杂记 08
1 调试断点
编程实践严重不足,index out of range是怎么一步步看的都不清楚的猪头。。。
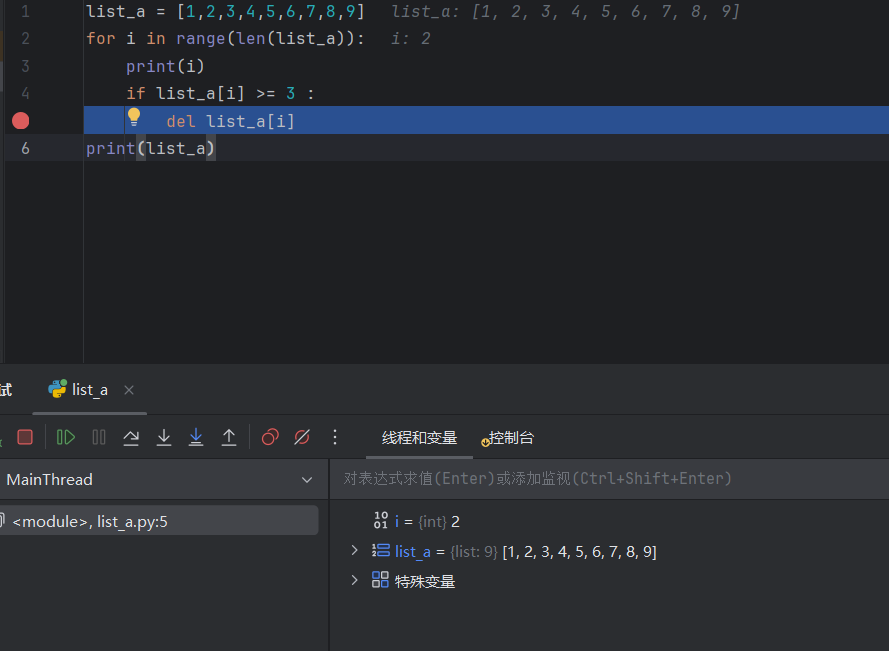
调试断点是个实用技能,跟着我一步步来学 Python 里用调试断点(以常见的 PyCharm 编辑器为例,其他编辑器 / IDE 逻辑类似 ):
一、基础操作流程
- 打(设置)断点
找到代码行号,点击行号左侧的空白区域,会出现一个小红点(断点标记),就像你截图里代码del list_a[i]那行的黄色小灯旁边,点行号左边就能打。 - 启动调试模式
点击编辑器右上角(或工具栏里)的 “虫子” 图标(调试运行按钮),代码会运行到第一个断点处暂停,进入调试状态。 - 调试面板功能
- 变量查看:下方调试区域能看当前变量值(像你截图里
i、list_a的实时数据 ),清楚代码执行到这一步变量啥状态。 - 单步执行:
- Step Over(F8):逐行执行代码,遇到函数调用不进去,直接执行完函数看结果,适合快速走流程。
- Step Into(F7):遇到函数调用会进入函数内部逐行调试,想深究函数逻辑就用它。
- Step Out(Shift + F8):在函数里调试时,直接执行完当前函数剩下代码,跳出函数回到调用位置。
- 继续运行(F9):从当前断点直接跑到下一个断点(没新断点就跑完程序),适合跳过中间已知没问题的代码。
二、实用小技巧
- 条件断点:右键断点小红点,能设置条件(比如
i > 5),代码执行到这行且满足条件才暂停,过滤无效调试超好用。 - 监视表达式:在调试面板 “监视” 区,手动输入变量、表达式(像
list_a[i] > 3),实时看计算结果,不用频繁看变量列表。
简单说,就是打个断点 → 调试运行 → 用单步 / 继续等控制代码暂停,看变量 / 表达式找问题 ,多试几次写几行小代码(比如你截图里的列表操作)调试,很快就熟练啦,遇到具体编辑器问题随时再问~
2 关于python多模块学习
Python 模块多是常态,但无需全部学习,核心是按 “需求驱动” 分类学习,优先掌握高频实用模块,再逐步拓展。以下是一套可落地的学习路径,帮你避免 “眉毛胡子一把抓”:
第一步:明确 “优先级”—— 先学 “基础高频模块”(必学)
这些模块是 Python 开发的 “基本功”,几乎所有场景都会用到,优先掌握能快速解决 80% 的基础问题。
| 模块类别 | 核心模块 | 学习重点(解决什么问题) | 学习建议 |
|---|---|---|---|
| 数据处理 | math | 基础数学运算(如开方、三角函数、取整) | 不用死记,用到时查官方文档,重点记常用函数(如math.sqrt、math.ceil) |
random | 生成随机数(如随机选值、打乱列表) | 结合小案例练(如 “模拟掷骰子”“随机抽选名单”) | |
datetime | 处理时间(如获取当前时间、时间格式转换、计算时差) | 重点掌握datetime.datetime和strftime/strptime(时间与字符串互转) | |
| 数据结构 | list/dict | (虽不是 “模块”,但属于核心数据类型) | 熟练掌握列表推导式、字典键值操作,这是后续模块的基础 |
| 文件操作 | os/os.path | 操作文件 / 文件夹(如创建文件夹、遍历文件、路径拼接) | 重点练 “批量处理文件”(如批量修改文件名),结合os.path.join避免路径错误 |
第二步:按 “应用场景” 学 “进阶模块”(按需选择)
学会基础模块后,根据你的目标(如数据分析、自动化、Web 开发)针对性学习,避免无目的拓展。
场景 1:数据分析 / 可视化(最热门场景之一)
- 核心模块:
numpy(数值计算)→pandas(表格数据处理)→matplotlib/seaborn(画图) - 学习逻辑:先学
numpy的数组操作(比列表快 10 倍 +),再用pandas处理 Excel/CSV 数据(如筛选、分组统计),最后用matplotlib画折线图 / 柱状图。 - 小案例驱动:比如 “用
pandas读取 Excel 表格,统计每月销售额,再用matplotlib画趋势图”,边做边记。
场景 2:自动化办公(提高效率)
- 核心模块:
openpyxl(操作 Excel)、python-docx(操作 Word)、smtplib(发邮件)、pyautogui(模拟鼠标键盘) - 学习逻辑:先解决 “重复工作”(如 “用
openpyxl批量填写 Excel 表格”“用python-docx批量生成报告”),再学复杂自动化(如 “用pyautogui自动截图 + 发邮件”)。
场景 3:Web 开发(做网站 / 接口)
- 核心模块:
flask(轻量 Web 框架)/django(全能 Web 框架)、requests(发送 HTTP 请求,调用别人的接口) - 学习逻辑:先学
requests(比如 “调用天气 API 获取天气数据”),再用flask写一个简单接口(如 “接收前端请求,返回数据”),最后学django做完整网站。
第三步:掌握 “查模块” 的能力(比记模块更重要)
Python 模块太多,没人能全记住,关键是 “用到时能快速找到方法”:
- 优先查官方文档:Python 官方文档(docs.python.org)是最权威的,比如查
pandas就搜 “pandas official documentation”,看 “Quick Start” 和 “User Guide”。 - 用 “关键词 + 模块名” 搜案例:比如 “python pandas 筛选数据”,优先看 Stack Overflow 或掘金的实战文章,比纯看文档快。
- 善用
help()函数:在 Python 终端输入help(模块名.函数名)(如help(pandas.DataFrame.filter)),能直接看函数的参数和用法,不用跳网页。
总结:3 个核心原则
- 不贪多,先 “用” 再 “记”:比如学
pandas,先做 “处理一个 Excel 表格” 的案例,比先背 10 个函数管用。 - 不脱离场景:如果你的目标是 “自动化办公”,就别先学
numpy(用不上),先学openpyxl;如果是 “数据分析”,就别先学pyautogui。 - 先解决 “小问题”:比如先学 “用
os模块批量删除空文件夹”,再学 “用pandas处理 10 万行数据”,从小问题积累信心。
按这个路径,你不会被 “模块多” 吓到,反而能快速把模块用起来,形成 “学习→实践→巩固” 的正循环。
3 不能使用本地Windows路径在Linux服务器上访问文件
在 Linux 服务器上无法直接使用 Windows 本地路径(如 C:\Users\File.txt)访问文件,核心原因是操作系统的文件系统架构、路径格式和网络协议完全不同。要实现跨系统文件访问,需通过「协议挂载」「远程传输」或「工具映射」等方式解决,以下是具体原因分析和解决方案。
一、核心原因:Windows 与 Linux 的底层差异
直接使用 Windows 路径失败的本质是两者的底层设计不兼容,主要体现在 3 个方面:
| 对比维度 | Windows 系统 | Linux 系统 | 不兼容后果 |
|---|---|---|---|
| 路径分隔符 | 使用反斜杠 \(如 C:\Doc) | 使用正斜杠 /(如 /home) | 路径符号不识别,直接报错 |
| 文件系统 | 基于盘符(C 盘、D 盘)管理 | 基于单根目录 / 树形结构 | 不存在 “C 盘”“D 盘” 概念,路径无效 |
| 访问协议 | 本地路径依赖 NTFS/FAT32 协议 | 本地路径依赖 Ext4/XFS 协议 | 跨系统无统一协议,无法直接读取 |
二、解决方案:3 种常用跨系统文件访问方式
根据需求(临时传输 / 长期挂载 / 可视化操作),可选择以下 3 种方案,覆盖绝大多数场景:
方案 1:临时文件传输(适合单次 / 少量文件)
如果仅需偶尔传输文件(如把 Windows 本地文件传到 Linux,或反之),无需长期挂载,推荐用「文件传输协议」工具,操作简单且无需配置系统。
| 工具类型 | 推荐工具 | 操作步骤(以 Windows→Linux 为例) |
|---|---|---|
| GUI 可视化工具 | FileZilla(免费)、WinSCP | 1. 打开工具,输入 Linux 服务器的 IP、用户名、密码(端口默认 22,需确保 Linux 开启 SSH 服务); 2. 左侧是 Windows 本地文件(可直接选 C 盘 / D 盘文件),右侧是 Linux 目录; 3. 拖拽文件即可完成传输。 |
| 命令行工具 | Windows Terminal(自带) | 1. 打开 Terminal,输入命令:scp C:\Users\YourName\test.txt 用户名@LinuxIP:/home/用户名/(解释: scp是跨系统复制命令,前半段是 Windows 本地路径,后半段是 Linux 目标路径);2. 输入 Linux 密码,等待传输完成。 |
方案 2:长期挂载(适合频繁访问,像用本地文件一样)
如果需要长期、高频访问 Windows 文件(如 Linux 服务器需持续读取 Windows 共享文件夹中的数据),可将 Windows 路径「挂载」到 Linux 目录,实现 “Linux 中用本地路径访问 Windows 文件”。
核心原理:通过 Samba 协议(Windows 文件共享默认协议),让 Linux 识别 Windows 的共享目录,并映射为 Linux 的本地目录(如 /mnt/win_share)。
具体步骤(以 CentOS/Ubuntu 为例):
-
Windows 端:共享目标文件夹
- 找到需要访问的 Windows 文件夹(如
D:\Linux_Share),右键「属性」→「共享」; - 添加 “Everyone” 或指定用户,设置 “读取 / 写入” 权限(根据需求调整);
- 记录 Windows 的 IP 地址(按
Win+R输入cmd,执行ipconfig查看 IPv4 地址,如192.168.1.100)。
- 找到需要访问的 Windows 文件夹(如
-
Linux 端:安装 Samba 客户端并挂载
- 安装 Samba 工具(CentOS 用
yum,Ubuntu 用apt):bash
# CentOS/RHEL sudo yum install -y cifs-utils # Ubuntu/Debian sudo apt install -y cifs-utils - 创建 Linux 本地挂载目录(如
/mnt/win_share):bash
sudo mkdir -p /mnt/win_share - 执行挂载命令(将 Windows 共享目录挂载到 Linux 目录):
bash
sudo mount -t cifs //192.168.1.100/Linux_Share /mnt/win_share \ -o username=Windows用户名,password=Windows密码,vers=3.0- 参数说明:
//WindowsIP/共享文件夹名是 Windows 共享路径,/mnt/win_share是 Linux 本地目录,vers=3.0是 Samba 协议版本(避免兼容性问题)。
- 参数说明:
- 安装 Samba 工具(CentOS 用
-
验证与开机自动挂载
- 挂载后,访问
/mnt/win_share即可看到 Windows 文件夹中的文件,操作方式与 Linux 本地文件完全一致; - 若需开机自动挂载,编辑
/etc/fstab文件(需谨慎操作):bash
sudo vi /etc/fstab # 在末尾添加一行 //192.168.1.100/Linux_Share /mnt/win_share cifs username=Windows用户名,password=Windows密码,vers=3.0 0 0 - 保存后执行
sudo mount -a生效,下次开机将自动挂载。
- 挂载后,访问
方案 3:远程桌面映射(适合图形化操作)
如果习惯用 Windows 远程桌面(RDP)控制 Linux(需 Linux 安装 XRDP 服务),可在远程桌面中直接 “映射” Windows 本地磁盘到 Linux,实现可视化访问。
操作步骤:
- Linux 端:安装 XRDP 服务(以 Ubuntu 为例):
bash
sudo apt install -y xrdp xfce4 sudo systemctl enable --now xrdp - Windows 端:打开远程桌面连接(按
Win+R输入mstsc):- 输入 Linux 服务器 IP,点击「显示选项」→「本地资源」→「详细信息」;
- 勾选需要映射的 Windows 本地磁盘(如 C 盘、D 盘),点击「确定」→「连接」;
- 远程登录 Linux 后:
- 打开 Linux 的文件管理器(如 Thunar),在左侧 “网络” 中会看到映射的 Windows 磁盘(如
tsclient/C),双击即可访问 Windows 本地文件。
- 打开 Linux 的文件管理器(如 Thunar),在左侧 “网络” 中会看到映射的 Windows 磁盘(如
三、常见问题排查
-
挂载时提示 “权限被拒绝”:
- 检查 Windows 共享文件夹的权限是否正确(确保指定用户有读写权限);
- 确认 Linux 挂载命令中的 Windows 用户名 / 密码是否正确(注意区分大小写)。
-
Samba 挂载后中文文件名乱码:
- 挂载命令中添加编码参数
iocharset=utf8,如:bash
sudo mount -t cifs //192.168.1.100/Linux_Share /mnt/win_share \ -o username=xxx,password=xxx,vers=3.0,iocharset=utf8
- 挂载命令中添加编码参数
-
Linux 无法连接 Windows 共享目录:
- 检查 Windows 防火墙是否关闭(或允许 “文件和打印机共享” 端口);
- 确认 Windows 和 Linux 在同一局域网(或能互通 IP),可通过
ping 192.168.1.100测试连通性。
通过以上方案,可实现 Windows 与 Linux 的文件互通,替代无效的 “直接使用 Windows 本地路径” 方式。根据访问频率和操作习惯选择对应方案即可(临时传文件用方案 1,长期访问用方案 2,图形化操作用方案 3)。
4 OOM错误
OOM(Out Of Memory)错误是指程序或系统在尝试分配内存时,发现可用内存不足而导致的错误。这种错误在各种编程语言和操作系统中都可能出现,尤其常见于内存密集型应用或资源受限的环境中。
一、OOM 错误的常见表现
- 程序突然崩溃或终止,无明显征兆
- 系统日志中出现 "Out of memory" 相关提示
- 应用响应变慢,最终停止响应
- 部分系统会触发 "内存不足杀手(OOM Killer)",自动终止消耗内存最多的进程
二、常见原因分析
- 内存泄漏:程序未能正确释放不再使用的内存,导致内存占用持续增长
- 数据量过大:处理的数据超过了系统或程序的内存限制
- 内存分配不合理:一次性申请了过多内存(如创建过大的数组)
- 资源竞争:多个进程 / 线程同时竞争有限的内存资源
- 配置不当:JVM 等运行环境的内存参数设置不合理
- 内存碎片化:频繁分配和释放小块内存导致内存碎片,无法分配连续的大块内存
三、不同环境下的 OOM 错误处理
1. Java 中的 OOM 错误
Java 中常见的 OOM 错误包括:
java.lang.OutOfMemoryError: Java heap space:堆内存不足java.lang.OutOfMemoryError: PermGen space/Metaspace:方法区 / 元空间不足java.lang.OutOfMemoryError: Requested array size exceeds VM limit:数组过大
解决方法:
- 调整 JVM 参数:
-Xms(初始堆大小)、-Xmx(最大堆大小)、-XX:MetaspaceSize等 - 使用内存分析工具(如 VisualVM、MAT)检测内存泄漏
- 优化数据处理方式,避免一次性加载大量数据
2. Linux 系统中的 OOM
Linux 内核有 OOM Killer 机制,当系统内存耗尽时,会选择 "最合适" 的进程终止以释放内存。
查看 OOM 相关日志:
bash
dmesg | grep -i 'out of memory'
grep -i 'killed process' /var/log/messages
临时解决方法:
- 增加系统内存或交换分区
- 终止不必要的进程释放内存:
kill -9 <进程ID> - 调整 OOM Killer 参数,保护关键进程
3. Python 中的 OOM 错误
Python 中 OOM 错误通常表现为MemoryError异常。
解决方法:
- 使用生成器(generator)处理大数据,避免一次性加载
- 增加系统内存或使用 64 位 Python
- 使用内存分析工具(如 memory_profiler)定位内存问题
- 采用分批处理的方式处理大数据集
四、通用排查与解决策略
-
监控内存使用情况
- 系统层面:
top、free、vmstat等命令 - 应用层面:各语言对应的内存分析工具
- 系统层面:
-
优化内存使用
- 及时释放不再使用的资源
- 采用流式处理而非一次性加载全部数据
- 使用更高效的数据结构和算法
-
增加可用内存
- 物理内存升级
- 配置适当的交换分区(swap)
- 分布式处理,将任务分配到多个节点
-
设置内存限制
- 为进程设置最大内存使用限制
- 实现内存使用监控,在接近阈值时主动释放资源
五、预防措施
- 进行充分的压力测试,模拟高负载场景
- 实现内存监控告警机制
- 定期检查内存使用趋势,及时发现内存泄漏
- 为关键服务配置自动重启机制,在 OOM 后能快速恢复
- 合理规划系统架构,避免单点内存压力过大
处理 OOM 错误通常需要结合具体环境和应用场景,通过监控、分析和优化三个步骤,逐步定位问题根源并采取相应措施。