CephFS存储文件系统介绍
CephFS(Ceph File System)是 Ceph 分布式存储系统提供的 原生分布式文件系统,核心优势是兼容 POSIX 接口、支持大规模扩展,并与 Ceph 的对象存储、块存储能力无缝整合,形成 “统一存储” 解决方案。它特别适合需要 多节点共享文件、低延迟高吞吐 的场景(如 HPC 高性能计算、容器共享存储、大数据分析等)。
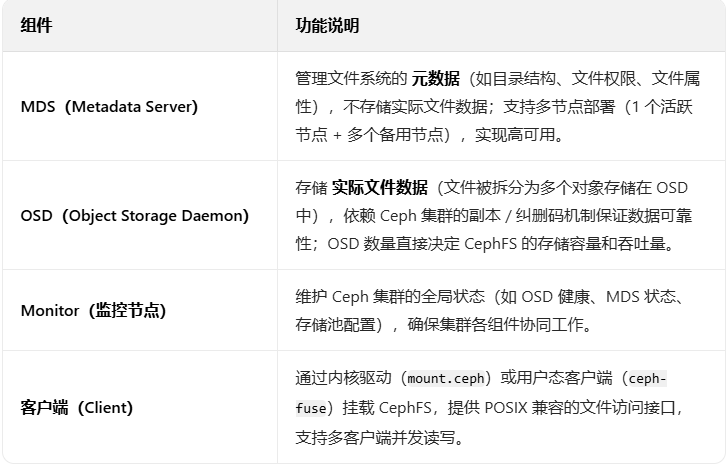
一、CephFS 核心架构
CephFS 的架构围绕 “元数据管理” 和 “数据存储” 分离设计,确保大规模场景下的性能与可靠性,核心组件包括:
二、CephFS 关键特性
- POSIX 兼容:支持标准文件操作(如
open/read/write/delete)、权限控制(UGO/RBAC)、硬链接 / 软链接,可直接替代传统 NAS 或本地文件系统,无需修改应用代码。 - 大规模扩展:
- 容量:支持 EB 级存储(依赖 OSD 节点扩展,如你之前的 3 节点 72 块 NVMe SSD 架构,可提供约 183TB 可用容量,扩展节点后容量线性增长);
- 性能:吞吐量随 OSD 数量提升(NVMe 环境下单集群可轻松达到数百 GB/s 吞吐),延迟可低至毫秒级。
- 高可靠性:
- 数据冗余:基于 Ceph 存储池的 多副本(如 3 副本,容忍 2 个节点故障)或 纠删码(如 EC 4+2,用 6 块盘存储 4 块盘的数据,节省 33% 容量)保护数据;
- 自愈能力:OSD 或 MDS 故障后,集群自动触发数据恢复(副本同步)或 MDS 主备切换,无需人工干预。
- 与 Ceph 统一存储整合:CephFS 的数据存储在 Ceph 集群的 OSD 中,可与 Ceph 的块存储(RBD)、对象存储(S3/Swift)共享同一存储资源,避免多套存储系统的运维复杂度。
- 灵活的存储池配置:元数据(小文件、目录结构)和实际数据可分别存储在不同存储池(如 “元数据池” 用 SSD 保证低延迟,“数据池” 用 HDD 降低成本),按需优化性能与成本
三、CephFS 适用场景与不适用场景
1. 适用场景
- HPC 高性能计算:如气象模拟、分子动力学、AI 训练等场景,需要多计算节点并发读写大文件(如数十 GB 至 TB 级文件),CephFS 的并行 IO 能力可满足高吞吐需求。
- 容器 / 云原生共享存储:Kubernetes 集群中,多个 Pod 需共享配置文件、日志或中间件数据(如 Kafka 日志存储、Spark 作业临时文件),CephFS 可通过 CSI 插件(
ceph-csi)提供ReadWriteMany类型的 PVC,支持多 Pod 共享。 - 企业级文件共享:替代传统 NAS,为办公场景(如设计文件、视频素材)提供跨部门、跨地域的文件共享,支持权限隔离和容量配额。
- 大数据分析:如 Hadoop/Spark 任务的输入输出文件存储,CephFS 可直接挂载为 HDFS 的替代存储,避免数据在 HDFS 和其他存储间迁移。
2. 不适用场景
- 海量小文件场景(如每秒数万次 1KB 以下文件读写):元数据操作(如创建 / 删除小文件)会频繁访问 MDS,可能成为性能瓶颈(需通过 MDS 缓存优化或使用 Ceph 对象存储 + MinIO 替代)。
- 单客户端极致性能场景:若仅需单个客户端访问文件(如本地数据库),CephFS 的分布式 overhead 会略高于本地 SSD,此时更适合 Ceph RBD(块存储)或本地文件系统。
- 低运维成本需求场景:CephFS 部署和调优复杂度高于 GlusterFS 或 NAS(需维护 MDS、OSD、Monitor 等组件),中小企业若仅需简单文件共享,可优先选择开箱即用的 NAS 设备。
四、CephFS 部署与使用关键注意事项
- MDS 配置:
- 生产环境需部署 至少 2 个 MDS 节点(1 主 1 备),避免 MDS 单点故障;
- 元数据缓存(
mds_cache_size)建议设置为节点内存的 50%-70%(如 32GB 内存节点设置 16GB 缓存),减少元数据读写延迟。
- 存储池规划:
- 元数据池(如
cephfs-metadata):建议用 SSD,PG 数量按 “OSD 数 × 10 / 副本数” 计算(如 72 OSD 3 副本,PG 设为 256); - 数据池(如
cephfs-data):按 “OSD 数 × 100 / 副本数” 计算(如 72 OSD 3 副本,PG 设为 2560),避免 PG 数量过多导致集群负载过高。
- 元数据池(如
- 客户端挂载选择:
- 内核挂载(
mount.ceph):性能更好(直接通过内核态访问,减少用户态 - 内核态切换),适合生产环境; - FUSE 挂载(
ceph-fuse):部署简单(无需内核支持),适合测试或内核版本不兼容的场景,性能比内核挂载低约 10%-20%。
- 内核挂载(
- 性能优化:
- NVMe 环境:启用 TRIM(
fstrim)、调整 NVMe 队列深度(io_queue_size=1024)、关闭 HDD 缓存(bluestore_cache_size_hdd=0); - 网络优化:配置万兆 / 25G 以太网、启用 Jumbo Frame(MTU=9000)、使用 RDMA(远程直接内存访问)进一步降低网络延迟。
- NVMe 环境:启用 TRIM(
- 监控与运维:
- 核心指标:MDS 缓存命中率(目标 > 95%)、OSD 使用率(避免超过 85%)、集群健康状态(
ceph -s显示HEALTH_OK); - 工具:使用 Prometheus + Grafana 监控集群指标,
ceph dashboard查看集群状态,ceph fs status检查 CephFS 运行情况。
- 核心指标:MDS 缓存命中率(目标 > 95%)、OSD 使用率(避免超过 85%)、集群健康状态(
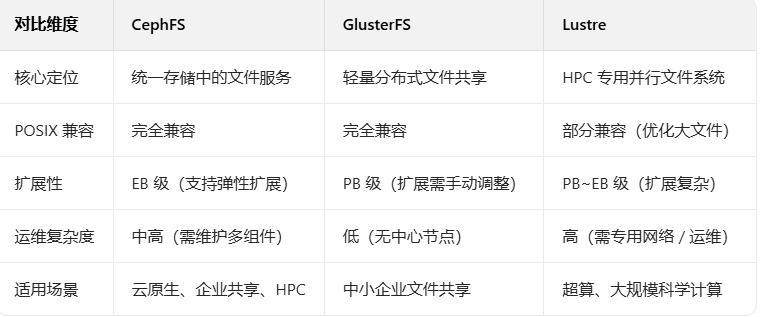
五、CephFS 与其他分布式文件系统对比(补充你之前的疑问)