WALL-OSS--自变量机器人--2025.9.8--开源
0. 前言

项目页
github
1. 背景与相关技术
1.1 提出问题
尽管 foundation models 在语言和视觉上取得了显著进展,现有的视觉–语言模型(VLMs)在空间感知和具身(embodiment)理解方面仍然有限。
LLM 的进展轨迹现在在 VLM(视觉语言模型)中得到了映射:像 Gemini 2.5(28)和 GPT-5(56)这样的强大全能模型能够联合处理文本与视觉流,同时在多模态领域保持有意图的推理能力与较低的错误率。
然而,这些系统在很大程度上仍是“非具身的”(disembodied):它们既不会通过与物理世界交互的反馈来自我改进,也不会直接生成可执行的动作。因此,在具身领域,动作理解与生成仍然是通往 AGI 路上的核心瓶颈。
将 VLMs 转移到具身(embodied)领域会暴露出模态之间、预训练分布(pretraining distributions)以及训练目标之间的根本性不匹配,从而使得动作的理解与生成成为通往 AGI 的关键瓶颈。
这一现状促使研究者把强大的 VLM 骨干网迁移到动作空间,例如 OpenVLA(39)和 π0(14),这些模型在学习跨模态对应关系的同时对连续动作进行建模,试图将视觉与语言先验(VL priors)迁移到动作空间。
一种简单粗暴的微调策略——在预训练的 VLM 上接一个动作头并用机器人轨迹监督它——经常导致严重的权重漂移(weight drift),从而侵蚀原有的视觉—语言先验。
“知识隔离”(knowledge insulation)策略通过尽量减少对 VLM 参数的扰动来保留预训练能力;但松耦合的架构设计限制了语义与控制之间的紧密绑定,而且由于 VLM 本身在具身场景中也存在不足,当执行超出视觉—语言先验的动作时表现不佳。
总体而言,使用当前 VLM 学习动作面临三大根本性差距:
模态与数据规模差距
得益于计算机视觉的长期发展,视觉编码器能提取过滤高频噪声同时保留高层语义的特征;这些被压缩的视觉 token,连同已高度压缩的文本模态,在大规模网页图像/视频与文本对上训练后(如 CLIP 及相关多模态模型),使得两者的对齐成为可能。
相比之下,具身空间中的动作是对三维空间和时间的连续信号;与视觉模态相比,动作的特征提取缺乏长期的表征研究,并且其与文本的高层语义对齐也缺乏大规模数据的驱动。
此外,在具身场景中,多个子任务与具体场景级的动作描述常被抽象为单条高层指令,这进一步增加了跨模态关联的难度。
基于流水线的 agent(先用 LLM 分解指令,再调用技能库(6,44))受限于不可微接口与误差累积问题,从而在长时序任务上的成功率下降。另外,一些方法(如 3D-VLA(79)与 PointVLA(41))尝试使用 3D 视觉模态作为 2D 视觉与动作之间的桥梁,但 3D 数据同样难以获取,且现有的 3D 视觉基础模型(如 VGGT(69)和 π3(72))在精细动作预测所需的精度上仍不够。
预训练分布差距
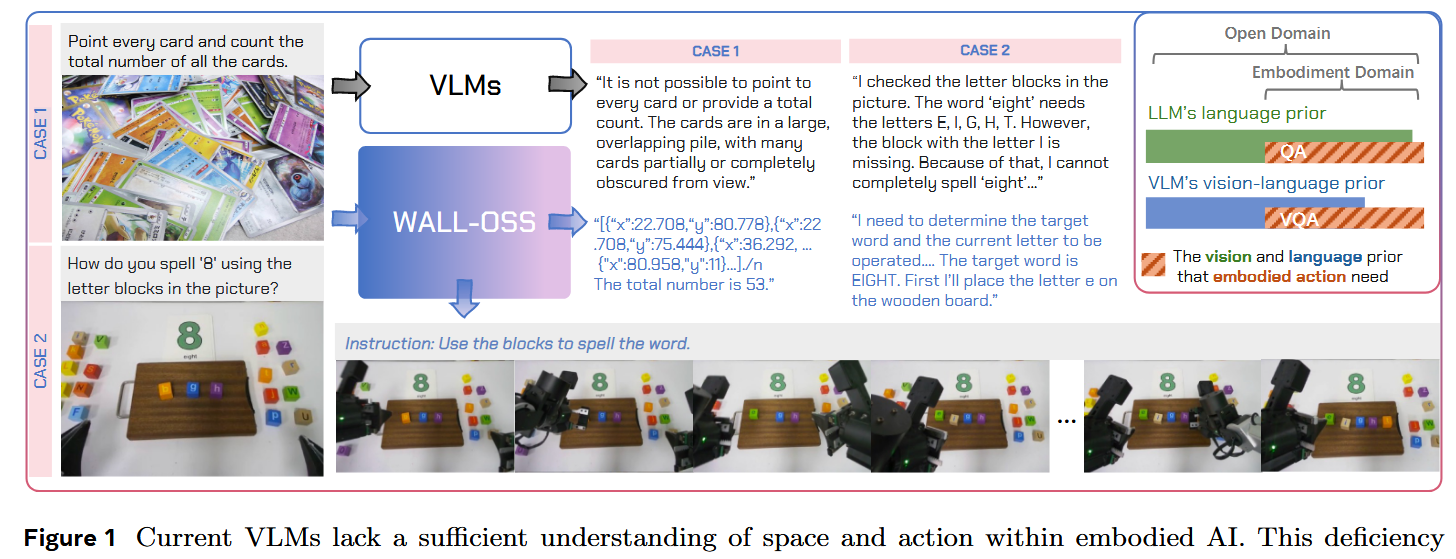
如图 1 所示,经过大规模预训练后,LLM 在文本模态中在很大程度上覆盖了具身语义的需求(例如能做问答)。但对视觉模态而言,具身数据通常包含第一人称视角、鱼眼镜头与自遮挡,这些与互联网图像有显著差异。
即便在大规模预训练后,VLM 在满足具身场景需求(例如具身 VQA)方面仍然困难,先前分析报告也指出其在空间推理、具身场景理解和进度跟踪方面存在不足(36,70)。
训练目标差距
LLM/VLM 通常采用对离散序列做下一 token 的最大似然作为训练目标,而动作轨迹是连续的、高频的信号,更自然地用条件生成目标来建模,例如扩散(diffusion)(32,22)或流匹配(flow matching)(46),这些方法学习将基分布变换到动作分布的 score/速度场。
然而,直接把这些生成目标嫁接到 VLM 上会放大“token 化差距”(tokenization gulf)和独立性假设,从而导致灾难性退化,削弱语言—动作的对齐与泛化能力。这与在当前图像/视频领域里尝试统一“生成”与“理解”时遇到的挑战相呼应。
一些方法(例如 π0)尝试在自回归范式下把动作在高层离散化,以把动作 token 与文本 token 对齐,然后通过让扩散/流匹配的动作噪声和中间的 VLM 表示通过自注意力交互,来生成连续的动作信号(14)。
然而,这类松耦合的设计仍然无法学到紧密的文本—动作绑定,导致对指令的执行不充分或不准确。
1.2 解决问题
为解决问题提出了 WALL-OSS —— 一个端到端的具身 foundation model,利用大规模多模态预训练来实现
- 具身感知的视觉–语言理解
- 强健的语言—动作关联
- 可靠的操纵能力。
作者的方法采用一个紧耦合的MoE架构和多策略训练课程(curriculum):在不同阶段以不同的动作建模方法(离散或连续)激活不同的专家并调整权重,从而弥合训练目标差距。
从而实现 Unified CrossLevel CoT——在一个可微分框架内无缝地统一指令推理(instruction reasoning)、子目标分解(subgoal decomposition)和细粒度动作合成(fine-grained action synthesis)。
把多模态任务与面向具身的 VQA 任务及其相应数据集(针对空间定位与进度建模)相结合,以修补 VLM 在具身场景中的不足;同时将离散化的动作先验植入 VLM 的输出空间以提供粗粒度的动作监督,从而弥合 VLM 预训练分布差距。
在这些设计基础上,作者建模了统一的 CoT(Chain-of-Thought)前向映射,使模型能够把任务从高层语义分解到细粒度动作,迫使模型理解链中每个层级之间的关系,从而弥合模态差距。
他们的核心贡献在于建立了一个将 VLM 扩展到具身智能(embodied intelligence)的原则性框架。
在方法学上,展示了如何通过架构耦合与课程化训练(curriculum design)系统地解决非具身预训练与具身领域之间的根本性不匹配。
结果表明 WALL-OSS 在复杂的长时程(long-horizon)操作任务上取得了高成功率,展示了强大的指令执行能力、复杂的理解与推理能力,并且优于强基线,从而为从 VLMs 向具身 foundation models 的可靠且可扩展路径提供了支持。
更广义地说,作者的工作验证了一种可扩展范式,用以弥合语义—感觉运动(semantic–sensorimotor)鸿沟,并对通用具身 AI 系统提供了理论洞见与实用进展。
鉴于当前具身通用基础模型的稀缺,他们还开源了完整的训练代码与模型检查点,以促进可重复研究与社区在这一新兴领域的发展。
1.3 相关工作
语言、视觉与操控方向的基础模型
网络规模的预训练推动了 LLM 与 VLM 在多模态推理与落地(grounding)能力上的进展(例如 Gemini 2.5、Claude 3.7、DeepSeek-R1、Llama 3/4、Qwen 2.5;GPT-4o、Qwen2.5-VL,以及 InternVL 系列等)。
在这些先验的基础上,VLA 基线方法通过把动作编码为 token 或训练连续输出头,将 VLM 与机器人控制对齐;方法包含连续模型(如扩散、flow-matching,例如 DP、Octo、π0、π0.5)以及通过压缩的离散化(例如 ACT、OpenVLA、FAST、RT-2)。
作者方案遵循“离散先验 → 连续控制”的思路:先把离散动作先验植入 VLM 的输出空间(Inspiration),再为高频动作优化一个 flow-matching 的头(Integration),同时用一个带静态路由的紧耦合 MoE 强制实现牢靠的语言—动作绑定。
与机器人数据的多模态联合训练
为弥补机器人轨迹在代价与覆盖上的限制,跨源多模态联合训练被证明是有效的。从 VLM 初始化,并将网络图像—文本、对话和长视频与多主体(multi-embodiment)机器人数据一起联合训练,可以在保持开放世界语义—视觉能力的同时注入具身的空间语义。
跨机体(cross-embodiment)与跨环境的聚合进一步提升了迁移能力。作者的方法强调用统一格式的具身认知监督来连接指令、推理、子任务与连续动作;通过两阶段的分布混合与配额对开源动作数据进行系统性整合以限制漂移;并采用带静态路由的紧耦合 MoE,将异构监督转化为可控的动作通道增益,从而提高在陌生场景与不同机体间的鲁棒性。
语言推理与子任务分解
对于长时序任务,把高层推理与低层控制结合起来能提高成功率。
与把 VLM 规划器与独立控制器拼接的流水线式设计不同(例如 SayCan、Code-as-Policies,以及层次化变体如 Hi Robot、GR00T N1),作者采用单模型的 Uni-CoT 形式,学习从指令到 Chain-of-Thought(CoT)、子任务与连续动作的端到端映射。
这与层次化和动作语法(action-grammar)方法(例如 RT-H)、近来的用于控制的 CoT 方法与提示式框架、以及用于动作的指令微调和层次化目标条件策略相互补充。模型可以选择包含或跳过中间步骤,并在推理与执行间交替进行(interleave reasoning with execution)。
结合作者的两阶段课程化训练与紧耦合路由,这种统一设计减少了由接口引起的误差累积,并增强了对进度的感知和对指令的遵循性,尤其在复杂的长时序操作任务中。
2. WALL-OSS
本节介绍 WALL-OSS 的整体架构与训练方法。作者的目标是构建一个基于 Transformer 的具身领域基础模型,既能增强 VLM 在具身场景中的空间理解,又能实现高质量的动作生成。
2.1 模型架构
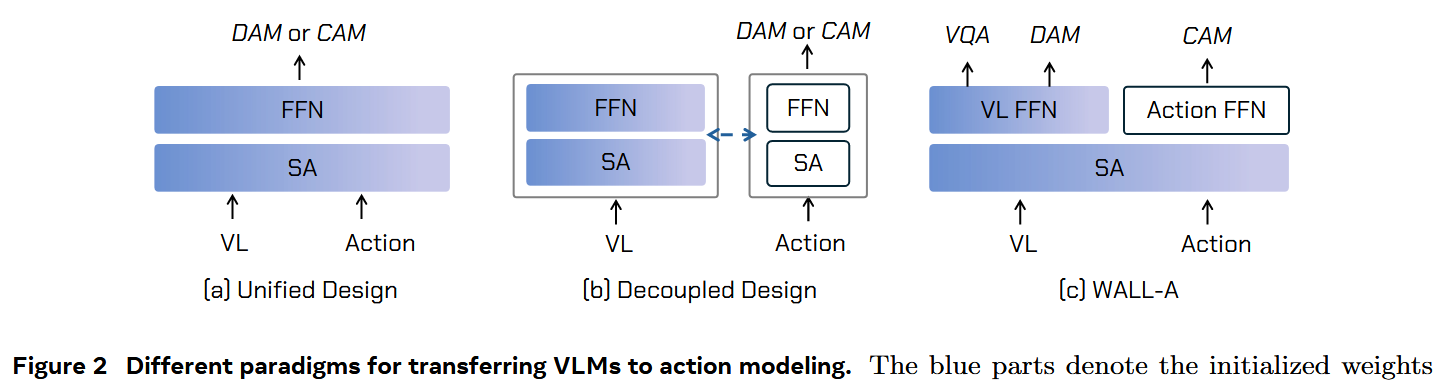
图 2(a) 与 2(b) 展示了现有 VLA 模型的结构范式。SA是指self-attention。
在 (a) 中,混合式设计直接扩展原始 VLM 来建模动作,采用 Discrete Action Modeling(DAM)或 Continuous Action Modeling(CAM),沿用下一个 token 预测范式,RT-2 与 OpenVLA 是此类范例。
然而,对动作的监督会显著扰动原始 VLM 的权重分布,导致在动作指令跟随与泛化能力上出现严重退化,甚至出现对动作样本的过拟合。
在 (b) 中,解耦式设计为动作预测设立独立分支,该分支与 VLM 交互并从中提取信息(如 π0 所示)。其局限在于视觉与语言仅作为动作生成的辅助手段;这种松耦合架构削弱了动作预测对指令的严格遵循能力。
作者的架构通过采用 Mixture-of-Experts(MoE)设计并为不同训练任务分配不同的 FFN,从而形成一个紧耦合的跨模态结构,有效增强模型的跨模态关联能力。
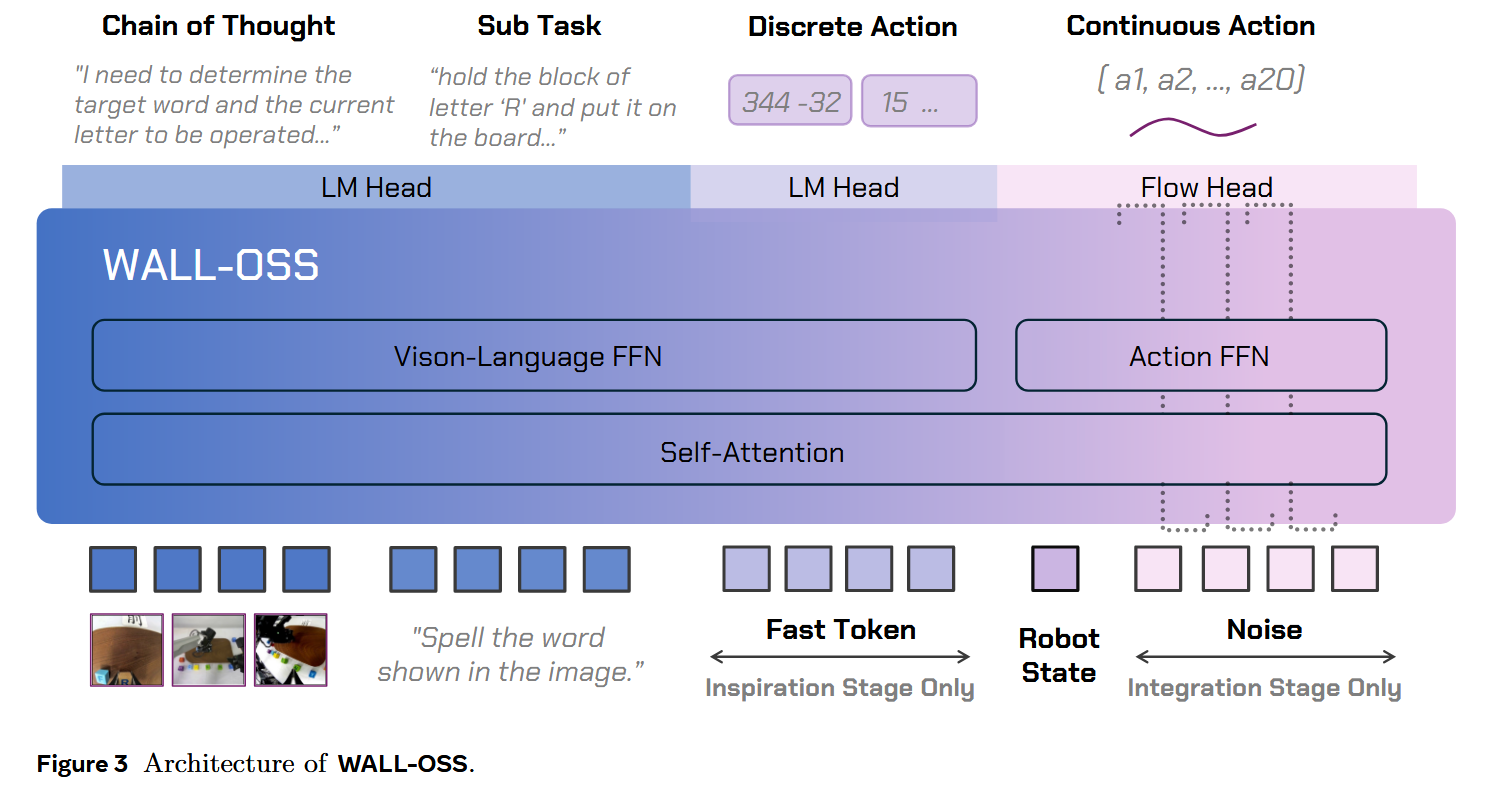
图3展示了WALL-OSS整体的架构,把QwenVL2.5-3B作为主要的backbone,模型的输入是视觉(包括第一人称视角和臂载相机视角)以及文本指令;模型会根据不同训练阶段输出不同结果,但始终以相同的多模态输入作为条件。
在 VLM 预训练之后,作者的预训练过程包含两个主要组成部分:VLM 的 Inspiration 阶段与三模态(Vision–Language–Action)的 Integration 阶段(见图 4)。
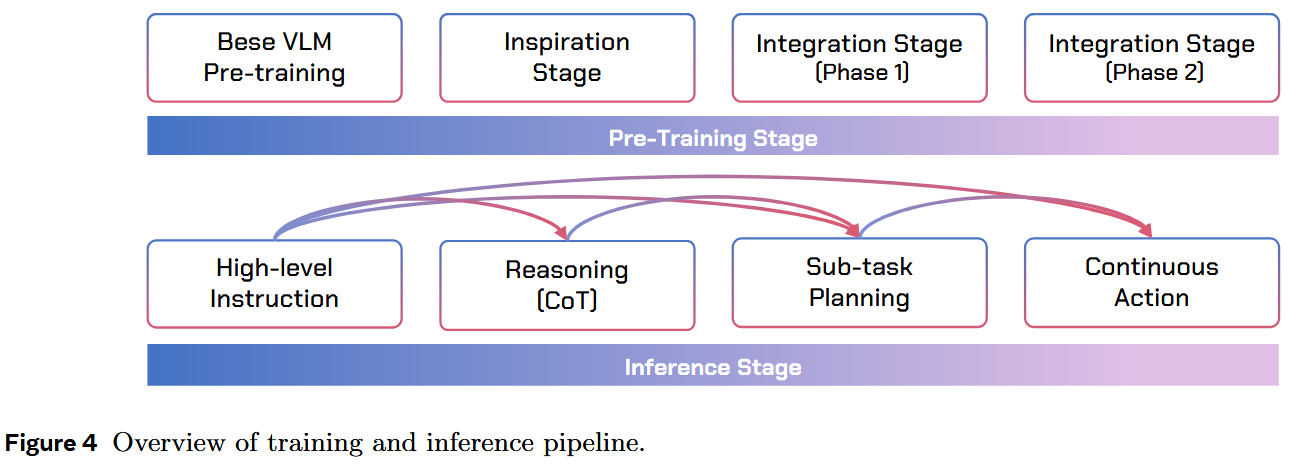
2.2 Inspiration Stage / 启发阶段
首先复用预训练 VLM 的原始 FFN,并通过加入具身 VQA(embodied VQA)来增强其在机器人环境中的空间推理能力。
训练目标包括 masked language modeling、图像/视频–文本对比学习、指令跟随,以及时序顺序/因果建模,旨在构建强健的 grounded VL 先验。
同时,引入了一个离散动作目标:将文本 token 与通过 FAST tokenization 获取的离散动作 token 对齐(参见 π0-FAST):
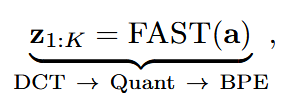
Inspiration 的损失为:
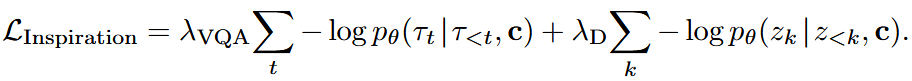
该阶段为 VLM 装备了粗粒度、语义锚定的动作感知;其输出包括 chain-of-thought 推理、子任务预测和离散的 FAST 动作 token。
具身 VQA 提升了 VLM 在具身环境下的空间理解能力,而 FAST token 的预测提供了粗粒度的动作理解。该阶段用以启发初始 VLM,使其具备基础的具身推理与动作意识。
2.3 Integration Stage / 集成阶段
在这些先验基础上,用 flow matching 的连续动作建模替代离散动作预测,并将该阶段分为两个子阶段:
- 冻结 VLM,仅训练 Action FFN 下的 flow head;
- 解冻 VLM,进行联合优化。
在 Integration 阶段,视觉、语言和动作表征通过 attention 交互,同时用静态路由将以动作为中心的特征导向 Action FFN,而将视觉—语言特征导向 Vision–Language FFN(而非学习的 softmax/top-k 路由)。
在第一阶段,构造噪声样本并回归速度场,令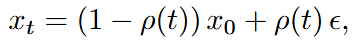 损失为:
损失为: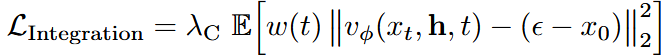 并采用梯度路由
并采用梯度路由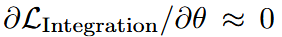 (对 VLM 施加 stop-grad,以减轻灾难性遗忘),而
(对 VLM 施加 stop-grad,以减轻灾难性遗忘),而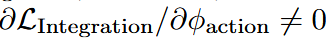 (仅优化 flow head 与 Action FFN)。Inspiration 阶段的监督在此处稳定了跨模态 attention,保留了 VL 先验,并为连续动作提供了可靠初始化。
(仅优化 flow head 与 Action FFN)。Inspiration 阶段的监督在此处稳定了跨模态 attention,保留了 VL 先验,并为连续动作提供了可靠初始化。
在第二阶段,使用相同的 flow-matching 目标对两个模块进行联合优化,梯度路由为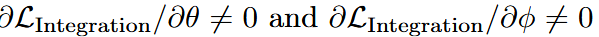 (解冻 VLM,与动作分支一起训练)。这种集成使模型在紧耦合架构内输出细粒度动作,促使模型整合多模态信息并高效完成多模态任务,从而实现不同模态之间的对齐。
(解冻 VLM,与动作分支一起训练)。这种集成使模型在紧耦合架构内输出细粒度动作,促使模型整合多模态信息并高效完成多模态任务,从而实现不同模态之间的对齐。
2.4 Unified Cross-Level CoT / 统一的跨层 CoT
将 chain-of-thought 推理的概念从传统狭义(LLM 中逐步文本推理)推广为广义 CoT,覆盖从语义到感觉运动的整个谱系:instruction → reasoning(CoT)→ subtask plan → continuous actions。
这种统一形式支持在层级抽象级别之间做任意的正向映射,使模型能在一个可微分的框架内无缝地在高层推理与低层执行之间切换。
现有方法通常把这些层级分解为流水线式或多模块系统(先由规划器生成高层计划,再由控制器执行),例如 Hi Robot 与 GR00T N1。尽管这些范式在短期内能显著降低训练与执行难度,但它们引入了不可微接口,受制于各模块的能力,并且容易在各阶段间累积误差。
相比之下,WALL-OSS 采用单一的端到端模型,共同学习跨抽象层级的映射,支持灵活的正向任意映射:模型可以根据任务复杂性与上下文要求,自适应地使用完整的中间推理步骤,或直接将指令映射到动作。
形式化地,设 v 为视觉输入,x为语言指令,c为可选的 chain-of-thought,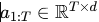 为目标动作轨迹。
为目标动作轨迹。
Uni-CoT 训练一个统一预测器FθF_θFθ,并采用 path-drop 目标使模型能够灵活地以或不以中间推理为条件: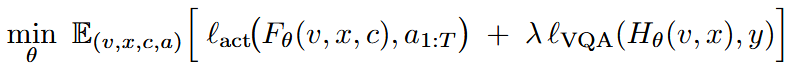 其中HθH_θHθ是带监督 y 的具身感知 VQA 头。
其中HθH_θHθ是带监督 y 的具身感知 VQA 头。
该形式使得同一模型既能进行完整链路训练,也能直接进行 x→a(指令到动作)的训练,保证端到端可微性并保留推理灵活性。通过覆盖跨语义层级的映射,Uni-CoT (i) 通过具身 VQA 加强 VLM 的空间理解,从而提升落地性与动作预测能力;(ii) 显著提高长时序任务的成功率与指令遵循度。
此外(见图 4 下部),在推理阶段,Uni-CoT 可以自适应决定是否调用 CoT/子任务分解,甚至在推理与执行间交错进行——在继续推理的同时为已完成的子任务发出动作,从而支持用于实时人机交互的灵活且异步的控制。
3. 数据构成
作者构建了一个以 embodiment 为中心的多源数据集,旨在弥补现有 VLM 在大规模对齐 VLA 监督不足与空间理解能力方面的空缺。该语料库超过 10,000 小时,包含三类互补成分:
- 为保证高质量与任务复杂度而自采的机器人动作数据;
- 用以实现跨形态(cross-morphology)与跨环境泛化的开源动作数据;
- 用于保持并增强语言—视觉能力且为时空与推理提供额外监督的多模态 VQA 数据(见图 5)。

为与作者的两阶段训练方案(Inspiration 与 Integration)对齐,对数据源做功能性编排:
- Inspiration 阶段侧重于具身 VQA、指令跟随,以及通过 FAST 注入的离散动作先验,以在提升空间推理的同时向 VLM 灌输粗粒度的动作意识;
- Integration 阶段则聚焦于以 flow matching 在真实与统一的开源轨迹上训练高频连续控制——先训练动作分支,再与 VLM 联合优化,以收紧语言—视觉—动作对齐并缓解遗忘。
3.1 自采机器人动作数据
平台与场景
作者的目标是真实世界的日常操作,覆盖台式机械臂、移动支架、轮式双臂系统和轮式类人机器人,并配备第一人称/外部视角与臂载相机。场景包括厨房清洁、穿衣/整理、移动拾放、与装配任务等。
任务谱系
包含两类核心任务:
- 在明确指令下的短时操控,强调精度与泛化能力;
- 具有清晰目标但步骤隐含的长时序推理任务,需要任务分解、进度跟踪与实时决策以完成多步流程。
标注与质量控制
构建了一个多模型流水线来生成细粒度步骤标注,并辅以人工抽检,从而允许在轨迹上直接做 CoT 风格的阶段监督。
强制执行多传感器时间戳同步、离群点过滤、低质量/空闲帧剔除、基于规则的校验加人工审计,并进行自动化增强(如照明/背景变化)。为与开源动作与多模态语料平衡,从自采数据中挑选具有代表性的子集用于 WALL-OSS 训练。
3.2 开源动作数据
覆盖与来源
聚合了多样的数据集,以补充传感器形式、操作风格和环境变异,代表性来源包括 DROID、BC-Z、BRIDGE 等(完整列表见表 1)。

标准化
为使异构来源能稳定地联合预训练,作者强制执行统一规范:
- 坐标系与单位(位置用米,角度用弧度);
- 通过一个最大表达能力的 DoF 模板进行形态归一化,并对单臂/双臂、轮式与类人平台中缺失关节使用掩码/占位符;
- 感知对齐:统一相机内外参与时间戳,重采样帧率/分辨率,并对多视图视频做通道对齐;
- 动作时间基准归一化:标准化控制频率,并把轨迹重采样/插值到 flow-matching 的网格上。
该协议可减少跨源摩擦并提高优化稳定性。
3.3 多模态 VQA:通用与具身
采用两条 VQA 流:一条通用的、以感知为中心的流以维护 VLM 能力;另一条具身流专注于操控的时空与任务推理。
用于 VLM 维护的通用 VQA
作者把开源 VQA 数据集(例如 CapsFusion、RoboPoint、Robo2VLM、COCO 等)与自采轨迹上的通用 VQA 标注结合起来,以维护并提升语言—视觉能力与指令遵循性。这些信号与操控的关联较弱,主要起到对视觉—语言骨干的正则化作用,而非直接监督动作头。
用于时空与推理的具身 VQA
作者在自采轨迹上构建了自动生成流程,以提供瞄准空间理解与任务推理的监督:包括动作规划 VQA(子目标推理)、时空问答(定位、顺序、进度)、感知 VQA(属性识别)以及认知与可供性(affordance、可交互性)。
标签采用统一格式以便跨任务共享,例如 < box >[x1,y1,x2,y2]< /box >、< point>[x,y]< /point>、可选的 < mask> 编码与自然语言 QA/描述。这些信号显式地连接了“instruction → CoT → sub任务 → 连续动作”链路,并直接服务于 Uni-CoT 与紧耦合的 MoE 架构。
3.4 划分、采样与规模
依照场景/物体/任务/形态做分层(stratify),以构建跨环境与跨形态的验证/测试集。
对长时序与稀有技能采用温度控制的重采样(temperature-controlled resampling)与困难样本上采样(hard-example upsampling),以强化长程依赖与进度建模。
在两个训练阶段中,以配额控制混合各来源,既保留 VLM 能力,也联合提升连续控制。对视觉流施加轻度域随机化与遮挡扰动以提升鲁棒性。整体语料超过数万小时;并按来源展示时长、场景与形态的比例以及任务拆分。
提供定性可视化,并通过消融实验表明,具身 VQA 加上离散动作先验能显著提升后续 flow-matching 控制质量与指令遵循性,尤其是在长时序任务中。
4. 实验
4.1 实验设置
为了全面评估 VLA 模型的能力,作者设计了一套评测套件,包含一个 Embodied VQA 基准和六个机器人操控任务。该套件围绕三个核心维度:1)语言指令理解、推理与泛化;2)面向长时域多阶段任务的规划与执行;3)动作精度与鲁棒性。
4.1.1 评测任务
具身视觉问答(Embodied VQA)——为了评估模型对具身场景的理解,构建了一个 Embodied VQA 基准。该基准以从动作数据集中随机采样的视频帧为基础,要求模型完成三项任务:
- 场景描述(Scene Captioning):为给定图像生成文字描述;
- 物体定位(Object Grounding):定位文本描述指定物体的二维坐标;
- 动作规划(Action Planning):在给定图像与高层指令下以自然语言规划下一步动作。
通过人工评估比较了预训练的 WALL-OSS 与基础 VLM(qwen2.5-vl-3b)在该基准上的表现。
机器人操控任务 —— 设计了六个操控任务来评估模型在上述核心维度上的表现。其中 set-table、tidy-bedroom 与 place-by-color 为预训练中未见的新任务,用以考察模型在新任务上的适应能力。任务按其主要考察能力分组:
- 指令遵循与推理类
– Instruction-pick-place:模型需遵循多样的自然语言指令(例如描述性命令),去拾取指定物体并将其放置到指定位置。该任务不参与微调,用于评估零样本泛化能力。
– Place-by-color:模型需将毛线球放到对应颜色的纸上。此任务包含两种条件: (1) 直接视觉颜色匹配(例如把红色毛线球放在红色纸上);(2) 基于文本的推理(例如把球放在印有单词 “red” 的白纸上)。用于微调 500 个 episode。
– Block-spell:该任务要求模型用玩具方块拼写答案。它评估模型的推理能力,因为在开始拼写之前答案必须被完全推断出来。提示分为两类: (1) 识别并拼写图片卡上所示物体名称;(2) 计算简单算术表达式并拼写结果。用于微调 1600 个 episode。 - 长时序规划类
– Set-table:模型需为两个位点摆放餐具:从桌子中央拿取盘子、刀、叉并为每个位点正确摆放(盘子在中间,餐具在两侧)。微调 1500 个 episode。
– Tidy-bedroom:模型需整理一间卧室:把床上的脏衣服收集到洗衣篮中,并正确摆放枕头。微调 1000 个 episode。 - 动作精度与鲁棒性类
– Collect-waste:模型需导航到垃圾桶、收集周围散落的垃圾并准确投放。该任务包含动态物体交互与在移动受限下的空间推理。微调 900 个 episode。
– Pick-place-cup:模型需把杯子放到桌上正中摆放的盘子上。该任务通过变化初始状态(例如杯子倒置、把手朝向错误或盘子位置偏离)来增加难度,要求动态的一系列操作(如先把杯子翻正、调整盘子位置等)以完成最终放置。微调 500 个 episode。
4.1.2 基线和微调配置
将 WALL-OSS 与两类具有代表性的基线进行比较,覆盖 VLA 学习的不同范式:
- π0(14)——利用预训练 VLM 并用 flow matching 进行动作生成;
- 以及 Diffusion-Policy(23)——采用条件去噪扩散(conditional denoising diffusion)做视觉运动控制,且不依赖 VLM 的初始化权重。
为保证评估全面,作者为基线模型实现了两种指令范式:一是使用高层任务指令的平铺训练(Flat training);二是 GPT4-Subtask 训练——借助人工标注的子任务分解并用 GPT-4 在推理时生成子任务。此设计使我们能把**“任务分解”对性能的贡献与模型架构创新**区分开来。
为实现公平的骨干网络比较,WALL-OSS 与 π0 都使用预训练 VLM 权重,而 Diffusion-Policy 因为模型容量较小而从头训练。
所有模型接受相同的任务监督;WALL-OSS 的独特之处在于它支持通过交错抽样(interleaved sampling)对动作与 VQA 进行联合训练(非子任务 VQA 与动作的采样比为 1:15,子任务样本的比为 1:100)。
4.1.3 评估协议
为确保评估的客观性与公平性,实施了严格的盲测第三方评估协议。模型训练方提供了详尽的测试文档,规定了环境搭建、每项任务的初始状态与统一评分细则。
随后由未参与模型开发或训练的第三方评估人员执行评测。他们对被测模型版本信息一无所知(盲测),并严格按照提供的文档执行评估并记录结果。该协议最大限度地减少了主观偏差并保证评测结果的可靠性。
4.2 结果与分析
呈现实验结果,先评估模型对场景基础理解的能力,然后逐步展示其在更复杂操控任务上的表现。
4.2.1 预训练提升了具身场景理解
首先验证:在评估动作生成能力之前,作者的预训练策略不仅保留了 VLM 的视—语对齐能力,还增强了它对具身场景的深度理解。
如表 2 所示,在自采的 Embodied VQA 基准上将 WALL-OSS 与其原始基础 VLM(qwen2.5-vl-3b)进行了比较。

在物体定位(Object Grounding)任务上,WALL-OSS 显著优于基础 VLM;基础 VLM 因为对具身操控场景(其预训练数据中较少见)不熟悉,常被机器人臂等元素误导,从而导致定位失败。
在场景描述(Scene Captioning)任务中也呈现类似趋势:基础 VLM 常生成与场景无关的幻觉(hallucination),而 WALL-OSS 能准确描述机器人臂的操控动作。
最后在动作规划(Action Planning)上,两者都容易误判当前任务阶段,但 WALL-OSS 给出的回答更具体、更切题。
这些发现共同证明:作者的预训练策略成功将以机器人为中心的场景知识注入 VLM,为其在后续操控任务上的表现奠定了关键基础。
4.2.2 预训练后出现零样本指令遵循能力
在确立模型具身场景理解增强之后,接着评估 WALL-OSS 是否能在无需任务特定微调的情况下遵循新指令。本分析旨在验证模型利用预训练能力对未见任务形式进行泛化的能力。
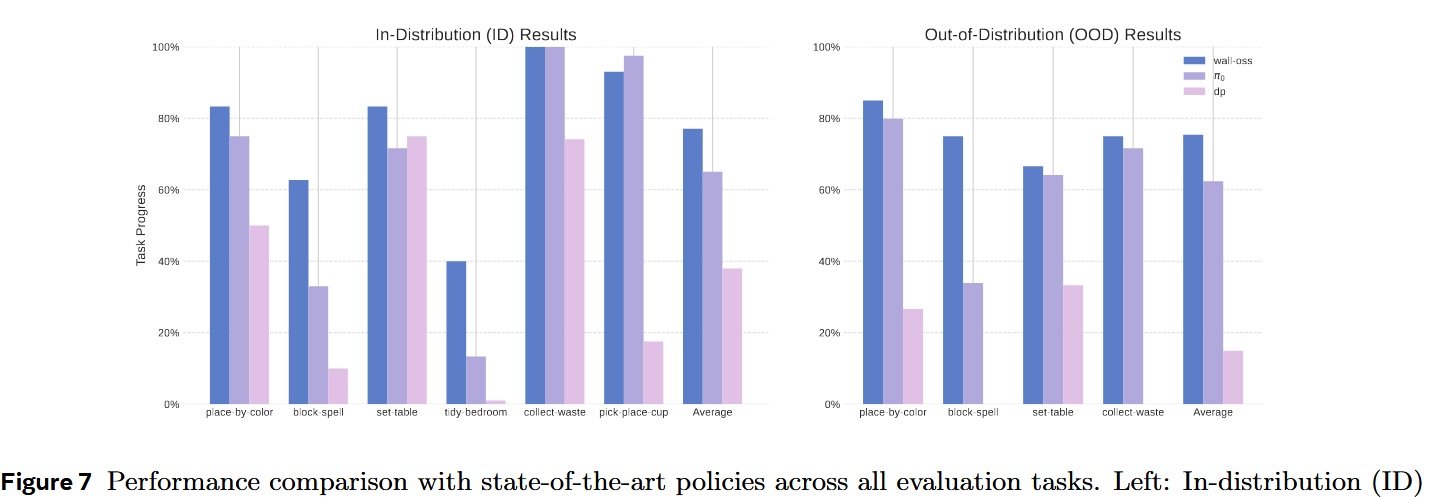
如图 7 所示,在一个 pick-and-place 任务上用两类指令评估模型: (1) 涉及在预训练中遇到过的物体与容器的指令;(2) 包含完全新颖物品的指令。在见过的物体指令上,模型平均任务完成进度为 85%;在新物体指令上也能保持 61% 的表现。
多数失败案例归因于在为不熟悉物体选择抓取或放置姿态时发生的轻微位姿不准,而非对指令目标的语义误解。这些结果表明,WALL-OSS 能在零样本情形下准确解释并执行操控指令。该能力源自其多模态预训练:既保留了 VLM 的固有推理能力,又支持对新任务的稳健泛化。
4.2.3 预训练增强动作精度和泛化能力
除了指令理解与推理外,有效的具身智能还需要精确且鲁棒的动作执行。为此,通过两个任务(Collect-Waste 与 Pick-Place-Cup)评估预训练对原始动作精度与泛化能力的影响。
结果表明:在有足够示范数据的条件下(Collect-Waste,1000 条示范),预训练模型(WALL-OSS 与 π0)在同分布(ID)任务上取得了 100% 的成功率,而未使用预训练的 DP 模型仅达到 80%。
然而,当任务复杂度上升且数据减少(Pick-Place-Cup,500 条示范)时,性能差距大幅拉开:预训练模型仍保持 >90% 的成功率,而 DP 则下降到低于 20%。
在分布外(OOD)泛化测试中——在新环境中执行 Collect-Waste——DP 的成功率从 80% 降到 0%,完全无法完成任务。相比之下,WALL-OSS 与 π0 在该情形下仍保持 >80% 的成功率,展现出强大的鲁棒性。
这些结果清楚地表明:预训练对 VLA 模型至关重要,它显著提高了动作精度、数据效率(即少样本学习能力)以及对新环境的泛化。
4.2.4 子任务生成提升长时序任务表现
长时序任务对具身智能模型提出了重大挑战,原因在于其内在复杂性、监督延迟以及执行错误跨阶段的累积效应。
为此,他们考察了是否通过语言模型动态地将高层目标分解为中间子任务(subtask),能否提升任务成功率与执行稳定性。
作者设计了两个未出现在预训练数据中的长时序任务(Set-Table 与 Tidy-Bedroom)来评估 WALL-OSS 的泛化能力。每个任务包含超过五个顺序阶段,平均执行时长分别超过 3 分钟(Set-Table)与 5 分钟(Tidy-Bedroom)。
在微调阶段,WALL-OSS 对动作生成与子任务预测进行联合训练。尽管只有 1% 的训练数据带有子任务标签,模型仍能稳定学会生成高质量的子任务指令。
在推理时,WALL-OSS 首先生成子任务指令,然后用该指令指导动作生成。如图 7 所示,在 Set-Table 与 Tidy-Bedroom 任务上,WALL-OSS 显著优于 π0 与 Diffusion-Policy。
定性分析显示,尽管所有模型在低层动作(比如拿起盘子)上表现相近,但基线模型常因缺乏明确的子任务指引而出现阶段混淆。这会表现为重复或放错位置的动作——例如反复把餐具放到同一处,或没能完成桌面其余部分的摆放——因为模型缺乏清晰的任务进度感。
此外,在相似视觉观测下存在多种合理动作时,基线模型往往难以消歧,常做出不一致或次优的选择,进一步在后续阶段放大执行错误。在空间更复杂的 Tidy-Bedroom 任务中,这些问题尤为明显:基线模型常陷入重复且低效的行为——尤其当目标物体(例如被遗漏的衣物)不在当前视野内时。
4.2.5 COT增强具身规划和推理
复杂的具身任务常常需要对空间关系、物体属性以及序列动作的后果进行推理。尽管现有 VLA 模型能把指令直接映射为动作,但在需要中间决策与常识推理的任务上往往表现欠佳。
为此,作者研究了 CoT 提示(CoT prompting)在使 WALL-OSS 通过显式中间推理来规划与执行多步行为中的作用。受大型语言模型(LLM)成功的启发,尝试把 CoT 推理能力迁移到 VLA 模型中。
为评估推理与动作执行的整合,设计了两个需要中间逻辑推断的任务:Place-by-Color 与 Block-Spell。
在微调阶段,WALL-OSS 被训练去联合生成 CoT 推理轨迹与子指令,而仅用 1% 的训练帧提供这类监督信号。在推理时,模型会自主生成 CoT 推理轨迹与子指令,并将其作为条件输入用于动作生成。
在 Place-by-Color 任务中,当目标是直接的视觉匹配(例如把红色毛线球放到红色纸上)时,我们观察到 CoT 带来的益处非常有限。但在更具挑战性的文本推理条件下(例如把毛线球放到印有“red”一词的白纸上),WALL-OSS 的任务完成率显著高于所有基线模型。这表明直接输出动作的模型限制在视觉直觉任务上,而在需要中间推理的指令化任务中,融合 CoT 是必要的。
在 Block-Spell 任务中,基线模型在平铺(flat)设定下几乎没有任务进展,再次证明缺乏任务分解会严重伤害需推理密集型任务的表现。因此在图 7 中,仅在 GPT-subtask(由 GPT 生成子任务)设定下报告基线结果。如图所示,WALL-OSS 在 ID 与 OOD 场景中均明显优于 GPT-subtask 基线。
作者的分析表明,尽管 GPT-4 往往能推断出正确的子指令,但它的响应缺乏 WALL-OSS 那样的时效性与上下文适应性——在诸如被遮挡的第一人称视角等复杂情形尤为明显。
此外,基线模型还存在 GPT 生成的高层策略与低层动作执行模块之间的不连贯,导致对齐差、指令遵循性能下降。
4.2.6 多模态联合训练增强指令跟随
除了通用的指令遵循,许多现实任务还需要精确地将细粒度的视觉与语言线索落地到动作上。因此检验了多模态联合训练(multi-modal co-training)在提升模型解读并执行细粒度、面向对象指令能力上的有效性。
如表 3 所示,WALL-OSS 在 Block-Spell 任务上比 π0 达到显著更高的准确率,尤其体现在识别并放置正确顺序的字母方块上。
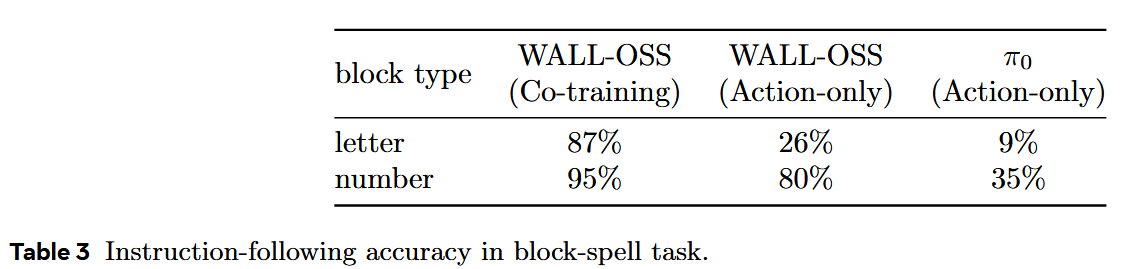
在同一任务中,观察到 π0 在识别与操作特定字母方块方面远逊于 WALL-OSS。
为调查该差距,我们做了消融实验,比对三种微调配置:
- WALL-OSS(多模态共训):通过联合训练动作生成、CoT+子任务生成、以及 2D 指称表达定位来微调。
- WALL-OSS(仅动作):仅用子任务指令对动作生成进行微调。
- π0(仅动作):与 WALL-OSS 架构相似的 VLA,仅用动作生成进行微调。
如表 3 所示,评估了每个模型在给定精确指令(例如 “拿起字母 A”)时选择正确方块的能力。结果表明,WALL-OSS(多模态共训)配置取得了最高的指令遵循准确率。
尽管 WALL-OSS(仅动作)的性能相较于多模态配置有所下降,但仍明显优于 π0(仅动作),后者的准确率接近随机。
这些发现明确表明:多模态联合训练能显著提升模型对细粒度指令的遵循能力。WALL-OSS 的预训练阶段为多模态动作对齐奠定了坚实的基础,而在微调时继续保持共训策略,则能进一步放大模型在基于指令的执行能力。
5. 讨论
5.1 面向具身的基础模型统一理论
基础模型的出现从根本上重塑了我们对人工智能的理解,然而将它们扩展到具身领域又提出了关于“智能本质”的更深层问题:
- 模态之间的内在差距有多大?
- 是否存在一种统一的架构可以在不削弱任何模态能力的前提下处理异构模态?
- 如果存在,哪些近似路径能够最高效地达到该状态?
WALL-OSS 的设计目标是弥合语言—视觉—动作之间的鸿沟。作者的紧耦合 MoE 架构、用以增强 VLM 具身理解的多模态课程化训练,以及多阶段训练计划,共同构成了一条统一的、灵活的、可微分的端到端映射路径:从高层指令——通过 CoT(Chain-of-Thought)与子任务分解——到离散动作,再到连续动作。训练期间学到的丰富正向映射也相应地在推理时赋予模型更多灵活性。
早期的尝试倾向于把非语言模态强行离散化,并在“下一个 token”目标下与文本一起联合训练,但结果并不理想。随后领域转向对新模态采取较保守的“旁支”策略,但这常常严重扰动原有的视觉—语言先验。与此相反,WALL-OSS 通过只引入较小比例的额外参数,证明了在不必假设视觉—语言能力与动作能力互为零和的前提下,同时提升具身 VL 理解与动作生成既自然又可行。
总体而言,WALL-OSS 实现了:
- 得益于具身 VQA 与 Uni-CoT 设计,在具身环境中增强的多模态落地与推理能力;
- 具有竞争力的动作生成能力,在分布外泛化上优于 Diffusion-Policy,但在精确操控上 π0 仍更胜一筹;
- Inspiration 阶段带来的可量化提升,验证了我们分阶段训练策略的有效性。
这些发现支持作者的主张:紧耦合的多模态推理与动作建模是实现可扩展具身智能的关键。
5.2 未来方向
尽管文本—图像统一架构得出了一些相似结论,但动作在性质上仍有质的不同:动作信号稀疏、位于高维流形上,而一条紧凑的轨迹对应该有庞大的视觉与语言表征。
这些表征覆盖高层的状态分析、意图形成与任务分解,而执行则依赖低层的空间感知与运动学。因此,有效的建模必须把高层文本/视觉推理与低层感知与控制对齐。
受上述动机驱动,引入大型语言模型来处理高层语义;与此同时,也在发出提问:是否需要中间表述(例如未来帧预测)或中间模态(例如 3D 感知)来降低学习 VL → A 映射的难度。
作者将严格的端到端 VL→A 路径与基于中间模态/表述的路线视为两条逐渐汇合的路径,关注它们在通向 AGI 时的相对效率。
视频与 3D 模态通常与动作的相关性高于文本—动作对,能有效“去稀疏化”监督信号;但 3D 数据仍然稀缺。大规模的视频预测可以利用互联网数据,但会引入大量冗余监督——人类在行动时并不预测所有细节,且按意图有选择地感知——这促使我们需要双向的世界建模来做行为预测。
人类媒体基本保持不变的现实下,各模态中数据与算法的增长受相邻产业(例如 AIGC、图形学)驱动,它们同样培育了动作建模所需的“中间”先验。
端到端动作预测的进展依赖于具身产业的发展,同时也相当于对这些中间先验的隐式学习。随着需求推动学界与业界并进,不同路线通向 AGI 的相对效率将始终处于动态变化中。