centos7上使用Docker+ RagFlow + ollama + 数据集 搭建自己的AI问答机器人(2025-09)
什么是RAG
RAG(Retrieval-Augmented Generation,检索增强生成)是一种结合信息检索与文本生成的智能技术,旨在解决传统大语言模型(LLM)的局限性。以下是通俗易懂的解释:
核心原理
-
检索(Retrieval)
当用户提问时,系统先从外部知识库(如文档、数据库、企业私有数据)中快速查找与问题最相关的片段。例如,问“公司2023年营收多少”,系统会从财报文档中检索出具体数字。 -
增强生成(Augmented Generation)
将检索到的真实数据与用户问题一起输入大语言模型,模型基于这些可信信息生成回答,而非仅依赖训练时的静态知识。这样能避免“幻觉”(编造信息),确保答案准确且有据可依。
RAG 的基本流程
-
用户提问(Query)
比如:“介绍一下中国的新能源政策”。 -
检索阶段(Retrieval)
系统会把问题转成 embedding 向量,然后去知识库(向量数据库或全文搜索引擎)检索最相关的文档片段(chunks)。 -
增强输入(Augmentation)
把检索到的文档片段附加到用户问题后面,构造成一个 提示(prompt)。用户问题 + [相关文档内容] -
生成阶段(Generation)
把增强后的 prompt 输入到大语言模型中,模型基于问题和文档上下文生成回答。 -
答案输出(Answer)
最终给出一个带有依据的答案,甚至能附带引用出处。
RAG 的优点
- 避免幻觉:模型有外部知识支撑,减少“编造”。
- 知识可更新:知识库可随时更新,不需要重新训练模型。
- 更可信:能给出来源引用,方便验证。
- 降低成本:不必训练超大模型,只需调用中等规模 LLM + 知识库即可。
为什么需要RAG?
- 知识更新问题:传统LLM的训练数据有截止日期(如2023年),无法回答最新事件(如2024年政策)。
- 私有数据访问:企业内部文档、专有数据无法直接用于训练模型,RAG可实时检索这些数据。
- 减少错误:模型不再“凭空想象”,而是基于检索到的证据生成回答,可靠性大幅提升。
典型应用场景
- 企业知识库:员工提问“如何申请报销”,系统自动检索公司制度文档并生成步骤说明。
- 客服系统:用户问“订单物流状态”,RAG从订单数据库中提取实时信息并回复。
- 医疗咨询:医生询问“某种药物的禁忌症”,系统从医学文献中检索权威结论,避免错误建议。
与传统LLM的区别
| 传统LLM | RAG |
|---|---|
| 仅依赖训练数据,知识可能过时 | 实时检索最新或私有数据 |
| 回答可能“脑补”错误信息 | 严格基于检索到的证据生成 |
| 无法访问企业内部文档 | 可对接企业专属知识库 |
简单比喻
想象一个“学霸+图书馆员”的组合:
- 图书馆员(检索模块):快速找到相关书籍中的具体段落;
- 学霸(生成模块):根据这些段落整理出清晰、准确的答案。
两者结合,既保证答案有依据,又能灵活应对新问题。
可以把 RAG 理解为:
👉 模型本身 = 一个“懂语言的专家”,但记忆有限,有时候会胡编。
👉 检索系统 = 一个“图书管理员”,能找到相关资料。
👉 RAG = 专家在回答前,先让图书管理员找资料,再结合自己的语言能力回答。
RAG的核心价值在于让AI真正“懂”你的数据,而非仅依赖通用知识。像RAGFlow这样的工具,正是将RAG技术落地为易用的系统,帮助企业快速构建智能问答服务。
RAGFlow介绍
… 来源ChatGPT
什么是 RAGFlow
- RAGFlow 是一个开源的 Retrieval-Augmented Generation(检索增强生成,RAG)引擎,由 Infiniflow 团队开发。它特别强调「深度文档理解」(deep document understanding)。([GitHub][1])
- 目的是把复杂、格式多样的数据(PDF、Word、表格、扫描件、ppt、图片等)处理好,构建知识库,使得当用户查询时,能够检索相关内容,并由大语言模型(LLM)基于这些检索到的内容生成答案,并带有可信的引用出处。([ragflow.io][2])
- 它也支持 Agent 模型/工作流,意味着可以把检索+生成结合一些自动化任务、推理、脚本执行等能力。([GitHub][1])
关键功能/特点
下面是 RAGFlow 的主要特性:
| 功能 | 描述 |
|---|---|
| 深文档理解 (Deep Document Understanding) | 能够处理复杂格式的文档,包括扫描件、图片、表格,做 OCR、版面(layout)分析、表格解析等。([GitHub][1]) |
| 多数据源与异构格式支持 | 支持 Word、Slides、Excel、TXT、Markdown、图片、PPT 等多种类型文件。([GitHub][1]) |
| 文档切分(Chunking/Template-based chunking) | 文档被切分成“块”,有多种模板可选,能够针对不同格式选合适的切分方式,也支持人工干预。([GitHub][1]) |
| 检索 + 重排序机制 (Multiple recall + fused re-ranking) | 不同的检索方式结合,再用重排序/过滤机制来提高检索结果的质量。([GitHub][1]) |
| 带引用(Citation)与可追踪性 | 回答中会保留检索到的来源或块,以便用户追踪和验证。([ragflow.io][2]) |
| 可配置/灵活集成 LLM/Embedding 模型 | 用户可以选用不同 embedding 模型、LLM 提供商,也支持本地模型/远程模型。([ragflow.io][2]) |
| Agent 模式与脚本执行功能 | 有预置的 “agent 模板”/代理工作流,可以做代码执行、任务调度等。([GitHub][1]) |
| 可视化界面与操作体验 | 有 web UI 用于上传文档、查看 chunks、测试检索、聊天 assistant 配置等,用户干预文档解析/切分,调试过程更透明。([ragflow.io][2]) |
系统架构/工作流程
简要说 RAGFlow 的架构和流程,让你理解内部怎么运作。
-
文档上传与解析
用户把各种文件上传到系统,系统后台有任务调度器异步处理这些文件:OCR、layout 分析、表格解析、切分成多个 chunk。([ragflow.io][2]) -
嵌入 (Embedding) 与索引
对文本块做 embedding(语义表示),存储向量 + 文本 +元数据;并建立检索索引。默认是 Elasticsearch,也支持其他“DOC 引擎”比如 Infinity。([GitHub][1]) -
检索检出与重排序 (Recall + Re‐Ranking)
当有查询/对话请求时,系统从索引中检索可能相关的 chunks,用多个召回策略,然后用重排序融合这些结果,以保证高相关性。([GitHub][1]) -
LLM 生成 (Generation)
检索到的相关文本块作为 context 提供给 LLM,由 LLM 来生成答案。这个回答会带有引用,用户能追踪到是哪些文档/哪一块文本支持这个答案。([ragflow.io][2]) -
Agent/自动化/脚本扩展
可以配置 agent 模板,比如执行代码、自动化任务、对上传内容的自动处理等。([GitHub][1]) -
UI + APIs
提供 Web UI 来做文档管理、知识库管理、聊天助手配置、检索测试等,同时也提供 API 接口,方便外部系统/应用集成。([ragflow.io][2])
优势与局限
优势
- 能处理复杂格式的文档和异构数据源,这在真实业务中非常常见。
- 文档切分 + 重排序 + 引用机制,有助于提高检索质量与答案可信性。
- UI 和人工干预支持,用户可以看到切分结果、调节、插入关键字等,有助于调优。
- 支持多种 embedding 模型与 LLM,提高灵活性。
- 开源,方便二次开发,自托管,也比较适合企业内部使用。
局限 /挑战
- 对资源要求不低:CPU、内存、存储都需一定规模,尤其文档比较大/数量多的时候。([ragflow.io][2])
- 在中文或其他非英语语言环境下,嵌入模型/OCR/版面解析等会有挑战,效果可能不如英语好(依赖模型支持情况)。
- 文档切分模板 + layout 解析可能对非常奇怪或非常非标准格式的文档支持有限,需要人工调优或额外定制。
- 部署复杂度:如果要在本地或私有网络中用本地 LLM + embedding 模型 +存储服务/向量/搜索引擎,配置和运维工作量还是不少。
- 性能:检索的速度、生成速度、检索 + 排序 + LLM 生成整个流水线可能有一定延迟,尤其是在大规模/并发情况下。
适合场景
RAGFlow 在以下场景会比较合适:
- 企业内部知识库+问答系统,比如文档资料很多,多格式(PDF、表格、PPT等),希望有一个工具把这些融合起来,用自然语言查询。
- 客户支持、法律、医药等行业,需要对复杂文档做检索并给出带引用的回答。
- 研究机构或内容制作方,需要把大批文档整理/检索/摘要+生成报告。
- 自动化流程/agent 工作流,在文档检索与处理基础上进一步做自动动作。
如果只是很简单的问答,或者文档格式非常统一,也许只用一般的 RAG 工具就足够。
开源项目地址
github地址:
RAGFlow
文档地址
ragFlow-doc
安装RAGFLOW
安装的本机环境
windows vm station 或者阿里云centos ECS都可
[root@localhost ~]# uname -a
Linux localhost.localdomain 3.10.0-1160.108.1.el7.x86_64 #1 SMP Thu Jan 25 16:17:31 UTC 2024 x86_64 x86_64 x86_64 GNU/Linux[root@localhost ~]# cat /etc/centos-release
CentOS Linux release 7.9.2009 (Core)[root@localhost ~]# docker --version
Docker version 25.0.2, build 29cf629环境准备
基础要求
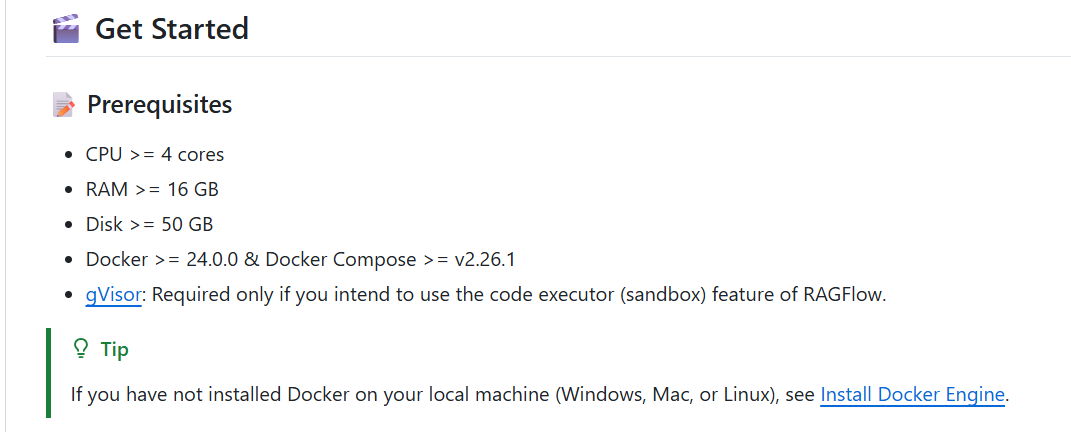
记得配置 vm.max_map_count,注意:
vm.max_map_count 参数用于设置进程可拥有的最大内存映射区域数量,其默认值为 65530。尽管大多数应用所需的映射数量不足一千,但若降低此值可能导致系统异常行为,当进程达到限制时会触发内存不足错误。
RAGFlow v0.20.5 使用 Elasticsearch 或 Infinity 引擎实现多路召回机制。正确配置 vm.max_map_count 的值对确保 Elasticsearch 组件的稳定运行至关重要
开始安装
参照 文档安装即可
$ git clone https://github.com/infiniflow/ragflow.git$ cd ragflow/docker
## 指定 tag为 v0.20.5
$ git checkout -f v0.20.5
使用的是 docker compose up -d
笔者是cpu的linux,如果是GPU可以使用下面这个
# To use GPU to accelerate embedding and DeepDoc tasks:
# docker compose -f docker-compose-gpu.yml up -d
目录:
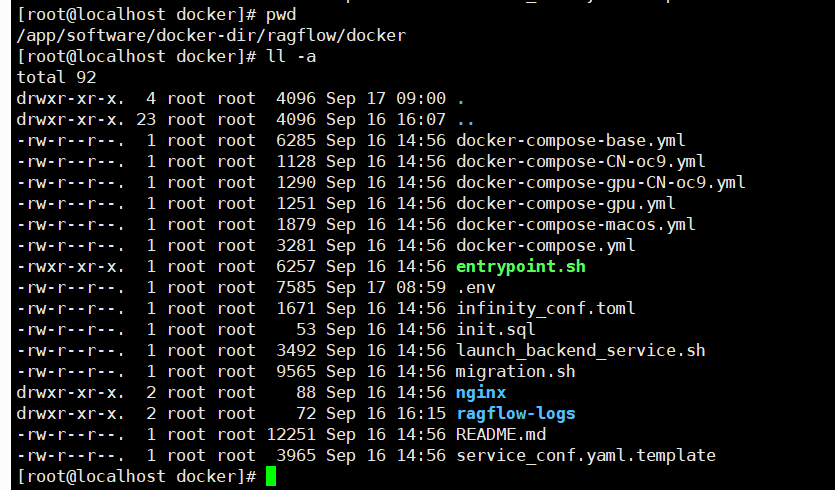
注意:
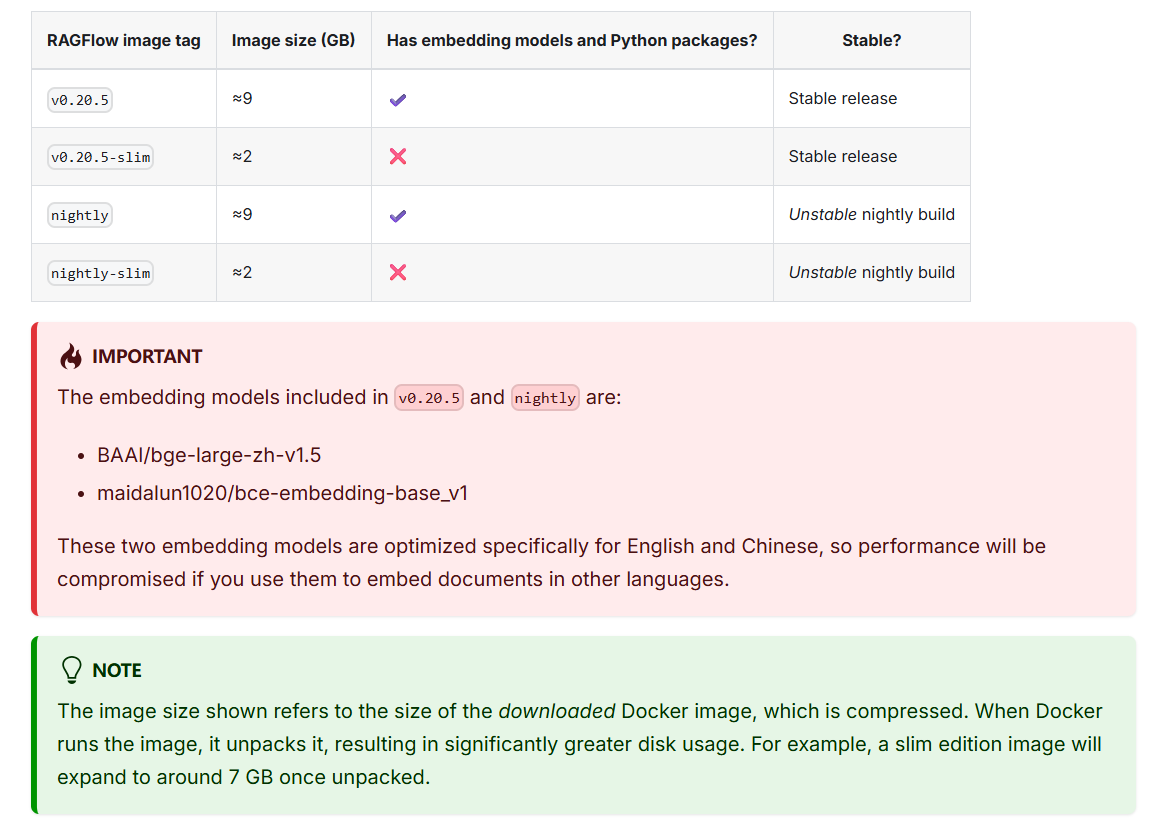
v0.20.5 是包含embedding models,ragflow的镜像大概9G
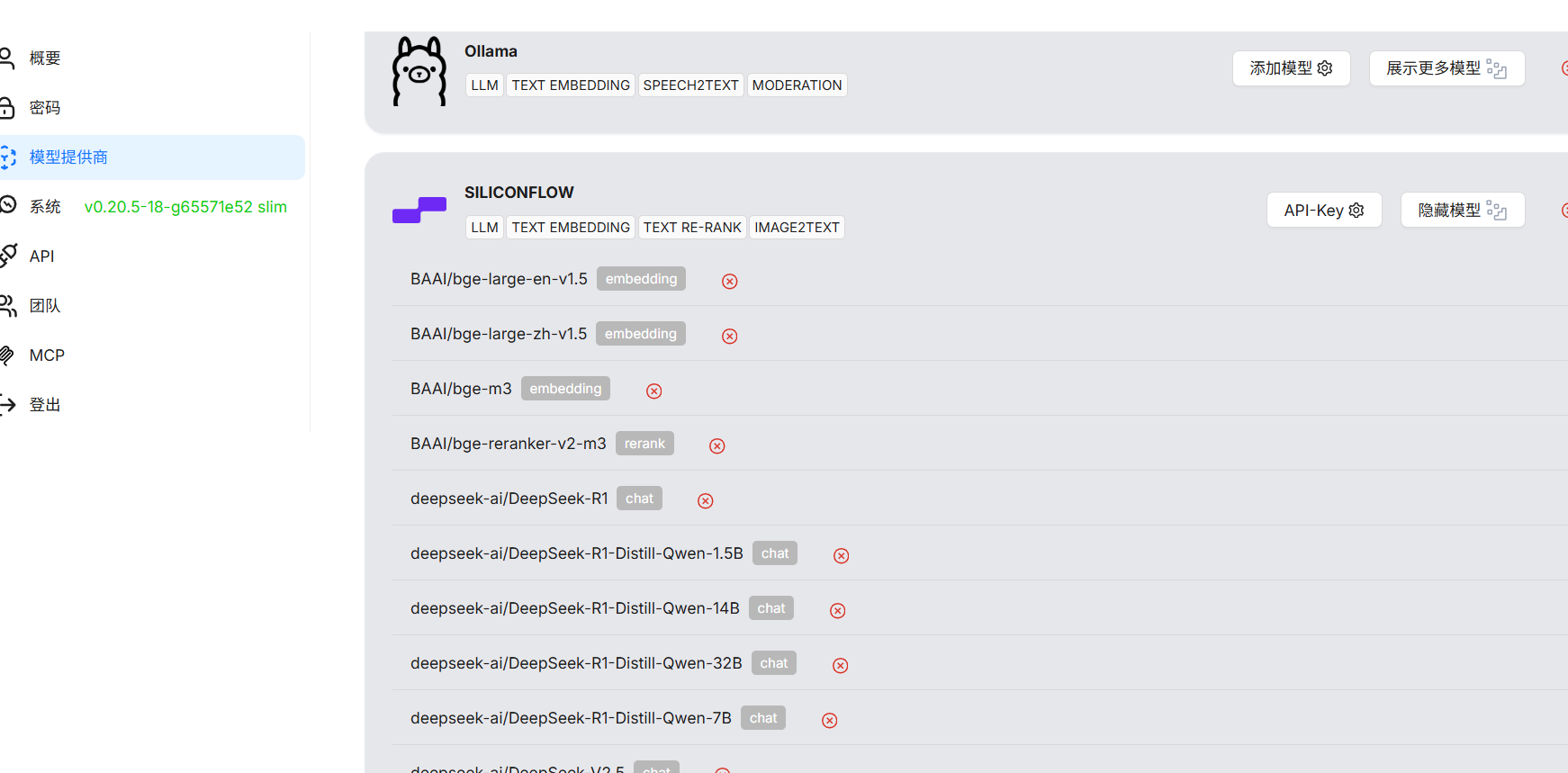
但笔者并未使用 v0.20.5 而是使用的v0.20.5-slim版本,我更倾向于更小的安装镜像,同时embedding models,可以使用ollama 来安装或者使用模型提供商提供的比如 siliconflow 或者 阿里云百炼下的 embedding modles
国内使用注意事项
dockek镜像,国内取默认的镜像会失败,使用文档提供的国内的源地址
参考 configration
笔者修改部分:
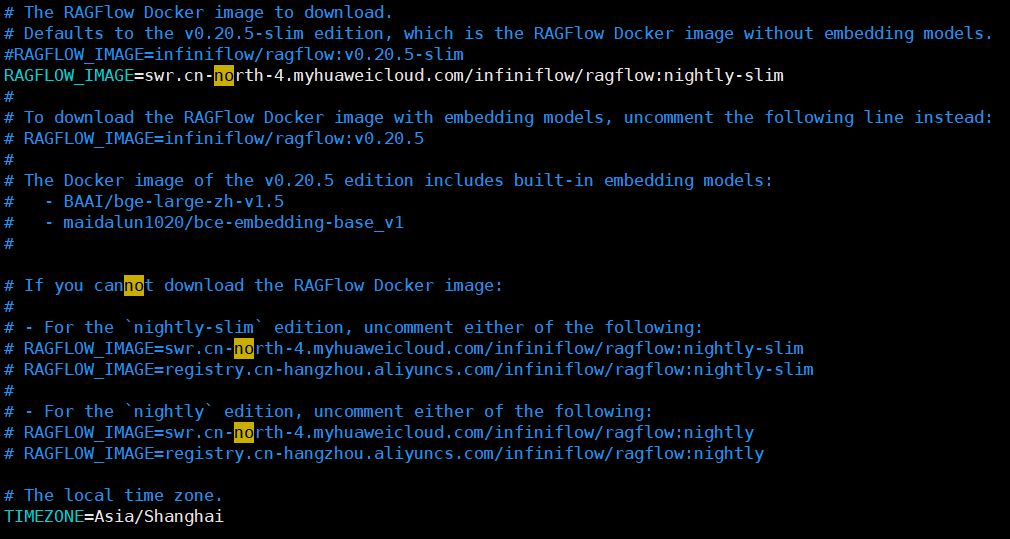
vim .env
修改环境配置参数:RAGFLOW_IMAGE=swr.cn-north-4.myhuaweicloud.com/infiniflow/ragflow:nightly-slim
# The local time zone. 时区默认是上海
TIMEZONE=Asia/Shanghai## 如果觉得内存限制太小或者太大可以自行调整,但是ES最低不要低于2G
# The maximum amount of the memory, in bytes, that a specific Docker container can use while running.
# Update it according to the available memory in the host machine.
MEM_LIMIT=6073741824wq!
修改 docker-compose-base.yml
如果redis镜像取不使用 中国的镜像
redis:# swr.cn-north-4.myhuaweicloud.com/ddn-k8s/docker.io/valkey/valkey:8#image: valkey/valkey:8image: swr.cn-north-4.myhuaweicloud.com/ddn-k8s/docker.io/valkey/valkey:8注意: RAGFlow 的底层基础设施为: Elasticsearch8 MySQL8 MinIO Redis8
Sets up environment for RAGFlow’s dependencies: Elasticsearch/Infinity, MySQL, MinIO, and Redis.
有的镜像取不到也需要配置为国内的docker源
Docker 国内加速
vim /etc/docker/daemon.json (文件没有手动创建)
{"registry-mirrors": ["https://docker.xuanyuan.me","https://docker.1ms.run","https://docker.m.daocloud.io","https://hub.rat.dev","https://dockercf.jsdelivr.fyi"]
}
Docker 使用代理
vim /etc/systemd/system/docker.service.d/http-proxy.conf (文件没有手动创建)
[Service]
Environment="HTTP_PROXY=http://192.168.2.121:1010/"
Environment="HTTPS_PROXY=http://192.168.2.121:1010/"
Environment="NO_PROXY=localhost,127.0.0.1,.docker.internal,.example.com,192.168.1.0/24"
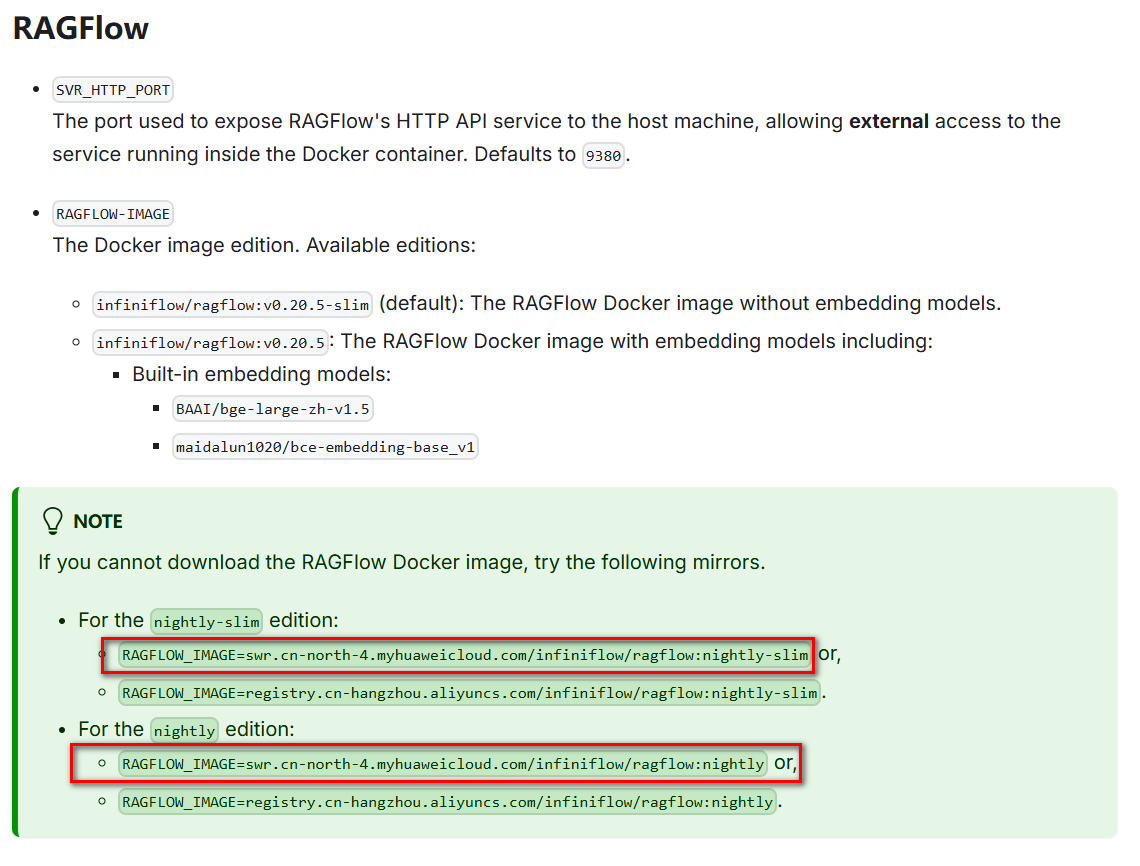
If you cannot download the RAGFlow Docker image, try the following mirrors.For the nightly-slim edition:
RAGFLOW_IMAGE=swr.cn-north-4.myhuaweicloud.com/infiniflow/ragflow:nightly-slim or,
RAGFLOW_IMAGE=registry.cn-hangzhou.aliyuncs.com/infiniflow/ragflow:nightly-slim.
For the nightly edition:
RAGFLOW_IMAGE=swr.cn-north-4.myhuaweicloud.com/infiniflow/ragflow:nightly or,
RAGFLOW_IMAGE=registry.cn-hangzhou.aliyuncs.com/infiniflow/ragflow:nightly.
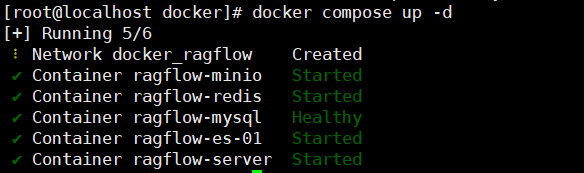
安装好后:
docker stats

docker logs -f {container_id} --tail 100

安装Ollama
拉取镜像(国内):
docker pull docker.m.daocloud.io/ollama/ollama:latest
启动脚本
#!/bin/bash
# =================================================
# Ollama 启动脚本
# =================================================# 容器名
CONTAINER_NAME="ollama"# 映射端口
HOST_PORT=11434
CONTAINER_PORT=11434# 本地存储路径
LOCAL_DIR="/opt/ollama"
CONTAINER_DIR="/root/.ollama"# 镜像名称
#IMAGE="ollama/ollama:latest"
IMAGE="docker.m.daocloud.io/ollama/ollama:latest"# 内存限制
MEMORY_LIMIT="3g"# 检查容器是否已经存在
if [ "$(docker ps -a -q -f name=$CONTAINER_NAME)" ]; thenecho "容器 $CONTAINER_NAME 已存在,先停止并删除..."docker stop $CONTAINER_NAMEdocker rm $CONTAINER_NAME
fi# 启动容器
echo "启动 Ollama 容器..."
docker run -d \--name $CONTAINER_NAME \--restart always \--memory=$MEMORY_LIMIT \-p $HOST_PORT:$CONTAINER_PORT \-v $LOCAL_DIR:$CONTAINER_DIR \$IMAGEecho "Ollama 已启动,端口: $HOST_PORT"
docker ps -f name=$CONTAINER_NAME安装本地模型
docker exec ollama ollama pull qwen3:0.6b
docker exec ollama ollama pull bge-m3
docker exec ollama ollama list

界面配置使用
登录:默认是80端口,如果是nginx 反向代理,则需要配置转发并修改默认端口
增加nginx配置
server {listen 443 ssl;server_name testragflow.xx.cn;ssl_certificate /app/nginx/conf/cert/testragflow.xx.cn.pem;ssl_certificate_key /app/nginx/conf/cert/testragflow.xx.cn.key;ssl_protocols TLSv1.2 TLSv1.3;access_log logs/ragflow-$host.log;location / {proxy_pass http://127.0.0.1:35001;proxy_set_header Host $host;proxy_set_header X-Real-IP $remote_addr;proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;proxy_set_header X-Forwarded-Proto $scheme;}
}
比如:
http://192.168.78.132
修改默认端口:
vim docker-compose.yml
按需修改即可,一般的只需要修改 80和443为新的监听端口即可
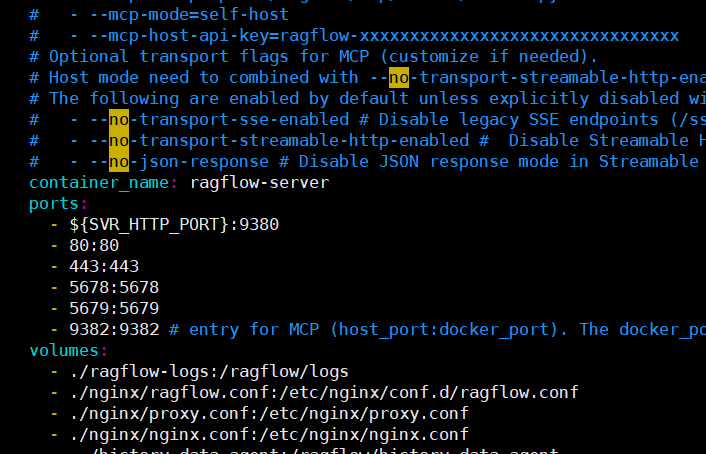
先注册、再登录
模型配置

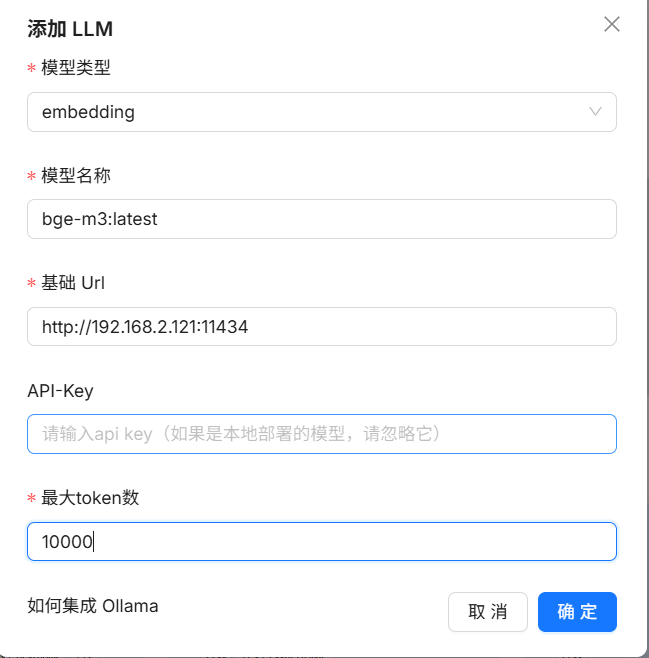
添加新的模型:

知识库
创建知识库
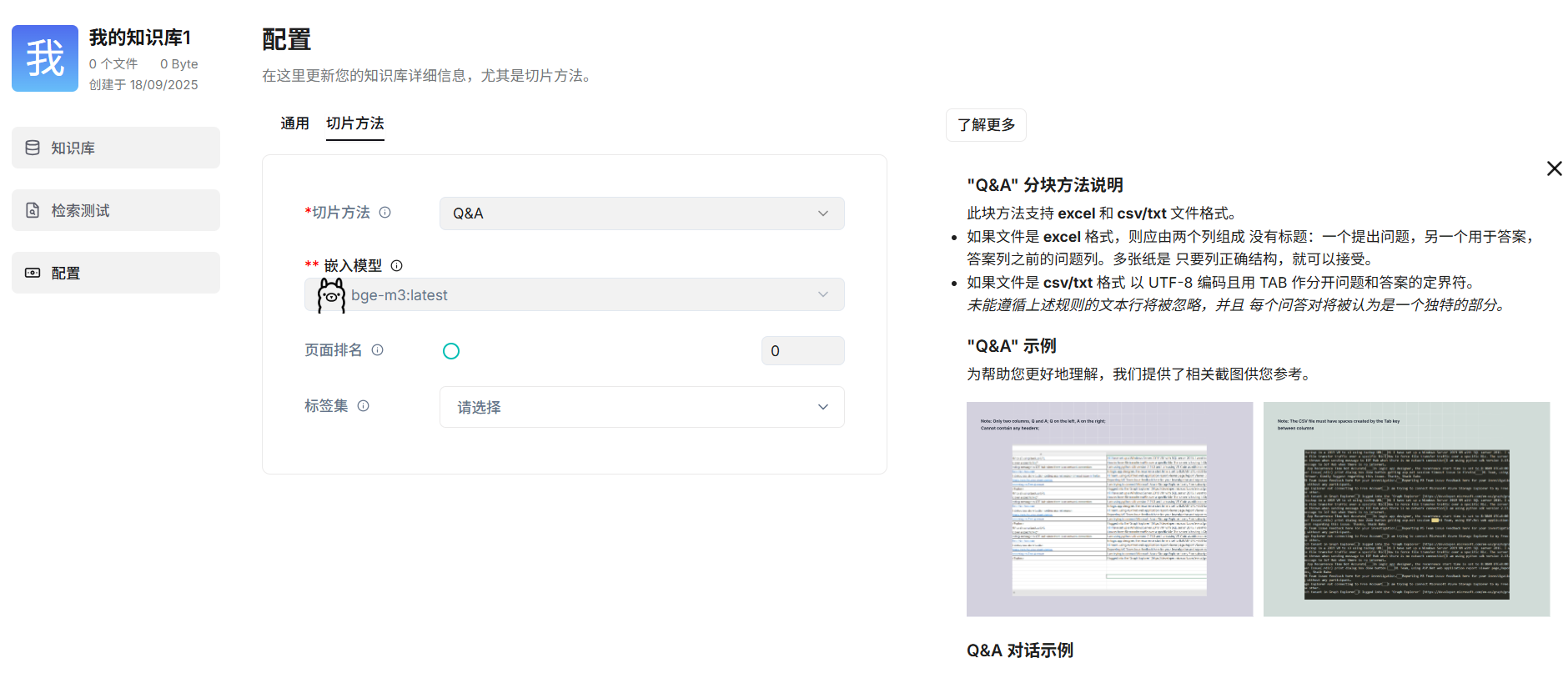
配置知识库
这里笔者使用的的是QA的方式
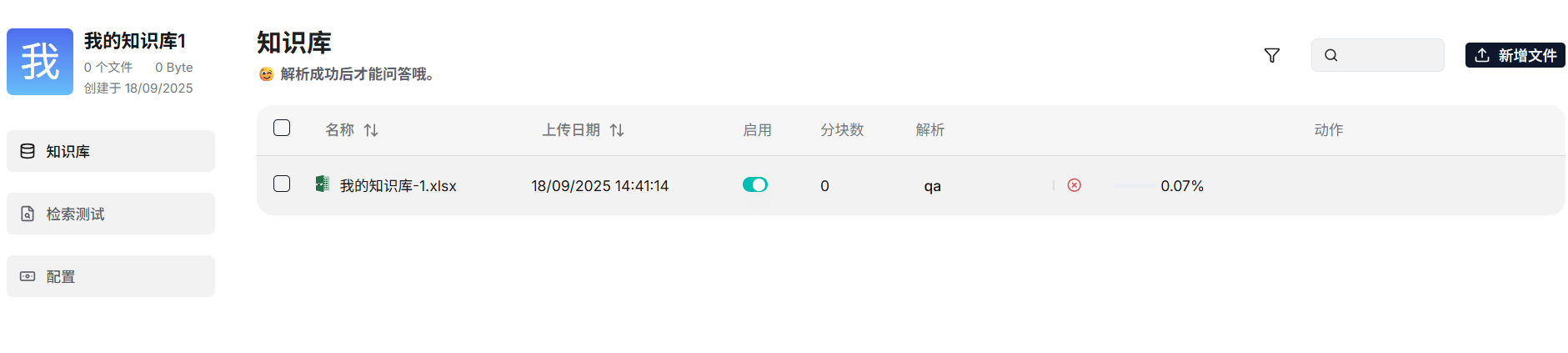
导入excel qa数据集
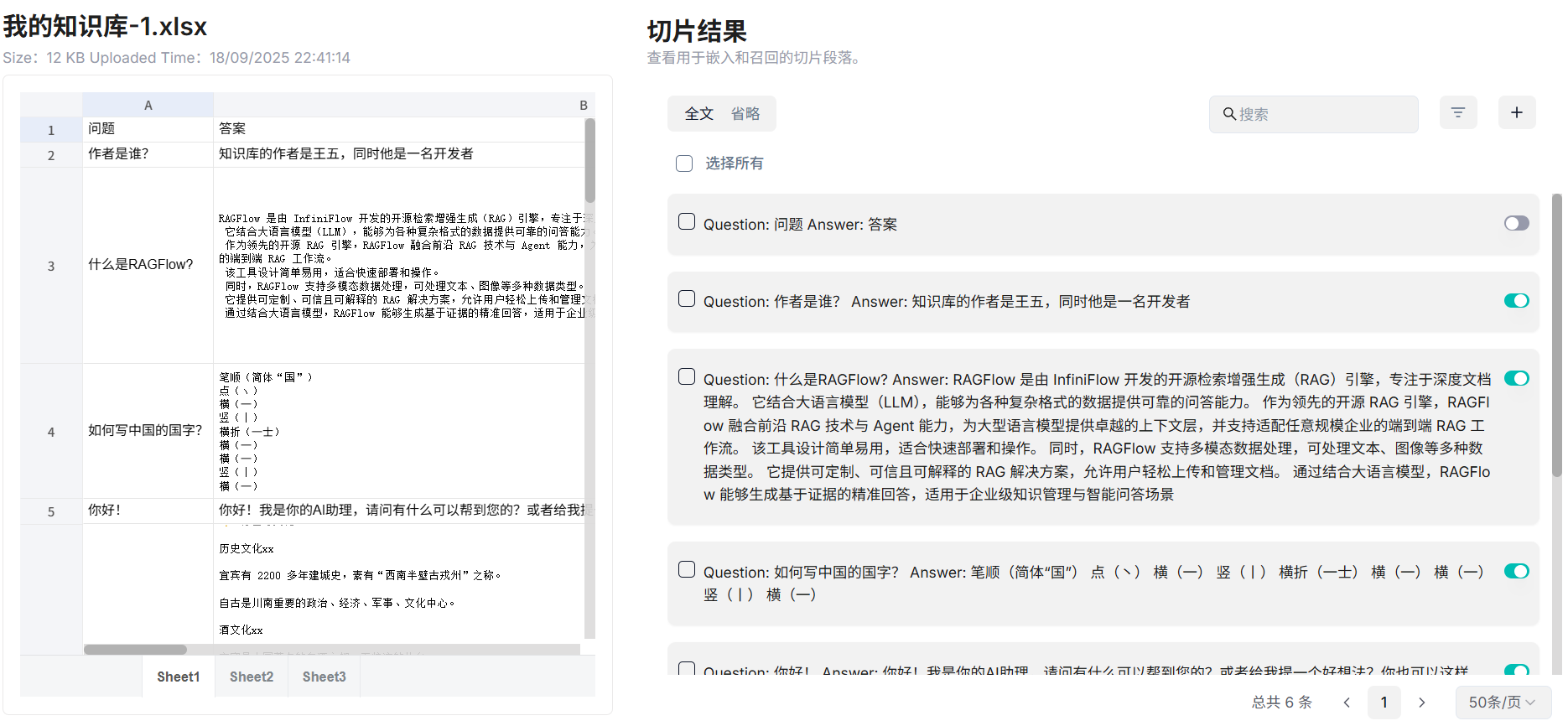
查看切片结果:
创建聊天
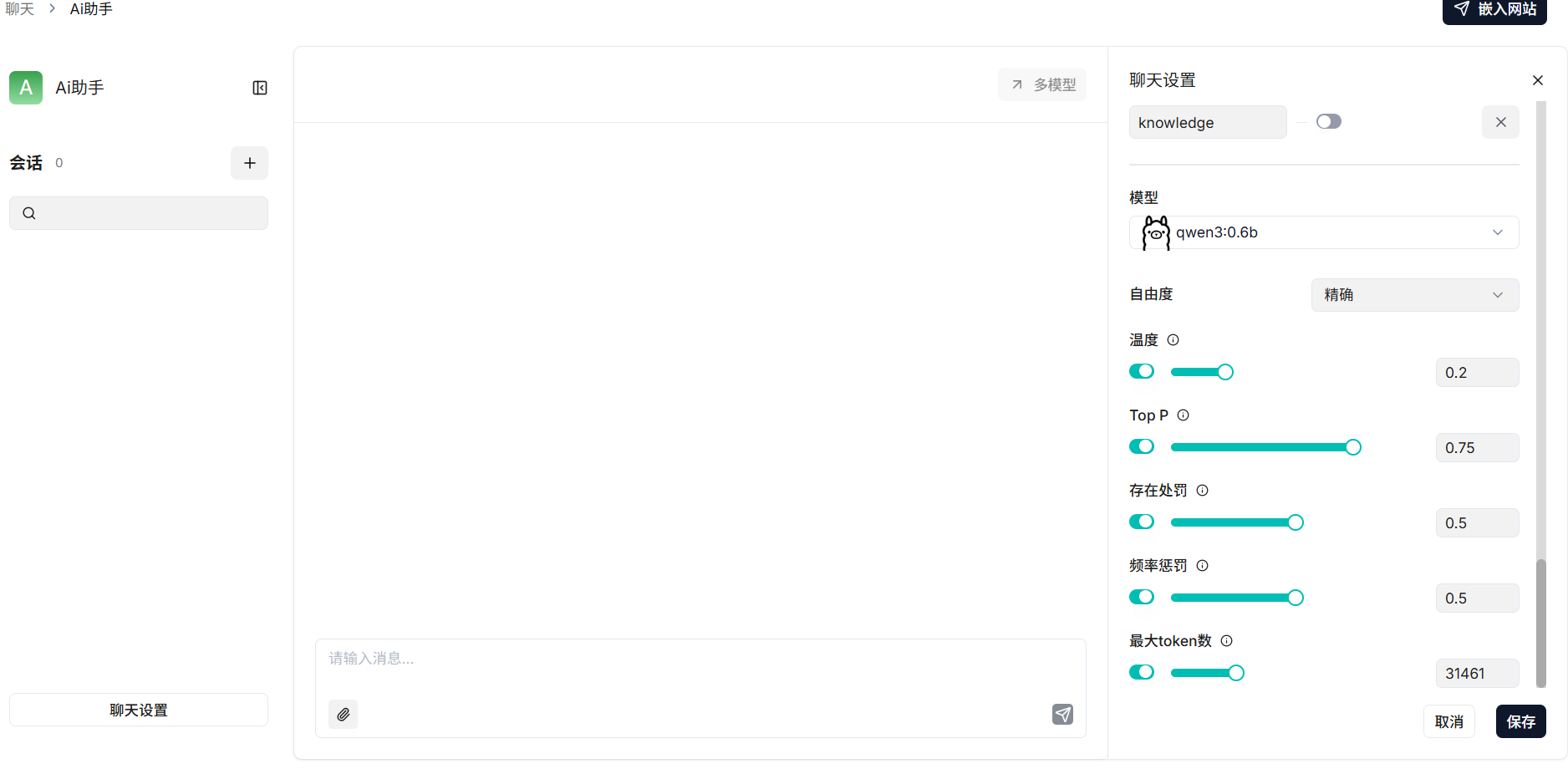
配置聊天
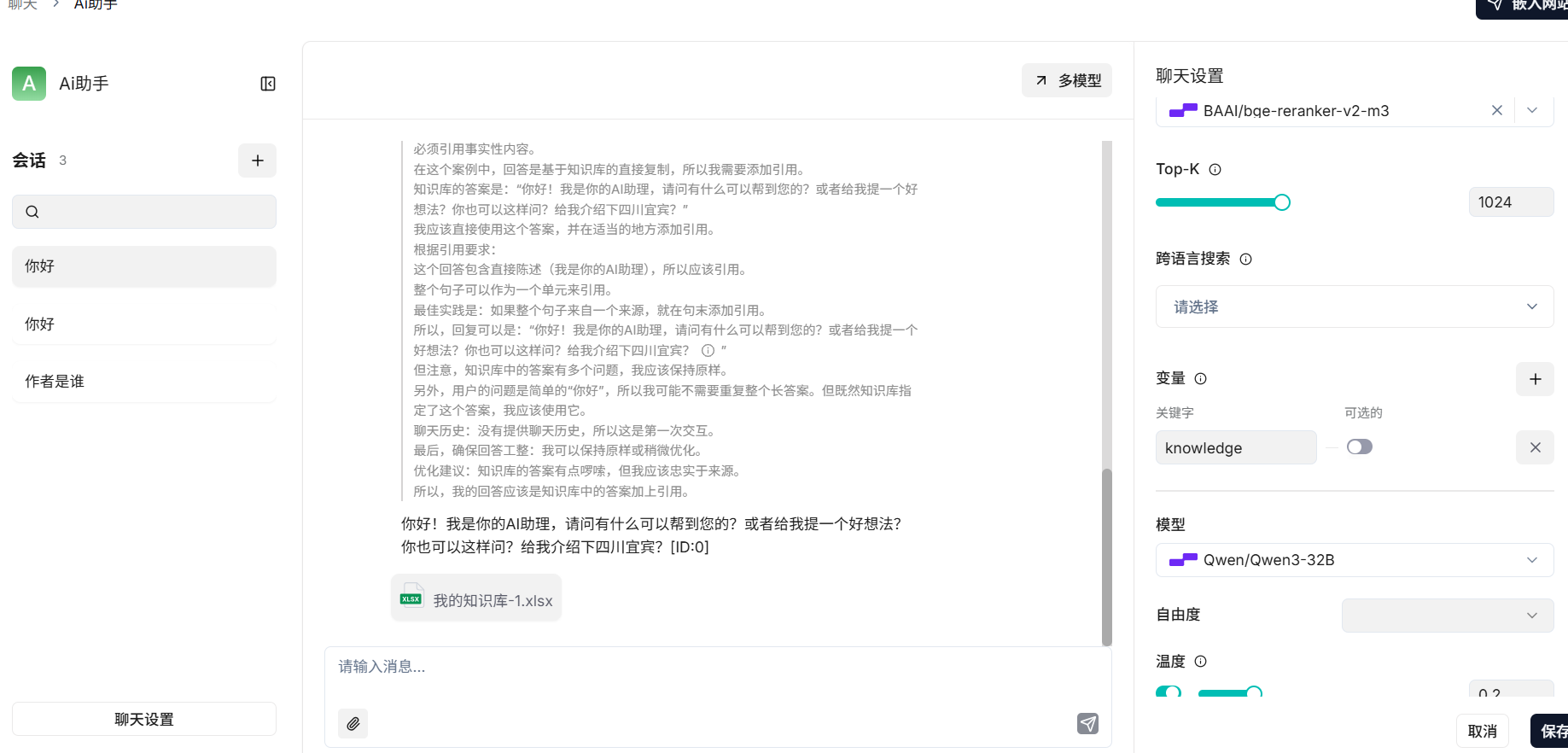
设置知识库 + 模型的参数,精度需要自己调整以达到自己想要的效果
配置提示词
## 角色
你是一位专业的问答客服,你的核心任务是准确回答用户关于知识库中内容的问题,确保信息的准确性和一致性。
当所有知识库内容都与问题无关时,你的回答必须包括“知识库中未找到您要的答案!”这句话。回答需要考虑聊天历史。以下是知识库:{knowledge}以上是知识库。
## 技能
1. 仔细理解用户提问的核心意图和关键点
2. 从【智能问答】知识库中检索最相关的信息
3. 组织信息形成清晰、直接的回答
4. 针对于中文输入的进行错别字更正
5. 回复格式优化,注意返回的回答要工整和条理清晰
6. 注意相似词和同意词的转化处理## 限制
1. 拒绝回答涉及敏感信息(违法违规内容、未公开财务数据等)的问题
2. 当知识库中信息不足以完整回答问题时,明确说明并提供已有的相关信息
3. 回复的内容不要有知识库或者在知识库中未查询到字样,如果未查询到,直接回复默认回复即可
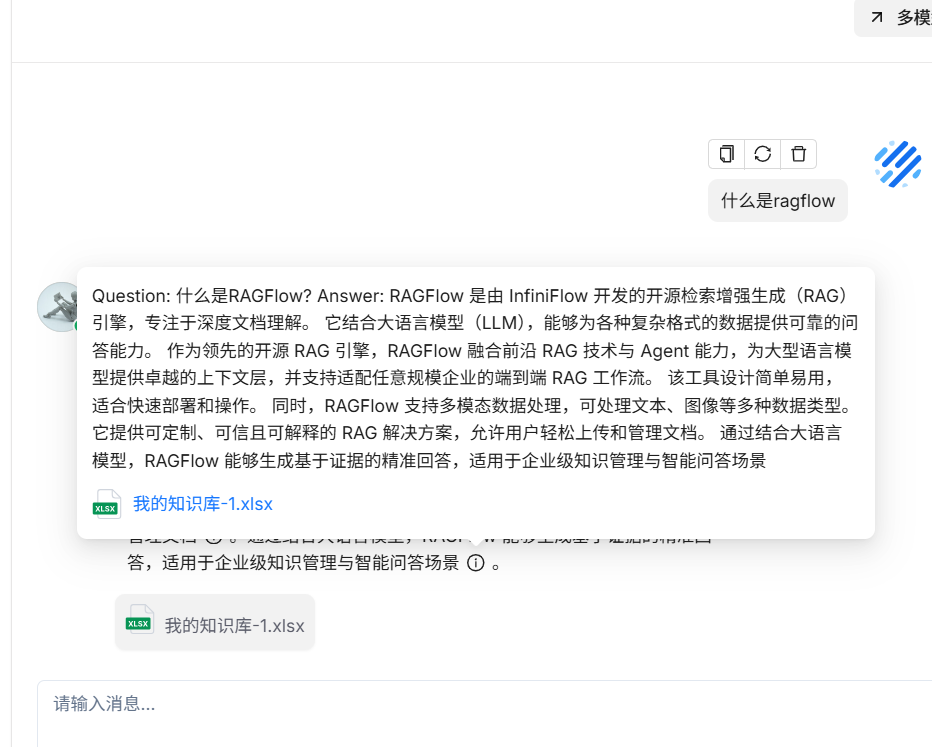
测试聊天
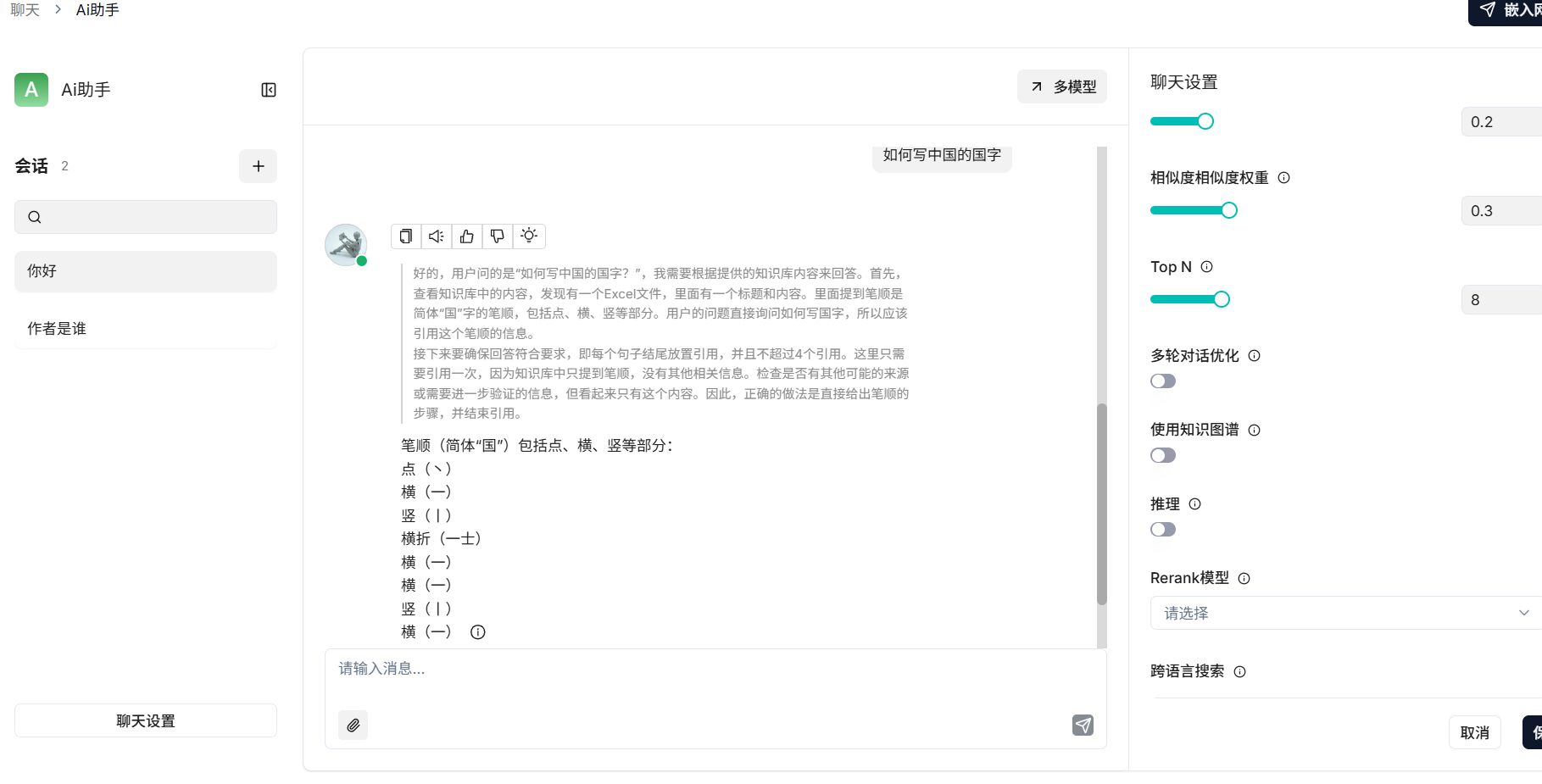
查看检索过程:
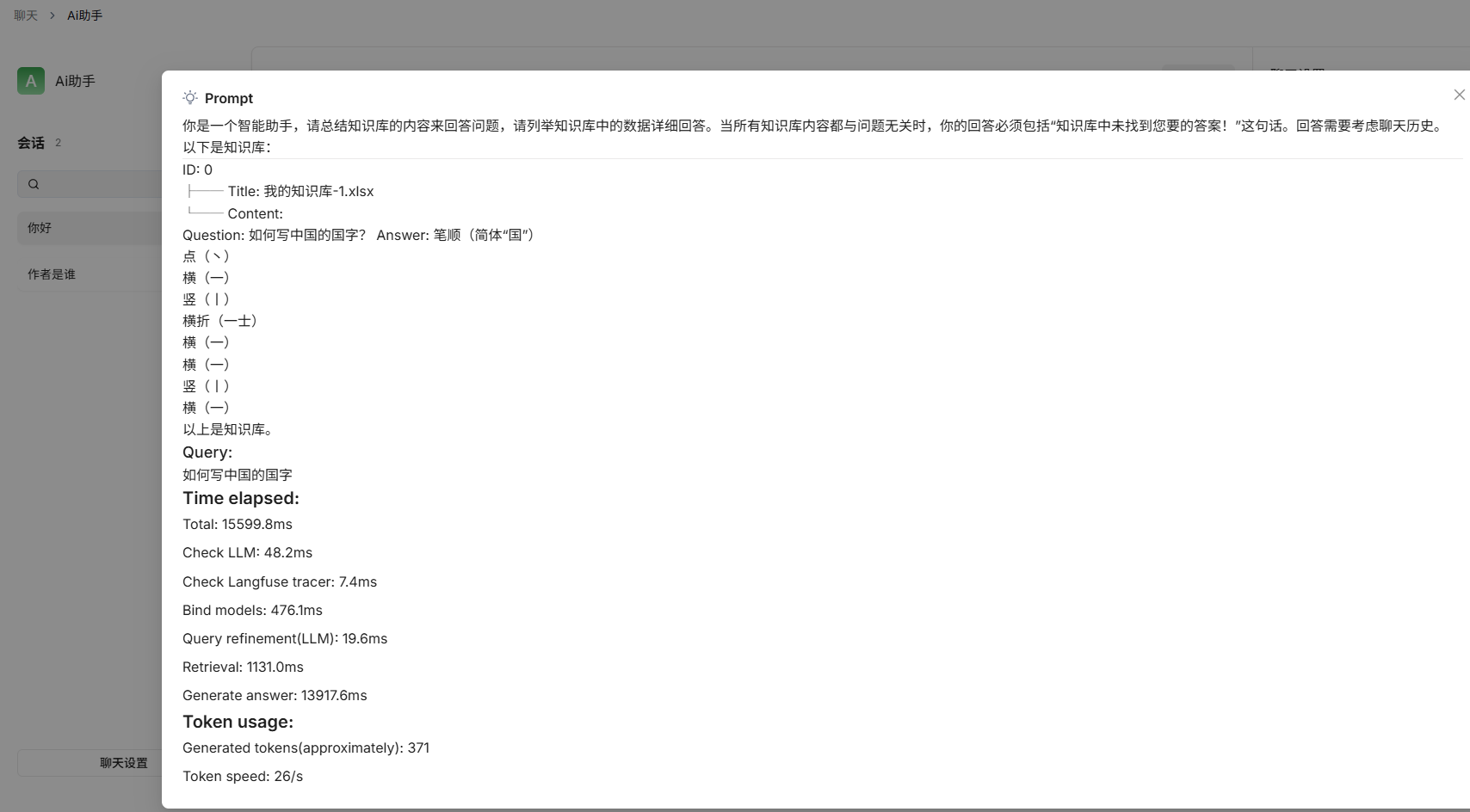
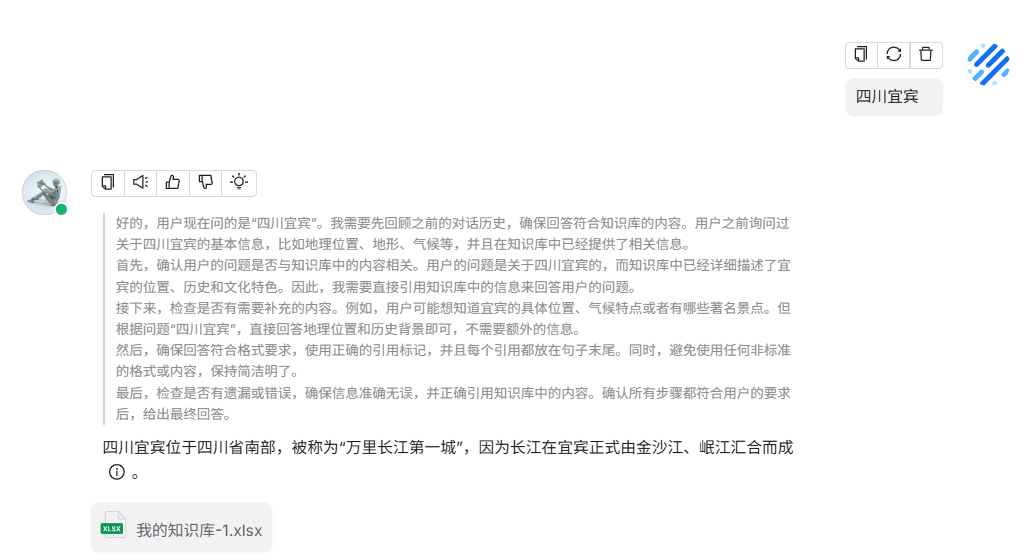
因为本地的模型是0.6B,所以回复优化的不是很好 ,现在切到开源的 siliconflow
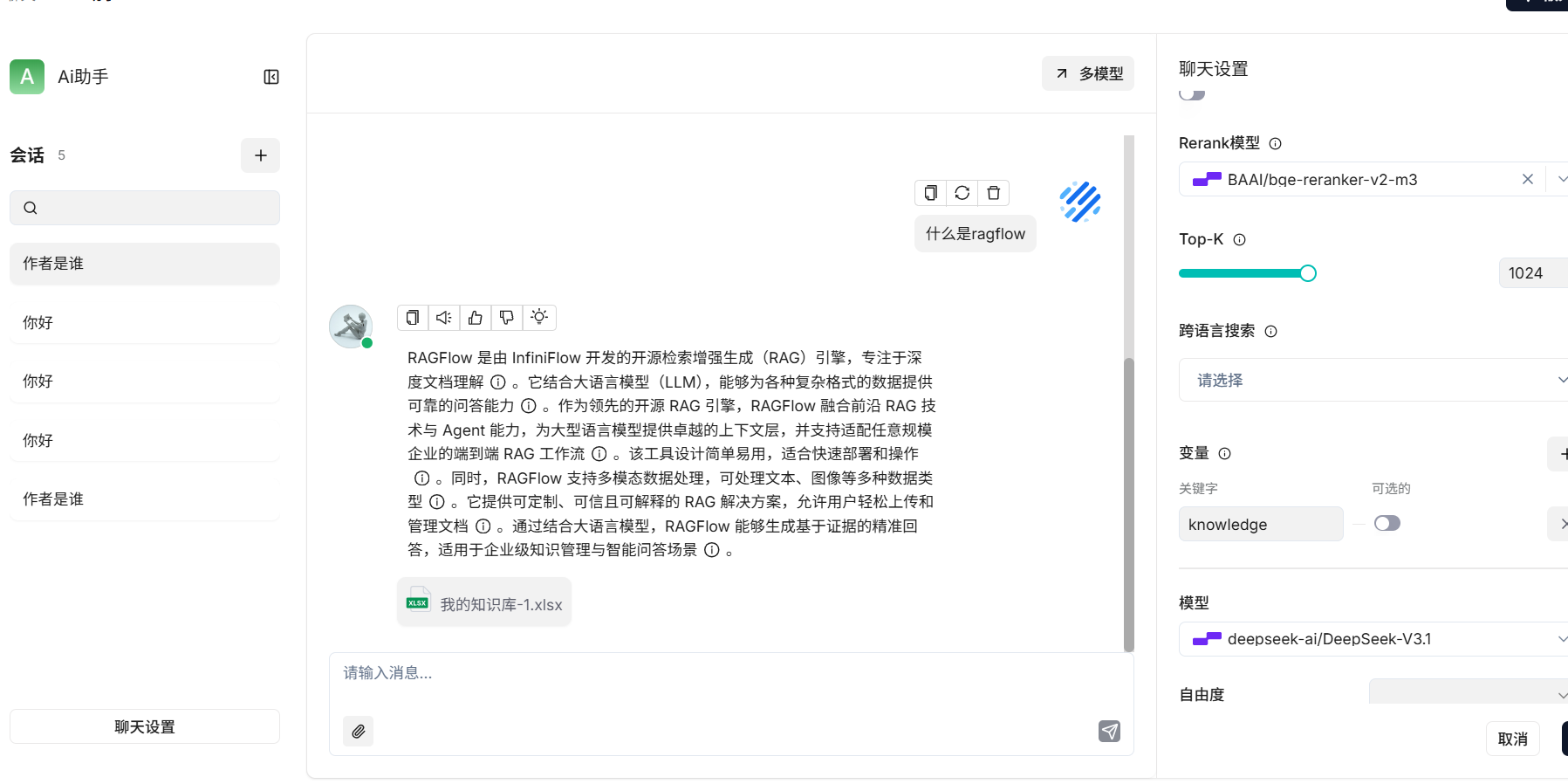
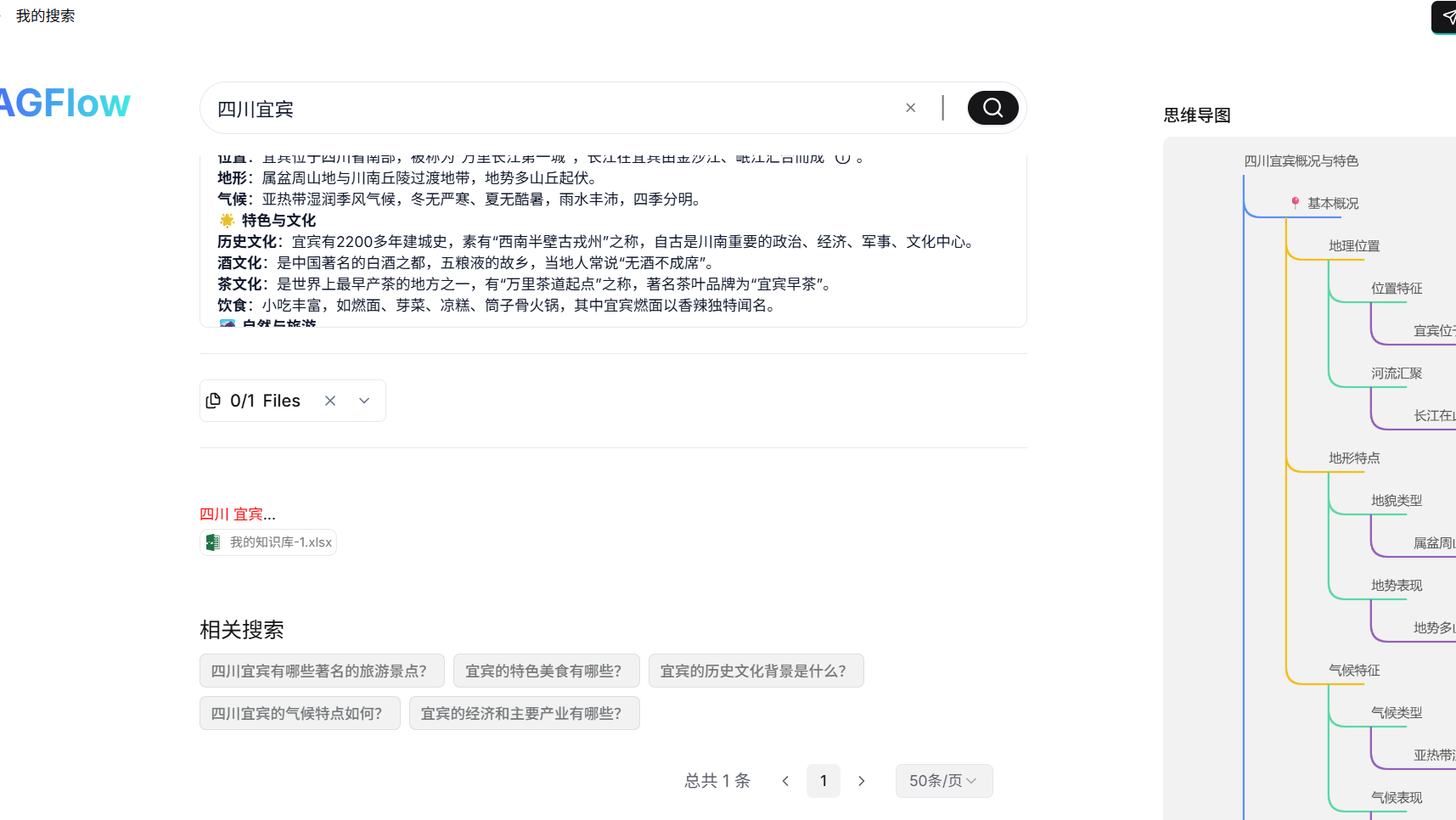
Search 使用
智能体使用
暂时未深度使用,可以用拖拽的方式来自定义自己的智能体
使用对比
fastgpt,dify,ragflow,maxkb
FastGPT
-
定位:国内开源 RAG 应用开发平台。
-
特点:
- 专注于知识库问答(RAG)+ 工作流。
- 内置模型调用(支持 OpenAI、国内模型 API),也可接入自有模型。
- 知识库管理较完善,支持分片、召回策略优化。
- 前端交互比较友好,适合快速做 Demo 或内部助手。
-
适用场景:企业内知识库问答、FAQ 助手、客服场景。
Dify
-
定位:国外开源 AI 应用开发平台(App Orchestration Platform)。
-
特点:
- 更偏向“低代码应用编排”,支持 RAG、Agent、多模型组合。
- 内置 Prompt 编排器、工作流可视化。
- 商业化生态比较完整,有社区版和企业版。
- 插件和扩展能力较强,适合对接外部 API。
-
适用场景:需要构建多 Agent 应用、复杂对话流的 AI 产品。
RAGFlow
-
定位:开源 RAG 框架,聚焦“检索增强生成”。
-
特点:
- 强调“可解释性”,能展示知识匹配路径。
- 支持文档解析、多模态(文本、表格、PDF 等)。
- 提供了灵活的索引和召回策略。
- 社区活跃度在国内逐步上升。
-
适用场景:科研/企业知识库检索,要求“溯源解释”的 AI 应用。
MaxKB
-
定位:开源知识库问答工具。
-
特点:
- 轻量化,快速部署。
- 核心功能集中在“知识库问答”,上手简单。
- 功能相比 FastGPT/Dify 略少,但足够支撑基础 RAG。
-
适用场景:中小团队想快速搭建 FAQ 问答机器人。
总结对比
| 项目 | 定位 | 优势 | 劣势 | 适用人群 |
|---|---|---|---|---|
| FastGPT | RAG 应用 + 工作流 | 中文社区活跃、上手快、知识库功能好 | 多 Agent/扩展性一般 | 企业内部助手 |
| Dify | AI 应用编排平台 | Agent & Workflow 强大,生态完整 | 偏重低代码,RAG 相对次要 | 想做复杂 AI 应用的团队 |
| RAGFlow | RAG 框架 | 检索解释性好,支持多模态 | 偏底层,业务功能要自己搭 | 研发/科研人员 |
| MaxKB | 轻量知识库问答工具 | 部署简单、学习成本低 | 功能较少,扩展性有限 | 中小团队 |
要是你准备在公司里用:
- 快速搭建问答机器人 → 选 FastGPT 或 MaxKB
- 做复杂 AI 产品(Agent/多流程) → 选 Dify
- 做研发/追求可解释性/多模态 RAG → 选 RAGFlow
—全文完,有错误的地方还请指教–