英雄归来”,“悟空传”,“银河护卫队2”,“情圣”,“新木乃伊”,]
b=[56.01,26.94,17.53,16.49,15.45,12.96,11.8,11.61,11.28,11.12,10.49,10.3,8.75,7.55,7.32,6.99,6.88,6.86,6.58,6.23] 单位:亿
数据来源: http://58921.com/alltime/2017
绘制竖着的条形图
from matplotlib import pyplot as plt# 设置中文
plt.rcParams['font.family'] = ['SimHei']# 数据
film = ["战狼2","速度与激情8","功夫瑜伽","西游伏妖篇","变形金刚5:最后的骑士","摔跤吧!爸爸","加勒比海盗5:死无对证","金刚:骷髅岛","极限特工:终极回归","生化危机6:终章","乘风破浪","神偷奶爸3","智取威虎山","大闹天竺","金刚狼3:殊死一战","蜘蛛侠:英雄归来","悟空传","银河护卫队2","情圣","新木乃伊",]
fare =[56.01,26.94,17.53,16.49,15.45,12.96,11.8,11.61,11.28,11.12,10.49,10.3,8.75,7.55,7.32,6.99,6.88,6.86,6.58,6.23]# 设置图片大小
plt.figure(figsize=(16,10),dpi=80)# 绘制图片
plt.bar(film,fare,color='orange',width=0.5)# 设置x轴
plt.xticks(film,rotation=90)# 设置描述信息
plt.xlabel("电影名称")
plt.ylabel("票房数(亿)")
plt.title("2017年内地电影票房前20的电影统计图")# 展示图片
plt.show()
运行效果:
绘制横着的条形图
# 绘制横着的条形图
from matplotlib import pyplot as plt# 设置中文
plt.rcParams['font.family'] = ['SimHei']# 数据
film = ["战狼2","速度与激情8","功夫瑜伽","西游伏妖篇","变形金刚5:最后的骑士","摔跤吧!爸爸","加勒比海盗5:死无对证","金刚:骷髅岛","极限特工:终极回归","生化危机6:终章","乘风破浪","神偷奶爸3","智取威虎山","大闹天竺","金刚狼3:殊死一战","蜘蛛侠:英雄归来","悟空传","银河护卫队2","情圣","新木乃伊",]
fare =[56.01,26.94,17.53,16.49,15.45,12.96,11.8,11.61,11.28,11.12,10.49,10.3,8.75,7.55,7.32,6.99,6.88,6.86,6.58,6.23]# 设置图片大小
plt.figure(figsize=(16,10),dpi=80)# 绘制图片,横着的条形图
plt.barh(film,fare,color='orange',height=0.5)# 设置x轴
plt.yticks(film)# 设置描述信息
plt.xlabel("票房数(亿)")
plt.ylabel("电影名称")
plt.title("2017年内地电影票房前20的电影统计图")plt.grid(alpha=0.4,linestyle=":")# 展示图片
plt.show()运行效果:
绘制多次条形图
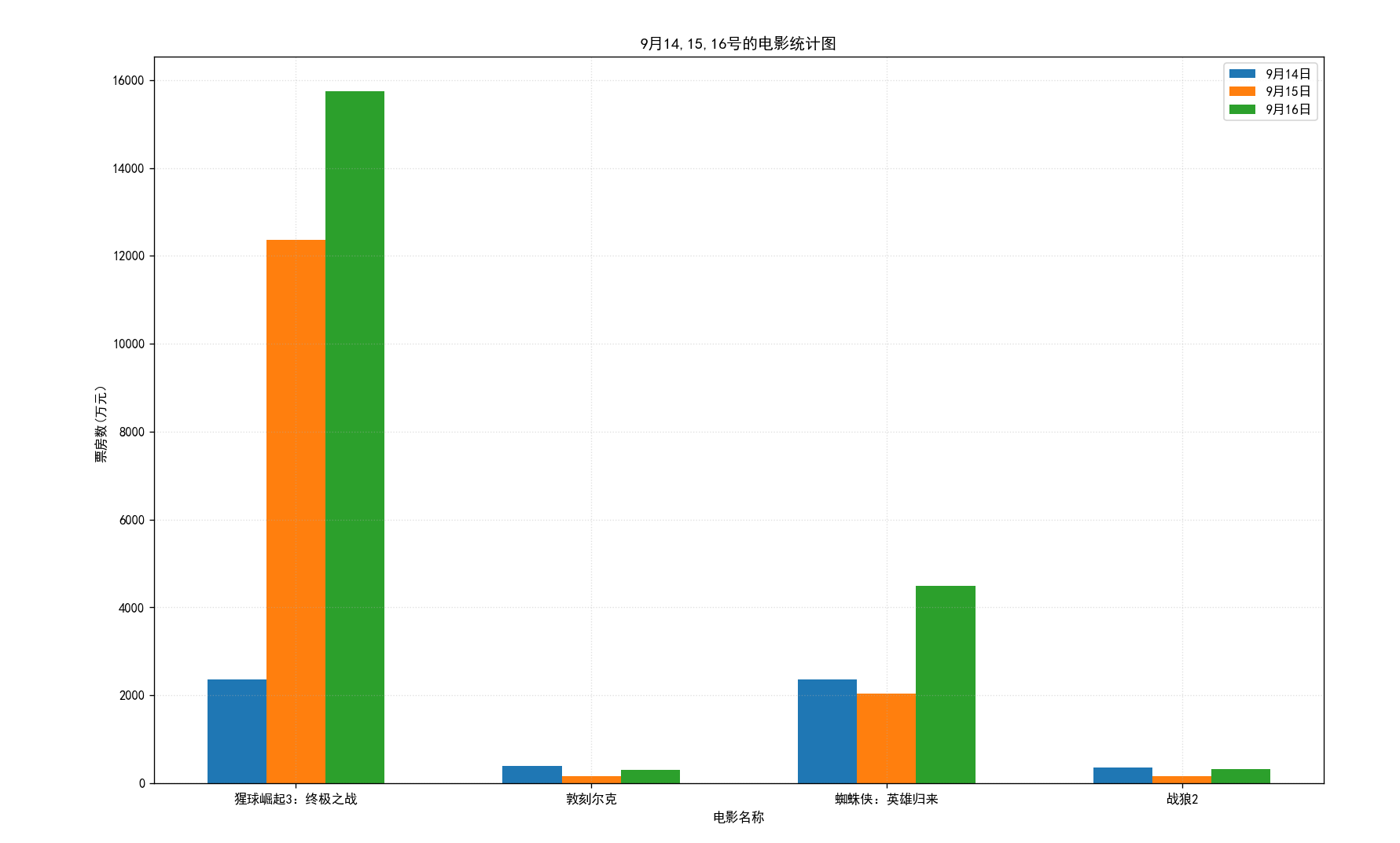
假设你知道了列表a中电影分别在2017-09-14(b_14), 2017-09-15(b_15), 2017-09-16(b_16)三天的票房,为了展示列表中电影本身的票房以及同其他电影的数据对比情况,应该如何更加直观的呈现该数据?
a = [“猩球崛起3:终极之战”,“敦刻尔克”,“蜘蛛侠:英雄归来”,“战狼2”]
b_16 = [15746,312,4497,319]
b_15 = [12357,156,2045,168]
b_14 = [2358,399,2358,362]
数据来源: http://www.cbooo.cn/movieday
# 绘制横着的条形图
from matplotlib import pyplot as plt# 设置中文
plt.rcParams['font.family'] = ['SimHei']# 数据
film = ["猩球崛起3:终极之战","敦刻尔克","蜘蛛侠:英雄归来","战狼2"]
box_office_16 = [15746,312,4497,319]
box_office_15 = [12357,156,2045,168]
box_office_14 = [2358,399,2358,362]# 设置图片大小
plt.figure(figsize=(16,10),dpi=80)bar_width = 0.2
film_14 = list(range(len(box_office_14)))
film_15 = [i+bar_width for i in film_14]
film_16 = [i+bar_width*2 for i in film_14]# 绘制图片,横着的条形图
plt.bar(film_14,box_office_14,width=bar_width,label="9月14日")
plt.bar(film_15,box_office_15,width=bar_width,label="9月15日")
plt.bar(film_16,box_office_16,width=bar_width,label="9月16日")# 设置x轴
plt.xticks(film_15,film)# 显示图例
plt.legend()# 设置描述信息
plt.ylabel("票房数(万元)")
plt.xlabel("电影名称")
plt.title("9月14,15,16号的电影统计图")plt.grid(alpha=0.4,linestyle=":")# 展示图片
plt.show()运行结果:
6.直方图
应用场景:
- 用户的年龄分布状态
- 一段时间内用户点击次数的分布状态
- 用户活跃时间的分布状态
假设你获取了250部电影的时长(列表a中),希望统计出这些电影时长的分布状态(比如时长为100分钟到120分钟电影的数量,出现的频率)等信息,你应该如何呈现这些数据?
a=[131, 98, 125, 131, 124, 139, 131, 117, 128, 108, 135, 138, 131, 102, 107, 114, 119, 128, 121, 142, 127, 130, 124, 101, 110, 116, 117, 110, 128, 128, 115, 99, 136, 126, 134, 95, 138, 117, 111,78, 132, 124, 113, 150, 110, 117, 86, 95, 144, 105, 126, 130,126, 130, 126, 116, 123, 106, 112, 138, 123, 86, 101, 99, 136,123, 117, 119, 105, 137, 123, 128, 125, 104, 109, 134, 125, 127,105, 120, 107, 129, 116, 108, 132, 103, 136, 118, 102, 120, 114,105, 115, 132, 145, 119, 121, 112, 139, 125, 138, 109, 132, 134,156, 106, 117, 127, 144, 139, 139, 119, 140, 83, 110, 102,123,107, 143, 115, 136, 118, 139, 123, 112, 118, 125, 109, 119, 133,112, 114, 122, 109, 106, 123, 116, 131, 127, 115, 118, 112, 135,115, 146, 137, 116, 103, 144, 83, 123, 111, 110, 111, 100, 154,136, 100, 118, 119, 133, 134, 106, 129, 126, 110, 111, 109, 141,120, 117, 106, 149, 122, 122, 110, 118, 127, 121, 114, 125, 126,114, 140, 103, 130, 141, 117, 106, 114, 121, 114, 133, 137, 92,121, 112, 146, 97, 137, 105, 98, 117, 112, 81, 97, 139, 113,134, 106, 144, 110, 137, 137, 111, 104, 117, 100, 111, 101, 110,105, 129, 137, 112, 120, 113, 133, 112, 83, 94, 146, 133, 101,131, 116, 111, 84, 137, 115, 122, 106, 144, 109, 123, 116, 111,111, 133, 150]

# 代码需求
# 假设你获取了250部电影的时长(列表a中),
# 希望统计出这些电影时长的分布状态(比如时长为100分钟到120分钟电影的数量,出现的频率)等信息,
# 你应该如何呈现这些数据?from matplotlib import pyplot as plt
import numpy as np# 设置全局字体
plt.rcParams['font.family'] = ['SimHei']# 导入数据
# 分组建议:小数据集 (n < 100):使用 5-10 个分组
# 中等数据集 (100 < n < 1000):使用 10-20 个分组
# 大数据集 (n > 1000):使用 20-50 个分组
# 探索性分析:尝试多种分组方式,观察数据分布特征
data =[131, 98, 125, 131, 124, 139, 131, 117, 128, 108, 135, 138, 131, 102, 107, 114, 119, 128, 121, 142, 127, 130, 124, 101,110, 116, 117, 110, 128, 128, 115, 99, 136, 126, 134, 95, 138, 117, 111,78, 132, 124, 113, 150, 110, 117, 86, 95,144, 105, 126, 130,126, 130, 126, 116, 123, 106, 112, 138, 123, 86, 101, 99, 136,123, 117, 119, 105, 137, 123, 128,125, 104, 109, 134, 125, 127,105, 120, 107, 129, 116, 108, 132, 103, 136, 118, 102, 120, 114,105, 115, 132, 145, 119,121, 112, 139, 125, 138, 109, 132, 134,156, 106, 117, 127, 144, 139, 139, 119, 140, 83, 110, 102,123,107, 143, 115,136, 118, 139, 123, 112, 118, 125, 109, 119, 133,112, 114, 122, 109, 106, 123, 116, 131, 127, 115, 118, 112, 135,115,146, 137, 116, 103, 144, 83, 123, 111, 110, 111, 100, 154,136, 100, 118, 119, 133, 134, 106, 129, 126, 110, 111, 109,141,120, 117, 106, 149, 122, 122, 110, 118, 127, 121, 114, 125, 126,114, 140, 103, 130, 141, 117, 106, 114, 121, 114,133, 137, 92,121, 112, 146, 97, 137, 105, 98, 117, 112, 81, 97, 139, 113,134, 106, 144, 110, 137, 137, 111, 104,117, 100, 111, 101, 110,105, 129, 137, 112, 120, 113, 133, 112, 83, 94, 146, 133, 101,131, 116, 111, 84, 137, 115,122, 106, 144, 109, 123, 116, 111,111, 133, 150]# y = range(min(x),max(x))# 设置图片大小
plt.figure(figsize=(18,8),dpi=80)# 绘制直方图
# plt.hist(x,y)
# 方法1:指定分组数量: bins=20
# plt.hist(data, bins=20, alpha=0.7, edgecolor='black')
# 方法2:使用numpy的histogram_bin_edges自动计算
# bin_edges = np.histogram_bin_edges(data, bins='auto')
# plt.hist(data, bins=bin_edges, alpha=0.7, edgecolor='black')
# 使用课程计算分组
width = 3
num_bins = (max(data)-min(data)) //width
plt.hist(data,num_bins,edgecolor='blue',density=True)# 设置x轴刻度
plt.xticks(range(min(data),max(data)+width,width))# 增加网格线
plt.grid(alpha=0.4,linestyle="-.")# 展示图片
plt.show()问题:
在美国2004年人口普查发现有124 million的人在离家相对较远的地方工作。根据他们从家到上班地点所需要的时间,通过抽样统计(最后一列)出了下表的数据,这些数据能够绘制成直方图么?
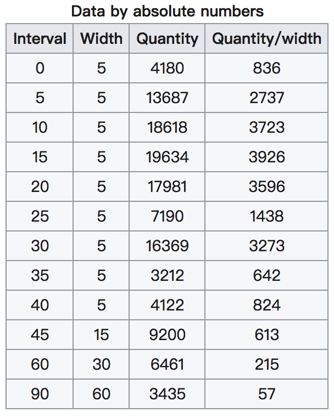
interval = [0,5,10,15,20,25,30,35,40,45,60,90]
width = [5,5,5,5,5,5,5,5,5,15,30,60]
quantity = [836,2737,3723,3926,3596,1438,3273,642,824,613,215,47]
数据来源:https://en.wikipedia.org/wiki/Histogram
普查报告地址:https://www.census.gov/prod/2004pubs/c2kbr-33.pdf
前面的问题问的是什么呢? 问的是:哪些数据能够绘制直方图。
前面的问题中给出的数据都是统计之后的数据,所以为了达到直方图的效果,需要绘制条形图。
所以:一般来说能够使用plt.hist方法的的是那些没有统计过的数据。
matplotlib常见问题总结
- 应该选择那种图形来呈现数据
- matplotlib.plot(x,y)
- matplotlib.bar(x,y)
- matplotlib.scatter(x,y)
- matplotlib.hist(data,bins,normed)
- xticks和yticks的设置
- label和titile,grid的设置
- 绘图的大小和保存图片
matplotlib使用的流程总结
- 明确问题
- 选择图形的呈现方式
- 准备数据
- 绘图和图形完善
matplotlib更多的图形样式:
matplotlib支持的图形是非常多的,如果有其他的需求,可以查看一下url地址:http://matplotlib.org/gallery/index.html
更多的绘图工具:
plotly:可视化工具中的github,相比于matplotlib更加简单,图形更加漂亮,同时兼容matplotlib和pandas
使用用法:简单,照着文档写即可
文档地址: https://plot.ly/python/
总结
numpy学习
1.基础概念
- 快速
- 方便
- 科学计算的基础库
什么是numpy:一个在Python中做科学计算的基础库,重在数值计算,也是大部分PYTHON科学计算库的基础库,多用于在大型、多维数组上执行数值运算。
numpy中常见的更多数据类型:

2.创建数组(矩阵)
import randomimport numpy as np
# 创建数组
a = np.array([1,2,3,4])
print(a) #[1 2 3 4]
print(a.dtype) #默认int64b = np.array(range(9))
print(b) #[0 1 2 3 4 5 6 7 8]print("+"*20)
c = np.arange(1,9)
print(c) #[1 2 3 4 5 6 7 8]
print(c.dtype) #int64
d = np.arange(1,9,dtype="int8")
print(d.dtype) #int8print("="*20)
t1 = np.array([1,0,1,1,0],dtype=np.bool)
print(t1) #[ True False True True False]
print(t1.dtype) #boolprint("="*20)
t2 = np.array([random.random() for i in range(10)])
# [0.65683302 0.57608277 0.08110183 0.84688298 0.0918024 0.36220563
# 0.0589628 0.63071695 0.96216577 0.17804765]
print(t2)
# 保留两位小数
t3 = np.round(t2,2)
# [0.86 0.97 0.33 0.51 0.93 0.97 0.07 0.82 0.06 0.47]
print(t3)3.数组的形状


4.数组和数组的计算
广播机制
在numpy中可以理解为方向,使用0,1,2…数字表示,对于一个一维数组,只有一个0轴,对于2维数组(shape(2,2)),有0轴和1轴,对于三维数组(shape(2,2, 3)),有0,1,2轴。
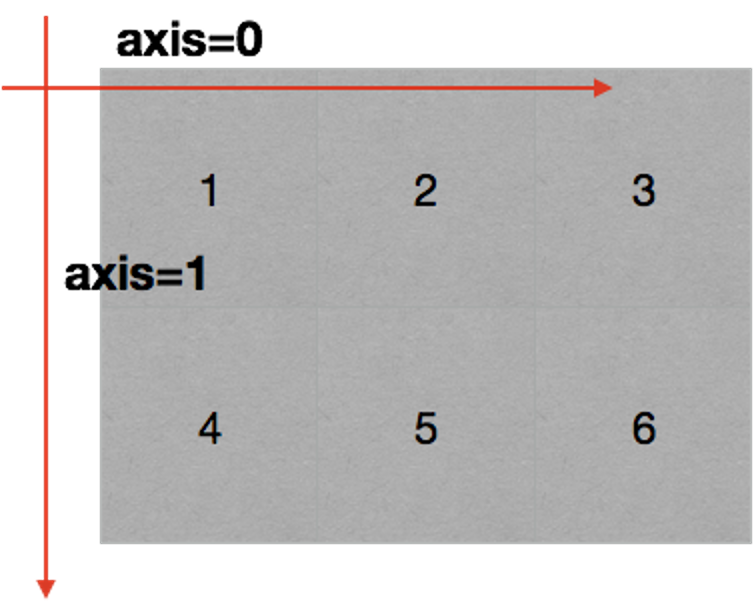
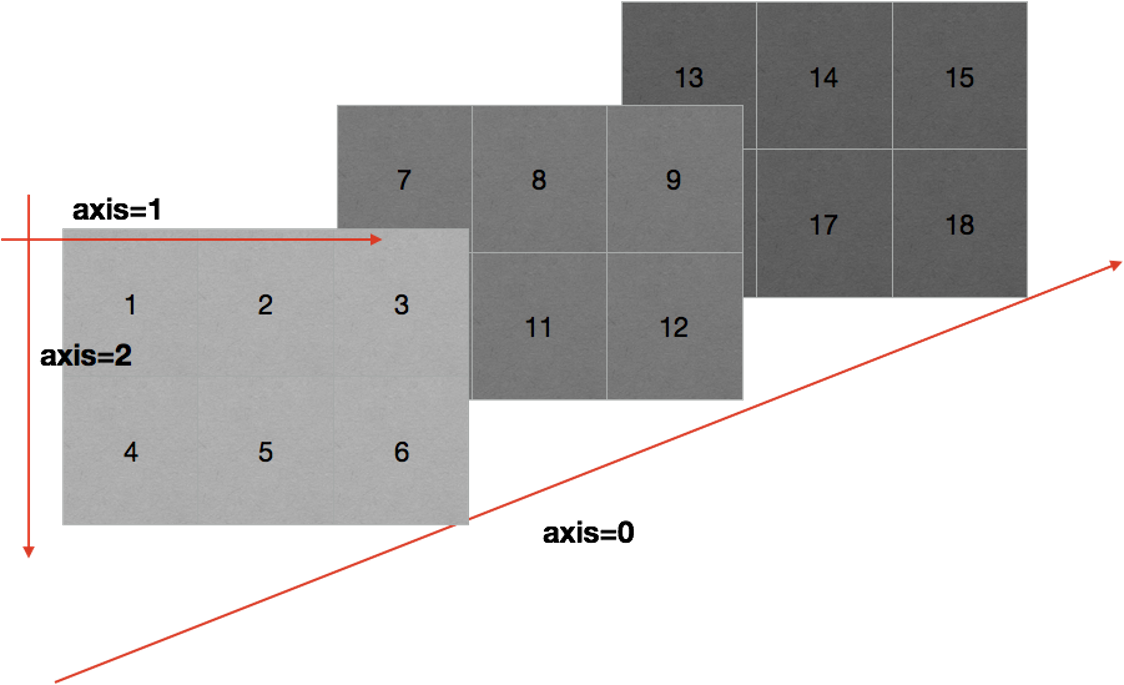
5.numpy读取和存储数据
CSV:Comma-Separated Value,逗号分隔值文件
显示:表格状态
源文件:换行和逗号分隔行列的格式化文本,每一行的数据表示一条记录
由于csv便于展示,读取和写入,所以很多地方也是用csv的格式存储和传输中小型的数据,为了方便教学,我们会经常操作csv格式的文件,但是操作数据库中的数据也是很容易的实现的。
np.loadtxt(fname,dtype=np.float,delimiter=None,skiprows=0,usecols=None,unpack=False)
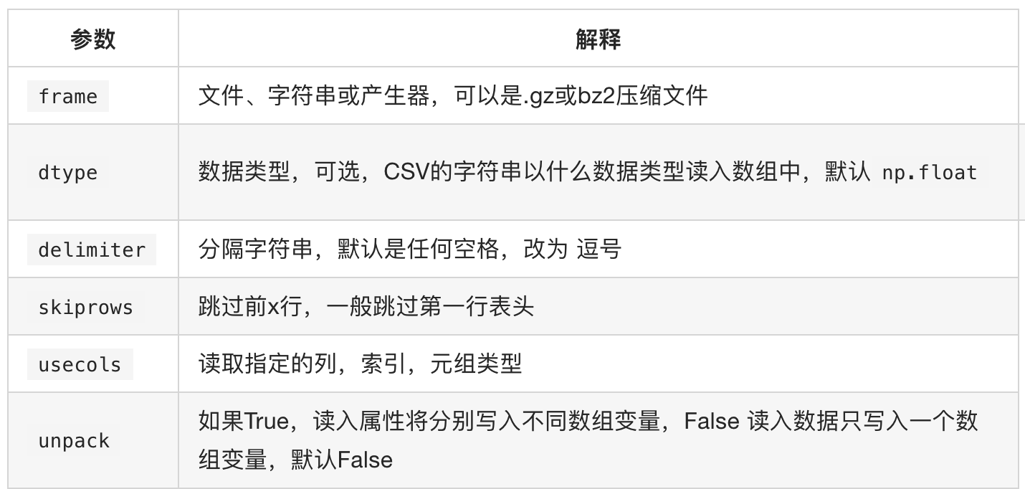
注意其中添加delimiter和dtype以及unpack的效果
delimiter:指定边界符号是什么,不指定会导致每行数据为一个整体的字符串而报错
dtype:默认情况下对于较大的数据会将其变为科学计数的方式
那么unpack的效果呢?
upack:默认是Flase(o),默认情况下,有多少条数据,就会有多少行
为True(1)的情况下,每一列的数据会组成一行,原始数据有多少列,加载出来的数据就会有多少行,相当于
转置的效果
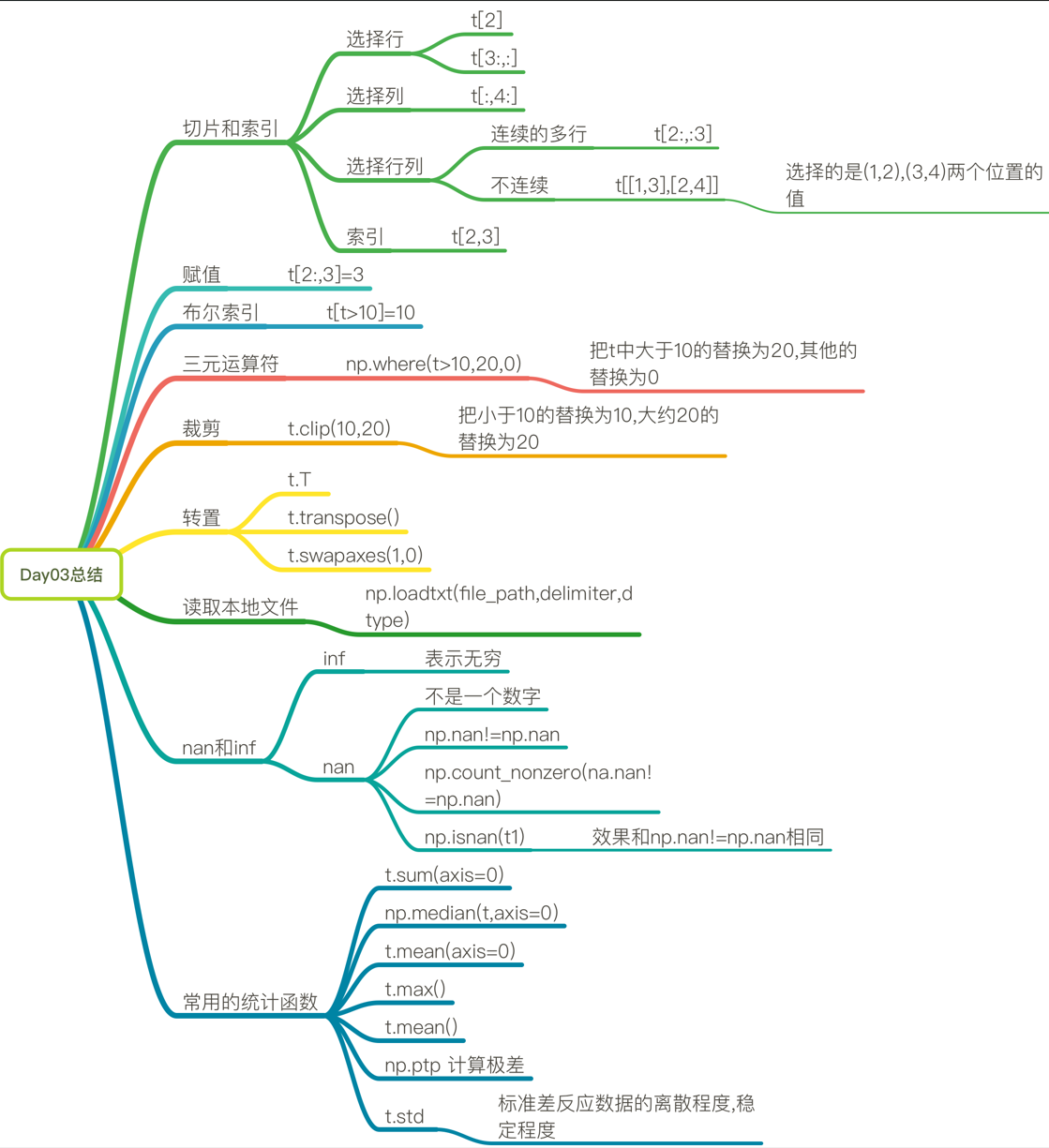
numpy索引和切片
numpy中数值的修改
numpy中布尔索引 np.where()
numpy中的clip(裁剪),t.clip(10,18),小于10的替换为10,大于18的替换为了18,但是nan没有被替换
numpy中的nan和inf
nan(NAN,Nan):not a number表示不是一个数字
什么时候numpy中会出现nan:
当我们读取本地的文件为float的时候,如果有缺失,就会出现nan
当做了一个不合适的计算的时候(比如无穷大(inf)减去无穷大)
inf(-inf,inf):infinity,inf表示正无穷,-inf表示负无穷
什么时候回出现inf包括(-inf,+inf)
比如一个数字除以0,(python中直接会报错,numpy中是一个inf或者-inf)

numpy中常用统计函数:
求和:t.sum(axis=None)
均值:t.mean(a,axis=None) 受离群点的影响较大
中值:np.median(t,axis=None)
最大值:t.max(axis=None)
最小值:t.min(axis=None)
极值:np.ptp(t,axis=None) 即最大值和最小值只差
标准差:t.std(axis=None) ,标准差是一组数据平均值分散程度的一种度量。一个较大的标准差,代表大部分数值和其平均值之间差异较大;一个较小的标准差,代表这些数值较接近平均值反映出数据的波动稳定情况,越大表示波动越大,越不稳定
默认返回多维数组的全部的统计结果,如果指定axis则返回一个当前轴上的结果
例题:现在这里有一个英国和美国各自youtube1000多个视频的点击、喜欢、不喜欢、评论数量。([“views”,“likes”,“dislikes”,“comment_total”])的csv,运用刚刚所学习的只是,我们尝试来对其进行操作。
数据来源:https://www.kaggle.com/datasnaek/youtube/data
import numpy as npuk_file_path = "../numpy/GB_video_data_numbers.csv"
us_file_path = "../numpy/US_video_data_numbers.csv"t1 = np.loadtxt(us_file_path,delimiter=",",dtype="int")
# t2 = np.loadtxt(us_file_path,delimiter=",",dtype="int",unpack=True)#转置输出print(t1)
print("#"*100)
# print(t2)
# 按行取值
# print(t1[2])
# 连续取多行
print(t1[2:4])
# 取不连续的多行
print("#"*100)
print(t1[[2,5,8]])# 取列
print(t1[:,3])# 取连续的多列
print("#"*100)
print(t1[:,2:])# 取不连续的多列
print("#"*100)
print(t1[:,[0,2]])# 取多个不相邻的点
print("#"*100)
# 选出的位置为(1,0)(3,2)
print(t1[[1,3],[0,2]])现在我希望把之前案例中两个国家的数据方法一起来研究分析,那么应该怎么做?
import numpy as npuk_file_path = "../numpy/GB_video_data_numbers.csv"
us_file_path = "../numpy/US_video_data_numbers.csv"# 加载数据
us_date = np.loadtxt(us_file_path,delimiter=",",dtype="int")
uk_date = np.loadtxt(uk_file_path,delimiter=",",dtype="int")# 构造全为0,1的数作为标记
zeros_date = np.zeros((us_date.shape[0],1)).astype(int)
ones_date = np.ones((uk_date.shape[0],1)).astype(int)
# print(zeros_date)
# print(ones_date)# 分别添加一列全为0,1的数组
us_date = np.hstack((us_date,zeros_date))
uk_date = np.hstack((uk_date,ones_date))# 拼接两组数据
final_date = np.vstack((us_date,uk_date))
print(final_date)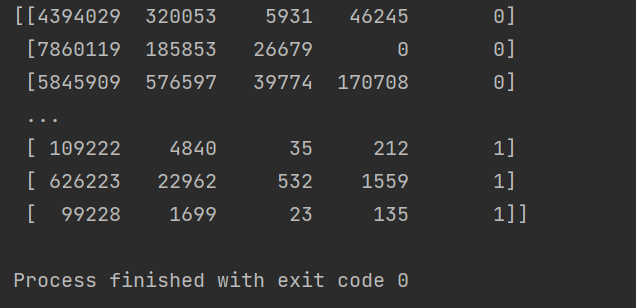
numpy更多好用的方法:
- 获取最大值最小值的位置
np.argmax(t,axis=0)
np.argmin(t,axis=1) - 创建一个全0的数组: np.zeros((3,4))
- 创建一个全1的数组:np.ones((3,4))
- 创建一个对角线为1的正方形数组(方阵):np.eye(3)
numpy生成随机数:

均匀分布:在相同的大小范围内的出现概率是等可能的
正态分布:呈钟型,两头低,中间高,左右对称
numpy的注意点copy和view
- a=b 完全不复制,a和b相互影响
- a = b[:],视图的操作,一种切片,会创建新的对象a,但是a的数据完全由b保管,他们两个的数据变化是一致的,
- a = b.copy(),复制,a和b互不影响
6.练习题
现在这里有一个英国和美国各自youtube1000多个视频的点击、喜欢、不喜欢、评论数量。([“views”,“likes”,“dislikes”,“comment_total”])的csv,运用刚刚所学习的只是,我们尝试来对其进行操作。
英国和美国各自youtube1000的数据结合之前的matplotlib绘制出各自的评论数量的直方图
import numpy as np
from matplotlib import pyplot as plt
uk_file_path = "../numpy/GB_video_data_numbers.csv"
us_file_path = "../numpy/US_video_data_numbers.csv"# 加载数据
us_date = np.loadtxt(us_file_path,delimiter=",",dtype="int")
uk_date = np.loadtxt(uk_file_path,delimiter=",",dtype="int")# 取“评论”列的数据
us_date_comments = us_date[:,-1]
us_date_comments = us_date_comments[us_date_comments<5000]
print(us_date_comments)
print(us_date_comments.max(),us_date_comments.min()) # 582624 0# 手动设置组数
d = 50
bin_nums = (us_date_comments.max()-us_date_comments.min())//d# 绘图
plt.figure(figsize=(16,8),dpi=80)plt.hist(us_date_comments,bin_nums)# 显示图片
plt.show()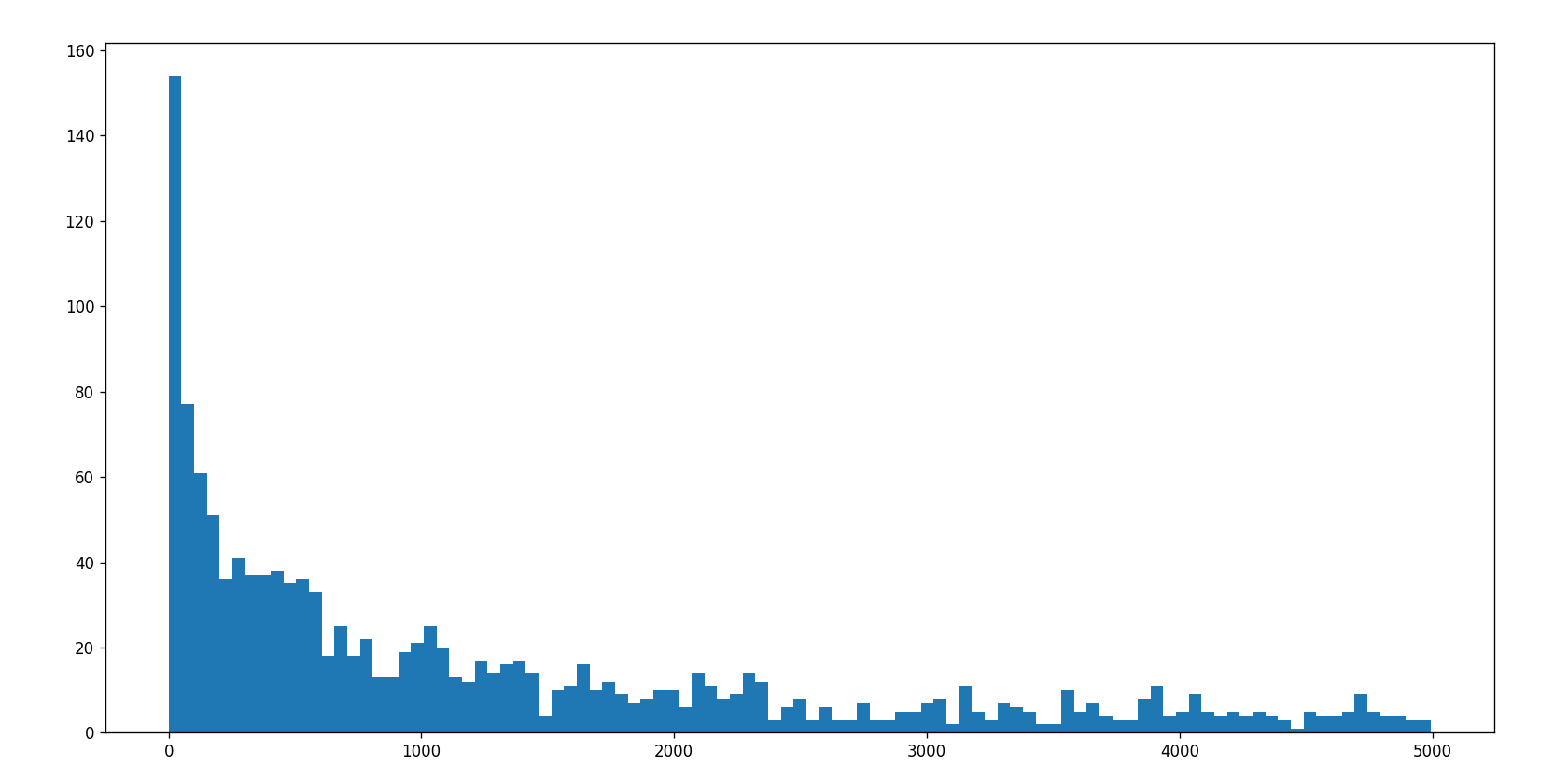
希望了解英国的youtube中视频的评论数和喜欢数的关系,应该如何绘制该图?
import numpy as np
from matplotlib import pyplot as plt
uk_file_path = "../numpy/GB_video_data_numbers.csv"
us_file_path = "../numpy/US_video_data_numbers.csv"# 加载数据
us_date = np.loadtxt(us_file_path,delimiter=",",dtype="int")
uk_date = np.loadtxt(uk_file_path,delimiter=",",dtype="int")# 选择“喜欢数”小于500000的数据
uk_date = uk_date[uk_date[:,1]<=500000]# 取“评论”列的数据
uk_date_comments = uk_date[:,-1]
# 取"喜欢“列的数据
uk_date_like = uk_date[:,1]plt.figure(figsize=(16,8),dpi=80)
plt.scatter(uk_date_like,uk_date_comments)# 添加趋势线(线性拟合)
z3 = np.polyfit(uk_date_like, uk_date_comments, 1) # 3月线性拟合
p3 = np.poly1d(z3)
plt.plot(uk_date_like, p3(uk_date_like), color='blue', linestyle='--')plt.show()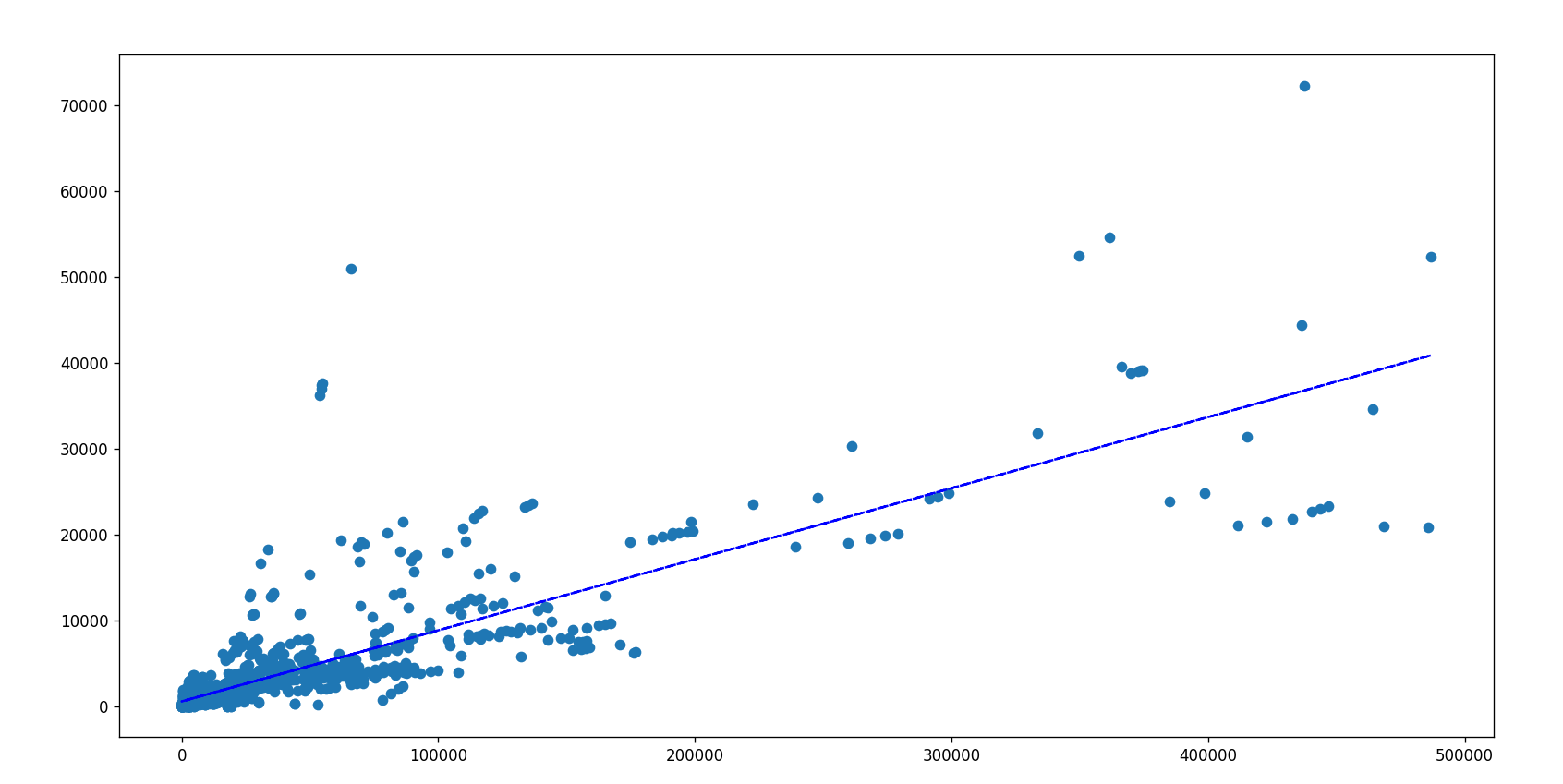
7.总结
pandas学习
使用清华大学的pandas镜像进行安装:
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple pandas
查看安装模块有哪些
python -m pip list
1.为什么要学习pandas?
那么问题来了:numpy已经能够帮助我们处理数据,能够结合matplotlib解决我们数据分析的问题,那么pandas学习的目的在什么地方呢?
numpy能够帮我们处理处理数值型数据,但是这还不够。很多时候,我们的数据除了数值之外,还有字符串,还有时间序列等。
比如:我们通过爬虫获取到了存储在数据库中的数据。
比如:之前youtube的例子中除了数值之外还有国家的信息,视频的分类(tag)信息,标题信息等。
所以,numpy能够帮助我们处理数值,但是pandas除了处理数值之外(基于numpy),还能够帮助我们处理其他类型的数据
pandas的常用数据类型:
- Series 一维,带标签数组
- DataFrame 二维,Series容器
2.Series创建、切片、索引
注意这样几个问题:
pd.Series能干什么,能够传入什么类型的数据让其变为series结构;
index是什么,在什么位置,对于我们常见的数据库数据或者ndarray来说,index到底是什么;如何给一组数据指定index?
pandas之Series切片和索引:
切片:直接传入startend或者步长即可
索引:一个的时候直接传入序号或者index,多个的时候传入序号或者index的列表
pandas之Series的索引和值:
Series对象本质上由两个数组构成,一个数组构成对象的键(index,索引),一个数组构成对象的值(values),键->值
ndarray的很多方法都可以运用于series类型,比如argmax,clip
series具有where方法,但是结果和ndarray不同
import stringimport pandas as pd
import numpy as npt = pd.Series(np.arange(5),index=list(string.ascii_uppercase[:5]))
print(t)
# A 0
# B 1
# C 2
# D 3
# E 4
# dtype: int64
print(type(t)) #<class 'pandas.core.series.Series'>
print("="*100)# 通过字典创建一个Series,注意其中的索引就是字典的键
test_dict = {"name":"zhangsan","sutID":"1122","tel":"10909"}
t2 = pd.Series(test_dict)
# name zhangsan
# sutID 1122
# tel 10909
# dtype: object
print(t2)3.Series读取外部数据
import pandas as pd# pandas从CSV文件中读取数据
df = pd.read_csv("../day03/numpy/GBvideos.csv")
# video_id ... date
# 0 jt2OHQh0HoQ ... 13.09
# 1 AqokkXoa7uE ... 13.09
# 2 YPVcg45W0z4 ... 13.09
# 3 T_PuZBdT2iM ... 13.09
# 4 NsjsmgmbCfc ... 13.09
print(df)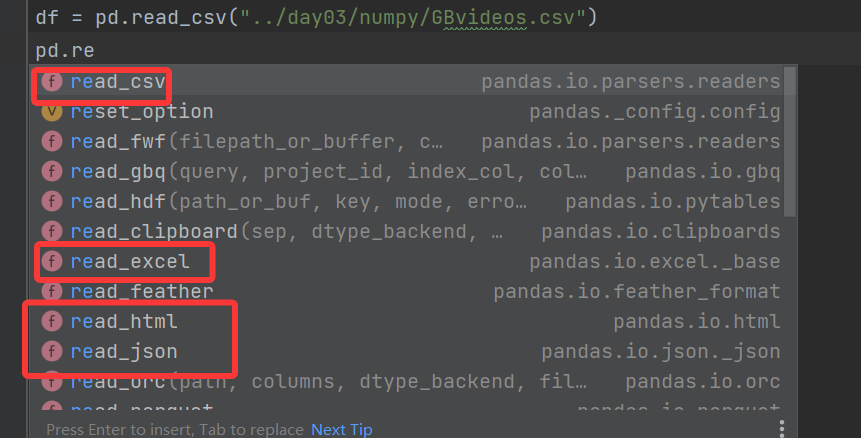
我们的这组数据存在csv中,我们直接使用pd. read_csv即可
和我们想象的有些差别,我们以为他会是一个Series类型,但是他是一个DataFrame,那么接下来我们就来了解这种数据类型
但是,还有一个问题:
对于数据库比如mysql或者mongodb中数据我们如何使用呢?
pd.read_sql(sql_sentence,connection)
那么,mongodb呢?
C:\Users\22141> pip install pymongo -i http://mirrors.aliyun.com/pypi/simple --trusted-host mirrors.aliyun.com
Looking in indexes: http://mirrors.aliyun.com/pypi/simple
Collecting pymongoDownloading http://mirrors.aliyun.com/pypi/packages/4d/68/9ddf20d882508dae1ef5a6199a634221d3062e3458d29311c3834cc9810c/pymongo-4.15.0-cp313-cp313-win_amd64.whl (961 kB)━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 961.6/961.6 kB 8.9 MB/s 0:00:00
Collecting dnspython<3.0.0,>=1.16.0 (from pymongo)Downloading http://mirrors.aliyun.com/pypi/packages/ba/5a/18ad964b0086c6e62e2e7500f7edc89e3faa45033c71c1893d34eed2b2de/dnspython-2.8.0-py3-none-any.whl (331 kB)
Installing collected packages: dnspython, pymongo
Successfully installed dnspython-2.8.0 pymongo-4.15.0from pymongo import MongoClientclient = MongoClient()collection = client["douban"]["tv1"]
data = list(collection.find())print(data)
出现上述错误是因为没有安装mongodb服务。
阅读这个教程:[(99+ 封私信 / 1 条消息) 解决:pymongo.errors.ServerSelectionTimeoutError: localhost:27017: WinError 10061] 由于目标计算机积极拒绝,无法连接。 - 知乎
4.DataFrame基础属性
DataFrame对象既有行索引,又有列索引
行索引,表明不同行,横向索引,叫index,0轴,axis=0
列索引,表名不同列,纵向索引,叫columns,1轴,axis=1
import pandas as pd
import numpy as npt1 = pd.DataFrame(np.arange(12).reshape(3,4))# 0 1 2 3
# 0 0 1 2 3
# 1 4 5 6 7
# 2 8 9 10 11
print(t1)t2 = pd.DataFrame(np.arange(12).reshape(3,4),index=list("abc"),columns=list("wxyz"))
# w x y z
# a 0 1 2 3
# b 4 5 6 7
# c 8 9 10 11
print(t2)和一个ndarray一样,我们通过shape,ndim,dtype了解这个ndarray的基本信息,那么对于DataFrame我们有什么方法了解呢?

现在假设我们有一个组关于狗的名字的统计数据,那么为了观察这组数据的情况,我们应该怎么做呢?
数据来源:https://www.kaggle.com/new-york-city/nyc-dog-names/data
import pandas as pddf = pd.read_csv("../day04/dogNames2.csv")# print(list(df))
# print(df)
# Row_Labels Count_AnimalName
# 0 1 1
# 1 2 2
# 2 40804 1
# 3 90201 1
# 4 90203 1
print(df.head())
print("*"*100)
# <class 'pandas.core.frame.DataFrame'>
# RangeIndex: 16220 entries, 0 to 16219
# Data columns (total 2 columns):
# # Column Non-Null Count Dtype
# --- ------ -------------- -----
# 0 Row_Labels 16217 non-null object
# 1 Count_AnimalName 16220 non-null int64
# dtypes: int64(1), object(1)
# memory usage: 253.6+ KB
# None
print(df.info())print("="*100)
# dataFrame中的排序方法,默认是升序,
df = df.sort_values(by="Count_AnimalName",ascending=False)
print(df)5.DateFrame切片与索引
pandas之loc
- 还有更多的经过pandas优化过的选择方式:
- df.loc 通过标签索引行数据
- df.iloc 通过位置获取行数据
import pandas as pd
import numpy as np
t1 = pd.DataFrame(np.arange(12).reshape(3,4),index=list("abc"),columns=list("wxyz"))
t1
w x y z
a 0 1 2 3
b 4 5 6 7
c 8 9 10 11
t1.loc["a","z"]
np.int64(3)
type(t1.loc["a","z"])
numpy.int64
t1.loc["a"]
w 0
x 1
y 2
z 3
Name: a, dtype: int64
t1.loc[:,"y"]
a 2
b 6
c 10
Name: y, dtype: int64
# 选择多行
t1.loc[["a","c"]]
w x y z
a 0 1 2 3
c 8 9 10 11
# 选择多行
t1.loc[["a","c"],:]
w x y z
a 0 1 2 3
c 8 9 10 11
# 选择多列
t1.loc[:,["x","w"]]
x w
a 1 0
b 5 4
c 9 8
# 选择多行多列
t1.loc[["a","c"],["x","z"]]
x z
a 1 3
c 9 11
# iloc方法,取某一行
t1.iloc[1]
w 4
x 5
y 6
z 7
Name: b, dtype: int64
# iloc方法,取某一列
t1.iloc[:,1]
a 1
b 5
c 9
Name: x, dtype: int64
# 取不连续的多列
t1.iloc[:,[2,1]]
y x
a 2 1
b 6 5
c 10 96.布尔索引
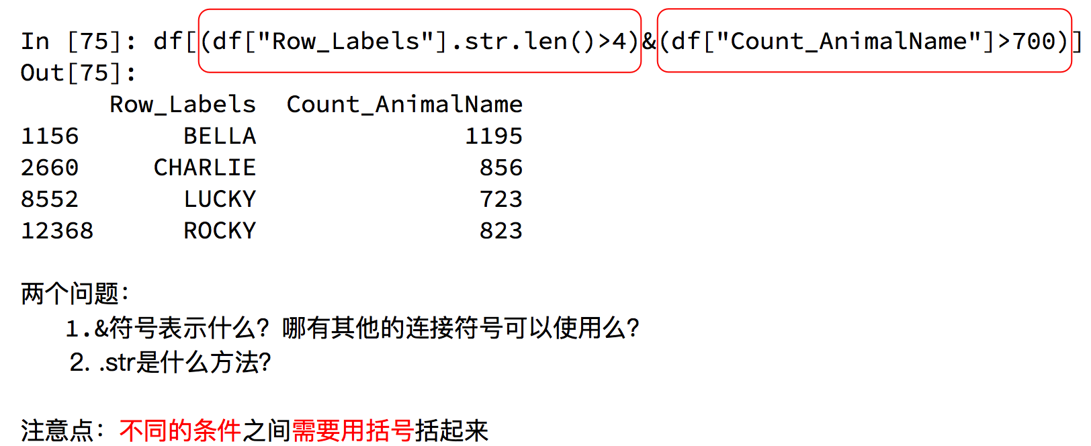
pandas之字符串方法

7.缺失数据的处理
对于NaN的数据,在numpy中我们是如何处理的?
在pandas中我们处理起来非常容易
判断数据是否为NaN:pd.isnull(df),pd.notnull(df)
处理方式1:删除NaN所在的行列dropna (axis=0, how=‘any’, inplace=False)
处理方式2:填充数据,t.fillna(t.mean()),t.fiallna(t.median()),t.fillna(0)
处理为0的数据:t[t==0]=np.nan
当然并不是每次为0的数据都需要处理
计算平均值等情况,nan是不参与计算的,但是0会
8.常用的统计方法
假设现在我们有一组从2006年到2016年1000部最流行的电影数据,我们想知道这些电影数据中评分的平均分,导演的人数等信息,我们应该怎么获取?
数据来源:https://www.kaggle.com/damianpanek/sunday-eda/data
import numpy as np
import pandas as pdfile_path = "IMDB-Movie-Data.csv"df = pd.read_csv(file_path)
pd.set_option('display.max_columns',None)
# print(df.info())
print(df.head(1))# 获取平均评分
mean_score = df["Rating"].mean()
print(mean_score)# 导演的人数
director_list = df["Director"].tolist()
# print(director_list)
print(len(director_list)) #1000
director_list_set = set(df["Director"].tolist()) #去重
print(len(director_list_set)) #644
# 最终导演的人数
director_num = len(set(df["Director"].tolist()))print("="*100)# 获取演员的人数
temp_actors_list = df["Actors"].str.split(", ").tolist()
# [['Chris Pratt', 'Vin Diesel', 'Bradley Cooper', 'Zoe Saldana'],
# ['Noomi Rapace', 'Logan Marshall-Green', 'Michael Fassbender', 'Charlize Theron'], ........
# print(temp_actors_list)
actors_list = [i for j in temp_actors_list for i in j]
actors_num = len(set(actors_list))
print(actors_num) #2015
# temp_actors_list2 = df["Actors"].str.split(", ")
# actors_list2 = list(np.array(temp_actors_list2).flatten())
# print(len(set(actors_list2)))
对于这一组电影数据,如果我们想rating,runtime的分布情况,应该如何呈现数据?
import numpy as np
import pandas as pd
from matplotlib import pyplot as pltfile_path = "IMDB-Movie-Data.csv"df = pd.read_csv(file_path)
pd.set_option('display.max_columns',None)
print(df.info())
# print(df.head(1))# 对于这一组电影数据,如果我们想rating,runtime的分布情况,应该如何呈现数据?
# 分析rating,runtime之间的数据关系
# 选择图形,直方图
# 准备数据
runtime_data = df["Runtime (Minutes)"].values
rating_data = df["Rating"].values
# print(runtime_data)
max_runtime = df["Runtime (Minutes)"].max()
min_runtime = df["Runtime (Minutes)"].min()
# print(max_runtime) #191
# print(min_runtime) #66# 计算组数
bin_nums = (max_runtime - min_runtime) // 5# 绘图
# 设置图片的大小
plt.figure(figsize=(16,8),dpi=80)
plt.hist(runtime_data,bin_nums)# 设置x轴
plt.xticks(range(min_runtime,max_runtime+5,5))plt.show()对于这一组电影数据,如果我们希望统计电影分类(genre)的情况,应该如何处理数据?
思路:重新构造一个全为0的数组,列名为分类,如果某一条数据中分类出现过,就让0变为1
构造全为0的二维数组:
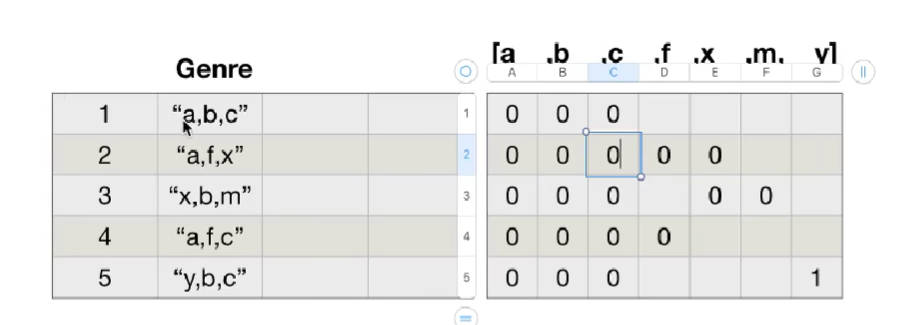
再将对应有类别的数据对数值更改值为1:
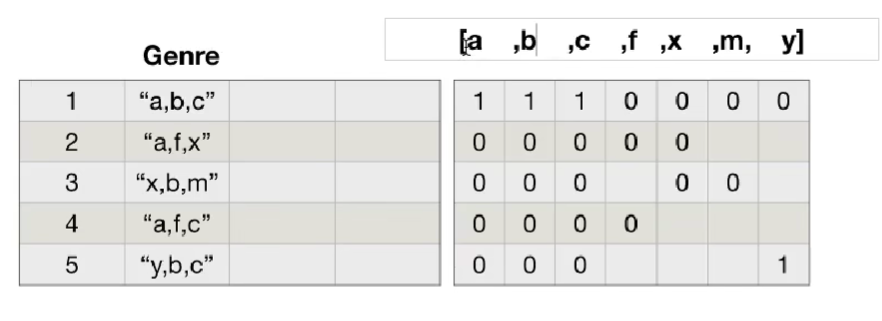
import numpy as np
import pandas as pd
from matplotlib import pyplot as pltfile_path = "IMDB-Movie-Data.csv"df = pd.read_csv(file_path)
pd.set_option('display.max_columns',None)
# print(df.info())
# print(df.head(1))
# print(df["Genre"])# 统计分类的列表
temp_list = df["Genre"].str.split(",").tolist() # [[],[],[].....]
# print(temp_list)
temp_set = set([i for j in temp_list for i in j])
# {'Thriller', 'Sport', 'Western', 'Family', 'Comedy', 'Biography', 'Mystery', 'Adventure', 'Music', 'Crime', 'Romance',
# 'History', 'Fantasy', 'Musical', 'Drama', 'Horror', 'Action', 'Sci-Fi', 'Animation', 'War'}
# print(temp_set)
genre_list = list(temp_set)
# ['Comedy', 'Drama', 'Biography', 'History', 'Thriller', 'War', 'Western', 'Music', 'Horror', 'Mystery', 'Crime', 'Sport',
# 'Fantasy', 'Romance', 'Animation', 'Musical', 'Adventure', 'Action', 'Sci-Fi', 'Family']
# print(genre_list)# 构造全为0的数组
# 1.确定行数
row_num = df.shape[0] #1000
# 2.确定列数
column_num = len(genre_list) #20
# 3.构造数组[1000,20]
zeros_df = pd.DataFrame(np.zeros((row_num,column_num)),columns=genre_list)
# print(zeros_df)# 给每个电影出现分类的时候赋值为1
for i in range(df.shape[0]):# zeros_df.loc[0,['Action', 'Adventure', 'Sci-Fi']] = 1zeros_df.loc[i,temp_list[i]] = 1# print(zeros_df)
# 统计每个分类的电影的数量和
genre_count = zeros_df.sum(axis=0)
# print(genre_count)# 排序
genre_count = genre_count.sort_values()
_x = genre_count.index
_y = genre_count.values# 画图
plt.figure(figsize=(16,8),dpi=80)
plt.bar(range(len(_x)),_y,width=0.4)
plt.xticks(range(len(_x)),_x)
plt.show()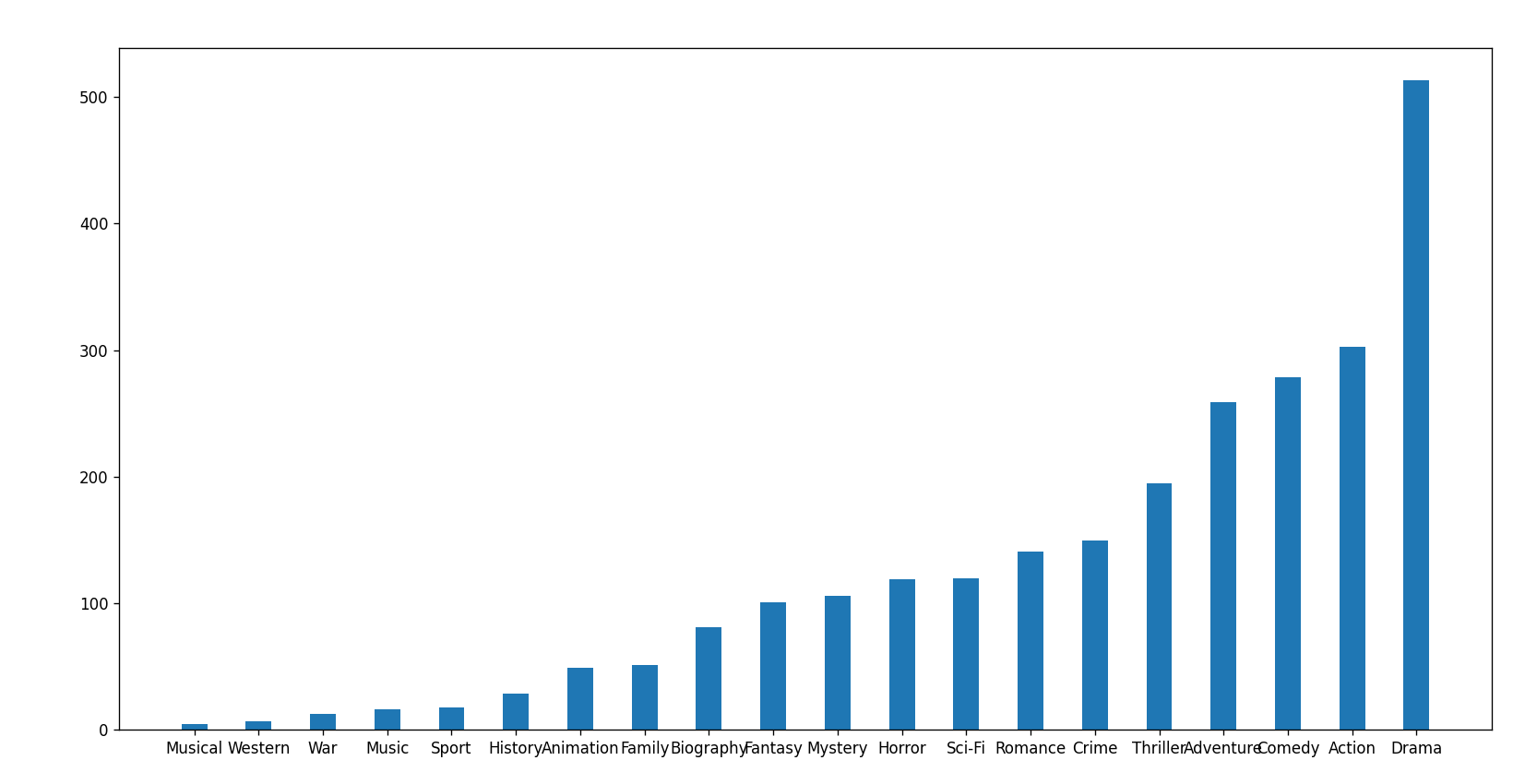
9.数据合并
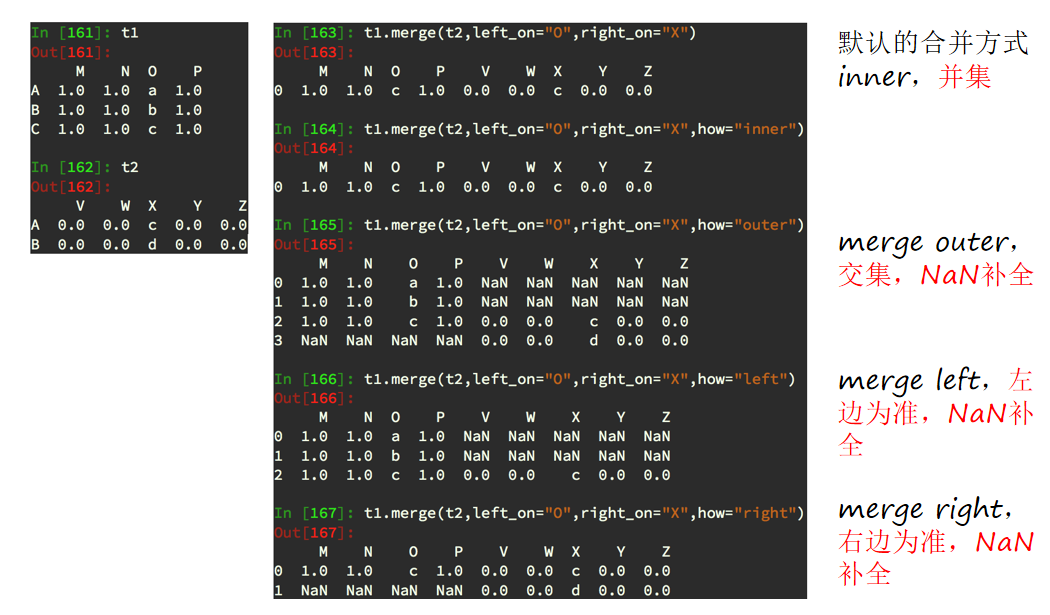
join:默认情况下把行索引相同的数据合并到一起

merge:按照指定的列把数据按照一定的方式合并到一起。
10.分组和聚合
在pandas中类似的分组的操作我们有很简单的方式来完成:
df.groupby(by=“columns_name”)
那么问题来了,调用groupby方法之后返回的是什么内容?
grouped = df.groupby(by=“columns_name”)
grouped是一个DataFrameGroupBy对象,是可迭代的
grouped中的每一个元素是一个元组
元组里面是(索引(分组的值),分组之后的DataFrame)
DataFrameGroupBy对象有很多经过优化的方法:

如果我们需要对国家和省份进行分组统计,应该怎么操作呢?
grouped = df.groupby(by=[df[“Country”],df[“State/Province”]])
很多时候我们只希望对获取分组之后的某一部分数据,或者说我们只希望对某几列数据进行分组,这个时候我们应该怎么办呢?
获取分组之后的某一部分数据:
df.groupby(by=[“Country”,“State/Province”])[“Country”].count()
对某几列数据进行分组:
df[“Country”].groupby(by=[df[“Country”],df[“State/Province”]]).count()
观察结果,由于只选择了一列数据,所以结果是一个Series类型
如果我想返回一个DataFrame类型呢?
t1 = df[[“Country”]].groupby(by=[df[“Country”],df[“State/Province”]]).count()t2 = df.groupby(by=[“Country”,“State/Province”])[[“Country”]].count()
以上的两条命令结果一样
和之前的结果的区别在于当前返回的是一个DataFrame类型
现在我们有一组关于全球星巴克店铺的统计数据,如果我想知道美国的星巴克数量和中国的哪个多,或者我想知道中国每个省份星巴克的数量的情况,那么应该怎么办?
思路:遍历一遍,每次加1 ???
数据来源:https://www.kaggle.com/starbucks/store-locations/data
import pandas as pd
import numpy as npfile_path = "./starbucks_store_worldwide.csv"
df = pd.read_csv(file_path)
# 显示全部信息
pd.set_option('display.max_columns',None)
# print(df.head(50))
# print(df.info())grouped = df.groupby(by="Country")
print(grouped)
# DataFrameGroupBy
# 可以进行遍历
# for i,j in grouped:
# print(i)
# print("-"*100)
# print(j,type(j))
# print("="*100)
# df[df["Country"]=="UK"]# 可以进行聚合方法
# print(grouped.count())
# country_count = grouped["Brand"].count()
# # 统计出美国的数量
# print(country_count["US"])
# # 统计出中国的数量
# print(country_count["CN"])# 统计中国每个省份星巴克的数量的情况
# china_data = df[df["Country"] == "CN"]
# grouped = china_data.groupby(by="State/Province").count()["Brand"]
# print(grouped)# 数据按照多个条件进行分组,返回Series
grouped = df["Brand"].groupby(by=[df["Country"],df["State/Province"]]).count()
print(grouped)
print(type(grouped)) #<class 'pandas.core.series.Series'> 带有两个索引的Series类型# # 数据按照多个条件进行分组,返回DateFrame
grouped1 = df[["Brand"]].groupby(by=[df["Country"],df["State/Province"]]).count()
grouped2 = df.groupby(by=[df["Country"],df["State/Province"]])[["Brand"]].count()
grouped3 = df.groupby(by=[df["Country"],df["State/Province"]]).count()[["Brand"]]
print(type(grouped1))
print(type(grouped2))
print(type(grouped3)) #<class 'pandas.core.frame.DataFrame'>索引和复合索引:
简单的索引操作:
获取index:df.index
指定index :df.index = [‘x’,‘y’]
重新设置index : df.reindex(list(“abcedf”))
指定某一列作为index :df.set_index(“Country”,drop=False)
返回index的唯一值:df.set_index(“Country”).index.unique()
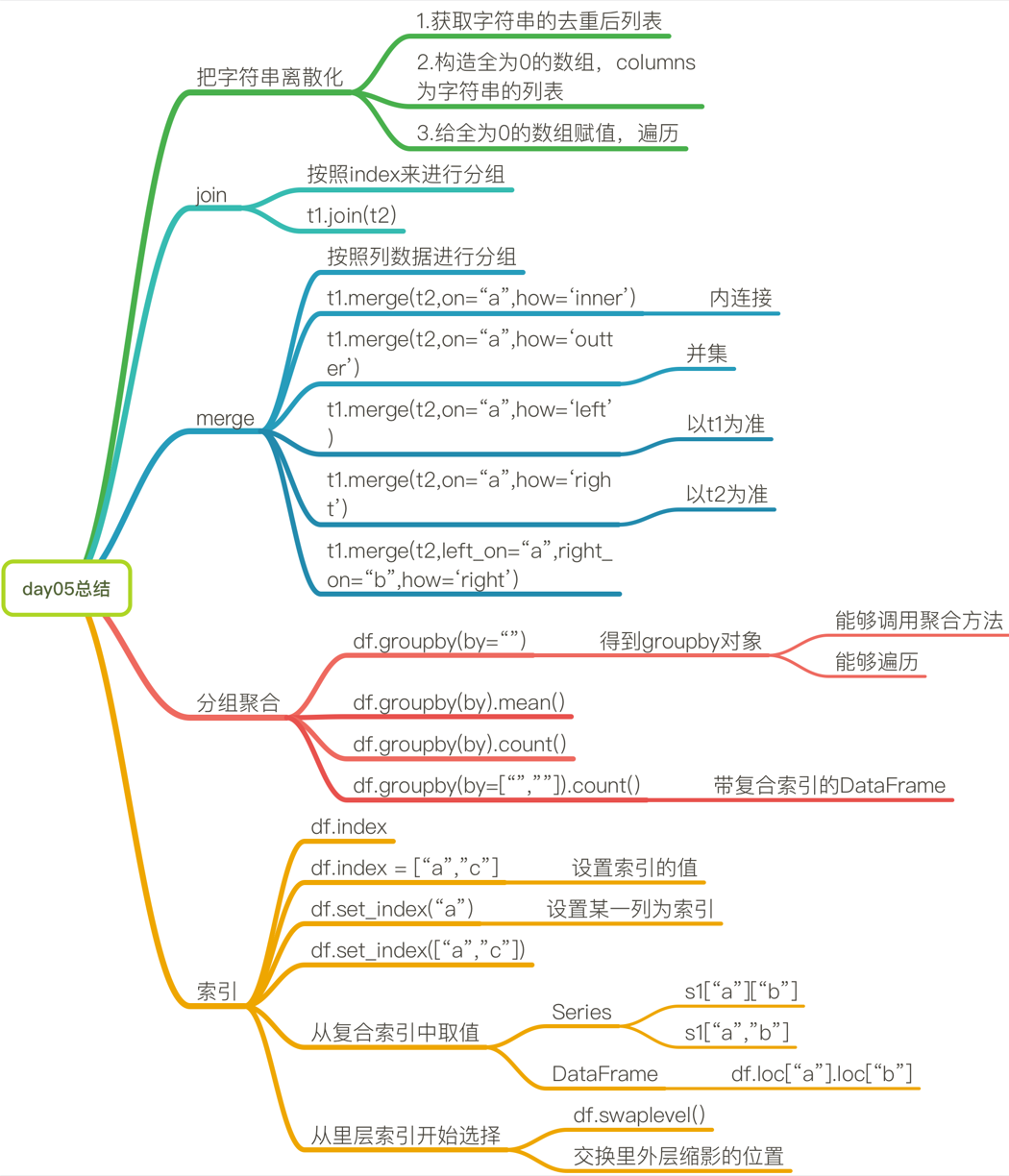
假设a为一个DataFrame,那么当a.set_index([“c”,“d”])即设置两个索引的时候是什么样子的结果呢?
a = pd.DataFrame({‘a’: range(7),‘b’: range(7, 0, -1),‘c’: [‘one’,‘one’,‘one’,‘two’,‘two’,‘two’, ‘two’],‘d’: list(“hjklmno”)})
11.pandas中的时间序列
现在我们有2015到2020年66万条911的紧急电话的数据,请统计出出这些数据中不同类型的紧急情况的次数,如果我们还想统计出不同月份不同类型紧急电话的次数的变化情况,应该怎么做呢?
数据来源:https://www.kaggle.com/mchirico/montcoalert/data
import pandas as pd
import numpy as npfile_path = "./911.csv"
df = pd.read_csv(file_path)
# 显示全部信息
pd.set_option('display.max_columns',None)
# print(df.head(10))
# print(df.info())# 获取分类
# print(df["title"].str.split(": ")[0][0])
temp_list = df["title"].str.split(": ").tolist()
cate_list = list(set([i[0] for i in temp_list]))
# ['Fire', 'Traffic', 'EMS']
# print(cate_list)# 构造全为0的数组
zeros_df = pd.DataFrame(np.zeros((df.shape[0],len(cate_list))),columns=cate_list)
# 赋值
for cate in cate_list:# print(df["title"].str.contains(cate))zeros_df[cate][df["title"].str.contains(cate)] = 1# break# print(zeros_df)# 运行速度很慢
# for i in range(df.shape[0]):
# zeros_df.loc[i,temp_list[i][0]] = 1
#
# print(zeros_df)sum_ret = zeros_df.sum(axis=0)
print(sum_ret)下面代码可以实现上述代码相同的功能
import pandas as pd
import numpy as npfile_path = "./911.csv"
df = pd.read_csv(file_path)
# 显示全部信息
pd.set_option('display.max_columns',None)
# print(df.head(10))
# print(df.info())# 获取分类
# print(df["title"].str.split(": ")[0][0])
temp_list = df["title"].str.split(": ").tolist()
cate_list = [i[0] for i in temp_list]
# print(cate_list)
temp_cate = pd.DataFrame(np.array(cate_list).reshape((df.shape[0],1)))
# print(temp_cate)
# 在原始数据的最后增加cate这一列
df["cate"] = temp_cate
# print(df.head(10))
# 以最后的cate列进行分组,并将title列的数据取出
print(df.groupby(by="cate").count()["title"])为什么要学习pandas中的时间序列?
不管在什么行业,时间序列都是一种非常重要的数据形式,很多统计数据以及数据的规律也都和时间序列有着非常重要的联系。而且在pandas中处理时间序列是非常简单的。
生成一段时间范围:
pd.date_range(start=None, end=None, periods=None, freq=‘D’)
start和end以及freq配合能够生成start和end范围内以频率freq的一组时间索引
start和periods以及freq配合能够生成从start开始的频率为freq的periods个时间索引
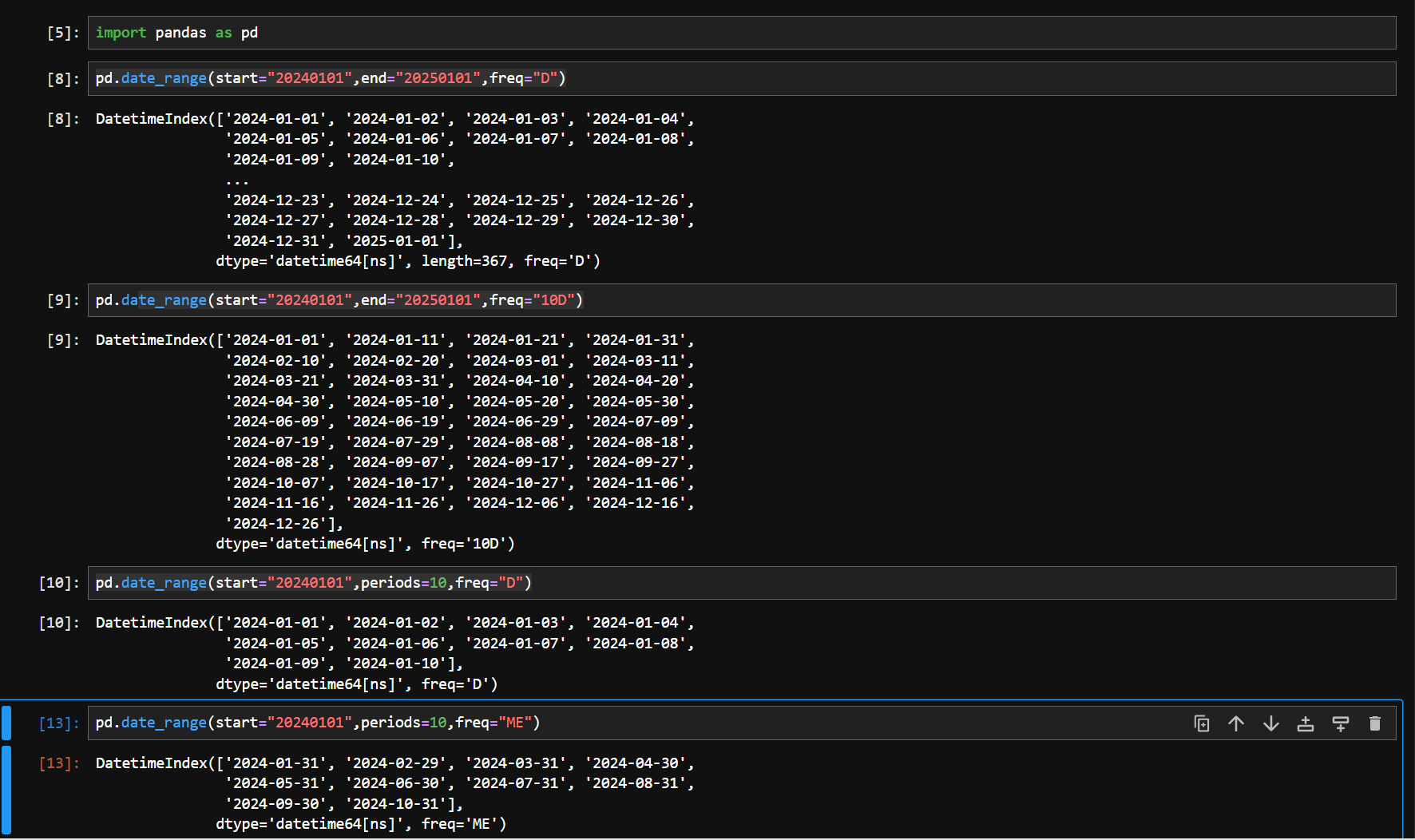

python中如何实现格式化时间 – PingCode
在DataFrame中使用时间序列:
index=pd.date_range(“20170101”,periods=10)
df = pd.DataFrame(np.random.rand(10),index=index)
回到最开始的911数据的案例中,我们可以使用pandas提供的方法把时间字符串转化为时间序列
df[“timeStamp”] = pd.to_datetime(df[“timeStamp”],format=“”)
format参数大部分情况下可以不用写,但是对于pandas无法格式化的时间字符串,我们可以使用该参数,比如包含中文。
pandas重采样:
重采样:指的是将时间序列从一个频率转化为另一个频率进行处理的过程,将高频率数据转化为低频率数据为降采样,低频率转化为高频率为升采样。
pandas提供了一个resample的方法来帮助我们实现频率转化
动手实验:
- 统计出911数据中不同月份电话次数的变化情况
- 统计出911数据中不同月份不同类型的电话的次数的变化情况
import timeimport pandas as pd
import numpy as np
from matplotlib import pyplot as pltfile_path = "./911.csv"
df = pd.read_csv(file_path)
# 显示全部信息
pd.set_option('display.max_columns',None)df["timeStamp"] = pd.to_datetime(df["timeStamp"])
# 将索引值设置为timeStamp
df.set_index("timeStamp",inplace=True)# print(df.head(10))# 统计出911数据中不同月份电话次数
count_by_month = df.resample("ME").count()
# print(count_by_month)# 画图
_x = count_by_month.index
_y = count_by_month.values# 时间格式化
_x = [i.strftime("%Y.%m.%d") for i in _x]plt.figure(figsize=(16,8),dpi=80)plt.plot(range(len(_x)),_y)
plt.xticks(range(len(_x)),_x,rotation=45)plt.show()# 统计出911数据中不同月份不同类型的电话的次数的变化情况
import pandas as pd
import numpy as np
from matplotlib import pyplot as pltfile_path = "./911.csv"
df = pd.read_csv(file_path)
# 显示全部信息
pd.set_option('display.max_columns',None)# 把时间字符串转换为时间类型并设置为索引
df["timeStamp"] = pd.to_datetime(df["timeStamp"])# 设置添加列,表示分类
temp_list = df["title"].str.split(": ").tolist()
cate_list = [i[0] for i in temp_list]
temp_cate = pd.DataFrame(np.array(cate_list).reshape((df.shape[0],1)))
# 在原始数据的最后增加cate这一列
df["cate"] = temp_cate# 注意索引的位置
# 将索引值设置为timeStamp
df.set_index("timeStamp",inplace=True)plt.figure(figsize=(16, 8), dpi=80)# 分组
for group_name,group_data in df.groupby(by="cate"):# 对不同的分类进行绘图count_by_month = group_data.resample("ME").count()["title"]# 画图_x = count_by_month.index_y = count_by_month.values# 时间格式化_x = [i.strftime("%Y.%m.%d") for i in _x]plt.plot(range(len(_x)), _y,label=group_name)plt.xticks(range(len(_x)), _x, rotation=45)
plt.legend(loc="best")
plt.show()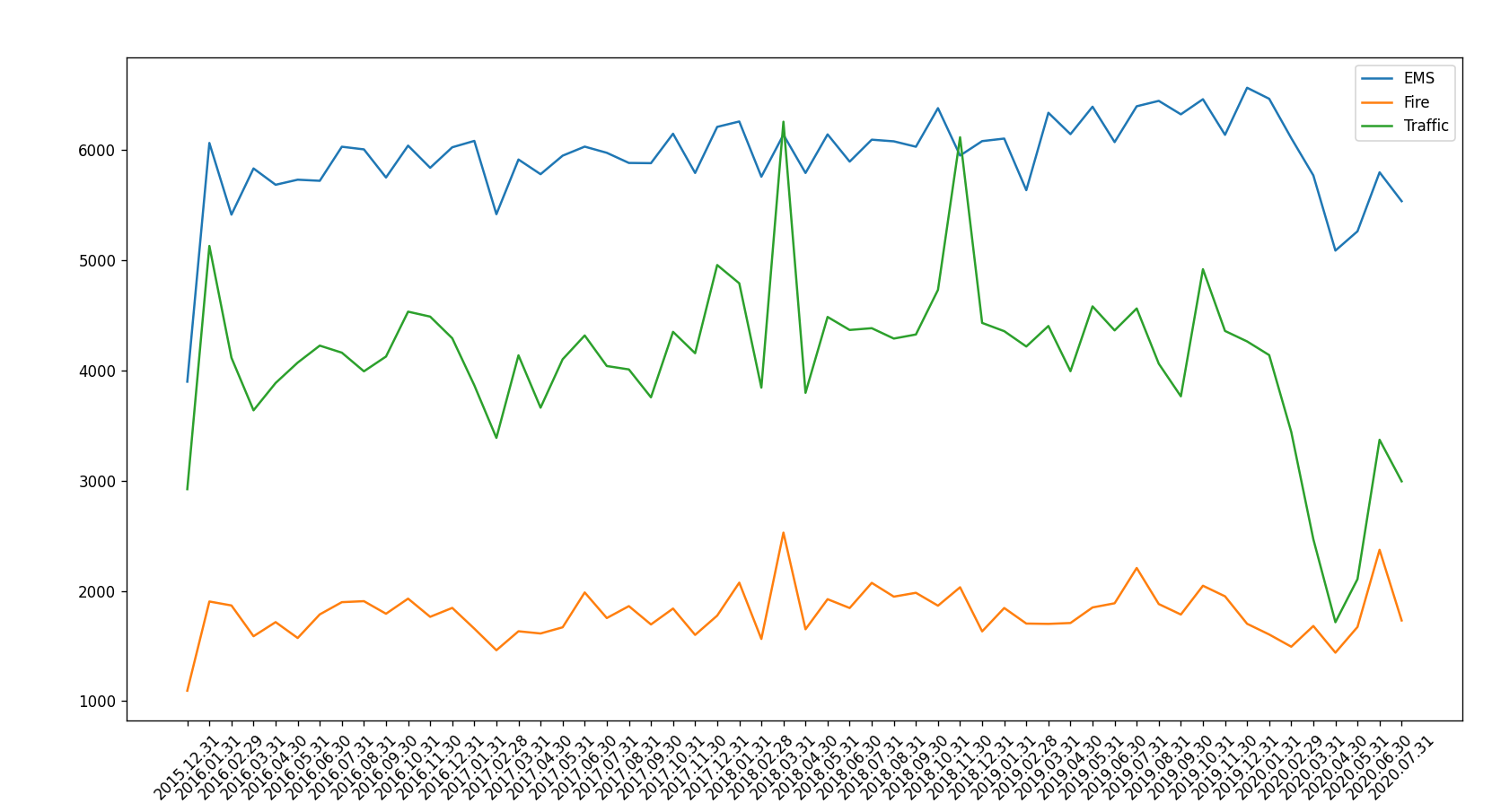
课程链接:
【python教程】数据分析——numpy、pandas、matplotlib_哔哩哔哩_bilibili