告别冰冷AI音!B站开源IndexTTS2模型,零样本克隆+情感解耦,玩法超多!
上周,哔哩哔哩的Index团队宣布开源一个新东西,就是他们最新研发的语音合成系统IndexTTS-2.0
目前,该项目已经Github上获得了9.5k的星标,,已经有人称其为“宇宙最强开源语音克隆模型”。
精确时长控制,解决音画同步难题
IndexTTS-2.0最大的技术突破在于首次在自回归TTS架构中实现了精确的时长控制。
而在以往的语音合成模型中,往往无法精准控制生成语音的长度,这样,在视频配音、有声读物制作等场景中,会经常出现音画不同步的问题。
面对这种情况,我们一般是导出生成好的语音,再次放入剪辑软件去修改速度。
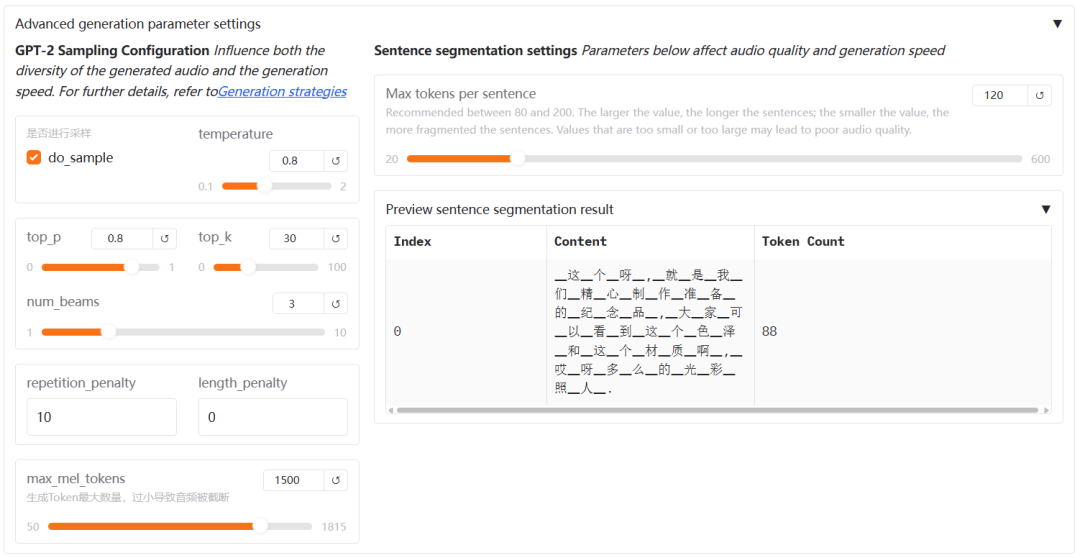
目前,该系统支持两种生成模式:
一种可以通过明确指定生成的token数实现精确时长控制,另一种则保持自然的韵律生成。
这种设计让配音师能够根据视频画面的时间节点,精准匹配语音的长度,实现完美的音画同步效果。
音色与情感完全解耦
IndexTTS-2.0的另一个创新,是实现了音色与情感的完全解耦。
简单来说,你可以用任何人的声音表达各种不同的情感,而不需要原始音频中包含相应的情感表达。
系统支持多种情感控制方式:
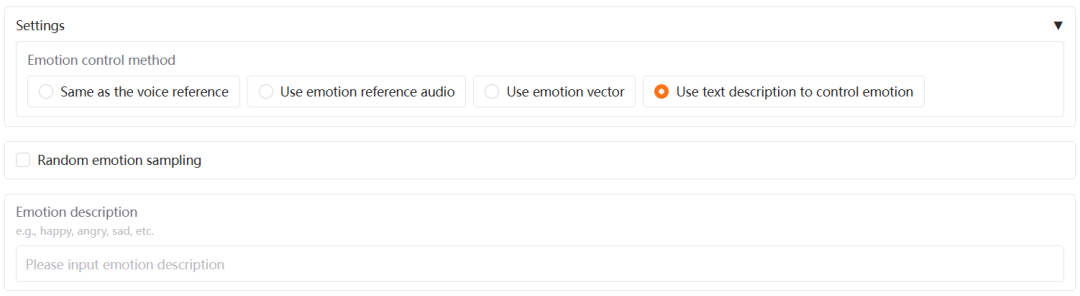
• 情感参考音频:单独提供情感参考音频文件
• 情感强度向量:通过8位浮点数列表精确控制八种情感强度
• 自然语言描述:直接用"巨巨巨难过"这样的文字描述触发情感

这样,可以让一个声音表达愤怒、哭泣、恐惧、沮丧等多种情感,而且每种情感的强度都可以精确调节。
零样本语音克隆
IndexTTS-2.0采用零样本语音克隆技术,只需要提供10秒左右的音频样本就能实现高质量的声音复制。
与需要大量训练数据的传统方法相比,这种技术大大降低了使用门槛。

在多项测试中,IndexTTS-2.0在词错率、说话人相似度和情绪保真度上都超越了当前最先进的零样本TTS模型。
包括Fish-Speech、CosyVoice2、FireRedTTS、F5-TTS等知名开源系统。
中文场景深度优化
之前我们介绍过一期关于Google的TTS系统,但是在官网的说明文件中,并没有提及说支持中文。
如果硬让他去说中文,能说是能说,但是出来的效果就非常一般了。
而针对中文语言的特殊性,IndexTTS-2.0采用字符与拼音混合建模的方式,有效解决了多音字和长尾字的读音问题。
来看看《让子弹飞》这个片段中的效果:
《让子弹飞》翻译片段
用户可以通过拼音修正特定字的发音,获得更加精准的中文语音合成效果。
开源部署
B站团队已经将该项目的核心组件进了开源:
• Github:
https://github.com/index-tts/index-tts
• Huggingface:
https://huggingface.co/IndexTeam/IndexTTS-2
• 在线体验Demo:
https://huggingface.co/spaces/IndexTeam/IndexTTS-2-Demo
• 论文地址:https://arxiv.org/abs/2506.21619
具体的部署步骤,可以直接查看下面的链接:
https://github.com/index-tts/index-tts/blob/main/docs/README_zh.md
好了,今天的分享就到这里了,如果喜欢本文的话,可以帮忙点个赞、点个关注支持一下喔~