【Datawhale25年9月组队学习:llm-preview+Task1:大模型介绍与环境配置】
1.大模型与传统NLP模型(如BERT)的不同点
最大的区别在于使用范式的改变:
BERT:像一个大学毕业生,基础不错(经过了预训练),但要胜任某个具体工作(比如情感分析),还需要岗前培训(用情感分析的数据集去微调)。
大模型:像一个经验丰富的行业专家,你不需要再培训他。你只需要用自然语言给他下达指令(我们称之为“写提示词”),他就能直接开始工作。你想让他做情感分析,就问他“这段话是积极的还是消极的?”;你想让他翻译,就说“把这句话翻译成英文”。
这种从“微调”到“提示”的转变,极大地降低了NLP技术的使用门槛,也是大模型如此强大的核心原因之一。
2.课后作业
请自行选择 Hugging Face 或 ModelScope 平台下载 Qwen/Qwen3-4B 模型,并加载模型进行推理。
以中文友好的ModelScope为例,作业要求:
安装 modelscope 库
运行代码下载 Qwen3-4B 模型
写代码加载模型并提问(至少一个问题)
得到模型的回答(截图或保存结果)
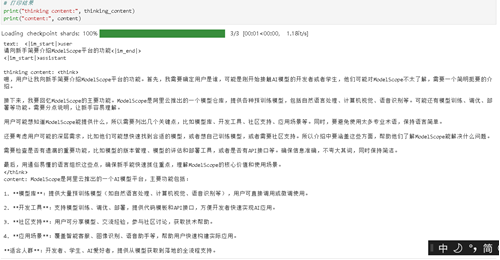
问题:
prompt = “请向新手简要介绍ModelScope平台的功能”