因果推断在解决多触点归因问题上的必要性
继续【用户增长策略如何使用因果机器学习的案例】本篇Attribution in Growth Marketing is Broken Without Causal AI探讨了因果AI在增长营销归因中的重要性,亮点在于明确区分了相关性与因果性,揭示了传统归因模型的局限性,特别是在预算分配和效果评估方面的误导。文章通过具体案例,展示了不同角色(如初创企业的增长经理、企业数据科学团队和CFO)在归因方法上的挑战与需求。
文章目录
- 1. 归因为什么需要因果判定?
- 2. 角色 1:初创公司增长经理
- 2.1. 为什么这会失败
- 3. 角色 2:企业数据科学团队
- 3.1. 为什么这会失败
- 4. 角色 3:首席财务官
- 4.1. 为什么这会失败
- 5. 因果推断的实践
- 5.1. 为什么这是因果的
- 5.2. 为什么因果推断很重要
- 6 总结
1. 归因为什么需要因果判定?
目前企业中使用的归因模型数量众多:末次点击、多触点或基于回归的营销组合模型(MMM),它们都旨在揭示哪些营销活动、渠道或策略真正起到了作用,但它们的共同问题是衡量的是关联性而非因果关系。
- 隐形的反事实: 营销团队很少提出关键的反事实问题:如果这位客户没有看到这则广告,他们还会转化吗? 没有因果方法,答案仍然隐藏,我们就有可能将噪声视为信号。
- 预算错配: 如果归因是基于关联的,那么恰好与转化同时发生的渠道会被过度归功,而真正有影响力但处于早期阶段的触点则会被低估。预算会转移到错误的地方。
- 末次点击的错觉: 如果没有因果推理,团队通常会得出结论,认为最后接触的渠道“导致”了转化。实际上,许多用户无论如何都会转化。这意味着在再营销上过度投入,而在发现新客户上投入不足。
- 渠道蚕食: 当两个渠道相关联时(例如,Facebook和电子邮件经常触达相同的用户),简单的模型会重复计算它们的影响。因果推断有助于理清哪个渠道真正带来了增量提升。
- 首席财务官的噩梦: 财务负责人想要投资回报率(ROI)。但基于相关性的归因会产生夸大或误导性的ROI数字,使得支出无法与增量收入挂钩。许多对因果归因最感兴趣的人都是那些在公司财务部门工作的人,他们迫切需要准确地证明其决策的合理性。
在接下来的部分,我们将探讨我所接触到的一些角色,介绍他们当前归因方法背后的统计学原理及其存在的问题,然后提出替代性的、具备因果意识的方法。
2. 角色 1:初创公司增长经理

Sarah 是一家种子期 SaaS 初创公司的第一位营销人员,她的团队规模很小,而且烧钱速度有点令人担忧。她工作效率很高,最近实施了Google广告、Facebook广告系列、LinkedIn外联和每周电子邮件通讯。不幸的是,创始人对支出感到恐慌,需要被说服Sarah的努力确实有效。
Sarah需要快速回答一些棘手的问题,例如:
- “我们应该加倍投入Google广告还是Facebook?”
- “电子邮件真的起作用了吗?”
- “新注册用户到底从何而来?”
Sarah没有时间(或资源)来运行受控实验或构建复杂的统计模型。相反,她求助于最简单的可用工具:末次点击归因。
末次点击归因是Google Analytics或HubSpot等工具中的默认设置。它将转化的所有功劳都归因于用户在注册或购买前与之互动的最后一个渠道。
下面是一个代码片段,展示了Sarah(极其简化)的客户数据集以及如何计算末次点击归因。
import pandas as pddf = pd.DataFrame([{"user_id": 1, "channel": "Google Ads", "signed_up": 1},{"user_id": 2, "channel": "Facebook", "signed_up": 0},{"user_id": 3, "channel": "Email", "signed_up": 1},
])attribution = df.groupby("channel")["signed_up"].mean()
print(attribution)
2.1. 为什么这会失败
末次点击归因的错觉在于它隐藏了用户旅程中发生的所有其他事情。
- 如果用户首先看到了Facebook广告,然后点击了电子邮件,最后注册了,那么电子邮件将获得所有功劳。
- 如果用户在听朋友提及品牌后通过Google搜索了该品牌,Google将获得100%的功劳。
实际上,末次点击衡量的是谁最后出现。在这个例子中,它将导致Sarah将预算从真正有影响力的发现渠道(如Facebook)转移到被过度归功的渠道(如Google)。
3. 角色 2:企业数据科学团队

在一家财富500强电子商务公司,有一个由高级数据科学家Ravi领导的完整营销分析团队。与初创公司的Sarah不同,Ravi可以访问大量的点击流数据、CRM日志和数百万笔交易。首席营销官(CMO)期望对以下问题给出精确的答案:
- “第三季度每个渠道贡献了多少收入?”
- “如果我们削减展示广告支出,会损失多少销售额?”
- “当客户接触多个渠道时,公平分配功劳的方法是什么?”
面对多个利益相关者(财务、营销、产品)对透明度的要求,Ravi需要一种感觉数学上严谨且政治上可接受的方法。
Ravi可能会决定采用多触点归因(MTA),通常由Shapley值驱动。Shapley值考虑所有可能的渠道组合,以了解哪个渠道真正对转化负责。
其吸引力显而易见:它看起来公平,因为它将转化功劳分配给每个触点,而不是全部归于一个渠道。它感觉复杂,因为Shapley值来源于合作博弈论,这在高管讨论中增加了数学可信度。它扩展性好,允许Ravi的团队处理数百万用户旅程。也许最重要的是,它有助于避免内部冲突,因为每个渠道团队都看到他们至少获得了一部分功劳。
from itertools import combinationschannels = ["Google Ads", "Facebook", "Email"]contributions = {c: 1/len(channels) for c in channels}print("Shapley-style attribution:", contributions)
3.1. 为什么这会失败
尽管多触点归因感觉比末次点击更好,但它仍然存在相关性而非因果关系的根本缺陷:
- 功劳不等于因果关系: 用户与三个渠道互动并不意味着所有三个渠道都导致了转化。其中一个可能是驱动因素,而其他只是顺带。
- 重复计数: 如果Facebook和电子邮件经常同时出现在用户旅程中,MTA可能会夸大它们各自的贡献。
- 没有反事实: Ravi的团队无法回答:如果客户从未看到Facebook,他们还会购买吗?
- 昂贵但误导: 计算量大(实际计算Shapley值是出了名的计算密集型),模型看起来很复杂,但洞察力仍然可能导致预算错配。
4. 角色 3:首席财务官

在中大型公司,营销支出是议程上最大的开支之一。Maria是公司的首席财务官。与Sarah(初创公司增长黑客)或Ravi(数据科学家)不同,Maria主要关注投资回报率(ROI)。她的问题直接且与财务相关:
- “我们每在Google广告上花费1英镑,能产生多少增量收入?”
- “如果我们将电视支出削减20%,我们的销售额会怎样?”
- “我们能证明每个季度投入Facebook广告的数百万英镑是合理的吗?”
为了回答这些问题,她的团队通常会转向营销组合模型(MMM),这是一种基于回归的方法,将销售结果与渠道支出联系起来。MMM之所以吸引人,是因为它能产生清晰的系数,这些系数似乎能将每个营销渠道直接与收入挂钩,它适用于财务部门已经追踪的聚合数据,并且看起来足够严谨,可以在董事会层面进行展示。
import pandas as pd
import statsmodels.api as smspend = pd.DataFrame({"google_ads": [10, 20, 30, 40],"facebook": [5, 15, 25, 35],"sales": [100, 150, 200, 280],
})X = spend[["google_ads", "facebook"]]
y = spend["sales"]X = sm.add_constant(X)
model = sm.OLS(y, X).fit()print(model.summary())
输出显示了Google Ads和Facebook的系数,Maria将其解释为“Google广告每花费1英镑,就能带来12英镑的销售额。”
4.1. 为什么这会失败
营销组合模型(MMM)本质上是一种多元回归方法,它将销售额(因变量)与营销投入(如渠道支出或曝光量)联系起来,通常会进行转换并控制季节性或促销活动。虽然它能产生整洁的系数,似乎量化了每个渠道的影响,但实际上,MMM容易受到混淆变量、时间滞后和遗漏变量的影响,因此它常常夸大或错误地归因营销的真实因果效应。
- 季节性扭曲: 如果Facebook广告活动总是与节假日促销活动同时进行,MMM可能会得出Facebook非常有效的结论,即使真正的驱动因素是季节性。
- 与品牌实力混淆: 当品牌知名度提高时,自然销售额和广告支出可能同时增加,从而夸大了对付费渠道的归因。
- 滞后效应难以捕捉: 某些渠道(如电视或内容)具有滞后影响,回归模型通常无法捕捉。
- 虚假的精确感: R²值和p值给人一种严谨的错觉,但它们没有回答反事实问题:如果我们没有投放Facebook广告,销售额会是多少?
5. 因果推断的实践
归因和因果推断之间的关键区别在于反事实思维。归因模型(末次点击、多触点、MMM)都描述了发生了什么,它们根据观察到的相关性在渠道之间分配功劳。但因果推断则询问如果事情不同会发生什么。
例如:
- 如果用户看到了Facebook广告并注册了,归因会说“Facebook促成了注册。”
- 因果推断会问:如果这个用户没有看到Facebook广告,他们还会注册吗?
这种反事实推理是因果方法更接近营销行动真实增量效应的原因。
5.1. 为什么这是因果的
像DoWhy这样的因果推断框架将归因模型忽略的三件事形式化:
结构性假设(DAG):
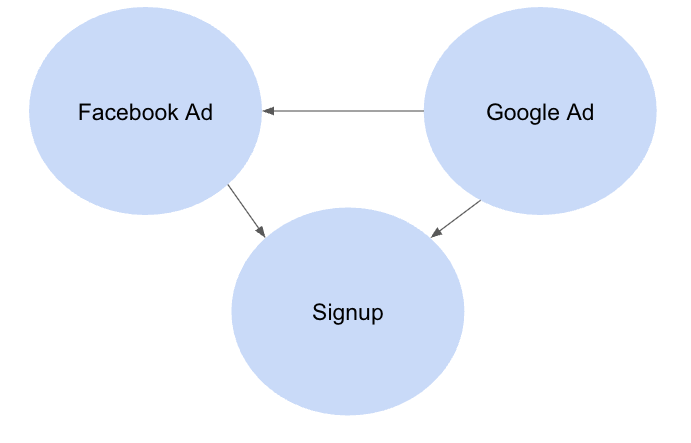
我们使用因果图(有向无环图)明确建模不同变量如何相互影响。例如,下面的DAG编码了我们的假设,即Google广告对客户接触业务以及他们接触Facebook广告具有因果影响。也许Google广告增加了业务Facebook页面的曝光量。
效应的反事实定义:
因果效应被定义为有处理和无处理之间结果的差异:
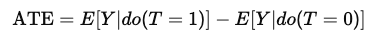
其中 do(T)do(T)do(T) 意味着我们干预并设置处理 T=tT=tT=t(例如,展示Facebook广告),而不仅仅是观察相关性。
混淆变量调整:
因果方法不是简单地比较处理组和未处理组用户,而是使用倾向得分匹配等技术调整混淆变量(例如,Google广告曝光)。这确保我们隔离了从处理到结果的真实因果路径。
下面我们展示如何使用DoWhy库计算Facebook广告对注册的因果影响。由于我们在DAG中将Google广告识别为混淆变量,因此在计算Facebook的总体影响时,我们对其进行了调整。
import dowhy
from dowhy import CausalModel
import pandas as pddata = pd.DataFrame({"facebook_ad": [1,0,1,0,0,1,0],"google_ad": [0,1,0,1,0,0,1],"signed_up": [1,1,0,1,0,1,0],
})model = CausalModel(data=data,treatment="facebook_ad",outcome="signed_up",common_causes=["google_ad"]
)identified_estimand = model.identify_effect()estimate = model.estimate_effect(identified_estimand,method_name="backdoor.propensity_score_matching"
)print("Causal Effect of Facebook Ads on signups:", estimate.value)
5.2. 为什么因果推断很重要
注意区别:
- 末次点击归因只会将Facebook的功劳归于它作为最后渠道的每次注册。
- 多触点归因会在Facebook和Google之间分配功劳。
- MMM会为Facebook分配一个回归系数,即使Facebook支出和注册量都因季节性而增加。
但因果推断更深入:通过调整混淆变量并明确建模处理与结果的关系,它估计了Facebook广告的增量提升。换句话说,它告诉我们如果我们关闭Facebook,会有多少注册量消失,这是因果影响的直接衡量。
6 总结
本文展示了不同公司如何应对同一个问题:所有这些方法都未能真正告诉我们是什么真正导致了增长。它们描述了相关性,分配了功劳,并制造了精确的错觉,但它们未能回答反事实问题:如果我们没有开展这项营销活动,结果会有所不同吗?
这就是因果推断改变游戏规则的地方。通过将营销衡量建立在明确的因果模型上并估计反事实结果,我们可以超越功劳分配,转向衡量增量提升——每个渠道创造的实际价值。
简而言之:归因告诉我们谁在房间里。因果推断告诉我们谁真正推动了增长。