微服务相关面试题
写在前面
🔥我把后端Java面试题做了一个汇总,有兴趣大家可以看看!这里👉
⭐️在反复复习面试题时,我发现不同资料的解释五花八门,容易造成概念混淆。尤其是很多总结性的文章和视频,要么冗长难记,要么过于简略,导致关键知识点含糊不清。
⭐️为了系统梳理知识,我决定撰写一份面试指南,不只是简单汇总,而是融入个人理解,层层拆解复杂概念,构建完整的知识体系。我希望它不仅帮助自己更自信地应对面试,也能为同行提供清晰、实用的参考。
微服务相关面试题
面试官: Spring Cloud 5大组件有哪些?
候选人:
早期我们一般认为的Spring Cloud五大组件是 :
- Eureka : 注册中心
- Ribbon : 负载均衡
- Feign : 远程调用
- Hystrix : 服务熔断
- Zuul/Gateway : 网关
随着SpringCloudAlibba在国内兴起 , 我们项目中使用了一些阿里巴巴的组件:
-
注册中心/配置中心 Nacos
-
负载均衡 Ribbon
-
服务调用 Feign
-
服务保护 sentinel
-
服务网关 Gateway
面试官: 服务注册和发现是什么意思?Spring Cloud 如何实现服务注册发现?
候选人:
我理解的是主要三块大功能,分别是服务注册 、服务发现、服务状态监控
我们当时项目采用的Eureka作为注册中心,这个也是Spring Cloud体系中的一个核心组件。
-
服务注册:服务提供者需要把自己的信息注册到Eureka,由Eureka来保存这些信息,比如服务名称、ip、端口等等。
-
服务发现:消费者向Eureka拉取服务列表信息,如果服务提供者有集群,则消费者会利用负载均衡算法,选择一个发起调用。
-
服务监控:服务提供者会每隔30秒向Eureka发送心跳,报告健康状态,如果Eureka服务90秒没接收到心跳,从Eureka中剔除。
面试官: 你能说下nacos与eureka的区别?
候选人:
我当时有个项目就是采用的Nacos作为注册中心,选择Nacos还要一个重要原因就是它支持配置中心,不过Nacos作为注册中心,也比Eureka要方便好用一些,主要相同不同点在于几点:
-
共同点:Nacos与Eureka都支持服务注册和服务拉取,都支持服务提供者心跳方式做健康检测。
-
Nacos与Eureka的区别:
①Nacos支持服务端主动检测提供者状态:临时实例采用心跳模式,非临时实例采用主动检测模式
②临时实例心跳不正常会被剔除,非临时实例则不会被剔除
③Nacos支持服务列表变更的消息推送模式,服务列表更新更及时
④Nacos集群默认采用AP方式,当集群中存在非临时实例时,采用CP模式;Eureka采用AP方式
面试官: 你们项目负载均衡如何实现的 ?
候选人:
在服务调用过程中的负载均衡一般使用SpringCloud的Ribbon 组件实现 , Feign的底层已经自动集成了Ribbon , 使用起来非常简单。
当发起远程调用时,Ribbon先从注册中心拉取服务地址列表,然后按照一定的路由策略选择一个发起远程调用,一般的调用策略是轮询。
面试官: Ribbon负载均衡策略有哪些 ?
候选人:
我想想啊,有很多种,我记得几个:
-
RoundRobinRule:简单轮询服务列表来选择服务器
-
WeightedResponseTimeRule:按照权重来选择服务器,响应时间越长,权重越小
-
RandomRule:随机选择一个可用的服务器
-
ZoneAvoidanceRule:区域敏感策略,以区域可用的服务器为基础进行服务器的选择(就近原则)。
面试官: 如果想自定义负载均衡策略如何实现 ?
候选人:
提供了两种方式:
1,创建类实现IRule接口,可以指定负载均衡策略,这个是全局的,对所有的远程调用都起作用
public class CustomLoadBalancer implements IRule {private Random random = new Random();private ZoneAwareLoadBalancer<Server> loadBalancer;@Overridepublic Server choose(Object key) {List<Server> servers = loadBalancer.getAllServers();return servers.get(random.nextInt(servers.size())); // 随机选择一个服务器}@Overridepublic void setLoadBalancer(ZoneAwareLoadBalancer<Server> lb) {this.loadBalancer = lb;}@Overridepublic ZoneAwareLoadBalancer<Server> getLoadBalancer() {return loadBalancer;}
}
2,在客户端的配置文件中,可以配置某一个服务调用的负载均衡策略,只是对配置的这个服务生效
serviceName:ribbon:NIWSServerList: "service1,service2,service3"rule: "customRule" # 指定使用自定义的负载均衡策略面试官: 什么是服务雪崩,怎么解决这个问题?
候选人:
服务雪崩是指一个服务失败,导致整条链路的服务都失败的情形,一般我们在项目解决的话就是两种方案,第一个是服务降级,第二个是服务熔断,如果流量太大的话,可以考虑限流。
服务熔断:当某个微服务不可用或者响应时间太长时,会进行服务降级,进而熔断该结点微服务的调用,快速返回“错误”的响应信息。当检测到该结点微服务调用响应正常后恢复调用链路。在 Spring Cloud 框架里熔断机制通过 Hystrix 实现, Hystrix 会监控微服务间调用的状况,当失败的调用到一定阈值,默认是5s 内调用 20 次,如果失败,就会启动熔断机制。(服务熔断 是为了防止系统因某个服务故障而崩溃,快速停止对该服务的调用)
服务降级:服务降级,一般是从整体负荷考虑。就是当某个服务熔断之后,服务器将不再被调用,此时客户端可以自己准备一个本地的 fallback 回调,返回一个默认值。这样做,虽然服务水平下降,但比直接挂掉强。(服务降级 是在服务熔断后,提供一个简化的响应或默认值,确保用户仍然能继续使用系统的其他功能)

在Feign接口上的@FeignClient里添加fallback配置,配置的是实现服务降级的类,这类继承了当前接口,并覆盖接口类中的相应方法,方法中实现用户想做的fallback处理。
面试官: 你们项目中有没有做过限流 ? 怎么做的 ?
候选人:
针对XXX项目的XXX模块,我们实现了限流,以应对优质课程发布时可能出现的高QPS。具体做法:我们采用了令牌桶算法,每秒生成固定数量的令牌,只有在获取到令牌后,请求才能被处理,确保流量在可控范围内。
我的思路是通过创建一个
TokenBucket类来实现令牌桶算法,包含四个主要属性:桶的容量、令牌生成速率、当前令牌数量,以及上次补充令牌的时间。定义了一个tryConsume方法,用于尝试获取令牌。在这个方法中,首先调用refill方法计算可用的令牌数量。如果当前桶中有令牌,就消费一个;否则返回失败,表示流量受限。在refill方法中,根据当前时间和上次补充时间的差值计算可以生成的令牌数量,并更新当前令牌数量,确保不超过桶的最大容量。import java.util.concurrent.TimeUnit;public class TokenBucket {private final long capacity; // 桶的容量private final long rate; // 令牌生成速率private long tokens; // 当前令牌数量private long lastRefillTimestamp; // 上次补充令牌的时间public TokenBucket(long capacity, long rate) {this.capacity = capacity;this.rate = rate;this.tokens = 0;this.lastRefillTimestamp = System.currentTimeMillis();}public synchronized boolean tryConsume() {refill();if (tokens > 0) {tokens--;return true; // 成功获取令牌}return false; // 令牌不足}private void refill() {long now = System.currentTimeMillis();long newTokens = (now - lastRefillTimestamp) * rate / 1000; // 计算补充的令牌数量tokens = Math.min(capacity, tokens + newTokens);lastRefillTimestamp = now;} }
面试官: 限流常见的算法有哪些呢?
候选人:
比较常见的限流算法有漏桶算法和令牌桶算法。
漏桶算法是把请求存入到桶中,以固定速率从桶中流出,可以让我们的服务做到绝对的平均,起到很好的限流效果。
令牌桶算法在桶中存储的是令牌,按照一定的速率生成令牌,每个请求都要先申请令牌,申请到令牌以后才能正常请求,也可以起到很好的限流作用。
☘️区别:
漏桶算法可以平滑处理流量,确保请求按照一定的速率被处理。即使有很多请求涌入,桶只会以固定速度漏出,保证流量平稳。但是不能解决流量突发的问题。Nginx通常采用漏桶算法,适合需要严格控制流量的场景。
令牌桶算法能处理突发流量,如果在某段时间没有请求,桶里会积累令牌;当请求突然增多时,可以一次性处理多个请求。Spring Cloud Gateway:它支持令牌桶算法,更适合需要灵活处理流量的场景,能够容忍短时间内的流量突发。
面试官:什么是CAP理论?
候选人:
CAP主要是在分布式项目下的一个理论。包含了三项,一致性、可用性、分区容错性。
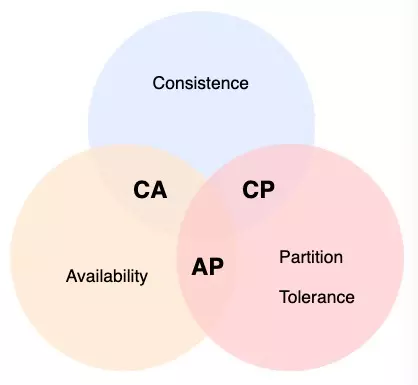
-
**一致性(Consistency)**是指更新操作成功并返回客户端完成后,所有节点在同一时间的数据完全一致(强一致性),不能存在中间状态。
-
可用性(Availability) 是指系统提供的服务必须一直处于可用的状态,对于用户的每一个操作请求总是能够在有限的时间内返回结果。
-
分区容错性(Partition tolerance) 是指分布式系统在遇到任何网络分区故障时,仍然需要能够保证对外提供满足一致性和可用性的服务,除非是整个网络环境都发生了故障。
面试官:为什么分布式系统中无法同时保证一致性和可用性?
候选人:
首先一个前提,对于分布式系统而言,分区容错性是一个最基本的要求,因此基本上我们在设计分布式系统的时候只能从一致性(C)和可用性(A)之间进行取舍。
如果保证了一致性(C):对于节点N1和N2,当往N1里写数据时,N2上的操作必须被暂停,只有当N1同步数据到N2时才能对N2进行读写请求,在N2被暂停操作期间客户端提交的请求会收到失败或超时。显然,这与可用性是相悖的。
如果保证了可用性(A):那就不能暂停N2的读写操作,但同时N1在写数据的话,这就违背了一致性的要求。
面试官:什么是BASE理论?
候选人:
BASE是CAP理论中AP方案的延伸,核心思想是即使无法做到强一致性,但应用可以采用适合的方式达到最终一致性(Eventual Consitency)。它的思想包含三方面:
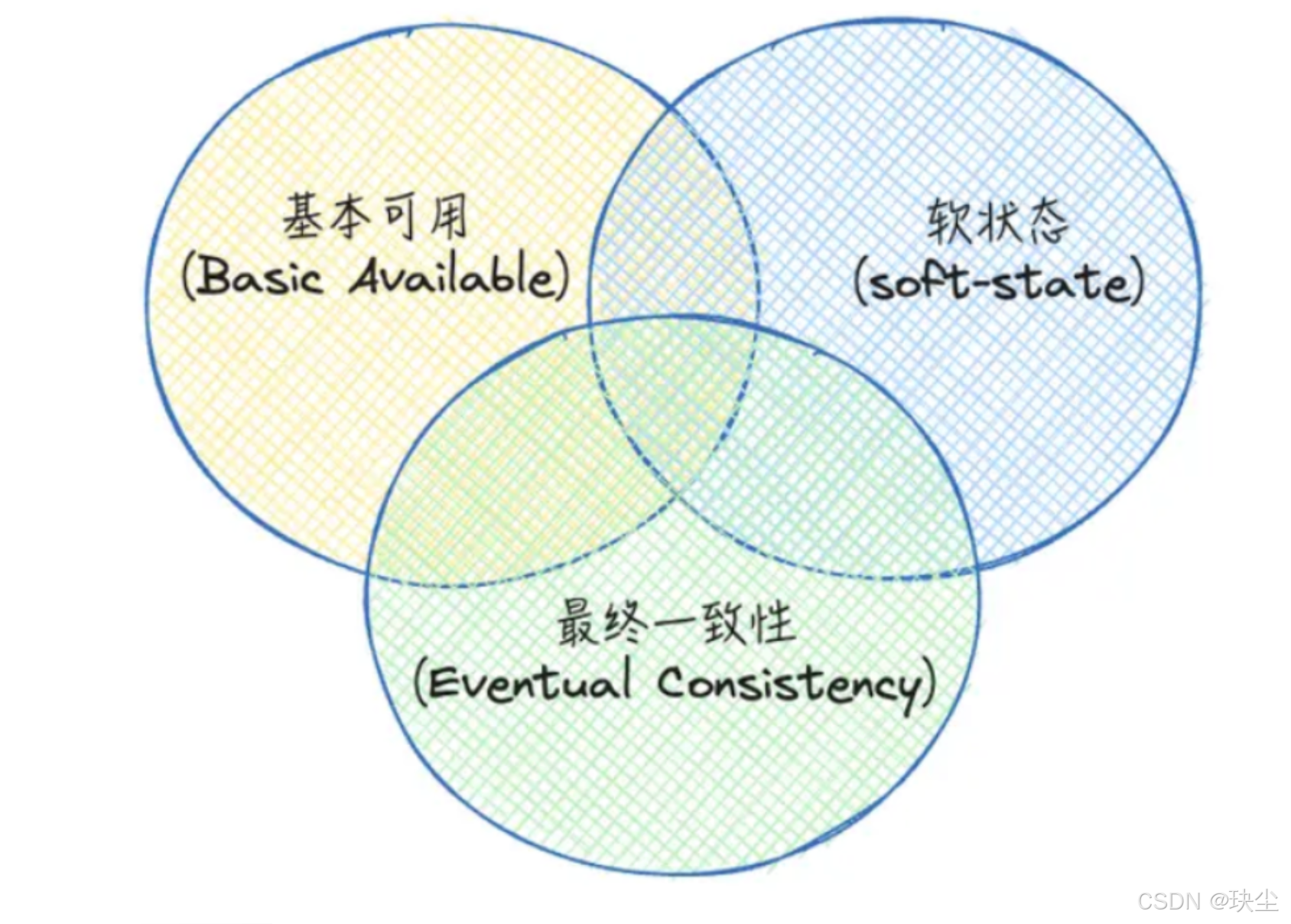
1、Basically Available(基本可用):基本可用是指分布式系统在出现不可预知的故障的时候,允许损失部分可用性,但不等于系统不可用。
2、Soft state(软状态):即是指允许系统中的数据存在中间状态,并认为该中间状态的存在不会影响系统的整体可用性,即允许系统在不同节点的数据副本之间进行数据同步的过程存在延时。
3、Eventually consistent(最终一致性):强调系统中所有的数据副本,在经过一段时间的同步后,最终能够达到一个一致的状态。其本质是需要系统保证最终数据能够达到一致,而不需要实时保证系统数据的强一致性。