大模型的超大激活值研究
说明现象的论文:Massive Activations in Large Language Models
解释原因的论文:Quantizable Transformers: Removing Outliers by Helping Attention Heads Do Nothing
一、大模型存在超大激活值
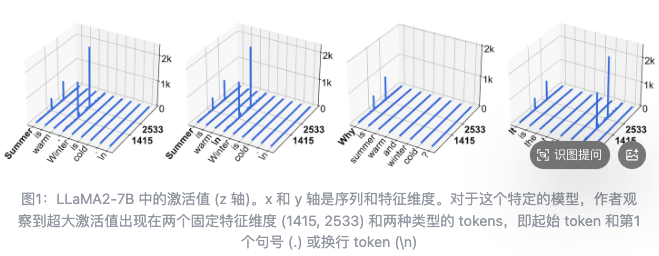
从特征维度和 token 来看,它们固定在很少的几个特征维度上,和输入内容没关系。
位置上主要分三类:
有的只在序列开头的 token(比如 LLaMA2-13B);
有的在开头 token 和第一个句号、换行符这些分隔符 token 上(比如 LLaMA2-7B);
还有的除了开头和分隔符,还在 “and”“of” 这类语义简单的词上(比如 Mixtral-8x7B)。
超大激活值的作用
超大激活值是 LLM 中固定但重要的偏置项。
缺了不行,必须要有。

二、超大激活值产生的原因
论文发现这些激活值和注意力头试图不更新隐藏状态的行为有关。为了实现完全的零更新,输入到softmax的值需要变得越来越大,这导致了网络其他部分的异常值。
提出的解决方法:

🌟 核心概念回顾
- 隐藏状态(Hidden State):在Transformer的每一层中,输入经过自注意力和前馈网络后,会更新一个隐藏表示(即 token 的向量表征)。
- 残差连接 + LayerNorm:Transformer 的标准结构是:
输出 = LayerNorm(输入 + 自注意力输出)然后再接LayerNorm(上一步结果 + 前馈网络输出)→ 所以,如果自注意力或前馈网络的输出是
0,那么隐藏状态就完全不被更新。
🔍 论文的核心发现:为什么会出现“大规模激活”?
✅ 1. 模型“希望”某些token的隐藏状态保持不变
- 在长序列中,有些token(比如句首的“[CLS]”、标点、或重复词)可能对当前语义贡献很小。
- 模型学习到:“不更新这些token的隐藏状态”能提升性能(例如减少噪声、稳定表示、节省计算资源)。
- 这是一种隐式优化目标——不是显式编程的,而是通过训练自动学到的策略。
✅ 2. 如何让隐藏状态“不更新”?
- 在残差结构中,要让隐藏状态不变,必须让自注意力模块的输出 ≈ 0。
- 但自注意力模块的输出是由 softmax(QK^T) * V 得到的。
- 要让 softmax 输出趋近于零向量(即所有位置权重都接近0),唯一办法是:
让 QK^T 中的所有值变得非常小(负无穷大)
→ 但这里有个矛盾:如果所有 QK^T 都很小,那 softmax 就会输出均匀分布(≈ 1/n),而不是零!
✅ 3. 所以模型找到了一个“取巧”的方式 —— 让某个位置的 QK^T 变得极大正数!
- 假设我们想让第 i 个 token 的隐藏状态不被其他 token 影响(即它自己不更新)。
- 那么,模型会让:
- 对于第 i 个 token 的 query:Q_i 与所有 K_j 的点积 Q_i · K_j → -∞(除了 j=i)
- 但对于 j=i(自己):Q_i · K_i → +∞(极大正值)
- 这样,softmax(QK^T) 会变成:
softmax([ -∞, -∞, ..., +∞, -∞, ... ]) ≈ [0, 0, ..., 1, 0, ...]- 即:注意力权重完全集中在自己身上(self-attention)。
- 那么自注意力输出 = 1 × V_i = V_i
- 最终残差连接:
hidden_state_new = LayerNorm(hidden_state_old + V_i)- 如果 V_i ≈ hidden_state_old,那么
hidden_state_new ≈ hidden_state_old→ 几乎没更新!✅ 4. 但 V_i 是由前面的线性变换生成的 → 它不可能天然等于 hidden_state_old
- 所以模型只能强迫 V_i 极大(通过放大权重或激活值),使得:
V_i的幅值远超原始 hidden_state_old- 从而即使加上去,经过 LayerNorm 后,也能“压住”原始值,实现“伪不变”
→ 这就是为什么会出现 “大规模激活”:为了制造一个巨大的 V_i,必须在前馈网络或注意力计算中产生极端大的中间激活值(比如 10⁵
倍于正常值)。
⚠️ 结果:网络中出现异常值(outliers)
- 这些“大规模激活”是系统性的、非随机的,它们是模型为达成“零更新”目标而主动构建的数学机制。
- 它们导致:
- 注意力概率高度集中(几乎100% attention on one token)
- 前馈网络中的神经元输出出现极端值(如 1000 vs 正常 0.01)
- 数值不稳定风险(浮点溢出、精度损失)
- 模型行为变得“脆弱”——轻微扰动可能导致注意力崩溃
💡 类比:就像你想让一辆车停住,但刹车失灵了,于是你选择把油门踩到底再猛踩刹车——虽然车停了,但引擎快烧了。
✅ 总结一句话:
“大规模激活”是模型为实现“隐藏状态零更新”这一高效策略,被迫在数值上制造极端异常值的结果。这种策略虽然有效,却牺牲了数值稳定性,暴露了Transformer架构在优化目标与数值实现之间的深层矛盾。
参考:
https://zhuanlan.zhihu.com/p/689959264
https://papers.cool/arxiv/search?highlight=1&query=Quantizable+Transformers+Removing+Outliers+by+Helping+Attention+Heads+Do+Nothing