信用违约风险分类预测:XGBoost +SHAP实践案例
本篇文章信用违约风险预测适合希望了解信用风险管理的读者。文章的亮点在于采用XGBoost和SHAP方法,不仅实现了准确的违约预测,还能解释模型的决策过程,增强了模型的可解释性。它适用于金融机构进行客户信用评估和风险控制,尤其在处理复杂数据时表现出色。
文章目录
- 1 引言
- 1.1 为何信用风险至关重要
- 1.2 机器学习在信用风险中的应用
- 1.3 项目目标
- 1.4 数据集来源
- 1.5 数据集内容
- 1.6 目标变量定义
- 1.7 数据预处理
- 1.8 分类变量
- 1.9 独热编码如何工作?
- 2 实践代码
- 2.1 为什么我们使用“drop_first=True”以及多重共线性问题
- 2.2 特征与目标分离
- 2.3 模型选择与训练
- 2.3.1 为什么选择XGBoost?
- 2.3.2 模型训练 — 训练集与测试集划分
- 2.3.3 模型训练 — 参数设置
- 2.3.4 模型训练 — xgboost.fit()
- 2.3.5 模型评估与结果
- 2.3.6 准确率
- 2.3.7 精确率
- 2.3.8 召回率
- 2.3.9 F1-分数
- 2.3.10 ROC AUC 分数
- 2.3.11 混淆矩阵
- 2.4 截至目前的总体评估
- 3 使用SHAP进行模型可解释性
- 3.1 什么是SHAP,以及我们为什么使用它?
- 3.2 SHAP分析与结果解释
- 3.3 实际适用性
- 3.4 未来步骤
- 4 结论
- 5 参考文献
1 引言
本项目旨在利用机器学习方法预测银行客户贷款违约风险,并且同样重要的是,使训练模型的推理过程可理解——通过SHAP方法,我们可以清楚地看到模型是如何得出预测的。
1.1 为何信用风险至关重要
在本项目背景下,信用风险的重要性可从三个关键领域来看待:
- 财务可持续性: 适当的信用风险管理有助于金融机构最大限度地减少违约损失,从而提高盈利能力并保持运营的可持续性。不良的风险管理可能导致严重的信用损失和流动性问题。
- 经济稳定性: 通过控制系统性风险,它支持宏观经济稳定,并有助于防止金融危机。2008年危机等重大崩溃往往源于薄弱的风险评估实践。
- 决策过程: 准确的风险评估能够实现更智能的资源分配和更明智的贷款决策。更好的客户细分和更智能的产品定价带来更强的竞争优势。
1.2 机器学习在信用风险中的应用
随着数据量的增长,关系变得更加复杂。传统经济模型在处理这种复杂性时显得力不从心,因为它需要高处理能力,而机器学习在理解这些复杂数据关系方面表现得更好。它可以作为一种快速决策支持机制,尤其适用于大型数据集。
1.3 项目目标
本项目从一个基本问题开始:
“我们能多准确地预测客户是否会忠实履行其信用——也就是说,他们是否会违约?”
关于这个主题已经进行了许多研究,其中一些已成为行业标准。 本项目旨在利用SHAP解释输出,我将在后面详细讨论,以探究这些研究结果背后的原因。通过本项目中的模型和输出,相关机构不仅能够预测违约,还能够从两方面调查违约背后的原因。
这种方法本质上打开了机器学习算法的**“黑箱”**,引出了一个问题:
“算法在做决策时优先考虑什么?”
我们的主要目标是能够解释算法的工作原理,并通过这样做,识别在决策中应优先考虑的特征。
1.4 数据集来源
本项目使用广为接受的**UCI Irvine“信用卡客户违约”**数据集。您可以在以下链接找到它:
https://archive.ics.uci.edu/dataset/350/default+of+credit+card+clients
1.5 数据集内容
我们的数据集包含25个特征和30,000行,代表台湾的信用卡客户。每一行对应一个客户,而每一列代表客户的特定属性。我们可以在下表中查看所有这些数据及其描述:
- ID: 每个客户的唯一ID。
- LIMIT_BAL: 授予客户的信用额度,单位为新台币。
- SEX: 1 = 男性 / 2 = 女性
- EDUCATION: 1 = 研究生院或博士 / 2 = 大学 / 3 = 高中 / 4 = 其他 / 5 = 未知 / 6 = 其他
- MARRIAGE: 1 = 已婚 / 2 = 单身 / 3 = 其他
- AGE: 年龄
- PAY_X: X个月前的还款状态。
- BILL_AMTX: X个月前的账单金额。
- PAY_AMT_X: X个月前支付的金额。
- default payment next month: 我们想要获得的最终输出;它表示客户下个月是否会违约。1 = 将违约 / 2 = 将不违约。
1.6 目标变量定义
我们的目标变量是_关于信用卡客户下个月是否会违约的信息_。
在数据预处理阶段(我将在后面讨论)之后,它被命名为**“DEFAULT”**。
1.7 数据预处理
原始数据通常包含缺失值、错误和空值。这是训练模型和检查结果之前最关键的步骤。
- 数据预处理转换原始数据,使其可用。
1.8 分类变量
数据集包含需要在模型训练前进行组织的分类变量。让我们以**“SEX”**变量为例。
“SEX”变量可以取值“1”和“2”。尽管“1”和“2”看起来是数字,但它们实际上代表不同的类别,如**“男性”和“女性”,并且没有数学关系(例如,“2”不比“1”好两倍)。**
因此,我们需要将分类变量转换为数值格式。为此最常见和有效的方法之一是独热编码(One-Hot Encoding)。
1.9 独热编码如何工作?
独热编码获取指定数据列中的值,并为每个唯一值创建一个二进制列。让我们以**“MARRIAGE”**列为例。
它包含三个不同的唯一值:“1”=已婚,“2”=单身,和“3”=其他。 这些需要重新排列,而不暗示它们之间存在数值上的优越性。
独热编码后,“MARRIAGE”特征将转换为“MARRIAGE_1”、“MARRIAGE_2”和“MARRIAGE_3”。如果一个人已婚(即“MARRIAGE”=1),新列将是:
- MARRIAGE_1 = 1
- MARRIAGE_2 = 0
- MARRIAGE_3 = 0
2 实践代码
categorical_cols = ['SEX', 'EDUCATION', 'MARRIAGE']df_encoded = pd.get_dummies(df, columns=categorical_cols, drop_first=True)print("\nFirst 5 rows of the dataset after One-Hot Encoding:")
print(df_encoded.head())print("\nColumns of the dataset after One-Hot Encoding:")
print(df_encoded.columns)print(f"\nShape of the dataset after One-Hot Encoding: {df_encoded.shape[0]} rows, {df_encoded.shape[1]} columns")
2.1 为什么我们使用“drop_first=True”以及多重共线性问题
多重共线性,尤其在_基于回归的模型_中很常见,是指两个或多个特征之间高度相关的情况。为了防止这种情况,我们在独热编码中使用了drop_first=True参数。此参数会删除创建的第一个列。
例如,对于SEX列(“1”代表男性,“2”代表女性),只创建了SEX_2列。
- 如果
SEX_2值为1,则该人为“女性”。 - 如果
SEX_2值为0,则该人为“男性”。
2.2 特征与目标分离
在开始训练模型之前,我们需要将特征与目标分离。让我们检查下面的代码。
X = df_encoded.drop('DEFAULT', axis=1)
y = df_encoded['DEFAULT']print("\nFirst 5 rows of the features (X) dataset:")
print(X.head())print("\nFirst 5 values of the target variable (y):")
print(y.head())print(f"\nShape of X: {X.shape}")
print(f"Shape of y: {y.shape}")
- “X”,即特征,代表我们将用于训练模型的所有变量。
- “y”,即目标变量,是模型试图预测的输出。
通过这种方式,数据集被划分为目标和特征。
2.3 模型选择与训练
2.3.1 为什么选择XGBoost?
在此过程和类似项目中,最关键的一点是模型选择。 对于这个复杂的问题,我选择了高性能且经过验证的XGBoost(eXtreme Gradient Boosting)。 我将简要解释我选择它的原因。
- 损失函数优化: 模型固有地构建顺序决策树,每棵新树旨在纠正前一棵树的错误。这种持续改进过程确保模型找到最优解决方案。
- 解决过拟合: XGBoost使用“正则化”来控制模型复杂性并抑制过拟合问题。
- 高性能和速度: 凭借其并行处理支持,XGBoost可以快速处理大型数据集,使其具有高度可扩展性。
2.3.2 模型训练 — 训练集与测试集划分
在开始训练模型之前,需要针对它从未见过的数据集进行评估,以衡量其成功。 为此,在模型训练之前,数据集被划分为训练数据集和测试数据集。
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42, stratify=y)print(f"Training set X shape: {X_train.shape}")
print(f"Training set y shape: {y_train.shape}")
print(f"Test set X shape: {X_test.shape}")
print(f"Test set y shape: {y_test.shape}")print("\n'DEFAULT' distribution in training set:")
print(y_train.value_counts(normalize=True))print("\n'DEFAULT' distribution in test set:")
print(y_test.value_counts(normalize=True))
以上代码执行了训练集和测试集的划分。
2.3.3 模型训练 — 参数设置
我们已经完成了所有数据的预处理和准备阶段。现在是时候理解和设置参数,然后开始训练模型了。您可以在下面的代码行中看到。
xgb_model = xgb.XGBClassifier(objective='binary:logistic',eval_metric='logloss',use_label_encoder=False,n_estimators=200,learning_rate=0.1,max_depth=5,subsample=0.8,colsample_bytree=0.8,gamma=0.1,random_state=42,n_jobs=-1
)
现在,让我们简要地检查这些参数的每个作用:
**objective='binary:logistic'**:指定模型将执行二元分类,输出0或1。**n_estimators=200**:表示模型将通过创建200棵决策树进行学习。**learning_rate=0.1**:控制每棵新树对纠正前一棵树的错误的贡献程度。**max_depth=5**:将每棵树的最大深度设置为5,这可以防止模型变得过于复杂。**subsample**和**colsample_bytree**:确保为训练每棵树随机选择特定比例的数据和特征,从而提高模型的泛化能力。
通过调整这些超参数,可以获得更稳定和成功的结果。在本研究中,我使用这些值来获得我的结果。
2.3.4 模型训练 — xgboost.fit()
在确定参数后,剩下的就是训练模型,我们可以使用以下代码完成:
xgb_model.fit(X_train, y_train)print("\nXGBoost model training completed successfully!")
2.3.5 模型评估与结果
为了理解像本项目这样的理论项目在实际世界中的成功,我们使用各种工具来评估模型。首先,我将包含我用于评估的代码。
y_pred = xgb_model.predict(X_test)
y_pred_proba = xgb_model.predict_proba(X_test)[:, 1]print("Model Evaluation Results:")
print("---------------------------------")accuracy = accuracy_score(y_test, y_pred)
print(f"Accuracy: {accuracy:.4f}")precision = precision_score(y_test, y_pred)
print(f"Precision: {precision:.4f}")recall = recall_score(y_test, y_pred)
print(f"Recall: {recall:.4f}")f1 = f1_score(y_test, y_pred)
print(f"F1-Score: {f1:.4f}")roc_auc = roc_auc_score(y_test, y_pred_proba)
print(f"ROC AUC Score: {roc_auc:.4f}")conf_matrix = confusion_matrix(y_test, y_pred)
print("\nConfusion Matrix:")
print(conf_matrix)plt.figure(figsize=(6, 5))
sns.heatmap(conf_matrix, annot=True, fmt='d', cmap='Blues', cbar=False,xticklabels=['Predicted: No Default (0)', 'Predicted: Default (1)'],yticklabels=['Actual: No Default (0)', 'Actual: Default (1)'])
plt.title('Confusion Matrix')
plt.xlabel('Predicted Value')
plt.ylabel('Actual Value')
plt.show()print("\nClassification Report:")
print(classification_report(y_test, y_pred))
现在让我们逐一回顾每个结果及其含义。
2.3.6 准确率
这根据模型的测试结果检查模型的整体正确性。我从试验中得到的结果如下:
准确率(Doğruluk):0.8162
这表明模型在**81.6%**的时间内给出了正确的结果。
2.3.7 精确率
这是模型预测会违约的客户中实际违约的比例。在我们的模型中,结果如下:
精确率(Kesinlik):0.6534
这表明**65.3%**的违约预测是正确的。精确率是一个关键指标,特别是对于减少假阳性(在我们的例子中,预测会违约但实际没有违约的客户)。
2.3.8 召回率
我们可以将其视为精确率的倒数;它显示了实际违约但未被模型正确识别的客户的比例。
召回率(Duyarlılık):0.3595
与精确率不同,召回率旨在减少假阴性(在我们的例子中,实际违约但被模型遗漏的客户)。我们的例子显示,模型仅检测到**35.9%**的实际违约客户。
2.3.9 F1-分数
此指标是精确率和召回率的调和平均值。
F1=2×Precision×RecallPrecision+RecallF1 = 2 \times \frac{\text{Precision} \times \text{Recall}}{\text{Precision} + \text{Recall}} F1=2×Precision+RecallPrecision×Recall
需要进行此评估的原因是衡量模型在不平衡数据集上的性能。我们可以将F1-分数视为一个平衡杆,一端是精确率,另一端是召回率。我们的目标是两者都产生高输出,从而提高F1-分数。
这里我们需要深入一点。模型可能已被训练成只优先考虑精确率或只优先考虑召回率。让我们用一个例子来解释这一点。
如果我们提高精确率会发生什么?
- 我们让训练好的模型仅在非常有信心时才预测“有风险”。这些“有风险”的预测大部分将是正确的,但这会降低召回率。 召回率下降意味着模型将错过许多真正有风险的客户。
如果我们提高召回率会发生什么?
- 我们让模型即使有丝毫疑问也预测“有风险”。这样,我们几乎可以捕捉所有真正有风险的客户,但这会降低精确率。 精确率下降意味着我们将把许多没有风险的客户标记为“有风险”。
总而言之,F1-分数越高,模型在数据集上的工作就越平衡和稳定。
现在,让我们回到我们的例子:
F1-分数:0.4638
F1-分数和我们之前的值表明,我们的模型无法在不牺牲精确率的情况下提高召回率。换句话说,模型做出了可靠的预测,但在捕捉全部有风险客户方面不足。
2.3.10 ROC AUC 分数
此分数用于衡量像我们这样的二元分类问题的成功。它由两部分组成:ROC曲线和AUC面积。 让我们也简要地看一下这些。
- ROC曲线显示了模型在不同阈值下的表现。
- AUC是ROC曲线下的面积。
为了更好地理解这些,让我们绘制曲线。
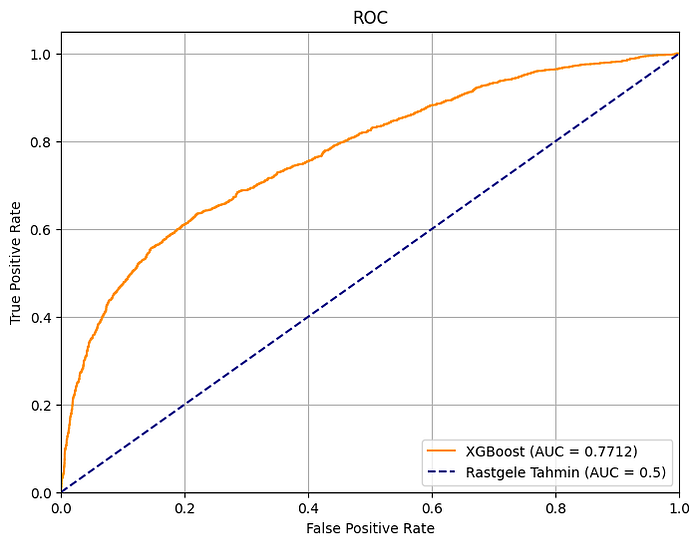
橙色线代表我们训练好的模型,而虚线蓝色线代表AUC值为0.5。曲线下的面积是AUC,我们的模型面积计算结果为0.7712。我们可以说,这个数字越大——也就是说,我们的曲线离中心越远,其下的面积越大——成功率就越高。
2.3.11 混淆矩阵
此矩阵显示了我们的模型所做的正确和不正确预测的数量。它是评估成功的一种常用方法。
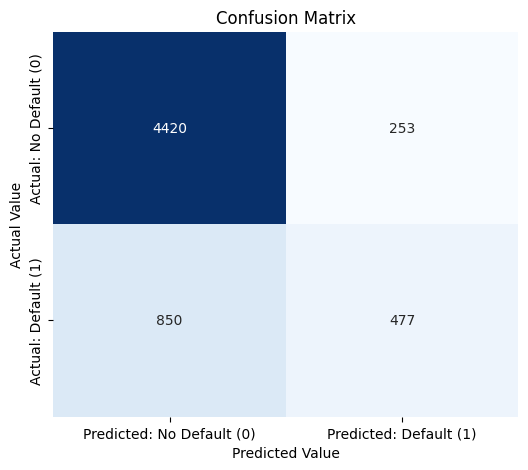
我们可以观察到:
- 4420(真阴性 — TN): 我们正确预测了不会违约(0)的客户。
- 477(真阳性 — TP): 我们正确预测了会违约(1)的客户。
- 253(假阳性 — FP): 我们错误地预测客户会违约,而他们实际上不会。
- 850(假阴性 — FN): 我们错误地预测客户不会违约,而他们实际上会。
上面的数字850解释了为什么我们的召回率如此之低。 这些是未被发现的风险,可能在实际应用中造成意想不到的巨大损失。
2.4 截至目前的总体评估
根据我们获得的输出,我们可以说,虽然我们的模型显示出中等偏好的准确率,但由于数据集不平衡,它在捕捉可能违约的风险客户方面存在困难。
这一发现对项目的后续阶段是一个有价值的提示。
3 使用SHAP进行模型可解释性
3.1 什么是SHAP,以及我们为什么使用它?
SHAP,即**“SHapley Additive exPlanations”,是本项目和近期机器学习应用中的流行概念之一。像我们使用的XGBoost模型这样的复杂算法通常被称为“黑箱”。**
“公平地说,虽然这些模型可以做出预测,但很难解释它们是如何得出这些预测的。”
这就是SHAP的作用所在,它提供了有价值的见解,说明模型是如何得出其预测的。尤其是在金融风险等高度监管的领域,能够解释决策原因至关重要。
至于我们为什么选择SHAP,它计算一个值**(SHAP值)**,显示每个客户的特征对模型最终决策的贡献程度。在实际应用中,这提供了以下好处:
- 当信用申请被拒绝时,我们可以用具体数据解释拒绝的原因。
- 通过了解哪些因素对违约风险影响最大,我们可以相应地制定业务策略和信用政策。
- 当模型做出意外或不正确的预测时,我们可以找出导致这些错误的特征。
- 在金融领域,有义务证明决策是公平和无偏的。
因此,总而言之,通过SHAP,可以回答结果背后的“为什么”。
3.2 SHAP分析与结果解释
由于代码可以从GitHub获取,并且主要用于绘制SHAP结果,我将只评估输出。
全局特征重要性(SHAP平均绝对值)
此图表显示了哪些特征对模型的整体预测影响最大。条形越长,其对模型决策机制的影响越大。
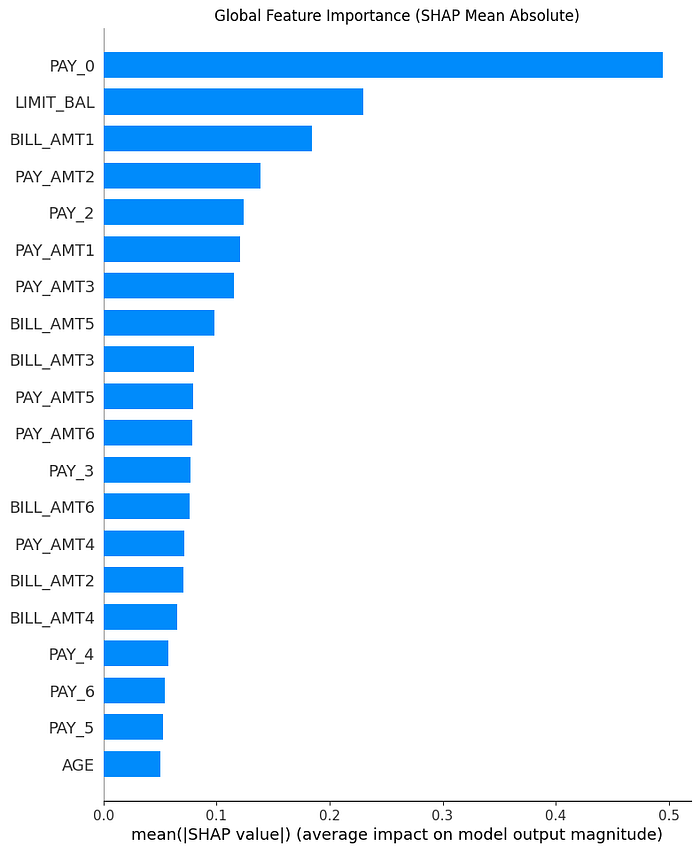
从图表中,我们可以说:
PAY_0,最近一个月的还款状态,是影响我们模型决策的最重要因素。这表明在预测客户的违约风险时,模型高度关注他们过去的支付行为。其他特征,如LIMIT_BAL(信用额度)和BILL_AMT1(最近的账单金额),在PAY_0之后被模型考虑。
特征对预测的影响
此特征提供了每个特征如何影响预测的更详细视图。在下面的输出中,每个点代表一个客户。
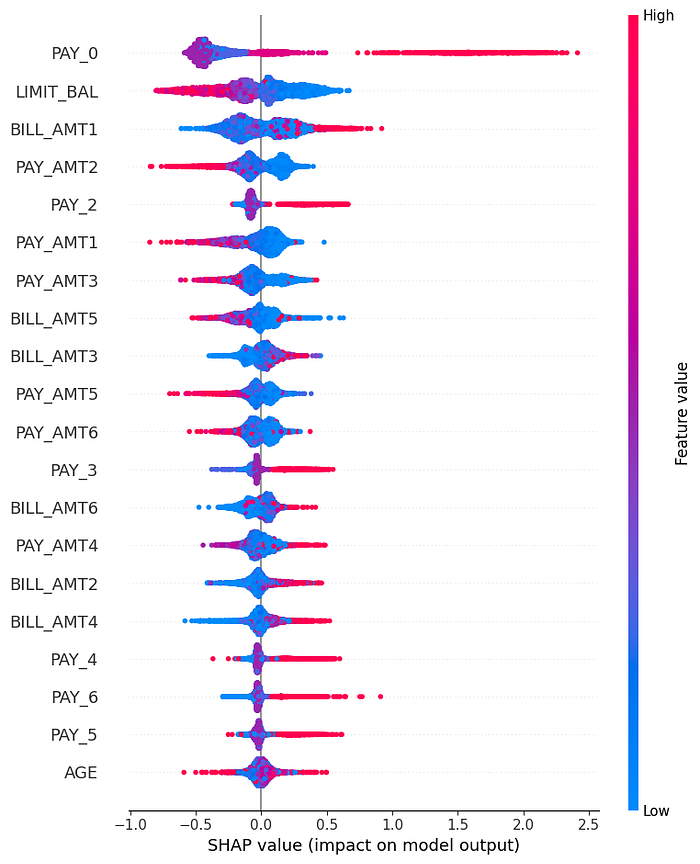
在上面的输出中,我们应该关注的点是它们与中心的距离及其密度。如图所示,PAY_0特征的点从中心向外推。
“SHAP表明,客户过去的支付习惯,特别是上个月的支付状态,对增加违约风险有显著影响。”
我们可以从LIMIT_BAL中得出的另一个见解。如您所见,红点代表特征的高值。在LIMIT_BAL高的地方,红点聚集的地方,SHAP值最低。
“这表明,在其他因素保持不变的情况下,高信用额度对违约风险具有显著的风险降低作用。”
同样,我们可以为每个值导出不同的见解,从而深入了解模型的决策机制。
前5个实例的力图(Force Plot)
SHAP最强大的优点之一是它能够解释单个客户或一组客户的预测。力图显示了每个特征如何影响客户的预测(右侧的Output Value)与平均预测(左侧的Base Value)相比。
此图表是动态的,我建议运行代码以获得最佳结果。尽管如此,让我们使用下面的截图来解释结果。
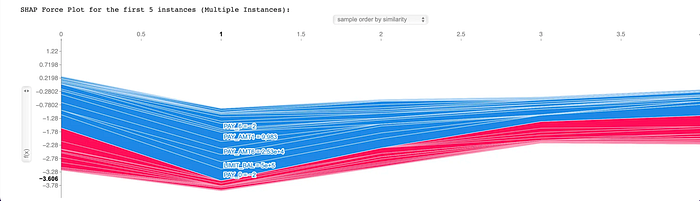
在此图表中,红线表示增加违约风险的特征,而蓝线表示降低违约风险的特征。线条的粗细表示特征对预测影响的大小。
从图表中,我们可以看到,表示支付延迟的特征(如PAY_0)的低值(蓝线)显著降低了违约风险。同时,此可视化中客户的低LIMIT_BAL(红线)作为风险增加因素突出。
这种情况表明模型捕获了复杂的交互:
- 支付历史: 对于没有支付延迟的客户(即
PAY_0为0),此特征是降低风险的最强因素之一。 - 信用额度: 虽然高信用额度本身可以降低风险,但低额度(如本例所示)具有增加风险的作用。
力图的真正强大之处在于它允许我们观察这些个体效应。 在需要解释每个客户的预测并生成决策原因的场景中,此可视化创造了SHAP的所有魔力,并阐明了决策机制。
3.3 实际适用性
在整个项目中,我们使用了强大的模型XGBoost来衡量违约风险。我们的目标不仅是做出准确的预测,还在于使预测背后的推理和模型的逻辑可理解。 现在,让我们看看如何在实际问题中应用它。
虽然SHAP能够产生广泛的见解,但其实际应用可以归纳为以下几点:
- 当集成到银行的贷款申请流程中时,此模型可以从一开始就筛选出有风险的申请,可能将不良信用比率降低X%。 这直接降低了不良贷款(NPL)比率并提高了资本效率。
- 客户关系部门可以利用模型的SHAP输出,与看起来有风险的客户主动沟通。 这使得可以实施主动措施,如债务重组或限额降低。
- 营销团队可以通过向模型标记为低风险的客户提供特殊信用活动来遵循更安全的增长策略。
- 内部审计和监管团队可以证明决策是公平的,这得益于模型的可解释性功能。
3.4 未来步骤
我们可以进行一些改进以进一步增强模型的性能。
- 为了解决模型的低召回率问题,可以使用SMOTE(合成少数类过采样技术)等方法。该技术增加了违约客户的数量,使模型能够更好地从该类别中学习。
- 为了进一步提高模型的性能,可以使用GridSearchCV或RandomizedSearchCV等方法找到超参数(例如
n_estimators、learning_rate、max_depth)的最佳组合。 - 可以从现有特征中派生出新的、更有意义的变量。例如,
BILL_AMT和PAY_AMT之间的比率或支付延迟的累积和等特征可以提高模型的预测能力。 - 可以测试并比较其他高级梯度提升算法,如LightGBM或CatBoost的性能。
- 此模型可以通过Web应用程序或API集成到信用申请系统中,以提供实时预测。
4 结论
在本文中,我旨在全面介绍机器学习过程,从数据预处理到模型训练以及训练结果的评估,包括SHAP输出。通过将独热编码等基本概念与SHAP等复杂输出相结合,本研究为违约风险管理的经典和成熟方法提供了不同的视角。
本项目的所有源代码都可以从下面的GitHub存储库获取。
default-risk-prediction-xgboost-shap
5 参考文献
Yang, Ş., Huang, Z., Xiao, W., & Shen, X. (2025). Interpretable credit default prediction with ensemble learning and SHAP. arXiv. https://doi.org/10.48550/arXiv.2505.20815
Lin, L., & Wang, Y. (2025). SHAP stability in credit risk management: A case study in credit card default model. arXiv. https://doi.org/10.48550/arXiv.2508.01851
Zhu, M., Zhang, Y., Gong, Y., Xing, K., Yan, X., & Song, J. (2024). Ensemble methodology: Innovations in credit default prediction using LightGBM, XGBoost, and LocalEnsemble. arXiv. https://doi.org/10.48550/arXiv.2402.17979
Moradi, M., Alizadeh, M., & Ghasemi, M. (2024). Explainable artificial intelligence (XAI) in finance: A systematic literature review. Artificial Intelligence Review. https://doi.org/10.1007/s10462-024-10854-8