计算机网络基础(四) --- TCP/IP网络结构(网络层) (上)
网络层 -- (数据平面)
1. 网络层概述 -- 互联网的GPS与交通系统
想象一下,你要从北京给远在广州的朋友寄一个礼物包裹。你不需要亲自规划路线、不需要知道中途要经过哪个转运中心,你只需要写好收件人地址,把包裹交给快递公司即可。
快递公司会处理一切:他们有自己的分拣中心、运输路线和调度策略,确保你的包裹能最终送达。
在这个比喻中:
你的主机(电脑/手机) = 你(寄件人)
数据包 = 礼物包裹
路由器 = 一个个快递分拣中转中心
网络层 = 整个快递公司的运输网络系统
IP地址 = 收件人和寄件人的详细地址
网络层的核心任务就是这个:将数据包从源主机一路护送到目标主机,无论它们在世界上的哪个角落。这个宏伟的目标又具体分解为两个至关重要的功能:转发和路由选择,它们分别对应着数据平面和控制平面。
1.1 转发和路由选择: 数据平面 vs 控制平面
- 这是网络层最核心的一对概念,理解了它们,就理解了网络层的工作灵魂。我们继续用快递系统来类比。
1.1.1 转发( forwarding ) - 数据平面:分拣员的一线操作
- 定义: 指将分组从一个输入链路接口转移到适当的输出链路接口的路由器本地动作. 转发发生的时间很短(通常为几纳秒),通常用硬件实现
- 生动比喻:想象你是一个快递分拣中心(路由器)的分拣员。你的工作很简单:传送带送来一个包裹(数据包),你只看包裹上的目的地邮编(IP地址),然后迅速查阅手边一份非常简单的《分拣手册》(转发表)。手册上写着:“邮编100xxx的放3号口,邮编200xxx的放1号口...”。你根本不需要知道这个包裹从哪来、到哪去全程怎么走,你只需要根据当前的目的地,把它扔到对应的出口(链路),这就是转发。
深度解析:
是什么:转发是路由器本地的、即时的操作。当一个数据包到达某台路由器的输入端口时,路由器必须将其移动到适当的输出端口。这个过程速度极快(纳秒级),通常由硬件专用芯片(ASIC)完成。
关键工具 - 转发表:转发表就像一个非常精简的“路口指示牌”。它通常只包含网络前缀(比如
192.168.1.0/24)和对应的出口接口。路由器通过最长前缀匹配算法,为每个数据包找到最具体的“下一跳”方向。本质:数据平面关心的是“如何做”,它处理每个通过路由器的数据包,执行的是转发这一动作。它是网络层中“实干”的部分。
1.1.2 路由选择( routing ) - 控制平面:总部的路线规划师
定义: 确定分组从源目的地
生动比喻:现在,想象快递公司的总部规划团队。他们的工作不是去亲手分拣包裹,而是研究全国地图、分析交通状况、评估成本,然后制定出最优的运输路线。最后,他们把规划好的路线成果汇总成那一本本简单的《分拣手册》(转发表),下发到全国每一个分拣中心(路由器)。这个“规划路线、生成手册”的过程,就是路由选择。
深度解析:
是什么:路由选择是全局的、周期性的过程。它决定了数据包从源到目的地的端到端路径。路由器之间通过运行路由协议(如OSPF, BGP)来相互通信,交换网络拓扑信息,并利用路由选择算法(如Link-State, Distance-Vector)计算出通往所有已知网络的最佳路径。
关键工具 - 路由表:路由表是规划师手中的“完整地图”,它包含了通往所有网络的可能路径、距离(度量值)等信息。控制平面根据路由表,最终生成并维护数据平面使用的那个精简的转发表。
本质:控制平面关心的是“怎么选”,它负责生成转发表,是网络层中“决策”的部分。
核心总结:两者的关系
分工:控制平面(路由选择) 像公司的决策层(制定战略和计划),通常用软件实现;数据平面(转发) 像公司的执行层(根据计划进行具体操作), 通常用硬件实现。
协作:没有控制平面的智能计算,数据平面就无法正确转发;没有数据平面的高效执行,控制平面的决策就毫无意义。
分离趋势:在现代(Software - Defined Networking ~ SDN)(软件定义网络)中,这种分离更加彻底。控制平面被集中到一个叫SDN控制器的软件中,它统揽全局,直接向所有路由器下发流表(高级转发表),使得网络管理变得更加灵活和智能。
1.2 网络服务模型:快递公司的服务水平协议
不同的快递公司提供不同的服务。有的便宜但慢,有的贵但快且安全。网络层也是如此,它的服务模型定义了它在传输数据包时所能提供的服务品质。
IP协议提供的是一种极其简单、核心的服务模型——尽力而为服务。
生动比喻:这就像最基础的平邮服务。
不保证送达:包裹可能会丢失(数据包丢失)。快递公司不赔偿。
不保证顺序:你先寄出的包裹A,后寄出的包裹B,但B可能比A先到(乱序)。
不保证时效:包裹可能延迟,也可能很快,没准(延迟不确定)。
不保证完好:如果运输车装满了,你的大包裹可能会被拆成几个小包分别运送(分片),甚至如果车子实在装不下,你的包裹可能被直接扔下(丢弃)。
听起来很糟糕?但这正是互联网成功的关键!这种极简的设计将复杂性放在了网络边缘(终端主机),保持了网络核心的简单和高效,使得互联网能够以极低的成本无限扩张。
当然,某些应用(如视频通话、在线游戏)需要更高质量的服务。IP本身不提供,但可以通过其他技术(如综合服务 / 差分服务)在某种程度上实现,或者更常见的,由传输层(TCP) 和应用层自己来解决这些问题(比如TCP通过确认和重传机制来保证可靠性)。
其他服务模型(了解即可):
可靠服务:保证数据包按序、无损地送达。比如虚电路网络(如ATM)。
带宽保证:为数据流预留固定的带宽,适合视频流量。
延迟保证:保证数据包在特定时间内送达,适合语音通话。
总结一下:IP的“尽力而为”模型是一种“大道至简”的哲学。网络层只负责“尽力”把数据包往目标方向传送,而将恢复错误、保证顺序、控制流量等更复杂的任务,交给了通信的起点和终点(终端系统)去智能地处理。这种设计是互联网得以蓬勃发展、包容各种应用的基石。
注意:
我们将约定术语 "分组交换机" 是指一台通用分组设备, 他根据分组首部字段的值, 从输入链路接口到输出链路接口转移分组.
路由器和链路交换机都是分组交换机, 链路层交换机实现了协议栈的第一层和第二层, 而路由器实现了第一层到第三层.
由于路由器基于网络层数据报中的首部的字段值做出转发决定. 路由器因此是网络层(第三层)设备. 因此在本章中我们将主要使用术语 "路由器 " 来替代 "分组交换机".
2. 路由器工作原理
一台路由器的核心任务可以概括为:接`收数据包 -> 决策转发路径 -> 发送数据包。为了实现这个任务,其内部结构主要包含四个部分:输入端口、交换结构、输出端口和路由处理器。
2.1 输入端口处理和基于目的地转发
精简比喻:输入端口就像是立交桥的入口收费站和导航牌。
深度解析:
- 1. 物理层处理:首先在物理接口接收光/电信号,将其转换为数字比特流。
- 2. 链路层处理:处理数据链路层(如以太网)的帧头帧尾,进行差错校验后,解封出内部的IP数据包。
- 3. 查询转发表:这是最关键的步骤。路由器查看数据包首部的目的IP地址,并查询其本地的转发表,使用最长前缀匹配算法,确定该数据包的下一跳路由器和对应的输出端口。
- 4. 最长前缀匹配:好比找目的地是“北京市海淀区清华园”的包裹。转发表中可能有“北京市”(更短但更泛的前缀)和“北京市海淀区”(更长更具体的前缀)两条记录。路由器会选择更精确的“北京市海淀区”这条规则来决定转发路径。
- 目标:输入端口处理完成后,数据包就已经被“贴好了标签”,知道了自己该从哪个出口离开。
2.2 交换
精简比喻:交换结构是连接所有输入和输出端口的立交桥桥体本身,负责将车辆(数据包)从入口引到正确的出口。
深度解析:这是路由器内部的数据通路,其设计决定了路由器的吞吐量。主要有三种类型:
- 1. 经内存交换:路由器最早期的形式: 是传统计算机在输入端口与输出端口之间的交换是在CPU (路由选择处理器) 的直接控制下完成的. 路由处理器充当“交通协管员”,直接将数据包从输入端口内存拷贝到输出端口内存。速度慢,无法并行。
- 原理: 输入输出端口的功能, 就像在传统操作系统中的 I/O 设备一样. 一个分组到达一个输入端口时, 该端口会先通过中断方式向路由选择处理器发送信号. 于是, 该分组从输入端口处被复制到了处理器内存中. 路由选择处理器则从其首部中提取目的地址, 在转发表中找到适当的输出端口, 并将该分组复制到输出端口的缓存中
- 古今区别: 许多现代路由器通过内存进行交换, 然而与早期路由器的主要差别是, 目的地址的查找和分组存储 (交换) 进入适当的内存存储位置是由输入线路卡来进行处理的.
- 2. 经总线交换:使用一条共享总线。输入端口为数据包贴上标签(目标输出端口)后放入总线,所有输出端口都能看到,但只有标签匹配的才会接收。成本低,但总线带宽成为瓶颈。
- 瓶颈: 如果多个分组同时到达路由器, 每个位于不同的输出端口, 除了一个分组外所有其他的分组必须等待, 因为一次只能有一个分组跨越总线.
- 3. 经互联网络交换(纵横式交换机):使用一个复杂的交换矩阵(如Crossbar),可以同时建立多条输入和输出端口之间的并行连接。这是高性能路由器采用的方式,像是一个复杂的多层立交桥,允许多辆车同时通过而不堵塞。
- 特性: 纵横式交换机是非阻塞的, 即只要没有其他分组当前被转发到该输出端口, 转发到输出据端口的分组将不会被到达输出端口的分组阻塞.
- 1. 经内存交换:路由器最早期的形式: 是传统计算机在输入端口与输出端口之间的交换是在CPU (路由选择处理器) 的直接控制下完成的. 路由处理器充当“交通协管员”,直接将数据包从输入端口内存拷贝到输出端口内存。速度慢,无法并行。
2.3 输出端口处理
含义: 输出端口处理取出已经存放在输出端口内存中的分组并将其发送到输出链路上 这包括选择和取出排队的分组进行传输, 执行所需的链路层和物理传输功能.
精简比喻:输出端口是立交桥的出口收费站和调度站。
深度解析:
- 缓存排队:从交换结构接收到的数据包会先被放入输出队列(缓存) 中等待发送。
数据封装:为IP数据包重新加上数据链路层的帧头和帧尾(目标MAC地址等)。这个地址是通过ARP等协议查询下一跳IP地址得到的。
- 物理层发送:将封装好的帧转换为物理线路上的光/电信号发送出去。
输出端口是拥塞最容易发生的地方,如果数据包到达的速率超过端口发送的速率,队列就会堆积。
2.4 何处出现排队
- 排队是管理流量的必要手段,但也是性能瓶颈和包丢失的根源。
输入排队:在旧式采用共享总线交换的路由器中,即使输出端口空闲,多个输入端口也可能因为争夺同一个输出端口而排队,甚至导致线头阻塞——一个排在队列头部的包阻塞了后面去往空闲端口的包。
出现时机: 如果交换结构不能快得使所有到达分组无时延地通过它的传送, 此时在输入端口也将出现分组排队, 到达的分组必须加入输入端口队列中, 以等待通过交换结构传送到输出端口.
示例: 我们考虑纵横式交换结构 :
假定:
1. 所有链路速度相同
2. 一个分组能够以一 条输入链路接收一个分组所用的相同的时间量, 从任意一个输入端口传送到给定的输出端口
3. 分组按照FCFS (先来先服务 First-Come, First-Serve) , 从一指定输入队列移动到其要求的输出队列中.
则只要其输出端口不同, 多个分组可以被并行传送. 然而如果位于两个输入队列前端的两个分组是发往同一输出队列的, 则其中一个分组将被阻塞, 且必须在输入队列中等待.
输出排队:这是最主要的排队位置。当交换结构转发数据的速率快于输出端口发送数据的速率时,数据包就会在输出缓存中堆积。一旦缓存被填满,就必须要做出决定: 要么丢弃到达的分组(采用一种叫做弃尾 (drop-tail) 的策略) 要么删除一个或多个已排队的分组为新来的分组腾出空间,这是网络拥塞的主要表现。
2.5 分组调度
- 既然输出端口需要排队,那么下一个问题就是:接下来该发送哪个数据包? 这就是分组调度算法要解决的问题。
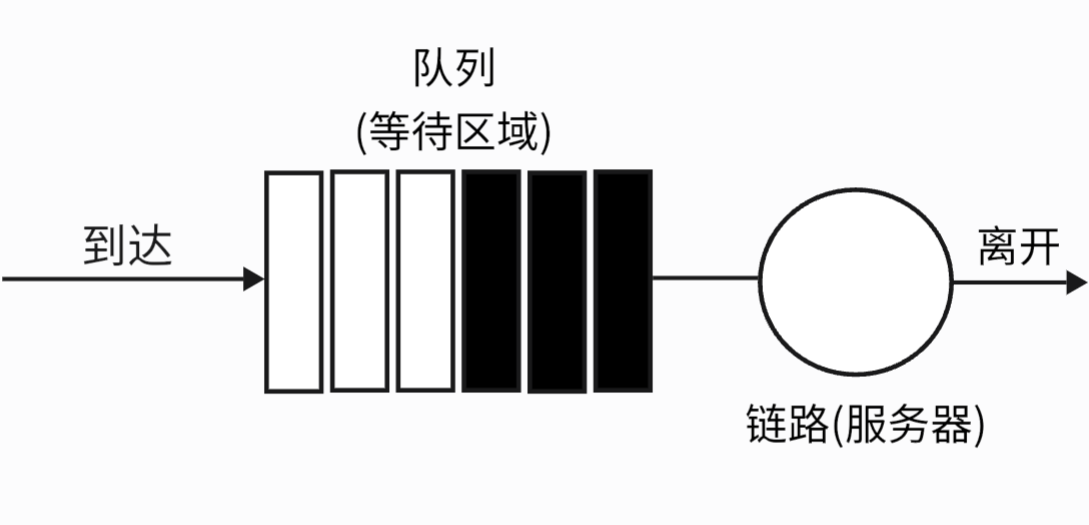
2.5.1 先进先出 (FIFO - First-In-First-Out)
解释: 如果链路当前正忙于传输另一个分组去, 到达链路输出队列的分组要排队等待传输, 如果没有足够的缓存空间来容纳到达的分组, 队列的分组丢弃策略则决定该分组是否将被丢弃 (丢失) 或者从队列中去除其他分组以便为到达的分组腾出空间
比喻:最简单的单一路队,先来的先被服务。
分析:简单粗暴,但“坏公民”(发送大量数据的流)会挤占“好公民”(发送少量数据的流)的带宽,导致不公平。
图示:
2.5.2 优先权排队
解释:
到达输出链路的分组被分类放入输出队列中的优先权类, 如下图所示. 同时在实践中, 网络操作员可以配置一个队列, 这样携带网络管理信息的分组 (例如: 由源或目的TCP/IP 端口号所标识) 获得超过用户流量的优先权; 每个优先权类通常都有自己的队列.
当选择一个分组传输时, 优先权排队规则将从队列为非空 ( 也就是有分组等待传输 ) 的最高优先权类中传输一个分组.
在同一优先权类的分组之间的选择通常以FIFO方式完成
比喻:机场的头等舱/经济舱通道。高优先级队列(如语音通话包)总是被优先发送。
分析:可以保证关键业务质量,但如果高优先级流量持续不断,低优先级流量可能会被“饿死”(完全得不到服务)。
图示: 优先权排队模型
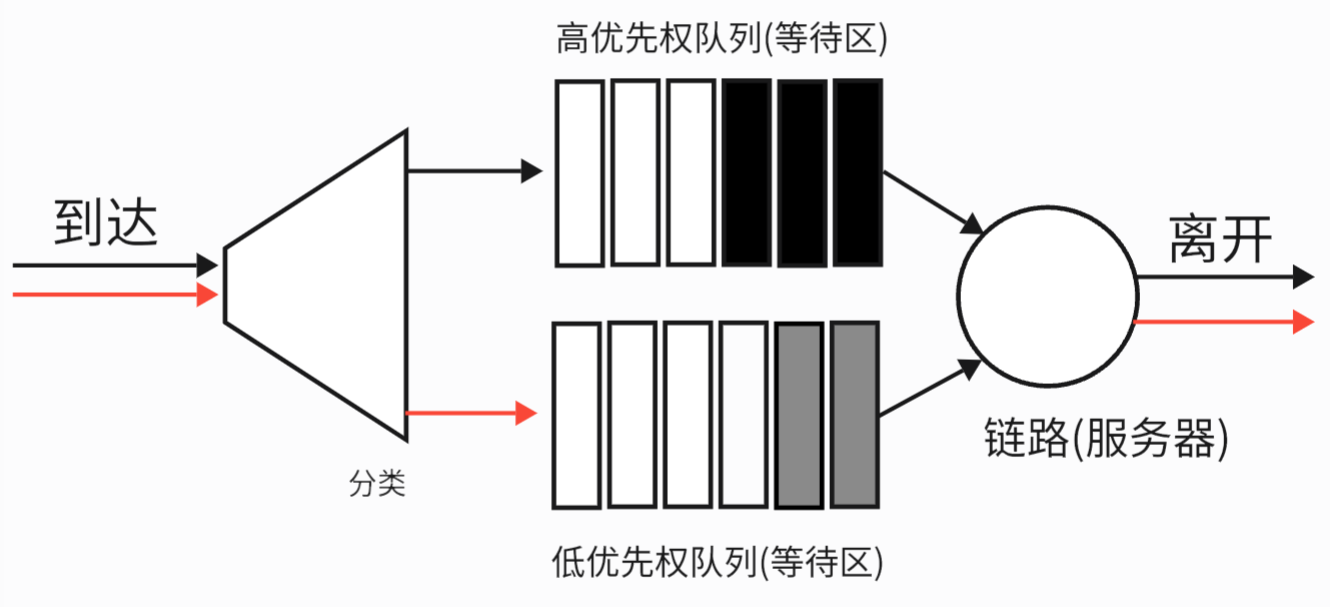
注意: 在非抢占式优先权排队规则下: 一旦分组开始传输, 无论是否已经传输完成, 都不能被打断.
2.5.3 循环排队 / 轮询调度 (Round Robin)
解释: 在循环排队规则( round robin queuing discipline ) 下, 分组像使用优先权排队那样被分类, 然而在类之间不存在严格的服务优先权, 循环调度器在这些类之间轮流提供服务.
比喻:银行的多队列多窗口。调度器依次为每个队列服务一次,循环往复。
分析:保证了公平性,每个流 (每个类) 都能得到服务机会。但无法区分数据包的大小,一个大数据包会占用很长的发送时间。
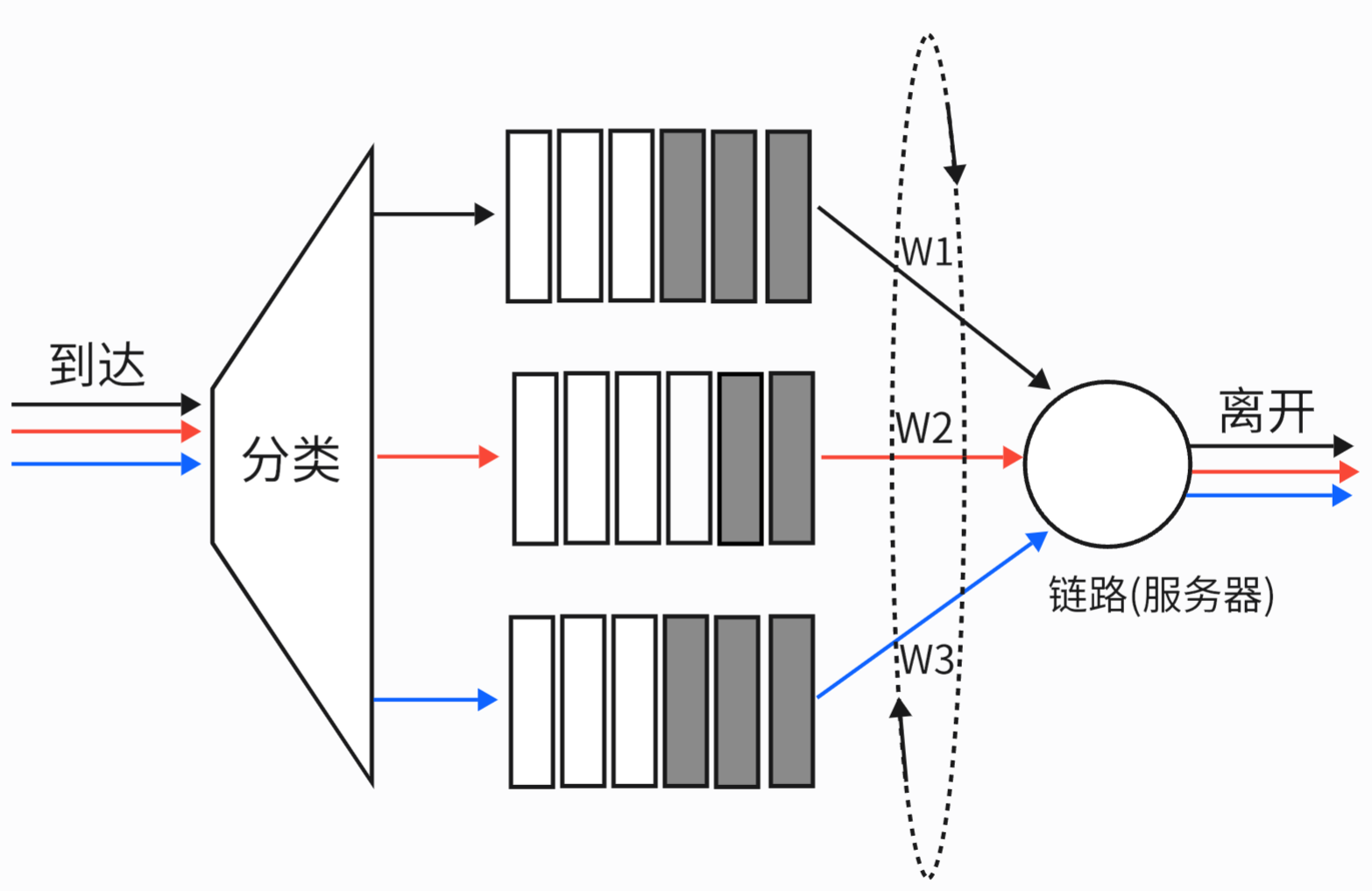
2.5.4 加权公平排队 (WFQ - Weighted Fair Queuing)
解释:
其中, 到达的分组被分类并在合适的每个类的等待区域排队. 与使用循环调度一样, WFQ 调度器也以循环的方式为各个类提供服务
WFQ 也是一种保持工作规则, 因此在发现一个空队列时, 他立即移向服务队列中的下一个类.
比喻:升级版的轮询。每个队列(流)被分配一个权重(如带宽比例)。权重高的队列,在每次轮询中能发送更多字节的数据。
分析:这是最复杂也最理想的调度方式。它既考虑了公平性(每个流都有机会),又考虑了优先级(通过权重分配带宽),被广泛用于保证服务质量。
区分: WFQ 与 循环排队的不同之处在于, 每个类的任何时间间隔内可能收到不同数量的服务.
图示: 加权公平排队
3. 网络协议: IPv4, IPv6, 寻址 及其他
本部分我们将关注点转向因特网网络层的关键方面和著名的网络协议 (IP).
3.1 IPv4 数据报格式
关键字段:
版本 (Version, 4 bits):指明IP协议版本号,这里是
4。路由器靠这个字段来区分IPv4和IPv6。首部长度 (IHL, 4 bits):指示IP报头本身的长度(以4字节为单位)。因为选项字段很少使用,所以最常见的首部长度是20字节(值为5)。
区分服务 (Differentiated Services, 8 bits):用于表示数据包的服务类型,如低延迟、高吞吐量或高可靠性要求。这是实现服务质量(QoS) 的基础。
数据报长度 / 总长度 (Total Length, 16 bits):指整个IP数据报(报头+数据)的总字节数。理论最大长度为65535字节。然而, 很少有数据报会超过1500 字节的, 该长度使得IP 数据报能容纳最大长度以太网帧的载荷字段.
标识、标志、片偏移 (Identification, Flags, Fragment Offset):这三个字段是分片重组的“三件套”,我们将在3.2节详细解析。它们是理解IPv4如何处理大数据包的关键。
生存时间 (TTL, 8 bits):一个极其重要的安全卫士字段。数据包每经过一个路由器,TTL值就减1。当TTL减为0时,该数据包会被丢弃,并向源主机发送一个ICMP超时消息。这可以防止由于路由环路而导致的数据包在网络中“永生”和无限循环,消耗网络资源。
协议 (Protocol, 8 bits):指示数据部分应该交给哪个上层协议处理。例如,
6代表TCP,17代表UDP。这是实现协议多路复用/分解的关键,相当于告诉收货点“这个是给TCP部门的,那个是给UDP部门的”。协议号是将网络层与运输层绑定到一起的 "粘合剂" ; 而端口号是将运输层和应用层绑定到一起的 "粘合剂"首部检验和 (Header Checksum, 16 bits):用于检测IP报头在传输过程中是否出错。路由器收到数据包后会验证此检验和,若出错则直接丢弃。注意:它只校验报头,不校验数据部分,数据的可靠性交由上层(如TCP)保障。
计算方法:
将首部的每两个字节当作一个数, 用反码算术对这些数求和. 该和的反码 (被称为因特网检验和) 存放在检验和字段中. 路由器要对每个收到的 IP 数据报计算其首部检验和, 如果数据报首部中携带的检验和与计算得到的检验和不一样, 则检测出是个差错.
源IP地址和目的IP地址 (32 bits each):包裹的“寄件人”和“收件人”地址。这是整个数据报的终极目标,所有转发决策都基于目的IP地址。
选项 (Options):选项字段允许 IP 首部被扩展. 很少使用, 如记录路径、时间戳等。然而少量的选项使得问题变得复杂: 因为数据报首部长度可变, 故不能预先确定字段从何开始. 值得注意的是: IPv6中已将 IP选项 去掉了
数据 ( 有效载荷 ): 最后也是最重要的字段, 这是数据报存在的首要理由, 大多数情况下, IP 数据报中的数据字段包含要交付给目的地的运输层报文段 (TCP / UDP) 然而 , 该数据字段也可以承载其他类型的数据, 如 ICMP 报文
3.2 IPv4 数据报分片
为什么需要分片?
网络是异构的,每种链路技术都有自己的最大传输单元( Maximum Transmission Unit , MTU),即一帧能承载的最大数据量(如以太网MTU通常是1500字节)。如果一个IP数据报的大小超过了某段链路的MTU,它就必须被“分片”,分成多个更小的IP数据报才能传+输。分片过程如何工作?(“三件套”的作用)
分片逻辑:
为了让目的主机执行这些重新组装任务, IPv4 的设计者将标识, 标志, 片偏移 字段放在了 IP数据报中的首部中. 当生成一个数据报时, 发送主机在为该数据报设置源和目的地址的同时贴上标识号.
发送主机通常将它发送的每个数据包加1 , 当某路由器需要对一个数据报分片时 , 形成的每个数据报 (即片) 具有初始数据报的源地址 , 目的地址, 标识号.
1. 标识 (Identification):源主机发送的每个原始数据报都有一个唯一ID。所有属于同一个原始数据报的分片,都拥有相同的ID。这是重组时识别“一家人”的唯一凭证。
2. 标志 (Flags):
DF (Don't Fragment):如果置1,则路由器禁止对此数据报分片。如果它超过MTU,路由器会丢弃它并发回一个ICMP差错报文。
ping -f命令就利用了此位。MF (More Fragments):除最后一个分片外,所有分片的MF位都置1。意思是“后面还有兄弟,别急着组装”。最后一个分片MF=0,表示“我是老幺,可以开始组装了”。
3. 片偏移 (Fragment Offset):指示当前分片的数据部分在原始数据报中的起始位置(以8字节为单位)。重组端依靠这个偏移量,像拼图一样把所有分片按正确顺序组装起来。
性能影响与现状:
分片和重组是一个非常消耗资源的操作(对路由器和小型设备而言)。现代网络设计通常尽量避免分片。做法是让端系统使用路径MTU发现技术,主动探测路径上的最小MTU,然后源主机就发送小于该MTU的数据包,从而从源头上避免分片。
3.3 IPv4 编址: 稀缺资源的精密规划
3.3.1 主机与路由器接入网络的方法:
- 主机与物理链路之间的边界叫做接口, 路由器与它任意一条链路之间的边界也叫做接口, 一台路由器因此有多个接口,每个接口都有其链路,
- 因为每台主机和路由器都需要接收和发送 IP 数据报, 所以IP 要求每台主机和路由器都要拥有自己的IP地址,-- 因此从技术上讲, 一个IP 地址与一个接口相关联, 而不是与包括该接口在内的主机或路由器相关联.
3.3.2 IPv4详解
- 1. IPv4规则与子网
- IPv4地址是一个32比特 (4个字节) 的数字,因此有大约 4 Billion 个. 通常用“点分十进制”表示(如
192.168.1.1)。- 例如: 考虑 IP 地址: 193.32.216.9 , 其中 193 是该地址的第一个 8 比特的十进制等价数 , 32 是该地址的第二个 8 比特的十进制等价数 以此类推: 他的二进制等价值数是: 11000001 00100000 11011000 00001001 ;
- 在全球因特网中的每台主机和每台路由器上的每个接口, 都必须有一个全球唯一的 IP 地址 (NAT 面的接口除外) 然而这些地址不能随意的自由选择. 一个接口的 IP 地址的一部分需要由其连接的子网决定
- 对于一个路由器和主机的通用互联系统, 我们能够使用下列有效方法定义系统中的子网:
- 为了确定子网, 分开主机和路由器的每个接口, 产生几个隔离的网络岛, 使用接口端接这些相互隔离的网络的端点. 这些隔离的网络中每一个都叫做子网.
- 图示: 3台路由器互联6个子网
- 其中的 6 个子网正如下图椭圆形彩色区域所示: 3个主机和路由器接口互联形成的子网- 223.1.1.0/24 ; 223.1.2.0/24 ; 223.1.3.0/24 还有 3个 路由器接口的互联子网- 223.1.9.0/24(R1-R2) ; 223.1.8.0/24(R2-R3) ; 223.1.7.0/24 (R3-R1)o
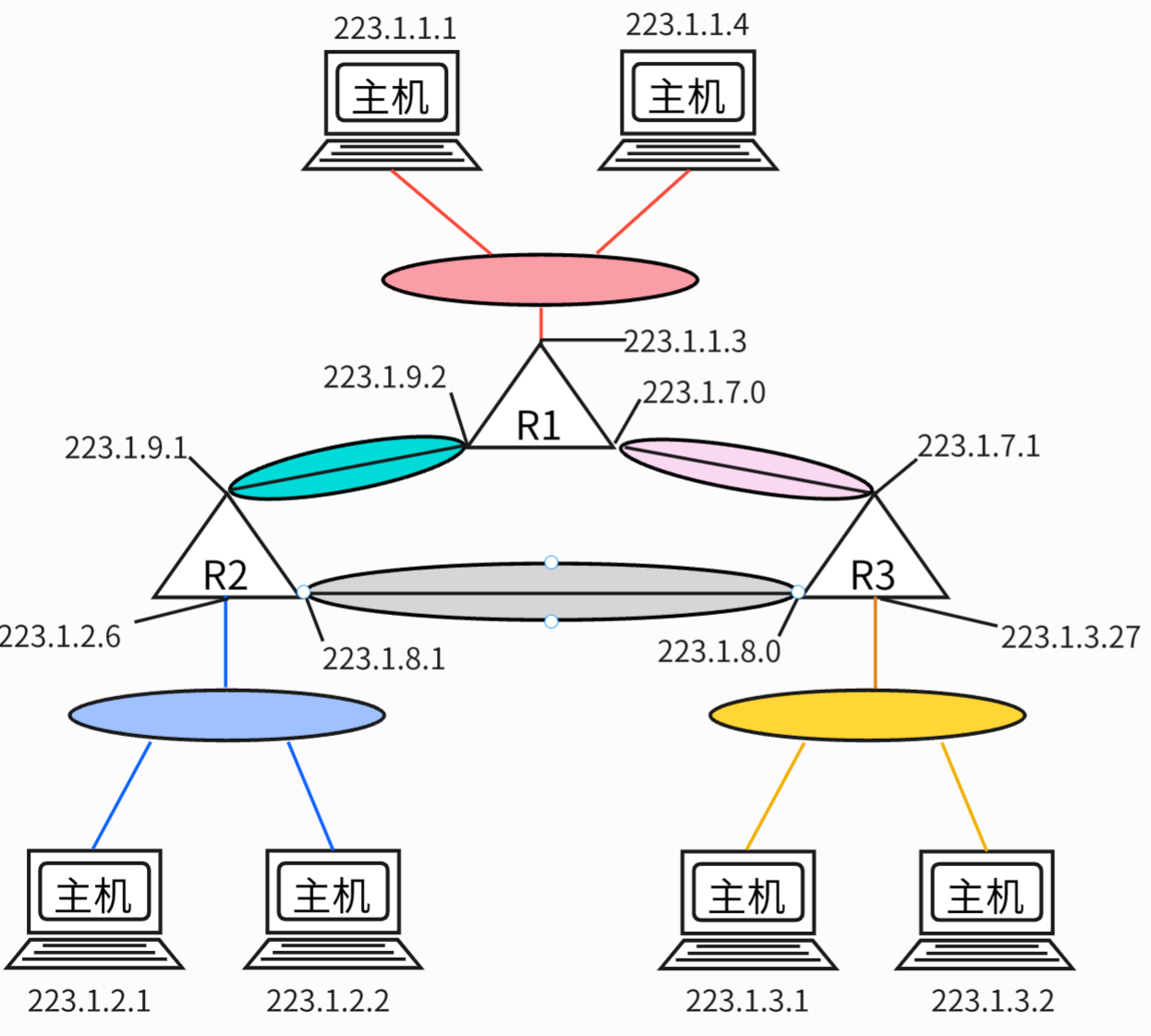
- IPv4地址是一个32比特 (4个字节) 的数字,因此有大约 4 Billion 个. 通常用“点分十进制”表示(如
2. 编址方案
分类编址 (Classful Addressing) - 已成历史
早期将IP地址空间划分为A、B、C、D、E五类。这种方式非常不灵活,导致地址大量浪费(一个B类网络拥有65534个主机地址,但很多中型机构根本用不完)。无类别域间路由 (Classless Interdomain Routing ,CIDR) - 现代方案
CIDR是拯救IPv4地址枯竭危机的最重要创新。它是什么:它抛弃了固定的A、B、C类网络划分,允许按需分配任意大小的地址块。
表示法:使用
网络前缀/前缀长度的表示法,如192.168.1.0/24。/24表示32比特中的前24位 (前三个字节) 是网络号 -- 子网地址,剩下的8位是主机号。一个组织通常被分配一块连续的地址, 即具有相同前缀的一块地址, 此时该组织内部的设备 IP 地址将共享共同的前缀 , 当该组织外部的一台路由器转发一个数据报, 且该数据报的目的地址位于该组织的内部时, 仅需要考虑该地址前面的 x 比特.
核心优势:
- 1. 节省地址:可以精确地为一个有500台主机的公司分配一个
/23的块(510个可用地址),而不是一个浪费了6万多个地址的B类网络。 - 2. 路由聚合:使用单个网络前缀通告多个网络的能力通常称为地址聚合 , 也叫路由聚合 . ISP可以从上级获取一个大的地址块(如
a.b.c.d/16),然后将其细分成更小的块(如a.b.0.0/20,a.b.16.0/20...)分配给客户。当它向外部网络通告路由时,只需要通告聚合后的大块a.b.c.d/16即可,极大地减少了全球路由表的规模。这是互联网能够持续扩张的关键。
- 1. 节省地址:可以精确地为一个有500台主机的公司分配一个
子网划分 (Subnetting):在一个大的CIDR地址块内部进一步划分出更小的网络。例如,公司将
192.168.1.0/24划分为192.168.1.0/25和192.168.1.128/25两个子网,分别给财务部和研发部使用,实现了广播隔离和安全管理。
- 1. IPv4规则与子网
3.3.3 一个设备得到地址块的具体过程
- 在学习了 IP 编址的逻辑之后, 我们需要知道主机或者子网是如何得到他们的地址块的? 我们现在看看一个组织是如何为其设备得到一个地址块的, 然后看看一台设备是如何从某组织的地址块中分配到一个地址的.
- 1. 获取一块地址
- 某网络管理员也许会与他的ISP联系, 该ISP可能会从已分给他的更大地址块中提供一些地址.比如该 ISP 也许自己被分配到了地址快 220.23.16.0/20 . 该 ISP 可以依次将该地址块分为8 个长度相同的连续地址块并为本ISP 支持的最多达8 个组织中的一个分配这些地址快中的一块.
- 如下图:

- 现在我们的设备已经有地址了, 那么ISP 的地址又从何而来呢?
- IP 地址实际上由因特网名字和编号分配机构 (Internet Corporation for Assigned Names and Numbers , ICANN) 管理 , 它不仅分配IP地址还管理 DNS 根服务器
- 2. 获取主机地址: 动态主机配置协议 -- DHCP
- a. 当组织获得一个地址块后, 他就可以为本组织内的主机与路由器接口逐个分配 IP 地址
- b. 系统管理员通常手动配置路由器中的IP地址, 而主机地址往往由动态主机配置协议 (Dynamic Host Configuration Protocol , DHCP) 来完成, DHCP 允许主机自动获取 (被分配) 一个IP地址 , 而网络管理员能够配置 DHCP 使得某给定主机每次于网络连接时能得到一个相同的 IP地址, 或者某主机将被分配一个临时的IP地址, 每次网络连接时该地址也许是不同的
- c. 除了主机 IP 地址的分配外 , DHCP 还允许一台主机得知其他信息, 例如他的子网掩码, 它的第一跳路由器地址(通常叫做默认网关)
- d. 由于 DHCP 具有将主机连接进一个网络的网络相关方面的自动能力, 故他又常被称为即插即用协议 或 零配置 (zeroconf) 协议. 如果没有他们网络管理员只能手动执行这些任务!
- e. DHCP 是一个客户 - 服务器 协议, 客户往往是新到达的主机, 它需要获得包括自身使用的 IP 地址在内的网络配置信息, 在最简单的场景下, 每个子网都有自己的 DHCP 服务器 , 但当该子网没有此服务器时, 则需要一个 DHCP 中继器, (通常是一台路由器) 它需要知道DHCP 服务器的地址
- 对于一台新到达的主机 DHCP 协议是一个四步骤的过程:
- 1. DHCP 服务器发现:
- 这个新到达的主机首要任务是发现一个要与之交互的DHCP 服务器, 这可以通过 DHCP 发现报文来完成, 客户在UDP 分组中向端口67 发送该发现报文, 此时 DHCP 客户生成包含DHCP 发现报文的 IP 数据报, 其中使用广播目的地址 255.255.255.255 并且使用"本主机" 源IP 地址0.0.0.0 ; DHCP 客户将该IP 数据报传递给链路层, 之后由其将该帧广播到所有该子网的节点 (#6.4节)
- 2. DHCP 服务器提供:
- 当DHCP 服务器收到一个 DHCP 发现报文时, 用DHCP 提供报文向客户做出响应, 该报文向该子网的所有节点广播, 仍然使用 IP 广播地址255.255.255.255 ; 因为在子网中可能存在几个DHCP 服务器, 该客户也许会发现他处于能在几个提供者之间进行选择的优越位置.
- 3. DHCP 请求 :
- 新到的客户从一个或多个服务器提供中选择一个, 并向选中的服务器提供用 DHCP 请求报文 进行响应, 回显配置参数
- 4. DHCP ACK :
- 服务器用 DHCP ACK报文 对 DHCP 请求报文进行响应, 证实所要求的参数
- 一旦客户收到 DHCP ACK 后 , 交互便完成啦! 客户能在租用期内使用DHCP 分配的 IP 地址.
3.4 网络地址转换 (NAT):公私地址的转换器
- NAT- (Network Address Translation)是另一个延缓IPv4地址枯竭的伟大发明。
核心思想:允许一个整体网络(如一个家庭或公司)只使用一个公有IP地址(全球唯一),而网络内部的所有设备使用私有IP地址(如
192.168.x.x,10.x.x.x,这些地址不能在公网上路由)。工作原理:
- 1. 一个用户用家庭网络主机 ( 10.0.0.1 ) 请求 IP 地址为 128.119.40.186 的某台Web 服务器 (端口 80) 上的一个Web 界面. 主机10.0.0.1为其指派了 (任意源端口号 3345) 并将其发送到 LAN 中.
- 2. NAT路由器(如你家光猫)收到这个数据报,并执行一个关键操作:为数据报生成一个新的源端口号 (5001) , 将源 IP 替代为其广域网中的一侧接口的 IP 地址 138.76.29.7 , 并且将源端口号: (3345) 转换为新端口号: (5001) , 此时 NAT 路由器可选择任意一个当前未在 NAT 转换表中的源端口号, 路由器中的NAT 也在它的 NAT 转换表中增加一表项.
- 3. 由于 Web 服务器并不知道刚才到达的包含 HTTP 请求的数据报已被 NAT 路由器 进行了改装, 因此它会返回一个响应报文 , 其目的地址是 NAT 路由器的 IP 地址, 其目的端口是 (5001) .
- 4. 当该报文到达NAT 路由器时,路由器使用目的 IP 地址与目的端口号从 NAT 转换表中检索出家庭网络浏览器使用的适当 IP 地址和 目的端口号, 于是路由器重写该数据报的目的 IP 地址与目的端口号, 并向家庭网络转发该数据报.
争议与思考:
优点:极大地节省了公有IP地址,提供了天然的防火墙效果(外部无法主动发起连接到NAT后的设备)。
缺点:破坏了端到端通信的原则,增加了网络的复杂性。某些对等连接(P2P)应用需要复杂的打洞技术才能穿透NAT。它本质上是一种“打补丁”的解决方案,IPv6才是根治地址短缺的终极答案。
有人认为: 端口号是用来进程寻址的, 而非主机寻址, 这种违法的用法确实会产生问题, 服务器进程在周知的端口号上等待入请求, 并且 P2P 协议中对等方在充当服务器时需要接受入连接 . 对于这些问题的解决包括: NAT 穿越工具 和 通用即插即用 (Universal Plug and Play - UPnP).
3.5 IPv6
- IPv6的设计初衷就是为了解决IPv4的地址枯竭和其他固有缺陷.
3.5.1 IPv6 数据报格式
- 1. IPv6 数据报格式:
- 图示:
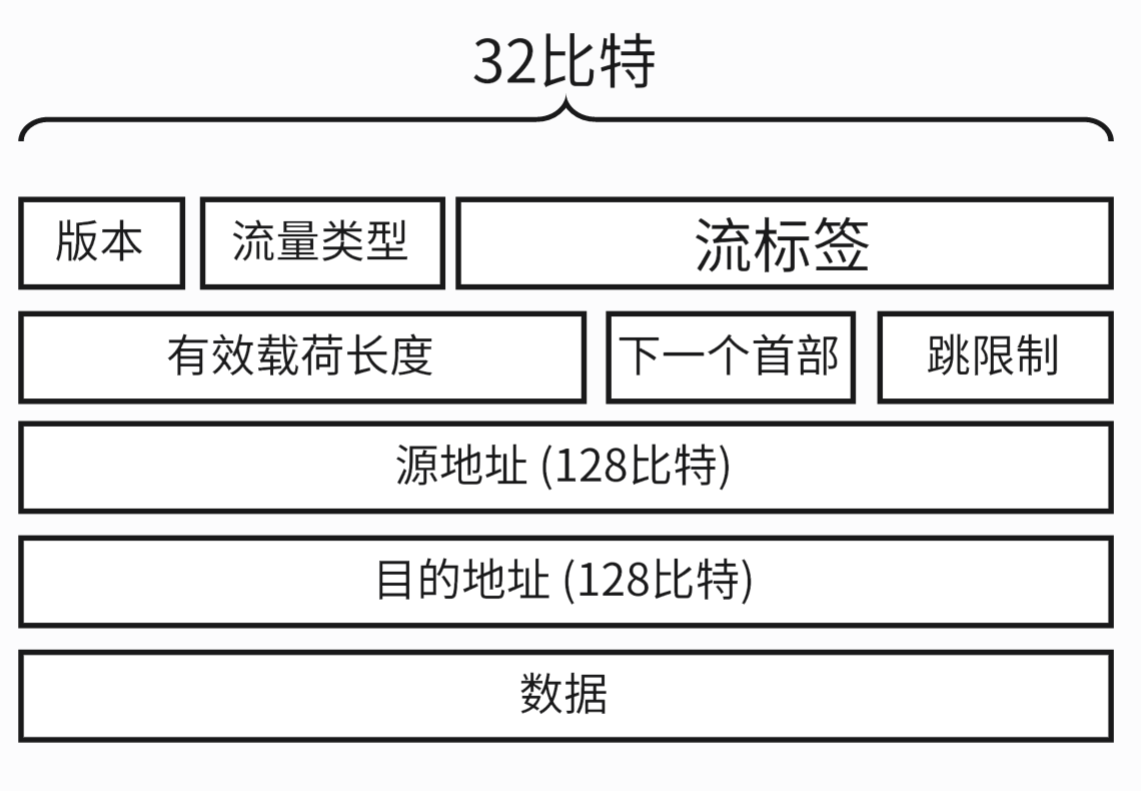
- 字段详解:
- a. 版本
- 4比特字段用于标识 IP 版本号 , IPv6 将其设置为 6.
- b. 流量类型
- 该 8比特字段与我们在 IPv4中的 TOS 字段的含义类似
- c. 流标签
- 该 20 比特的字段用于标识一条数据报的流, 能够对一条流中的某些数据报给出优先权, 或者对来自某些其他应用的数据报给出更高优先权
- d. 有效载荷长度
- 该 16 比特值作为一个无符号整数, 给出了IPv6 数据报中跟在定长的 40 字节数据报首部后面的字节数量
- e. 下一个首部
- 该字段标识数据报中的内容需要交付给哪个协议(如TCP/ UDP)
- f. 跳限制
- 转发数据报的每台路由器将该字段的内容减1 , 如果跳限制的值变为0 , 则该数据报将被丢弃
- g. 源地址和目的地址
- IPv6 128 比特地址的各种形式详见 RFC4291
- h. 数据
- IPv6 数据报的核心有效载荷部分, 当数据报到达目的地时, 该有效载荷就从IP 数据报中移除 并交给在下一个首部字段中指定的协议出处理
- a. 版本
- 消失的部分:
- a. 分片 / 重组
- IPv6 不允许再中间路由器上进行分片和重组, 这种操作只能在源和目的地执行, 如果路由器收到的 IPv6 数据报因太大而不能转发到出链路上, 路由器只需要将该数据报丢掉即可, 并向发送方回复一个"分组太大" 的 ICMP 差错报文即可
- b. 首部检验和
- 由于IPv4 首部中包含有一个 TTL 字段(类似于IPv6中的跳限制字段) 因此在每台路由器上还要重新计算IPv4首部检验和, 而这违反了IPv6 发明者的初衷.
- c. 选项
- 选项字段不再是标准IP首部的一部分了, 但他并没有消失, 而是可能出现在IPv6首部中由"下一个首部"指出的地方.
- a. 分片 / 重组
- 核心变化:
- a. 扩大的地址容量
- IPv6 将 IP 地址长度从32比特增加到128比特, 现在 地球上每一颗沙子都能被分配一个 IP 地址, 同时 IPv6 引入了一种称为 任播地址(anycast address) 的新型地址, 它可以将数据报交付给一组主机中的任意一个
- b. 简化高效的 40 字节首部
- IPv6 形成的 40 字节定长首部允许路由器更快的处理 IP 数据报
- c. 流标签
- RFC 2460 中描述道: 该字段可以用于"给属于特殊流的分组加上标签, 这些特殊的流是发送方要求进行特殊处理的流, 如一种非默认服务质量或需要实时服务的流", 比如音频和视频传输或者由高权限用户承载的流量就有可能被当做一个流. 流的确切含义尚未确定
- a. 扩大的地址容量
- 特性:
- 巨量的地址空间:128位地址,地址数量多到“可以为地球上的每一粒沙子分配一个IP地址”。彻底解决了地址短缺问题。
简化的固定报头:IPv6报头固定为40字节,去除了IPv4中许多不常用的字段(如首部校验和、分片相关字段),大大加快了路由器的处理速度。
不再需要分片:IPv6规定路径MTU发现是强制性的,分片工作由源主机完成,路由器不再负责分片,减轻了路由器的负担。
原生安全性和QoS支持:IPsec(提供加密和认证)原本是IPv6的强制组成部分,虽然现在IPv4也常用,但体现了其设计理念。流标签字段为处理实时流量提供了更好的QoS支持。
地址表示法:8组4位十六进制数,用冒号分隔,如
2001:0db8:85a3:0000:0000:8a2e:0370:7334。可以通过规则压缩连续为零的组(::)。过渡技术:由于IPv4和IPv6网络将长期共存,出现了多种过渡技术,如双栈(设备同时运行IPv4和IPv6)、隧道(将IPv6包封装在IPv4包中穿越IPv4网络)、翻译(在IPv4和IPv6网络之间进行协议转换)。
- 1. IPv6 数据报格式:
3.5.2 从 IPv4 到 IPv6 的迁移
- 已经得到广泛采用的 IPv4 到 IPv6 迁移的方法包括建隧道, 具体步骤如下:
- 1. 假定两个 IPv6 节点要使用 IPv6 数据报进行交互, 但他们是经由中间的 IPv4 路由器进行互联的, 我们将两台 IPv6 路由器之间的中间 IPv4 路由器的集合称为一个隧道,
- 2. 借助于该隧道, 在隧道发送端的 IPv6 节点 可将整个 IPv6 数据报放到一个 IPv4 数据报的数据 (有效载荷) 字段中, 则该IPv4 数据报的地址设为指向隧道接收端的 IPv6节点, 再发送给隧道中的第一个节点.
- 3. 隧道中间的 IPv4 路由器在他们之间为该数据报提供路由, 正如对待其他正常的数据包一样
- 4. 隧道接收端的 IPv6 节点最终收到该 IPv4 数据报, 并确认该数据包中含有一个 IPv6 数据报 (通过观察在IPv4 中的协议号字段是 41 指示其有效载荷是一个IPv6 数据报) , 从中取出 IPv6 数据报, 然后为该数据报提供路由.(仿佛它好像是从一个直接相连的IPv6 邻居那里接收到了IPv6 数据报一样).
- 已经得到广泛采用的 IPv4 到 IPv6 迁移的方法包括建隧道, 具体步骤如下:
4. 通用转发和 SDN
SDN(软件定义网络)的核心思想是控制平面与数据平面分离。控制逻辑被上移到中心化的控制器(Controller),而网络设备(如交换机)则变得简单、通用,只负责根据既定规则高速转发数据。
OpenFlow规定了控制器和交换机之间通信的标准,特别是规定了交换机内部的流表(Flow Table)的结构和行为。一台支持OpenFlow的交换机,其核心就是一个或多个流表 (Flow Table)。每个流表本质上都是一个“匹配-动作”规则的集合。数据处理流程如下:
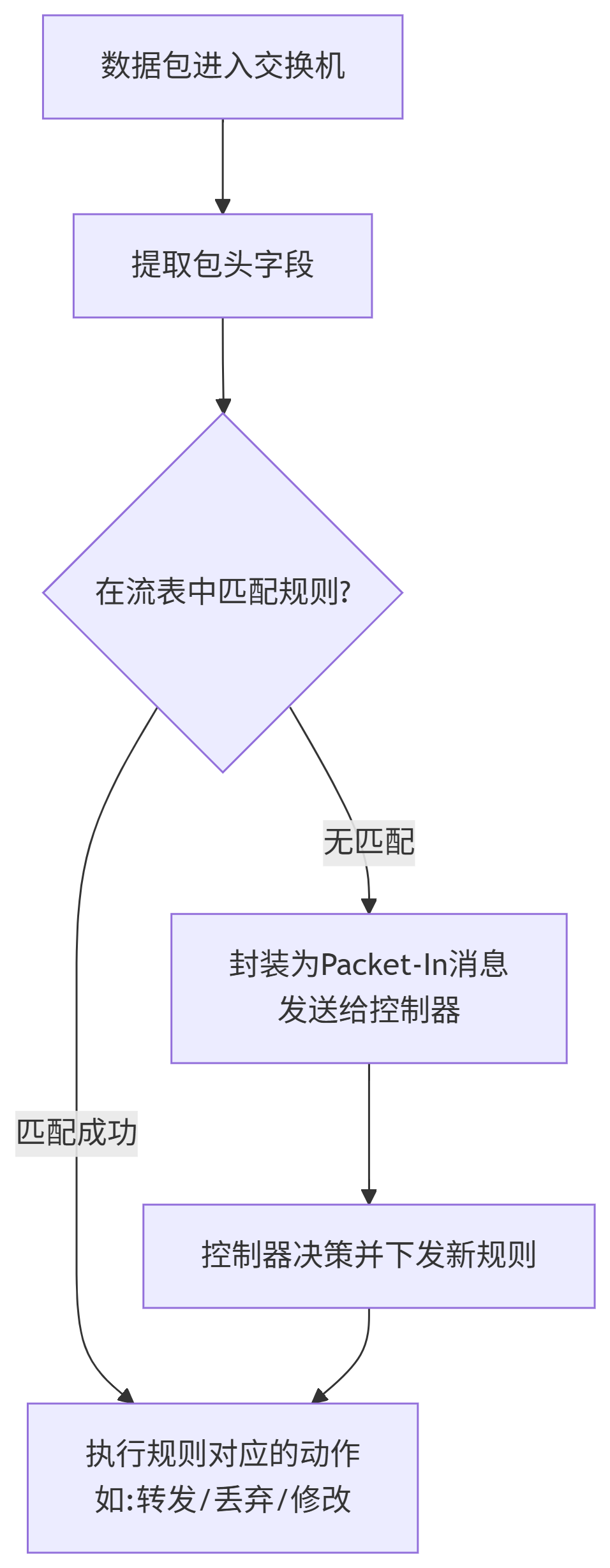
流表 (Flow Table) 的每个表项:
a. 首部字段值的集合
与基于目的地转发一样, 基于硬件匹配在 TCAM 内存中执行得最为迅速 , 匹配不上流表项的分组将被丢弃或者发送到远程控制器做更多处理.
b. 计数器集合
当分组与流表项匹配时更新计数器 , 这些计数器可以包括已经与该表项匹配的分组数量, 以及自从该表项上次更新以来的时间.
c. 动作集合
指当分组匹配流表项时采取的动作集合, 他们可能将分组转发到给定的输出端口, 丢弃 , 复制该分组和将他们发送到多个输出端口, 和 / 或重写所选的首部字段.
4.1 匹配 (Matching)
- “匹配”的过程就像是查字典或查地址簿。交换机接收到一个数据包后,会解析并提取其包头中的多个字段,然后用这些字段作为“键”,去流表中逐条比对规则。
- 在 "匹配加动作" 新范式中, 其中能够对协议栈的多个首部字段进行 "匹配", 而这些首部字段是与不同层次的不同协议相关联的.
- 1. 匹配字段 (Match Fields):
OpenFlow协议涵盖了网络二、三、四层甚至更高层的标识符。OpenFlow 1.0 流表的分组匹配字段包括:a. 入端口 (Ingress Port): 分组交换机上接收分组的输入端口.
b. 链路层 (第二层) 字段:
源/目的MAC地址 (Ethernet Src/Dst)
以太网类型 (EtherType): 如0x0800代表IPv4, 0x86DD代表IPv6。
VLAN ID / VLAN优先级
c. 网络层 (第三层) 字段:
源/目的IP地址 (IPv4/v6 Src/Dst): 支持子网掩码匹配(通配符)。
IP协议号 (IP Protocol): 如1代表ICMP,6代表TCP,17代表UDP。
d. 运输层 (第四层) 字段:
TCP/UDP源/目的端口 (TCP/UDP Src/Dst Port)
e. 其他字段: 如MPLS标签、ARP字段等。
2. 匹配方式:
精确匹配: 必须所有字段都完全一致。
通配符匹配: 使用掩码(wildcards),可以只匹配IP地址的前缀(即一个网段),或者忽略某些字段。这提供了巨大的灵活性,是实现聚合流、减少流表规模的关键。
示例: 一条匹配规则可以定义为:
{Ingress_Port=3, Ethernet_Src=00:1A:2B:3C:4D:5E, Ethernet_Type=0x0800, IP_Proto=6, TCP_Dst=80}这条规则匹配的是:从端口3进入、源MAC为00:1A...、IP协议为TCP、且目标端口是80(HTTP) 的所有数据包。
4.2 动作
- "动作"能够包括: 将分组转发到一个或多个输出端口 (就像在基于目的地转发一样) , 跨越多个通向服务的离开接口进行负载均衡分组 (就像在负载均衡中一样), 重写首部值 (就像在 NAT 中一样) , 有意识地阻挡 / 丢弃某个分组 (就像在防火墙中一样), 等等.
- “动作”定义了当数据包与某条流表项匹配成功后,交换机应该对它做什么。一条规则可以对应零个、一个或多个动作。
- 动作主要分为以下几类:
1. 转发类 (Forwarding Actions):
OUTPUT: [端口号]: 将数据包从指定的物理端口转发出去。这是最核心的动作。ALL: 转发到所有端口(类似洪泛,慎用)。CONTROLLER: 将数据包封装成Packet-In消息发送给控制器。常用于第一个未知数据包的处理。LOCAL: 转发给交换机本地的控制管理平面(例如操作系统网络栈)。IN_PORT: 从接收它的端口再发回去。
2. 丢弃 (Drop):
如果一个数据包匹配了一条没有指定任何动作的流表项,它会被默认丢弃。你也可以显式地指定
DROP动作。
3. 修改类 (Modification Actions - 也称为封装/解封装):
在分组被转发到所选的输出端口之前, 分组首部10 个字段( 即上文 : 4.1 匹配字段中除 IP 协议字段外的所有第二, 三, 四层的字段 ) 中的值可以被重写.
4.3 匹配加动作操作中的 OpenFlow
- “匹配+动作”就构成了流表中最基本的单元——流表项 (Flow Entry)。每条流表项通常包含以下部分:
1. 匹配字段 (Match Fields): 定义匹配规则。
2. 优先级 (Priority): 当数据包匹配多条规则时,优先级高的规则先被执行。
3. 计数器 (Counters): 记录匹配该规则的数据包数量、字节数等统计信息。
4. 指令 (Instructions): 匹配成功后要执行的动作或一系列操作。指令可能不仅仅是立即执行动作,还可能包括:
APPLY-ACTIONS: 立即执行指定的动作列表。WRITE-ACTIONS: 将动作集合写入到一个“动作集(Action Set)”中,该动作集稍后(在所有流表处理完毕后)统一执行。GOTO-TABLE: 跳转到下一个指定编号的流表继续处理。这实现了多级流表流水线,允许将匹配过程分阶段进行,提高效率和灵活性。
5. 超时时间 (Timeouts): 空闲超时(Idle Timeout)和硬超时(Hard Timeout),用于控制器管理流表的生命周期。
6. Cookie: 控制器用来标识该流表项的元数据,交换机自身不使用。
工作流程示例(简化版):
1. 一个
TCP SYN包进入交换机的端口1。2. 交换机提取包头字段:
{in_port=1, eth_type=0x0800, ip_proto=6, tcp_dst=80}。3. 它在流表中查找,发现匹配了这样一条高优先级规则:
匹配:
{in_port=1, tcp_dst=80}动作:
OUTPUT: 4(从端口4转发出去)
4. 交换机执行动作,将该数据包从端口4转发出去,并更新这条流表项的计数器。
如果没有任何流表项匹配呢?
这正是SDN的妙处。交换机会将这个“未知”的数据包封装成一个 Packet-In 消息发送给控制器。控制器上的应用程序(如路由算法、防火墙策略)会根据全局网络视图做出决策(“这个包该去哪?”),然后通过 Flow-Mod 消息向交换机下发一条新的流表项。后续所有相同的流量就可以直接在交换机上被快速处理了,而无需再惊动控制器。这就是“首包慢路径,后续包快路径”的工作机制。总结:
OpenFlow通过“匹配+动作”的抽象,将网络设备从固定的硬件功能中解放出来,变成了可编程的通用转发设备。匹配提供了精细识别流量的能力,动作定义了丰富的处理手段,而两者结合构成的流表,则通过网络操作系统(控制器)的集中控制,实现了前所未有的网络灵活性和可编程性。这正是SDN革命的核心所在。
- “匹配+动作”就构成了流表中最基本的单元——流表项 (Flow Entry)。每条流表项通常包含以下部分:
本章小结:
在本章中, 我们详细的讨论了网络层 -- 数据平面(data plane) 功能 , 即每台路由器的如下功能: 决定到达输出链路之一的分组如何转发到该路由器的输出链路之一.
我们重点关注了:
路由器的内部操作 , 输入及输出端口功能
基于目的地的转发 , 路由器的内部交换机制 , 分组排队管理机制等
系统性的分析了 IPv4 , IPv6 协议以及因特网编址
传统 IP 转发(基于数据报的目的地址进行) 和通用转发 (其中转发和其他功能可以使用数据报首部中的几个不同的字段值来进行)