线性回归与 Softmax 回归
一、线性回归:预测 “连续值” 的一把好手
先从一个你肯定遇到过的场景切入:买房时,怎么估算一套房子的合理价格?你会下意识想 “面积多大?几室几厅?地段好不好?”—— 这些影响因素就是 “输入特征”,而 “房价” 就是我们要预测的 “连续值”。线性回归,本质就是帮我们把 “特征” 和 “连续值” 用数学公式串起来的工具。
1. 核心公式:用 “线性组合” 算预测值
线性回归的公式特别直观,就像小学学的 “四则运算” 升级版:
- 单样本公式:
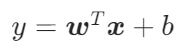 比如一套房子,特征x是 [面积 80㎡,卧室 3 个,房龄 5 年],权重w是 [0.8,0.3,-0.1](权重正代表特征越优、价格越高,负代表特征越差、价格越低),偏置\(b=50\)(相当于 “基础房价”)。代入计算就是:
比如一套房子,特征x是 [面积 80㎡,卧室 3 个,房龄 5 年],权重w是 [0.8,0.3,-0.1](权重正代表特征越优、价格越高,负代表特征越差、价格越低),偏置\(b=50\)(相当于 “基础房价”)。代入计算就是: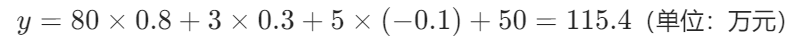 这个y,就是模型估算的房价。
这个y,就是模型估算的房价。 - 多样本公式:
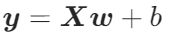 要是有 100 套房子的数据,X就变成 “100 行 3 列” 的特征矩阵(每行一套房的特征),y就是 100 个预测房价组成的向量,计算逻辑和单样本完全一致。
要是有 100 套房子的数据,X就变成 “100 行 3 列” 的特征矩阵(每行一套房的特征),y就是 100 个预测房价组成的向量,计算逻辑和单样本完全一致。
2. 冷知识:线性回归 = 最简单的神经网络!
它是个标准的 “单层神经网络”:
- 输入层:有多少个特征,就有多少个神经元(比如面积、卧室数、房龄,就是 3 个输入神经元);
- 输出层:只有 1 个神经元(对应预测的连续值,比如房价);
- 连接:输入和输出神经元之间的 “线” 就是权重w,输出神经元还带个 “基础值”b(偏置)。
后来学多层神经网络时,我总想起这个结构 —— 原来复杂模型,不过是在这个基础上 “叠层” 而已!
3. 模型训练:怎么让预测越来越准?
刚初始化的模型,权重和偏置都是随机的,预测房价肯定不准(比如把 118 万的房子估成 90 万)。这就需要 “训练” 来调整参数,核心靠两件事:损失函数和优化算法。
(1)用 “平方损失” 算误差
损失函数就是 “给模型打分” 的工具,线性回归最常用平方损失:![]() 比如真实房价 118 万,预测 115.4 万,这个样本的损失就是
比如真实房价 118 万,预测 115.4 万,这个样本的损失就是![]() 。损失越小,说明模型预测越准。
。损失越小,说明模型预测越准。
(2)用 “梯度下降” 调参数
梯度下降法,原理像 “下山找最低点”:
- 随机初始化w和b(相当于在山的某个位置);
- 算梯度:梯度是 “所有参数偏导数的向量”,能告诉你 “往哪个方向走,损失降得最快”;
- 更新参数:
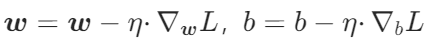 ,n是学习率,控制 “每步走多远”);
,n是学习率,控制 “每步走多远”); - 重复 2-3 步,直到损失不再下降(走到山底)。
实际训练中,我们常用小批量随机梯度下降(Mini-batch SGD):每次用 32 或 64 个样本算梯度,既比 “每次 1 个样本” 稳定,又比 “每次所有样本” 快,是深度学习的 “默认操作”。
(3)避坑指南:超参数怎么选?
训练时容易踩坑的两个超参数:
- 学习率:不能太大(容易 “跳过最低点”,损失反而上升),也不能太小(训练慢到崩溃),常用 0.1、0.01、0.001;
- 批量大小:选 16、32、64 就行,太小浪费 GPU 算力,太大训练耗时久。
二、Softmax 回归:搞定 “多分类” 的神器
学会线性回归,能预测房价、销量这些 “连续值”,但如果遇到 “给图片分类(是猫还是狗)”“给评论打分(是好评还是差评)” 这种 “选类别” 的问题,就得靠 Softmax 回归了 —— 它专门解决 “多分类任务”,还能告诉你每个类别的概率。
任务差异:从 “算数值” 到 “选类别”
线性回归输出 “一个数”,Softmax 回归输出 “多个概率”。比如给一张手写数字图片分类,它会输出 “是 0 的概率 0.02、是 1 的概率 0.01、……、是 5 的概率 0.95”,我们直接选概率最大的 “5” 作为结果。
它的应用场景特别多:
- 图像分类:MNIST 手写数字(10 类)、ImageNet(1000 类,识别猫、狗、汽车);
- 文本分类:维基百科恶语评论(7 类,比如 toxic、insult)、新闻分类(政治、体育、娱乐)。
三、一张表分清:线性回归 vs Softmax 回归
学到这里,可能有人会混淆两个模型,我整理了一张对比表,帮大家快速区分:
| 对比维度 | 线性回归 | Softmax 回归 |
|---|---|---|
| 任务类型 | 连续值预测(回归) | 多分类预测(分类) |
| 输出层神经元数 | 1 个 | 等于类别数 K 个 |
| 输出处理 | 直接输出线性组合结果 | Softmax 运算转概率 |
| 常用损失函数 | 平方损失(L2 损失) | 交叉熵损失 |
| 应用场景 | 房价、销量、温度预测 | 图像、文本、评论分类 |
但它们也有 “血缘关系”:
- 都是单层神经网络,核心都是 “特征 × 权重 + 偏置” 的线性计算;
- 都用梯度下降法训练,学习率、批量大小的调优逻辑一样;
- 都是复杂模型的基础 —— 比如 CNN 做图像分类,最后一层就是 “Softmax 回归”;多层感知机做回归,最后一层就是 “线性回归”。