音频驱动视频生成新突破:Wan2.2-S2V 模型全面体验与教程
一、模型介绍
Wan2.2-S2V 是一款基于先进人工智能技术的音频驱动视频生成模型,它通过创新的算法架构实现了静态图像与音频输入的深度融合与动态合成。该模型能够将单一的静态人像图片与任意音频文件(如对话、歌唱或旁白)相结合,自动生成口型精准同步、表情生动自然且具备电影级画质的动态视频内容,极大降低了高质量动态视频内容的制作门槛。
核心功能亮点
-
高精度音画同步:依托先进的语音识别与动态渲染技术,实现音频与人物口型的毫米级同步,输出效果自然流畅;
-
极致画面品质:生成视频具有高清乃至电影级的视觉表现,细节丰富,光影自然,支持多种人像模式(半身/全身);
-
长视频生成能力:突破生成长度限制,可生成分钟级别的连续视频,满足短视频、教学视频、虚拟偶像内容等创作需求;
-
动作与环境控制:结合文本指令可对生成角色动作、背景环境进行控制,提供更强的内容可控性和创意自由度。
典型应用场景
-
虚拟形象内容创作:为虚拟主播、数字人提供高效内容生成能力;
-
多媒体教学与培训:快速制作口型精准的讲解视频,支持多语种;
-
艺术表演与娱乐短片:生成歌唱、对话、剧情表演类视频,扩展创意表达形式;
-
广告与营销视频制作:大幅提升商品介绍、品牌宣传视频的制作效率。
该模型适合内容创作者、影视制作团队、教育工作者及技术开发者使用,无需专业后期技能,也可快速产出高质量视频作品。
星海智算平台已经为大家部署好这个镜像,开箱即用,下面为大家介绍一下,如何在星海智算平台上使用。星海智算平台![]() https://spacehpc.com/user/register?inviteCode=57833422
https://spacehpc.com/user/register?inviteCode=57833422
具体操作:
1.从官网进入平台
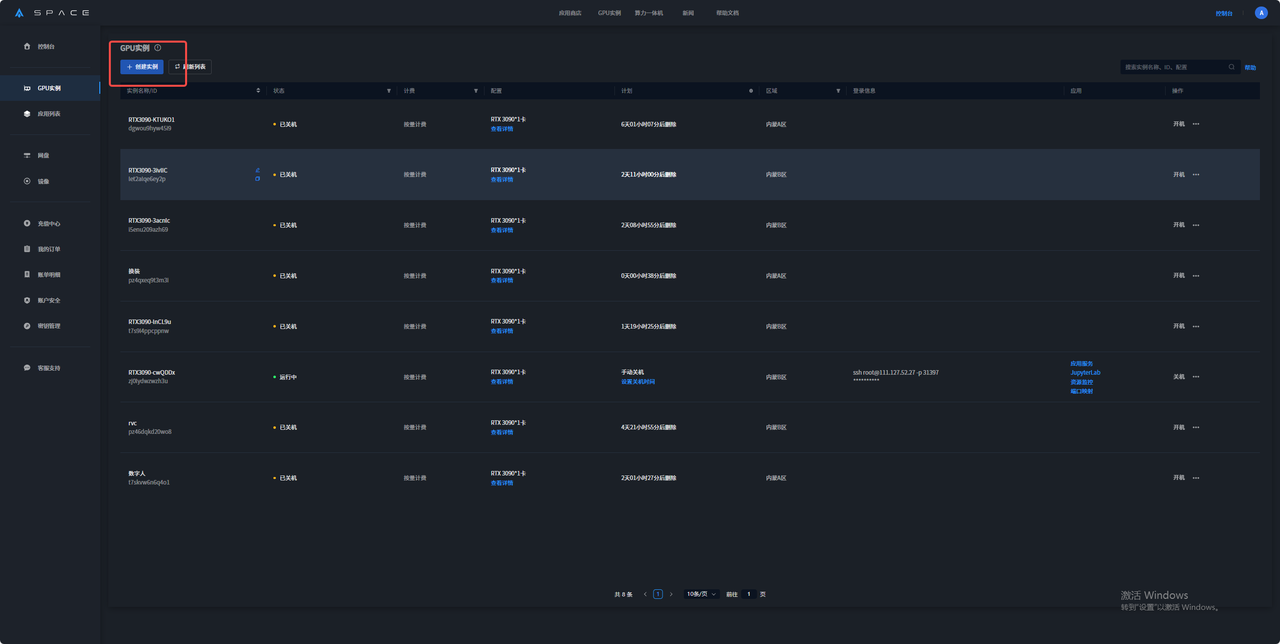
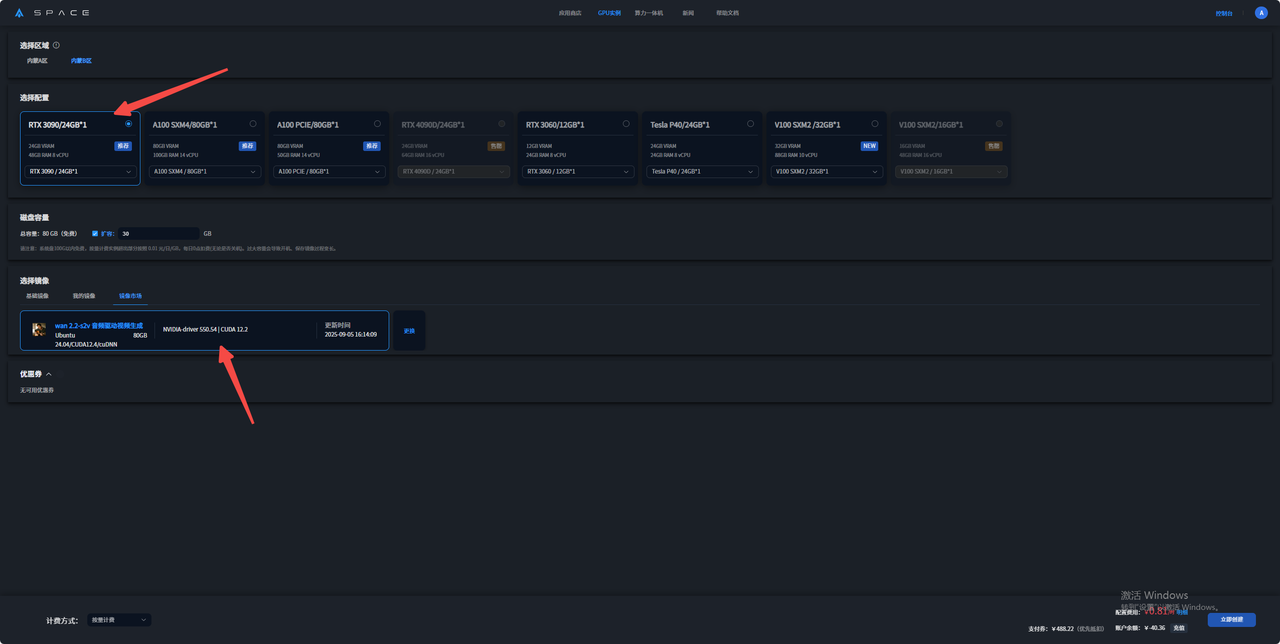
2. 在GPU实例界面中选择创建实例
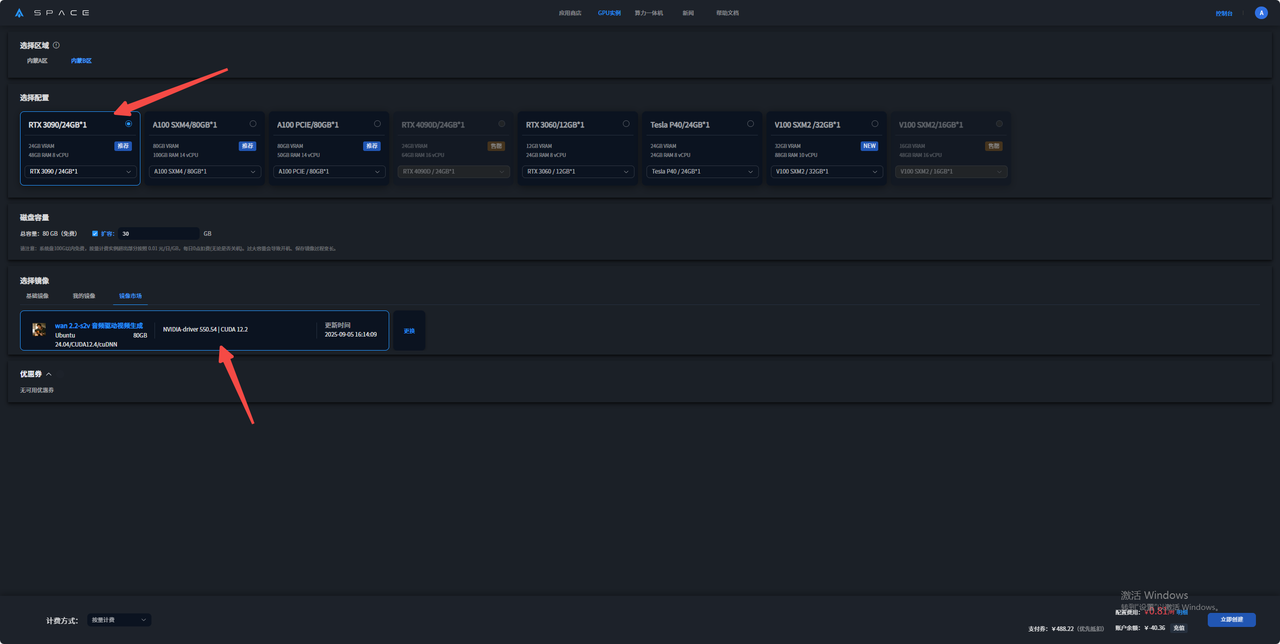
3.选择好所在区域、所需配置、计费方式后在镜像市场搜索wan2.2-s2v 音频驱动视频生成 镜像
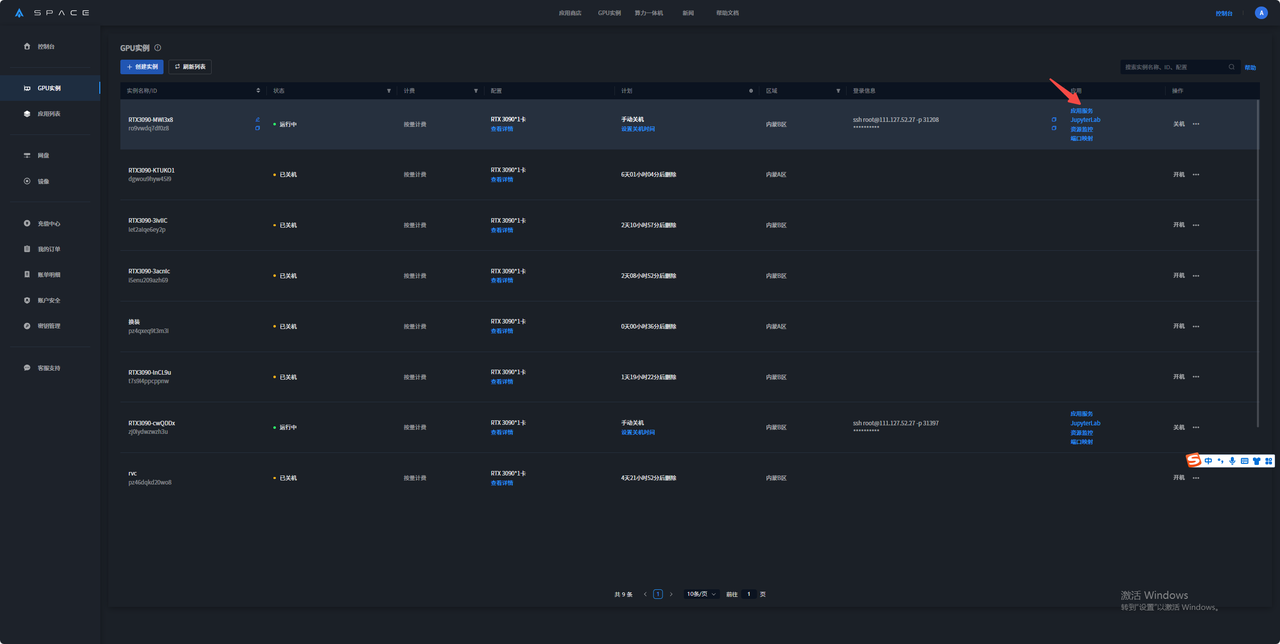
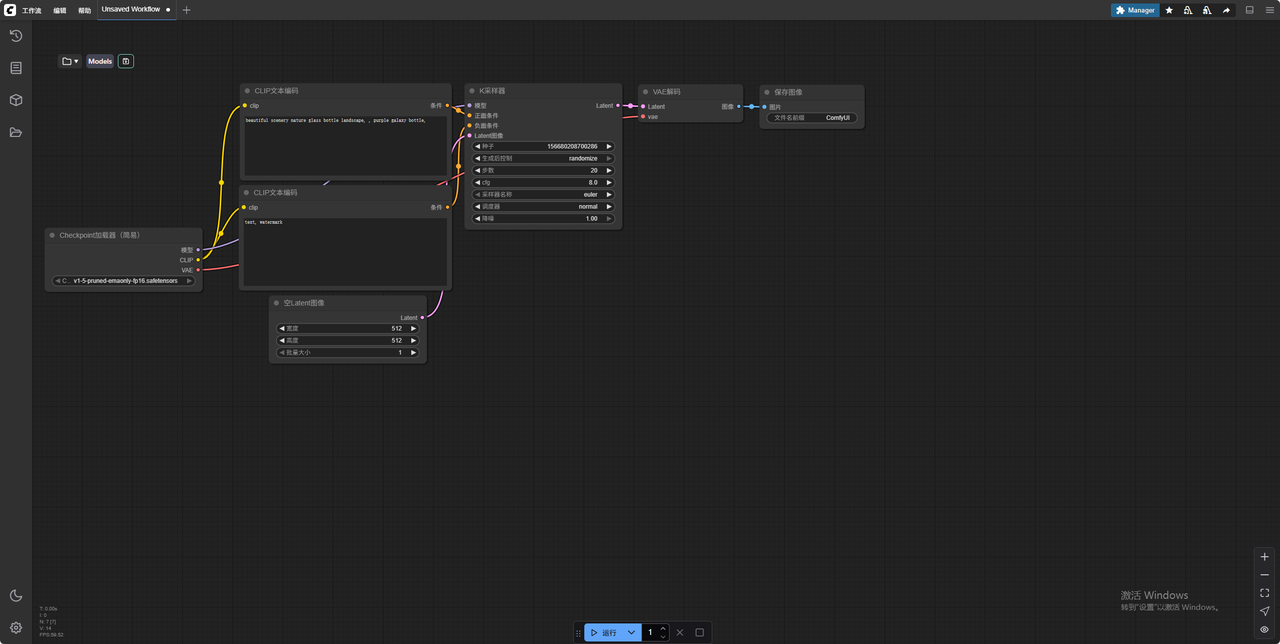
4.开机后等模型加载几分钟 点击应用服务
打开界面如下:
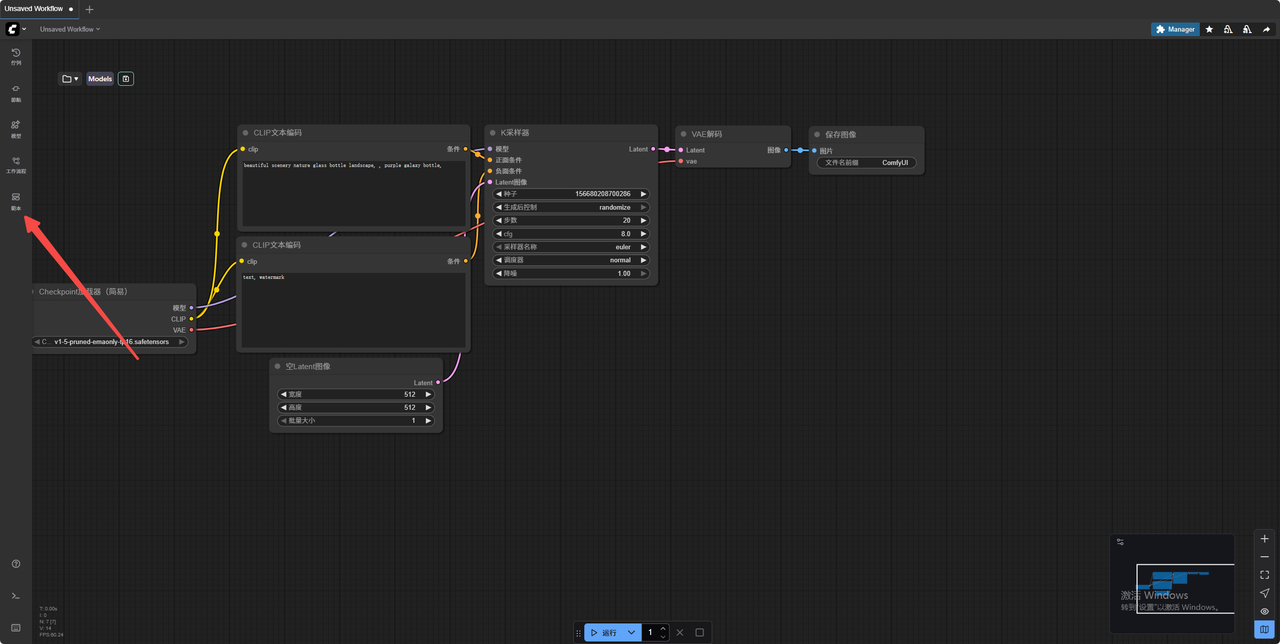
5.点击模板图标
6.选择工作流
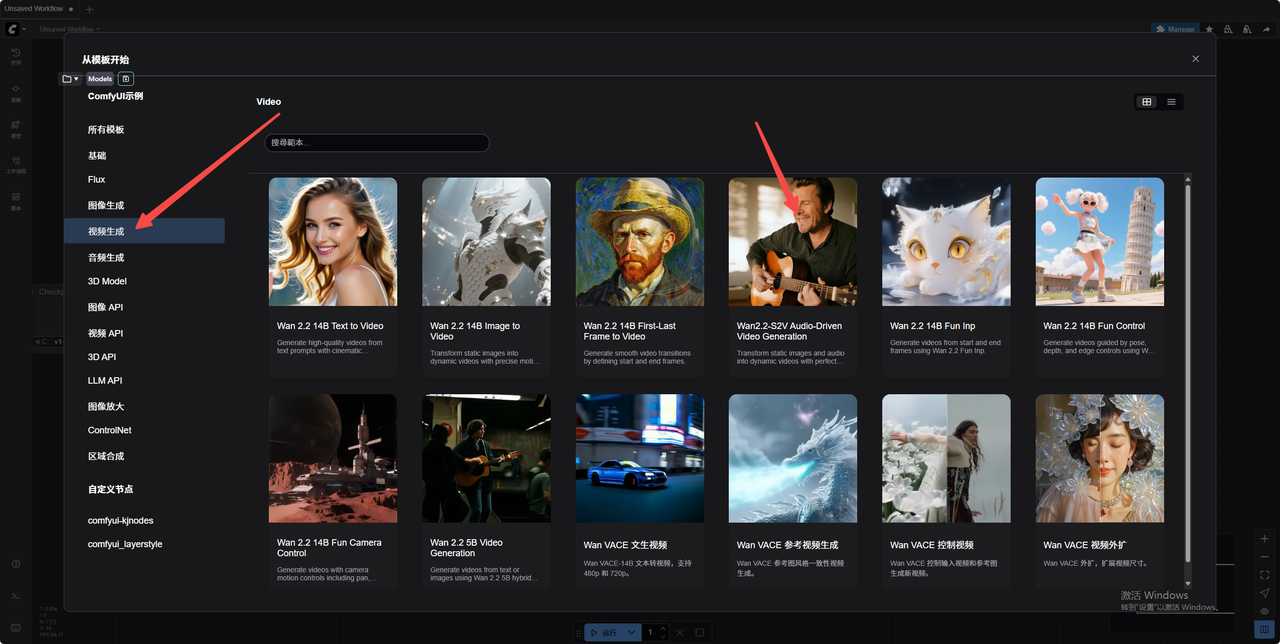
打开界面如下
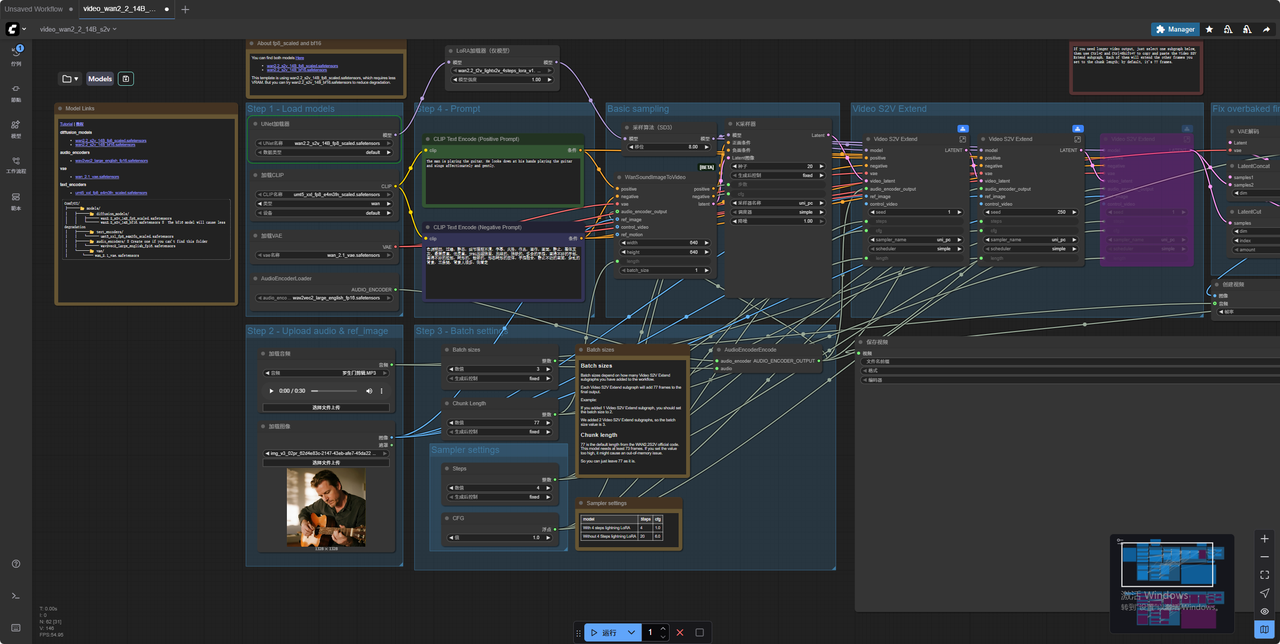
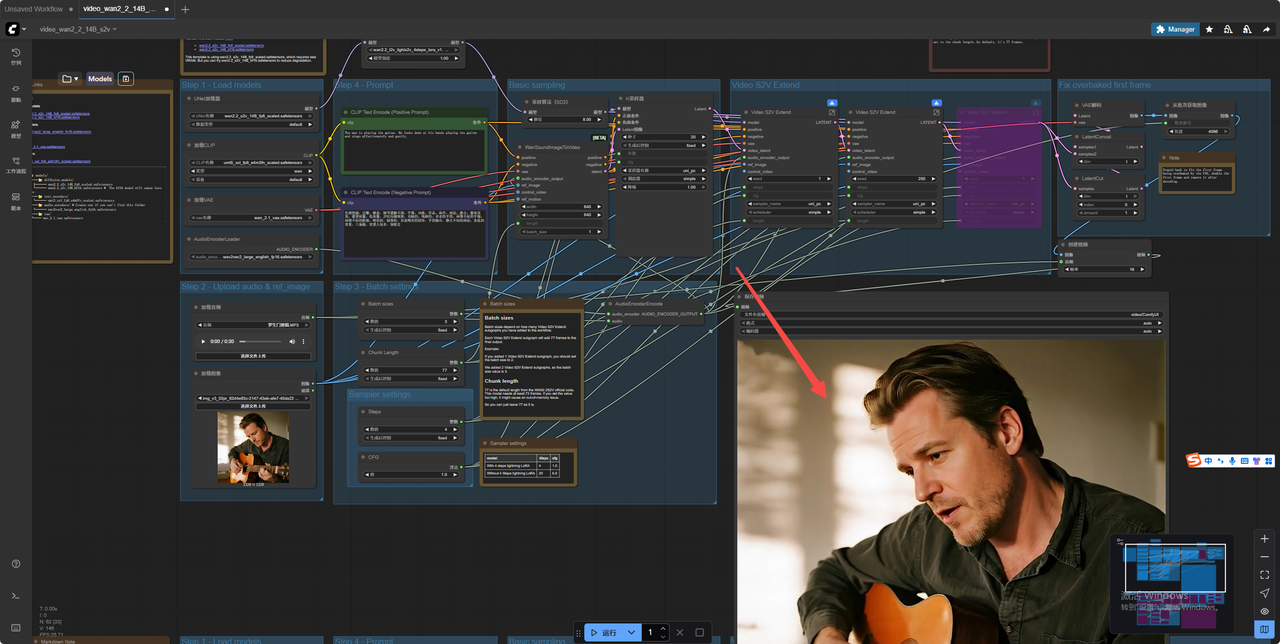
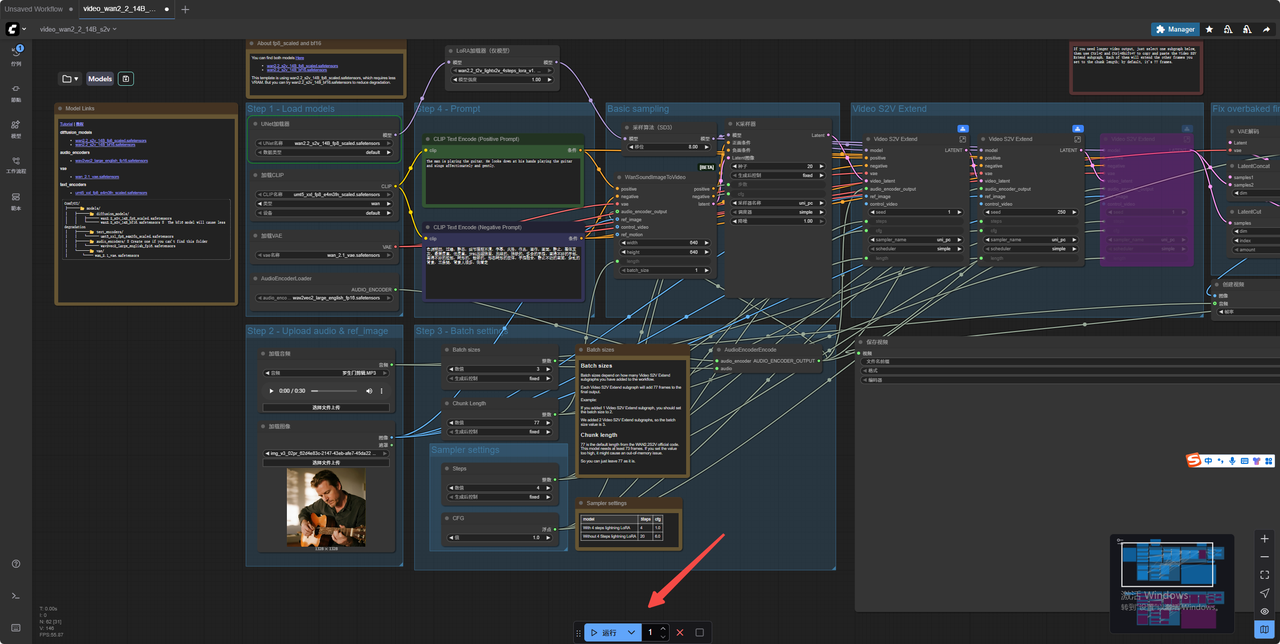
7.输入提示词 点击运行 (上传的音频不要太长)
8.生成结果 (图生视频对显卡配置要求较高,请选用3090及以上显卡)